
Transparent Interoperability Middleware between Data and Service
Cloud Layers
Elivaldo Lozer Frac alossi Ribeiro, Marcelo Aires Vieira, Danie la Barreiro Claro and Nathale Silva
FORMAS (Research Group on Formalisms and Semantic Applications) - LASID - DCC - PGCOMP,
Federal University of Bahia, s/n Adhemar de Barros Ave., Ondina, 40.170-110, Salvador, Bahia, Brazil
Keywords:
Cloud Computing, Interoperability, Middleware, DaaS, DbaaS.
Abstract:
Over the years, many organizations have been using cloud computing services to persist, consume and provide
data. Models such as Software as a Service (SaaS), Data as a Service (DaaS), and Database as a Service
(DBaaS) are consumed on demand to serve a specific purpose. In summary, SaaS is a delivery model for
applications, while DaaS and DBaaS are models to provide data and database management systems on de-
mand, respectively. SaaS applications r equire additional efforts to access those data due to their heterogeneity:
Non-structured (e.g. text), semi-structured (e.g. XML, JSON ), and structured format (e.g. Relational Data-
base). Consequently, the lack of standardization from DaaS and DBaaS generates a lack of interoperability
among cloud layers. In this paper, we propose a middleware MIDAS (Middleware for DaaS and SaaS) to
provide transparent interoperability between Services (SaaS) and Data layers (DaaS and DBaaS). Our current
version of MIDAS concerns two important issues: (i) a formal description of our middleware and (ii) a joining
data f rom different DaaS and DBaaS. To evaluate our middleware, we provide a set of experiments to handle
functional, execution time, overhead, and interoperability issues. Our results demonstrate the effectiveness of
our approach to addressing interoperability concerns in cloud computing environments.
1 INTRODUCTION
The volume of digital data grows exponentially, with
an estimated total of 40 trillion gigabytes in 2020
(Gantz and Reinsel, 2012). Because these data need
to be stored and available both to consumers and to or-
ganization s, da ta manag e ment have been facing som e
challenges to handle the variety and amount d ata. The
cloud computing paradigm has emerged to fill some
of these requirements, once it provides serv ic es with
high availability and data distribution (Me ll et al.,
2011). By 2020, nearly 40% of the ava ilable data will
be managed and stored by a c loud computing provider
(Gantz and Reinsel, 2012).
Authors in (Armbrust et al., 2010) define cloud
computing as a model that en a bles a ubiquitous and
on-demand network of applications, platforms, and
hardware, both provided as services. These services
are organize d into levels and consumed on demand
by users in a scheme of pay-per-use. Software as a
Service (SaaS), Data as a Service (DaaS), and Data -
base as a Service (DBaaS) are instances of service
types organized in cloud levels. SaaS is cloud ap-
plications made available to end users via the Inter-
net. DaaS provides data on dema nd through appli-
cation programm ing interfaces (APIs). DBaaS p rovi-
des database man a gement systems (DBMS) with me-
chanisms for organizations to store , access and mani-
pulate their d atabases (Hacigumus et al., 2002). Alt-
hough confusing, DaaS and DBaaS are different con-
cepts.
The emergence of Inter net of T hings (IoT), social
networks and the use of web-enabled devices su c h as
smartphones, laptops, and notebooks generate a huge
volume and variety of data (Armbru st et al., 2010).
Data ar e stored in non-structur e d, semi-structured or
structured databases. Governments, Institutions, and
Companies most use DaaS as a way to make their data
(expenses, budgets, economic or census data) availa-
ble to pub lic or private users ac ross the Internet (Ba-
routi et al., 2013).
The access to DaaS and DBaaS in different cloud
providers by SaaS applications needs, in most of the
cases, substantial efforts. This kind of situation hand -
les a lock-in problem due to the lack of inte ropera-
bility among cloud levels (Loutas et al., 2011; Silva
et al., 2013). For instance, if demographic researchers
need to make studies about census data provide d by
148
Lozer Fracalossi Ribeiro, E., Aires Vieira, M., Barreiro Claro, D. and Silva, N.
Transparent Interoperability Middleware between Data and Service Cloud Layers.
DOI: 10.5220/0006704101480157
In Proceedings of the 8th International Conference on Cloud Computing and Services Science (CLOSER 2018), pages 148-157
ISBN: 978-989-758-295-0
Copyright
c
2019 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

governments in different DaaS (and/or DBaaS), they
will face the difficult to process these data due to the
lack of standards and consequently no interoperabi-
lity between SaaS and DaaS (and/or DBaaS). To ac-
complish this interoperability issue, we propose our
middleware called MIDAS ( Middleware for DaaS and
SaaS).
Our current version of M IDAS (MIDAS 1.8) is re-
sponsible for mediating the comm unication between
different SaaS, DaaS, and DBaaS. MIDAS makes
possible that SaaS applications retrieve data seam-
lessly on various cloud data sources sin ce our MI-
DAS mediates all communication between SaaS and
DaaS/DBaaS. Our version g uarantees acce ss to DaaS
regardless of modifications mad e to its API.
We propose in this paper a new enhanced ver-
sion of our middleware MIDAS to provide a trans-
parent interoperability among different cloud layers.
The current version of MIDAS (MI DAS 1.8) hand-
les two important issues: (i) a formal description of
our approach and (ii) a join clause to manipulate dif-
ferent data (DaaS a nd DBaaS) into a single query.
Some minor improvements were made in order to ad -
just our MIDAS, such as (i) recogniz ation of diffe-
rent data query structures sent by SaaS, such as SQL
and NoSQL queries; (ii) manipulate different DaaS
and DBaaS from statements such as join (SQL) and
lockup (MongoDB); (iii) manipulate different data
models returned by D aaS and DBaaS, such as JSON,
XML, CSV and table s; and (iv) return the result into
the required format by SaaS, such as JSON, XML,
and CSV.
We performed some experiments to evaluate our
novel approach, con sid ering fou r important issues:
Functional, execution time, overhead, and interopera-
bility. Our results demonstrated that our middleware
is effective, thus providing the desired results.
The remainder of this pap er is organized as fol-
lows: Section 2 presents the most re levant related
works; Section 3 describes our current version of MI-
DAS; Section 4 formalizes our middleware; Section
5 provides a set of experiments to validate our appro-
ach; Section 6 presents some results; and Section 7
conclud es with some envisioning work.
2 RELATED WORKS
Some close works were proposed to solve the lack
of interoperability. In medical field, authors in (Park
and Moon, 2015) propose a solution for heterogene-
ous DBaaS that share medical data between different
institutions. However, this approach handles data th a t
follows the Health Level Seven (HL7) standards, thus
minimizing efforts regarding hetero geneity.
The authors in (Igamberdiev et al., 2016) present
a fra mework to solve problems in Big Data systems
in the ar ea of oil and gas. The g oal is to automate the
transfer of information between projects, identifying
similarities and differences. Their framework handles
only one da ta source per query, not allowing to merge
data from more than one source.
