
Performance and Cost Analysis between Elasticity Strategies over
Pipeline-structured Applications
Vinícius Meyer
1 a
, Miguel G. Xavier
1 b
, Dionatra F. Kirchoff
1 c
, Rodrigo da R. Righi
2 d
and Cesar A. F. De Rose
1 e
1
Pontifical Catholic University of Rio Grande do Sul (PUCRS), Porto Alegre, Brazil
2
University of Vale do Rio dos Sinos (UNISINOS), São Leopoldo, Brazil
Keywords:
Resource Management, Elasticity, Pipeline-structured Applications.
Abstract:
With the advances in eScience-related areas and the growing complexity of scientific analysis, more and more
scientists are interested in workflow systems. There is a class of scientific workflows that has become a stan-
dard to stream processing, called pipeline-structured application. Due to the amount of data these applications
need to process nowadays, Cloud Computing has been explored in order to accelerate such processing. How-
ever, applying elasticity over stage-dependent applications is not a trivial task since there are some issues
that must be taken into consideration, such as the workload proportionality among stages and ensuring the
processing flow. There are studies which explore elasticity on pipeline-structured applications but none of
them compare or adopt different strategies. In this paper, we present a comparison between two elasticity
approaches which consider not only CPU load but also workload processing time information to reorganize
resources. We have conducted a number of experiments in order to evaluate the performance gain and cost
reduction when applied our strategies. As results, we have reached an average of 72% in performance gain
and 73% in cost reduction when comparing non-elastic and elastic executions.
1 INTRODUCTION
Scientific workflows are widely performed to model
processes in eScience-related areas and are defined as
a collection of tasks that are processed in a specific or-
der to perform a real application. Scientific workflow
has been proved an efficient and popular method to
model various scientific computing problems in par-
allel and distributed systems (Li et al., 2018). How-
ever, as the complexity of scientific computing de-
mand has increased, this class of application becomes
increasingly data-intensive, communication-intensive
and computation-intensive. Moreover, traditional in-
frastructures such as clusters and grids are expensive
appliances and sometimes complex to expand. There-
fore, it is crucial to perform workflows in cloud com-
puting environments as they implement a pay-as-you-
go cost model (Aldossary and Djemame, 2018).
a
https://orcid.org/0000-0001-5893-5878
b
https://orcid.org/0000-0003-4306-5325
c
https://orcid.org/0000-0002-6604-8723
d
https://orcid.org/0000-0001-5080-7660
e
https://orcid.org/0000-0003-0070-0157
Cloud computing is a large-scale distributed com-
puting ecosystem that provides resources solution
delivered on demand to its customers, driven by
economies (Juve and Deelman, 2011). Those who
benefit from this technology are generating a large
amount of data on various services, which increas-
ingly comes to show all typical properties of scientific
applications. The technological advantages of clouds,
such as elasticity, scalability, accessibility, and reli-
ability, have generated significantly better conditions
to execute scientific experiments than private in-house
IT infrastructures (Li et al., 2018). Elasticity is a fun-
damental characteristic of cloud computing aimed at
autonomous and timely provisioning and releasing of
shared resources in response to variation in demands
dynamically with time (Mera-Gómez et al., 2016).
Managing elasticity implies in being effective and ef-
ficient to provide resource management. Moreover,
a cloud provider, in general, intends to reduce their
costs by an efficient resource sharing and minimizing
energy consumption of their infrastructure (Liu et al.,
2018).
There are studies focused on performing elasticity
in cloud computing (Anderson et al., 2017; Aldos-
404
Meyer, V., Xavier, M., Kirchoff, D., Righi, R. and F. De Rose, C.
Performance and Cost Analysis between Elasticity Strategies over Pipeline-structured Applications.
DOI: 10.5220/0007729004040411
In Proceedings of the 9th International Conference on Cloud Computing and Services Science (CLOSER 2019), pages 404-411
ISBN: 978-989-758-365-0
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

sary and Djemame, 2018) and studies focused on ex-
ploring stage-dependent applications (Li et al., 2010;
Meyer et al., 2019), however, none of them com-
pare or adopt more than one strategy. In this context,
this paper presents and examines two elasticity strate-
gies for pipeline-structured applications, in order to
achieve a gain of performance and cost reduction.
