
Semantic Annotation of Images Extracted from the Web
using RDF Patterns and a Domain Ontology
Rim Teyeb Jaouachi
1
, Mouna Torjmen Khemakhem
1
, Nathalie Hernandez
2
, Ollivier Haemmerl
´
e
2
and Maher Ben Jemaa
1
1
ReDCAD Laboratory, National School of Engineers of Sfax, University of Sfax, Sfax, Tunisia
2
IRIT, Universit
´
e Toulouse - Jean Jaur
`
es, Toulouse, France
Keywords:
Semantic Annotation, RDF Patterns, Domain Ontology, Information Retrieval.
Abstract:
Semantic annotation of web resources presents a point of interest for several research communities. The use
of this technique improves the retrieval process because it allows one to pass from the traditional web to the
semantic web. In this paper, we propose a new method for semantically annotating web images. The main
originality of our approach lies in the use of RDF (Resource Description Framework) patterns in order to guide
the annotation process with contextual factors of web images. Each pattern presents a group of information to
instantiate from contextual factors related to the image to annotate. We compared the generated annotations
with annotations made manually. The results we obtain are encouraging.
1 INTRODUCTION
The concept of the semantic web is the brainchild
of Tim Berners-Lee (Cunningham et al., 2002), the
original creator of the World Wide Web. The main
idea behind this kind of web is to weave a web that
not only links documents to each other but also that
recognises the meaning of the information in those
documents. The aim of Tim Berners-Lee was to trans-
form the current web from a set of interconnected
data by simples links semantically isolated into a huge
mass of information linked in a semantic manner.
In other words, the semantic web consists in
adding formal semantics to the web content in order to
allow a more efficient access and management. This
is possible thanks to the improvement of the capabil-
ity of computers to manipulate data meaningfully by
providing meaning into web resources
1
. In doing so,
external software agents have to carry out complex
tasks on behalf of a human user and to improve the
degree of cooperation between humans and comput-
ers.
However, the transformation from traditional web
to semantic web depends on the presence of a critical
mass of metadata (Krestel et al., 2010) corresponding
1
A web resource is an entity that can be described on the
web. Each resource is identified by a unique URI (Uniform
Resource Identifier).
to web resources. The acquisition of these metadata
is a major challenge for the semantic web commu-
nity. As a solution, many manual tools ((Kahan and
Koivunen, 2001), (McDowell et al., 2003), (Hand-
schuh et al., 2001), (Bechhofer and Goble, 2001)),
semi-automatic tools ((Cunningham et al., 2002),
(Laclavik et al., 2009), (Vargas-Vera et al., 2002))
and automatic tools ((Popov et al., 2004), (Kogut and
Holmes, 2001)) for semantic annotation have been de-
veloped.
In our case, we are interested in the semantic an-
notation of web images. With the presence of a huge
number of web images, many approaches were devel-
oped. There are many approaches based on the image
content (color, texture, etc.) in order to produce an-
notations and only a few works using the contextual
factors of the image to annotate it without human in-
tervention.
Our goal is to obtain a fully automatic approach
for web images annotation based on contextual fac-
tors such as image caption, document title and sur-
rounding text. The main idea is to generate an RDF
2
graph from each contextual factor. The elementary
RDF graph (concerning one contextual factor) is com-
posed of concepts and instances of concepts linked
between them by semantic relations. After the genera-
tion of all elementary RDF graphs from all the contex-
2
http://www.w3.org/tr/2004/rec-rdf-primer-20040210/
137
Teyeb Jaouachi R., Torjmen Khemakhem M., Hernandez N., Haemmerle O. and Ben Jemaa M..
Semantic Annotation of Images Extracted from the Web using RDF Patterns and a Domain Ontology.
DOI: 10.5220/0005374301370144
In Proceedings of the 17th International Conference on Enterprise Information Systems (ICEIS-2015), pages 137-144
ISBN: 978-989-758-097-0
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)

tual factors, the next step consists in combining them
into a global RDF graph which is considered as an
image annotation.
The originality of our work is the use of a set of
RDF patterns and a domain ontology in order to guide
the step of annotation.
This paper is organised as follows: Section 2 re-
views the related works. Section 3 details the ap-
proach we propose for the image annotation. In sec-
tion 4, we present the domain ontology used in our
work. Section 5 finally demonstrates the obtained re-
sults.
