
Exploring Crowdsourced Reverse Engineering
Sebastian Heil, Felix F
¨
orster and Martin Gaedke
Technische Universit
¨
at Chemnitz, 09107 Chemnitz, Germany
Keywords:
Reverse Engineering, Crowdsourcing, Microtasking, Concept Assignment, Classification, Web Migration,
Software Migration.
Abstract:
While Crowdsourcing has been successfully applied in the field of Software Engineering, it is widely over-
seen in Reverse Engineering. In this paper we introduce the idea of Crowdsourced Reverse Engineering and
identify the three major challenges: 1) automatic task extraction, 2) source code anonymization and 3) quality
control and results aggregation. To illustrate Crowdsourced Reverse Engineering, we outline our approach
for performing the Reverse Engineering activity of concept assignment as a crowdsourced classification task
and address suitable methods and considerations with regard to each of the the three challenges. Following a
brief overview on existing research in which we position our approach against related work, we report on our
experiences from an experiment conducted on the crowdsourcing platform microworkers.com, which yielded
187 results by 34 crowd workers, classifying 10 code fragments with decent quality.
1 INTRODUCTION
Migration of legacy systems to the Web is an im-
portant challenge for companies which are develo-
ping software. Driven by the high number of ways
in which users interact with recent web applications,
changing user expectations pose new challenges for
existing non-web software systems. Continuous evo-
lution of technologies and the termination of support
for obsolete technologies furthermore intensify the
pressure to renew these systems (Wagner, 2014). As
web browsers are becoming the standard interface for
many applications, web applications provide a solu-
tion to platform-dependence and deployment issues
(Aversano et al., 2001). Many companies are aware
of these reasons for web migration. On the other
hand, in particular Small and Medium-sized Enterpri-
ses (SMEs) find it difficult to commence a web mi-
gration (Heil and Gaedke, 2017).
Using LFA
1
problem trees, we identified doubts
about feasibility as one of the main factors which
are keeping SME-sized software developing compa-
nies from migrating their existing software products
to the web. This is mainly due to the danger of losing
knowledge. Successful software products of small
and medium-sized software providers are often spe-
cifically tailored to a certain niche domain and result
1
Logical Framework Approach, cf. http:// ec.europa.eu/
europeaid/
from years of requirements engineering (Rose et al.,
2016). Thus, the amount of valuable domain kno-
wledge from problem and solution domain (Marcus
et al., 2004) such as models, processes, rules, algo-
rithms etc. represented by the source code is vast.
(Wagner, 2014) The redevelopment required due to
the many paradigm shifts for web migration – client-
server separation in the spatial and technological di-
mension, asynchronous request-response-based com-
munication, explicitely addressable application states
via URLs and navigation to name but a few – bear the
risk of losing this knowledge.
However, in legacy systems, domain knowledge
is only implicitly represented by the source code
and often poorly documented (Warren, 2012; Wag-
ner, 2014). Reverse Engineering is required to eli-
cit the knowledge, make it explicit and available for
subsequent web migration processes. Existing re-
documentation approaches (Kazman et al., 2003) are
not feasible for small and medium-sized enterprises
since they cannot be integrated into day-to-day agile
development activities. Therefore, we introduced an
approach based on source code annotations (Heil and
Gaedke, 2016) which allows to enrich the legacy
source code by directly linking parts of it with re-
presentations of the knowledge which they contain.
Supported by a web-based platform, this enables de-
velopers to reference the knowledge in emails, wikis,
task descriptions etc. and to jump directly to their de-
Heil, S., Förster, F. and Gaedke, M.
Exploring Crowdsourced Reverse Engineering.
DOI: 10.5220/0006758401470158
In Proceedings of the 13th International Conference on Evaluation of Novel Approaches to Software Engineering (ENASE 2018), pages 147-158
ISBN: 978-989-758-300-1
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
147

finition and location in the legacy source code. The
identification of domain knowledge in source code
is known as concept assignment (Biggerstaff et al.,
1994).
While manual concept assignment can easily be
integrated into the daily development activities of the
small and medium-sized enterprise and allows to in-
crementally re-discover and document the valuable
domain knowledge, it still requires a high amount of
effort and time, in particular taking into account the
limited resources of small and medium-sized enter-
prises. This process involves reading a source code,
selecting a relevant area of it and determining the type
of knowledge which this area represents, before furt-
her analysis can extract model representations of the
knowledge. This can be considered a classification
task. Crowdsourcing has a history of successful appli-
cation in classification tasks. Also, crowdsourcing has
been successfully employed in software engineering
contexts, in particular on smaller tasks without inter-
dependencies (Stol and Fitzgerald, 2014)(Mao et al.,
2017). Thus, in this work we explore crowdsourced
reverse engineering (CSRE) on the example of iden-
tification of knowledge type in legacy codebases.
Challenges of the Application of Crowdsourcing in
Reverse Engineering include:
1. automatic extraction and preparation of crowd-
sourcing tasks from the legacy source,
2. balancing controlled disclosure of proprietary
source code with readability and
3. quality control and aggregation of results.
In order to create suitable tasks for crowdsourcing
platforms, the legacy source code has to be split into
fragments which can then be classified by the crowd
workers. These fragments should be large enough
to provide sufficient context for a meaningful clas-
sification and small enough to allow for a unambi-
guous classification and a good recall. Since the le-
gacy source is a valuable asset of the company, pu-
blic disclosure of code fragments on a crowdsourcing
platform needs to be well controlled. Competitors
should not be able to identify the authoring company,
the software product or the application domain, in or-
der to prevent them from gaining insights on the soft-
ware product or even replicating parts of it. Howe-
ver, the required anonymization needs to be balan-
ced against the readability of the code. Code obfus-
cation algorithms produce results that are intendedly
hard to read (Ceccato et al., 2014), which jeopardi-
zes getting high quality classification results from the
crowd. Controlling the quality and aggregating the
classification results is a key challenge. In particular,
effort needed to ensure a decent classification quality
should not mitigate the advantage gained by crowd-
sourcing. Fake contributions should be filtered and
contradicting classifications have to be aggregated.
In the following paper, we report on our experiences
in the application of crowdsourcing in the reverse en-
gineering domain. We briefly outline our approach in
2, detail the three aforementioned challenges of auto-
matic task extraction in 3, source code anonymization
in 4 and quality control and results aggregation in 5.
We position our approach against existing work in 6,
report on the results from a small-scale validation ex-
periment in 7 and conclude the paper with an outlook
on open issues in 8.
