
Discovering Good Links Between Objects in the Internet of Things
Francesco Buccafurri
1
, Gianluca Lax
1
, Serena Nicolazzo
1
, Antonino Nocera
1
, Luca Console
2
and Assunta Matassa
2
1
DIIES, University Mediterranea of Reggio Calabria, Via Graziella, Localit
`
a Feo di Vito, 89122 Reggio Calabria, Italy
2
Dipartimento di Informatica, University of Torino Corso Svizzera, 185 10149 Torino, Italy
Keywords:
Internet of Things, Network Efficiency, Assortativity, Twitter.
Abstract:
The Internet of Things is an emerging paradigm allowing the control of the physical world via the Internet
protocol and both human-to-machine and machine-to-machine communication. In this scenario, one of the
most challenging issues is how to choose links among objects in order to guarantee an effective access to
services and data. In this paper, we present a new selection criterion that improves the classical approach. To
reach this goal, we extract knowledge coming from the social network of humans, as owners of objects, and we
exploit a recently proven property called interest assortativity. The preliminary experimental results reported
in this paper give a first evidence of the effectiveness of our approach, which performs better than classical
strategies. This is achieved by choosing only not redundant links in such a way that network connectivity is
preserved and power consumption is reduced.
1 INTRODUCTION
The Internet of Things refers to a new paradigm com-
posed of networked interconnection of everyday ob-
jects, which are often smart, e.g., equipped with ubiq-
uitous intelligence. This innovative scenario will
increase the ubiquity of the Internet by integrating
every object for interaction via embedded systems.
Moreover, it will lead to a highly distributed network
of devices where machine-to-machine and human-to-
machine communication will be possible.
One of the basic problems to face is how to build
the Internet of Things. Indeed, the choice of a strat-
egy to drive the formation of communities of objects
has a direct impact on different aspects relevant from
the application point of view. A first desiderata is
that the network of objects has a sufficient connec-
tivity degree, to guarantee that the potential benefits
arising from the communication among objects are
not inhibited. According to this principle, one could
think of a highly connected network, ideally a com-
plete graph. However, the trade-off to solve regards
the limited computational and power capabilities of
smart objects, for which the number of connections
should be minimized.
The typically adopted approach to establishing
a direct connection between two objects is mainly
based on proximity (Union, 2005; Zhang et al., 2011;
Evangelos A et al., 2011). Instead, we define a new
strategy leveraging the properties of the objects, and
estimating how much similar properties should en-
force a direct link between two objects. This is done
by matching object properties to human interests, and
by measuring the assortativity degree of such inter-
ests in the human social network of owners supposed
to be Twitter (Buccafurri et al., 2015a). The claim
is that the higher such an interest assortativity (Buc-
cafurri et al., 2015b), the higher the potential bene-
fit of directly connecting the corresponding objects.
This process allows us to discover good links between
objects, which guarantee good network connectivity
among similar objects by limiting the node degree and
then the related inefficiencies. We tested the above
strategy experimentally and obtained very promising
results. According to a number of social-network-
analysis measures (Buccafurri et al., 2015c), we con-
clude that the network of objects created by means of
our approach is much better than the network obtained
by using the classical one.
1.1 Motivating Example
To better explain our goal, we present the following
real-life situation.
Francis
is a runner. He likes measure his per-
formance and is especially interested in knowing his
speed during his activity. He is used to measure his
advancement by a smart bracelet in companion to his
102
Buccafurri, F., Lax, G., Nicolazzo, S., Nocera, A., Console, L. and Matassa, A.
Discovering Good Links Between Objects in the Internet of Things.
DOI: 10.5220/0006475601020107
In Proceedings of the 14th International Joint Conference on e-Business and Telecommunications (ICETE 2017) - Volume 6: WINSYS, pages 102-107
ISBN: 978-989-758-261-5
Copyright © 2017 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

smartphone. Both ensure him a full tracking of his
personal activity data. He has a Twitter account and
he is follower of many sportive man, personal coach,
instructor because he wants to stay well informed
about all news in the field.
Lucy
is always watching her weight. She likes to
be in fit and to eat biologic food, she likes read about
nutrient information on food, herbs’ properties, cos-
metics’ use and so on. To accomplish her goal, she is
used to adopt a series of mobile apps to track about
food, sports and to stay informed about these top-
ics. On Twitter, for instance, she follows famous ac-
tresses, personal trainers and nutritionists to get well
informed about these topics.
