
Using Domain Knowledge in Association Rules Mining
Case Study
Jan Rauch and Milan
ˇ
Sim
˚
unek
Faculty of Informatics and Statistics, University of Economics, Prague, Czech Republic
Keywords:
Data Mining, Domain Knowledge, Association Rules, Patterns of Domain Knowledge, Logic of Association
Rules.
Abstract:
A case study concerning an approach to application of domain knowledge in association rule mining is pre-
sented. Association rules are understood as general relations of two general Boolean attributes derived from
columns of an analysed data matrix. Interesting items of domain knowledge are expressed in an intuitive form
distinct from association rules. Each particular pattern of domain knowledge is mapped onto a set of all as-
sociation rules which can be considered as its consequences. These sets are used when interpreting results of
data mining procedure. Deduction rules concerning association rules are applied.
1 INTRODUCTION
An approach to dealing with domain knowledge in
association rules data mining is sketched in (Rauch
and
ˇ
Sim
˚
unek, 2011). Association rules of the form
ϕ ≈ ψ are used. Here ϕ and ψ are general Boolean
attributes derived from columns of an analysed data
matrix. Symbol ≈ is a 4ft-quantifier, it corresponds to
a condition concerning a contingency table of ϕ and
ψ (Rauch, 2013).
Boolean attributes ϕ and ψ are built from basic
Boolean attributes of the form A(α) where A is an at-
tribute i.e. a column of a data matrix with possible
values a
1
, . . . , a
t
and α ⊂ {a
1
, . . . , a
t
}. Basic Boolean
attribute A(α) is true in row o of an analysed data ma-
trix if it holds A(o) ∈ α i.e. if the value A(o) of the
attribute A in row o belongs to the set α.
We use the 4ft-Miner procedure (Rauch, 2013;
Rauch and
ˇ
Sim
˚
unek, 2005) which mines for such as-
sociation rules. The 4ft-Miner procedure is an en-
hanced implementation of the ASSOC procedure in-
troduced in (H
´
ajek and Havr
´
anek, 1978). Its imple-
mentation is based on dealing with suitable strings of
bits making possible to easy deal with basic Boolean
attributes A(α). We do not use the a-priori algorithm
(Agrawal et al., 1996).
We deal with SI-formulas expressing mutual influ-
ence of attributes. The expression BMI ↑↑ Diastolic
is an example of SI-formula. It concerns attributes
BMI i.e. body mass index and Diastolic i.e. diastolic
blood pressure. Its meaning is: if BMI increases then
diastolic blood pressure increases as well.
For each SI-formula Ω and 4ft-quantifier ≈ a set
Cons(Ω, ≈) of association rules ϕ ≈
0
ψ which can be
considered as consequences of Ω is defined. This set
is then used when interpreting results of the 4ft-Miner
procedure. Deduction rules rules of the form
ϕ≈ψ
ϕ
0
≈ψ
0
where both ϕ ≈ ψ and ϕ
0
≈ ψ
0
are association rules
play an important role. If the deduction rule
ϕ≈ψ
ϕ
0
≈ψ
0
is correct and the association rule ϕ ≈ ψ is true in a
given data matrix M , then the association rule
ϕ
0
≈ ψ
0
is also true in M . These deduction rules are
studied in (Rauch, 2013) in details together with addi-
tional features of special logical calculi of association
rules.
An application of this approach for SI-formula
BMI ↑↑ Diastolic is outlined in (Rauch and
ˇ
Sim
˚
unek,
2011). The goal of the paper is to present this ap-
proach for additional SI-formulas in details. The goal
of this paper is not to get new medical knowledge,
the goal is to present new possibilities of dealing
with domain knowledge in association rules data min-
ing. Well known items of domain knowledge together
with freely downloadable medical data set are used to
achieve this goal.
No similar approach based on domain knowledge
and logical calculi of association rules is known to
the authors. However, various alternative approaches
are published e.g. in (Delgado et al., 2001; Delgado
et al., 2011; Brossette et al., 1998; Ordonez et al.,
2006; Roddick et al., 2003). Their detailed compari-
son with the approach presented here is beyond of the
scope of this paper and it is left as a further work.
The STULONG medical data set is introduced
in section 2 together with related items of domain
knowledge. An analytical question concerning this
104
Rauch J. and Šim˚unek M..
Using Domain Knowledge in Association Rules Mining - Case Study.
