
Formatting Bits to Better Implement Signal Processing Algorithms
Benoit Lopez
1
, Thibault Hilaire
1
and Laurent-St
´
ephane Didier
2
1
LIP6, Pierre and Marie Curie University (UPMC Univ Paris 06), Paris, France
2
IMATH, University of the South, Toulon-Var (USTV), Toulon, France
Keywords:
Fixed-point Arithmetic, Accurate Sum-of-Products, Bit Formatting, Digital Signal Processing Implementa-
tion.
Abstract:
This article deals with the fixed-point computation of the sum-of-products, necessary for the implementation
of several algorithms, including linear filters. Fixed-point arithmetic implies output errors to be controlled.
So, a new method is proposed to perform accurate computation of the filter and minimize the word-lengths of
the operations. This is done by removing bits from operands that don’t impact the final result under a given
limit. Then, the final output of linear filter is guaranteed to be a faithful rounding of the real output.
1 INTRODUCTION
Usually, embedded digital signal processing algo-
rithms are specified using floating-point arithmetic
and next implemented using fixed-point (FxP) arith-
metic (Padgett and Anderson, 2009) for cost, size and
power consumption reasons. FxP arithmetic is used
as an approximation of real numbers based on inte-
gers and implicit fixed scaling by a power of 2. Of
course, the quantization of coefficients and the round-
ing errors due to FxP computations lead to a degraded
numerical accuracy of the implemented algorithm.
Therefore, it is a great interest for the designer of em-
bedded system to determine and control the imple-
mentation error while maintaining low computational
effort.
In fixed-point arithmetic, a main current prob-
lem is to minimize the word-lengths of operands
under constraints of precision in order to minimize
area and/or power consumption (Constantinides et al.,
2004). In this paper, a new method to reduce the
number of bits to consider in each sum-of-products
(SoP, also called Multiply-And-Accumulate) is pro-
posed. The SoPs are one of the elementary operations
of DSP algorithms. The main point of our approach
is that if the final fixed-point format is known, then
the bits having no impact in the final result can be
detected and therefore discarded. Each term of the
sum-of-products can be then reformatted into a new
fixed-point format having less bits.
Some fixed-point arithmetic definitions and nota-
tions are reminded in section ??. Section 3 formalizes
the proposed approach, which is decomposed into two
formatting, for most significant bits and least signif-
icant bits, respectively. Section 4 describes the error
analysis for Direct Form I filters implemented with
the bit formatting technique. Finally, an illustrative
example is given with a 4
th
order Butterworth filter,
before conclusion in section 6.
2 FIXED-POINT ARITHMETIC
AND SUM-OF-PRODUCTS
In this article we consider signed FxP arithmetic in
two’s complement representation. Let x be such a FxP
number with w bits as word-length:
x = −2
m
x
m
+
m−1
∑
i=`
2
i
x
i
(1)
where x
i
∈ B , {0,1} is the i
th
bit of x, m and ` are the
position of the most significant bit (MSB) and least
significant bits (LSB), respectively (Fig. 1). It can be
noted that m > ` and
w = m − ` +1. (2)
In a digital system, x is represented by an integer X ,
composed by the w bits {x
i
}
`6i6m
. In other words,
X = x.2
−`
, or equivalently
X = −2
m−`
x
m
+
m−`−1
∑
i=0
2
i
x
i+`
. (3)
104
Lopez B., Hilaire T. and Didier L..
Formatting Bits to Better Implement Signal Processing Algorithms.
DOI: 10.5220/0004711201040111
In Proceedings of the 4th International Conference on Pervasive and Embedded Computing and Communication Systems (PECCS-2014), pages
104-111
ISBN: 978-989-758-000-0
Copyright
c
2014 SCITEPRESS (Science and Technology Publications, Lda.)

s
m + 1
−`
w
−2
m
2
0
2
−1
2
m−1
2
`
Figure 1: Fixed-point representation. m and ` are the posi-
tion of the MSB and LSB respectively (in this figure, m = 5
and ` = −4).
Through this paper the notation (m,`) is used to
denote the Fixed-Point Format (FPF) of such a fixed-
point number and m, ` and w will be suffixed by the
variable or constant they refer to.
Remark 1. In FxP arithmetic, there is no restriction
on the the position of the MSB and LSB. The FPF is
often chosen with m > 0 and ` 6 0. FPF with ` > 0
are also possible (the quantization step is greater than
1) or m < 0 (the largest represented number is lower
than
1
2
).
2.1 Conversion from Real to
Fixed-point
Many SoP-based DSP algorithms involve real coeffi-
cients that have to be converted into FxP arithmetic.
Let consider a real constant c ∈ R
∗
. The position of
the most significant bit m of its w-bit wide FxP repre-
sentation in binary two’s complement is:
m =
log
2
|c|
if c < 0
log
2
|c|
+ 1 if c > 0
(4)
where b·cand d·e are the round to the integer towards
minus infinity and round towards plus infinity opera-
tors, respectively.