2 APPROACH
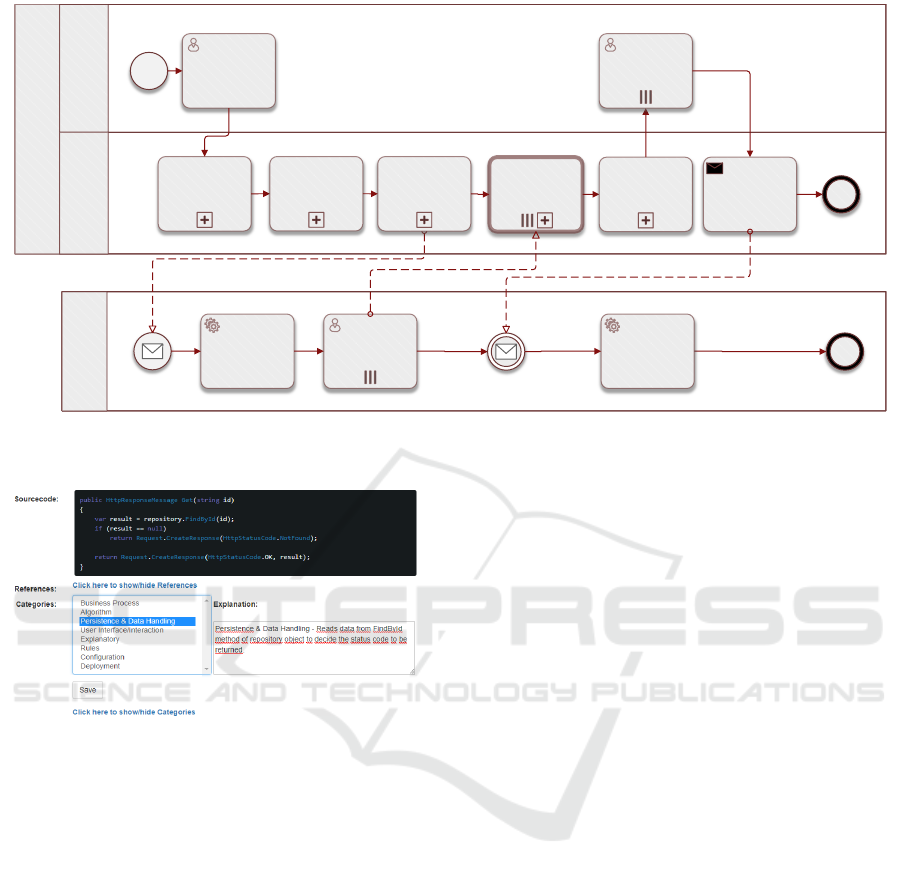
Figure 1 shows an overview of the crowdsourcing-
based classification process for reverse engineering.
There are three roles involved: Migration Engineers
are the actors in charge of conducting the migration,
the Annotation Platform is a system role representing
our platform for supporting web migration through
code annotation (Heil and Gaedke, 2016), and CS
Platform represents a crowdsourcing platform allo-
wing to post classification tasks to crowd workers.
A migration engineer starts the process by defi-
ning the scope on the legacy codebase. This scope can
be defined in terms of selected source files, software
components (represented by project/solution files) or
the complete code base. Next, the annotation platform
automatically extracts code fragments for classifica-
tion as described in section 3.
The next step is the pre-processing of the extracted
fragments for achieving the intended anonymization
properties, which we describe in section 4.
Then, the annotation platform deploys classifica-
tion tasks for each of the anonymized code fragments
in the CS Platform . The data passed to the CS Plat-
form includes a brief description of the reverse engi-
neering classification task, a URL pointing to the cro-
wdworker classification view (figure 2) in the annota-
tion platform, the crowdworker requirements and the
reward configuration. Crowdworkers matching the re-
quirements are provided with a description of the ca-
tegories for classification, following our ontology for
knowledge in source code (Heil and Gaedke, 2016).
The URL pointing to the crowd worker view can
either be presented as a link or integrated in the CS
platform using an iframe, depending on the technolo-
gical capibilities and terms of use of the CS platform.
In the crowd worker view, the crowd worker is
presented with the code fragment to be classified, and
ENASE 2018 - 13th International Conference on Evaluation of Novel Approaches to Software Engineering
148
Software CompanySoftware Company
Migration
Engineers
Migration
Engineers
Annotation
Platform
Annotation
Platform
CS PlatformCS Platform
Start
Define Scope
CS Start
Display
Classification Task
and Link to
Annotation Platform
Get Classification
by Crowdworkers
CS End
Extract Source
Code Areas
Deploy CS Tasks
Anonymize Code
Gather Results
Aggregate Results
and Control Quality
Check and confirm
Classifications
Notify CS Platform
End
Reward
Crowdworkers
Figure 1: Crowdsourcing-based source code classification process.
Figure 2: Crowd worker view.
the list of possible categories. The crowdworker view
additionally contains a list of source code references,
allowing the crowdworker to review also the source
code of pieces of source code which are referenced.
Basic authentication of crowd workers is achieved
through user-specific urls and temporary tokens.
The classification results are then aggregated and
quality control measures are applied as described in
section 5. The filtered results can then be automati-
cally included in the annotation platform, or they are
marked for review by a migration engineer, who can
accept or reject them. Ultimately, the annotation plat-
form notifies the CS platform so that the participating
crowd workers can be rewarded as configured.
In the following three sections, we provide details
about the components addressing the main challenges
raised in the introduction.
3 CLASSIFICATION TASK
EXTRACTION
Micro-tasks are characterized as self-contained, sim-
ple, repetitive, short, requiring little time, cogni-
tive effort and specialized skills (Stol and Fitzgerald,
2014). Of these properties, classification of code frag-
ments matches the first five: classification results are
not dependent on other classification results, the clas-
sification is a simple selection from a list of available
classes, the classification activity is highly repetitive
and a single classification can be achieved in relati-
vely low time. Compared to other successfully cro-
wdsourced classification tasks like image classifica-
tion, a higher cognitive effort is required. Specialized
skills are required, because the crowd workers have
to have a sufficient reading understanding of the pro-
vided source code. However, since reading and un-
derstanding enough of a source code to determine the
correct class requires only a basic understanding of
programming and limited knowledge of the program-
ming language used, the skill requirements are not too
high. It is suitable for a wider range of crowd workers
in comparison to crowdsourcing the development an
application.
In order to extract micro classification tasks from
the legacy code base, the source code has to be au-
tomatically divided. The code fragments for classi-
fication are identified by analysis of the source code
structure. Suitable methods serving this purpose must
have three essential Classification Task Extraction
Properties:
Exploring Crowdsourced Reverse Engineering
149

1. Automation
2. Legacy language support
3. Completeness of references
Automation. A suitable extraction method should
not require additional user interaction to perform the
analysis and to carry out the identification of relevant
code fragments for classification.
