
An Adaptive Pre-detection Based RFID Tag Anti-collision Scheme
Chiu-Kuo Liang and Yuan-Cheng Chien
Dept. of Computer Science and Information Engineering, Chung Hua University, Hsinchu, Taiwan, R.O.C.
Keywords: Tag Anti-Collision, Hybrid Query Tree, Pre-Detection Query Tree.
Abstract: One of the research areas in RFID systems is a tag anti-collision protocol; how to reduce identification time
with a given number of tags in the field of an RFID reader. There are two types of tag anti-collision
protocols for RFID systems: tree based algorithms and slotted aloha based algorithms. Many anti-collision
algorithms have been proposed in recent years, especially in tree based protocols. However, there still have
challenges on enhancing the system throughput and stability due to the underlying technologies had faced
different limitation in system performance when network density is high. Particularly, the tree based
protocols had faced the long identification delay. Recently, a Hybrid Hyper Query Tree (H
2
QT) protocol,
which is a tree based approach, was proposed and aiming to speedup tag identification in large scale RFID
systems. The main idea of H
2
QT is to track the tag response and try to predict the distribution of tag IDs in
order to reduce collisions. In this paper, we propose a pre-detection tree based algorithm, called the
Adaptive Pre-Detection Based Query Tree algorithm (APDBQT), to avoid those unnecessary queries. Our
proposed APDBQT protocol can reduce not only the collisions but the idle cycles as well by using pre-
detection mechanism. The simulation results show that our proposed technique provides superior
performance in high density environments. It is shown that the APDBQT is effective in terms of increasing
system throughput and minimizing identification delay.
1 INTRODUCTION
Radio Frequency IDentification (RFID) is an
automatic technology that guarantees to advance
modern industrial practices in object identification
and tracking, asset management, and inventory
control (Vogt, 2002). Recently, several identification
systems such as barcodes and smart cards are
incorporated for automatic identification and data
collection. However, these systems have several
limits in read rate, visibility, and contact. RFID
systems are a matter of great concern because they
provide fast and reliable communication without
requiring physical sight or touching between readers
and tags.
One of the areas of research is the speed with
which a given number of tags in the field of RFID
readers can be identified. For fast tag identification,
anti-collision protocols, which reduce collisions and
identify tags irrespective of occurring collisions, are
required (Vogt, 2002; Myung and Lee, 2005; Myung
et al., 2006; Law et al., 2000; Lee et al., 2005;
Capetanakis, 1979; Zhou et al., 2003). There are two
types of collisions: reader collisions and tag
collisions. Reader collisions indicate that when
neighboring readers inquire a tag concurrently, so
the tag cannot respond its ID to the inquiries of the
readers. These collision problems can be easily
solved by detecting collisions and communicating
with other readers. Tag collisions occur when multi
tags try to respond to a reader simultaneously and
cause the reader to identify no tag. For low-cost
passive RFID tags, there is nothing to do except
response to the inquiry of the reader. Thus, tag anti-
collision protocols are necessary for improving the
cognitive faculty of RFID systems.
In general, the tag anti-collision techniques can
be classified into two categories, aloha-based and
tree-based protocols. Aloha-based approaches use
time slot to reduce collision probability, such as
Framed-Slotted aloha algorithm (Vogt, 2002; Park et
al., 2007), dynamic framed slotted aloha algorithm
(Lee et al., 2005). Tags randomly select a particular
slot in the time frame, load and transmit its
identification to the reader. Once the transmission is
collided, tags will repeatedly send its id in next
interval of time to make sure its id is successfully
recognized. Aloha-based protocols can reduce the
collision probability. However, they have the tag
starvation problem that a particular tag may not be
identified for a long time. For the consideration of
69
Liang C. and Chien Y..
An Adaptive Pre-detection Based RFID Tag Anti-collision Scheme.
DOI: 10.5220/0005268800690076
In Proceedings of the 4th International Conference on Sensor Networks (SENSORNETS-2015), pages 69-76
ISBN: 978-989-758-086-4
Copyright
c
2015 SCITEPRESS (Science and Technology Publications, Lda.)

performance, when number of RFID tag increased,
the tag collision rate will be increased as well; this
may result a low tag recognition rate.
