
Application of Artificial Intelligence Approach for Optimizing
Management of Road Traffic
Charlène Béatrice Bridge-Nduwimana
1
, Abdessamad Malaoui
1
and Jilali Antari
2
1
Polydisciplinary Faculty of Beni Mellal, Sultan Moulay Slimane University, Morocco
2
Polydisciplinary Faculty of Taroudant, Ibn Zohr University, Morocco
Keywords:
Road traffic. Fuzzy system. Artificial intelligence. Combination
Abstract:
An approach based on the artificial intelligence is proposed for the management of road traffic. By a fuzzy
system, we are looking for purely numerical parametric characteristics and those that influence its structure. In
fact, we use input and output data from a portion of the road traffic to identify a fuzzy model which makes pos-
sible the evaluation of the results of the estimated parameters obtained. This has been achievable through the
combination of parametric and structural adjustment algorithms with the backpropagation algorithm. Conse-
quently, the obtained results show that adaptive models are successfully used in the analysis and the manage-
ment of road traffic through the efficiency of this combination.
1 INTRODUCTION
Overall, we will deal with the problem of identifying
fuzzy models from input-output data. Sometimes we
need to have the parameters of a system without kno-
wing all the members. Through an example we de-
monstrate this fuzzy identification (RASTEGAR and
al., 2011). With the fuzzy modeling formalism of sys-
tems focusing particularly on the Takagi-Sugeno mo-
del (CHEN and XIAO, 1999) , we represent the non-
linear behavior of a system by a composition of "If
. . . Then" rules, concatenating a set of sub-models lo-
cally linear. In what follows, the fuzzy model has been
identified for a signal based on data in autoregressive
way. This method is simple and allowed us to generate
data without other variables in addition. The model is
capable to predict other data on the process being stu-
died once the optimization phase is over.
To build such models, we approach the applica-
tion of a competitive agglomeration method : the al-
gorithm of Gustafson and Kessel (PALACIO, 2007),
(WU and al., 2018), which belongs to fuzzy cluste-
ring methods based on the minimization of an objec-
tive function. Finally, after having considered the ge-
neral methodology for the construction of the Takagi-
Sugeno fuzzy model from data, we will comment on
what we will obtain as results.
This paper is organised as follows. Section 2 de-
velops Takagi-Sugeno’s fuzy model and discusses the
types of adjustments made to fuzzy systems. Section
3 concisely discusses about achievements in scientific
research related to the subject. And Sect. 4 explains
the approaches adopted and the results of the simula-
tions are established in Sect. 5. Finally, we conclude
this paper in Sect. 6.
For all our simulations, we carried out fuzzy clus-
tering simulations for the structural adjustment, pa-
rametric adjustment simulations with the GLS and
WLS algorithms (OLSSON and al., 2000) combined
with the backpropagation (ELMZABI, 2005) algo-
rithm simultaneously. They give Root Mean Square
Error (RMSE) on the validation set between the pre-
dicted values and measured data.
2 TAKAGI-SUGENO’S (TS)
FUZZY MODELS
Developing an artificial intelligence to process a large
amount of data is therefore an excellent idea. Today,
the practical advantages of artificial intelligence are in
fairly pragmatic operations. A fuzzy system is a sys-
tem that integrates human expertise and aims to emu-
late the reasoning of human experts in complex sys-
tems. It is an important part of artificial intelligence.
In fuzzy systems, the basic idea is to model pro-
cesses as would the human being (BOUZID and
S.BENMERIEM, 2013). The relationships between
input and output variables are explicitly represen-
Bridge-Nduwimana, C., Malaoui, A. and Antari, J.
Application of Artificial Intelligence Approach for Optimizing Management of Road Traffic.