2 BACKGROUND
2.1 Cloud Computing and Elasticity
Cloud computing is an emerging technology that is
becoming increasingly popular because, among other
advantages, allows customers to easily deploy elas-
tic applications, greatly simplifying the process of ac-
quiring and releasing resources to a running appli-
cation, while paying only for the resources allocated
(pay-per-use or pay-as-you-go model). Elasticity and
dynamism are the two key concepts of cloud com-
puting (Lorido-Botran et al., 2014). Using the def-
inition from NIST
1
"Cloud computing is a model
for enabling ubiquitous, convenient and on-demand
network access to a shared pool of configurable com-
puting resources that can be rapidly provisioned and
released with minimal management effort or service
provider interaction". This definition means that elas-
ticity defines the ability of the cloud infrastructure
provider to change quickly the amount of allocated
resource capacity, over time, according to the actual
users’ demand.
Vertical elasticity (scaling up/down) is the abil-
ity that cloud providers have to add/remove process-
ing, memory and/or storage resources inside a run-
ning virtual instance. Horizontal elasticity consists
of adding/removing instances of virtual machines
in/from the cloud environment. These instances can
be virtual machines, containers, or even application
modules (in SaaS). Replication is a wide method
used to provide elasticity, being used in most public
providers (Galante and d. Bona, 2012).
2.2 Elasticity Methods
There are two classes of automatic policies on cloud
computing: Proactive and Reactive. Proactive ap-
proach normally uses heuristics to anticipate the sys-
tem’s load behavior and based on these results, to
decide when and how to scale in/out resources. On
the other hand Reactive approach is based on Rule-
Condition-Action mechanism. A rule is composed of
1
http://www.nist.gov/
a set of conditions that when satisfied trigger some
actions over the underlying cloud. Every condition
considers an event or a metric of the system which
is compared against a threshold. The information
about metrics values and events is provided by the
infrastructure monitoring system or by the applica-
tion (Galante and d. Bona, 2012). Furthermore, us-
ing Reactive method implies that the system reacts
to changes in the workload only when those changes
have been detected (Lorido-Botran et al., 2014). In
this paper, we have adopted a Reactive approach in
our experiments.
2.3 Pipeline-structured Applications
Pipeline-structured workflows enable the decomposi-
tion of a repetitive sequential process into a succes-
sion of distinguishable sub-processes called stages,
each of which can be efficiently executed on a dis-
tinct processing element or elements which operate
concurrently. Pipelines are exploited at fine-grained
level in loops through compiler directives and in oper-
ating system file streams, and at coarse-grained level
in parallel applications employing multiple proces-
sors (Gonzalez-Velez and Cole, 2008).
A pipeline-structured application initially receives
an input, and the last stage returns the result. The pro-
cessing is done from stage to stage, and the output of
each stage is the input of the next one. Each stage is
allocated to a processing element, Virtual Machines
(VMs) in this case, in order to compose a parallel
pipeline. The performance of a pipeline can be char-
acterized in terms of latency, the time is taken for one
input to be processed by all stages, and throughput,
the rate at which inputs can be processed when the
pipeline reaches a steady state. Throughput is primar-
ily influenced by the processing time of the slowest
stage or bottleneck (Bharathi et al., 2008).
3 PROBLEM STATEMENT AND
ELASTICITY STRATEGIES
3.1 Problem Description
A pipeline application is a type of workflow that re-
ceives a set of tasks, which must pass through all
stages of this application in a sequential manner,
which can lead to a prohibitive execution time (Meyer
et al., 2019). The input stream for applications that
use pipeline standards can be intense, erratic or ir-
regular (Righi et al., 2016a). However, specific de-
pendencies and distributed computing problems arise
Performance and Cost Analysis between Elasticity Strategies over Pipeline-structured Applications
405
due to the interaction between the processing stages
and the mass of data that must be processed. Here,
we highlight the most critical problem coming from
pipeline-structured applications: According to the
task flow behavior, some stages may have degraded
performance, delaying subsequent stages and ulti-
mately interfering in the entire application’s perfor-
mance. In this context, we compare two elasticity
strategies for pipeline applications to take advantage
of the dynamic resource provisioning capabilities of
cloud computing infrastructure.
3.2 System Architecture
To reach performance gain on application execution,
we have created techniques to provide elasticity auto-
matically and dynamically in the stages of pipeline-
structured applications in a cloud computing envi-
ronment. For this purpose, we have designed a sys-
tem with some characteristics to support our solu-
tion strategies, as follows: (i) Creating a coordination
mechanism between existing nodes and virtual ma-
chines, knowing which VM belongs to each stage and
when a node is active or inactive; (ii) Performing load
balancing at each stage, to not over-provisioning VMs
in that stage; (iii) Using a communication strategy be-
tween all components that is asynchronous and oper-
ates regardless of the current dimension of the cloud
infrastructure; (iv) Distributing tasks among different
VMs, independent of their processing capacity; (v)
Ensuring elasticity at each stage and also in the whole
system.