The tree-based schemes use a data structure
similar to a binary search algorithm, such as binary
tree splitting protocol (Myung et al., 2006), query
tree (QT) algorithm, and tree working algorithm
(Capetanakis, 1979; Feng et al., 2006). An RFID
reader consecutively communicates with tags by
sending prefix codes based on the query tree data
structure. Only tags in the reader’s interrogation
zone and of which ID match the prefix respond. The
reader can identify a tag if only one tag respond the
inquiry. Otherwise the tags responses will be
collided if multiple tags respond simultaneously.
Although tree based protocols deliver 100%
guaranteed read rates, but they have relatively long
identification delay. Recently, a hybrid query tree
protocol (HQT) (Ryu et al., 2007) was proposed and
aiming to reduce transmission overhead by using 4-
ary search tree mechanism and slotted backoff
mechanism, in order to speed up tag identification
and to increase the overall read rate and throughput
in large-scale RFID systems. The main idea of the
HQT technique is to reduce the number of collisions
during the identification phase. In the 4-ary search
tree mechanism, the prefix string of a collided query
will be extended by 2-bits next time, unlike of 1-bit
in the QT protocol. This way, collisions can be
reduced substantially. Furthermore, the HQT
protocol was aiming to reduce the idle cycles by
using a slotted backoff mechanism. When a tag
responds to a reader, it sets its backoff timer using a
part of its ID. If there is a collision (multiple tags
respond), the reader can partially deduce how the
IDs of tags are distributed and potentially reduce
unnecessary queries.
Based on the HQT protocol, a H
2
QT protocol
(Kim and Lee, 2009) was proposed and aiming to
reduce the idle cycles and improve the performance
of tag identification. Although the H
2
QT technique
performs better than the HQT technique in reducing
the number of idle cycles, it still has some idle
cycles, which cannot be reduced during the tag
identification process. In this paper, we proposed a
pre-detection based protocol, called Adaptive Pre-
Detection Based Query Tree (APDBQT) protocol, to
eliminate those unnecessary idle cycles. To evaluate
the performance of our proposed technique, we have
implemented our proposed APDBQT scheme along
with previous proposed methods, HQT and H
2
QT
protocols. The experimental results show that the
proposed technique presents significant
improvement in most circumstance.
The remainder of this paper is organized as
follows: Related work is discussed in Section II. In
Section III, the tree based tag identification
algorithm is introduced as preliminary of this study.
In Section IV, our proposed algorithm, the APDBQT
algorithm is presented. Performance comparisons
and analysis of the proposed technique will be given
in Section V. Finally, in Section VI, some
concluding remarks are made.
2 RELATED WORK
Many research results for collision avoidance have
been presented in literature. The existing tag
identification approaches can be classified into two
main categories, the Aloha-based anti-collision
scheme (Vogt, 2002; Law et al., 2000; Lee et al.,
2005; Park et al., 2007; Klair et al., 2007) and the
tree-based scheme (myung et al., 2006; Capetanakis,
1979; Zhou et al., 2003; Feng et al., 2006). RFID
readers in the former scheme create a frame with a
certain number of time slots, and then add the frame
length into the inquiry message sent to the tags in its
vicinity. Tags response the interrogation based on a
random time slot. Because collisions may happen at
the time slot when two or more tag response
simultaneously, making those tags could not be
recognized. Therefore, the readers have to send
inquiries contiguously until all tags are identified.
As a result, Aloha-based scheme might have long
processing latency in identifying large-scale RFID
systems (Law et al., 2000). In (Vogt, 2002), Vogt et
al. investigated how to recognize multiple RFID tags
within the reader’s interrogation ranges without
knowing the number of tags in advance by using
framed Aloha. A similar research is also presented in
(Zhen et al., 2005) by Zhen et al. In (Klair et al.,
2007), Klair et al. also presented a detailed
analytical methodology and an in-depth qualitative
energy consumption analysis of pure and slotted
Aloha anti-collision protocols. Another anti-collision
algorithm called enhanced dynamic framed slotted
aloha (EDFSA) is proposed in (Lee et al., 2005).