DOI: 10.5220/0004539101040111
In Proceedings of the International Conference on Knowledge Discovery and Information Retrieval and the International Conference on Knowledge
Management and Information Sharing (KDIR-2013), pages 104-111
ISBN: 978-989-8565-75-4
Copyright
c
2013 SCITEPRESS (Science and Technology Publications, Lda.)

data set and related items of domain knowledge is
presented in section 3. Applications of the 4ft-Miner
procedure relevant to this analytical question are de-
scribed in section 4. Sets of association rules which
can be considered as consequences of items of do-
main knowledge in question are introduced in section
5. These sets are used to interpret results of the 4ft-
Miner procedure, see section 6. Results related to an
additional analytical question are shortly presented in
section 7. Concluding remarks are in section 8.
2 STULONG DATA SET
2.1 Data Matrix Entry
We use data set STULONG concerning Longitu-
dinal Study of Atherosclerosis Risk Factors, see
http://euromise.vse.cz/challenge2004/. Data set con-
sists of four data matrices, we deal with data ma-
trix Entry only. It concerns 1 417 patients – men
that have been examined at the beginning of the
study. Each row of data matrix describes one patient.
Data matrix has 64 columns corresponding to partic-
ular attributes – characteristics of patients. The at-
tributes can be divided into various groups, see e.g.
http://euromise.vse.cz/challenge2004/data/entry/.
We use four groups defined for this paper – So-
cial + BMI, Vices, Problems, and Examinations. The
groups are introduced in Tab. 1 together with at-
tributes belonging to particular groups. Let us note:
names of categories are followed by the frequen-
cies of particular categories, married /1207 means that
there are 1207 married patients in the data matrix En-
try. Frequencies of categories of the attribute BMI
are in Fig. 1. Frequencies of categories of the at-
tribute Cholesterol are distributed similarly. There
are missing values in the data matrix Entry, thus the
sum of frequencies of all particular categories of some
attributes can be less 1417. Names of some cate-
gories are abbreviated, we use manager instead of
managerial worker, etc., see http:// euromise.vse.cz/
challenge2004/ data/ entry/ social.html#zodpov. Tric
means Skinfold above musculus triceps (mm) and
Subsc means skinfold above musculus subscapularis
(mm).
Figure 1: Frequencies of categories of BMI.
Table 1: Group of attributes and attributes.
Group of attributes
Attribute Categories
Social + BMI
M Status married /1207, divorced/104
single/95, widover/10
Education basic/151, apprentice/405
secondary/444, university/397
Responsibility manager/286, independent /435
others/636, pensioner/25
BMI < 22, 22, . . . , 32, > 32
13 categories frequencies see Fig. 1
Vices (given amount/day)
Beer (litres) not/465, ≤ 1/777, > 1/157
Vine (litres) not /675, ≤ 0.5/689, > 0.5/36
Liquers (cc) not/759, ≤ 100/574, > 100/76
Smoking not/383, 1-4 /45, 5-14 /206
(cigarettes) 15-20/391, 21+/346, pipe/29
Coffee (cups) not/488, 1-2 /45, 3+/643
Problems
Hypertension yes/220, no/1192
Infarction yes/34, no/1378
Diabetes yes/30, no/1378
Hyperlipidemia yes/54, no/815
Examinations
Tric (in cm) h0; 5i/176, (5; 10i/667,
(10;15i/303, (15; 20i/92,
(20;40i/43
Subsc (in cm) h0;10i/130, (10; 15i/323,
(15;20i/399, (20; 25i/189,
(25;30i/118, (30; 55i/121
Cholesterol (in mg%) h100;160), h160; 180), . . .
(10 categories) . . . , h300; 320), h320; 540)
2.2 Mutual Influence of Attributes
There are various items of domain knowledge con-
cerning mutual influence of attributes and related to
the STULONG data set. We use several of them, they
correspond to the following SI-formulas.
SI-formula BMI ↑
+
Hypertension(yes) means: if
BMI increases, then the relative frequency of Hyper-
tension(yes) increases as well. Here BMI is a general
ordinal attribute, the attribute BMI i.e. a column of
data matrix Entry is an example of an instance of the
general ordinal attribute BMI. Similarly, Hyperten-
sion(yes) is a general Boolean attribute, the attribute
Hypertension(yes) is its instance. This approach can
be described formally, SI-formulas can be understood
as an enhancement of a logical calculus of association
rules (Rauch, 2011). We use a less formal approach
here.