DOI: 10.5220/0009771200050010
In Proceedings of the 1st International Conference of Computer Science and Renewable Energies (ICCSRE 2018), pages 5-10
ISBN: 978-989-758-431-2
Copyright
c
2020 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
5

ted in the form of "If . . . Then . . . " rules, ie : If
HYPOTHESIS (antecedent part) Then CONCLUSION
(consequent part) (ISHIBUSHI and al., 1995). The
above form allows to interpret the results and to deter-
mine the action of each rule and express an inference
(MILAN and al., 2018) mechanism such that if a
fact (hypothesis) is known, then another fact (conclu-
sion) can be inferred. The Takagi-Sugeno fuzzy mo-
del (RASTEGAR and al., 2011) uses linear functions
in the consequent part : for i rule and j output, we
have : y
i
j
= f
i
j
(x).
So, it can be seen as a combination (TOMAR and
al., 2018) of the linguistic model and the mathemati-
cal regression (TOMAR and al., 2018) model in the
sense that the antecedents describe fuzzy regions in
the input space in which the consequent functions are
valid. Basically, this model can encode the expertise,
either directly from the prior knowledge of the pro-
blem, or indirectly from a set of learning data. It is
very easy to identify because the conclusion of each
rule is linear and its parameters can be estimated from
the numerical data using optimization (MILAN and
al., 2018) methods such as least squares algorithms.
We will use more particularly these models be-
cause they allow to approach non-linear systems by a
combination (TOMAR and al., 2018) of several linear
and simple local models. They are written as follows
(IQDOUR, 2006) :
R
i
: I f x
t
is A
i
T hen
b
y
t,i
= β
0i
+ x
T
t
β
i
(1)
R
i
(i = 1, 2, ..., c) indicates the i
th
fuzzy rule, x
t
(t =
1, 2, ..., N) is the input variable (x
t
∈ R
n
),
b
y
t,i
is the
output of the i
th
rule relative to the input x
t
, A
i
a fuzzy
set (YANG and HU, 2018) and β
i
= (β
1
, β
2
, ..., β
n
)
T
.
2.1 Structural Adjustment
Structural adjustement is about determining the cor-
rect number of rules to use in a fuzzy system (DASS
and SRIVASTAVA, 2018), (KASHANI and MOHAY-
MANY, 2011). The structure to be searched for will
have to be rich enough to allow for optimal learning,
but not too much to avoid noise modeling in the data.
2.2 Parametric Adjustment
Once the number of rules determined, it is necessary
to estimate the parameters (β
i
) for each conclusion of
the rules. If we have :
W
i
=
µ
i1
0 · · · 0
0 µ
i2
· · · 0
.
.
.
.
.
.
.
.
.
.
.
.
0 0 · · · µ
iN
(2)
X =
x
1
.
.
.
x
N
, y =
y
1
.
.
.
y
N
(3)
And if we have :
X
e
= [1 X],
e
X =
W
1
X
e
W
2
X
e
. . . W
c
X
e
.
2.2.1 Weighted Least Square (WLS)
The localized linearization method causes the resolu-
tion of c independent optimization problems. Linear
parameters obtained do not depend on how the rules
are aggregated. The criterion to be minimized is :
J =
c
∑
i=1
N
∑
t=1
w
i
ˆy
t
− x
T
t
β
i
2
(4)
The determination of the linear parameters β
i
passes by the minimization of the criteria of each local
model. This amounts to solving c independent weigh-
ted least squares problems whose solution is :
β
i
=
X
T
e
W
i
X
e
−1
X
T
e
W
i
y (5)
2.2.2 Global Least Square (GLS)
The global system resulting from this method (IQ-
DOUR, 2006), approximates the database with more
perfection. But nothing tells us that the linear models
thus obtained are optimal in their areas of expertise.
Linear parameters are obtained by solving the equa-
tion :
e
Xβ = y or
e
X
T
e
X
β =
e
X
T
y (6)
The criterion to be minimized for GLS is :
J =
1
2
N
∑
t=1
ˆy
t
− y
t
2
(7)
3 A STATE OF THE ART
Accurate data from accident and road databases
can be essential for modeling, mapping, identifying
hazardous road segments and other studies to make
decisions in a road network. Researches relating to
the problems that are in the databases of road traffic
and which propose solutions exist and bring a plus.