EDFSA estimates the number of unread tags first
and adjusts the number of responding tags or the
frame size to give the optimal system efficiency.
In tree-based scheme, such as ABS (Myung et al.,
2006), Improved Bit-by-bit Binary-Tree (IBBT)
(Choi et al., 2004) and IQT (Sahoo et al., 2006),
RFID readers split the set of tags into two subsets
and labeled them by binary numbers. The reader
repeats such process until each subset has only one
tag. Thus, the reader is able to identify all tags. The
SENSORNETS2015-4thInternationalConferenceonSensorNetworks
70

adaptive memoryless tag anti-collision protocol
proposed by Myung et al. (Myung and Lee, 2005) is
an extended technique based on the query tree
protocol. Choi et al. (Choi et al., 2004) also
proposed the IBBT (Improved Bit-by-bit Binary-
Tree) algorithm in Ubiquitous ID system and
evaluate the performance along three other old
schemes. The IQT protocol (Sahoo et al., 2006) is a
similar work approach by exploiting specific prefix
patterns in the tags to make the entire identification
process. Recently, Zhou et al. (Zhou et al., 2007)
consider the problem of slotted scheduled access of
RFID tags in a multiple reader environment. They
developed centralized algorithms in a slotted time
model to read all the tags. With the fact of NP-hard
(Zhou et al., 2007), they also designed
approximation algorithms for the single channel and
heuristic algorithms for the multiple channel cases.
Although tree based schemes have advantage of
implementation simplicity and better response time
compare with the Aloha based ones, they still have
challenges in decreasing the identification latency.
In this paper, we present an enhanced tree based tag
identification technique aims to coordinate
simultaneous communications in large-scale RFID
systems, to speedup minimize tag identification
latency and to increase the overall read rate and
throughput. Simulation results show that our
proposed technique outperforms previous techniques.
3 TREE BASED
ANTI-COLLISION SCHEMES
In this section, we present two tree-based anti-
collision techniques, namely HQT algorithm (Ryu et
al., 2007), and the H
2
QT algorithm (Kim and Lee,
2009), that are most related to our work.
3.1 Hybrid Query Tree Algorithm
In the environment with high tags density, collision
may happen very frequently while using the query
tree algorithm, and due to that, a lot of query time
will be wasted. By using the 4-ary search query tree
mechanism, HQT can enable the prefix to increase
two bits at a time from 1 bit. In this way, some
collisions occurred in QT protocol can be reduced in
HQT protocol. However, the drawback of the 4-ary
search tree mechanism is the increasing number of
idle cycles. To resolve this problem, HQT protocol
introduces the slotted backoff mechanism. The
slotted backoff mechanism is a technique that makes
tags respond to the transmit prefix after waiting a
certain time, instead of immediately respond. When
a tag responds to a reader, it sets its backoff timer
using a part of its ID. The backoff time of each tag is
determined from the 2-bits, which follow the prefix
of tag ID identical to the query prefix string. For
example, tags do not defer their response if it is ‘00’.
If it is ‘01’, ‘10’, or ‘11’, tags will defer 1, 2, or 3
backoff time slots until they respond to the reader,
respectively. Fig. 1 shows the operation of the
slotted backoff mechanism in HQT algorithm.
Figure 1: The slotted backoff mechanism in HQT.
3.2 Hybrid Hyper Query Tree
Algorithm
The main problem in HQT algorithm is that those
idle cycles between busy slots cannot be reduced. To
resolve the problem, the H
2
QT algorithm uses a
different slotted backoff mechanism. The backoff
time of each tag is determined from the 3-bits, which
follows the prefix of tag ID identical to the prefix.
Unlike the mechanism used in HQT, the H
2
QT
counts the number of ‘1’ in the following 3-bits and
uses this number as the selected time slot for tags to
respond. Fig. 2 shows the tag selecting its response
slot based on tag ID.
Figure 2: H
2
QT algorithm.