Our techniques are designed to operate at the PaaS
level, using a private cloud infrastructure, which al-
lows non-elastic pipeline-structured applications to
derive the benefits of computational cloud elasticity
without the need for user intervention. To provide
elasticity, the model operates with allocation, consol-
idation, and reorganization of instances of virtual ma-
chines over physical machines. The elasticity is sup-
plied independently at each stage in an exclusive way.
There is an agent, named Stage Controller (SC), re-
sponsible for orchestrating all stage requests. Each
stage has a certain number of virtual machines in op-
eration, distributing tasks among them. The SC re-
ceives the requests and places them in the stage’s
queues. After that, SC distributes the next task to
the VMs available in that stage. Elasticity Manager
(EM) monitors each stage and the overall application.
According to the rules established in the chosen tech-
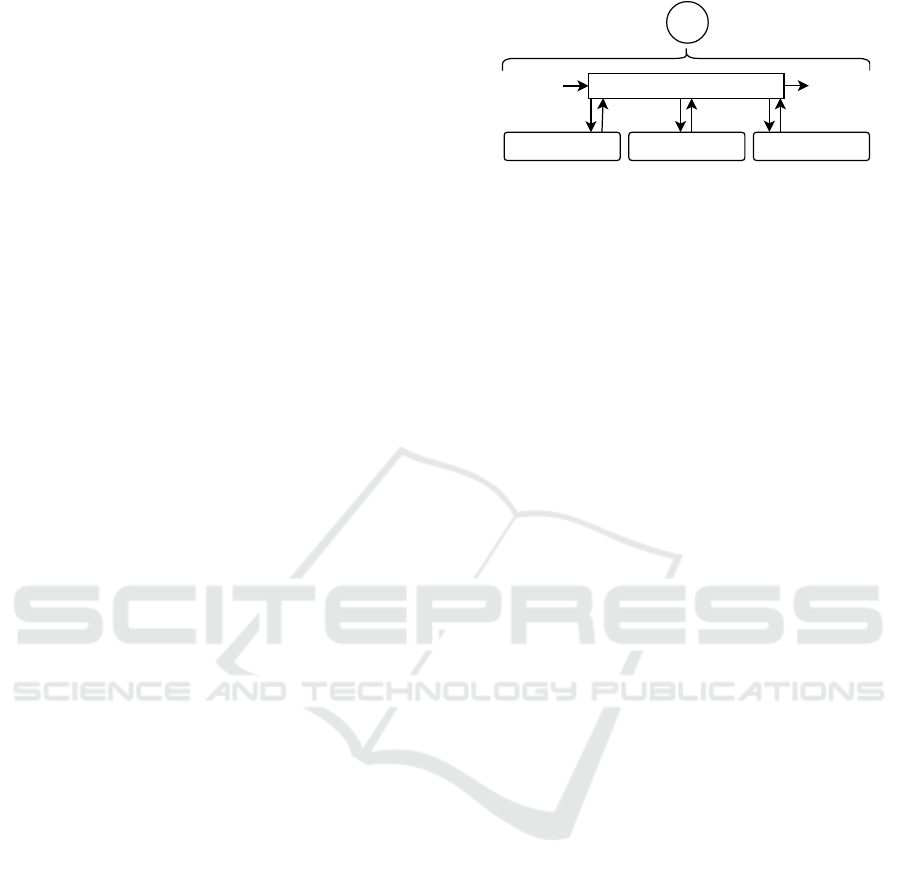
nique and SLA, EM applies elastic actions. Figure 1
shows system architecture overview.
Here is applied the reactive, horizontal and au-
tomatic concept of elasticity, as in (Meyer et al.,
Input
Tasks
Stage1 Stage2 StageN
Output
Tasks
EM
StagesController
Figure 1: System architecture overview.
2019; Righi et al., 2016b). The horizontal elastic-
ity was chosen because the vertical one has limita-
tions among available resource dependencies in a sin-
gle node. Also, most famous operating systems do
not allow on the fly changes in the resources (Dutta
et al., 2012).
Each virtual machine uses only one processor of a
certain node, and for each virtual machine, only one
process will be sent at a time. SC is also an instanti-
ated virtual machine that controls task queues, divides
tasks into sub-tasks, and distribute them to the virtual
machines allocated for the stage in question. After
performing the processing is responsible for grouping
and forwarding the result to the next stage of the ap-
plication. Each virtual machine is allocated to a spe-
cific stage. Since it is allocated to stage 1, for exam-
ple, it will only process requests requested by stage 1
until it is consolidated or transferred to another stage.
