
Multi-camera Video Object Recognition Using Active Contours
Joanna Isabelle Olszewska
School of Computing and Technology, University of Gloucestershire, The Park, Cheltenham, GL50 2RH, U.K.
Keywords:
Active Contours, Multi-camera Detection, Unsupervised Segmentation, Video-object Recognition, Semantic
Colors, Multi-feature Vector Flow, Information Fusion, Video Surveillance, Scene Understanding.
Abstract:
In this paper, we propose to tackle with multiple video-object detection and recognition in a multi-camera
environment using active contours. Indeed, with the growth of multi-camera systems, many computer vision
frameworks have been developed, but none taking advantage of the well-established active contour method.
Hence, active contours allow precise and automatic delineation of entire object’s boundaries in frames, leading
to an accurate segmentation and tracking of video objects displayed into the multi-view system, while our late
fusion approach allows robust recognition of the detected objects in the synchronized sequences. Our active-
contour-based system has been successfully tested on video-surveillance standard datasets and shows excellent
performance in terms of computational efficiency and robustness compared to state-of-art ones.
1 INTRODUCTION
The growing use of multi-camera networks for video
surveillance (Kumar et al., 2010), (Bhat and Ol-
szewska, 2014) and its related applications such as
robotics (M. Kamezaki, 2014), intelligent transport
(Spehr et al., 2011), monitoring (Remagnino et al.,
2004), event detection (Zhou and Kimber, 2006), or
tracking (Fleuret et al., 2008) stimulates the devel-
opment of computer-vision approaches which aim to
efficiently analyse the resulting big amount of visual
data to extract meaningful information.
Figure 1: Outlook of the field of view (FOV) of each cam-
era, as in the used scenario to test our approach.
In particular, the design of multi-view video
recognition systems is of prime importance. Such
systems need to process multi-view video streams, i.e.
video sequences of a dynamic scene captured simul-
taneously by multiple cameras, for detecting and rec-
ognizing objects of interest in order to automatically
understand the acquired, complex scene. For this pur-
pose, visual data should be processed through three
main stages, namely, object-of-interest detection, seg-
mentation, and recognition.
Most of the existing works about the analysis of
multi-camera video streams are focused on tracking
multiple, moving objects and apply approaches such
as background subtraction (Diaz et al., 2013), lo-
cal descriptors’ matching (Ferrari et al., 2006), oc-
cupancy map based on motion consistency (Fleuret
et al., 2008), Bayesian framework (Hsu et al., 2013),
particle filter (Choi and Yoo, 2013), or Cardinalized
Probability Hypothesis Density (CPHD) based filter
(Lamard et al., 2013).
In this paper, we propose to introduce the ac-
tive contour method (Olszewska, 2012), (Olszewska,
2013), (Bryner and Srivastava, 2014), which is ef-
ficient both for precisely segmenting and tracking
meaningful objects of interest, into a full and auto-
matic system which takes multi-camera video stream
inputs and performs visual data processing to recog-
nize multi-view video objects, in context of outdoor
video-surveillance.
Our system does not require any camera calibra-
379
Isabelle Olszewska J..
Multi-camera Video Object Recognition Using Active Contours.
DOI: 10.5220/0005334303790384
In Proceedings of the International Conference on Bio-inspired Systems and Signal Processing (MPBS-2015), pages 379-384
ISBN: 978-989-758-069-7
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)
tion parameter, since in real-world situations, camera
characteristics are not often readily available (Guler
et al., 2003), (Mavrinac and Chen, 2013) and/or cam-
era calibration is computationally expensive (Black
et al., 2002), (Farrell and Davis, 2008), (Lee et al.,
2014). Moreover, our approach does not use any 3D
model as in (Sin et al., 2009), and thus reduces the
computational burden.
Our system deals with dynamic scenes recorded
by standard pan-tilt-zoom (PTZ) static cameras with
partially overlapping and narrow fields of view
(FOV). In fact, this configuration (Fig. 1) captures a
rich variety of real-world situations, where target ob-
jects could be seen in both views, leading to a full cov-
erage of some areas like with omnidirectional cam-
eras (Guler et al., 2003), or where targets could be
visible in only one view, this latter case being simi-
lar to records of a non-overlapping camera network
(Kettnaker and Zabih, 1999), (Chen et al., 2008).