Considering a non- domain-sp e cific interoperabi-
lity solution, there are two related work: (Sellami
et al., 2014 ) an d (Xu et al., 2016). These proposals
do not deal with different types of NoSQL, nor en-
vision to handle NewSQL approaches. Besides, they
manipulate data sou rces witho ut join ing, and they do
not work with data provided by DaaS. It is noteworthy
that manipulating both DaaS and DBaaS is one of the
main advantages of our pro posal.
The cloud Interoperability Broker (CIB) is a solu-
tion to interoperate different SaaS (Ali et al., 2016).
This work was evaluated in a dataset through an ac-
tual application, but unlike our pr oposal, they do not
consider the inter operability between SaaS and DaaS.
Despite the fact that our prior a pproach (MIDAS
1.6) (Vieira et al., 2017), it had some limitations: (i)
Each DaaS m ust be manually inserted and updated;
(ii) DBaaS is not provided; and (iii) data were retur-
ned to SaaS only in JSON for mat.
Thus, to the be st of our knowledge, this is the first
middleware that interoperates SaaS with DaaS and/or
DbaaS in cloud environments.
3 THE CURRENT MIDAS
The current MIDA S architecture is depicted in Fig.
1. This novel approach is composed of six compo-
nents. The Query Decomposer which receives a query
from SaaS and maps the statement into an internal
structure. Query Builder which receives the query de-
composed and builds a query to DaaS and /or DBaaS.
The Data Mapping c omponent which identifies and
obtains data from different DBaaS. Dataset Informa-
tion Storage (DIS), that sets the information about
DaaS APIs. A Crawler which maintains DIS up-to-
date. Finally, the Result Formatter, which formats,
associates, and selects data before returning to SaaS.
The following co mponen ts were included or mo-
dified to meet the goals of our curr e nt version: Data
Mapping, Query Builder, Re sult Formatter, and Cra-
wler. The other components, Query Decomposer and
DIS, both works similarly to our previous version
(Vieira et al., 2017).
The Data Mapping generates a DaaS from a
DBaaS based on a manually ma intained data dicti-
Transparent Interoperability Middleware between Data and Service Cloud Layers
149
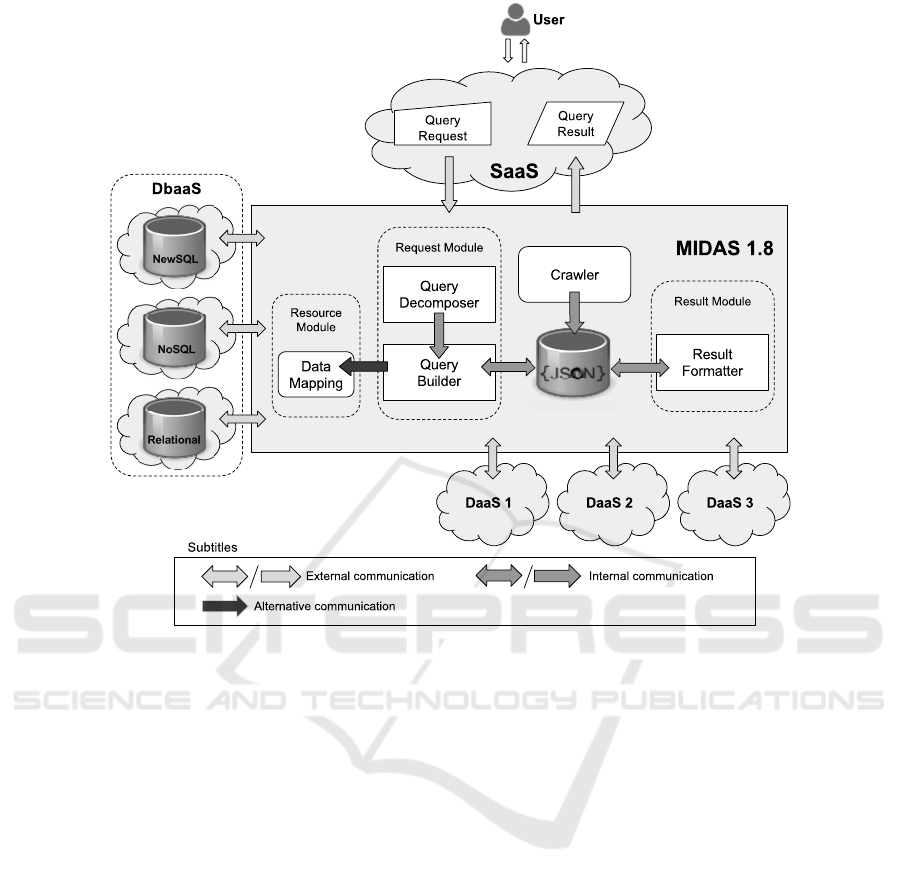
Dataset Information
Storage
Figure 1: Our current MIDAS architecture.
onary. It identifies the DBaaS in which the data is
stored and it obtains the requested data. DBaaS can
be tables, columns, grap hs, key-values or docu ments.
The Query Builder accesses multiple DaaS in a sin-
gle query if the query has a join statement (such as
SQL jo in or Mon goDB aggregation). In our cur-
rent version, th e Result Formatter receives either data
from DaaS and DBaaS and perf orms the merge of
such data, regardless the model. Finally, our Craw-
ler maintains the DIS information up- to-date, consi-
dering that DaaS providers can change the paramete rs
to conduct a query. Besides, the SaaS provider can
now indicate the desired form a t to return its result.
Our Crawler has a challengin g ro le in keep ing
DIS information up-to-date because of the DaaS.
DaaS is not standardized thus it can change fre-
quently. Moreover, they are usually distributed. Our
Crawler sear c hes for every DaaS API information
from its web page, e nsuring that the information does
not cause any h arm to the ap plications, in the c a se of
updating. It was developed to run re peatedly toward
search of different information from those persisted in
DIS. When this information is found to be uneven, it
is recorded in DIS.
Fig. 2 illustrates the MIDAS execution sequence
for a SQL query with the join statement that acces-
ses one DaaS and two DBaaS. In this example, SaaS
sends a SQL query to MIDAS, which performs the de-
composition (by Query Decomposer) and forward s to
the Query Builder. Query Builder accesses the DIS
and identifies that the data is in one DaaS (daas1)
and two DBaaS (dbaas1 and dbaas2). Query Builder
builds the request to DaaS and asks the Data Map-
ping to connect to both DBaaS to get the rest of the
data. Each provider executes the request and returns
the result to the Result Formatter ( daas1, dbaas1, and
dbaas2 returned in CSV, table, and document for-
mats, r espectively). The Result Formatter receives the
data, performs the join, formats the r equested return
(JSON), and forwards to the SaaS.
4 FORMAL MODEL OF MIDAS
The formal model of MIDAS a ims to explain the com-
munication among its modules. The formalization
of MIDAS is based on canonical models (Schreiner
et al., 2015) with trees and sets of keys and values.
