
Adaptive Kriging for Simulation-based Design under Uncertainty
Development of Metamodels in Augmeted Input Space and Adaptive Tuning of
Their Characteristics
Alexandros A. Taflanidis
1,2
and Juan Camilo Medina
1
1
Department of Aerospace and Mechanical Engineering, University of Notre Dame, Notre Dame, IN, U.S.A
2
Department of Civil and Environmental Engineering & Earth Sciences, University of Notre Dame, Notre Dame, IN, U.S.A
Keywords: Optimization under Uncertainty, Stochastic Simulation, Kriging, Augmented Metamodel Input Space.
Abstract: This investigation focuses on design-under-uncertainty problems that employ a probabilistic performance as
objective function and consider its estimation through stochastic simulation. This approach puts no
constraints on the computational and probability models adopted, but involves a high computational cost
especially for design problems involving complex, high-fidelity numerical models. A framework relying on
kriging metamodeling to approximate the system performance in an augmented input space is considered
here to alleviate this cost. A sub region of the design space is defined and a kriging metamodel is built to
approximate the system response (output) with respect to both the design variables and the uncertain model
parameters (random variables). This metamodel is then used within a stochastic simulation setting
(addressing uncertainties in the model parameters) to approximate the system performance when estimating
the objective function for specific values of the design variables. This information is then used to search for
a local optimum within the previously established design sub domain. Only when the optimization
algorithm drives the search outside this domain, a new metamodel is generated. The process is iterated until
convergence is established and an efficient sharing of information across these iterations is established to
adaptively tune characteristics of the kriging metamodel.
1 INTRODUCTION
In any engineering design application, the
performance predictions for the system under
consideration involve some level of uncertainty,
stemming from the incomplete knowledge about the
system itself and its environment (Schuëller and
Jensen, 2008). Explicitly accounting for these
uncertainties is exceptionally important for
providing optimal configurations that exhibit robust
performance and a probability logic approach
provides a rational and consistent framework for this
task (Jaynes, 2003). In this setting, the objective
function corresponds to the expected value
(probabilistic integral) of some chosen performance
measure over the adopted probability distributions.
For complex systems, this probabilistic integral
can rarely be calculated or accurately approximated
analytically, and stochastic simulation (i.e. Monte
Carlo) based techniques are emerging as a popular
approach due to their general applicability as well
as the possibility of exploiting advances in
parallel/distributed computing (Royset and Polak,
2004, Taflanidis and Beck, 2008). A challenge
related to this approach is, though, the significant
computational cost involved to estimate the
objective function (Spall, 2003).
An alternative framework, relying on surrogate
modeling to approximate the system performance, is
developed here to alleviate this burden. Kriging
(Sacks, 1989, Lophaven, 2002) is utilized as
surrogate model since it has been proven highly
efficient for approximating complex response
functions while simultaneously providing gradient
information. Though, metamodeling approaches for
design optimization under uncertainty are typically
implemented for (i) approximating the objective
function in the design space (Gasser and Schueller,
1997) (metamodel is used to guide optimization) or
for (ii) approximating the system performance for
specific design configurations (Gavin and Yau,
2007) (metamodel is used to calculate the objective
function for these design configurations), a different
approach is investigated here by considering an
785
Taflanidis A. and Medina J..
Adaptive Kriging for Simulation-based Design under Uncertainty - Development of Metamodels in Augmeted Input Space and Adaptive Tuning of Their
Characteristics.
DOI: 10.5220/0005134007850797
In Proceedings of the 4th International Conference on Simulation and Modeling Methodologies, Technologies and Applications (SDDOM-2014), pages
785-797
ISBN: 978-989-758-038-3
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

augmented input space. The approach is similar to
the ideas in (Dubourg et al., 2011), a study that was
constrained, though, to reliability based design
optimization problems and investigated
implementation within the entire design domain
(gradually converging to smaller subsets). Here, a
sub region of the design space is defined and a
kriging metamodel is built to approximate the
system response with respect to both the design
variables and the uncertain model parameters. High-
fidelity model evaluations are obtained at properly
selected support points, and the kriging model is
then developed employing this information. This
metamodel is then used within a stochastic
simulation setting to approximate the system
performance when estimating the objective function
and its gradient for specific values of the design
variables, where the stochastic simulation is
ultimately established with respect to the random
model parameters. This information (i.e. estimate of
objective function and gradient) is then used to
search for a local optimum within the previously
established design sub domain. Only when the
optimization algorithm drives the search outside this
sub domain, a new metamodel is generated, and the
process is iterated until convergence is obtained.
This framework provides great computational
savings, since the high-fidelity model is only utilized
for calculating the response for the chosen support
points (as long as the design choices remain within
the initial sub domain).
Additionally, an adaptive tuning of some
characteristics of the kriging metamodel is
established by sharing information across the
iterations of the numerical optimization. For
selecting the basis functions of the metamodel, a
recently developed probabilistic global sensitivity
analysis (Jia and Taflanidis, 2011) is seamlessly
integrated, quantifying the importance of each model
parameter and design variables towards the overall
probabilistic performance. Higher order basis
functions are assigned to the more important
variables, contributing to increased approximation
accuracy. Furthermore, an hybrid, adaptive sampling
approach is developed for selecting the support
points (design of experiments, DoE), populating
more densely those regions in the random variable
space that have higher contribution to the integrand
quantifying the probabilistic performance. This DoE
leads to a kriging model with enhanced accuracy in
those regions, something that ultimately improves
the accuracy of the objective function estimates. The
overall framework is demonstrated with an example
considering the optimization of semi-active dampers
for a half-car model. Within this example the
influence of explicitly including the kriging
prediction error in the evaluation of the performance
function is investigated.
2 PROBLEM FORMULATION
Consider a system with design vector x=[x
1
x
2
… x
n
x
]
x
n
X
, where X is the admissible design space,
and uncertain model parameters (random variables)
θ=[θ
1
θ
2
… θ
n
θ
]
n
Θ
, where Θ denotes the set
of their possible values. Α Probability Density
Function (PDF) p(θ), which incorporates our
available knowledge about the system is assigned to
these parameters. Let
(,)
z
n
zxθ
be the response
vector of the system model dependent upon both x
as well as θ, and let
(, ):
x
nn
h
x θ
be the
performance function characterizing the favorability
of that response. The probabilistic performance is
then given by the expected value under p(θ)
() (,) ()
Θ
H
hpd
xxθθθ (1)
and corresponds to the objective function for a
robust to uncertainties design. Assuming that lower
values for h(x,θ) correspond to more favorable
performance (i.e. h(x,θ) represents a cost function)
the robust to uncertainties design problem is
*
xargmin ()
X
H
x
x
(2)
where any deterministic constraints have been
incorporated in the definition of the admissible
design space X.
Utilizing stochastic simulation and sample set
{ : 1,..., }
j
jNθ from a proposal density q(θ) the
objective function in Eq. (1) is estimated as
1
1()
ˆ
() (, )
()
j
N
j
j
j
p
Hh
N
q
θ
xxθ
θ
(3)
where the proposal density is chosen to improve the
accuracy of the approximation by concentrating the
computational effort in regions of the model
parameter space that have higher contribution to the
integrand defining the probabilistic performance, an
idea corresponding to the concept of importance
sampling (IS) (Robert and Casella, 2004). The
optimal design in Eq. (2) is then solved by
substituting the approximation of Eq. (3) as the
objective function. This leads to a challenging
SIMULTECH2014-4thInternationalConferenceonSimulationandModelingMethodologies,Technologiesand
Applications
786

simulation-based optimization problem because of
the existence of an unavoidable estimation error, the
high computational cost associated with each
objective function evaluation (requiring N
evaluations of the system model response) and the
inability to obtain gradient information for problem
with complex, black-box models (Taflanidis and
Beck, 2008). This paper considers an approach,
utilizing kriging metamodeling for approximating
the model response, that addresses these problems.