Fig. 3 depicts an example of the query tree
structure of identifying 5 tags with 6-bits ID length
using H
2
QT algorithm. The process of the
identification is as follows: First of all, the reader
sends request command with the empty-prefix to the
AnAdaptivePre-detectionBasedRFIDTagAnti-collisionScheme
71

tags. In this case, tags A, C and D will delay one
time slot to respond since the first 3-bits of their tag
IDs contain only one ‘1’, as shown in Fig. 4.
Similarly, tags B and E will delay two time slots to
respond due to the number of ‘1’ in the first 3-bits if
their tag IDs is 2. In this case, since no tag responds
immediately, it means that there is no tag whose first
3-bits of their tag IDs match ‘000’. Therefore, there
is no need for reader to send the prefix string ‘000’.
Similarly, since no tag responds after 3 time slot
delay, the reader does not need to send the prefix
string ‘111’. Therefore, the idle cycles can be
eliminated.
Next, the reader receives tag IDs from tags A, C
and D after one time slot delay. At this moment, the
reader is aware that the pattern of the first 3-bits of
tags A, C and D is ‘X0X’, in which ‘X’ represents a
collision bit. Thus, the reader recognizes that the
first 3-bits of tag A, C and D may be ‘001’ or ‘100’,
which will be added into the queue for re-
transmission. Similarly, the reader is aware that the
bit pattern of the first 3-bits of tags B and E is ‘XX1’
after two time slots delay. Thus, the reader will put
prefix strings ‘011’ and ‘101’ into the queue for re-
transmission.
Next, the reader then sends the request command
with prefix string ‘001’. At this moment, only tag A
responds after 1 time slot delay. In this case, tag A is
identified by the reader. Table 1 summarizes the
detail steps of communication between the reader
and the tags with the example shown in Fig. 3.
Figure 3: An example of H
2
QT algorithm.
Figure 4: The response of tags after reader’s empty prefix
request in Figure 3.
Table 1: Communication steps of Figure 3.
Step
HQT H
2
QT
Broadcast Status
Broadcas
t
Status
1 empty Collision empty Collision
2 00 Identify Tag A 001 Identify Tag A
3 01 Identify Tag B 100 Collision
4 10 Collision 011 Identify Tag B
5 1000 Collision 101 Identify Tag E
6 1001 Idle 100001
Identify Tag C
7 1010 Identify Tag E 100010
Identify Tag D
8 100001 Identify Tag C
9 100010 Identify Tag D
4 THE PROPOSED SCHEME
Recall that, in H
2
QT algorithm, the idle cycles can
be reduced substantially. However, there still have
some collision time slots. As a result, the reader has
to spend more time slots to resolve the collisions.
Due to that, it will take more time to complete the
tag identification process. In this paper, we proposed
a pre-detection scheme to eliminate the collision
time slots and idle cycles.
4.1 Adaptive Pre-Detection based
Query Tree Algorithm
We proposed an APDBQT algorithm, which uses
pre-detection technique to realize the precise
distribution of tag IDs. Once the distribution of tag
IDs has been obtained, the reader broadcasts such
message to tags and each tag is aware of the exact
time slot to response. As a result, tags respond to the
reader in different time slots and collisions can be
avoided. Furthermore, since each tag realizes its
corresponding time slot to respond, no empty time
slot exists.
In our proposed APDBQT algorithm, after the
reader send the request command to tags, the
operations during the tag response period can be
partitioned into three phases: the pre-detection phase,
the broadcasting phase and the tag response phase,
as shown in Fig. 5. The purposes of three phases
design can be explained as follows: In pre-detection
phase, the reader can realize the distribution of tag
IDs by collecting the responses from tags. Then, in
broadcasting phase, the reader will send the
distribution information to tags so that each tag is
aware of the time slot to send its ID to reader.
Finally, in the tag response phase, the responses
from tags are arranged into a sequence of time slots
so that collisions and empty slots can be avoided.
SENSORNETS2015-4thInternationalConferenceonSensorNetworks
72

Figure 5: The tag response cycle of our proposed scheme.