Among them, we have :
C. Yixin and X. Deyun (CHEN and XIAO, 1999)
represent an extension of the Takagi-Sugeno-Kang
model (ETSK). Its analytic expression has been de-
livered and an algorithm to identify such a mo-
del has been proposed. TSK with variable weight
ICCSRE 2018 - International Conference of Computer Science and Renewable Energies
6
(VWTSK) was made to present the fuzzy control-
ler algorithm of the ETSK model even definition of
fuzzy rules since they are roughly equivalent. The si-
mulation of this algorithmshows that the ETSK mo-
del can give more precision on the long-term pre-
dictions and the control algorithmcan reach a better
controlmore efficient that Proportional-Integral- Deri-
vative fuzzy regulation (PID). Furthermore, an adap-
tive control identification or method for a system ba-
sed on FCM-KNN (Fast Fuzzy C-Means—K-Nearest
Neighbors) and PSO (Particle Swarm Optimization)
has been proposed by Rastegar et al. (RASTEGAR
and al., 2011). The model identify the structure and
parameters of the nonlinear model : the fuzzy set and
the number of rules, and the location of the member-
ship functions are automatically pulled from the sys-
tem data. In comparison with other identification me-
thods, larger values corresponding to a lower num-
ber of fuzzy rules have been achieved. Thus, their
results showed that the proposed control model can
control the process just by using a database of the
TS Adaptive Fuzzy Model initialization process. On
the other hand, C. N. Babu and B. E. Reddy (BABU
and REDDY, 2015), for the prediction of time-based
internet traffic that is very volatile in nature, have ex-
plored the applicability of various forecasting models.
They considered during their study ARIMA (AutoRe-
gressive Integrated Moving Average), ANN (Artifi-
cial Neural Network), Zhang’s ARIMA-ANN hybrid
model, Khashei and Bijari’s ARIMA-ANN hybrid
model, the ARIMA-ANN multiplicative model, MA
(Moving Average Filter) filter based on the ARIMA-
ANN hybrid model. One-step and/or multi-step pre-
dictions have been made. The measures of the er-
ror performance, MAE (Mean Absolute Error) and
RMSE (RootMean Squared Error) are used to eva-
luate accuracy (BOVEIRI and ELHOSENY, 2018),
(HAIDI and al., 2018), (CHEN and al., 2018). The
results of the forecast in both cases showed that the
MA filter based on the ARIMA-ANN hybrid model
outperformed all the others models, both in terms of
MAE and RMSE and is therefore suitable for more
accurate prediction of internet traffic data.
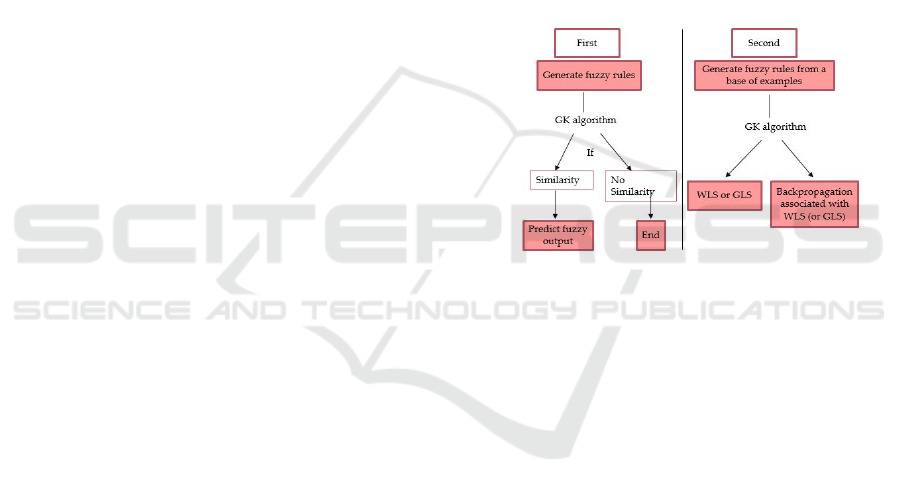
4 APPROACHES
At first, we generate (ISHIBUSHI and al., 1997)
fuzzy rules of the TS model. We use classification
(KASHANI and MOHAYMANY, 2011), (MURU-
GAN and al., 2019), (SHANKAR and al., 2018) ,
(MUHAMMAD and al., 2019) , (HURRAH and al.,
2019) algorithm (Gustafson Kessel : GK (BABUSKA
and al., 2002) to estimate the number and initial po-
sitions of cluster centers where each one allows us
to determine a fuzzy relationship between inputs and
outputs by checking their similarity. Then we adopt
fuzzy generation algorithms to predict fuzzy output.