Steven
is a student. He spends a lot of time stay-
ing sit and working on the laptop. He is worried about
assuming a right posture then he had bought a pin able
to give a vibration whenever his posture is wrong or
he is staying to long. He has a Twitter account and he
is follower of healthy products in general: from pos-
ture, to food, to sports and so on. He does not like to
practice sports.
By following the interest assortativity approach,
we found out ’health’ like a common macro-interest,
pushing on this topic of interest, we are able to sug-
gest friendship between these components supporting
their owners in achieving their goals, however they
look like truly different. In fact,
Francis
and
Lucy
have never considered the importance of a right pos-
ture for the wellbeing; conversely,
Steven
does not
take care enough about sports and food, while he is a
very sedentary person. What the new approach allows
is the establishment of friendship between this series
of devices to allow the full accomplishment of per-
sonal goals of everybody, suggesting them new ones
and novel ways to accomplish the same results.
This is discussed in the next section, in which we
show that, in the cases like those described above,
the knowledge typically used to establish a connec-
tion between objects would produce unsatisfactory re-
sults. For example, by considering proximity (i.e., the
fact that the objects meet each other a given number
of times with a sufficient frequency), we should con-
clude that there is no reason to connect the above ob-
jects. Indeed, probably, the above objects never meet.
1.2 Structure of the Paper
The plan of this paper is as follows. In Section 2,
we present our approach to chose links in a IoT envi-
ronment. Section 3 describes the preliminary experi-
mentation carried out to study the effectiveness of our
technique. Section 4 deals with literature related to
our work. Finally, in Section 5, we draw our conclu-
sions.
2 DISCOVERING GOOD LINKS
According to the Internet-of-Thing paradigm, an en-
tity on a network has to be notified of the availabil-
ity of desirable services or devices on the network in
order to form a link. Typically, the fact that two ob-
jects get in touch somewhere and sometimes (maybe
because the corresponding owners meet in a certain
location) is enough to trigger (with a given thresh-
old) the establishment of a link between the two ob-
jects (Union, 2005; Zhang et al., 2011; Evangelos A
et al., 2011). This property is called proximity. The
aim of this section is to identify possible enhanced
ways to discover potentially beneficial links. To do
this, preliminarily, we consider which are the candi-
date properties (existing in the literature) we can use
to build a more complex model. They are: (i) prox-
imity, (ii) homogeneity, i.e., they are the same kind of
object created by the same manufacturer; (iii) owner-
ship, i.e., they belong to the same user; (iv) friendship,
i.e., owners are mutual friends in a social network.
Arguing that the decision regarding the insertion
of a link between two objects could rely on a mix of
the above properties, we define a decision function to
decide whether a link between two objects ⟨x,y⟩ has
to be inserted or not.
Observe that all the above properties give us some
information about the direct relationship between two
objects. Our proposal aims to use also some indirect
knowledge coming from the social network of own-
ers to support the computation of the above decision
function (Buccafurri et al., 2016b). In addition, de-
spite the classical selection criteria that are based on
the sole proximity, we use all the above direct prop-
erties. Therefore, we introduce two measures, which
we combine to compute the aimed decision function.
These are:
1. T
dir
x,y
, which derives from the direct knowledge
about objects and owners, and
2. T
ind
x,y
, which encodes some indirect knowledge.
As indirect knowledge we exploit a recently
proven property occurring in online social networks,
called interest assortativity (Buccafurri et al., 2016a).
According to this result, it is possible to have a mea-
sure of the correlation between a given human interest
and the presence of links between humans.
To exploit the above indirect property, we need to
match objects to humans, in such a way that interests
are someway preserved. To do this, we define a taxon-
omy on top of the properties and/or aims of objects.
Discovering Good Links Between Objects in the Internet of Things
103

This taxonomy allows us to associate each object x
with a set of (human) interests I
x
(belonging to a given
domain I) derived from the owners’ social network.
Clearly, the following reasoning is valid only if all the
involved humans have a social network account. To
build this taxonomy, we consider how many times a
user with a certain interest, say i, owns a given object
x. This way, we can define an occurrence degree O
x
i
of i w.r.t. x as the ratio between the number of users
with interest i owing x and the total number of occur-
rences of the interest i in the network.