3 DESIGN OPTIMIZATION
THROUGH KRIGING IN
AUGMENTED SPACE
The augmented input space for development of the
kriging metamodel is defined as a tensor product
between the design and uncertain spaces
X Θ
,
whereas to improve accuracy of the metamodel a
smaller set of the design domain is considered
instead of the entire domain, establishing the
iterative approach
1
(|{})
j
kkrigkk
G
xxθ (4)
where the function G
krig
represents the kriging-based
optimization recursive relations and the notation
{}
j
k
θ is used to denote the sample set (in the
stochastic simulation) used within the k
th
iteration.
Note that this sample set will ultimately change from
iteration to iteration so that there is no dependence
of the solution on the sample set used, an approach
corresponding to the concept of exterior sampling
(Spall, 2003). The design sub-domain in the
th
k
iteration, also known as trust region, of the
optimization algorithm will be denoted X
k
herein.
Thus, the input vector
y
for the kriging
metamodel is composed of the design and uncertain
model parameter vectors y=[x θ] whereas the output
vector corresponds to the system response vector
(,)zxθ . Note that the computational complexity of
the performance evaluation model for estimating
(,)h x θ based on (,)zxθ is typically small for most
practical engineering applications. Establishing an
approximation for
(,)zxθ , and then using the actual
performance evaluation model to estimate
(,)h x θ
circumvents one level of approximations and can
ultimately offer significant improvements in
accuracy (Jin et al., 2001). This approach further
allows, as will be demonstrated in the illustrative
example, the explicit consideration of the local
kriging prediction error within the definition of the
performance function.
The kriging model ultimately will provide an
approximation for the response vector
() (,)
zy zxθ , and through this, an approximation
to the performance function is established, denoted
by
() (,)hhyxθ
. Simultaneously, gradient
information can be also obtained for both of these
quantities as will be demonstrated in the next
section. Using this information the numerical
optimization scheme G
krig
can be formulated. In this
step, the objective function and its gradient are
approximated as
() (,) ()
krig
Θ
H
hpd
xxθθθ (5)
() (,) ()
(,) () () (,)
krig
Θ
ΘΘ
Hhpd
hpd phd
xxθθθ
x θθθ θ x θθ
(6)
where for obtaining the second equation we assume
that the functions
(,) ()hpx θθ and
((,)/ )()
i
hxpx θθ
are continuous in the domain
X
and bounded, thus the differentiation and the
expectation operators can commute (Spall, 2003).
These probabilistic integrals can be then evaluated
through stochastic simulation, leading to
1
1()
ˆ
ˆ
() (, )
()
j
N
j
krig
j
j
k
p
Hh
N
q
θ
xxθ
θ
(7)
1
1()
ˆ
ˆ
() (, )
()
j
N
j
krig
j
j
k
p
Hh
N
q
θ
xxθ
θ
(8)
where the notation q
k
(θ) is used herein to represent
the ability to choose the proposal density different at
each iteration of the numerical optimization (more
details on this later). Due to the computational
efficiency of the kriging metamodel a large number
of samples can be utilized within this setting to yield
high accuracy for the stochastic simulation
estimates.
Utilizing this information, especially the gradient
approximation in Eq. (6), an appropriate gradient-
based algorithm is adopted to establish a local search
within X
k
. Two possible outcomes can occur for this
optimization: (i) converge to a local optimum within
k
X
or (ii) reach the boundary of the search domain,
which means that the local search should stop to
AdaptiveKrigingforSimulation-basedDesignunderUncertainty-DevelopmentofMetamodelsinAugmetedInputSpace
andAdaptiveTuningofTheirCharacteristics
787

avoid extrapolations. The latter prompts the
optimization algorithm to advance to the next
iteration x
k+1
, and generate a new kriging model if
the overall optimization has not converged. Note
that the local search optimization identifying the
optimal solution within X
k
has evidently its own
inner iterations, but we are interested here in the
iterations of the exterior optimization algorithm
characterized by Eq. (4).
4 ADAPTIVE KRIGING
4.1 Review of Kriging Metamodeling
For forming the kriging metamodel a database with
n observations is utilized that provides information
for the y-z pair. For this purpose n samples for {y
l
l=1,…,n}, also known as support points, are created
and the model response z(y
l
) is evaluated for each of
them. Using this dataset the kriging model is then
obtained, providing ultimately approximation for
each response quantity
() () ()
iii
zz
yyy
(9)
where
i
z stands for the mean prediction whereas
i
is a Gaussian variable with zero mean and standard
deviation σ
i
(y) (Lophaven, 2002). The fundamental
building blocks of kriging are the n
p
dimensional
basis vector, f(y), and the correlation function
R(y
j
,y
k
). Selection of the former will be discussed
later whereas for the latter the popular generalized
exponential correlation is used
1
1
11
(, ) exp[ | | ]
[ ]
y
n
y
y
n
s
jk j k
ii i
i
n
Rs
ss
yy y y
s
(10)
Then for the set of n observations with input
matrix Y=[y
1
… y
n
]
T
and corresponding output
matrix Z=[z
1
… z
n
]
T
, we define the basis matrix
F=[f(y
1
) … f(y
n
)]
T
and the correlation matrix R
with the jk-element defined as R(y
j
,y
k
), j,k=1, …, n.
Also for every new input y, we define the correlation
vector r(y)=[R(y,y
1
) … R(y,y
n
)]
T
between the input
and each of the elements of Y. The kriging mean
prediction for vector z is given by (Lophaven, 2002)
**
*111*1*
( ) ( ) ( )
() ; ()
TTT
TT
zy fyα ry β
α FR F FR Z β RZFα
(11)
Through the proper tuning of the parameters s of
the correlation function, kriging can efficiently
approximate very complex functions. The optimal
selection of s is based on the Maximum Likelihood
Estimation (MLE) principle, where the likelihood is
defined as the probability of the n observations, and
maximizing this likelihood with respect to s
ultimately corresponds to the optimization problem
1
2
1
arg min
n
n
i
i
s
sR
(12)
where |.| stands for determinant of a matrix and
2
i
,
i = 1,.., n
z
correspond to the diagonal elements of
matrix (Z-Fα
*
)
Τ
R
-1
(Z-Fα
*
). Beyond the mean
kriging predictions the error can be also explicitly
considered in the optimization as will be illustrated
in the example considered later. This requires
estimation of the prediction error variance
2
()
i
y
for
z
i
and input y which is given by
22 11 1
1
() [1 ( ) () ()]
() ()
TT T
ii
T
yuFRFuryRry
uFRry fy
(13)
Gradient information can be also easily derived
by differentiating directly Eqs. (11) and (13) and
noting that vectors α
*
and β
*
are independent of y .
For example, for the mean kriging predictions, and
denoting J
f
and J
r
are the Jacobian matrices with
respect to y of f and r, respectively, this leads to
**
() ()
TT
r
T
f
y α yJJβz
(14)
4.2 Adaptive Formulation
In the proposed framework, a kriging approximation
is developed in the augmented input space by
sharing information across the iterations of the
optimization algorithm described through Eq. (4).