2 RELATED WORKS
2.1 Annotation Approaches for Images
We can classify the existing approaches into two cat-
egories: (1) Content-Based Image Annotation; and
(2) Context-based Image Annotation.
Several works have studied Content-Based Image
Annotation. Among these approaches, we find (Li
and Wang, 2003) (Cusano et al., 2004), (Halaschek-
wiener et al., 2006), (Bellini et al., 2011), (Arndt
et al., 2007). The main idea of this type of approaches
is to associate a semantic description with the image
in totality or to describe a specific region of the im-
age. (Wang et al., 2007) shows a good classification
of these different approaches. Using the content of the
image for annotation purpose resolves, partially, the
Semantic Gap Problem defined by (Smeulders et al.,
2000).
Only a few works use contextual factors of the im-
age in order to annotate it. Among these approaches,
we find (Declerck et al., 2004). This approach was
proposed in the project Esperonto. It was based
on natural language techniques, ontologies and other
knowledge bases.
The approach proposed in (Nguyen, 2007) used
two contextual factors associated with web images. It
exploited the caption and keywords associated with
the image in order to construct a graph representing
its semantics.
2.2 SPARQL Query Generation using
Patterns
Our work is inspired by the SWIP system presented
in (Pradel et al., 2013). This system allows the trans-
lation of natural language queris into formal ones, ex-
pressed in SPARQL. The translation process is done
thanks to the use of query patterns, each pattern repre-
senting a family of typical queries. After the selection
of the pattern which is the best match to the natural
language query, that pattern is modified in order to
build the SPARQL query corresponding to the natural
query. The formal definition of a pattern is given in
(Pradel et al., 2012). An extension of that work has
been presented in (Gillet, 2013). It allows the genera-
tion of SPARQL queries based on different ontologies
of a same domain, thanks to ontology alignments.
Even if our goal is to annotate documents instead
of querying them, we propose to use patterns in our
work. These patterns are deeply inspired by the pat-
terns defined in (Pradel et al., 2012), but they are used
for multimedia document annotation purpose. The
patterns are adapted in order to take into account the
notions related to images. The details of our approach
is presented in Section 3.
3 OUR APPROACH FOR IMAGE
ANNOTATION
In this section, we present our approach aiming at an-
notating web images. Our idea is to use RDF patterns
in order to guide the extraction of relevant informa-
tion from contextual factors surrounding the image to
be annotated.
Among these factors, we cite (1) the image cap-
tion; (2) the paragraph title; (3) the text around the
image; (4) the hyperlinks between documents con-
taining images (if they exist); (5) the image name (if
it is significant) and (6) the table content if the images
are grouped in this structure.
After the choice of the factors to be used, the next
step is to apply, for each factor, a set of processings.
The goal of this step is to instantiate the RDF pat-
terns and to select the best instantiated pattern. More
details about our approach can be found in (Jaouachi
et al., 2013). Figure 1 shows an overview of the pro-
posed approach.
In this paper, we will focus on the step of the def-
inition, the instantiation and the use of RDF patterns.
A pattern is an RDF graph which represents a pro-
totype regrouping information considered as impor-
tant by the domain experts (the cinema in our case).
Each pattern is built by focusing on a group of pieces
of information related to the cinema field. Different
relationships between various concepts forming the
patterns are inspired from the “Movie ontology”.