For some very special cases, eq. (4) should be
adapted (Hilaire and Lopez, 2013). The position of
the least significant bit ` is deduced from eq. (2) and
the w-bit integer C representing c is computed:
C =
j
c.2
`
m
(5)
where b·e is the round to the nearest integer operator.
2.2 Sum-of-Products
In digital signal processing, the computation of fil-
ter or controller algorithms requires the evaluation of
one or several SoP. Their type and number depend on
the algorithm chosen (Hanselmann, 1987; Istepanian
and Whidborne, 2001; Gevers and Li, 1993). For in-
stance, the direct forms require only 1 SoP, whereas
the n-th order state-space require n + 1 SoPs.
The products considered in such a SoP are prod-
ucts of real constants and real variables. But, in the
context of fixed-point design, only fixed-point vari-
ables and fixed-point constants are considered. In this
article, we consider SoPs whose constants have al-
ready been converted in FxP format.
More formally, we consider SoPs
s =
n
∑
i=1
c
i
· v
i
, (6)
where {c
i
}
16i6n
are given non-null FxP constants
and {v
i
}
16i6n
FxP variables only known to be in
known intervals [v
i
;v
i
]. We focus on the best way
(i.e. employing the minimum word-lengths) to obtain
a rounding of the exact sum s at a given format.
Remark 2. It is also possible to consider the {c
i
}
to be real constants instead of FxP constants, so as
to analyze the impact of their quantization that is not
considered here.
However, this impact is well studied with sensitiv-
ity measures such as the transfer function sensitivity
(Tavs¸ano
˘
glu and Thiele, 1984; Gevers and Li, 1993;
Hinamoto et al., 2006), the pole/zero sensitivity (Gev-
ers and Li, 1993; Li, 1998) or IIR stability (Lu and
Hinamoto, 2003).
3 BITS FORMATTING
The main point of the proposed approach is that if the
final fixed-point format of a sum s =
∑
p
i
, denoted
FPF
f
= (m
f
,`
f
) is known, then it is probably possi-
ble to discard some useless bits.
More formally, this paper is focused on bits of p
i
s
with positions lower than `
f
(section 3.2) and greater
than m
f
(section 3.3) in order to determine their im-
pact on the result. We determine the useless bits
and remove them from p
i
s before the sum is com-
puted. The p
i
s are rounded into an intermediate for-
mat (m
i
,`
f
−δ), where δ is the number of non-useless
bits with position lower than `
f
. Then, the sum of
these modified p
i
s is computed and rounded into the
final format FPF
f
in order to obtain the final result
(see Figure 2(b)).
3.1 Definitions and notations
In this section the fixed-point rounding modes used in
this article are defined.
Definition 1 (Fixed-point rounding modes). Let x be
a real value. The notations ◦
d
(x), O
d
(x) and M
d
(x)
express the rounding to the nearest, the rounding
down (i.e. truncation) and the rounding up of x ac-
cording to the d
th
bit, respectively. These operators
FormattingBitstoBetterImplementSignalProcessingAlgorithms
105

s
s
s
s
s
s
s
s
s
s
f
(a) The exact sum is performed and then rounded to
(m
f
,`
f
)
s
s
s
s
s
s
δ
s
s
δ
s
s
0
f
(b) The sum is performed on the format (m
f
,`
f
+δ) and
then rounded to (m
f
,`
f
)
Figure 2: Two different ways to perform the FxP accumulation.
are defined by:
◦
d
(x) , 2
d
·
j
x
2
d
m
, (7)
O
d
(x) , 2
d
·
j
x
2
d
k
, (8)
M
d
(x) , 2
d
·
l
x
2
d
m
. (9)
The operator ?
d
(x) is the faithful rounding of x at
the d
th
bit, i.e.
?
d
(x) ∈ {O
d
(x),M
d
(x)}. (10)
The round-to-the-nearest operation always returns
the nearest representable point of the real exact value,
while the faithful rounding operation produces either
the nearest or next-nearest point.
Notations. Some notations need to be explicitly de-
fined before explaining the proposed approach:
• p
i
, c
i
× v
i
denotes the result of the fixed-point
product of c
i
and v
i
. According to the fixed-point
multiplication rule (Lopez et al., 2012), the fixed-
point format of p
i
is defined as FPF
p
i
, (m
i
,`
i
) =
(m
c
i
+ m
v
i
+ 1,`
c
i
+ `
v
i
).
• p
i, j
is the j
th
bit of p
i
, for 1 6 i 6 n and `
i
6 j 6
m
i
.
• (M,L) is the FPF of the exact sum s =
n
∑
i=1
p
i
,
where
M , max
i
(m
p
i
) +
log
2
(n)
(11)
and
L , min
i
(`
p
i
). (12)
log
2
(n)
corresponds to the number of carry bits
to consider for the sum of n terms.