Definition 1 (MIDAS internal structure). The struc-
ture used internally by MIDAS (MIDASql) is a tuple
CLOSER 2018 - 8th International Conference on Cloud Computing and Services Science
150
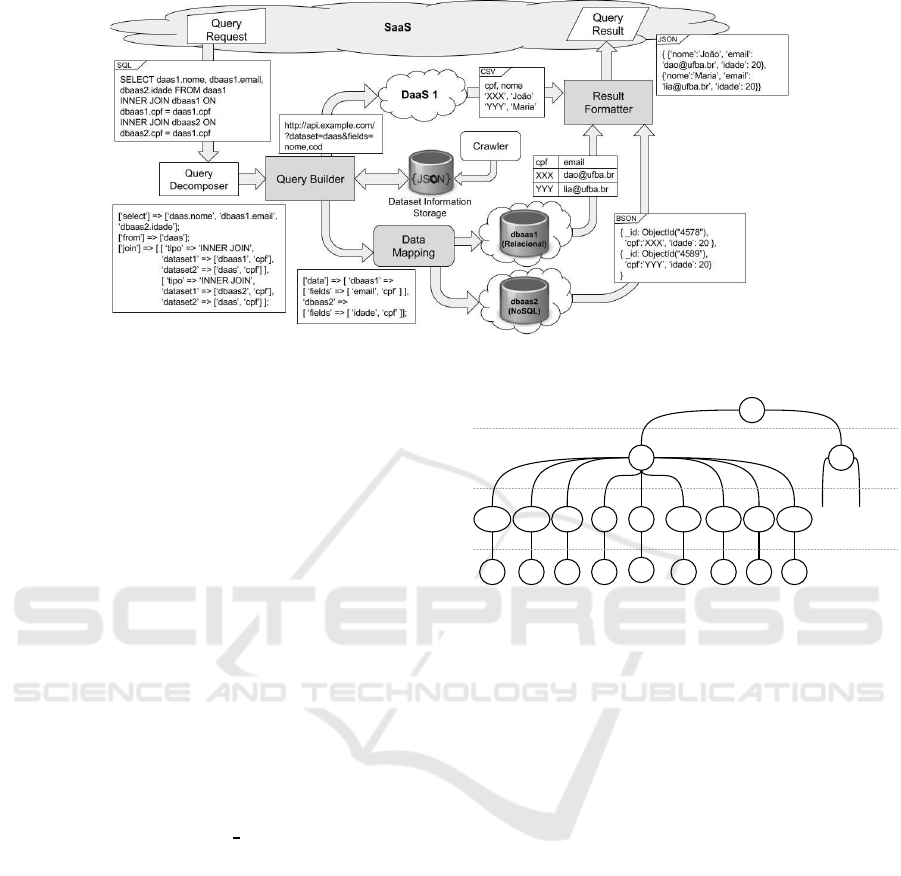
Figure 2: MIDAS execution sequence among one DaaS and two DBaaS through a join statement.
MIDASql = (mDIS,mSaaS,mDaaS), where: mDIS
is the ca nonical model of DaaS presented in DIS;
mSaaS is the canonical model that maps the query
(sent by SaaS); and mDaaS is the canonical model
that maps DaaS return(s).
In the following sections, each canonica l model is
detailed.
4.1 Canonical Model mDIS
Definition 2 (mDIS). The canonical mod el that sto-
res DIS information (mDIS) is a tuple mDIS =
(N
root
,DAAS), where: N
root
is the name of the mo del;
and DAAS is a set of DaaS models (daas set).
Definition 3 (daa s). The canonical mode l for a
specific DaaS (daas ∈ DAAS) is a tuple da as =
(N
root
daas
,K), where: N
root
daas
is the name of DaaS;
and K is a predefined set of keys (k) for each DaaS,
where K = {domain, search
path, query, sort, limit,
dataset, records, fields, format}.
Definition 4 (k). A key k ∈ K is an information about
daas a nd it is defined as k = (N
root
k
,i), where: N
root
k
is the name used to characterize a specific informa -
tion about daas, k.N
root
k
∈ K; and i is the information
about k, it can be empty, atomic, or multivalued.
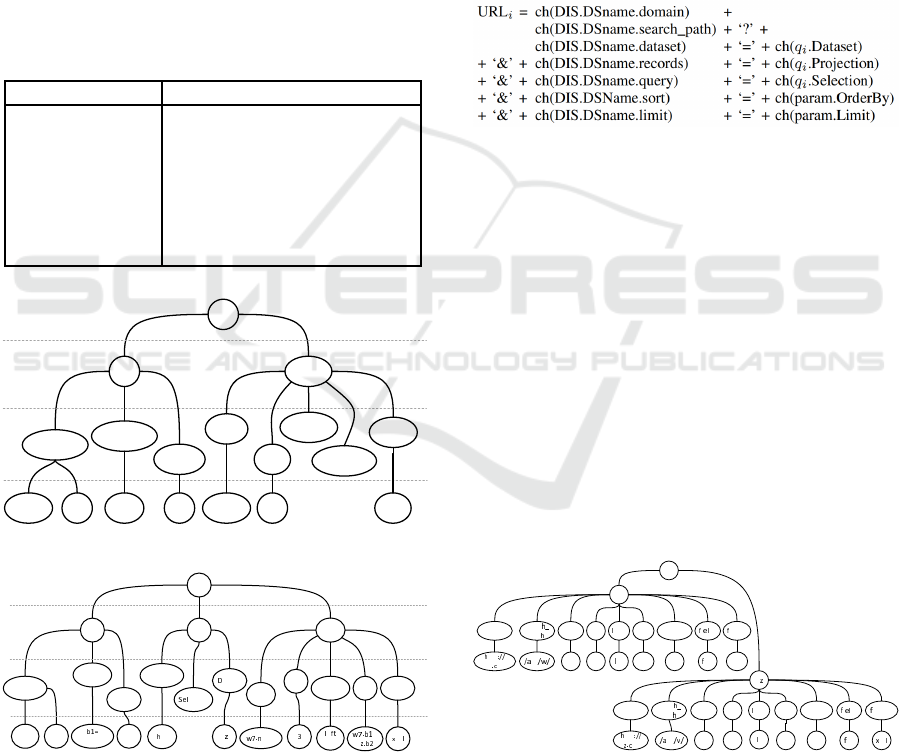
Considering a hypothetical DIS with two DaaS
(NYC and v8), part of the canonical model mDIS can
be seen in Fig. 3: The main node stores the beginning
of subtrees, where each subtree stores the information
about a particular DaaS. Eac h node of level i stores in-
formation on the k level, immediately above.
4.2 Canonical Model mSaaS
Definition 5 (mSaaS). The canonical model mSaaS
converts the query (submitted by Sa aS) in a set with n
DIS
nyc v8
dataset records fieldssortquery
search_
path
x6 x7 x8x4x3x2
...
mDIS
daas
k
i
domain format
x1 x9
limit
x5
Figure 3: Example of mDIS for two DaaS.
queries (to sent to DaaS), wh ere n indicates the num-
ber of relations in the query (e.g.: n = 2 indicates
join with 2 tables), n ≥ 1. The model mSaaS is a tuple
mSaaS = (N
root
,C
1
), where: N
root
is the value of n;
and C
1
is a set of first-level clauses (c
1
) used in the
mapping to identify qu eries and operations.