Even though there is no indication of this kind of pro-
blem, the GK algorithm (WU and al., 2018) makes it
possible by giving the state or the quality of the road
traffic taken as example from the output of the fuzzy
model.
Secondly, we generate fuzzy rules from a base of
examples where we want to classify the outputs into
a set of predefined fuzzy classes. Then we use the
first approach for fuzzy rule generation, we apply a
weighted or generalized least squares fit to compare
the fuzzy and predefined outputs of our model (Fig.
1).
Figure 1: Approaches.
5 RESULTS
5.1 First Simulation
In Figs. 2 and 3, we represent the results after a si-
mulation realized on matlab R2017a. There are the
membership functions, the linear β
i
and nonlinear pa-
rameters that are estimated with the WLS or GLS al-
gorithms.
And in the following tables, Tables 1 and 2, we
present the results on different values of the set of in-
put in order to capture the sensitivity and the effects
of these two methods on our example.
5.2 Second Simulation
In order to estimate road traffic (IHUEZE and ON-
WURAH, 2018) parameters, we use a database
consisting of daily measured values for January 2012.
These values were taken in the Gironde region, a
french department located in the south-west of the
Application of Artificial Intelligence Approach for Optimizing Management of Road Traffic
7

Figure 2: For 31 values with WLS algorithm.
Figure 3: For 31 values with GLS algorithm.
Table 1: Results obtained with WLS algorithm.
Values Clusters RMSE Errors
11 4 0.0076 6.3315 × 10
−4
21 4 0.0217 0.0099
31 4 0.0467 0.0676
51 4 0.0580 0.1717
71 6 0.0498 0.1763
151 8 0.0494 0.3678
501 26 0.0226 0.2554
Table 2: Results obtained with GLS algorithm.
Values Clusters RMSE Errors
11 4 0.0074 6.0077 × 10
−4
21 4 0.0213 0.0095
31 4 0.0460 0.0655
51 4 0.0582 0.1730
71 6 0.0498 0.1758
151 8 0.0446 0.2997
501 28 0.0185 0.1709
country in the New Aquitaine region. You should
know that a very simple autonomous car is only a ca-
tegorization in real time to identify all objects on the
road and define the behavior to adopt.
The performance criterion chosen remains the root
mean squared error. We chose to sort three complete
classes of the database that normally contains several
classes (see Tables 3 and 4). We want to estimate the
ratio between the length and speed provided. This is
indeed an important data that characterizes the portion
of the road taken into consideration.
Table 3: Results for WLS algorithm.
Class Clusters RMSE Errors
CL1 : 4 0.0324 0.0326
CL2 : 4 1.3714×10
−
4 5.8305×10
−
7
CL3 : 4 5.3609×10
−
4 8.9092×10
−
6
Table 4: Results for GLS algorithm.
Class Clusters RMSE Errors
CL1 : 4 0.0313 0.0304
CL2 : 4 1.3724×10
−
4 5.8389×10
−
7
CL3 : 4 5.3909×10
−
4 9.0088×10
−
6
A better approximation is an added value for predic-
tion which is very useful in applications because it al-
lows to generate traffic data for localities where mea-
surements are not available. When the linear function
is bounded and the activation function is derivable,
it is possible to use powerful learning algorithms ba-
sed on the search for a minimum of the error func-
tion, in particular the backpropagation (WANG and
MENDEL, 1992) of the gradient which includes hid-
den layers. So, to update the connection weight within
a network so that it succeeds in the task that is asked
of it, and thus apply our example to artificial intelli-
gence (JOHNSON and al., 2018), we used the method
of backpropagation (HASSABIS and al., 2017).
Table 5: Results for WLS & Backpropagation algo-
rithm.