Moreover, three different sums are also considered,
where
d
is a given common rounding mode (round-
to-nearest or truncate):
d
∈ {◦
d
,O
d
}:
• s
f
,
`
f
(s) is the rounding of the exact sum s into
the final format FPF
f
.
• s
δ
,
n
∑
i=1
`
f
−δ
(p
i
) is the sum of the products p
i
s
rounded into format (m
i
,`
f
−δ) where δ is a given
positive constant to be discussed later.
• s
0
f
,
`
f
(s
δ
) is the rounding of the sum s
δ
into the
final format FPF
f
.
Figures 2(a) and 2(b) illustrate these different approx-
imation of the sum s.
Modular fixed-point sum. As reminded in equa-
tion (3), a fixed-point number x is coded in computer
with a w-bit signed integer X. As a consequence, all
the operations are done modulo 2
w
on this integer.
Proposition 1 specifies the modular fixed-point sum
as an extension of the modular sum on integers.
Proposition 1 (Modular fixed-point sum). The sum
modulo 2
d
of two fixed-point numbers x and y sharing
the same FPF (m,`), is noted x
d
⊕ y and is computed
as:
x
d
⊕y ,
(X +Y + 2
d−`
) mod 2
d−`+1
− 2
d−`
2
`
.
(13)
Moreover, the modular fixed-point sum of n fixed-
point numbers x
i
is noted and computed as:
d
M
16i6n
x
i
, x
1
d
⊕ x
2
d
⊕ ...
d
⊕ x
n
. (14)
Proof: The fixed-point sum modulo d, x
d
⊕ y, corre-
sponds to the d − `-bits sum of the integers X = x.2
−`
and Y = y.2
−`
.
Therefore, adding two signed fixed-point num-
bers requires to convert them in positive integers, add
them modulo 2
d−`+1
, and convert the result back into
signed fixed-point number.
PECCS2014-InternationalConferenceonPervasiveandEmbeddedComputingandCommunicationSystems
106

Example 1. Adding 12.5 and 3.75 in FPF (4,−3)
(two’s complement with 8 bits) is given by 12.5
4
⊕3.75
and leads to −15.75 according to eq. (13) because of
the overflow. 12.5 is coded by 01100.100
B
, 3.75 is
coded by 00011.110
B
, so the modular sum leads to
10000.010
B
into format (4,−3), that is interpreted as
−15.75.
3.2 LSBs Formatting
Let consider the final FxP format (m
f
,`
f
) of a SoP. It
appears that not all the least significant bits are use-
full in order to correctly round the result of a SoP to
(m
f
,`
f
). The value δ is the position such that all bits
with a position lower than `
f
− δ are insignificant and
can be removed from p
i
s (Fig. 2(b)). Therefore, only
p
i
s such that `
i
< `
f
−δ are rounded, the other remain
unchanged. The sum s
δ
of rounded p
i
s is computed
on format (m
f
,`
f
− δ) and finally rounded onto the
final format (m
f
,`
f
).
The following proposition formalizes the choice
of δ.
Proposition 2. For both rounding mode (
l
f
= ◦
l
f
round-to-nearest or
l
f
= O
l
f
truncation), the integer
δ that provides s
0
f
= ?
l
f
(s
f
) is given by:
δ = dlog
2
(n
f
)e (15)
with n
f
= Card(I
f
) and I
f
, {i | `
i
< `
f
}.
Proof: This proof is done for truncation round-
ing mode.The same reasoning can be established for
round-to-nearest mode.
Computation of s involves all bits p
i, j
whereas s
δ
requires only bits p
i, j
for j > 2
l
f
−δ
, so:
s > s
δ
(16)
The trivial case s = s
δ
implies s
f
= s
0
f
, so there-
after only the case s − s
δ
> 0 is considered and the
difference s − s
δ
is evaluated precisely as the sum of
bits p
i, j
for 1 6 i 6 n and L 6 j 6 `
f
− δ − 1:
s − s
δ
=
n
∑
i=1
`
f
−δ−1
∑
j=L
2
j
p
i, j
(17)
Since
∑
`
f
−δ−1
j=L
2
j
p
i, j
< 2
`
f
−δ
for 1 6 i 6 n, s − s
δ
can be bounded as follows:
s − s
δ
< n
f
· 2
`
f
−δ
(18)
Now, the difference s
f
− s
0
f
corresponds to the
rounding of the difference s − s
δ
according to the `
f
th
bit:
s
f
− s
0
f
= O
`
f
(s − s
δ
) (19)
It also can be viewed as the carry bits greater than 2
`
f
implied by the difference s − s
δ
.