Since all stages are monitored individually, each
one can undergo different elasticity actions. While
some stage is instantiating more resources, another
may be consolidating them. When the EM decides
to consolidate resources on a given stage, a checking
is made over the other stages, and if any other stage is
requiring resources, the EM transfers that VM to that
stage instead of being consolidated. This approach
reduces time in the initialization of its operating sys-
tems. If the system needs to instantiate new resources,
EM checks if there is any allocation or consolidation
activity already happening in that stage. If there is,
EM keeps the monitoring. If it does not, it sends a
message to Cloud Front-End to add another VM in
that stage.
3.3 Elasticity Decisions
The Elasticity Manager periodically monitors the
CPU load of virtual machines on each application
stage. It collects processing load (CPU) values from
each virtual machine, which is executing the sub-
tasks of its specific stage and applies a time-series
calculation, also considering values previously col-
lected to acquire the total load, here called as Gen-
eral CPU Load (GCL). Monitoring happens through
a cycle of repetitions. After having a considerable
CLOSER 2019 - 9th International Conference on Cloud Computing and Services Science
406

number of data collections, EM applies an average
on these values, for each stage. According to the up-
per and lower thresholds (Lorido-Botran et al., 2014),
EM evaluates the necessity to instantiate/consolidate
virtual machine(s) in each stage.
The General CPU Load of the system is obtained
through Equation 2, where the function called GCL
(o, e), calculates the simple average of all process-
ing loads of the virtual machines in observation o for
stage e. Where q
e
represents the number of virtual
machines at the stage e. CPU (i, o, e) represents
the CPU load of virtual machines i, at the instant o
in the stage e. CPU loads are obtained through the
Simple Exponential Smoothing (SES) method, repre-
sented by SES (o, e), according to Equation 1.
SES(o, e) =
(
CPU(o,e)
2
if o = 0
SES(o−1,e)
2
+
CPU(o,e)
2
if o 6= 0
(1)
GCL(o, e) =
∑
q
e
i=0
SES(i, o, e)
q
e
(2)
In order to evaluate the techniques, two algorithms
have been tested individually over each scenario. Al-
gorithm 1 follows the idea from (Righi et al., 2016b),
in which the algorithm considers only the CPU load
of the running application. If at a certain application’s
moment, the CPU load of some stage is above the
upper threshold, EM includes more resource in that
stage. If the CPU load is below the lower threshold,
EM removes a resource from that stage. This algo-
rithm is named ReactiveC (RC).
Data: monitoring data
Result: elastic decisions
initialization;
int x=0;
while application is executing do
for (x<stages amount) do
get GCL(stage x);
if (GCL(stage x) > UpperT) then
add VM in stage x;
end
if (GCL(stage x) < LowerT) then
remove VM from stage x;
end
x++;
end
x=0;
end
Algorithm 1: ReactiveC (RC) monitoring routine.
The communication between pipeline stages
might be completely asynchronous and the effi-
ciency of this parallel model is directly dependent
on the ability to balance the load between its stages
(Bharathi et al., 2008). Taking this idea into con-
sideration, Algorithm 2 not only considers CPU load
but also the time execution metrics. This algorithm
aims to reduce the idleness of stage resources caused
by delays in the processing of the previous stage(s).
LTT represents the Last Task Time, avgLT means the
Last Time average and sdLT is the standard deviation
from time metric. When CPU load violates the upper
threshold or when the time of the last task performed
is bigger than the average time minus standard devi-
ation among all stages, EM adds more resources in
that monitored stage. To remove resources is manda-
tory that the CPU load is below the lower threshold
and the time of the last task executed on that stage
is smaller than the other stage’s average plus standard
deviation. The purpose of this approach is to create an
interval of time that is acceptable for not making elas-
tic actions. This idea is an improvement from (Meyer
et al., 2019) and is named as ReactiveCT (RCT).
Data: monitoring data
Result: elastic decisions
initialization;
int x=0;
boolean lc=false;
while application is executing do
for (x<stages amount) do
get GCL(stage x);
get LTT(stage x);
if (GCL(stage x) > UpperT) then
add VM in stage x;
end
if (GCL(stage x) < LowerT) then
lc=true;
end
if (LTT(stage x) < (avgLC-sdLT) & lc== true) then
remove VM from stage x;
end
if (LTT(stage x) > (avgLC+sdLT)) then
add VM in stage x;
end
x++;
end
x=0;
end
Algorithm 2: ReactiveCT (RCT) monitoring routine.