Legacy Language Support. Since source code
analysis is programming language specific, the met-
hod should support the most common programming
languages. According to IEEE SPEKTRUM
2
, the
ten most widely used programming languages are: C,
Java, Python, C++, R, C#, PHP, JavaScript, Ruby and
Go. While Go is a relatively new language (appeared
in 2009) and Ruby and Javascript have only recently
seen an increased use in the context of web applicati-
ons, R is a language mainly used for statistics and data
analysis. Typical languages found in legacy software
to a larger extent include C, C++ and Java.
Completeness of References. For a crowd wor-
ker to have sufficient information to properly catego-
rize a code fragment, he must be able to understand
the control and data flow. To provide this informa-
tion to the crowd worker, the extraction method must
also provide information about source code which is
referenced in the code fragment.
We analyzed three groups of approaches for clas-
sification task extraction. Documentation tools are
originally used to automate the creation of source
code documentation. Instead of developing specific
extraction tools, existing documentation tools can be
re-used: Since the structure of the source code is ana-
lyzed in order to create the documentation, this group
of methods offer possibilities for identifying struc-
tural properties of source code. Syntactic analysis
tools explicitely analyze code regarding its structural
properties. There are two different types: regular-
expression-based and parsers. Regular expressions
are used to recognize patterns in texts. Thus, a set of
regular expressions allows identifying relevant source
code areas for classification. Parsers create repre-
sentations of the syntactical structure of a program.
Abstract syntax trees are used to represent the struc-
ture and sequence of program code. Syntax highlig-
hting tools usually generate custom representations of
source code structure in order provide syntax highlig-
hting in text editors.
We systematically investigated the applicability of
these three groups for the extraction of classification
tasks against the three aforementioned essential pro-
perties as requirements. For most programming lan-
2
http://spectrum.ieee.org/computing/software/the-
2016-top-programming-languages
guages, production-grade implementations of docu-
mentation tools exist. Source code references are
completely traceable, ensuring good understanding
for crowd workers. Automation is easily achieved due
to the capability to configure the extraction process
by command line parameters. Regular expressions
are a standardized means of extracting information
from text and are supported by all current program-
ming languages. Thus they can be employed for au-
tomatic extraction from within a surrounding custom
extraction program. However, source code references
can only be traced with high effort and with many ite-
rations of using regular expressions. Parsers, on the
other hand, allow the tracking of source code referen-
ces by analyzing the data and control flow and also
exist for most programming languages. However, the
analysis results generated in the parsing process can
either not be exported or are only available as graphi-
cal representations, making further processing diffi-
cult. Therefore, their use in an automated extraction
process is significantly limited. While syntax highlig-
hting tools allow the identification of code fragments
and, create a structure overview internally, support for
exporting the structure file is only available for certain
platforms. As a result, their applicability is limited.
Based on these considerations and a feasibility study
by students, we decided to use documentation tools
as basis for the fully automated classification task ex-
traction. Our prototypical implementation employs
the tool “Doxygen”
3
and parses the generated docu-
mentation to identify relevant code fragments.
4 SOURCE CODE
ANONYMIZATION
In crowdsourcing, the crowd workers respond to an
open call. They are unknown to the organization and
the group of workers is potentially large.(Latoza and
van der Hoek, 2016) Therefore, placing a task on a
crowdsourcing platform implies making the task con-
tents publicly available. This bears the risk that com-
petitors could access the code fragments published in
the crowd tasks and make unintended use of them.
To enable companies to employ CSRE, means
of source code anonymization are therefore rele-
vant. Code obfuscation techniques provide means to
change source code to make it harder for human rea-
ders to understand maintaining the original functiona-
lity (Ceccato et al., 2014). While this would provide
a certain protection from unintended distribution of a
company’s valuable source code, it also severely im-
3
https://www.stack.nl/ dimitri/doxygen/
ENASE 2018 - 13th International Conference on Evaluation of Novel Approaches to Software Engineering
150

pacts the readability. The impact of code obfuscation
techniques on understandability by human readers has
been assessed in (Ceccato et al., 2014).
The challenge of source code anonymization in
the context of CSRE is to balance information disclo-
sure and readability. While a suitable anonymization
method should modify a source code to sufficiently
prevent unintended use, it has to maintain its readabi-
lity so that crowd workers are still able to achieve a
level of understanding of the code sufficient for per-
forming the reverse engineering task.
This necessary balance is expressed in the follo-
wing Anonymization Properties. A suitable anony-
mization method must:
1. Prevent identification of software provider, soft-
ware product and application domain
2. Maintain the information relevant for classifica-
tion and the control flow
3. Avoid negative impact on readability of the source
In the following, we address these three anonymi-
zation properties. Since achievement of any of the
properties influences the others, we do not structure
this section per property. Any obfuscation techni-
ques which alters the syntactic sequence of expres-
sions, for instance by code optimizations such as in-
line expansion
4
or by adding artificial branches to the
control flow (cf. opaque predicates(Arboit, 2002)) is
disregarded because the control flow is not maintai-
ned. In source code obfuscation, identifier renaming
has shown good results (Ceccato et al., 2014). Iden-
tifiers, however, are not the only parts of code which
contain information that allows identification of soft-
ware provider, software product or application dom-
ain (referred to as identification information in the fol-
lowing). There are three different loci of identification
information: identifiers, strings and comments. While
code obfuscation has to produce identical software,
for anonymization, modifications can also be applied
to string contents, since the altered source code is only
presented to crowd workers for reverse engineering
and not used to compile to running software.
In contrast to code obfuscation, where identi-
fier renaming typically yields intendedly meaningless
random combinations of characters and numbers, re-
placements for source code anynomization in the con-
text of CSRE have to maintain readability and infor-
mation content as good as possible. The na
¨
ıve ap-
proach would be to create custom lists of words to
be replaced and mappings onto their respective repla-
cements. However, this requires a high manual effort
and the completeness of the anonymization highly de-
pends on the completeness of theses lists. For larger
4
replacing calls to usually short functions by their body
code bases as found in the professional software pro-
duction context of small and medium-sized enterpri-
ses as outlined in the introduction, this is not feasible.
There are two main origins of information in iden-
tifiers, strings, comments: problem and solution dom-
ain knowledge (Marcus et al., 2004). Identifiers or
words in strings originating from problem domain
knowledge form identification information. By con-
trast, names originating from solution domain know-
ledge are classification information, i.e. information
relevant for classifying a given piece of source code.