On the other hand, the acquired multi-view se-
quences usually contain noise, complex backgrounds
and blurred, moving objects, called objects of inter-
est or foregrounds. Video frames could be subject to
illumination variations or poor resolution (Fig. 2).
Hence, the contribution of this paper is threefold:
• the use of active contours for multi-camera video
stream analysis;
• the color categorization algorithm for object-of-
interest recognition purpose;
• the development of an automatic system based
on active contours for multiple, visual target de-
tection and recognition in multi-camera environ-
ment.
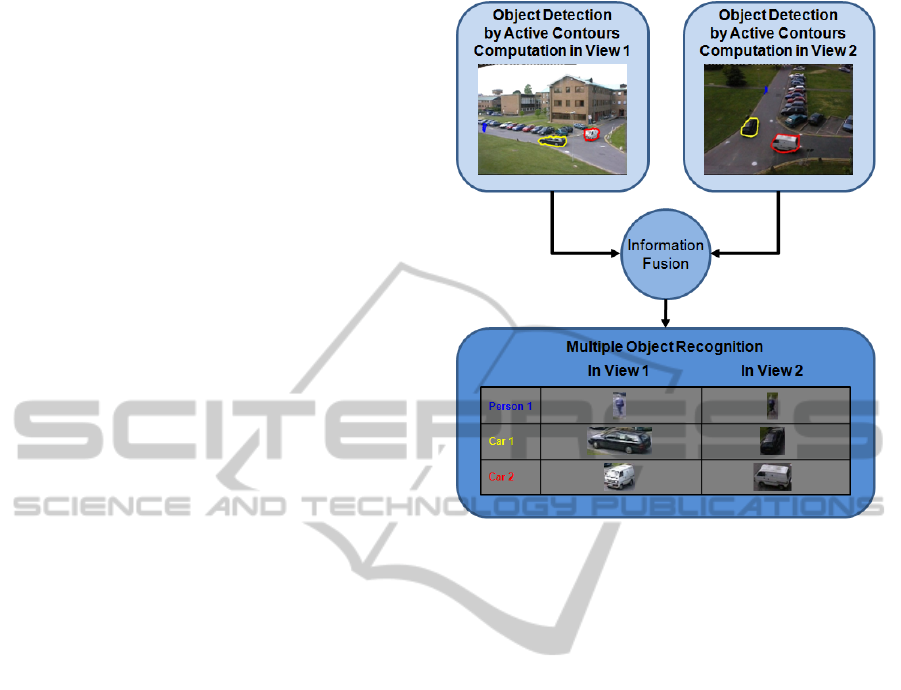
The paper is structured as follows. In Section 2,
we describe our multi-camera stream analysis sys-
tem (see Fig. 2) based on active contour computa-
tion in each view and on the late fusion of the result-
ing information for fast, multiple video-object recog-
nition. Our approach performance have been assessed
on standard, real-world video-surveillance dataset as
reported and discussed in Section 3. Conclusions are
presented in Section 4.
2 PROPOSED APPROACH
To detect multiple objects of interest in video scenes,
we use active contours (Olszewska and McCluskey,
2011; Olszewska, 2011; Olszewska, 2012) which
present the major advantage to quickly and precisely
delineate an entire targeted object and thus to seg-
ment the object as a whole, rather than only disparate
pieces as in (Travieso et al., 2014). Hence, we adopt
Figure 2: Overview of our active-contour-based approach
for multiple-object detection and recognition in a multi-
camera environment.
multi-target, multi-feature vector flow active contour
approach (Olszewska, 2012) which has been proven
to be efficient to detect objects of interest accurately
and robustly.
In order to initialized these active contours, we
first use the background subtraction method. This
could be computed by difference between two con-
secutive frames (Archetti et al., 2006), by subtract-
ing the current frame from the background (Toyama
et al., 1995; Haritaoglu et al., 2000), or combin-
ing both frame difference and background subtraction
techniques (Huang et al., 2007; Yao et al., 2009).