We assume that BMI ↑
+
Hypertension(yes) is
an approved and generally accepted medical knowl-
edge. There are additional and similar SI-
formulas BMI ↑
+
Infarction(yes), BMI ↑
+
Dia-
betes(yes), BMI ↑
+
Hyperlidemia(yes), and a simi-
UsingDomainKnowledgeinAssociationRulesMining-CaseStudy
105

lar set of SI-formulas can be created for each of ordi-
nal attributes Education, Beer, Vine, Liquers, Smok-
ing, Tric, Subsc, and Cholesterol. However, to show
possibilities of formulation and answering analytical
questions based on SI-formulas, we assume that
BMI ↑
+
Hypertension(yes) is the only approved rele-
vant medical knowledge here.
3 ANALYTICAL QUESTIONS
We have groups of attributes Social + BMI, Vices,
Problems, and Examinations, see Tab. 1. In ad-
dition, we have SI-formulas concerning ordinal at-
tributes from the groups Social + BMI and Vices
and Boolean attributes from the group Problems. In
addition, we assume that SI-formula BMI ↑
+
Hy-
pertension(yes) is the only approved and generally
accepted medical knowledge concerning data matrix
Entry. Thus, it is natural to ask the following question
Q
1
:
Q
1
: In the data matrix Entry, are there any inter-
esting relations between attributes of the groups So-
cial + BMI and Vices on the one side and the at-
tributes of the group Problems on the other side
which cannot be considered as consequences of
BMI ↑
+
Hypertension(yes)?
We deal with association rules and thus the ques-
tion Q
1
can be formulated as the question QAR
1
:
QAR
1
: In the Entry data matrix, are there any in-
teresting true association rules ϕ ≈ ψ such that ϕ is
a Boolean characteristics of the groups Social + BMI
and Vices, ψ is a Boolean characteristics of the group
Problems, ≈ is a suitable 4ft-quantifier, and these
rules ϕ ≈ ψ cannot be considered as consequences
of BMI ↑
+
Hypertension(yes)?
We use the procedure 4ft-Miner to solve QAR
1
in
the following four steps. Below, we write Hpt(yes)
instead of Hypertension(yes) (also BMI ↑
+
Hpt(yes)
etc.):
1. We define a set Φ of interesting Boolean charac-
teristics of the groups Social + BMI and Vices
and a set Ψ of interesting Boolean characteristics
of the group Problems. An example is in section
4.2.
2. We find a set True(Entry, Φ, ≈, Ψ) of all rules
ϕ ≈ ψ which are true in Entry, ϕ ∈ Φ, ψ ∈ Ψ, and
≈ is a suitable 4ft-quantifier. Several variants of
definitions of Φ, Ψ, and ≈ can be used. Examples
are in section 4.3.
3. We define a set Cons(BMI ↑
+
Hpt(yes), ≈) of all
rules ϕ ≈ ψ which can be considered as conse-
quences of BMI ↑
+
Hpt(yes), see section 5.
4. We investigate the set T C defined as
True(Entry, Φ, ≈, Ψ) ∩Cons(BMI ↑
+
Hpt(yes), ≈).
Depending on results of investigation we can get
the following conclusions.
If T C contains only rules from the set
Cons(BMI ↑
+
Hpt(yes), ≈) then we conclude:
All rules from True(Entry, Φ, ≈, Ψ) can be consid-
ered as consequences of BMI ↑
+
Hpt(yes); there is
no interesting rule ϕ ≈ ψ indicating an additional
item of knowledge.
If T C contains no (or only several) rules from
the set Cons(BMI ↑
+
Hpt(yes), ≈) then we con-
clude: There are no (or only too few) rules in
True(Entry, Φ, ≈, Ψ) which can be considered as con-
sequences of BMI ↑
+
Hpt(yes). Assuming that the
definitions of sets Φ and Ψ are reasonable we can fur-
ther conclude that this is suspicious and start inves-
tigation of circumstances of acquisition of the Entry
data matrix.
If T C contains rules which are not from the set
Cons(BMI ↑
+
Hpt(yes), ≈) then we start interpreta-
tion of these rules. One of ways how to do this is
to look if there are rules which can be considered as
consequences of additional SI-formulas which corre-
spond to items of knowledge which are not approved
and generally accepted. This way is outlined below.