Using equation (18), the difference s
f
− s
0
f
can
also be bounded:
b(s − s
δ
) · 2
−`
f
c 6 (s − s
δ
) · 2
−`
f
< n
f
· 2
−δ
(20)
s
f
− s
0
f
< n
f
· 2
`
f
−δ
(21)
Since δ needs to be determined in order to verify
|s
f
− s
0
f
| 6 2
`
f
, the following inequality comes from
equation (21):
n
f
· 2
`
f
−δ
6 2
`
f
(22)
The smallest integer solving inequality (22) is δ =
dlog
2
(n
f
)e.
Remark 3. With Proposition 2, it may happened that
one p
i
(or more) has a MSB lesser than `
f
− δ, and
so all bits of this p
i
will be removed by applying this
technique. Therefore, a good idea will be to redeter-
mine δ with n
f
minus the number of removed p
i
. So
equation (15) can be replaced by Algorithm 1.
Algorithm 1: Evaluation of the integer δ.
Input: Operands p
i
s in format (m
i
,`
i
)
The final format FPF
f
= (m
f
,`
f
)
Output: δ ∈ N
1 n
δ
← n;
2 repeat
3 n
0
← n
δ
;
4 δ ← dlog
2
(n
0
)e;
5 n
δ
← Card({i | 1 6 i 6 n and m
i
< `
f
−δ});
6 until n
0
= n
δ
;
7 return δ
Formating method. The first step of LSB format-
ting is a direct application of proposition 2: it removes
useless bits. After this step `
i
> `
f
− δ,∀1 6 i 6 n.
The second step involves having `
i
= `
f
− δ,∀1 6
i 6 n. To do this, either FPF
p
i
can be changed from
(m
i
,`
i
) to (m
i
,`
f
− δ) for p
i
s such that `
i
> `
f
− δ
(consisting to add `
i
−`
f
+δ zeros to the right of these
p
i
s), or multipliers can be rewritten to perform opera-
tion into a given word-length. Let M
i
be the multiplier
computing p
i
= c
i
×v
i
. Then, w
M
i
, the word-length of
the result of M
i
is given by:
w
M
i
= m
M
i
+ `
M
i
+ 1 (23)
with
m
M
i
= m
c
i
+ m
v
i
+ 1 (24)
`
M
i
= `
f
− δ (25)
where m
c
i
and m
v
i
are MSBs of c
i
and v
i
respectively.
FormattingBitstoBetterImplementSignalProcessingAlgorithms
107

Remark 4. For a better accuracy, m
M
i
can be evalu-
ated using formulas from section 2.1, it avoids double
sign bit in general case (given by the +1 in eq. (24)).
Moreover, if `
c
i
+ `
v
i
> `
M
i
, then `
c
i
+ `
v
i
− `
M
i
zeros
are added to the right of p
i
s to ensure `
i
= `
f
− δ for
these p
i
s.
Error evaluation. Adding two numbers in FxP
arithmetic requires to align them onto the same LSB
using right-shifts. A rounding error may occur, which
introduces a numerical error. After the second step of
LSB formatting, where rounding errors may be intro-
duced, all p
i
s have the same LSB, i.e. `
f
− δ. There
is no need of right-shift to align operands of additions
and therefore no additional rounding errors are intro-
duced by the global sum of p
i
s.
The total number of right-shifts involved in the
first step of our method can be bounded as follows.
Proposition 3. With this LSB formatting technique
and for a n
th
-order SoP, the number of right-shifts is
bounded by n + 1, at most one right-shift by multi-
plier (denoted d
i
for multiplier M
i
) and exactly one
final right-shift (denoted d
f
). Their values are:
d
i
, `
f
− δ − `
c
i
− `
v
i
∀i ∈ I (26)
and
d
f
, δ (27)
where I = {i | 1 6 i 6 n and `
f
− δ > `
c
i
+ `
v
i
}.
Proof: d
i
is the right-shift in multiplier M
i
if a right-
shift is necessary, i.e. if `
f
− δ > `
c
i
+ `
v
i
so the
number of bits to remove to ensure `
i
= `
f
− δ is
`
f
− δ − `
c
i
− `
v
i
. All the additions are computed on
w
f
+ δ bits, and the result is w
f
bits long, so the final
right-shift value is δ.
Remark 5. In Proposition 3 only non-zero right-
shifts are considered. If d
i
is defined as max(`
f
−
δ − `
c
i
− `
v
i
,0) rather than just `
f
− δ − `
c
i
− `
v
i
, all
multipliers have a right-shift, possibly null, and so the
exact number of right-shifts is n + 1.
Finally, it is possible to bound the error introduced
by our method. As seen in (Hilaire and Lopez, 2013),
the right shifting of d bits of a variable x (with (m,`)
as FPF) is equivalent to add an interval error [e] =
[e;e] with
Truncation Round to the nearest
[e,e] [−2
`+d
+ 2
`
;0] [−2
`+d−1
+ 2
`
;2
`+d−1
]
(28)
So the global interval error for the LSB technique can
be evaluated with the following properties.