Within such a setting, the focus is on the adaptive
Design of Experiments (DoE) to select the support
points as well as the adaptive selection of the
polynomial order of basis functions.
To formalize these concepts, let x
k
denote the
design variable vector that has been identified at the
end of the
k
th
iteration of the numerical optimization
of Eq. (4). Evaluation of the approximation to the
system performance will be also available for x
k
,
{( , ); 1,..., }
j
k
hjNx θ for the sample set {θ
j
}
k
used
to estimate the objective function through Eq. (7). A
localized box-bounded design sub-domain (trust
region) is then defined
X
k
; this domain is centered
on x
k
and has an appropriate length for each design
variable (defining the length vector L
k
) that
SIMULTECH2014-4thInternationalConferenceonSimulationandModelingMethodologies,Technologiesand
Applications
788

ultimately prescribes the upper and lower bounds for
the design vector
l
k
x and
u
k
x , respectively. Any
appropriate technique may be adopted for selecting
the length vector L
k
(Rodrı
́
guez et al., 2000). A
relevant recommendation for this is that the length is
gradually reduced as iterations progress to regions
closer to a minimum, where one needs higher
accuracy approximations. A kriging metamodel is
then established within sub-domain
X
k
for the
augmented input vector
y and then used within the
optimization given in Eq. (4).
4.2.1 Design of Experiments
Space filling techniques or adaptive design of
experiments (Wang and Shan, 2007, Picheny et al.,
2010) are commonly preferred for the design of
experiments in kriging metamodeling applications.
However, the former may not provide the necessary
accuracy in regions of importance, while the latter
may significantly increase the computational cost for
selecting the support points. Therefore, a hybrid
DoE is proposed in this investigation instead.
Due to their distinct nature, the two different
components of the input vector y have different
characteristics/demands related to their accuracy.
For instance, in the case of x, accurate
approximations are needed within the entire domain
X
k
since the metamodel is ultimately used to
compare different design choices within this entire
domain to converge towards the optimal design
configuration. This indicates that a space filling
technique should be considered and Latin hypercube
sampling (LHS) is adopted here for this purpose.
On the other hand, for θ an accurate
approximation is needed over the domain in the
uncertain model parameters space
Θ that provides
higher contribution towards the integrand in the
evaluation of the objective function. Thus for θ a
target region DoE is needed and an approach with
minimal computational overhead is developed here
for this purpose. The basis of the approach is the
approximation of the target region as the important
region for the integrand of the objective function
through the definition of the auxiliary density
|(,)| ()
( | ) | (,)| ()
ˆ
()
krig
hp
hp
H
x θθ
θ xxθθ
x
(15)
Since this requires knowledge of
h(x,θ) an
approximation is established considering the
density
(|)
θ x , for which h(x,θ) is replaced by the
kriging prediction
(,)h x θ .
The density
(| )
k
θ x may be then taken to
represent the region of importance for the kriging
metamodel to be developed in the next iteration. An
efficient approximation for this density can be
established through sample set, denoted
{}
a
k
θ
, that
can be obtained utilizing the readily available
evaluations of
(,)
j
k
h x θ
for the sample set
{}
j
k
θ
(established in the previous iteration) for the
proposal density used in that iteration
q
k
(θ). Such
samples can be obtained through rejection sampling
by accepting the samples for which the following
relationships holds (Medina and Taflanidis, 2014)
|( , )|( ) |( , )|( )
max
() ()
jj jj
kk
jj j
j
kk
hp hp
uq q
x θθ x θθ
θθ
(16)
where { ; 1,..., }
j
uj N are independent uniformly
distributed random samples in range [0 1]. The
sample set
{}
a
k
θ corresponds to the samples of
{}
j
k
θ for which the above equation holds and
ultimately represents the region in the
Θ space that
contributes more towards the probabilistic
performance for x
k
and as such corresponds to a
good approximation for the target region where
higher accuracy is sought after in the kriging
metamodel. Any sample-based density
approximation approach can be utilized to
approximate the target region utilizing these
samples. This density will be denoted
()
s
k
f θ herein.
Because of the importance of this approximation
and ultimately of the number of samples in the set
{}
a
k
θ
for providing sufficient information for this
approximation, a further modification is introduced
to guarantee that a sufficient number of samples is
available. Upon convergence to x
k
, an additional
sample set, beyond the
N samples in
{}
j
k
θ
, is
generated to obtain a large sample set consisting of
N
p
samples for which
(,)
k
h x θ
is evaluated. The
rejection sampling in Eq. (16) is then performed
over this larger sample set. Given that evaluation of
(,)
k
h x θ
involves a small computational effort this
modification creates a small only additional burden,
but guarantees that sufficient samples will be
obtained to provide a good approximation of
()
s
k
f θ .
Finally it is important to consider that the kriging
metamodel needs to have sufficient accuracy even in
regions beyond this specific target region, since
erroneous approximations in such regions can
AdaptiveKrigingforSimulation-basedDesignunderUncertainty-DevelopmentofMetamodelsinAugmetedInputSpace
andAdaptiveTuningofTheirCharacteristics
789

impact the estimation result (these regions may
become erroneously important because of such
errors). This consideration leads to the following
two stage
hybrid DoE with the first stage aiming to
obtain satisfactory global accuracy in the broader
domain
Θ and the second stage aiming to obtain
higher accuracy in the target region. Initially (first
stage)
1
s
n samples are obtained adopting a space
filling approach (LHS) within the domain of
importance based on
p(θ) (for example 4-5 standard
deviations away from the median values for each
model parameters). Then, additional
2
s
n
are obtained
from the density approximation
()
s
k
f θ . The total
number of support points is, thus,
12
s
s
nn n .
4.2.2 Selection of Basis Functions
Another feature for the kriging approximation is the
selection of basis functions. Typically polynomials
of some lower order are used and then the important
question is the exact polynomial order of the basis
functions for each component of the input vector y.
Selecting the same higher order for all components
might reduce the accuracy of the kriging metamodel;
ultimately components that exhibit higher sensitivity
should have higher order associated with them but
the optimization to identify the best basis function
selection is in general a challenging task (Jia and
Taflanidis, 2013). This challenge is circumvented
here by integrating the global sensitivity analysis
proposed recently by Jia and Taflanidis (2011), and
selecting second order polynomial functions only for
the most important components and linear
polynomial functions for the rest.
For vector
y this sensitivity analysis is
established by considering the density function
() (, ) | (, )| () ()hpp
yxθ x θθx (17)
where
p(x) corresponds to a uniform density in X
k
,
and by comparing this density to the prior joint
distribution
() ()ppθ x for each component of y
separately (comparison of the marginal
distributions). Bigger differences correspond to
higher importance towards the overall probabilistic
performance (Jia and Taflanidis, 2011). This
comparison is efficiently performed utilizing
samples for
π(y); such samples can be readily
obtained
utilizing the support points within X
k
from
the second DoE
stage, using again rejection
sampling. They corresponds to the samples (out of
the larger set of samples utilizing distribution
()
s
k
f θ
for θ) for which the following relationship holds
2
1,...,
|( , )| ( ) |( , )| ( )
max
() ()
j
s
jj j j j
js j s j
jn
kk
hp hp
uf f
x θθ x θθ
θθ
(18)
This approach leads to total of N
s
samples,
denoted
{ }
i
s
y
for each component of y, and to the
following approximation for marginal distributions
of interest utilizing kernel density approximation
(Jia and Taflanidis, 2011)
=1
11
()=
N
s
s
ii
i
si i
s
yy
yK
Nt t
(19)
where K is a Gaussian kernel and bandwidth t
i
is
given by
1/5
1.06·
s
i
N
with σ
i
corresponding to the
standard deviation of the samples
{}
s
i
y
.