Definition 6 (c
1
). A first-level clause c
1
∈ C
1
sto-
res specific information about a query OR about an
operation, and it is a tuple c
1
= (N
root
c
1
,C
2
), where:
N
root
c
1
is the name that identifies the query OR the
operation; and C
2
is a set of second-level clauses (c
2
)
used in the mapping to identify the query attributes
and operations. Some important observations: (i)
N
root
c
1
∈ {q
1
,q
2
,...,q
n
, param} , where q
i
is an i-th
relation and param is a node for storing data about
join, order by and limit; an d (ii) given n, there are
n + 1 clauses c
1
.
Definition 7 (c
2
). A second-level clause c
2
∈ C
2
sto-
res information about clauses of a query OR clauses
of an operation, and it is a tuple c
2
= (N
root
c
2
,V ),
where: N
root
c
2
is the name that identifies th e clause
of a query OR the clause of an operation; e V is
a set of values (v) for each c
2
. Some important
observations: (i) if c
1
represents a query q
i
, then
N
root
c
2
indicates j a ttributes ( j ≥ 0) of q
i
stored,
where N
root
c
2
∈ {Pro jection,Selection,Dataset}; (ii)
Transparent Interoperability Middleware between Data and Service Cloud Layers
151
if c
1
represents param , then N
root
c
2
indicates j at-
tributes ( j ≥ 0) of n relations, where N
root
c
2
∈
{OrderBy, Limit,TypeJoin,CondJoin, Return}; and
(iii) given n, there are 3n + 5 clauses c
2
.
Definition 8 (v). A value v ∈ V is an element repre-
senting information about c
2
. Depending on the c
2
, V
may be empty, atomic, or multivalued. Thus, V = ∅
or V = {v
1
,v
2
,...,v
w
}, where: v
i
is the i-th value v
for c
2
; and w is the number of values v in the set V of
the key c
2
, i.e., v ∈ V .
For instance, the qu ery of Table 1 (presented in
SQL and NoSQL) generates the canonical model pre-
sented in Fig. 4; while the query in Ta ble 2 generates
the canonical model presented in Fig. 5.
Table 1: Example of a query in SQL and in NoSQL (Mon-
goDB) without join/aggregation.
SQL NoSQL (MongoDB)
SELECT name, w7.find(
(from)
age
{
‘age=10’
}
,
(where)
FROM w7
{
‘name’:1,
(select)
WHERE age=10 ‘age’:1
}
)
ORDER BY name .limit(10)
(limit)
LIMIT 10 .sort(
(order by)
{
‘name’:1
}
);
1
q1 param
Dataset
Selection
Projection
w7
age=
10
age
mSaaS
c
1
v
name
CondJoin
TypeJoin
Limit
Order
By
10name
c
2
Return
json
Figure 4: Example of mSaaS for query in Table 1.
2
q1
param
Dataset
Selection
Projection
age
mSaaS
c
1
v
Cond
Join
TypeJoin
Limit
Order
By
c
2
queens
w7
q2
ataset
ection
Projection
p one v
e
outer
=
v
ame
Return
m
name
Figure 5: Example of mSaaS for query in Table 2.
After mDIS and mSaaS are generated, it is neces-
sary to transform both canonical models into a set of
URLs to submit to DaaS. The data from DaaS is re-
ceived through a Uniform Resource Locator (URL),
MIDASql provides a mechanism to convert mDIS
and mSaaS into a set of URLs, the function genera-
teURLs(). Our fu nction has the following prototype:
“URLs generateURLs(mDIS, mSaaS)”. This means
that, given a mDIS and a mSaaS, generateURLs()
must returns a set of URLs, where: each URL is
a concaten ation sequence of mDIS and mSaaS ele-
ments; and the number of URLs is equal to the num-
ber of query relations (n, n ≥ 1 ), i.e., each q
i
(in
mSaaS) generate s URL
i
. For this, we assume that:
“+” is an ope rator that concatenates two strings (lite-
rals or variables); and ch(p) is a function that returns
the contents of the child(re n) of p node.
Thus, considering DSname = ch(q
i
.dataset), URL
i
is generated according to Fig. 6.
Figure 6: Concatenations that the generateURL() function
uses to generate URL
i
.
Considering the function generateURLs(), some
observations are important: (i) when ch(p) does
not return any element, the corresponding line p
in URL
i
must be disregarded; (ii) multivalued re-
sult of ch(p) is separated by commas; (iii) the last
two lines occ ur only for n = 1; an d (iv) for n ≥ 2,
ch(q
i
.Pro jection) must initially include the cor re-
sponding ch(param.CondJoin) if the junction attri-
bute is not part of the projection attribute set (i.e., if
ch(param.CondJoin) /∈ ch(q
i
.Pro jection)).
Given the mDIS of Fig. 7 and the
mSaaS shown in Fig. 4, the generateURLs()
generates the following URL: URL
1
=
<http://w7.com/api/w/?dsw=w7&rcw=name,age&
q=age=1 0& sort=name&rows=10>.
DIS
v
data
set
records i dssortquery
searc
pat
dsv rcv dvsvqvpi
domain ormat
ttp
v om
m
imit
v
w7
data
set
records i dssortquery
searc
pat
dsw rcw dwswqwpi
domain
ormat
ttp
w7 om
json
imit
w
Figure 7: Example of mSaaS for query in Table 2.