Therefore, given two objects ⟨x,y⟩, we compute
the overlapping set of associated interests as I
x,y
=
I
x
∩I
y
, and, for each common interest i ∈I
x,y
, we com-
pute the assortativity level IA
i
of i in the considered
social network, and the common occurrence degree
O
x,y
i
defined as the mean between O
x
i
and O
y
i
.
At this point, we are ready to define how T
ind
x,y
is
computed. In particular:
T
ind
x,y
=
∑
i∈I
x,y
O
x,y
i
·IA
i
|
I
x,y
|
.
In words, T
ind
x,y
is obtained as a mean between as-
sortativity degrees of common interests weighted by
the common occurrence degrees. Since objects ⟨x,y⟩
are both related to I
x,y
, we expect that the higher the
value T
ind
x,y
, the higher the linking power of interests in
I
x,y
should be also for objects.
Finally, we combine the two values T
dir
x,y
and T
ind
x,y
to obtain our boolean function to decide whether to
add a link between the two objects. Specifically, given
two objects ⟨x,y⟩, a new link is established if:
F(T
dir
x,y
,T
ind
x,y
) ≥th
where th is a suitable threshold value, and F is a pa-
rameter of our model to set by experiments.
3 EXPERIMENTS
In this Section, we describe our experimental cam-
paign carried out in order to validate our approach. In
particular, we started from a set of humans and ob-
jects, and we built two networks:
1. a network of objects obtained by adding links ac-
cording to our approach based on interest assorta-
tivity;
2. a network of objects formed through the classical
proximity-based criterion.
The obtained results showed that the quality of the
first network is better in terms of efficiency than the
second one. In the following, we will explain which
is the measures adopted to evaluate the network effi-
ciency.
3.1 Testbed and Dataset
Our experiments were carried out on a machine
equipped with a 2 Quad-Core E5440 processor and 16
GB of RAM. The operating system was Linux Ubuntu
Server 14.04.4 LTS, with kernel version 4.2.0-35,
Java Virtual Machine version 1.8.0 45 (64-Bit). We
wrote our code in Java by also exploiting some fea-
tures of Neo4J (neo, 2016), a graph database manage-
ment system.
For our experiments, we used a Neo4j graph data
set, called GraphofThings, consisting of nodes cat-
egorized by one or more labels and connected by
instances of directed relationships. We obtained it
from a github repository maintained by the GraphAl-
chemist group (Gra, 2016).
Figure 1 shows an instance of the graph model
representing interactions (i.e., arcs) between entities
(i.e., nodes) used in our experiments.
For our experimental campaign, we needed only
some of the entities showed in the above schema. In
particular, the nodes we took into consideration are:
• Human. A user equipped with a device.
• User. A node representing a social network profile
(i.e., Facebook , Linkedin, Twitter, etc.). Observe
that, not all the users are humans.
• Machine. A node that indicates any wearable or
mobile device. It posses a tag type that indicates
the family which it belongs to.
• Interest. A node that holds a single interest cate-
gory.
• Location. A node that indicates a physical place.
It can be equipped with a number of attributes (in-
dicating for example an event, an activity, a store,
a park, etc.).
The main relationships involved in our dataset are:
• Uses. A directed relationship between a human
and any number of devices he wears.
• Located. An action taken by a device implying
that a user were in a specific location.
• Friend. An implicitly bi-directional relationship
implying a connection in a given social network.
• Has. A relationship implying that a user has a
specific interest.