Ideally, an anonymization approach replaces all iden-
tification information while leaving all classification
information untouched. This could be achieved by
analysis and transformation of the underlying domain
model. However, for a legacy system, this is typically
not available in any representation (Wagner, 2014).
Therefore, we first use static program analysis to
extract the Platform Specific Model (PSM), and a list
of all identifiers, which are used as a basis.
Next, we automatically create a replacement map-
ping for each of the identifiers based on results from
the static program analysis. For this, our anonymiza-
tion algorithm distinguishes three basic types of iden-
tifiers: functions, variables and classes. The anony-
mized identifiers are generated based on the identifier
type. For instance, identifiers which represent class
names like BlogProvider are mapped to Class_A,
methods like Blogprovider.Init() to identifiers
like Class_A.Method_A().
Simple relationships like generalization and class-
instance can be expressed in the generated identi-
fiers to maintain a certain level of semantics which
is typically found in the natural-language relations-
hips of the words used as identifiers. For instance, a
class class Rectangle: Shape can be represented
as Class_B_extends_Class_A, an instance variable
Shape* shape = new Shape() can be represented
as instance_of_Class_A. Representation of furt-
her relationships such as composition or aggregation
would require prior creation of a domain model and is
therefore not considered in this exploration.
In the pre-processing phase, the source code is
prepared for the following renaming phase. Due to
the complexity of natural language texts contained in
comments, appropriate modifications would require
high effort. Thus, comments are stripped from the
source code. Like comments, the contents of strings
can contain complex natural language texts, in par-
ticular product or company names. Therefore, they
are replaced by "String". In the renaming phase,
remaining strings and identifiers are then replaced ac-
cording to the previously described mapping.
To assess the readability of the resulting anony-
Exploring Crowdsourced Reverse Engineering
151

mized code, we conducted a brief validation experi-
ment. Six employees of an small and medium-sized
enterprise software provider (Age min 22, max 50,
avg 32.7; Experience min 6, max 29, avg 13.2 years)
rated the readability of 10 anonymized source code
fragments (length min 7, max 57, avg 27.4 LOC, cf.
7.1) on a five-level Likert scale (measuring agreement
between 1 and 5 for: The code is easy to read.) As
expected, Obfuscation performed worst (0.7). Our
approach (3.7) shows a slight improvement over the
na
¨
ıve approach (3.2).
5 QUALITY CONTROL AND
RESULTS AGGREGATION
Crowdsourcing reverse engineering activities pro-
duces a set of results from different, potentially
unknown contributors. These results may even be
contradicting. For companies, the quality of results
from CSRE must justify the invested resources. Thus,
quality control and results aggregation is crucial.
Considering the classification task described in
2, the amount of correctly classified code fragments
should be as high as possible (i.e. high precision and
high recall). This depends on several factors. Crowd
workers could provide fake answers to maximize their
financial reward, leading to poor quality. Different le-
vels of experience among the crowd workers can lead
to different classification results on the same code
fragment.
The combination of approaches used to achieve
good results quality is described according to the
schema in (Allahbakhsh et al., 2013) by the following
quality control and results aggregation properties:
1. Worker selection
2. Effective task preparation
3. Ground truth
4. Majority consensus
Worker selection and effective task preparation are
quality-control design-time approaches, Ground truth
and majority consensus are quality-control run-time
approaches (Allahbakhsh et al., 2013).
Worker Selection. Since the quality of crowd-
sourcing results highly depends on the experience of
the crowd workers, we use reputation-based worker
selection (Allahbakhsh et al., 2013). In most crowd-
sourcing platforms, crowd workers receive ratings ba-
sed on the results they contributed to a task. These
ratings form the reputation of the crowd worker. Only
crowd workers above a specified reputation threshold
are allowed to complete a task. In our experiments on
the bespoke (Mao et al., 2017) crowdsourcing plat-
form microWorkers.com
5
, we allowed only workers
from the “best workers” group to participate.
Effective Task Preparation. The reverse engi-
neering task has to be described in a clear and unam-
biguous way and should keep the effort for fake con-
tributions similar to the effort for solving the task. In
crowdsourcing research, this is known as defensive
design (Allahbakhsh et al., 2013). Crowdworkers are
provided with a brief description of the classification
task and of the available classifications, along with
examples. They can refer back to this description at
any step of the process.
For the classification, they are presented with the
source code and references (as described in 3) with
syntax highlighting, the available categories and a text
input (cf. Figure 2). In this input, crowd workers
have to provide a brief explanation, arguing why they
chose a certain classification. Only explanations with
more than 60 characters will be accepted. This aims at
reducing or at least slowing down fake contributions
and allows for filtering during post-processing, e.g.
filtering out identically copied explanations. Accor-
ding to our compensation policy, crowd workers re-
ceive financial and non-financial rewards: After filte-
ring low quality contributions, remaining crowd wor-
kers receive a financial reward of 0.30 USD, which
corresponds to the platform average during the expe-
riment. Also, they automatically receive a rating of
their contribution as non-financial reward, which im-
proves their reputation.
Ground Truth. For the assessment of the quality
of a contribution by an individual crowd worker, we
employ the ground truth approach: We add previously
solved classification tasks with known correct ans-
wers into the set of all tasks, which form the ground
truth. In this way, assessment of a crowd worker ba-
sed on the correctness of answers for these test ques-
tions can be achieved. We process this information by
calculating an individual user score S(w
i
) ∈ [0, 1] for
each crowd worker w
i
∈ W . Comparing the amounts
of correct classifications C
+
w
i
and false classifications
C
−
w
i
, the user score is calculated as in 1:
S(w
i
) =
|C
+
w
i
|
|C
+
w
i
| + |C
−
w
i
|
(1)
This score can be used as weight factor during results
aggregation.