In addition to these relations, we use two proper-
ties belonging to the foaf ontology (foaf:depiction and
foaf:img) which allows us to express the relationship
ICEIS2015-17thInternationalConferenceonEnterpriseInformationSystems
138
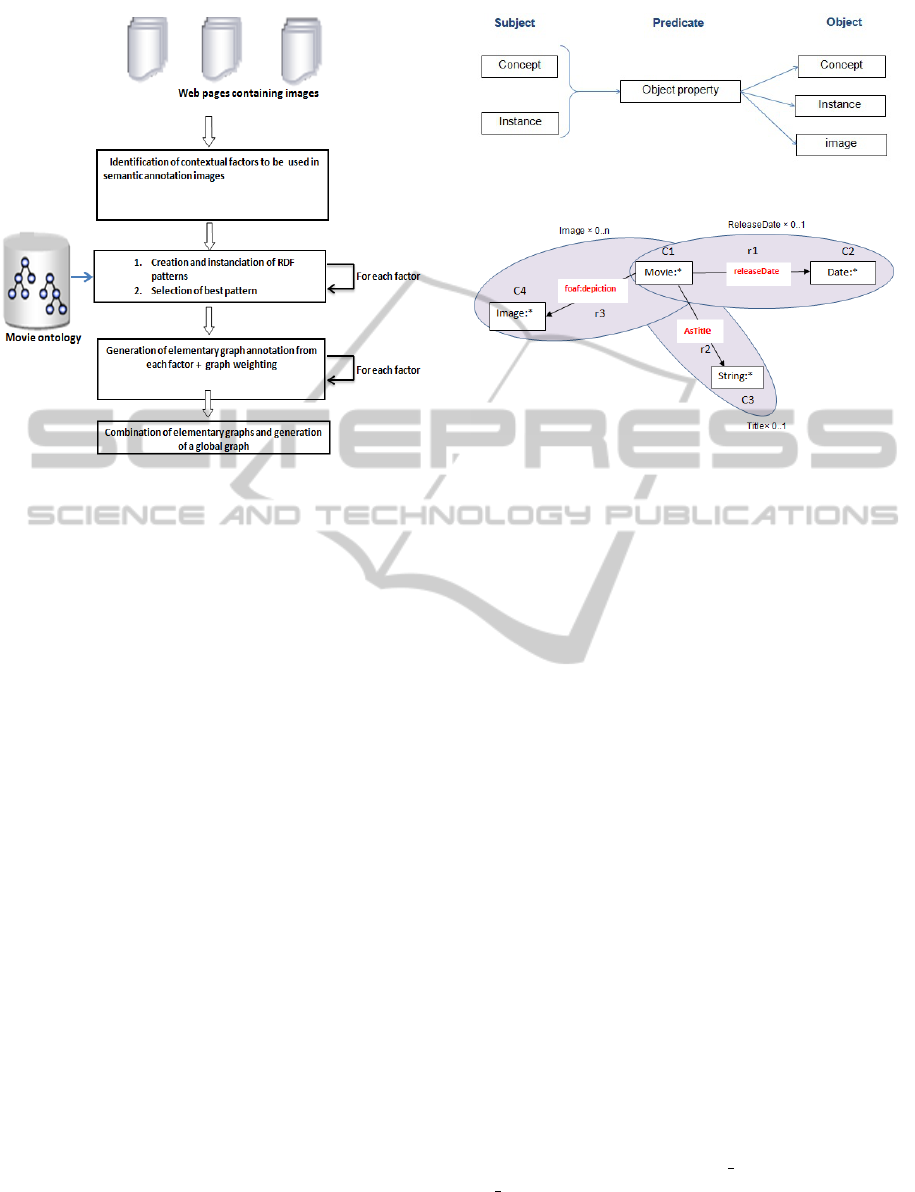
Figure 1: General approach overview.
between an element of the pattern (object or person
respectively) and the related image.
Definition
Our definition of a pattern is inspired from (Pradel
et al., 2013).
A pattern p is composed of 5 elements
(G, Q, SP, Img, S):
• G is a connected RDF graph which describes the
general structure of the pattern to be instantiated.
Such a graph is composed of triples according to
the structure presented in Figure 2. This structure
is formed by a subject (which can be a concept
or an instance of a concept), a predicate and an
object (which can be a concept or an instance of a
concept or an image);
• Q is a subset of elements of G, these elements
are considered to be characteristics of the pattern.
Such an element can be a class or an object prop-
erty or an image of G;
• SP is the set of sub-patterns sp of p;
• Img is the set of distinct images called qualifying
images present in the pattern. An image can illus-
trate an element of the pattern;
• S is a description of the meaning of the pattern in
natural language.
Example
Figure 3 shows an example of an RDF pat-
tern used for the step of annotation. It is
composed of three sub-patterns which are
[Movie,releaseDate,Date], [Movie,AsTitle,String]
Figure 2: Triples constituting the graph patterns.
Figure 3: Example of a pattern used for the annotation.
and [Movie,foaf:depection,Image]. All of them are
optional because they can remain uninstantiated.
Sub-patterns [Movie,releaseDate,Date] and
[Movie,AsTitle,String] are not repeatable and have
as cardinalities ReleaseDate*0..1 and Title*0..1
respectively with 0 is the minimal cardinality and 1
is the maximum cardinality. Indeed, a movie has one
title and one release date.
However, the sub-pattern
[Movie,foaf:depiction,Image] is repeatable and
has as cardinality image*0..n, n being the maximum
cardinality.