Class Clusters RMSE Errors
CL1 : 4 0.0311 0.0299
CL2 : 4 1.3712×10
−
4 5.8284×10
−
7
CL3 : 4 5.3922×10
−
4 9.0137×10
−
6
Table 6: Results for GLS & Backpropagation algo-
rithm.
Class Clusters RMSE Errors
CL1 : 4 0.0298 0.0276
CL2 : 4 1.3723×10
−
4 5.8380×10
−
7
CL3 : 4 5.3864×10
−
4 8.9941×10
−
6
5.3 Comments
The results obtained in Figs. (2) and (3) show that
whatever the WLS or GLS algorithm we can have a
ICCSRE 2018 - International Conference of Computer Science and Renewable Energies
8

good estimate justified by the mean squared error not
by the graph. We can note that the choice of the num-
ber of clusters in the algorithm depends on how much
data appears to us. It is important to find a number of
clusters that best estimate the input. In statistics, ge-
neralized least squares are techniques for estimating
parameters unknows in a linear regression model. In-
deed, GLS is used to perform a linear regression when
there is some degree of correlation between values
in a model. In this case, the classical weighted least
square method can be statistically ineffective or even
give misleading inferences.
In accordance with previous results (in Tables 5
and 5), the results show that backpropagation asso-
ciated with GLS, under conditions of poor specifica-
tion, provides realistic indices of model implementa-
tion and less biased parameter values for paths that
overlap with the real model. However, despite the re-
commendations of the literature that WLS should be
used when data is not distributed normally, we find
that under no circumstances is the WLS method better
than the other two methods of estimating parameters
in terms of bias and implementation. In fact, only for
large sample and for implementation indices close to
those obtained for backpropagation and the GLS me-
thod. In addition for wrongly specified models, WLS
gives low estimates reliable and overly optimistic va-
lues of fit.
With simulations performed with WLS / GLS
methods associated with backpropagation simulta-
neously, if we increase the number of iterations there
is noise added because it takes more time during the
simulation. It will be the same if we increase the num-
ber of hidden layers where a certain amount of in-
formation will be lost. It is advisable to consider few
layers hidden to avoid noise and a number of reaso-
nable iterations that best justifies the convergence of
the error towards zero. Then the class CL1 is the best
estimated by the GLS associated with backpropaga-
tion method which is more confident and is likely to
help us make a decision.
6 CONCLUSION
In this work the fuzzy model TS has been identi-
fied for our example and for a signal of the road traffic
studied based on data in an autoregressive way. This
method is simple and allowed us to generate data wi-
thout the need to use other variables in addition. Mo-
reover, once the optimization phase is over, the model
is capable to predict other data on the process being
studied. We used design methods based on a learning
that allows to iteratively define the best set of parame-
ters : the optimization of fuzzy rules (WLS, GLS) and
the optimization of membership functions. We also
have proposed one of the WLS or GLS optimization
models with backpropagation to test the convergence
of the error. The results obtained show that even with
a non linear we can hope to obtain quite satisfactory
performance.
REFERENCES
BABU, C. and REDDY, B. (2015). Performance compari-
son of four new arima-ann prediction models on inter-
net traffic data. Journal of Telecommunications and
Information Technology, 1 :67–75.
BABUSKA and al. (2002). Improved covariance estima-
tion for gustafson-kessel clustering. IEEE Internatio-
nal Conference on Fuzzy Systems, pages 1081–1085.
BOUZID, H. and S.BENMERIEM (2013). Application de
la technique de la logique floue pour la prédiction de
l’amorçage des intervalles d’air pointes-plans. Uni-
versité Kasdi Merbah -Ouargla, Algérie.
BOVEIRI, H. and ELHOSENY, M. (2018). A-coa : an
adaptive cuckoo optimization algorithm for conti-
nuous and combinatorial optimization. In Neural
Computing and Applications, pages 1–25.
CHEN and al. (2018). Emotion recognition using empiri-
cal mode decomposition and approximation entropy.
Computers and Electrical Engineering, 72 :383–392.