4 EVALUATION
METHODOLOGY
4.1 Elastic Speedup and Elastic
Efficiency
In order to observe the computational cloud elastic-
ity gain for pipeline-structured applications, two met-
rics have been adopted as an extension of the concepts
of speedup and efficiency: Elastic Speedup (ES) and
Elastic Efficiency (EE) (Righi et al., 2016a). These
metrics are exploited according to the horizontal elas-
ticity, where virtual machine instances can be added
or consolidated during application processing, chang-
ing the number of processes (CPUs) available. To
evaluate the system, it is considered a homogeneous
environment and each virtual machine instance can
execute 100% of a computational processing core. ES
is calculated by the function ES (i, l, u) according to
Equation 3, where i represents the initial number of
Performance and Cost Analysis between Elasticity Strategies over Pipeline-structured Applications
407

virtual machines while u and l represent the upper
and lower limits for the number of virtual machines
defined by the SLA. Moreover, t
ne
and t
e
refer to exe-
cution times of the executed application in elastic and
non-elastic scenarios. Thus, t
ne
is interpreted by the
minimum number of virtual machines (i) to execute
the whole application.
ES(i, l, u) =
t
ne
(i)
t
e
(i, l, u)
(3)
The function EE(i,l,u), represented by the Equa-
tion 4, calculates the elastic efficiency. Theses func-
tion parameters are the same as the function ES. Ef-
ficiency represents how effective the use of resources
is, and this is positioned as the denominator of the
formula. In this case, the number of resources are
dynamically changed and, for that reason, a mecha-
nism has been created to achieve a single value. EE
assumes the execution of a monitoring system which
captures the time spent in each configuration of vir-
tual machines. The Equation 5 presents the metric
Resources used in the EE calculation indicating the
resource usage of the application where pt
e
(j) is the
time interval in which the application was executed
with j virtual machines. Equation 4 presents the pa-
rameter i in the numerator, which is doing multiplica-
tion with elastic speedup.
EE(i, l, u) =
ES(i, l, u) × i
Resources(i, l, u)
(4)
Resources(i, l, u) =
u
∑
j=l
( j ×
pt
e
( j)
t
e
(i, l, u)
) (5)
4.2 Energy and Cost Model
To complement the resource consumption analysis,
not only Elastic Efficiency will be considered but also
a way to measure the resources consumed during the
execution of the application, named Energy. This
metric is based on the close relationship between en-
ergy consumption and resources consumption (Org-
erie et al., 2014). In this work, we have applied the
same idea from a model utilized by Amazon and Mi-
crosoft: it is considered the VM amount in each time
unit (e.g one hour). This idea is presented in Equa-
tion 6. The variable pt
e
(j) represents the time inter-
val that the application was executed with j VM in-
stances. The time unity depends on the pt
e
value (sec-
onds, minutes, hours) and the strategy is to sum the
number of virtual machines used in each unit of time.
Thus, Energy measures the use from l to u virtual ma-
chines instances, considering the partial time execu-
tion in each organization of the used resources. The
Energy metric allows us to compare different applica-
tions that use elasticity ranges.
Energy(l, u) =
u
∑
j=l
( j × pt
e
( j)) (6)
To estimate the elasticity viability in several sit-
uations, a metric was adopted that calculates the ex-
ecution time cost by multiplying the total execution
time of the pipeline-structured application by the en-
ergy used, according to the Equation 7. This idea is
an adaptation of parallel computation with elastic sce-
narios use cases. Energy consumption is proportional
to the resources usage (Righi et al., 2016a). The goal
is to obtain a lesser cost with elastic utilization com-
pared to static resources usage. Summing up, a con-
figuration can be considered as bad, if it is able to
reduce the total execution time by half of the elastic
application, but spends six times more, increasing the
costs.
Cost = application_time × Energy (7)
Cost
e
≤ Cost
we
(8)
The goal is to preserve the truth of inequality 8,
where Cost
e
represents the cost of application execu-
tion with elasticity and Cost
we
the cost of application
execution without elasticity.
4.3 Application and Test Scenarios
To mitigate the elasticity strategies, we have devel-
oped a synthetic application that processes images
over three different stages, following the idea from
(Li et al., 2010) and (Meyer et al., 2019). The original
images pass through three stages suffering sequential
changes and producing a final result. In order to create
load variations, the size of the image areas has been
distributed in four scenarios: Constant, Increasing,
Descending and Oscillating. The difference among
them is the order of area size of each image. For in-
stance, Increasing scenario starts with a small image
and it goes increasing until the end of the image list.
Decreasing is exactly the opposite of Increasing, the
area size of each image starts large and goes decreas-
ing. The same logic is applied to the other two sce-
narios. This workload variation forces the system to
have different processing levels, forcing the different
elasticity arrangements. Thus, the sum of all image
areas in each load configuration results in the same
value, so in each test, the amount of processed data is
the same.