The importance of the different model
parameters (Jia and Taflanidis, 2011) is quantified
based on the relative entropy of the marginal
distributions, which utilizing the kernel density
approximation can be calculated as
()
()||() ()log
()
ui
li
i
b
i
ii
i
b
i
Dp dy
y
yy y
yp
(20)
where b
ui
and b
li
are the upper and lower bounds,
respectively, for the sample set
{ }
i
s
y
and the
integral in this equation can be readily obtained
through one-dimensional numerical integration.
A threshold
min
re
D can be then set to determine
the importance of the input vector components. Only
if the value of relative entropy is larger than this
threshold, then that particular parameter will be
assigned a higher order basis function. This
threshold is adaptively selected to correspond to a
fraction of the highest relative entropy value. If the
allowable percentage reduction of the maximum
entropy among the entire input vector is
re
e
s
, then
min
max ( ) || ( )
re re
eii
i
Ds Dypy
(21)
and this formulation ultimately leads to
consideration of higher order basis functions for
parameters that correspond to relative entropy values
higher or equal to
re
e
s
of the maximum entropy over
the entire input vector.
SIMULTECH2014-4thInternationalConferenceonSimulationandModelingMethodologies,Technologiesand
Applications
790
4.3 Optimization under Uncertainty
with Adaptive Kriging
4.3.1 Considerations for Implementation
Across Iterations
For the proposed implementation of kriging across
the iterations of the numerical optimization the
following questions need to still be answered: (a)
How is the IS density q
k
(θ) for the estimations in
Eqs. (7) and (8) established? (b) How is convergence
evaluated? (c) What are the recommendations for the
selection of the length vector
k
L defining the trust
region?
Starting with the IS density, this density may be
selected based on the information from the sample
set
{}
a
k
θ from distribution π(θ|x
k
) which
corresponds actually to the optimal IS density for
design configuration x
k
(Robert and Casella, 2004).
The density π(θ|x
k
) is expected to provide a
satisfactory accuracy for the entire domain X
k
if, as
discussed previously, x
k
provides an adequate
representation about the behavior of the integrand
for different design configurations within X
k
. Recall
that exploiting the efficiency of the kriging
metamodel, a large number of samples N can be
used in this case for the stochastic-simulation-based
evaluation of the objective function and its gradient,
described in Eqs. (7) and (8), respectively. As such,
no special attention needs to be placed on a highly
efficient IS formulation; improvement in accuracy is
primarily sought after by adopting a larger number
of N, though considerable advantages are also
expected from the IS implementation. For example,
a simple parametric density approximation can be
implemented, although more advanced approaches
have been also recently proposed (Medina and
Taflanidis, 2014).
Moving now to the convergence of the
algorithm, this is established when the new
identified optimum
k
x
is a local optimum of the
trust region X
k
. To further improve the quality of the
obtained solution, a second optimization stage is
proposed: upon convergence, the number of support
points is increased to establish a higher accuracy
kriging metamodel and the optimization described
by Eq. (4) is repeated. This allows the use of smaller
number of support points
12
s
s
nn n in the initial
iterations, until convergence is established.
Ultimately we are not concerned with obtaining high
accuracy estimates for the kriging metamodel at the
initial iterations; establishing an approximate
descend direction in the design domain towards the
optimal design is sufficient (greedy optimization
approach).
Finally, with respect to the length vector
selection L
k
, initially it can be considered as a
specific fraction
1
l
s
of the design domain
X
, i.e.
11
l
s
XL . At each iteration a specific reduction,
r
s
, of this proportionality can be implemented
leading to selection
1
1
()
lrkl
k
s
ss
and
l
kk
s
XL
.
Upon initial convergence, a further reduction by
r
f
s
can be established to localize the search around the
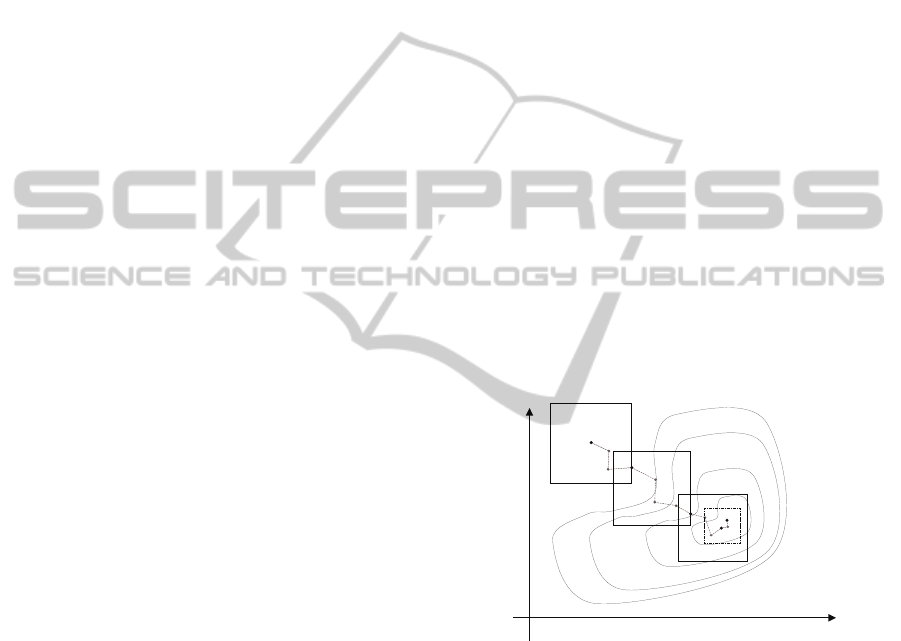
candidate optimum. Figure 1 provides an example of
how the algorithm progresses through the design
space. The squares are the trust regions
X
k
for each
iteration. The gray dots show the intermediate steps
needed to find a local optimum within the trust
region (only using evaluations of the kriging model).
The dash-dot line shows the second stage of the
optimization that starts when the first stage has
encountered an interior point local optimum. This
stage has a significantly more reduced length and the
number of support points within the domain is
increased in order to improve the accuracy of the
kriging model near the optimum point.
x
1
x
2
x
1
x
2
x
3
x
*
x
4
Figure 1: Evolution of trust region.
4.3.2 Algorithm for Adaptive Kriging
Implementation
When combining the previous ideas, one can
formulate the following optimization algorithm
utilizing adaptive kriging. First, define the bounded
design space
X, the starting point of the algorithm x
1
,
the number of support points for the hybrid DoE
approach,
1
s
n and
2
s
n , respectively, as well as the
respective numbers when the second optimization
stage (convergence) has been reached,
1
f
n and
2
f
n .
Select the number of samples
N for the estimation of
the objective function and its gradient utilizing
AdaptiveKrigingforSimulation-basedDesignunderUncertainty-DevelopmentofMetamodelsinAugmetedInputSpace
andAdaptiveTuningofTheirCharacteristics
791

stochastic simulation, the number of samples
N
p
for
which
(,)
k
h x θ
will be obtained, the allowable
percentage entropy reduction for the basis function
formulation
1
re
e
s . Finally choose the fraction
parameter
1
l
s
defining the initial trust region as well
as its reduction
r
s
per iteration and the final
reduction upon convergence
r
f
s
.