3.1 RDF Pattern Definition
In order to annotate web images, we define some RDF
patterns. Each pattern represents a prototype of a
group of information related to the domain studied.
In our case, we used six patterns considered as im-
portant by the experts of the domain. Each pattern is
centered around a vertex which is the Movie concept
and formed by a set of sub-patterns.
A sub-pattern can be defined as a simple triple
with the subject which is an instance of the Movie
concept (eg. triple [Movie:*,hasSoundmix,Sound-
Mix:*] with Movie:* is a vertex of the pattern)
or a set of triples whith one of them which is
linked at the vertex of the pattern (eg. triples
[Movie:*,hasComposer,Musical Artist:*] and [Musi-
cal Artist:*,foaf:img,image:*]) . The figure 4 rein-
forces the two definitions.
In order to define formally a pattern, we need three
type of vocabularies:
SemanticAnnotationofImagesExtractedfromtheWebusingRDFPatternsandaDomainOntology
139

Figure 4: Examples of sub-patterns.
• The first vocabulary allows the description of the
patterns in general. Indeed, we use the patters on-
tology
3
proposed in (Pradel et al., 2013). This
ontology defines the grammar allowing the repre-
sentation of patterns.
• The second vocabulary is the vocabulary of the
domain addressed in the context of the image.
It is necessary to associate each element or re-
lationship of a pattern with a concept or a rela-
tionship belonging to the domain ontology used
for the evaluation. In our case, we use the do-
main ontology named Movie ontology which will
be presented in section 4. We use properties of
this ontology to link the various properties used
in the construction of the RDF patterns. For ex-
ample, we have exploited the properties release-
Date from the Movie ontology to specify the pred-
icate between Movie concept and Date concept
and consequently to construct a sub-pattern of the
pattern shown in figure 3.
• The third vocabulary is necessary to describe all
the elements of the RDF patterns in relation to im-
ages. Indeed, by this vocabulary, we link an image
to the appropriate element of the pattern. In our
case, we use two properties from the foaf project:
foaf:depiction and foaf:img.The first property rep-
resents a relationship between a thing and an im-
age that depicts it, and the second property relates
a Person to an image that represents him/her.
To conclude, this step allows us to obtain several
patterns that have to be instantiated based on any
document related to the domain (cinema in our
case).
Example
Figure 5 shows an example of RDF pattern according
to the formal definition and uses the three vocabular-
ies mentioned above.
3
http://swip.univ-tlse2.fr/SwipWebClient/welcome.
html
Figure 5: Examples of pattern presented in formal defini-
tion.
This pattern is composed of two sub-patterns: lo-
cation and country. The three numbers after the name
of each sub-pattern are respectively : the minimal car-
dinality, the maximal cardinality and the identifying
of the element in order to instantiate the concerned
pattern.
3.2 Instanciation of RDF Patterns
The purpose of defining and using RDF patterns is to
guide the annotation procedure. We are not willing
to extract all the pieces of information contained in a
document but only to extract the pieces of information
which allow the instantiation of the patterns.
For example, by using the pattern shown in figure
3, we want to extract triples from a document that can
be instance of one of the three sub-patterns. In other
words, we look for the date of the Movie, its title and
its images.
This is possible by the following steps that will be
repeated as many times as the number of sub-patterns:
- The first step consists in identifying the predi-
cate of the sub-pattern. This step is based on the ap-
plication of extraction rules that will be described in
section 5.1.
- Once found, the second step consists in identify-
ing the subject and the predicate related by the iden-
tified relationship. This step is based on the identifi-
cation of instances forming two approximates of the
identified relationship.
- The third step consists in linking the web image
to the appropriate element of the pattern. This step
is based on the analysis of the image caption, if there
is any indication in the text describing the instance of
ICEIS2015-17thInternationalConferenceonEnterpriseInformationSystems
140

the concept concerned by the image.
We present in figure 7 the instantiation of the pat-
tern shown in figure 3 by using the text and the image.
Figure 6: Instantiation of the pattern presented in figure 3.
3.3 Selecting the Best Instantiated
Patterns to Represent the Text
The purpose of using patterns is to generate an RDF
annotation for the web document containing the im-
age. Our strategy is to instantiate patterns and then to
choose the best instantiated pattern.
In order to rank the instantiated patterns, we focus
on a set of criteria such as recall, precision, number
of correct extracted triples, number of automatic ex-
tracted triples. It is possible to use the three first crite-
ria only if we have a manual annotation as reference.