In all scenarios, with elasticity actions, many
thresholds were tested. As lower thresholds, 20%,
CLOSER 2019 - 9th International Conference on Cloud Computing and Services Science
408

30% and 40% have been used. For each lower thresh-
old, the upper threshold has been set to 60%, 70%
and 80%, producing nine variations to each one of the
four workload scenarios. Thus, this amount of tests
was executed on each elasticity algorithm. To analyze
the performance improvement with elasticity strate-
gies we also executed all proposed scenarios without
making elastic actions. In this case, the application
ran with only the minimum number of necessary re-
sources to complete all the tasks (WE, Without Elas-
ticity).
4.4 Computational Environment
All performed tests have been run over a Private
Cloud Computing Environment. We have adopted
OpenNebula
2
(v 5.4.13) as Cloud Front-End Middle-
ware. The proposed study was executed over 10 Dell
Optiplex 990, with 8GB of RAM and a Core i5 CPU
each one. Thus, the environment is considered as ho-
mogeneous. EM runs in one of these machines, and
for that purpose, this one is not used by the cloud.
The communication among the machines has been
made with Fast Ethernet (100 MBit/s) interconnec-
tion. All used codes and results are available in a
GitHub repository
3
.
5 RESULTS AND DISCUSSIONS
5.1 Analyzing Speedup and Efficiency
In the Constant scenario, the best speedup is achieved
by using the RC strategy (74% of performance gain),
and the worst case in this workload is adopting the
RCT strategy (70% of performance gain). On the
other hand, in all other scenarios, the best perfor-
mance was reached by using the RCT strategy. When
comparing their results with applications which do
not use elasticity, Decreasing scenario improves its
performance in 71% (best) and 61% (worst). The
increasing scenario has 81% (best) and 68% (worst)
of performance gain. Oscillating scenario achieves
76% (best) and 67% (worst) of performance gain, re-
spectively. The reason for this behavior is that when
the workload does not change, the task time factor
does not affect the resource reorganization since the
tasks in each stage are already balanced among them.
When the workload has variations over the applica-
tion execution, task time factor helps to balance the
proportionality among the stages of the application,
2
http://opennebula.org/
3
https://github.com/viniciusmeyer/closer2019
increasing the data flow and achieving a gain of per-
formance.
0
1
2
3
4
5
0.0
0.5
1.0
1.5
con_rc
con_rct
dec_rc
dec_rct
inc_rc
inc_rct
osc_rc
osc_rct
Scenario
Speedup
Efficiency
efficiency rc efficiency rct Speedup
Figure 2: Speedup and Efficiency average from all proposed
scenarios.
Figure 2 shows the average of all speedup and ef-
ficiency metrics in each scenario (among all thresh-
olds combinations). It is possible to notice that in
the experiments where workload varies (dec, inc, osc)
the RCT strategy has a better Speedup than Constant
scenario. When the workload is constant (con), the
best speedup is achieved with RC strategy, enforcing
our previous analysis. Hence, we claim our Obser-
vation 1: When the workload is balanced (with
no load variation), RC strategy tends to reach a
gain of performance over pipeline-structured ap-
plication. The efficiency is higher using the RC strat-
egy, the explanation from this behavior comes from
the idea that not taking time tasks into consideration,
the resource reorganization tends to add and remove
VMs faster than RCT strategy. Removing resources
happens even more frequently than adding it, because
of RCT strategy has a clause that only remove VMs
when thresholds and time rules are violated. By keep-
ing more resources, RCT reaches lower Efficiency
than RC strategy. That leads us to our Observation
2: In cases that the workload is unknown, keep-
ing more resources for pipeline-structured appli-
cations ensures the processing flow.
5.2 Analyzing Energy and Cost
Every scenario respects the inequality 8: The ap-
plication cost not making elastic decisions needs to
be equal or lower than applications using elasticity
strategies. In the Constant scenario, the application
cost is 81% better than scenario without elasticity.
The worst case is 57% better than no making elas-
tic actions. In the Decreasing scenario, the best and
worst case are 79% and 68% of gain, respectively. In
Performance and Cost Analysis between Elasticity Strategies over Pipeline-structured Applications
409

0
2500
5000
7500
10000
con_rc
con_rct
dec_rc
dec_rct
inc_rc
inc_rct
osc_rc
osc_rct
Scenario
Energy
(a) Energy average
0e+00
2e+06
4e+06
6e+06
8e+06
con_rc
con_rct
dec_rc
dec_rct
inc_rc
inc_rct
osc_rc
osc_rct
Scenario
Cost
(b) Cost average
Figure 3: Energy and Cost results from all scenarios.
the Increasing scenario 83% (b) and 57% (w) and in
the Oscillating scenario 90% (b) and 71% (w) of gain
compared with a scenario without elasticity strategy.