WINSYS 2017 - 14th International Conference on Wireless Networks and Mobile Systems
104
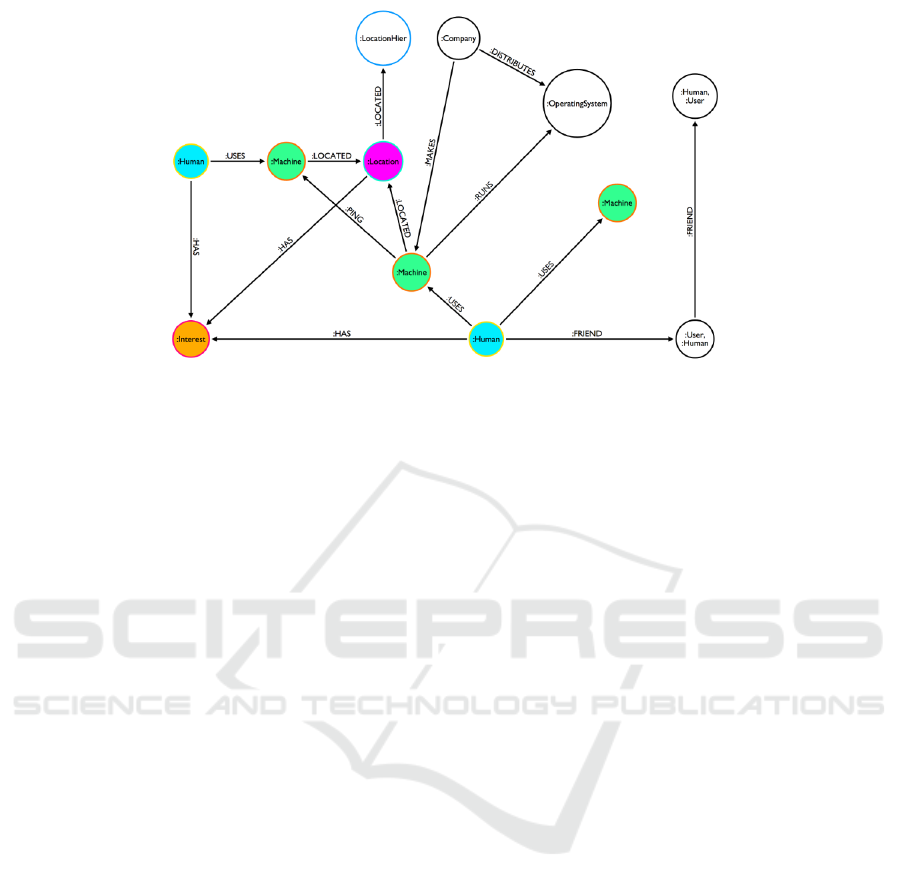
Figure 1: Graph representation of the GraphofThings nodes and relationships.
3.2 Results and Analysis
As first step, we generated the network of humans and
objects according to the classical proximity criterion.
Specifically, we added a link between two machines
if they had got in touch at least once in a certain loca-
tion.
Secondly, we generated the network of objects by
following our criterion. This task required some more
complex steps. Indeed, for two objects ⟨x,y⟩, we
added a link between them only if T
dir
x,y
·T
ind
x,y
≥ th,
where T
dir
x,y
is a boolean function returning 1 if x and
y had got in touch in a given location at least once
or their owners have a friendship relation in the corre-
sponding social network, 0 otherwise. In other words,
for this first investigation, we consider only proxim-
ity and friendship as direct properties and we set the
function F by the simple product between T
dir
x,y
and
T
ind
x,y
.
Once both the networks were created, we mea-
sured some quality parameters to compare them. Ta-
ble 1 shows the results of our analysis carried out by
exploiting UCINET (uci, 2016), a well-known soft-
ware package for the analysis of social network data.
From the results reported above, we can observe
that the network built by using the assortativity-based
approach shows a lower average degree and thus a
lower density level. Although, in general, high val-
ues of density imply a higher probability of reaching
target nodes, this has also a negative impact on the
network efficiency. Indeed, the higher the value of
density, the higher the traffic level (and duplication)
in broadcast communications.
We can make a similar reasoning for all parame-
ters that have a direct relationship with the number of
point-to-point communications that nodes have to
maintain, such as average degree. Observe that
network efficiency is a very important aspect in an
Internet-of-Things scenario, in which smart objects
have to preserve the battery consumption. Obviously,
in this context, what we have to minimize the number
of contacts per object, provided that the efficiency of
the network (also in terms of cohesion) is preserved.
By considering degree centralization, our network
achieves slightly better results, allowing us to con-
clude that it is more incline to have information ac-
cumulation points that can be used as seeds to start
the information propagation (Mislove et al., 2007).
Moreover, better results are achieved for component
ratio and connectedness. These parameters measure
the cohesion of the network and show us that our
network has a single connected component (so all
the nodes are reachable) and that the connectivity is
higher than the classical network. The latter prop-
erty means that the expected number of hops to reach
a given target is reduced in our network w.r.t. the
classical one. Hence, also for the compactness and
fragmentation point of view, we can conclude that the
strategy based on assortativity chooses only not re-
dundant links that allow a full connectivity. We ob-
serve that this has not a cost in terms of network re-
silience. Indeed, according to the definition of frag-
mentation, as it is 0.676 vs 0.776 of the classical net-
work, we obtain a network that is more resilient.
In summary, the obtained results allow us to state
that the approach based on interest assortativity has
been able to build a network showing better efficiency
in terms of both node reachability and cohesion level.