At iteration
k
of the numerical optimization
algorithm [Eq. (4)] perform the following steps:
Step 1 (trust region definition): Define box-
bounded search domain
X
k
centered around x
k
with
length vector given by
1
1
()
rk l
k
s
sX
L
. If
convergence has been established (last iteration)
further reduce length vector by
r
f
s
. Adjust (truncate)
trust region if it exceeds the design domain bounds
X.
Step 2 (support points): Employing the hybrid
DoE for θ, obtain
1
s
n (
1
f
n if convergence has been
established) samples using a space filling approach
(LHS) in the region of importance for
p(θ), then
obtain
2
s
n (
2
f
n if convergence has been established)
samples from density
()
s
k
f θ [p(θ) in first iteration].
For
x obtain
12
s
s
nn n
(
12
f
f
nn n
if
convergence has been established) samples using a
space filling approach (LHS) in
k
X
.
Step 3 (Evaluation of model response). For all
the support points evaluate the model response
{z(x
j
,θ
j
); j=1,…,n} and ultimately the system
performance function {
h(x
j
,θ
j
); j=1,…,n}.
Step 4 (Selection of basis functions): Based on
the evaluations on the performance function on the
support points from the second stage
{
h(x
j
,θ
j
);j=1,…,
2
s
n }, obtain samples from (,)
x θ
through rejection sampling as in Eq. (18). Then
calculate the entropy for each component of the
output vector
D(π(y
i
)||p(y
i
)) using the approximation
in Eq. (20) obtained through these samples. Consider
higher order (quadratic) basis functions only for
components of the input vector with relative entropy
higher than the value given by Eq. (21) and lower
order (linear) basis functions for the rest.
Step 5 (kriging model): employing the
information in steps 1-4, build the kriging model in
augmented input space through the approach
discussed in Section 4.1.
Step 6 (trust region local optimum): Simulate set
of
N samples from distribution q
k
(θ) [p(θ) in first
iteration] and perform optimization described by Eq.
(4) utilizing estimations in Eqs. (7) and (8),
employing a gradient based algorithm. Identify local
optimum
k
x
.
Step 7 (information for x
k+1
and proposal density
formulation for DoE); consider
1 kk
xx
and
evaluate the response and the performance function
through the kriging approximation for
p
N samples.
Obtain sample set
1
{}
a
k
θ through Eq. (16) and
establish
1
()
s
k
f
θ .
Step 8 (IS proposal density for iteration
1k
):
Utilizing the same sample set
1
{}
a
k
θ formulate the
IS proposal density
1
()
k
q
θ .
Step 9 (convergence check); if x
k+1
is on the
boundary of
X
k
then convergence has not been
established and proceed back to Step 1 and advance
to
k+1. If not, then convergence has been potentially
attained and the second optimization stage needs to
be implemented by repeating steps 1-6 with
12
f
f
nn n
and
r
f
s
.
5 ILLUSTRATIVE EXAMPLE
The framework is illustrated next in an example
considering the optimization of semi-active dampers
for the suspension of a half-car nonlinear model
riding on a rough road. The excitation (rough road)
is modelled as a stochastic process (Verros et al.,
2005) and the ride comfort and damper fatigue are
considered as performance objectives, both
estimated through their root mean square (RMS)
statistics. The models adopted include various
sources of nonlinearities and time-domain
simulation is used to estimate the car response and
ultimately RMS performance.
5.1 Numerical/Probability Model
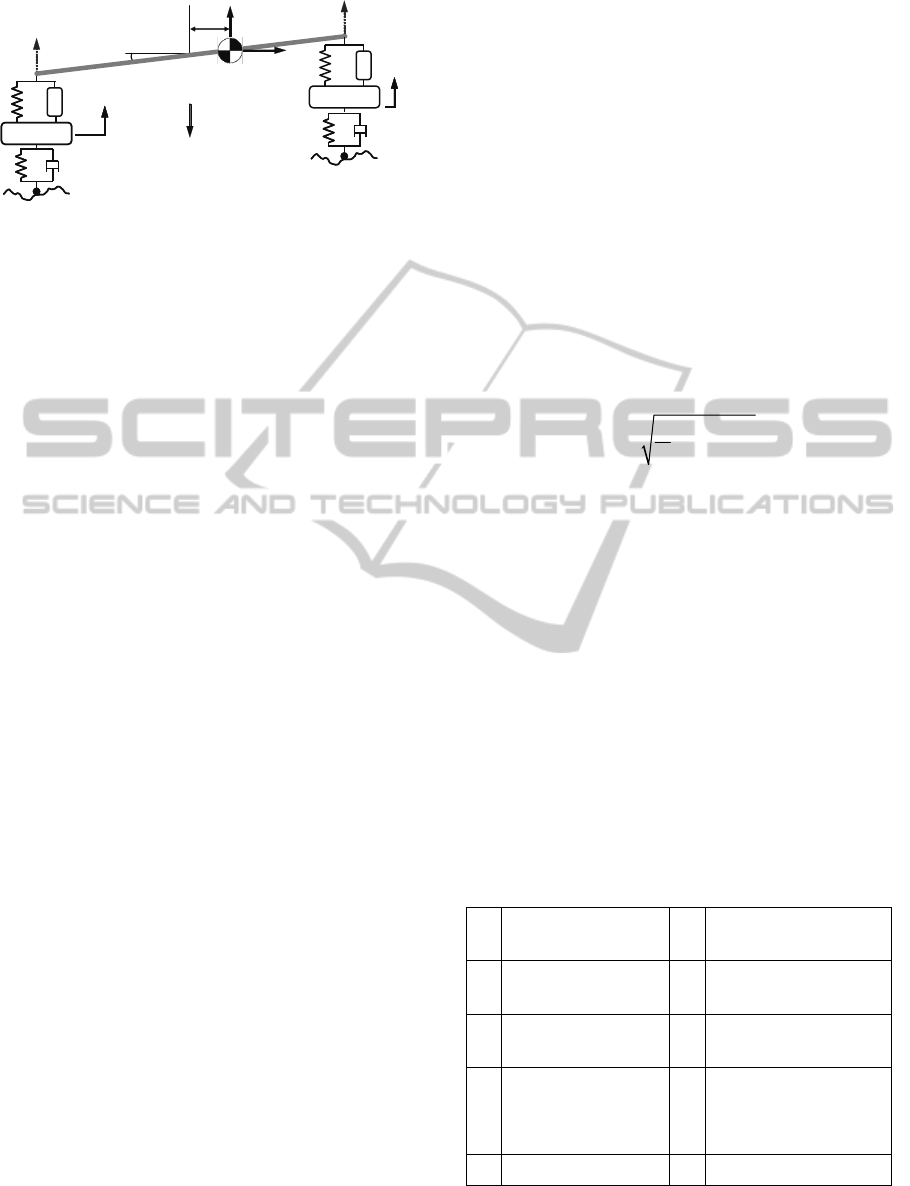
The half-car model is shown in Figure 2. The chassis
is represented as a rigid body connected to the tires
at the ends by a combination of a spring and a
dashpot. Furthermore, the tires are connected to the
ground by another spring/dashpot combination. A
detailed description of the numerical model
considered may be found in (Medina and Taflanidis,
2014). Next a brief review is offered.