On the other hand, given the same mDIS
from the previous example (Fig. 7) and the
mSaaS shown in Fig. 5, the generateURLs()
generates the following URLs: URL
1
=
<http://w7.com/api/w/?dsw=x7&rcw=b1,name,age&
CLOSER 2018 - 8th International Conference on Cloud Computing and Services Science
152
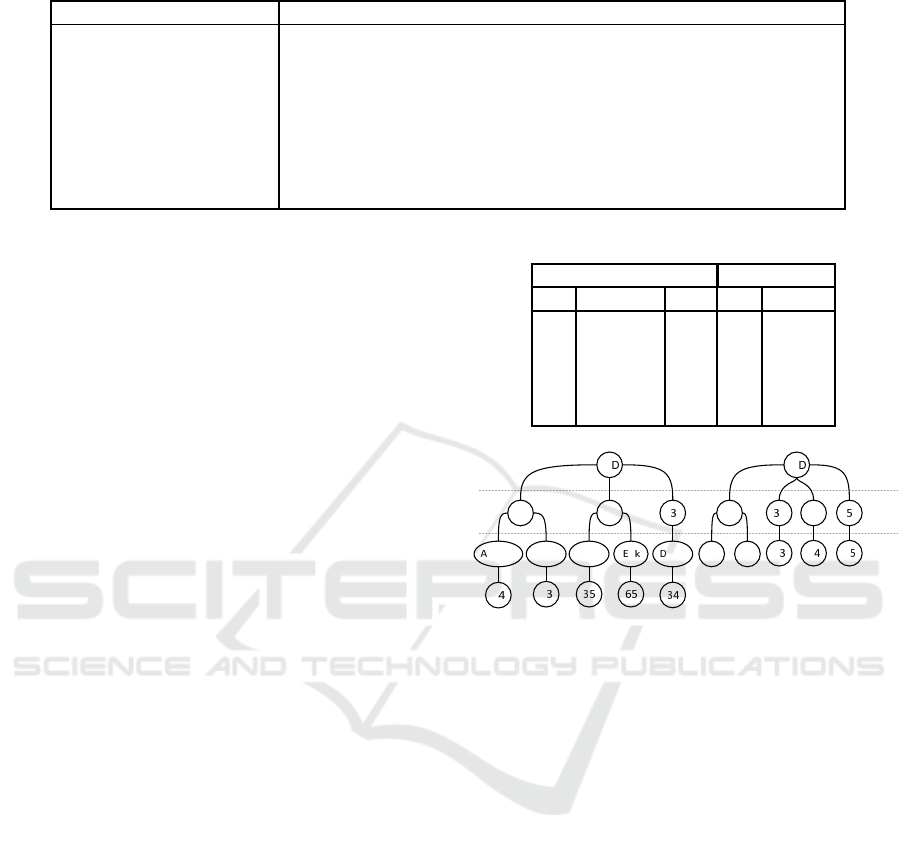
Table 2: Example of a query in SQL and in NoSQL (MongoDB) with join/aggregation.
SQL NoSQL (MongoDB)
SELECT w7.name, db.w7.aggregate.([
(from)
w7.age, vz.phone
{$
lookup:
{
from:‘vz’, localField:‘b1’,
(join)
FROM w7 foreignField:‘b2’
}}
,
LEFT OUTER JOIN vz
{$
match:
{
w7.b1=‘queens’
}}
,
(where)
ON w7.b1=vz.b2
{$
project:
{
w7.name:1, w7.age, vz.phone:1
}} (select)
WHERE w7.b1=‘queens’
{$
sort:
{
w7.name:1
}}
,
(order by)
ORDER BY w7.name
{$
limit:3
} (limit)
LIMIT 3 ]);
qw=b1=’queens’>; and URL
2
= <http://v z .com/api/
v/?dsv=vz&rcv=b2 ,phone>.
4.3 Canonical Model mDaaS
For each generated URL, the corresponding DaaS re-
turns the request dataset. Before sending the results to
SaaS, MI DAS pe rforms some operation s to make the
data “presentable”, such as join, order by, a nd lim it,
if applicable. This treatment is carried out employing
the canonical model mDaaS.
Definition 9 (mDaaS). The canonical m odel mD aaS
maps the output of n Da aS. DaaS sends a re-
turn (in the format described in the mDIS) for
each URL. If n = 1, th en mDaaS just converts
ch(DIS.ch(q
1
.dataset). f ormat) (format returned b y
DaaS) into ch(param.Return) (format desired by
SaaS), and the process is finalized. On the other hand,
when n ≥ 2 (i.e., if there is a join), then the relations
are mapped two- by-two, so that mDaaS generates n
canon ical mappings. In this case (n ≥ 2), mDaaS is a
tuple mDaaS = (N
root
,CJ), where: N
root
is the name
of the DaaS mo del (q
i
D, i is the i-th relation); and CJ
is a distinct set of ch(param.CondJoin) (c j) valu e s in
the corresponding relation.
Definition 10 (cj). An information c j ∈ CJ is a value
that the condition of join ch(param.CondJoin) assu-
mes in the corresponding relation, being c j a tuple
c j = (N
root
c j
,L), where: N
root
c j
is the name that iden-
tifies the value c j; and L is a set of lists (l) with all
attributes tha t contain c j.
Definition 11 (l). A list l ∈ L contains all elements
of the same tuple in which c j is part, in the same or-
der of occurrence of the relation (considering from
left to right). The amoun t of l ∈ L is equal to the
amount of o ccurrences of c j in the relation, thus
l = {a
1
,a
2
,...,a
m
}, where: a
i
is the i-th attribute a
for each l in c j; and m is the nu mber of attributes
a ∈ l.
Considering that the query in Table 2 (with join)
returns the two sets of data presente d in Table 3, the
canonical models (mDaa S) are shown in Fig. 8.
Table 3: DaaS returns for query presented in Table 2.
w7 vz
b1 name age b2 phone
1 Andrew 14 1 p1
2 Bruce 35 1 p2
1 Carl 13 30 p3
3 Dylan 34 2 p4
2 Erik 65 5 p5
mDaaS
cj
l
q
1
1
Carlndrew
1
1
2
riBruce ylan
q
2
1 2
p2p1
0
p p p
Figure 8: Example of mDaaS for query in Table 2.
Once the mDaaS has been generated, the join
can be done. The next step depends on the value
of ch(param.TypeJoin). For this, in addition to the
functions already mentioned, we assume that: lch(p)
is a function that returns the last child of a p node; and
con(p
1
, p
2
) is a function that connects the node p
1
to
the node p
2
.
If ch(param.TypeJoin) = ‘le f t outer’, the join is
performed as follows:
a) ∀c j
1
∈ ch(q
1
D) e ∀c j
2
∈ ch(q
2
D),
con(lch(q
1
D.c j
1
), ch(q
2
D.c j
2
)), ∀c j
1
= c j
2
;
b) case c j
1
/∈ ch(q
1
.Pro jection), then (i) con(q
1
D,
ch(q
1
D.c j
1
)) is performed and (ii) c j
1
is removed;
c) if there is ch(param.OrderBy), this node is sor-
ted;
d) if there is ch(param.Limit), this must be the total
of ch(q
1
D); and finally
e) q
1
D is converted to ch(p aram.Return) and it is
sent to SaaS.
Considering the mD aaS of Fig. 8, the execution
of the described steps should result in Fig. 9.
Transparent Interoperability Middleware between Data and Service Cloud Layers
153

mDaaS
cj
l
q
1
CarlAndrew
14 13
Bruce
35
p2
p1
p2p1
p4
Figure 9: Example of mDaaS for query presented in Table
2 after left outer join.
5 EVALUATION
To evaluate our middleware, we performed a set of
three experiments. The se experiments delimit the re-
lationship between SaaS and DaaS/DBaaS. A query
without join (or aggregation) statement connects one
SaaS to only one DaaS or one DBaaS provider (Ex-
periments 1 and 2). Queries with join (or with ag-
gregation) statements allow SaaS level to relate more
than one DaaS a nd/or more than one DBaaS provide rs
(Exper iment 3).