Figure 3a presents the result of the average’s en-
ergy from all tests. The result from the energy equa-
tion is proportional to resource utilization over time
application execution. As we previously mentioned,
RCT strategy tends to keep more resources than RC
strategy. Because of it, the energy is lower by apply-
ing the RC strategy. Furthermore, RCT is the strat-
egy which presents the higher energy utilization in-
dex in all cases. Figure 3b presents the result of av-
erage’s cost from all tests. RC strategy has the lowest
cost overhead. The RCT strategy performs the high-
est cost. This behavior happens because Cost equa-
tion is proportional to the energy index, enforcing our
previous explanation. After that, we state our Ob-
servation 3: consuming more energy (higher costs)
does not always benefit pipeline-structured appli-
cation’s performance.
5.3 Analyzing Resources Utilization
In order to analyze resource utilization, we have cal-
culated a resource usage percentage during time exe-
cution of some experiments: without elasticity (con,
dec, inc, osc) and its best (_b) and worst (_w) cases
with elasticity. We have chosen the best and worst
scenarios based on speedup indexes. Therefore, in the
Constant scenario the best performance was achieved
by applying the RC strategy and in other scenarios,
the best performances were reached utilizing RCT
strategy. These percentages can be observed on Fig-
ure 4. As shown in Oscillating, Increasing and De-
creasing scenarios, in worst cases (_w), higher levels
of resource utilization percentage are more scattered
over time execution than best scenarios (_b). How-
ever, the exact opposite occurs in the Constant sce-
nario: by using more resource over time execution
decreases the performance. Here, we state our Obser-
vation 4: when the workload varies, adding more
resources benefit pipeline-structured application’s
performance.
con
con_b
con_w
dec
dec_b
dec_w
inc
inc_b
inc_w
osc
osc_b
osc_w
0 500 1000 1500 2000 2500 3000
Time (s)
Experiments
0 25 50 75 100
Resources Utilization (%)
Figure 4: Resources utilization: without elasticity (con, dec,
inc, osc) and its best (_b) and worst (_w) elasticity strate-
gies.
6 RELATED WORK
A system for sequential hyperparameter optimiza-
tion for pipeline tasks was proposed by (Anderson
et al., 2017). The main concept is to use sequen-
tial Bayesian optimization to explore hyperparame-
ters’ space. However, these methods are not scalable,
as the entire data science pipeline still must be evalu-
ated on all the data. The author’s techniques are able
to gain similar performance improvements on three
different pipeline tests, but by computing on substan-
tially fewer data.
In order to avoid under or over-provisioning situ-
ations caused by strategies which use a fixed number
of resources in workflow applications, (Meyer et al.,
2019) creates a reactive elasticity model that uses
lower and upper load thresholds and the CPU metric
to on-the-fly select the most appropriated number of
compute nodes for each stage along the pipeline exe-
cution. They have executed a set of experiments and
as results, this elasticity model presents a gain of 38%
in the application time when compared with applica-
tions which do not make elastic actions.
Techniques as Auto-Regressive Integrated Mov-
ing Average and Recurrent Neural Network–Long
Short Term Memory are used for predicting the fu-
ture workload of based on CPU and RAM usage rate
collected from a multi-tier architecture integrated into
cloud computing ecosystem (Radhika et al., 2018).
After analyzing both techniques, RNN-LSTM deep
learning technique gives the minimum error rate and
can be applied on large datasets for predicting the fu-
ture workload of web applications.
CLOSER 2019 - 9th International Conference on Cloud Computing and Services Science
410

To connect a cloud platform-independent model
of services with cloud-specific operations, (Alipour
and Liu, 2018) presents an open source benchmark
application on two cloud platforms to demonstrate
the method’s accuracy. As a result, the proposed
method solves the vendor lock issue by model-to-
configuration-to-deployment automation.
7 CONCLUSION AND FUTURE
WORK
In this paper, we present two elasticity strategies for
pipeline-structured applications to achieve a gain of
performance and minimize execution cost. Our tech-
niques monitor pipeline-structured application’s met-
rics and provide elasticity over the entire system in
an asynchronous and automatic way, by stage. The
RC strategy only considers the CPU load thresholds
while RCT strategy uses information from workload
as well. In order to evaluate the results, we have
conducted many experiments with different threshold
combinations and workload variations among them.