Proposition 4. The global interval error using LSB
formatting technique is [e] = [e; e] with:
Truncation:
e =
∑
i∈I
(−2
`
i
+d
i
+ 2
`
i
) − 2
`
f
+ 2
`
f
−δ
(29)
e = 0 (30)
Round to nearest:
e =
∑
i∈I
(−2
`
i
+d
i
−1
+ 2
`
i
) − 2
`
f
−1
+ 2
`
f
−δ
(31)
e =
∑
i∈I
(2
`
i
+d
i
−1
) + 2
`
f
−1
(32)
with I = {i | 1 6 i 6 n and `
f
−δ > `
c
i
+`
v
i
} and `
i
=
`
c
i
+ `
v
i
, where `
c
i
and `
v
i
are positions of LSBs of c
i
and v
i
respectively.
Proof: By using (28) on a multiplier i, e equals to
−2
`
i
+d
i
−1
+ 2
`
i
where d
i
is the right-shift value given
by Proposition 3 and p
i
is the initial LSB of the mul-
tiplier result, i.e. the optimal LSB which is the sum
of LSBs of product operands c
i
and v
i
. For the final
right-shift, the initial LSB equals to `
f
− δ and the fi-
nal result is δ bits right-shifted.
Remark 6. The precise bounds of the global inter-
val error shown in Proposition 4 can be bounded by
a power of 2. Indeed, for truncation rounding mode
the global interval error is included in ] − 2
`
f
+1
;0],
whereas for round-to-nearest rounding mode it is in-
cluded in ] − 2
`
f
;2
`
f
[.
In (Lopez et al., 2012), all p
i
s have different LSBs,
and therefore the global error depends on the order of
the additions. Consequently, all the different evalua-
tion schemes (ES), i.e. all the different possible orders
of the additions, are generated and the choice is made
meanly for ES with a minimal error. Here, all ES have
the same global error value (Proposition 4), so error
can not be a criteria to choose the best ES representing
the sum. The criteria chosen in the section 5 is the in-
finite parallelism criteria, i.e. the most parallelizable
ES.
3.3 MSBs Formatting
The MSBs of p
i
s having a greater positions than the
final MSB, m
f
can be removed using a new formal-
ization of the Jackson’s Rule (Jackson, 1970). This
Rule states that in consecutive additions and/or sub-
tractions in two’s complement arithmetic, some inter-
mediate results and operands may overflow. As long
as the final result representation can handle the final
result without overflow, then the result is valid.
Example 2. Let us consider a sum S of three 8-bit in-
tegers with two’s complement arithmetic, for example
104 + 82 − 94. The result S = 92 is in the range of 8-
bit signed numbers, but the intermediate sum 104+82
PECCS2014-InternationalConferenceonPervasiveandEmbeddedComputingandCommunicationSystems
108

produces an overflow and equals to −70 into this for-
mat (instead of 186 that cannot be represented). The
final sum −70 − 94 also produces an overflow and
equals to 92 into the final format, that is the correct
result.
With this paper’s notations, it means that bits with
a greater position than m
f
can be removed from con-
cerned p
i
s.
Proposition 5 (Fixed-Point Jackson’s Rule). Let s be
a sum of n fixed-point number p
i
s, in format (M,L).
If s is known to have a final MSB equals to m
f
with
m
f
< M, then:
s =
m
f
+1
M
16i6n
m
f
∑
j=L
2
j
p
i, j
!
(33)
Proof: s =
∑
n
i=1
p
i
, so, from (1):
s =
n
∑
i=1
−2
M
p
i,M
+
M−1
∑
j=L
2
j
p
i, j
!
(34)
All bits of s greater than 2
m
f
(from p
i, j
with j > m
f
+
1 and from the carry bits produced by p
i, j
with j <
m
f
+ 1) are repetitions of the sign bits, since −2
m
f
6
s < 2
m
f
(by definition of the final FPF). Therefore, s
can be only computed with p
i, j
with j < m
f
+1 in the
format FPF
f
.
Thus, in our method, the MSB formatting is an
application of the propostion to a sum s
δ
previously
LSB-formatted p
i
s, i.e. with L = `
f
− δ. Therefore,
s
δ
can be computed only using bits p
i, j
with 1 6 i 6
n, `
f
− δ 6 j 6 m
f
without considering intermediate
overflows.
4 OUTPUT ERROR ANALYSIS
Let us consider a n-th order IIR
1
filter having H as a
transfer function:
H(z) =
b
0
+ b
1
z
−1
+ ··· + b
n
z
−n
1 + a
1
z
−1
+ ··· + a
n
z
−n
, ∀z ∈ C. (35)
This filter is usually realized with the following
algorithm
y(k) =
n
∑
i=0
b
i
u(k − i) −
n
∑
i=1
a
i
y(k − i) (36)
where u(k) is the input at step k and y(k) the output at
step k.