However the last criteria is independent of manual an-
notation.
In this paper, we present the results based on the
number of automatic extracted triples. The results us-
ing this criteria are presented in section 5. As a ref-
erence, we will compare the results obtained by using
our approach with manual ranking.
4 THE MOVIE ONTOLOGY
Like in most research domains, there are ontologies
which are used in order to represent, share and reuse
knowledge. Ontologies contain an effective structure
of the domain knowledge which improves the effi-
ciency of the retrieval system. The semantic web
techniques and technologies provide a manner to con-
struct and use web resources by attaching semantic
information to them.
In our work, we are interested in improving the
management of multimedia information by means
of knowledge representation, indexing and retrieval.
Among the multimedia entertainment, cinema stands
a good position so that we are interested, especially,
in the cinema domain.
In the literature, there is an ontology of the cin-
ema field which describes movie scenes. It is called
“Movie ontology”
4
and it is developed by the De-
partment of Informatics at the University of Zurich.
This ontology contains concept hierarchies for movie
categorisation, instances of concepts and relations be-
tween concepts.
It contains distinct concepts like Award, Certifica-
tion, Film, Person (Actor, Actress, Writer, Producer,
etc.).
5 EXPERIMENTATIONS AND
EVALUATION
In order to validate our proposition, we used a corpus
composed of 10 Wikipedia pages related to the cin-
ema domain, written in English language and contain-
ing images. The choice of these pages was arbitrary.
In our experiments, we have used only the surround-
ing text of images in order to instantiate six patterns.
As a reference, we annotated the corpus manually
and we generated the RDF graph corresponding to the
semantic annotation of each image. Figure 7 shows an
example of a web image and its surrounding text.
Figure 7: Example of image used for the evaluation.
5.1 Extraction Rules for Semantic
Relation Detection
In order to instantiate the RDF patterns, we use the
NLP (Natural Language Processing) tools, GATE
platform (Cunningham et al., 2002), Porter stemmer
(Porter, 1997) and our own extensions dedicated to
determinate the semantic relations for different pat-
terns.
4
http://www.movieontology.org/
SemanticAnnotationofImagesExtractedfromtheWebusingRDFPatternsandaDomainOntology
141

In this step, we used JAPE language (Cunningham
et al., 2002). It is a language based on regular expres-
sions. Using extraction rules, we try to detect an in-
stance of the Movie ontology relations (adapted as a
predicate for RDF pattern) and to detect instances of
concepts linked by this relationship.
Such a rule represents a set of phases, each of
which consists of a set of pattern/action rules. It has
always two sides: Left (LHS:Left-Hand Side) and
Right(RHS:Rigth-Hand Side). The LHS of the rule
contains the identified annotation pattern that may
contain regular expressions and the RHS outlines the
action to be taken on the detected pattern and con-
sists of annotation manipulation statements. The ex-
ample below (figure 8) shows a grammar which al-
lows the detection of instances of the semantic rela-
tion ”isAwardedWith”.
Figure 8: Rule example of JAPE grammar.
In the figure 8, we find an example of a rule
that is labeled isAwardedWith. ”Token.stem” cor-
responds to the lemmatised form of the word, ”To-
ken.category” corresponds to the grammatical cate-
gory of the word, ”Token.Kind” design the kind of
word. It means the word represents a number or a
simple word or a punctuation. ”Lookup.majortype”
means that the word is considered as the default con-
cept. ”Lookup.minortype” corresponds to the specific
categories of the word. "|" means that there are many
alternatives. "-->" is the boundary of the LHS rule.
Our relation will be part of the annotation prop-
erties that can be seen in GATE. This is possi-
ble using :is Awarded with.RelationShip = kind =
”is Awarded with”, rule=isAwardedwith.
5.2 Results
In order to choose the best pattern to be considered
as the basis for the annotation of the image, we did a
ranking according to the number of extracted triples.
Table 1 and table 2 present the results for the im-
age shown in Figure 7 using our approach firstly, and
the result of the manual classification secondly.
Table 1: Automatic ranking of patterns corresponding to
image 7.
Rank Patterns Ranking Number of automatic triple
1 pattern 2 7
2 pattern 4 6
3 pattern 1,pattern 6 4
4 pattern 3,pattern 5 0
Table 2: Manual RDF patterns classification.