The latter technique consists in computing in par-
allel, on one hand, the difference between a current
frame I
v
k
(x,y) in the view v and the precedent one
I
v
k−1
(x,y), and on the other hand, the difference be-
tween the current frame I
v
k
(x,y) and a background
model of the view v, and afterwards, to combine both
results in order to extract the foreground in the corre-
sponding view.
To model the background, we adopt the running
Gaussian average (RGA) (Wren et al., 1997), char-
acterized by the mean µ
v
b
and the variance (σ
v
b
)
2
,
rather than, for example, the Gaussian mixture model
(GMM) (Stauffer and Grimson, 1999; Friedman and
Russell, 1997; Zivkovic and van der Heijden, 2004),
since the RGA method is much more suitable for real-
BIOSIGNALS2015-InternationalConferenceonBio-inspiredSystemsandSignalProcessing
380

time tracking.
Hence, the foreground is determined by
F
v
(x,y) =
(
1 if
F
v
f
(x,y) ∪ F
v
b
(x,y)
= 1,
0 otherwise,
(1)
with
F
v
f
(x,y) =
(
1 if
I
v
k
(x,y) − I
v
k−1
(x,y)
> t f ,
0 otherwise,
(2)
and
F
v
b
(x,y) =
(
1 if
I
v
k
(x,y) − µ
v
b
> n · σ
v
b
,
0 otherwise,
(3)
where t f , is the threshold, and n ∈ N
0
.
Finally, to compute a blob defined by labeled
connected regions, morphological operations such as
opening and closure (Haralick, 1988) are applied to
the extracted foreground F
v
, in order to exploit the
existing information on the neighboring pixels, in a
view v,
f
v
(x,y) = Morph(F
v
(x,y)). (4)
Then, an active contour is computed for each
frame k in each view v separately, and for each tar-
geted object (see Fig. 2). In this work, an active con-
tour is a parametric curve C
C
C (s) : [0, 1] −→ R
2
, which
evolves from its initial position computed by means
of Eq. (4) to its final position, guided by internal and
external forces as follows
C
C
C
t
(s,t) = α C
C
C
ss
(s,t)− β C
C
C
ssss
(s,t)+Ξ
Ξ
Ξ, (5)
where C
C
C
ss
and C
C
C
ssss
are respectively the second
and the fourth derivative with respect to the curve pa-
rameter s; α is the elasticity; β is the rigidity; and Ξ
Ξ
Ξ
is the multi-feature vector flow (MFVF) (Olszewska,
2013) .
Once the object has been detected as per previ-
ous steps, the colors of the objects are extracted for
recognition purpose. In this work, the color concept
is defined by 16 basic color keywords defined in SVG
standard (Olszewska and McCluskey, 2011). More-
over, the object’s color is not the average value over
the whole detected object (Parker, 2010), but a set of
colors of the different parts of the object.
To compute object’s colors, an object is consid-
ered to have p parts according to intra-object rela-
tions using the o’clock concept (Olszewska and Mc-
Cluskey, 2011), which does not induce an arbitrary
division of the target but a partition taking automat-
ically into account object’s concavities and convexi-
ties. The color in each object’s part c
p
is found by as-
sociating the extracted numeric (R,G,B) value in the
Algorithm 1: Inhomogeneous/Homogeneous Color.
Given C = {c
b
}, the set of the object’s colors such as
C = CV
1
∪CV
2
and b ∈ N;
L = C \ {c
1
} with c
1
= head(C); G = {c
1
};
and th, the threshold;
do
repeat
c
j
= head(L);
if c
j
/∈ G then G = G ∪ {c
j
}
end if
L = L \ {c
j
};
until L =
/
0
return G
if (#G > th)
then the color of object is inhomogeneous
else the color of object is homogeneous
end if
end do
red (R), green (G), blue (B) color space to the related
semantic name.