SIMULTECH2014-4thInternationalConferenceonSimulationandModelingMethodologies,Technologiesand
Applications
792
cr
y
cf
y
tsf
F
c
y
c
ψ
x
e
c
I
c
m
c
v
tsr
F
tdr
F
tr
m
tr
y
dr
F
sr
F
t
f
y
f
u
r
u
tdf
F
g
tf
m
sf
F
df
F
Figure 2: Half-car model schematic.
The model is developed by using small angle
assumption. In this context, let
y
c
, y
tf
, y
tr
, and ψ
c
denote the vertical displacements of the chassis’
center of mass, the front tire, the rear tire, and the
angular displacement (pitch) of the chassis
respectively. These correspond to the primary state
variables for the system. The vertical displacement
of the front and rear suspensions are denoted by
y
cf
and
y
cr
and can be easily calculated based on the
primary state variables. To simplify notation the
location of a given component is represented herein
by subscript
:{,}ofr (either front or rear). For
example,
y
co
might correspond to any of the y
cr
or y
cf
discussed above.
For the spring,
F
tso
, and damper F
tdo
, tire forces
linear characteristics are assumed with spring
constant
K
to
and dashpot constant C
to
. For the spring
suspension force a linear and nonlinear (cubic term)
component are assumed with spring constants
K
o
l
and
K
o
n
, respectively. The semi-active suspension
damper force is taken to correspond to an idealized
skyhook damper
do so
st
ooot
F
y
CyC
(22)
and all coefficients are taken as design variables,
leading to definition of design variable vector as
x=
[]
tstsT
frrr
CCCC
.
The road surface input
o
u is modeled as a zero-
mean Gaussian stationary stochastic process with the
Power Spectral Density
()S proposed in (Verros
et al., 2005), defined through parameter
κ
i
representing the roughness coefficient whose value
is defined by the International Standard
Organization (ISO). A time-domain realization for
u
f
and
u
r
is obtained by using the spectral
representation method assuming that the car drives
with a constant horizontal velocity
v
c
.
Ultimately the system of equations describing the
half-car dynamical model are
()(1)()(1)0
cc sf df x sr dr x
c c sf df sr dr c
tr tr sr dr tsr tdr tr
tf tf sf df tsf tdf tf
IFFeLFFeL
mmg
mmg
mmg
yF F F F
yFFF F
yFFF F
(23)
where
g denotes gravity acceleration, e
x
is the
eccentricity between the geometric center of the
chassis and its center of mass,
L is the half-distance
between the two suspensions,
m
c
, m
tf
, m
tr
are masses
for the chassis, the front, and rear tires respectively,
and
I
c
is the moment of inertia of the chassis. A
numerical model for this dynamical system is
developed in SIMULINK (Klee and Allen, 2007)
and finally the response statistics (RMS) under the
random road excitation are obtained through the
time-domain simulation results by
2
0
1
()
T
c
RMS c t dt
T
(24)
where
T=L
r
/v
c
and L
r
is the total length of the road
considered. The computational burden for one
simulation, that is one evaluation of the response, is
on the average 3
s on a 3.GHz Xeon CPU (care was
taken to establish a model that balances between
numerical accuracy and efficiency), meaning that an
evaluation of the objective function within a
stochastic simulation setting with
N=600 samples
takes half an hour.
All model parameters apart from
L are
considered as uncertain, leading to θ ultimately
having 15 components, and
Table 1 reviews the
adopted probability models. In this Table
μ
corresponds to median,
cv to coefficient of variation
and
ρ to correlation coefficient.
Table 1: Probability models adopted for the different
model parameters.
m
c
Lognormal
μ=580 kg, cv=0.2
m
tο
Lognormal
μ=40 kg, cv=0.2
I
c
Lognormal
μ=1180 kg m
2
, cv=0.2
v
c
Lognormal
μ=60 km/h, cv=0.2
C
to
Lognormal
μ=20 N s/m, cv=0.2
K
to
Lognormal
μ=190 kN/m, cv=0.2
κ
i
Lognormal
μ=64e-6 m
2
/cycle
cv=0.1
Κ
ο
l
K
o
n
Correlated Lognormal
μ=23.5 kN/m, for K
o
l
μ=435 kN/m
3
, for K
o
n
cv=0.2, ρ=0.4
e
x
Uniform in [0.1 0.4]
L
4m (deterministic)
AdaptiveKrigingforSimulation-basedDesignunderUncertainty-DevelopmentofMetamodelsinAugmetedInputSpace
andAdaptiveTuningofTheirCharacteristics
793

5.2 Performance Quantification and
Adjustment for Kriging Error
The performance measure h(x,θ) is selected as the
normalized linear combination of the fragilities
related to the root mean square of the vertical
acceleration at the center of mass
RMS
ac
, which in
turn is a measure of passenger comfort, and of the
root mean square of the suspension’s damping forces
at the rear and front of the car
RMS
df
, RMS
dr
,
respectively, which is a measure of suspension
fatigue
,,
ln ln
1
(,)
3
ii
bi
iacdfdr
h
RMS b
x θ (25)
where
[.] corresponds to the standard Gaussian
Cumulative Distribution Function (CDF) –
i
b
is the
threshold related to each response quantity of
interest, taken here as 1 m/s
2
for the acceleration,
and 160 N in the damper forces, and
σ
bi
is the
coefficient of variation for the fragilities, assumed as
5% for all of them. The introduction of the fragilities
through the CDF, can be also viewed as addressing
unmodeled uncertainties (Taflanidis and Beck,
2010): rather than having a binary distinction of the
performance, i.e. perform acceptably when the
response is smaller than threshold
b
i
and
unacceptably when not. In this context each quantity
within the sum in Eq. (25) corresponds equivalently
to probability
P[RMS
i
>b
i
ε
i
] with
i
having a
lognormal distribution with median equal to one and
logarithmic standard deviation
σ
bi
. Analytical
integration of the influence of
ε
i
leads ultimately to
the CDF fragility expressions in Eq. (25). The
objective function
H(x) is the average failure
probability over the three different RMS response
quantities and is constrained within the [0 1] range.
The kriging approximation is formulated directly
for the log values of the RMS response, since these
are the ones appearing in the performance function,
thus z(x,θ)=[ln(
RMS
ac
) ln(RMS
df
) ln(RMS
dr
)]
T
.
Furthermore the
prediction error stemming from the
kriging metamodeling may be directly incorporated
into the performance function definition, exploiting
the equivalent representation discussed above. This
is established by considering the following
transformation of the probability
P[RMS
i
>b
i
ε
i
]
22
[ ] [ln( ) ln( ) ln( )]
[ln( ) ln( )]
ln( )
[ln( ) ln( )]
iii i i i
iii i
ii
iii i
ibi
PRMS b P RMS b
Pz b
zb
Pzb
(26)
where
i
z corresponds to the kriging approximation
for ln(
RMS
i
) and the last equality is based on the fact
that since ln(
ε
i
) and
i
are zero mean independent
Gaussian variables with variances,
σ
i
2
and σ
bi
2
,
respectively, their sum (or difference in this case) is
also a Gaussian variable with zero mean and
variance
σ
i
2
+σ
bi
2
. This leads to the following
approximation to the performance function
22
,,
ln( )
1
(,)
3
ii
iacdfdr
ibi
zb
h
θx (27)
The gradient of this expression will be also needed
in the optimization and can be obtained by
22
,,
22
,,
2
2
22
3
23/2
ln( )
1
(,)
3
ln( )
1
3
ln(
)
(
(
))
ii
ibi
ii
g
ibi
i
iacd
ii
i
ibi
fdr
iacdfdr
g
ibi
zb
h
zb
f
zb
f
z
x θ
(28)
where
corresponds to the Gaussian Probability
Density Function (PDF), and evaluation of all
required gradients in the last equation was discussed
in Section 4.