Firstly, we evaluate the overhead of our midd-
leware. We submitted 100 qu e ries directly to both
DaaS and DBaaS and, we compared the results with
MIDAS acc ess. Queries w e re performed to return
100, 1000, and 10000 rec ords. Secondly, we evalu-
ate wh e ther the query langua ge (SQL an d NoSQL)
influences the a ccess time to different data sources
(DaaS and DBaaS). Through MIDAS, we have sub-
mitted 10 0 queries: (i) With Mongo DB to Daa S; (ii)
SQL to DaaS; (iii) MongoDB to DBaaS; and (iv) SQL
to DBaaS. Thirdly, we evaluate the interoperability of
our proposal. In this experiment, we submit 100 que-
ries to mo re than one data source: (i) 2 DBaaS; (ii) 2
DaaS; and (iii) 1 DaaS and 1 DBaaS.
In experiment 1 we evaluated overhead; expe-
riment 3 we evaluated interoperability; and in all
experiments (1, 2 and 3 ) we evaluated function
and execution time. The average time (in ms) of
each task was registered by Apache JMeter tool
(http://jmeter.apache.org/).
5.1 Our Case Study
Our current MIDAS is based on ope n source
technologies that are found in any cloud with
PHP su pport. It was developed in Heroku c loud
(https://www.heroku.com/) because it is an open
cloud with sufficient storage space and a complete
Platform as a Service (PaaS) for our project. To si-
mulate a SaaS provide r, we develop a Demographic
Statistics by NY Hospital’s web application based on
PHP. This we b application is hosted in Heroku SaaS
instance, and it can be accessed at <https://midas-
saas.herokuapp.com>.
Regarding DaaS serv ice level, thr ee different
DaaS providers are used to perform our tests
and experiments (P
1
: <https://goo.gl/7sVsZB>;
P
2
: <https://goo.gl/E4YmYH>; and P
3
:
<https://goo.gl/vJomwT>):
• P
1
: Transportation Sites, with 13600 instances
and 18 attributes;
• P
2
: Hospital Gene ral Information, with 4812 in-
stances and 29 attributes; and
• P
3
: Demographic Statistics By Zip Code, with
236 instances and 46 attributes.
The same dataset provided by DaaS were
persisted into two DBaaS: P
1
in JawsDB
(https://www.jawsdb.com/) and P
2
in mLab
(https://www.mlab.com/). The D BaaS are based
on MySQL and MongoDB, respectively. The
choice for MySQL and MongoDB was motivated
by being the most widely used Relational and
NoSQL available an d free (according to ranking
https://db-engines.com/en/ranking). Our application
(simulating SaaS) perfor ms a jo in between P
2
and P
3
.
5.2 Experiments
To evaluate our middleware, we performed three ex-
periments: (E
1
) overhead; (E
2
) performance of diffe-
rent queries; and (E
3
) data join and interop erability.
In the first experiment, we submitted 100 queries
to both data sources (DaaS and DBaaS) with and wit-
hout MIDAS. We vary the number of reco rds returned
(100, 1000, and 10000). This a llows evaluating the
influence of MIDAS on the communication between
SaaS and DaaS/DBaaS. For this, in the first experi-
ment we submit:
• 1 00 queries d irectly to Daa S provider;
• 1 00 queries to DaaS provider throug h MIDAS;
• 1 00 queries d irectly to DBaaS provider; and
• 1 00 queries to DBaaS provider through MIDAS.
As stated , we evaluated whether the qu ery lan-
guage influences acce ss time depending on the data
source. Thus, in the second exp eriment we submit:
• 1 00 MongoDB queries to the DaaS provider
through MIDAS;
• 1 00 SQL querie s to the DaaS provider through
MIDAS;
CLOSER 2018 - 8th International Conference on Cloud Computing and Services Science
154
• 1 00 MongoDB queries to the DBaaS provider
through MIDAS; and
• 1 00 SQL queries to the DBaaS provider through
MIDAS.
Finally, our third experiment evaluates the intero-
perability of MIDAS. We estimate the average execu-
tion time required fo r MIDAS to relate data from dif-
ferent sources, through the join (or aggregation) sta-
tement. The association of the data was made through
a zip code field. having in dataset P
1
the attribute as
Zip and in the da taset P
2
the attribute as Zip Code. For
this, we submit:
• 1 00 queries with join statem ent to two DaaS pro-
viders through MIDAS;
• 1 00 queries with join statement to two DBaaS
providers through MIDAS; and
• 1 00 queries with join statement to one D a aS and
one DBaaS providers through MIDAS.
6 RESULTS
In this section, we present the results of our experi-
ments, and we discuss them.
6.1 Results from Experiment 1
The results obtained from experiment 1 were classi-
fied based on the value assigned to the query limit.
This value defines the number of records returned and
it was restricted up to 100, 1000 and 10000 data re-
cords.
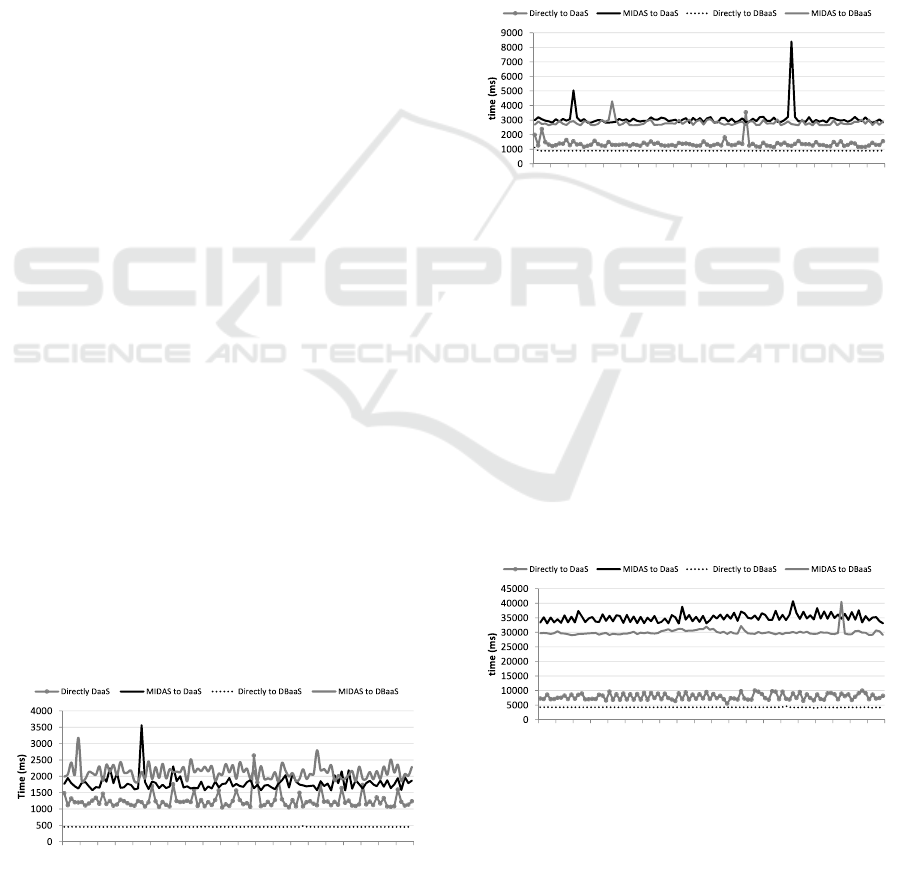
Firstly, we submitted 100 queries to return 100
data records. In this case, Fig. 10 shows the average
of the execution time:
• 1 267.77 ± 276.22 ms for qu e ries witho ut MIDAS
to Da aS;
• 2 052.37 ± 2658.98 ms for queries through MI-
DAS to DaaS;
• 4 89.76 ± 367.30 ms for queries without MIDAS
to DBaaS; a nd
1 10 20 30 40 50 60 70 80 90 100
Figure 10: Return time (y-axis) for each of the 100 queries
submitted (x-axis) with a limit of 100 records.