After the reader sends a query string (i.e. a prefix
string) and a parameter m to tags and then waits for
tags to response, in the pre-detection phase, each tag
whose tag ID matches with the prefix string sent
from the reader will respond on the pre-detection
time slot according to its following m-bits of its tag
ID. In order to collect the response information from
tags, we allocate 2
m
short time slots in pre-detection
phase for tags to respond and the time slots can be
numbered as the binary representation of m bits
respectively. Fig. 5 shows an example with m = 2.
Therefore, the pre-detection phase in Fig. 5 consists
of four time slots, namely the ‘00’, ‘01’, ‘10’, and
‘11’ time slots respectively. We also adapt the m-ary
search tree mechanism such that each tag whose tag
ID matches with the prefix string sent from the
reader will respond on the corresponding time slot
depending to its following m-bits of its tag ID. It
should be noticed that, in this phase, each tag
responds a 4-bits random number (RN) to reader
instead of the whole tag ID. The reasons for tags of
using 4-bits random numbers to respond are as
follows: First, it can reduce the time for reader to
realize the distribution of tag IDs, compared with the
response of whole tag IDs. Second, the status of
each time slot can be precisely identified with high
probability. If no tag responds in a time slot, then the
reader can correctly identify such time slot as an idle
cycle, which can be eliminated during the tag
response phase. If only one tag responds, the reader
can also correctly identify such time slot as a
successful cycle. Therefore, the reader will allocate a
time slot to receive the response from that tag in the
tag response phase. If more than one tag responds,
since the tags respond 4-bits random numbers, a
collision cycle can be identified by the reader by
checking the received different random numbers.
Although, there still has some chance for a reader to
receive the same random number from different tags,
however, the probability of successful collision
detection is very high. Therefore, by using our pre-
detection mechanism, the distribution of tag IDs can
be correctly obtained with high accuracy.
Meanwhile, the reader monitors and records the
response status from tags in each time slot during the
pre-detection phase. The reader uses a ‘0’-bit to
represent the time slot when no tag responds or more
than one tag respond. On the other hand, the reader
uses a ‘1’-bit to represent the time slot when only
one tag responds. Therefore, after the pre-detection
phase, the reader can use an m-bits string to
represent the status of 2
m
time slots in the pre-
detection phase. Then, during the broadcasting phase,
the reader broadcasts the m-bits string to tags and by
receiving the binary bit string, each tag can realize
the exact time slot to respond by counting the
number of ‘1’ in the received binary bit string from
the start bit to its corresponding bit. Then, the tag
can respond its tag ID to reader in the tag response
time slot by finding the correct time slot to respond.
For example, in Fig. 5, the tag which responds on
the ‘11’ time slot in the pre-detection phase can
realize that it can only send its tag ID on the third
time slot in the tag response phase since it receives
the binary bit string ‘1101’ sent from the reader and
there are three ‘1’s from the beginning to its
corresponding ‘1’.
After the tag response phase, the reader will re-
calculate the value of m depending on the idle slot
ratio in previous pre-detection phase. The idle slot
ratio is defined as the number of idle time slots to
the total number of time slots in previous pre-
detection phase. Thus, as the idle slot ratio gets high,
meaning that the density of tag distribution gets low
and vice versa. Therefore, the reader may allocate
more time slots in pre-detection phase by letting m
larger in the next cycle of identification when the
reader is aware of that the density of tags is getting
higher. Similarly, the reader may allocate less time
slots in pre-detection phase by letting m smaller in
the next cycle of identification when the reader is
aware of that the density of tags is getting lower.
4.2 An Example
To facilitate the understanding of our proposed
algorithm, an example is given as follows.