5.3 Numerical Details for Optimization
The design domains X has upper bounds
[400 4000 400 4000] N s/m , and lower bounds
[0000] N s/m. For the trust region definition,
the length of the initial region L
1
is initially selected
as 20% of the design domain
X
, i.e.
1
0.2
l
s with a
reduction in size of 5% with every iteration, i.e.
0.95
r
s . When the optimization has reached the
last stage, the reduction in the trust region is set to
50% or
0.5
r
f
s . For the local search within X
k
a
trust-region-reflective algorithm is adopted. For the
local search an exterior sampling approach is
SIMULTECH2014-4thInternationalConferenceonSimulationandModelingMethodologies,Technologiesand
Applications
794

adopted (same samples are utilized within the trust-
region-reflective algorithm) whereas, as discussed
earlier, the overall implementation is formulated as
interior sampling (different sample set is generated
whenever the algorithm is initiated at the beginning
of each local search/optimization).
The number of support points for the hybrid DoE
approach is selected as
1
200
s
n and
2
700
s
n
whereas the number of support points for the second
optimization stage, for increasing the accuracy of the
kriging approximation, is taken to be double these
values. The number of samples for the estimates in
Eqs. (7) and (8) for the local search is taken as
N=2000 and increased to N=10000 in the second
optimization stage. The total number of simulations
for
(,)
k
h x θ to inform the selection of IS densities
and the sampling density for the second stage of the
DoE approach is set to
N
p
=10000. For the basis
functions selection, the percentage reduction
(defining the cut-off entropy with respect to the
maximum entropy over the entire input vector) is set
to
0.4
re
e
s
.
Apart from the fully adaptive kriging
implementation that additionally incorporates the
kriging error in the objective function formulation,
two additional cases are examined, leading to a total
of three different optimization approaches
considered. The first, denoted AK (adaptive
kriging), and second, denoted AKE (adaptive
kriging with error), correspond to the proposed
algorithm that adaptively employs the probabilistic
sensitivity analysis to select the order of the basis
function for the kriging model, and also adopts the
proposed hybrid DoE. The only difference is that the
first approach does not include the kriging error in
the objective function while the second one does.
The former is established simply by taking
22
0
ii
in Eqs. (27) and (28). The third
approach, denoted LK (Latin Hypercube Kriging),
employs the traditional sampling technique of LHC
for both x and θ, uses quadratic basis functions for
all the parameters of the kriging model, and does not
include the kriging error in the objective function.
This last configuration is the baseline case, where
none of the proposed advances are employed.
To judge the quality of the obtained solutions,
the optimization problem was additionally solved
using the simultaneous perturbation stochastic
approximation algorithm (Spall, 2003) coupled with
the highly efficient adaptive IS formulation
proposed recently by Medina and Taflanidis (2014).
The optimal benchmark solution was found to be
x
*
=[175.2 1645.3 190.1 1495.4] with respective
performance
H(x
*
)=0.066% whereas the total
number of model evaluations needed to converge to
this solution was close to 265000. This large
computational effort should be attributed to the fact
that the performance close to the optimum
corresponds to a rare event (small failure
probability) requiring a large number of samples for
accurate approximation, even with implementation
of an efficient adaptive IS scheme.
5.4 Results and Discussion
Results are reported in Table 2 for five different
trials corresponding to different initial conditions x
1
for the algorithm. In particular, the optimal solution
x
*
, the total number of simulations of the system
high-fidelity model till convergence is established,
N
tot
, the objective function value obtained through
the use of the kriging metamodel,
ˆ
()
krig
H
x
, which
is obtained directly from the optimization algorithm,
as well as the objective function value obtained
through the use of the actual system model,
|
ˆ
({})
c
H
x θ
, are reported. For the latter the same
sample set
{}
c
θ (common random numbers) are
used across all comparisons for each design problem
to enable a consistent comparison (Spall, 2003).
N=10000 samples are used in this comparison which
facilitates a small coefficient of variation for
|
ˆ
({})
c
H
x θ
, close to 4%. A three-fold comparison
can be established based on these results: (i)
Comparison between
ˆ
()
krig
H
x
and
|
ˆ
({})
c
H
x θ
shows the accuracy of the kriging implementation,
(ii) comparison of the
N
tot
for different approaches
shows the computational efficiency for convergence
of the algorithm, (iii) comparison between
|
ˆ
({})
c
H
x θ
and the benchmark optimal solution of
0.0066% shows the robustness of the approach in
converging to the true optimum.
The results for AKE demonstrate a remarkable
computational efficiency and robustness. The
identified solution x
*
is always in the vicinity of the
benchmark optimum solution and, more importantly,
the attained performance is always comparable or
even better than the benchmark performance. This is
accomplished with a small number of model
evaluations, not exceeding 7100 for any trial. Note
that the differences between these trials are well
expected since there is a strong dependence of the
optimization approach on the initial conditions.
Overall the reported efficiency corresponds to
AdaptiveKrigingforSimulation-basedDesignunderUncertainty-DevelopmentofMetamodelsinAugmetedInputSpace
andAdaptiveTuningofTheirCharacteristics
795
tremendous computational savings (265000
simulations needed before), something that is
accomplished primarily through the proposed
formulation of the kriging metamodel in the
augmented input space.
Table 2: Optimization results for different cases
considered and different trials.
Trial x
*
(Nm/s)
tot
N
ˆ
()
krig
H
x
ˆ
({})|
c
H
x θ
AK (adaptive kriging)
1
[122.5 2121.1
142.8 1884.5]
8817 0.025 % 0.079 %
2
[161.3 1484.9
145.7 1725.3]
6607 0.023 % 0.091 %
3
[149.4 1780.3
168.6 1568.5]
12046 0.020 % 0.073 %
4
[125.6 2183.2
113.1 1656.2]
3736 0.020 % 0.113 %
5
[159.1 1541.0
160.2 1532.8]
8698 0.022 % 0.089 %
AKE (adaptive kriging with error)
1
[136.9 2091.9
154.5 1814.3]
5721 0.054 % 0.066 %
2
[159.4 1819
189.8 1521.3]
4751 0.053 % 0.063 %
3
[158.6 1886.3
153.6 1762.9]
5512 0.059 % 0.063 %
4
[173.1 1731.5
147.5 1808.1]
7076 0.045 % 0.064 %
5
[171.3 1847.5
170.1 1708.0]
4703 0.059 % 0.063 %
LK (Latin hypercube kriging)
1
[148.7 2649.4
195.1 1765.9]
19778 0.024 % 0.175 %
2
[220.3 2011.5
84.0 1860.4]
19720 0.182 % 0.279 %
3
[157.5 1838.1
145.3 2400.7]
19153 0.026 % 0.091 %
4
[189.9 1887.6
71.3 2174.7]
18763 0.032 % 0.119 %
5
[136.3 1937
306.3 859.2]
19591 0.119 % 0.191 %
Moving now to the accuracy of the kriging
implementation (still for AKE), assessed through the
comparison between
ˆ
()
krig
H
x
and
|
ˆ
({})
c
H
x θ
,
there is an overall good agreement. When compared
against the accuracy of the kriging implementation
when the prediction error is not included in the
performance function estimate (compare the values
of
ˆ
()
krig
H
x
and
|
ˆ
({})
c
H
x θ
for AK) it is evident
that the explicit consideration of that error provides
significantly improved estimates, i.e., closer values
of
ˆ
()
krig
H
x
and
|
ˆ
({})
c
H
x θ
.