Rank Patterns Ranking Number of manual triple
1 pattern 2 6
2 pattern 6 4
3 pattern1 3
4 pattern 3,pattern 4 1
We note that for this document, we obtained the
same best rated pattern (pattern 2 is the highest rated
pattern obtained by our approach and by a manual ap-
proach).
We note that the number of triples in a pattern
can influence the final ranking. Indeed, the pattern
2 (the best ranked pattern) contains the highest num-
ber of triples. In addition, the presence of the generic
triples having a maximum cardinality equal to n, can
affect scheduling. For example, we can instantiate the
generic triple [Movie: * hasActor, Actor *] repeatedly
since a film can have the participation of several ac-
tors.
We repeated the same work for the ten web docu-
ments used for the evaluation.
In order to evaluate the quality of the annotation
for the test collection, we used the following measure:
QA =
Nr.o f wellannotateddocuments
Totalnumbero f documents
(1)
with QA is the quality of the annotation.
We consider a well-annotated document if it is an-
notated by P
i
(i ∈ [1..6] with 6 is the number of pattern
used) having the first place automatically and the first
place manually (the same P
i
).
We also calculate QA where P
i
obtains the second
rank automatically.
Table 3 presents the results on the entire collec-
tion.
Obtained results are encouraging. Indeed, having
high rates for the two best patterns (compared to man-
ual annotation) shows the importance of our work.
ICEIS2015-17thInternationalConferenceonEnterpriseInformationSystems
142

Table 3: Quality of annotation.
Automatic Rank of P
i
QA
1 0.44
2 0.55
We succeeded to associate eighteen images to dif-
ferent elements of patterns that can be illustrated by a
picture.
The success of these association shows the interest
of our approach to annotate text and image at a time.
Choosing the number of extracted triples as cri-
terion of classification is not arbitrary. In fact, it is
impossible to use precision and recall as criterion of
selection because it is not possible to obtain manual
annotation for every test.
However, we note that the use of this criterion
(number of extracted triples) has the disadvantage of
promoting the pattern with the greatest number of
sub-patterns or with a maximum cardinality greater
than 1 (repeatable sub-patterns).
To overcome this problem, we plan to propose a
new ranking function in our future work.
6 CONCLUSION
The potential of the semantic web to resolve informa-
tion retrieval problems is tremendous. Based on se-
mantic annotation techniques, adding formal seman-
tics to the web content is vital to improve information
indexing and retrieval.
In our case, our goal is to improve web images re-
trieval. To achieve this aim, we propose an automatic
approach to semantically annotate images through
their context. Indeed, we use contextual factors such
as the caption of the image, the surrounding text, etc.
in order to instantiate RDF patterns.
In this paper, we focused on the process of instan-
tiation of RDF patterns using a domain ontology and
patterns of extraction written in Jape language and the
exploitation of instantiated patterns in order to choose
the suitable annotation.
Preliminary results are encouraged to automate
and use a bigger cinema corpus.
Working with all image contextual factors repre-
sents our next step. The aim of this step is to instan-
tiate RDF patterns from each factor and to generate a
global annotation.
REFERENCES
Arndt, R., Troncy, R., Staab, S., Hardman, L., and Vacura,
M. (2007). Comm: Designing a well-founded multi-
media ontology for the web. In Proceedings of the 6th
International Semantic Web Conference (ISWC2007),
pages 11–15.
Bechhofer, S. and Goble, C. (2001). Towards annotation
using daml+oil. In Workshop Knowledge Markup &
Semantic Annotation, Victoria B.C., Canada.
Bellini, P., Bruno, I., and Nesi, P. (2011). Exploiting intelli-
gent content via axmedis/mpeg-21 for modelling and
distributing news. International Journal of Software
Engineering and Knowledge Engineering, 21(1):3–
32.
Cunningham, H., Maynard, D., Bontcheva, K., and Tablan,
V. (2002). GATE: A Framework and Graphical Devel-
opment Environment for Robust NLP Tools and Ap-
plications. In ACL’02,the 40th Anniversary Meeting
of the Association for Computational Linguistics.
Cusano, C., Ciocca, G., and Schettini, R. (2004). Image an-
notation using SVM. Proceedings of SPIE, 5304:330–
338.
Declerck, T., Crispi, C., Contreras, J., and ?scar Cor-
cho (2004). Text-based semantic annotation service
for multimedia content in the esperonto project. In
Knowledge-Based Media Analysis for Self-Adaptive
and Agile Multi-Media, Proceedings of the European
Workshop for the Integration of Knwoledge, Seman-
tics and Digital Media Technology, EWIMT 2004,
November 25-26, 2004, London, UK.