So the evaluation of the filter relies on the evalua-
tion of a SoP. As seen in previous sections, the fixed-
point evaluation of eq. (36) implies the add of an error
1
Infinite Impulse Response
+
H
H
e
u(k)
e(k)
∆y(k)
y
†
(k)
y(k)
Figure 3: Equivalent system, with output error extracted.
e(k) at time k, and only y
†
(the output contaminated
with roundoff error) can be computed:
y
†
(k) =
n
∑
i=0
b
i
u(k − i) −
n
∑
i=1
a
i
y
†
(k − i) + e(k). (37)
In (Lopez et al., 2012), it has been shown that the
implemented system eq. (37) can be seen as the ini-
tial system (36) with an error added on the output, as
shown in Figure 3: by subtracting equations (37) and
(36), it comes
y
†
(k) − y(k) = e(k)−
n
∑
i=1
a
i
y
†
(k − i) − y(k − i)
(38)
So the output error ∆y(k) , y
†
(k) − y(k) can be seen
as the result of the error e(k) through the filter H
e
de-
fined by
H
e
(z) =
1
1 + a
1
z
−1
+ ··· + a
n
z
−n
, ∀z ∈ C. (39)
Since the error e(k) done in the evaluation of the
SoP is known to be in a given interval [e;e] (see
Proposition 4), then the following proposition (Hilaire
and Lopez, 2013) gives the output error interval:
Proposition 6 (Output error interval). ∆y(k) is the
output of the error e(k) through the filter H
e
. If the
error e(k) is in [e; e], then ∆y(k) is in [∆y; ∆y] with:
∆y =
e + e
2
|
H
e
|
DC
−
e − e
2
k
H
e
k
`
∞
(40)
∆y =
e + e
2
|
H
e
|
DC
+
e − e
2
k
H
e
k
`
∞
(41)
and
|
H
e
|
DC
is the DC-gain (low-frequency gain) of H
e
and
k
H
e
k
`
∞
its worst-case peak gain:
k
H
e
k
`
∞
,
sup
k>0
|y(k)|
sup
k>0
|u(k)|
∀u and y input and output of H
e
.
(42)
They can be computed by:
|
H
e
|
DC
= H
e
(1),
k
H
e
k
`
∞
=
∑
k>0
|h
e
(k)| (43)
where h
e
(k) is impulse response of the filter H
e
.
Proof: Since H
e
is linear, ∆y(k) can be seen as the
sum of a constant term
e+e
2
through the filter H
e
and
a variable term bounded by
e−e
2
. The constant term is
amplified by the low-frequency gain
|
H
e
|
DC
, whereas
the bound of the variable term is amplified by
k
H
e
k
`
∞
(eq. (42)).
FormattingBitstoBetterImplementSignalProcessingAlgorithms
109

s
p
6
s
p
7
s
p
8
s
p
9
s
p
3
s
p
2
s
p
4
s
p
1
s
p
5
s
s
δ
2
= 0
δ
3
= dlog
2
(n
f
)e
δ
1
= min
i
(`
i
)
Figure 4: Bits representation of the sum of the example.
5 RESULTS AND COMPARISONS
A 4-th order Butterworth filter is used as an illustra-
tive example. The chosen realization to compute this
filter is the Direct Form I:
y(k) =
4
∑
i=0
b
i
u(k − i) −
4
∑
i=1
a
i
y(k − i). (44)
Its coefficients a
i
s and b
i
s are given by the Matlab
command butter(4,0.136):
b
0
= 0.001328017792779
a
1
= −2.871116228316502 b
1
= 0.005312071171115
a
2
= 3.208250066295749 b
2
= 0.007968106756673
a
3
= −1.634594881084453 b
3
= 0.005312071171115
a
4
= 0.318709327789667 b
4
= 0.001328017792779
For implementations, the output variables y(i)s,
input variables u(i)s, constants a
i
s and b
i
s are 16-bit
words.
Moreover, variables u(i)s are consid-
ered in this example to be in the interval
[−13;13] (the corresponding FPF is (4,−11)),
and variables y(i)s (including result out-
put y(k)) are known to be in the interval
[−17.123541221107534;17.123541221107534]
(corresponding to the final FPF (m
f
,`
f
) = (5,−10)).
From these informations, the operands to be
summed, p
i
s, can be obtained with their respective
FPF:
p
i
,
b
i−1
u(k − (i − 1)) if 1 6 i 6 5
a
i−5
y(k − (i − 5)) if 6 6 i 6 9
FPF
p
1
= (−4, −35)
FPF
p
2
= (−2, −33) FPF
p
6
= (8, −23)
FPF
p
3
= (−1, −32) FPF
p
7
= (8, −23)
FPF
p
4
= (−2, −33) FPF
p
8
= (7, −24)
FPF
p
5
= (−4, −35) FPF
p
9
= (5, −26)
Four implementations are compared: a double
precision implementation and three fixed-point imple-
mentations using bit formatting approach using dif-
ferent values of δ. In the first FxP implementation
(denoted Fix
1
), all bits are considered. This means
that δ
1
is chosen such that `
f
− δ
1
= min
i
(`
i
). In other
word, we have δ
1
= `
f
− min
i
(`
i
) = 25. The Fix
1
im-
plementation corresponds to the computation of the
sum s with no LSB formatting.