Majority Consensus. To aggregate the crowd-
sourcing results, we employ the majority consensus
technique. For each source code area to be classified,
the classifications C ⊂ W × T are tuples (w
i
, t
k
) of a
5
https://microworkers.com/
ENASE 2018 - 13th International Conference on Evaluation of Novel Approaches to Software Engineering
152
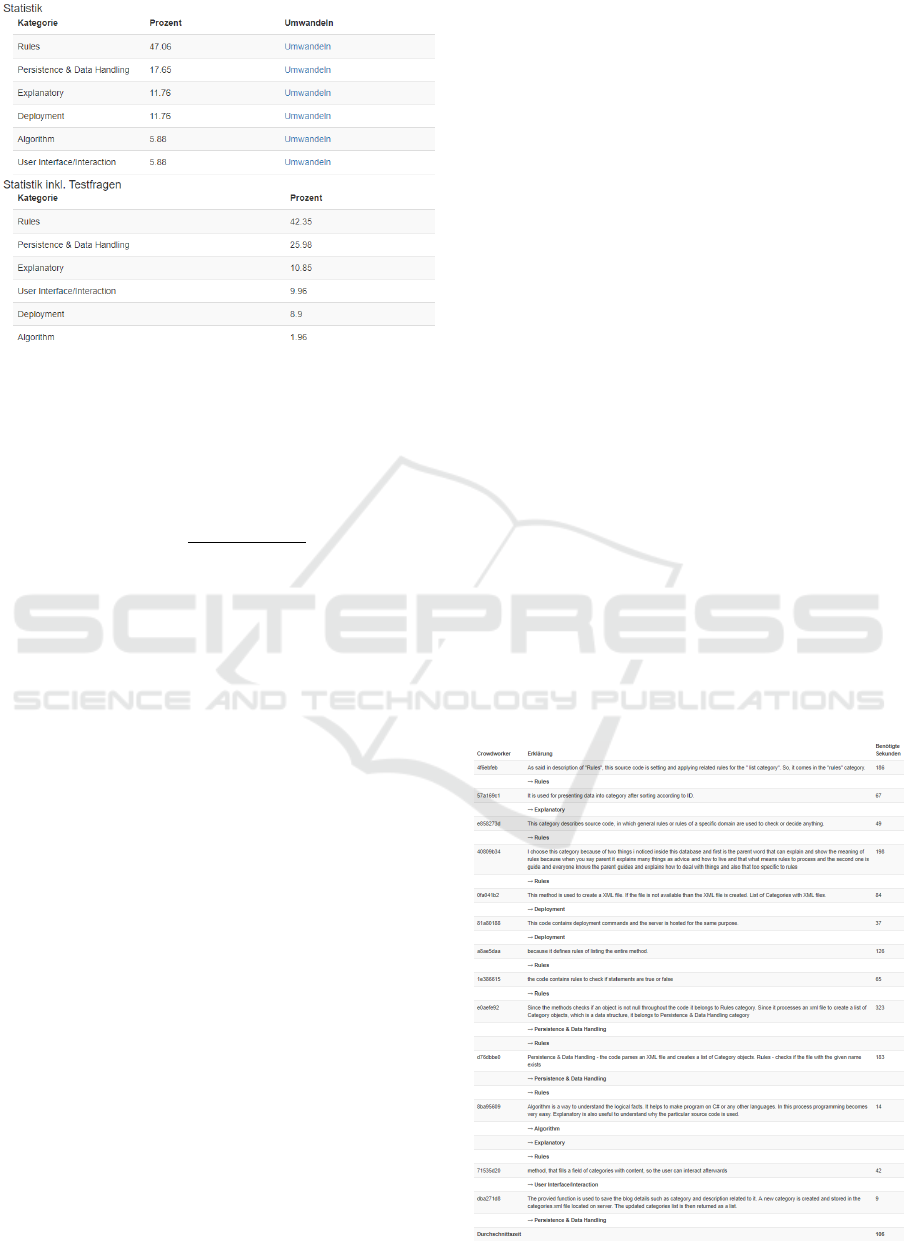
Figure 3: Results statistics view.
crowd worker w
i
∈ W and the type t
k
∈ T which the
crowd worker selected. The resulting voting distribu-
tion V : T 7→ [0, 1] is calculated for all possible types
t
i
∈ T as in 2:
V (t
i
) =
∑
(w,t)∈C|t=t
i
S(w)
∑
(w,t)∈C
S(w)
(2)
The aggregated result t
∗
of all crowd classifications is
the one with the highest voting value as in 3:
t
∗
= arg max
t∈T
V (t) (3)
To provide more control, we display an overview with
the results distributions and explanations so that it
easy to identify and decide edge cases, where no clear
majority could be found (cf. figure 3 and 4).
6 RELATED WORK
Research on the application of crowdsourcing for re-
verse engineering is sparse. Saxe et al. (Saxe et al.,
2014) have introduced an approach for malware clas-
sification combining NLP with crowdsourcing. While
the actual classification work is performed by classi-
cal statistical NLP methods such as full-text indexing
and Bayesian networks, the initial data is provided by
the crowd. The CrowdSource approach creates a sta-
tistical model for malware capability detection based
on the vast natural language corpus available on que-
stion and answer websites like StackExchange. The
model seeks to correlate low-level keywords like API
symbols or registry keys with high-level malware ca-
pabilities like screencapture or network communica-
tion. In contrast to our approach, in CrowdSource,
crowdsourcing is employed only to generate the re-
quired input probabilities for the Bayesian model and
not directly for performing the classification work.
Crowdsourcing has seen some consideration in
software engineering. For instance, (Nebeling et al.,
2012) presents a platform for the crowd-supported
creation of composite web applications. Following
the mashup paradigm, the web engineer creates the
design of the web application based on information
and interface components. Nebeling et al. combine a
passive and an active crowdsourcing model: Sharing
and Reuse is realized by providing a community-
based component library. It contains public compo-
nents which can be used by the web engineer to com-
pose the web application. Active crowdsourcing is
used for the creation of new components. The web en-
gineer defines the required characteristics of the com-
ponent and makes an open call to a paid, external
crowd to provide solution candidates. Improving the
technical quality of the crowdsourced contributions is
stated as one of the main issues. A good overview
on research on crowdsourcing in software engineer-
ing can be found in (Mao et al., 2017), which shows a
strong increase in this area since 2010.
In the HCI area, crowdsourcing was successfully
employed to adapt existing layouts to different screen
sizes (Nebeling et al., 2013). The CrowdAdapt appro-
ach leverages the crowd for the creation of adapted
web layouts and the selection of the best layout vari-
ants. Its focus is on end-user development web layout
tools driven by the crowd. Crowdsourcing was em-
Figure 4: Crowd result details.
Exploring Crowdsourced Reverse Engineering
153

ployed primarily as a means of exploring the design
space and eliciting design requirements for a multi-
tude of viewing conditions. Unlike other crowdsour-
cing approaches in software engineering, CrowdA-
dapt uses unpaid crowd work. Unpaid crowd work
can be successfully employed in many HCI contexts
due to the high number of users who implicitely con-
tribute feedback through their choices and behavior.