We have pointed out performance gain and cost re-
duction is totally dependent on the workload varia-
tion. As result, we achieve an average of 72% in per-
formance gain and 73% in cost reduction when com-
paring non-elastic and elastic executions. When com-
pared with related work, our study improves perfor-
mance gain in up to 34%.
As future work, we plan to include our elasticity
strategies in simulation tools in order to test different
machine arrangements.
REFERENCES
Aldossary, M. and Djemame, K. (2018). Performance and
energy-based cost prediction of virtual machines auto-
scaling in clouds. In 44th Euromicro Conference on
Software Engineering and Advanced Applications.
Alipour, H. and Liu, Y. (2018). Model driven deployment
of auto-scaling services on multiple clouds. In IEEE
International Conf. on Soft. Architecture Companion.
Anderson, A., Dubois, S., Cuesta-infante, A., and Veera-
machaneni, K. (2017). Sample, estimate, tune: Scal-
ing bayesian auto-tuning of data science pipelines. In
Int. Conf. on Data Science and Advanced Analytics.
Bharathi, S., Chervenak, A., Deelman, E., Mehta, G., Su,
M., and Vahi, K. (2008). Characterization of scientific
workflows. In 2008 Third Workshop on Workflows in
Support of Large-Scale Science.
Dutta, S., Gera, S., Verma, A., and Viswanathan, B. (2012).
Smartscale: Automatic application scaling in enter-
prise clouds. In 2012 IEEE Fifth International Con-
ference on Cloud Computing.
Galante, G. and d. Bona, L. C. E. (2012). A survey on cloud
computing elasticity. In IEEE Fifth International Con-
ference on Utility and Cloud Computing.
Gonzalez-Velez, H. and Cole, M. (2008). An adaptive par-
allel pipeline pattern for grids. In IEEE International
Symposium on Parallel and Distributed Processing.
Juve, G. and Deelman, E. (2011). Scientific Workflows in
the Cloud, pages 71–91. Springer London, London.
Li, J., Humphrey, M., van Ingen, C., Agarwal, D., Jackson,
K., and Ryu, Y. (2010). escience in the cloud: A modis
satellite data reprojection and reduction pipeline in the
windows azure platform. In IEEE International Sym-
posium on Parallel Distributed Processing.
Li, Z., Ge, J., Hu, H., Song, W., Hu, H., and Luo, B. (2018).
Cost and energy aware scheduling algorithm for sci-
entific workflows with deadline constraint in clouds.
IEEE Transactions on Services Computing.
Liu, J., Qiao, J., and Zhao, J. (2018). Femcra: Fine-
grained elasticity measurement for cloud resources al-
location. In IEEE 11th International Conference on
Cloud Computing.
Lorido-Botran, T., Miguel-Alonso, J., and Lozano, J. A.
(2014). A review of auto-scaling techniques for elastic
applications in cloud environments. Journal of Grid
Computing.
Mera-Gómez, C., Bahsoon, R., and Buyya, R. (2016). Elas-
ticity debt: A debt-aware approach to reason about
elasticity decisions in the cloud. In 9th International
Conference on Utility and Cloud Computing.
Meyer, V., Righi, R. R., Rodrigues, V. F., Costa, C. A. D.,
Galante, G., and Both, C. (2019). Pipel: Exploit-
ing resource reorganization to optimize performance
of pipeline-structured applications in the cloud. Inter-
national J. of Computational Systems Engineering.
Orgerie, A.-C., de Assuncao, M. D., and Lefevre, L. (2014).
A survey on techniques for improving the energy effi-
ciency of large-scale distributed systems. ACM Com-
put. Surv.
Radhika, E. G., Sadasivam, G. S., and Naomi, J. F. (2018).
An efficient predictive technique to autoscale the re-
sources for web applications in private cloud. In 4th
Int. Conf. on Advances in Electrical, Electronics, In-
formation, Communication and Bio-Informatics.
Righi, R. R., Costa, C. A., Rodrigues, V. F., and Rostirolla,
G. (2016a). Joint-analysis of performance and energy
consumption when enabling cloud elasticity for syn-
chronous hpc applications. Concurr. Comput. : Pract.
Exper.
Righi, R. R., Rodrigues, V. F., Costa, C. A., Galante, G.,
de Bona, L. C. E., and Ferreto, T. (2016b). Autoe-
lastic: Automatic resource elasticity for high perfor-
mance applications in the cloud. IEEE Transactions
on Cloud Computing.
Performance and Cost Analysis between Elasticity Strategies over Pipeline-structured Applications
411