The more interesting comparison is, however,
between AKE and the alternative approaches
(AK/LK) in terms of computational efficiency
(comparison of
N
tot
for same trial) and more
importantly robustness (comparison of
|
ˆ
({})
c
H
x θ
for same trial). In all instances it is shown that the
other two approaches do not share the robustness of
the proposed AKE implementation, as they converge
for some trials to a significantly suboptimal
performance
|
ˆ
({})
c
H
x θ
. The differences are
perhaps more evident for LK and secondary for AK.
This is an important result; it shows that a space-
filling DoE, even though might provide a good
global accuracy, leads to significant errors in regions
of the model parameters that are of importance for
the probabilistic performance and ultimately to
erroneous identified optimal designs. Similarly
ignoring the prediction error, not only decreases the
accuracy of the estimated performance as argued in
the previous paragraph, but, and perhaps more
importantly, can provide erroneous optimal
solutions. Even though calculation of this error does
involve a higher computational burden compared to
using only the mean kriging approximation (Jia and
Taflanidis, 2013), it is evident that its explicit
consideration provides significant enhancements that
counteract this burden.
6 CONCLUSIONS
An adaptive implementation of kriging
metamodeling was considered to reduce the
computational burden associated with optimization
under uncertainty problems adopting a simulation-
driven (stochastic simulation) approach for
evaluation of the objective function. Two important
aspects for tuning of the kriging metamodel were
adaptively addressed within this implementation by
seamlessly sharing information across the iterations
of the numerical optimization: (i) design of
experiments (DoE) for selecting support points
aimed at improving the accuracy over a targeted
region, the one contributing most towards the
probabilistic performance, and (ii) selection of the
order of basis functions for the different inputs of the
metamodel. Additionally, a novel implementation
SIMULTECH2014-4thInternationalConferenceonSimulationandModelingMethodologies,Technologiesand
Applications
796

was introduced formulating the kriging metamodel
in the augmented model parameter and design
variable space whereas the local prediction error
associated with the kriging approximation was
explicitly considered in the objective function
estimation.
The illustrative example showed the
computational efficiency (convergence with small
number of evaluations of the high-fidelity system
model) as well as robustness (convergence to
solutions that are close to the true optimum)
established through the proposed kriging
implementation in the augmented input space. The
proposed hybrid DoE for a targeted region was
additionally shown to greatly enhance the accuracy
of the kriging approximation and its ability to avoid
converging to suboptimal solutions. Finally the
explicit incorporation of the prediction error
improved not only the accuracy of the estimated
objective function through the kriging metamodel
but also similarly supported a more robust
optimization.
ACKNOWLEDGEMENTS
This research effort is supported by the National
Science Foundation (NSF) under Grant No. CBET-
1235768. This support is gratefully acknowledged.
REFERENCES
Dubourg, V., Sudret, B. & Bourinet, J.-M. 2011.
Reliability-based design optimization using kriging
surrogates and subset simulation. Structural and
Multidisciplinary Optimization, 44(5), 673-690.
Gasser, M. & Schueller, G. I. 1997. Reliability-based
optimization of structural systems. Mathematical
Methods of Operations Research, 46, 287-307.
Gavin, H. P. & Yau, S. C. 2007. High-order limit state
functions in the response surface method for structural
reliability analysis. Structural Safety, 30(2), 162-179.
Jaynes, E. T. 2003. Probability Theory: The logic of
science, Cambridge, UK, Cambridge University Press.
Jia, G. & Taflanidis, A. A. 2011 Relative entropy
estimation through stochastic sampling and stochastic
simulation techniques. Second International
Conference on Soft Computing Technology in Civil,
Structural and Environmental Engineering. Chania,
Greece.
Jia, G. & Taflanidis, A. A. 2013. Kriging metamodeling
for approximation of high-dimensional wave and surge
responses in real-time storm/hurricane risk assessment.
Computer Methods in Applied Mechanics and
Engineering, 261-262, 24-38.
Jin, R., Chen, W. & Simpson, T. W. 2001. Comparative
studies of metamodelling techniques under multiple
modelling criteria. Structural and Multidisciplinary
Optimization, 23(1), 1-13.
Klee, H. & Allen, R. 2007. Simulation of dynamic systems
with MATLAB and SIMULINK, Boca Raton, FL,
CRC Press.
Lophaven, S. N., Nielsen, H.B., and Sondergaard, J. 2002
DACE-A MATLAB Kriging Toolbox. Technical
University of Denmark.
Medina, J. C. & Taflanidis, A. 2014. Adaptive importance
sampling for optimization under uncertainty problems.
Computer Methods in Applied Mechanics and
Engineering, (10.1016/j.cma.2014.06.025).
Picheny, V., Ginsbourger, D., Roustant, O., Haftka, R. T.
& Kim, N. H. 2010. Adaptive designs of experiments
for accurate approximation of a target region. Journal
of Mechanical Design, 132(7).
Robert, C. P. & Casella, G. 2004. Monte Carlo statistical
methods, New York, NY, Springer.
Rodrı
́
guez, J. F., Renaud, J. E., Wujek, B. A. & Tappeta,
R. V. 2000. Trust region model management in
multidisciplinary design optimization. Journal of
Computational Applied Mathematics, 124(1), 139-
154.
Royset, J. O. & Polak, E. 2004. Reliability-based optimal
design using sample average approximations.
Probabilistic Engineering Mechanics, 19, 331-343.
Sacks, J., Welch, W.J., Mitchell, T.J., Wynn, H.P. 1989.
Design and analysis of computer experiments.
Statistical Science, 4(4), 409-435.
Schuëller, G. I. & Jensen, H. A. 2008. Computational
methods in optimization considering uncertainties -
An overview. Computer Methods in Applied
Mechanics and Engineering, 198(1), 2-13.
Spall, J. C. 2003. Introduction to stochastic search and
optimization, New York, Wiley-Interscience.
Taflanidis, A. A. & Beck, J. L. 2008. An efficient
framework for optimal robust stochastic system design
using stochastic simulation. Computer Methods in
Applied Mechanics and Engineering, 198(1), 88-101.
Taflanidis, A. A. & Beck, J. L. 2010. Reliability-based
design using two-stage stochastic optimization with a
treatment of model prediction errors. Journal of
Engineering Mechanics, 136(12), 1460-1473.
Verros, C., Natsiavas, S. & Papadimitriou, C. 2005.
Design optimization of quarter-car models with
passive and semi-active suspensions under random
road excitation. Journal of Vibration and Control,
11(5), 581-606.
Wang, G. G. & Shan, S. 2007. Review of metamodeling
techniques in support of engineering design
optimization. Journal of Mechanical Design, 129(4),
370-380.
AdaptiveKrigingforSimulation-basedDesignunderUncertainty-DevelopmentofMetamodelsinAugmetedInputSpace
andAdaptiveTuningofTheirCharacteristics
797