• 2 128.15 ± 219.87 ms for queries through MIDAS
to DBaaS.
Secondly, we submitted 100 queries to return 1000
data records. In this case, Fig. 11 shows the average
of execution time:
• 1 372.92 ± 275.70 ms for queries without MIDAS
to DaaS;
• 3 071.09 ± 585.30 ms for queries through MIDAS
to DaaS;
• 8 96.51 ± 22.83 ms for quer ie s without MIDAS to
DBaaS; and
• 2 813.19 ± 198.26 ms for queries through MIDAS
to DBaaS.
1 10 20 30 40 50 60 70 80 90 100
Figure 11: Return time (y-axis) for each of the 100 queries
submitted (x-axis) with a limit of 1000 records.
Finally, we submitted 100 queries to return 10000
data records. In this case, Fig. 12 shows the average
of execution time:
• 7 917.02 ± 1045.84 ms for queries without MI-
DAS to DaaS;
• 3 5039.22 ± 1 420.75 ms for queries through MI-
DAS to DaaS;
• 4 260.8 ± 61.25 ms for quer ie s without MIDAS to
DBaaS; and
• 3 0023.41 ± 1 213.57 ms for queries through MI-
DAS to DBaaS.
1 10 20 30 40 50 60 70 80 90 100
Figure 12: Return time (y-axis) for each of the 100 queries
submitted (x-axis) with a limit of 10000 records.
Regarding the overhead caused by MIDAS, we
can observe that the average differences of direct que-
ries to DaaS and DBaaS, respectively, whe n compa-
red to the access through MIDAS were: (i) 42.4%
Transparent Interoperability Middleware between Data and Service Cloud Layers
155
and 368.8%, for 100 data records; (ii) 123.7% and
213.8%, for 1000 data records; and (iii) 342.6% and
604.6%, for 10000 records. Time values are affected
by (i) data traffic on the Internet and (ii) MIDAS in-
frastructure. These results demonstrate that the algo-
rithms need optim iz a tions, not being the scope of this
work.
6.2 Results from Experiment 2
In this experimen t, we combine two query langua-
ges (SQL and NoSQL) with both sources (DaaS and
DBaaS).
As Fig. 1 3 sh ows, the following averages of exe-
cution time were obtained:
• 3 3569.03 ± 2663.39 ms for Mong oDB queries
through MIDAS to DaaS;
• 3 5039.22 ± 1 420.75 ms for SQL quer ies through
MIDAS to DaaS;
• 2 9415.03 ± 1065.52 ms for Mong oDB queries
through MIDAS to DBaaS; and
• 3 0023.41 ± 1 213.57 ms for SQL quer ies through
MIDAS to DBaaS.
1 10 20 30 40 50 60 70 80 90 100
Figure 13: Return time (y-axis) for each of the 100 queries
submitted (x-axis) from different languages to different data
sources.
We can observe that: (i) For access to DaaS,
SQL queries were 4.4% slower; while (ii) for DBaaS
access, SQL queries were 2% slower. The time dif-
ference between the two types o f queries is minimal,
not representing losses in the choice of which to use.
6.3 Results from Experiment 3
In this experiment, we performed a query with join
statements that access two different DaaS, two diffe-
rent DBaaS and one DaaS with one DBaaS.
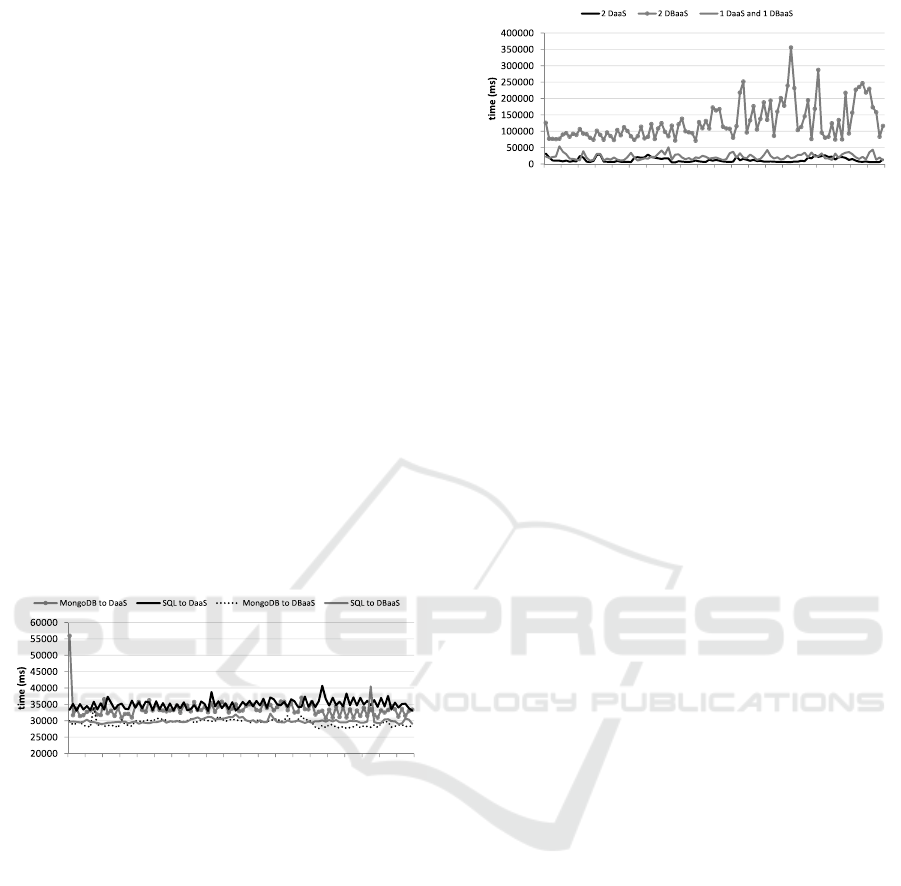
Figure 14 depicts the average of the execution
time.
• 1 2357.08 ± 6831.42 ms for two DaaS providers;
• 1 26957.46 ± 5 5870.66 ms for two DBaaS provi-
ders; and
1 10 20 30 40 50 60 70 80 90 100
Figure 14: Return time (y-axis) for each of the 100 queries
(x-axis) with join (or aggregation) statement.