Next, for object recognition purpose, our system
performs a late fusion, approach proven to be more
efficient than early fusion where all the cameras are
used to make a decision about the detection of the
objects of interest (Evans et al., 2013). Indeed, in
our system, objects of interest are detected in indi-
vidual cameras independently. Then, the results are
combined on the majority voting principle based on
the semantic consistency of the color across multiple
camera views (see Fig. 2) and not on the sole geomet-
rical correspondences of objects as in (Dai and Payan-
deh, 2013). Hence, in our recognition approach, the
object’s color sets CV
1
and CV
2
in view 1 and 2, re-
spectively, are matched using the Hausdorff distance
d
H
(CV
1
,CV
2
), which is computed as follows (Alqaisi
et al., 2012):
d
H
(CV
1
,CV
2
) = max
d
h
(CV
1
,CV
2
),d
h
(CV
2
,CV
1
)
,
(6)
where d
h
(CV
1
,CV
2
) is the directed Hausdorff dis-
tance from CV
1
to CV
2
defined as
d
h
(CV
1
,CV
2
) = max
cv∈CV
1
min
cw∈CV
2
d
P
(cv, cw), (7)
with d
P
(cv, cw), the Minkowski-form distance
based on the L
P
norm, and defined as
d
P
(cv, cw) =
∑
k
(cv
k
− cw
k
)
P
1/P
. (8)
Multi-cameraVideoObjectRecognitionUsingActiveContours
381

After the recognition step, objects of interest
could be categorized further, in context of video
surveillance. Indeed, based on real-world observa-
tion, assumption is made that an homogeneous color
is associated to an object such as ‘car’, while an inho-
mogeneous color corresponds to a ‘person’ type ob-
ject. Homogeneous and inhomogeneous colors of de-
tected objects are thus distinguished using the Algo-
rithm 1. Moreover, in the studied camera framework,
camera devices are relatively far from the scene, so
foregrounds’ close-up are not likely to occur, and a
car area is usually perceived as greater than a per-
son’s one. Thus, the area A
o
inside the active contour
of the detected object o could be used to validate the
classification of objects of interest into ‘car’ and ‘per-
son’ categories by comparing the area defined as A
o
= max
v
{A
v
o
} against a threshold ta, i.e if A
o
> ta the
object is a car, otherwise it is a person.
Hence, the semantic color values of any object de-
tected and segmented with active contours in a frame
are automatically compared within views and addi-
tionally checked against inhomogeneous and homo-
geneous criterion in order to achieve a precise target
recognition. This technique as well as the use of met-
rics, such as object’s area directly provided by the ac-
tive contours, ensures the robustness of the system.
3 EXPERIMENTS AND
DISCUSSION
To assess our approach, we have applied our sys-
tem on the standard dataset (PETS, 2001) consisting
of video-surveillance dynamic scene recorded by two
PTZ cameras whose fields of view are overlapping
(Fig. 1) as illustrated e.g. in Figs. 3 (a)-(b). Further-
more, the FOVs do not necessarily end neatly at the
edge of a camera’s field of vision as observed e.g. in
Fig. 3 (d). The resulting, two synchronized videos
were captured in outdoor environment and contain
2688 frames each, with an image average resolution
of 576x768 pixels.
This database owns challenges of multi-view
video stream, as well as quantity, pose, motion, size,
appearance and scale variations of the objects of in-
terest, i.e. of the people and cars.
All the experiments have been run on a computer
with Intel Core 2 Duo Pentium T9300, 2.5 GHz, 2Gb
RAM, and using MatLab.
Some examples of the results of our system are
presented, in Fig. 3, for detection and recognition
of multiple objects of interest, which could be either
moving persons and cars. These frames present dif-
ficult situations such as poor foreground/background
(a) (b)
(c) (d)
Figure 3: Examples of results obtained with our approach
for same scenes in both views. First column: view from the
first camera. Second column: view from the second camera.
contrast, light reflection, or illumination changes.
Moreover, some targeted objects could only seen in
one of the views as per configuration depicted in Fig.