Fig. 6 depicts the example of the process of
identifying 9 tags with 6-bits of tag IDs, namely
A:‘000010’, B:‘001001’, C:‘001010’, D:‘011001’,
E:‘100001’, F:‘100010’, G:‘101011’, H:‘110011’,
and I:‘110111’, respectively, by using APDBQT
protocol. The process of identification is as follows:
First of all, the reader sends the request command
with the empty-prefix and m = 2 to the tags. In this
case, all tags respond to this request command and
the time slot for a tag to respond is depending on the
first 2-bits of its tag ID. In this example, tags A, B
and C will respond in ‘00’ time slot, tag D will
respond in ‘01’ time slot, tags E, F, and G will
AnAdaptivePre-detectionBasedRFIDTagAnti-collisionScheme
73
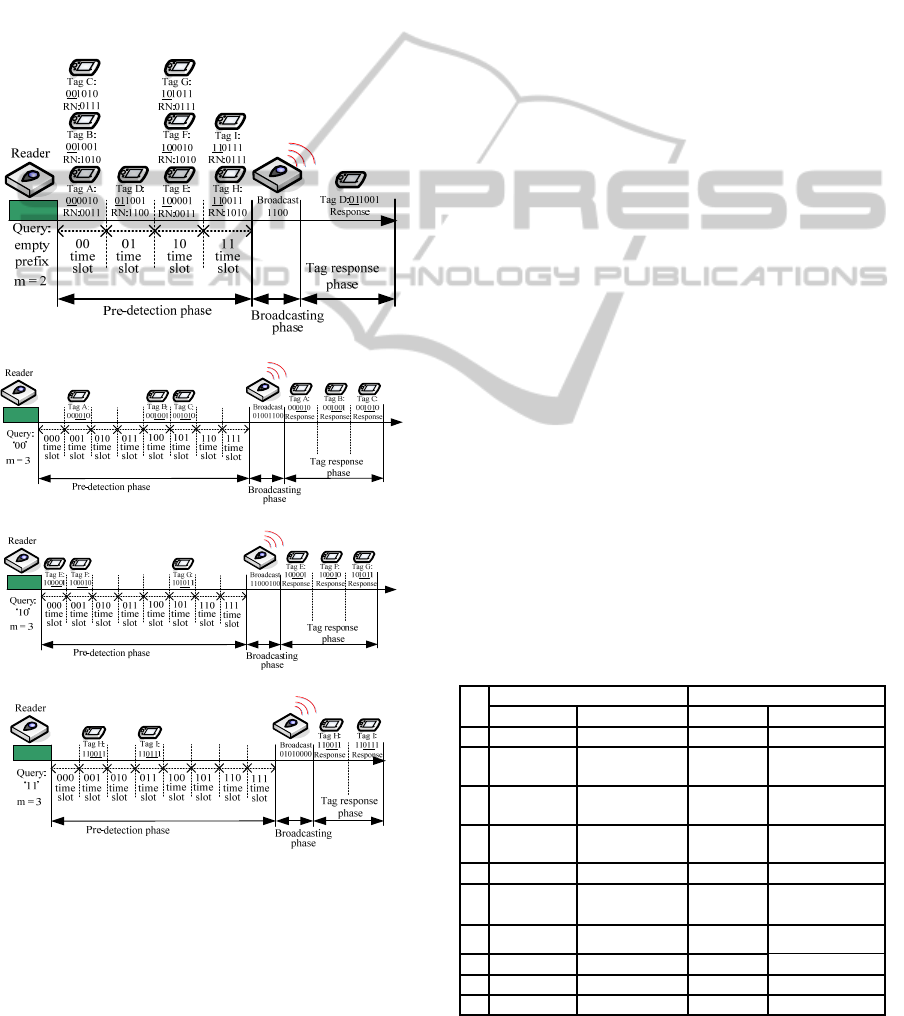
respond in ‘10’ time slot, and tags H and I will
respond in ‘11’ time slot, as shown in Fig. 6(a).
Suppose that the random numbers for tags to
respond are all different. It can easily be seen that,
since there is only one tag response for ‘01’ time slot,
the reader will mark the time slot as ‘1’.
Furthermore, since it has more than one tag
responses in ‘00’, ‘10’, and ‘11’ time slots, the
reader will mark these time slots as ‘0’. It should be
noticed that as the reader realizes that there is no idle
time slot in the pre-detection phase, the value of m
will be increased to 3. Meanwhile, as the reader
(a)
(b)
(c)
(d)
Figure 6: An example pf our APDBQT algorithm.
recognizes the collision time slot, the corresponding
prefix bit string will be added into a queue for
further requesting. In this example, ‘00’, ‘10’ and
‘11’ bit strings will be added into the queue, along
with the value of m. After the pre-detection phase,
the reader will mark all time slots as ‘0100’ and
broadcast it to tags. After tags receive the message,
tag D realizes its own time slot to respond.