• 2 2707.84 ± 9324.02 ms for one DaaS and one
DBaaS
In this experim ent, we can observe that (i) the
average query tim e to 2 DBaaS is 459% slower than 1
DaaS and 1 DBaaS queries, and 927 .4% slower than
2 DaaS queries. The average time for qu e ries to 1
DaaS an d 1 DBaaS is 83.8% slower than quer ies to 2
DaaS. When using DBaaS, the time values are hig her
than those presented by DaaS, due to the proce ss of
accessing and processing the data in the D BaaS.
6.4 Discussions
Our case study evaluates MIDAS through its overhead
and different languages and data sources.
Despite the fact that the execution time was pro-
portion al to the submitted query, in the first experi-
ment the results show that MIDAS inputs an extra
overhead regarding direct queries. This depreciation
was expected because of the new layer introduced be-
tween SaaS and DaaS. It is noteworthy that network
bandwidth, cloud providers, and latency might also
influence those results.
Considering DbaaS, we observed that the result
from a direc t access is more rapid than thro ugh MI-
DAS. In fact, MIDAS deals with DBaaS as a DaaS,
through the Data Mapping module.
The second exp e riment states that the language
used by a SaaS (i.e., SQL, NoSQL) does not influ-
ence the query performance or the return time with
both data (i.e., DaaS, Dbaa S).
Finally, the third experimen t states that DbaaS
needs to be deeply analyzed. Despite the fact that the
join clause has a comp lexity O(n
2
) (2: number of data
source), the join execution time decreases the perfor-
mance in almost 1 minute. On the other hand, results
on DaaS were less than 23 seconds. We can state that
the benefits of our approach to interoperate different
data sources by the use of join clauses outperforms
the time spent on gathering the results.
There is one threat of validity: all data sources
were public. Thus, offline data for a ny cau se can com-
promise our approach.
CLOSER 2018 - 8th International Conference on Cloud Computing and Services Science
156

7 CONCLUSIONS AND FUTURE
WORK
In this paper, we propose a new version of MIDAS,
describing a formal model to provide interoperability
among cloud layers. We performed some experiments
to validate our results and to show the effectivene ss of
our proposal.
Our middleware requires a minimu m adaptation
from SaaS applications despite the complexity of de-
aling with interoper ability problem between applica-
tion services and heterogeneous data in cloud envi-
ronments. As contributions, unlike the previous ver-
sion (1.6) o ur solution (i) even promotes the joining
of data from different DaaS and DBaaS, enabling gat-
hering data from various data sources; (ii) automati-
cally populates and maintains updated the DIS; and
(iii) considers other SaaS return formats in addition
to JSON.
As a future work, we intend to continue improving
MIDAS by adding new characteristics, such as (i) re-
cognizatio n of SPA RQL queries and other types of
NoSQL; (ii) au tomate the Crawler for searching no-
vel DaaS and disambiguate data from heterog eneous
data sources, and (iii) improve algorithms for be tter
results.
ACKNOWLEDGEMENTS
The author s would like to thank FAPESB (Founda-
tion for Research Su pport of the State of Bahia) for
financial support.
REFERENCES
Ali, H., Moawad, R., and Hosni, A. A. F. (2016). A Cloud
Interoperability Broker (CIB) for data migration in
SaaS. In 2016 IEEE International Conference on
Cloud Computing and Big Data Analysis (ICCCBDA),
pages 250–256.
Armbrust, M., Fox, A., Gr iffith, R., Joseph, A. D., Katz,
R., Konwinski, A., Lee, G., Patterson, D., Rabkin, A.,
Stoica, I., and Zaharia, M. (2010). A view of cloud
computing. Commun. ACM, 53(4):50–58.
Barouti, S., Alhadidi, D., and Debbabi, M. (2013).
Symmetrically-private database search in cloud com-
puting. In Cloud Computing Technology and Science
(CloudCom), 2013 IEEE 5th International Confe-
rence on, volume 1, pages 671–678. IEEE.
Gantz, J. and Reinsel, D. (2012). The digital universe in
2020: Big data, bigger digital shadows, and biggest
growth in the far east. IDC iView: IDC Analyze the
future, 2007(2012):1–16.
Hacigumus, H., Iyer, B., and Mehrotra, S. (2002). Provi-
ding database as a service. In Data Engineering, 2002.
Proceedings. 18th International Conference on, pages
29–38. IEEE.
Igamberdiev, M., Grossmann, G., Selway, M., and Stumpt-
ner, M. (2016). An integrated multi-level mo-
deling approach for industrial-scale data interoperabi-
lity. Software & Systems Modeling, pages 1–26.
Loutas, N., Kamateri, E., Bosi, F., and Tarabanis, K. (2011).
Cloud computing interoperability: The state of play.
In Cloud Computing Technology and Science (Cloud-
Com), 2011 IEEE Third International Conference on,
pages 752–757. IEEE.
Mell, P., Grance, T., et al. (2011). The NIST definition of
cloud computing.
Park, H.-K. and Moon, S.-J. (2015). DBaaS using HL7 ba-
sed on XMDR-DAI for medical information sharing
in cloud. International Journal of Multimedia and
Ubiquitous Engineering, 10(9):111–120.
Schreiner, G. A., Duarte, D., and Mello, R . d. S. (2015).
SQLtoKeyNoSQL: a layer for relational to key-based
nosql database mapping. In Proceedings of the 17th
International Conference on Information Integration
and Web-based A pplications & Services, page 74.
ACM.
Sellami, R., Bhiri, S., and Defude, B. (2014). ODBAPI:
a unified REST API for relational and NoSQL data
stores. In Big Data (BigData Congress), 2014 IEEE
International Congress on, pages 653–660. IEEE.
Silva, G. C., Rose, L. M., and Calinescu, R . (2013). A
systematic review of cloud lock-in solutions. In
Cloud Computing Technology and Science (Cloud-
Com), 2013 IEEE 5th International Conference on,
volume 2, pages 363–368. IEEE.
Vieira, M. A., Ribeiro, E. L. F., Rocha, W. S., Mane, B.,
Claro, D. B., Oliveira, J. S., and Lima, E. (2017). En-
hancing midas towards a transparent interoperability
between saas and daas. In Proceedings of the XIII
Brazilian Symposium on Information Systems, pages
356–363.
Xu, J., Shi, M., Chen, C., Zhang, Z., Fu, J., and Liu,
C. H. (2016). ZQL: A unified middleware brid-
ging both relational and nosql databases. In De-
pendable, Autonomic and Secure Computing, 14th
Intl Conf on Pervasive Intelligence and Computing,
2nd Intl Conf on Big Data Intelligence and C om-
puting and Cyber Science and Technology Congress
(DASC/PiCom/DataCom/CyberSciTech), 2016 IEEE
14th Intl C, pages 730–737. IEEE.
Transparent Interoperability Middleware between Data and Service Cloud Layers
157