Gillet, P. (2013). Gnration de patrons de requtes par-
tir dalignements dontologies: Application un systme
dinterrogation du web smantique fond sur les patrons.
Halaschek-wiener, C., Golbeck, J., Schain, A., Parsia,
B., and Hendler, J. (2006). Annotation and prove-
nance tracking in semantic web photo libraries. In In
International provenance and annotation workshop.
Chicago, pages 82–89.
Handschuh, S., Staab, S., and Maedche, A. (2001). Cream:
creating relational metadata with a component-based,
ontology-driven annotation framework. In K-CAP,
pages 76–83.
Jaouachi, R. T., Khemakhem, M. T., Jemaa, M. B., Hernan-
dez, N., and Haemmerle, O. (2013). Multi-factor rdf
graph based image annotation -application in cinema
domain-. In ICWIT’13, Fifth International Conference
on Web and Information Technologies.
Kahan, J. and Koivunen, M.-R. (2001). Annotea: An
open rdf infrastructure for shared web annotations.
In Proceedings of the 10th International Conference
on World Wide Web, pages 623–632, New York, NY,
USA. ACM.
Kogut, P. and Holmes, W. (2001). Aerodaml: Applying
information extraction to generate daml annotations
from web pages. In First International Conference
on Knowledge Capture (K-CAP 2001). Workshop on
Knowledge Markup and Semantic Annotation.
Krestel, R., Witte, R., and Bergler, S. (2010). Predicate-
Argument EXtractor (PAX). In New Challenges for
NLP Frameworks.
Laclavik, M., Hluch?, L., Seleng, M., and Ciglan, M.
(2009). Ontea: Platform for pattern based automated
semantic annotation. Computing and Informatics,
pages 555–579.
SemanticAnnotationofImagesExtractedfromtheWebusingRDFPatternsandaDomainOntology
143

Li, J. and Wang, J. Z. (2003). Automatic linguistic indexing
of pictures by a statistical modeling approach. IEEE
Trans. Pattern Anal. Mach. Intell., 25(9):1075–1088.
McDowell, L., Etzioni, O., Gribble, S. D., Halevy, A. Y.,
Levy, H. M., Pentney, W., Verma, D., and Vlasseva, S.
(2003). Mangrove: Enticing ordinary people onto the
semantic web via instant gratification. In The Seman-
tic Web - ISWC 2003, Second International Semantic
Web Conference, Sanibel Island, FL, USA, October
20-23, 2003, Proceedings, pages 754–770.
Nguyen, M.-T. (2007). Vers une plate-forme d’annotations
smantiques automatiques partir de documents multi-
mdias.
Popov, B., Kiryakov, A., Kirilov, A., Manov, D.,
Ognyanoff, D., and Goranov, M. (2004). Kim seman-
tic annotation platform. Journal of Natural Language
Engineering, pages 375–392.
Porter, M. F. (1997). Readings in information retrieval.
chapter An algorithm for suffix stripping. Morgan
Kaufmann Publishers Inc., San Francisco, CA, USA.
Pradel, C., Haemmerl
´
e, O., and Hernandez, N. (2012). Des
patrons modulaires de requtes sparql dans le systme
swip. In 23eme Journes Francophones dIngnierie des
Connaissances.
Pradel, C., Haemmerl
´
e, O., and Hernandez, N. (2013). Nat-
ural language query translation into sparql using pat-
terns. In COLD.
Smeulders, A. W. M., Worring, M., Santini, S., Gupta, A.,
and Jain, R. (2000). Content-based image retrieval at
the end of the early years. IEEE Trans. Pattern Anal.
Mach. Intell., 22(12):1349–1380.
Vargas-Vera, M., Motta, E., Domingue, J., Lanzoni, M.,
Stutt, A., and Ciravegna, F. (2002). Mnm: Ontology
driven semi-automatic and automatic support for se-
mantic markup. pages 379–391.
Wang, C., Jing, F., Zhang, L., and Zhang, H.-J. (2007).
Content-Based Image Annotation Refinement. Com-
puter Vision and Pattern Recognition, 2007. CVPR
’07. IEEE Conference on, pages 1–8.
ICEIS2015-17thInternationalConferenceonEnterpriseInformationSystems
144