Therefore, tag D will be identified. In the meantime,
all other tags recognize that the status of their time
slot is ‘0’, which means that they do not need to
send their tag IDs to reader at that time slot, as
shown in Fig. 6(a). After identifying tag D, the
reader sends another request command and m from
queue, which is the ‘10’ bit string and m = 3 in this
example as shown in Fig. 6(b). In this cycle, tags A,
B and C are identified. In the next round, as shown
in Fig. 6(c), tags E, F, and G can be identified. In the
last round, as shown in Fig. 6(d), tags H and I can be
identified.
4.3 Comparison of Tag Identification
Methods
To facilitate the understanding of the performance of
our proposed algorithm, we compare the
identification process between previous H
2
QT and
our proposed APDBQT algorithms by using the
example in Fig. 6.
Table 2 shows required prefixes and steps for
identifying all 9 tags by using different methods. In
Table 2, the H
2
QT scheme needs 10 steps to
complete the identification process while in our
proposed APDBQT scheme, only 4 steps are needed.
Thus, our proposed APDBQT protocol reduces
identification overhead efficiently and achieves
better performance than H
2
QT scheme.
Table 2: Communication steps of Figure 6.
Step
H
2
QT APDBQT
Broadcast Status Broadcast Status
1 empty Identify Tag A empty Identify Tag D
2 001 Collision 00
Identify Tags A,
B and C
3 100 Collision 10
I
dentify Tags E, F
and G
4 011 Identify Tag D 11
Identify Tags H
and I
5 101 Identify Tag G
6 110
Identify Tags H
and I
7 001001 Identify Tag B
8 001010 Identify Tag C
9 100001 Identify Tag E
10 100010 Identify Tag F
SENSORNETS2015-4thInternationalConferenceonSensorNetworks
74

5 PERFORMANCE
EVALUATION
To evaluate the performance of the proposed
technique, we implemented the APDBQT scheme
along with the HQT algorithm and the H
2
QT
algorithm. In the interrogation zone, we increase the
number of tags from 500 to 4000. All tags are
randomly generated in a uniform distribution
manner. The lengths of the tag IDs used in each
experiment are 96 bits. It should be noticed that
some overhead are not taken into account in our
simulation due to the communication latency and the
propagation delay from the signal processing on the
channel.
Fig. 7 shows the number of queries needed for
reader to complete the tags identification. We can
observe that, as the number of tags increases, each
algorithm increases linearly due to the number of
collision increases. However, our proposed
APDBQT scheme requires less number of queries
compared with other schemes.
Fig. 8 shows the number of idle cycles generated
by each algorithm during the tag identification
process. We can observe that, both H
2
QT and our
proposed APDBQT algorithm can eliminate all idle
cycles regardless the number of tags increases.
Figure 7: No. of queries required to complete
identification.
Figure 8: No. of idle cycles generated by each algorithm.
Fig. 9 shows the number of collisions generated
by each algorithm during the tag identification
process. We can observe that our proposed
APDBQT algorithm generates much fewer collisions
than both HQT and H
2
QT algorithms. Due to the
pre-detection mechanism, most collisions can be
detected in the pre-detection phase, there are only a
few time slots wasted in the tag response phase.
Figure 9: No. of collisions generated by each algorithm.
Figure 10: The time required to complete tag identification.
Fig. 10 shows the total time required for each
algorithm to complete the tag identification process.
We can observe that our proposed APDBQT
algorithm needs less time than both HQT and H
2
QT
algorithms to complete tag identification. Thus, the
APDBQT algorithm outperforms the HQT and
H
2
QT algorithms.