In the second FxP implementation Fix
2
, no addi-
tional bits are considered. The intermediate format
is the final format, (m
f
,`
f
), which corresponds to
δ
2
= 0. A large LSB reduction is performed.
The third FxP implementation Fix
3
is the faithful
implementation, with δ
3
determined from Proposition
2, i.e. δ
3
= dlog
2
(n
f
)e with n
f
= n = 9, so δ
3
= 4.
Only 4 guards bits are used in the LSB formatting.
Figure 4 illustrates this example. For Fix
1
, since
the intermediate format is (5,−35), additional bits
equal to 0 are considered to align all p
i
s onto this
format. For Fix
2
and Fix
3
, the intermediate formats,
(5,−10) and (5,−14) respectively, permit to remove
bits, blue and green hatched bits and blue hatched
bits respectively. Finally, the intermediate sums are
rounded to the final format (5,−10), except s
δ
2
which
is already in the final format.
The global interval error [e;e] is computed, for the
implementation Fix
3
, using Proposition 4 :
e = −1.4645302 × 10
−3
, e = 0. (45)
From equation (43), DC-gain and worst-case peak
gain of H
e
are obtained :
|
H
e
|
DC
= 49.5647,
k
H
e
k
`
∞
= 66.8474. (46)
Finally, the output error interval (Proposition 6)
[∆y;∆y] is computed from equations (45) and (46) :
∆y = −8.52445240×10
−2
, ∆y = 1.26555189×10
−2
.
(47)
As illustration (but not proof), of the theoretical
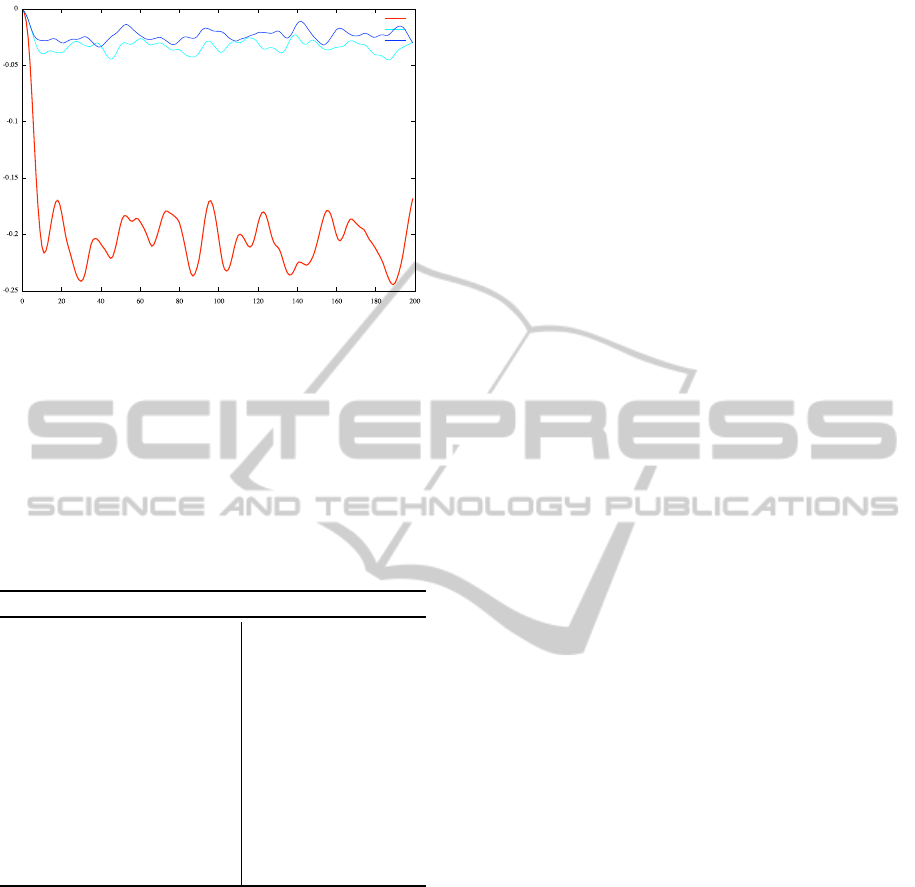
result (46), a simulation in FxP and floating point
arithmetic has been done with a white noise input u(k)
in [−13; 13]. The error between the double floating re-
sult and each of the FxP implementations is shown in
Figure 5.