1. Hence, in Figs. 3 (a)-(b), two objects of interest,
one person and one car, respectively, are present in
both views. On the other hand, in Figs. 3 (c)-(d),
there are six objects of interest, i.e. five persons and
one car, in the first view, whereas only four persons
and one car are visible in the second view, bringing
the number of observed objects of interest to five. Our
system copes well with these situations as discussed
below.
To measure the detection accuracy of our sys-
tem, we adopt the standard criteria (Izadi and Saeedi,
2008) as follows:
detection rate (DR) =
T P
T P + FN
, (9)
f alse detection rate (FAR) =
FP
FP + T P
, (10)
with T P, true positive, FP, false positive, and
FN, false negative.
The recognition accuracy of our system could be
assessed using the following standard criterion:
accuracy =
T P + T N
T P + T N + FP + FN
, (11)
with T N, true negative.
In Table 1, we have reported the average detec-
tion and false alarm rates of our method against the
rates achieved by (Izadi and Saeedi, 2008) and (Bhat
and Olszewska, 2014), while in Table 2, we have
BIOSIGNALS2015-InternationalConferenceonBio-inspiredSystemsandSignalProcessing
382

Table 1: Average detection rate (DR) and average false
alarm rate (FAR) of object-of-interests in video frames, us-
ing approaches of ♦(Izadi and Saeedi, 2008), (Bhat and
Olszewska, 2014), and our.
♦ our
DR 91.3% 91.6% 95.2
FAR 9.5% 4.9% 3.1%
Table 2: Average accuracy of object-of-interest recognition
in video frames, using approaches of 4(Athanasiadis et al.,
2007), (Bhat and Olszewska, 2014), and our.
4 our
average accuracy 85% 95% 96%
displayed the average accuracy of object-of-interest
recognition of our method against the rate obtained by
(Athanasiadis et al., 2007) and (Bhat and Olszewska,
2014).
From Tables 1-2, we can conclude that our sys-
tem provides reliable detection of objects of interest
in multi-camera environment, and that our multiple-
object recognition method is very accurate as well,
outperforming state-of-the art techniques.
For all the dataset, the average computational
speed of our approach is in the range of milliseconds,
thus our developed system could be used in context of
real-world, video surveillance.
4 CONCLUSIONS
In this paper, we focus on the reliable detection and
recognition of multiple objects of interest in multi-
stream visual data such as surveillance videos. For
this purpose, we have incorporated active contours in
the process of automatically analyzing multi-camera,
synchronized video sequences with narrow, partially
overlapping fields of view. Our approach outperforms
the ones found in the literature for both object detec-
tion and object recognition.
REFERENCES
Alqaisi, T., Gledhill, D., and Olszewska, J. I. (2012). Em-
bedded double matching of local descriptors for a fast
automatic recognition of real-world objects. In Pro-
ceedings of the IEEE International Conference on Im-
age Processing (ICIP’12), pages 2385–2388.
Archetti, F., Manfredotti, C., Messina, V., and Sorrenti, D.
(2006). Foreground-to-ghost discrimination in single-
difference pre-processing. In Proceedings of the In-
ternational Conference on Advanced Concepts for In-
telligent Vision Systems, pages 23–30.
Athanasiadis, T., Mylonas, P., Avrithis, Y., and Kollias, S.
(2007). Semantic image segmentation and object la-
beling. IEEE Transactions on Circuits and Systems
for Video Technology, 17(3):298–312.
Bhat, M. and Olszewska, J. I. (2014). DALES: Automated
Tool for Detection, Annotation, Labelling and Seg-
mentation of Multiple Objects in Multi-Camera Video
Streams. In Proceedings of the ACL International
Conference on Computational Linguistics Workshop,
pages 87–94.
Black, J., Ellis, T., and Rosin, P. (2002). Multi View Im-
age Surveillance and Tracking. In Proceedings of
the IEEE Workshop on Motion and Video Computing,
pages 169–174.
Bryner, D. and Srivastava, A. (2014). Bayesian active
contours with affine-invariant, elastic shape prior. In
Proceedings of the IEEE International Conference on
Computer Vision and Pattern Recognition, pages 312–
319.
Chen, K.-W., Lai, C.-C., Hung, Y.-P., and Chen, C.-S.