6 CONCLUSIONS
With the emergence of wireless RFID technologies,
identifying high density RFID tags is a crucial task
in developing large scale RFID systems. Due to the
nature of large scale RFID systems, many collisions
may occur during the process of tag identification. In
this paper, we proposed a nearly collision-free tag
identification algorithm to reduce the iteration
AnAdaptivePre-detectionBasedRFIDTagAnti-collisionScheme
75

overhead efficiently. By using the random numbers
for tags to respond in the pre-detection phase, many
unnecessary collided inquiries can be reduced and
the efficiency of tag identification can be
significantly improved. To evaluate the performance
of proposed techniques, we have implemented the
APDBQT technique along with previous HQT and
H
2
QT algorithms. The experimental results show
that the proposed technique provides considerable
improvements on the latency of tag identification. It
is also shown that the APDBQT is effective in terms
of increasing system throughput and efficiency.
REFERENCES
Vogt, H., 2002. Efficient Object Identification with
Passive RFID Tags. In Proc. Inter. Conf. on Pervasive
Computing, Pervasive’ 02. pp. 98-113, London, UK,
2002, Springer-Verlag.
Myung, J., Lee, W., 2005. An adaptive memoryless tag
anticollision protocol for RFID networks. In IEEE
INFOCOM’05, Poster Session.
Myung, J., Lee, W., Srivastava, J., 2006. Adaptive binary
splitting for efficient RFID tag anti-collision. In IEEE
Communication Letter, vol. 10, no. 3, pp. 144–146.
Law, C., Lee, K., Siu, K. Y., 2000. Efficient Memoryless
Protocol for Tag Identification. In proceedings of the
International Workshop on Discrete Algorithms and
Methods for Mobile Computing and Communications.
Lee, S., Joo, S., Lee, C., 2005. An enhanced dynamic
framed slotted ALOHA algorithm for RFID tag
identification. In Proc. MobiQuitous, pp. 166-172.
Capetanakis, J. I., 1979. Tree algorithms for packet
broadcast channels. In IEEE Trans. Information
Theory, vol. 25, pp. 505-515.
Zhou, F., Jin, D., Huang, C., Hao, M., 2003. Optimize the
Power Consumption of Passive Electronic Tags for
Anti-collision Schemes. In Proc. The 5th Inter. Conf.
on ASIC, Vol. 2, pp.1213-1217.
Park, J., Chung, M., Lee, T. J., 2007. Identification of
RFID Tags in Framed-Slotted ALOHA with Robust
Estimation and Binary Selection. In IEEE
Communications Letters, vol. 11, no.5, pp. 452-454.
Feng, B., Tao, L. J., Bo, G. J., Hua, D. Z., 2006. Id-binary
tree stack anti-collision algorithm for RFID. In IEEE
Transactions on Computers, pp. 207–212.
Ryu, J., Lee, H., Seok, Y., Kwon, T., Choi, Y., 2007. A
Hybrid Query Tree Protocol for Tag Collision
Arbitration in RFID systems. In IEEE International
Conference on Communications (ICC-07), pp. 24–28.
Kim, T. H., Lee, S. J., 2009. A Hybrid Hyper Tag Anti-
Collision Algorithm in RFID System. In ICACT, pp.
1276-1281.
Klair, D. K., Chin, K. W., Raad, R., 2007. An
investigation into the energy efficiency of pure and
slotted aloha based RFID anticollision protocols. In
proceedings of the IEEE WoWMoM’07, Finland.
Zhen, B., Kobayashi, M., Shimizui, M., 2005. Framed
aloha for multiple RFID objects Identification. In
IEICE Trans. on Comm, E88-B(3), pp. 991–999.
Choi, H. S., Cha, J. R., Kim, J. H., 2004. Improved Bit-by-
bit Binary Tree Algorithm in Ubiquitous ID System.
In proceedings of the IEEE PCM2004, Tokyo, Japan,
pp. 696–703.
Sahoo, A., Iyer, S., Bhandari, N., 2006. Improving RFID
System to Read Tags Efficiently. In KRSIT Technical
Report.
Zhou, Z., Gupta, H., Das, S. R., Zhu, X., 2007. Slotted
Scheduled Tag Access in Multi-Reader RFID Systems.
In proceedings of the IEEE International Conference
on Networks Protocols (ICNP), pp. 61–70.
SENSORNETS2015-4thInternationalConferenceonSensorNetworks
76