The number of additional bits considered in Fix
3
is small compared with Fix
1
which considers all bits,
PECCS2014-InternationalConferenceonPervasiveandEmbeddedComputingandCommunicationSystems
110
Fix
3
Fix
2
Fix
1
Figure 5: Computed error between double implementation
and the three different fixed-point implementations.
but it is good enough to have errors measures far bet-
ter than Fix
2
and really close to Fix
1
. The plotted er-
ror for implementation Fix
3
is in the bound predicted
by the theory.
The fixed-point implementation Fix
3
is given by
algorithm 2. In this implementation, sum modulo
2
m
f
+1
(i.e. 2
6
) is performed, but since algorithm
considers integer computations, the sum is performed
modulo 2
m
f
+1−`
f
+δ
(i.e. 2
20
).
Algorithm 2: Fixed-point algorithm.
Input:
U0 to U4: 16-bit input (4, −11)
Y 1 to Y 4: 16-bit input (5,−10)
Output: Y : 16-bit output (5,−10)
Data: Rx: 20-bit registers
⊕: the 20-bit sum
R0 ← (23520 ∗Y1) 9;
R1 ← (−26282 ∗Y2) 9;
R2 ← R0 ⊕ R1;
R0 ← (22280 ∗U0) 21;
R1 ← R0 ⊕ R2;
R0 ← (22280 ∗U3) 19;
R2 ← (−20887 ∗Y4) 12;
R3 ← R0 ⊕ R2;
R0 ← R1 ⊕ R3;
R1 ← (22280 ∗U4) 21;
R2 ← (26781 ∗Y3) 10;
R3 ← R1 ⊕ R2;
R1 ← (16710 ∗U2) 18;
R2 ← R3 ⊕ R1;
R1 ← (22280 ∗U1) 19;
R3 ← R2 ⊕ R1;
R1 ← R0 ⊕ R3;
// Output computation
Y ← R1 4;
6 CONCLUSIONS
Throughout this paper, a new method of formatting
bits has been described, in order to design fixed-point
sum-of-products and then linear filters. This method
allows to remove some bits and keep only the bits that
impact the final result. The computed result is a faith-
ful rounding of the final result considering all the bits.
The example has shown the utility of applying this
method to a linear filter expressed in a very common
form, and the gain in term of number of bits is signif-
icant.
Future work will consist of a word-length opti-
mization step that will consider the bit formatting
method, and a code generation for algorithm-to-code
mapping.
ACKNOWLEDGEMENTS
This work has been sponsored by french ANR agency
under grant No ANR-11-INSE-008.
The authors would like to thank Florent de
Dinechin for the instructive discussions about fixed-
point implementation.
REFERENCES
Constantinides, G., Cheung, P., and Luk, W. (2004). Syn-
thesis and Optimization of DSP Algorithms. Kluwer
Academic Publishers.
Gevers, M. and Li, G. (1993). Parametrizations in Control,
Estimation and Filtering Probems. Springer-Verlag.
Hanselmann, H. (1987). Implementation of digital con-
trollers - a survey. Automatica, 23(1):7–32.
Hilaire, T. and Lopez, B. (2013). Reliable implementation
of linear filters with fixed-point arithmetic. In Proc.
IEEE Workshop on Signal Processing Systems (SiPS).
Hinamoto, T., Omoifo, O., and Lu, W.-S. (2006). L2-
sensitivity minimization for mimo linear discrete-time
systems subject to l2-scaling constraints. In Proc. IS-
CCSP 2006.
Istepanian, R. and Whidborne, J., editors (2001). Digital
Controller implementation and fragility. Springer.
Jackson, L. (1970). Roundoff-noise analysis for fixed-
point digital filters realized in cascade or parallel form.
Audio and Electroacoustics, IEEE Transactions on,
18(2):107–122.
Li, G. (1998). On the structure of digital controllers with
finite word length consideration. IEEE Trans. on Au-
tom. Control, 43(5):689–693.
Lopez, B., Hilaire, T., and Didier, L.-S. (2012). Sum-of-
products Evaluation Schemes with Fixed-Point arith-
metic, and their application to IIR filter implementa-
tion. In Conference on Design and Architectures for
Signal and Image Processing (DASIP).
Lu, W.-S. and Hinamoto, T. (2003). Optimal design of
iir digital filters with robust stability using conic-
quadratic-programming updates. In IEEE Trans. Sig-
nal Processing, volume 51, pages 1581–1592.
Padgett, W. T. and Anderson, D. V. (2009). Fixed-point
signal processing. Synthesis Lectures on Signal Pro-
cessing, 4(1):1–133.
Tavs¸ano
˘
glu, V. and Thiele, L. (1984). Optimal design of
state-space digital filters by simultaneous minimiza-
tion of sensibility and roundoff noise. In IEEE Trans.
on Acoustics, Speech and Signal Processing, volume
CAS-31.
FormattingBitstoBetterImplementSignalProcessingAlgorithms
111