Similar to our approach, CrowdDesign (Weidema
et al., 2016) employs the microtasking crowdsourcing
model. CrowdDesign uses paid crowd workers from
Amazon Mechanical Turk for solving small user in-
terface design problems. The focus is on diversity, i.e.
given a set of decision points in the design space, Cro-
wdDesign intends to create various diverse solution
alternatives. Early results indicate that good diversity
can be easily achieved, but only a small percentage of
the crowd-created solutions achieved sufficiently high
quality. In contrast, for reverse engineering classifi-
cation, quality is the most relevant property whereas
diversity in the results is not intended.
Larger industrial case studies on the application of
crowdsourcing in software development like (Stol and
Fitzgerald, 2014) indicate that among the many diffe-
rent activities in software development, those which
are less complex and relatively independent are the
most successful for crowdsourcing. However, even
more complex software development tasks can benefit
from the lower costs, faster results creation and higher
quality of successful crowdsourcing application. Test
automation and modeling of the front end are the two
fields in this case study. Similar to our approach, (Stol
and Fitzgerald, 2014) focuses on the perspective of
an enterprise crowdsourcing customer. A significant
number of defects in the produced results indicates
quality as one of the main problems. Also, the authors
report on problems with continuity since new crowd
workers lacked the experience from their predeces-
sors and would at times even re-introduce previously
fixed bugs. For these reasons, they conclude that from
an enterprise perspective, applicability of crowdsour-
cing in software engineering is limited to areas which
are self-contained without interdependencies, such as
GUI design.
Latoza et al. (Latoza and van der Hoek, 2016)
identifies eight foundational and orthogonal dimen-
sions of crowdsourcing for software engineering:
crowd size, task length, expertise demands, locus of
control, incentives, task interdependence, task context
and replication. Based on these dimensions, they cha-
racterize three existing successful crowdsourcing mo-
dels: peer production, competitions and microtasking.
As shown in Figure 5, the Crowdsourcing-based Re-
verse Engineering Classification described in this pa-
per closely matches the microtasking model. Only
two of the eight dimensions are different: while ex-
pertise demand in microtasking is generally low, we
consider this low to medium for source code classifi-
cation. Task context, i.e. the amount of information
about the entire system required by the worker to con-
tribute, is none for microtasking, compared to low for
the classification. This high similarity indicates a high
likeliness that microtasking can be similarly success-
ful on the small, independent and easily replicatable
source code classification tasks as it already has pro-
ven in software testing. Both areas benefit from the
high number of workers and the possibility to execute
the tasks in parallel. LaToza et al. state that the key
benefit of reduced time to market through crowdsour-
cing can be achieved for models with two characte-
ristics: work must easily be broken down into short
tasks and each task must be self-contained with mini-
mal coordination demands. Our approach meets both
of these characteristics.
Crowd Size
Task Length
Expertise Demands
Locus of Control
Incentives
Task Interdependence
Task Context
Replication
Microtasking CS RE Classification
Figure 5: Comparing Microtasking and Crowdsourced Re-
verse Engineering (CS RE) Classification.
Satzger et al. (Satzger et al., 2014) describe a distribu-
ted software development which abstracts the work-
force as crowd. The private crowd consists of com-
pany employees whereas the public crowd is provi-
ded by crowdsourcing platforms. Aiming at colla-
borative crowdsourcing for the creation of software
in enterprise contexts, the proposed approach starts
with requirement descriptions in customer language
which are than transformed into developer tasks for
the crowd by a software architect. These tasks are
then delegated to private and public crowds, develo-
ped collaboratively. Crowd workers can furthermore
recursively divide tasks into smaller tasks and dele-
gate these tasks to the crowd. The development pro-
cess is iterative and tries to combine properties and ar-
tifacts of agile development methodologies with col-
laborative crowdsourcing. Similarly, our approach in-
tegrates with agile development, however, due to the
ENASE 2018 - 13th International Conference on Evaluation of Novel Approaches to Software Engineering
154

nature of the reverse engineering classification task, it
is not collaborative.
7 EVALUATION
In this section we report on our experiences from an
evaluation experiment which was conducted on cro-
wdsourcing platform microWorkers.
7.1 Experimental Design
To evaluate our proposed approach, we automati-
cally extracted and randomly selected 10 source code
fragments from the open source project BlogEn-
gine.NET
6
, an ASP.NET based blogging platform pu-
blished under the Microsoft Reciprocal License (MS-
RL)
7
. The 10 code fragments had a length between
7 and 57 LOC, on average 25.4 LOC. We manually
classified each of them using the following 8 catego-
ries from our source code knowledge ontology (Heil
and Gaedke, 2016):
1. Business Process
2. Algorithm
3. Persistence & Data Handling
4. User Interface & Interaction
5. Explanatory
6. Rule
7. Configuration
8. Deployment
These categories extend the 3 basic categories typi-
cally considered (presentation, application logic and
persistence (Canfora et al., 2000)) allowing a more
detailed distinction of the knowledge contained in
source code. We implemented our approach in a
prototype by extending our existing source code an-
notation platform (Heil and Gaedke, 2016). Crowd
worker views and authentication mechanisms, classi-
fication task extraction based on doxygen
3
and inte-
gration with crowdsourcing platform microWorkers
5
were implemented.
The crowd worker view was tracking the time
which the crowd worker spent on it, using focus and
blur events. We started a classification campaign
which ran for 14 days. Only workers from the “best
workers” group were allowed to participate. The fi-
nancial reward of 0.30 USD was paid for each set of
3 classifications.
6
http://www.dotnetblogengine.net/
7
https://opensource.org/licenses/MS-RL
7.2 Results
During the experiment, 34 unique crowd workers con-
tributed 187 classifications on our test data set. Table
1 shows the results. F are the ten code fragments,
Categories 1 to 8 correspond to the 8 categories in-
troduced before, |C| is the number of classifications
and |W | the number of crowd workers. The numbers
in the categories cells represent the number of clas-
sifications which classified this code fragment as be-
longing to this category. Highlighted in bold are the
maximum values, which are the basis for the majority
consensus. Highlighted with grey background is the
correct classification of the code fragment. Note that
the number of crowd workers and classifications can
be different, because we allowed to assign more than
one category per fragment. The length of the code
fragment in LOC is indicated by l, Σt represents the
overall time in seconds which crowd workers spent on
the crowd view of the code fragment, t is the average
time. The error rate f
e
(cf. 4)
f
e
=
|C
−
|
|C|
(4)
is the ratio of false classifications to all classifications
of a code fragment.
To investigate the degree of agreement or dis-
agreement between the crowd workers classifications,
we include the entropy E (cf. 5)
E = −
k
∑
i=1
f
i
lg f
i
(5)
and the normalized Herfindahl dispersion measure H
∗
(cf. 6)
H
∗
=
k
k − 1
1 −
k
∑
i=1
f
2
i
!