CHEN, Y. and XIAO, D. (1999). Fuzzy identification and
control algorithms based on an etsk model. 14th Trien-
nial World Congress, 32 :5456–5461.
DASS, A. and SRIVASTAVA, S. (2018). Identification and
control of dynamical systems using different architec-
tures of recurrent fuzzy system. ISA Transanctions.
ELMZABI, A. (2005). Une approche adaptative basée sur
le clustering flou : Outil d’aide à la gestion intelli-
gente du réseau. PhD thesis, Faculté des Sciences et
Techniques Mohammedia, Maroc.
HAIDI and al. (2018). Feature selection based on artificial
bee colony and gradient boosting decision tree. In Ap-
plied Soft Computing, volume 74, pages 634–642.
HASSABIS and al. (2017). Neuroscience-inspired artificial
intelligence. Neuron 95, pages 245–258.
HURRAH and al. (2019). Dual watermarking framework
for privacy protection and content authentication of
multimedia. Future Generation Computer Systems,
94 :654–667.
IHUEZE, C. and ONWURAH, U. (2018). Road traffic ac-
cidents prediction modelling : An analysis of anam-
bra state, nigeria. Accident Analysis and Prevention,
pages 21–29.
IQDOUR, R. (2006). Modélisation des séries temporelles
par les systèmes flous et les réseaux de neurones :
application à la prédiction des processus météorolo-
giques. PhD thesis, Faculté des Sciences Semlalia,
Maroc.
ISHIBUSHI and al. (1995). Selecting fuzzy if-then rules
for classification problems using genetic algorithms.
IEEE Transactions on Fuzzy Systems, 3 :260–270.
Application of Artificial Intelligence Approach for Optimizing Management of Road Traffic
9

ISHIBUSHI and al. (1997). A simple but powerful heuristic
method for generating fuzzy rules from medical data.
Journal of Fuzzy Sets and Systems, pages 251–270.
JOHNSON and al. (2018). Artificial intelligence in cardio-
logy. Journal of the American College of Cardiology,
71 :2668–2679.
KASHANI, A. and MOHAYMANY, A. (2011). Analysis
of the traffic injury severity on two-lane, two-way ru-
ral roads based on classification tree models. Safety
Science, 49 :1314–1320.
MILAN and al. (2018). Fuzzy optimization model and
fuzzy inference system for conjunctive use of surface
and groundwater resources. Journal of Hydrology,
566 :421–434.
MUHAMMAD and al. (2019). Efficient fire detection for
uncertain surveillance environment. IEEE Transac-
tions on Industrial Informatics, 15.
MURUGAN and al. (2019). Region-based scalable smart
system for anomaly detection in pedestrian walkways.
Computers and Electrical Engineering, 75 :146–160.
OLSSON and al. (2000). The performance of ml, gls, and
wls estimation in structural equation modeling un-
der conditions of misspecification and nonnormality.
Structural Equation Modeling, pages 557–595.
PALACIO, V. (2007). Modélisation et commande floues de
types Takagi-Sugeno appliquées à un bioprocédé de
traitement des eaux usées. PhD thesis, Université Paul
Sabatier, Toulouse.
RASTEGAR and al. (2011). Self-adaptative takagi-
sugeno model identification methodology for indus-
trial control processes. IECON 2014-40th Annual
Conference of the IEEE Industrial Electronics.
SHANKAR and al. (2018). Optimal feature level fusion
based anfis classifier for brain mri image classifica-
tion. Concurrency and Computation Practice and Ex-
perience.
TOMAR and al. (2018). Traffic management using logis-
tic regression with fuzzy logic. Procedia Computer
Science, pages 451–460.
WANG, L. and MENDEL, J. (1992). Back-propagation
fuzzy system as nonlinear dynamic system identifiers.
WU and al. (2018). Bisimulations for fuzzy transition sys-
tems revisited. International Journal of Approximate
Reasoning, 99 :1–11.
YANG, B. and HU, B. (2018). Communication between
fuzzy information systems using fuzzy covering ba-
sed rough sets. International Journal of Approximate
Reasoning, 103 :414–436.
ICCSRE 2018 - International Conference of Computer Science and Renewable Energies
10