(2008). An adaptative learning method for target
tracking across multiple cameras. In Proceedings of
the IEEE International Conference on Computer Vi-
sion and Pattern Recognition, pages 1–8.
Choi, J.-W. and Yoo, J.-H. (2013). Real-time multi-person
tracking in fixed surveillance camera environment. In
Proceedings of the IEEE International Conference on
Consumer Electronics.
Dai, X. and Payandeh, S. (2013). Geometry-based object
association and consistent labeling in multi-camera
surveillance. IEEE Journal on Emerging and Selected
Topics in Circuits and Systems, 3(2):175–184.
Diaz, R., Hallman, S., and Fowlkes, C. C. (2013). Detecting
dynamic objects with multi-view background subtrac-
tion. In Proceedings of the IEEE International Con-
ference on Computer Vision, pages 273–280.
Evans, M., Osborne, C. J., and Ferryman, J. (2013). Mul-
ticamera object detection and tracking with object
size estimation. In Proceedings of the IEEE Inter-
national Conference on Advanced Video and Signal
Based Surveillance, pages 177–182.
Farrell, R. and Davis, L. S. (2008). Decentralized discovery
of camera network topology. In Proceedings of the
ACM/IEEE International Conference on Distributed
Smart Cameras, pages 1–10.
Ferrari, V., Tuytelaars, T., and Gool, L. V. (2006). Simulta-
neous object recognition and segmentation from sin-
gle or multiple model views. International Journal of
Computer Vision, 67(2):159–188.
Fleuret, F., Berclaz, J., Lengagne, R., and Fua, P. (2008).
Multicamera people tracking with a probabilistic oc-
cupancy map. IEEE Transactions on Pattern Analysis
and Machine Intelligence, 30(2):267–282.
Friedman, N. and Russell, S. (1997). Image segmentation
in video sequences: A probabilistic approach. In Pro-
ceedings of the 13th Conference on Uncertainty in AI.
Guler, S., Griffith, J. M., and Pushee, I. A. (2003). Track-
ing and handoff between multiple perspective camera
views. In Proceedings of the 32nd IEEE Workshop on
Multi-cameraVideoObjectRecognitionUsingActiveContours
383

Applied Imaginary Pattern Recognition, pages 275–
281.
Haralick, R. M. (1988). Mathematical morphology and
computer vision. In Proceedings of the IEEE Asilo-
mar Conference on Signals, Systems and Computers,
volume 1, pages 468–479.
Haritaoglu, I., Harwood, D., and Davis, L. (2000). Real-
time surveillance of people and their activities. IEEE
Transactions on Pattern Analysis and Machine Intel-
ligence, 77(8):809–830.
Hsu, H.-H., Yang, W.-M., and Shih, T. K. (2013). People
tracking in a multi-camera environment. In Proceed-
ings of the IEEE Conference Anthology, pages 1–4.
Huang, W., Liu, Z., and Pan, W. (2007). The precise recog-
nition of moving object in complex background. In
Proceedings of 3rd IEEE International Conference on
Natural Computation, volume 2, pages 246–252.
Izadi, M. and Saeedi, P. (2008). Robust region-based back-
ground subtraction and shadow removing using colour
and gradient information. In Proceedings of the 19th
IEEE International Conference on Pattern Recogni-
tion, pages 1–5.
Kettnaker, V. and Zabih, R. (1999). Bayesian multi-camera
surveillance. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, vol-
ume 2, pages 1–5.
Kumar, K. S., Prasad, S., Saroj, P. K., and Tripathi, R. C.
(2010). Multiple cameras using real-time object track-
ing for surveillance and security system. In Proceed-
ings of the IEEE International Conference on Emerg-
ing Trends in Engineering and Technology, pages
213–218.
Lamard, L., Chapuis, R., and Boyer, J.-P. (2013). CPHD
Filter addressing occlusions with pedestrians and ve-
hicles tracking. In Proceedings of the IEEE Inter-
national Intelligent Vehicles Symposium, pages 1125–
1130.
Lee, G. H., Pollefeys, M., and Fraundorfer, F. (2014).