(6)
based on the relative frequencies f
i
of the classifica-
tions in the k = 8 classes. Entropy and Herfindahl
measure represent the disorder or dispersion among
crowd workers’ classifications, a unanimous classifi-
cation result yields E = 0 and H
∗
= 0. The higher the
disagreement between the crowd workers, the more
different classifications, the closer E and H
∗
get to 1.
Therefore, they can be seen as indicators of the cer-
tainty of the classification across the crowd workers.
On average, 16 crowd workers created 18.7 classifi-
cations per code fragment.
7.3 Discussion
The average error rate was 0.655, which seems high
at first glance. However, due to the majority consen-
sus method, 7 of 10 code fragments could be cor-
rectly classified. The minimum error rate was 0.25
Exploring Crowdsourced Reverse Engineering
155

Table 1: Experimental Results and descriptive statistics.
Categories
F 1 2 3 4 5 6 7 8 |C| |W | l Σt t f
e
E H
∗
A 1 14 4 1 1 1 1 1 24 19 18 2822 122 0.4167 0.6113 0.6906
B 0 1 3 0 0 12 0 0 16 16 20 2531 158 0.25 0.3053 0.4427
C 3 0 4 1 0 1 0 0 10 10 40 1128 112 0.6 0.6160 0.8
D 2 5 6 3 0 5 2 0 23 21 8 3033 131 0.7391 0.7402 0.8948
E 4 2 1 9 2 0 3 1 22 18 7 2580 117 0.5909 0.7228 0.8448
F 0 0 3 0 1 6 7 2 19 15 28 2857 150 0.6316 0.6146 0.8064
G 3 1 1 2 2 6 0 0 15 13 57 3225 215 0.8667 0.6891 0.8395
H 0 2 12 2 4 3 2 2 25 21 24 5249 209 0.52 0.6541 0.7893
I 0 1 3 1 2 8 0 2 17 13 40 1917 112 1 0.6504 0.7920
J 2 2 4 0 1 2 1 4 16 14 12 3393 212 0.9375 0.7902 0.9115
on fragment B and the maximum 1 for fragment I.
Assuming little variation in the expertise of the par-
ticipating crowd workers, this points to differences
in the classification difficulty (fragment I was one of
the longest) and in the understanding of the catego-
ries. Regarding the categories, Rule was the most fre-
quent classification with 23.5%, followed by Persis-
tence & Data Handling (21.9%), Deployment was the
least frequent category (5.3%). Business Process and
Explanatory did not get majorities in the fragments
where they were the correct result, indicating that they
might not be clear enough for the crowd workers. All
other categories were correctly classified by the re-
spective majorities.
Average entropy was calculated at 0.639 and
average Herfindahl dispersion measure at 0.757. The
minima of both co-occur with the minimal error
rate, their maxima with the second-highest error rate.
We found a significant (α = 0.05) positive correla-
tion (Pearson’s ρ = 0.724, p = 0.018) between the
error rate and the entropy and between error rate
and Herfindahl dispersion measure (ρ = 0.757, p =
0.011). Possible interpretation: the more crowd wor-
kers chose one classification, the less likely it is a
wrong classification. Clear majorities for wrong clas-
sifications were not observed in our experiment. This
underlines the basic “wisdom of the masses” princi-
ple of crowdsourcing in gerneral and the assumption
of majority consensus, that majorities are indicative
of correct answers.
Our experiment did not show a correlation bet-
ween the length of a code fragment and the time the
crowd workers needed for classification. This indica-
tes influence of another variable and can be interpre-
ted by assuming different levels of difficulty/clarity of
the classification of the code fragments.
Fragment J was classified as 3 (Persistence) or 8
(Deployment) by the majority. In the texts from the
explanation field, crowd workers argued that it is re-
lated to persistence because the class from which the
fragment was extracted is related to persistence (XML
or DB based). This was a very interesting observation
to us, because our dataset did not inlcude the entire
class source code. Thus, several crowd workers have
looked up the sample source code on the internet and
read also the surrounding parts in order to classify.
We were positively surprised by this level of active
engagement and investment in time by the crowd wor-
kers in order to complete their task.
Our experiment has shown that the the expertise
level of the best crowd workers group on crowdsour-
cing platform microWorkers in combination with our
quality control is sufficient to perform the reverse en-
gineering classification activity and produce decent
results. The overall degree of correctness of 70% is
a good result similar to what can be achieved by a
single expert performing the same task. However,
with less than 20 USD expenses for classifying the
ten code fragments, crowdsourcing is a significantly
more cost-effective solution. The results indicate that
crowdsourcing can be applied to perform specific re-
verse engineering activities, when they are broken
down into small tasks and the process is guided by
suitable quality control methods. Larger-scale experi-
mentation could look deeper into the applicability of
measures for disagreement as indicators for correct-
ness, into suitability of other crowds from different
platforms and into understanding the complexity of
different reverse engineering tasks for crowd workers.
8 CONCLUSION
In this paper, we introduced the idea of crowdsourced
reverse engineering and identified three major chal-
lenges – 1) automatic task extraction, 2) source code
anonymization and 3) quality control and results ag-
gregation – for applying crowdsourcing in the reverse
engineering domain. We illustrated these challenges
in relation to the reverse engineering problem of con-
ENASE 2018 - 13th International Conference on Evaluation of Novel Approaches to Software Engineering
156

cept assignment by presenting our approach based on
crowdsourced classifications. For each of the chal-
lenges, we presented the main properties of suitable
methods and described how we addressed these in our
approach. In particular, we have shown that balancing
readability and anonymization requirements in source
code anonymization is challenging and that it is an in-
teresting field for further research to find more sophi-
sticated methods. We demonstrated a suitable classi-
fication task extraction method re-using existing soft-
ware documentation tools. Regarding the quality as-
surance and aggregation of the crowdsourced results,
we showcased a method based on a combination of
several crowdsourcing quality control methods.
In the overview on existing literature, we identi-
fied a lack of consideration of crowdsourcing for re-
verse engineering, but also demonstrated the simila-
rity of crowdsourced concept assignment to micro-
tasking in eight dimensions and provided examples of
successful application of crowdsourcing in software
engineering. This matching procedure can be used
as a blueprint for identifying further reverse engineer-
ing activities and corresponding crowdsourcing para-
digms to explore their crowdsourced realization in fu-
ture work.
We reported on our experiences from an evalua-
tion experiment on the microWorkers crowdsourcing
platform, which produced 187 results by 34 crowd
workers, classifying 10 code fragments at a low cost.