An important achievement is that nodes exhibit a re-
duced average degree w.r.t. the classical network.
This aspect has a deep impact on the traffic level (and
duplication) in broadcast communications which is
Discovering Good Links Between Objects in the Internet of Things
105

Table 1: Statistics of our dataset.
Proximity-based Our Approach
Avg Degree 12.017 10.075
Density 0.101 0.085
Deg Centralization 0.265 0.273
Component Ratio 0.529 1
Connectedness 0.224 0.324
Compactness 0.162 0.190
Fragmentation 0.776 0.676
clearly reduced in our network.
4 RELATED WORK
In recent years, IoT has gained much attention from
researchers and practitioners, because this new sce-
nario is opening new opportunities for a large number
of novel applications (Xia et al., 2012; Leavell and
Cooper, 2016; Kopetz, 2011; Atzori et al., 2010). One
of the most challenging issue is how to build the net-
work of objects to access services and data in this new
scenario (Zhang et al., 2011). Some proposals are
presented in (Edwards, 2006; Kortuem et al., 2010;
Wang et al., 2010; Yap et al., 2008; Jara et al., 2014).
In particular, in (Kortuem et al., 2010), smart items
perceive and instruct their environment by capturing
and interpreting user actions, to analyze their obser-
vations and to communicate with other objects and
the Internet. (Wang et al., 2010) presents a search
engine useful to find suitable smart devices. The re-
trieval is performed thanks to the description con-
tained within the objects themselves, or other user
defined information. A user can query the engine
to find a particular mobile object, or a list of objects
that fit the description. Also the system presented in
(Yap et al., 2008) allows humans to search for and
locate smart things as needed, although it is based
on a hierarchical architecture consisting of tags, sub-
stations and basestations. The architecture presented
in (Jara et al., 2014) exploits social tools to perform
node discovery. It allows users to register their own
sensors into a common infrastructure and then dis-
cover the available resources through mobile. Our
proposal strongly leverages on interest assortativity
(Buccafurri et al., 2016a). The concept of assortativ-
ity was firstly proposed by (Newman, 2002) in terms
of degree-degree assortativity. Therein the authors
demonstrated that social networks are often assorta-
tively mixed, in the sense that the nodes in the net-
work having many relationships tend to be connected
to other nodes highly connected themselves. Starting
from (Newman, 2002), further studies concerning so-
cial network assortativity have been proposed, such
as (Goh et al., 2003; Newman and Park, 2003; Catan-
zaro et al., 2004; Wilson et al., 2009). In particular,
(Goh et al., 2003) studies the relationship between as-
sortativity and betweenness centrality correlation for
scale-free networks. (Newman and Park, 2003) ana-
lyzes the relation between assortativity and clustering
in social communities discovering that these commu-
nities are characterized by both high levels of cluster-
ing and assortative mixing. By contrast, (Catanzaro
et al., 2004) compares different type of networks (e.g.,
technological, biological and social networks), show-
ing that only social networks are typically assortative
with respect to the degree whereas the others appear,
in general, to be disassortative. (Wilson et al., 2009)
models interaction relationships among users through
an interaction graph.
5 CONCLUSION
Internet of Things paradigm is an extremely promis-
ing scenario that opens new challenging perspec-
tives in terms of interaction between humans and ma-
chines. In this context, a lot of improvements can be
done. For instance, one of the most critical issues
is how to choose the links among objects in order to
build an efficient network.
In this paper, we present a new selection criterion
that improves the classical proximity approaches. To
do this, we relied on the results presented by (Buc-
cafurri et al., 2016a). This work shows that Twitter is
highly assortative in users’ interests (i.e., users behave
uniformly w.r.t. different topics) and it presents a new
social network metric, called interest assortativity.
This position paper shows a first experimental ev-
idence of this result by illustrating that our approach
performs better than the classical strategies. Indeed,
our selection criterion allowed us to pick only not re-
dundant links. This result is advantageous in terms of
network connectivity and battery consumption, which
are two crucial aspects for smart devices. This en-
courages us to more deeply analyze this issue in the
next future also by testing some different ways to
combine direct and indirect knowledge.
REFERENCES
(2016). GraphofThings. http://github.com/GraphAlchemist/
GraphofThings.
(2016). Neo4J: World’s leading graph database.
http://neo4j.com/.
(2016). UCINET Software. http://sites.google.com/site/
ucinetsoftware.