Relative pose estimation for a multi-camera system
with known vertical direction. In Proceedings of the
IEEE International Conference on Computer Vision
and Pattern Recognition, pages 540–547.
M. Kamezaki, Y. Junjie, H. I. S. S. (2014). An autonomous
multi-camera control system using situation-based
role assignment for tele-operated work machines. In
Proceedings of the IEEE International Conference on
Robotics and Automation, pages 5971–5976.
Mavrinac, A. and Chen, X. (2013). Modeling coverage in
camera networks: A survey. International Journal of
Computer Vision, 101(1):205–226.
Olszewska, J. I. (2011). Spatio-temporal visual ontology.
In Proceedings of the 1st EPSRC Workshop on Vision
and Language (VL’2011).
Olszewska, J. I. (2012). Multi-target parametric active con-
tours to support ontological domain representation. In
Proceedings of the RFIA Conference, pages 779–784.
Olszewska, J. I. (2013). Multi-scale, multi-feature vector
flow active contours for automatic multiple-face de-
tection. In Proceedings of the International Confer-
ence on Bio-Inspired Systems and Signal Processing.
Olszewska, J. I. and McCluskey, T. L. (2011). Ontology-
coupled active contours for dynamic video scene un-
derstanding. In Proceedings of the IEEE International
Conference on Intelligent Engineering Systems, pages
369–374.
Parker, J. R. (2010). Algorithms for Image Processing and
Computer Vision. John Wiley and Sons, 2nd edition.
PETS (2001). PETS Dataset. Available online at:
ftp://ftp.pets.rdg.ac.uk/pub/PETS2001.
Remagnino, P., Shihab, A. I., and Jones, G. A. (2004). Dis-
tributed intelligence for multi-camera visual surveil-
lance. Pattern Recognition, 37(4):675–689.
Sin, M., Su, H., Savarese, S., and Fei-Fei, L. (2009).
A multi-view probabilistic model for (3D) object
classes. In Proceedings of the IEEE International
Conference on Computer Vision and Pattern Recog-
nition, pages 1247–1254.
Spehr, J., Rosebrock, D., Mossau, D., Auer, R., Brosig,
S., and Wahl, F. M. (2011). Hierarchical scene un-
derstanding for intelligent vehicles. In Proceedings
of the IEEE International Intelligent Vehicles Sympo-
sium, pages 1142–1147.
Stauffer, C. and Grimson, W. (1999). Adaptive background
mixture model for real-time tracking. In Proceedings
of the IEEE Conference on Computer Vision and Pat-
tern Recognition.
Toyama, K., Krumm, J., Brumitt, B., and Meyers, B.
(1995). Wallflower: Principles and practice of back-
ground maintenance. In Proceedings of the IEEE
International Conference on Computer Vision, vol-
ume 1, pages 255–261.
Travieso, C. M., Dutta, M. K., Sole-Casals, J., and Alonso,
J. B. (2014). Detection and tracking of the human hot
spot. In Proceedings of the International Conference
on Bio-Inspired Systems and Signal Processing, pages
325–330.
Wren, C. R., Azarbayejani, A., Darrell, T., and Pentland,
A. P. (1997). Real-time tracking of the human body.
IEEE Transactions on Pattern Analysis and Machine
Intelligence, 19(7):780–785.
Yao, C., Li, W., and Gao, L. (2009). An efficient mov-
ing object detection algorithm using multi-mask. In
Proceedings of 6th IEEE International Conference on
Fuzzy Systems and Knowledge Discovery, volume 5,
pages 354–358.
Zhou, H. and Kimber, D. (2006). Unusual event detection
via multi-camera video mining. In Proceedings of the
IEEE International Conference on Pattern Recogni-
tion, pages 1161–1166.
Zivkovic, Z. and van der Heijden, F. (2004). Recursive un-
supervised learning of finite mixture models. IEEE
Transactions on Pattern Analysis and Machine Intel-
ligence, 26(5):651–656.
BIOSIGNALS2015-InternationalConferenceonBio-inspiredSystemsandSignalProcessing
384