The quality of the results indicates that crowdsourcing
is a suitable approach for certain reverse engineering
activities. We were positively surprised by some ob-
servations which showed an unexpectedly high level
of engagement and effort by individual crowd wor-
kers to provide good solutions. By calucation of en-
tropy and Herfindahl dispersion measure, we could
see some evidence for the applicability of the wisdom
of the masses crowdsourcing principle in our context,
as higher levels of agreement across the crowd wor-
kers was indicative of correctness.
The next challenge is to see, how similar results
can be achieved in other areas of reverse engineering
or the quality of the results in the described appro-
ach can be further improved. A larger scale evalua-
tion should yield more insights into the applicability
of crowdsourcing for reverse engineering activities, in
particular when combined with more specific, tailored
measures of agreement in crowdworker results. One
very interesting field is the specification of concrete
problem and solution domain models by the crowd. It
has to be investigated if this is possible through iso-
lated microtasking using a more comprehensive clas-
sification ontology specific to the legacy system in-
stance, or whether complex collaborative crowdsour-
cing approaches are required. While anonymization
has been demonstrated as the most difficult challenge
providing many opportunities for further research, in-
vestigation of the application of our proposed method
in contexts without anonymization requirements such
as intra-organzation settings or open source projects
can produce further insights.
ACKNOWLEDGMENTS
This research was supported by the eHealth Research
Laboratory funded by medatixx GmbH & Co. KG.
REFERENCES
Allahbakhsh, M., Benatallah, B., Ignjatovic, A., Motahari-
Nezhad, H. R., Bertino, E., and Dustdar, S. (2013).
Quality control in crowdsourcing systems: Issues and
directions. 17(2):76–81.
Arboit, G. (2002). A method for watermarking java pro-
grams via opaque predicates. In The Fifth Interna-
tional Conference on Electronic Commerce Research
(ICECR-5), pages 102–110.
Aversano, L., Canfora, G., Cimitile, A., and De Lucia, A.
(2001). Migrating legacy systems to the Web: an
experience report. In Proceedings of the Fifth Euro-
pean Conference on Software Maintenance and Reen-
gineering, pages 148–157. IEEE Comput. Soc.
Biggerstaff, T., Mitbander, B., and Webster, D. (1994). The
concept assignment problem in program understan-
ding. In Proceedings of 1993 15th International Con-
ference on Software Engineering, volume 37, pages
482–498. IEEE Comput. Soc. Press.
Canfora, G., Cimitile, A., De Lucia, A., and Di Lucca, G. a.
(2000). Decomposing legacy programs: a first step
towards migrating to clientserver platforms. Journal
of Systems and Software, 54(2):99–110.
Ceccato, M., Di, M., Falcarin, P., Ricca, F., Torchiano,
M., and Tonella, P. (2014). A family of experiments
to assess the effectiveness and efficiency of source
code obfuscation techniques. Empirical Software En-
gineering, 19(4):1040–1074.
Heil, S. and Gaedke, M. (2016). AWSM - Agile Web Mi-
gration for SMEs. In Proceedings of the 11th Inter-
national Conference on Evaluation of Novel Software
Approaches to Software Engineering, pages 189–194.
SCITEPRESS - Science and and Technology Publica-
tions.
Heil, S. and Gaedke, M. (2017). Web Migration - A Sur-
vey Considering the SME Perspective. In Procee-
dings of the 12th International Conference on Evalu-
ation of Novel Approaches to Software Engineering,
pages 255–262. SCITEPRESS - Science and Techno-
logy Publications.
Kazman, R., Brien, L. O., and Verhoef, C. (2003). Ar-
chitecture Reconstruction Guidelines, Third Edition.
Exploring Crowdsourced Reverse Engineering
157

Technical Report November, Software Engineering
Institute, Carnegie Mellon University, Pittsburgh, PA.
Latoza, T. T. D. and van der Hoek, A. (2016). Crowdsour-
cing in Software Engineering : Models , Opportunities
, and Challenges. IEEE Software, pages 1–13.
Mao, K., Capra, L., Harman, M., and Jia, Y. (2017). A
survey of the use of crowdsourcing in software engi-
neering. Journal of Systems and Software, 126:57–84.
Marcus, A., Sergeyev, A., Rajlieh, V., and Maletic, J. I.
(2004). An information retrieval approach to concept
location in source code. Proceedings - Working Con-
ference on Reverse Engineering, WCRE, pages 214–
223.
Nebeling, M., Leone, S., and Norrie, M. (2012). Crowd-
sourced Web Engineering and Design. In Proceedings
of the 12th International Conference on Web Engi-
neering, pages 1–15, Berlin, Germany.
Nebeling, M., Speicher, M., and Norrie, M. (2013). Cro-
wdAdapt: enabling crowdsourced web page adapta-
tion for individual viewing conditions and preferen-
ces. Proceedings of the 5th ACM SIGCHI symposium
on Engineering interactive computing system, pages
23–32.
Rose, J., Jones, M., and Furneaux, B. (2016). An integrated
model of innovation drivers for smaller software firms.
Information & Management, 53(3):307–323.
Satzger, B., Zabolotnyi, R., Dustdar, S., Wild, S., Gaedke,
M., G
¨
obel, S., and Nestler, T. (2014). Chapter 8 - To-
ward Collaborative Software Engineering Leveraging
the Crowd. In Economics-Driven Software Architec-
ture, pages 159–182.
Saxe, J., Turner, R., and Blokhin, K. (2014). CrowdSource:
Automated inference of high level malware functiona-
lity from low-level symbols using a crowd trained ma-
chine learning model. In 2014 9th International Con-
ference on Malicious and Unwanted Software: The
Americas (MALWARE), pages 68–75. IEEE.
Stol, K.-J. and Fitzgerald, B. (2014). Two’s company,
three’s a crowd: a case study of crowdsourcing soft-
ware development. In Proceedings of the 36th Inter-
national Conference on Software Engineering - ICSE
2014, pages 187–198, New York, New York, USA.
ACM Press.
Wagner, C. (2014). Model-Driven Software Migration: A
Methodology. Springer Vieweg, Wiesbaden.
Warren, I. (2012). The renaissance of legacy systems: met-
hod support for software-system evolution. Springer
Science & Business Media.
Weidema, E. R. Q., L
´
opez, C., Nayebaziz, S., Spanghero,
F., and van der Hoek, A. (2016). Toward microtask
crowdsourcing software design work. In Proceedings
of the 3rd International Workshop on CrowdSourcing
in Software Engineering - CSI-SE ’16, pages 41–44,
New York, New York, USA. ACM Press.
ENASE 2018 - 13th International Conference on Evaluation of Novel Approaches to Software Engineering
158