WINSYS 2017 - 14th International Conference on Wireless Networks and Mobile Systems
106

Atzori, L., Iera, A., and Morabito, G. (2010). The internet of
things: A survey. Computer networks, 54(15):2787–
2805.
Buccafurri, F., Lax, G., Nicolazzo, S., and Nocera, A.
(2015a). Comparing twitter and facebook user behav-
ior: privacy and other aspects. Computers in Human
Behavior, 52:87–95.
Buccafurri, F., Lax, G., Nicolazzo, S., and Nocera, A.
(2016a). Interest assortativity in twitter. In Proceed-
ings of the 13th International Conference on Web In-
formation Systems and Technologies (WEBIST). WE-
BIST.
Buccafurri, F., Lax, G., Nicolazzo, S., and Nocera, A.
(2016b). A model to support design and development
of multiple-social-network applications. Information
Sciences, 331:99–119.
Buccafurri, F., Lax, G., and Nocera, A. (2015b). A New
Form of Assortativity in Online Social Networks.
International Journal of Human-Computer Studies,
80:56–65.
Buccafurri, F., Lax, G., Nocera, A., and Ursino, D. (2015c).
Discovering Missing Me Edges across Social Net-
works. Information Sciences, 319:18–37.
Catanzaro, M., Caldarelli, G., and Pietronero, L. (2004).
Social network growth with assortative mixing. Phys-
ica A: Statistical Mechanics and its Applications,
338(1):119–124.
Edwards, W. K. (2006). Discovery systems in ubiquitous
computing. IEEE Pervasive Computing, 5(2):70–77.
Evangelos A, K., Nikolaos D, T., and Anthony C, B. (2011).
Integrating rfids and smart objects into a unifiedin-
ternet of things architecture. Advances in Internet of
Things, 2011.
Goh, K., Oh, E., Kahng, B., and Kim, D. (2003). Between-
ness centrality correlation in social networks. Physical
Review E, 67(1):017101.
Jara, A. J., Lopez, P., Fernandez, D., Castillo, J. F., Zamora,
M. A., and Skarmeta, A. F. (2014). Mobile digcovery:
discovering and interacting with the world through the
internet of things. Personal and ubiquitous computing,
18(2):323–338.
Kopetz, H. (2011). Internet of things. In Real-time systems,
pages 307–323. Springer.
Kortuem, G., Kawsar, F., Sundramoorthy, V., and Fitton, D.
(2010). Smart objects as building blocks for the inter-
net of things. IEEE Internet Computing, 14(1):44–51.
Leavell, P. and Cooper, D. (2016). The internet of things:
Strategic considerations for bankers. Journal of Digi-
tal Banking, 1(1):22–32.
Mislove, A., Marcon, M., Gummadi, K. P., Druschel, P.,
and Bhattacharjee, B. (2007). Measurement and anal-
ysis of online social networks. In Proceedings of the
7th ACM SIGCOMM conference on Internet measure-
ment, pages 29–42. ACM.
Newman, M. and Park, J. (2003). Why social networks are
different from other types of networks. Physical Re-
view E , 68(3):036122.
Newman, M. E. (2002). Assortative mixing in networks.
Physical review letters, 89(20):208701.
Union, I. T. (2005). The Internet of Things. 7th Edition,
International Telecommunication Union Internet Re-
ports.
Wang, H., Tan, C. C., and Li, Q. (2010). Snoogle:
A search engine for pervasive environments. IEEE
Transactions on Parallel and Distributed Systems,
21(8):1188–1202.
Wilson, C., Boe, B., Sala, A., Puttaswamy, K., and Zhao, B.
(2009). User interactions in social networks and their
implications. In Proc. of the ACM European Confer-
ence on Computer systems (EuroSys’09), pages 205–
218, Nuremberg, Germany. ACM.
Xia, F., Yang, L. T., Wang, L., and Vinel, A. (2012). Internet
of things. International Journal of Communication
Systems, 25(9):1101.
Yap, K.-K., Srinivasan, V., and Motani, M. (2008).
Max: Wide area human-centric search of the phys-
ical world. ACM Transactions on Sensor Networks
(TOSN), 4(4):26.
Zhang, D., Yang, L. T., and Huang, H. (2011). Searching
in internet of things: Vision and challenges. In 2011
IEEE Ninth International Symposium on Parallel and
Distributed Processing with Applications, pages 201–
206. IEEE.
Discovering Good Links Between Objects in the Internet of Things
107