We use additional SI-formulas BMI ↑
+
ATR(yes)
where ATR is one of the attributes Infarction(yes), Di-
abetes(yes), and Hyperlidemia(yes). For each such
SI-formula Ω we continue this way: We define a set
Cons(Ω, ≈) of rules ϕ ≈ ψ which can be considered
as consequences of Ω. Then we investigate the set
T C
Ω
defined as True(Entry, Φ, ≈, Ψ) ∩Cons(Ω, ≈).
Remember that we assume that Ω is not and approved
and generally accepted item of medical knowledge.
Depending on results of investigation we can get
the following conclusions.
If T C
Ω
does not contain rules from the set
Cons(Ω, ≈) then we conclude: There is no indication
of Ω in the Entry data matrix.
If T C
Ω
contains some rules from the set
Cons(Ω, ≈) then we conclude: There are indications
of Ω in the Entry data matrix. Then we can start
suitable activity (e.g. confirmation analysis starting
with getting additional observations) to decide if Ω is
a generally acceptable item of knowledge.
Examples of such conclusions related to the ques-
tion QAR
1
are given in section 6. Examples of con-
clusions related to an additional task are in section 7.
KDIR2013-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
106
4 APPLYING 4ft-Miner
4.1 Association Rules
Association rule is an expression ϕ ≈ ψ where ϕ and
ψ are Boolean attributes. It means that ϕ and ψ are as-
sociated in a way given by the symbol ≈. ϕ is called
antecedent, ψ is called succedent. Symbol ≈ is a 4ft-
quantifier. It corresponds to a condition concerning a
four-fold contingency table of ϕ and ψ. The associa-
tion rule ϕ ≈ ψ concerns analysed data matrix. Data
matrix Entry is an example of such data matrix.
The rule ϕ ≈ ψ is true in data matrix M if the con-
dition corresponding to 4ft-quantifier ≈ is satisfied in
a four-fold contingency table of ϕ and ψ in M , other-
wise ϕ ≈ ψ is false in M . The four-fold contingency
table 4 ft(ϕ, ψ, M ) of ϕ and ψ in data matrix M is a
quadruple ha, b, c, di where a is the number of rows of
M satisfying both ϕ and ψ, b is the number of rows
of M satisfying ϕ and not satisfying ψ etc., see Table
2. There are various 4ft-quantifiers, see e.g. (Rauch,
2013).
Table 2: 4ft table 4 ft(ϕ, ψ, M ) of ϕ and ψ in M .
M ψ ¬ψ
ϕ a b
¬ϕ c d
We use here the 4ft-quantifier ⇒
p,B
of founded im-
plication. It is defined for 0 < p ≤ 1 and B > 0 by the
condition
a
a+b
≥ p ∧ a ≥ B. The association rule
ϕ ⇒
p,B
ψ means that at least 100p per cent of rows
of M satisfying ϕ satisfy also ψ and that there are at
least B rows of M satisfying both ϕ and ψ.
We also use 4ft-quantifier ∼
+
q,B
of above average
dependence defined for 0 < q, B > 0 by the condition
a
a+b
≥ (1 + q)
a+c
a+b+c+d
∧ a ≥ B. This says that among
rows satisfying ϕ is at least 100p per cent more rows
satisfying ψ than among all rows and that there are at
least B rows satisfying both ϕ and ψ.
4.2 Set of Relevant Rules
We solve analytical question QAR
1
: In the Entry data
matrix, are there any interesting true association rules
ϕ ≈ ψ such that ϕ is a Boolean characteristics of the
groups Social + BMI and Vices, ψ is a Boolean char-
acteristics of the group Problems, ≈ is a suitable 4ft-
quantifier, and ϕ ≈ ψ cannot be considered as a con-
sequence of BMI ↑
+
Hypertension(yes)?
We use the 4ft-Miner procedure in four steps in-
troduced in section 3. In the first step we define a set
Φ of relevant antecedents i.e. Boolean characteristics
of the groups Social + BMI and Vices and a set Ψ of
relevant succedents i.e. Boolean characteristics of the
group Problems. The set Φ is defined as a set of all
conjunctions ϕ
S
∧ ϕ
V
where ϕ
S
∈ B(Social + BMI)
and ϕ
V
∈ B(Vices). Here B(Social + BMI) means a
set of all Boolean attributes derived from the attributes
of the group Social + BMI we consider relevant to our
analytical question, similarly for B(Vices). The set Ψ
can be similarly denoted as B(Problems).
Figure 2: Definitions of relevant antecedents and succe-
dents.
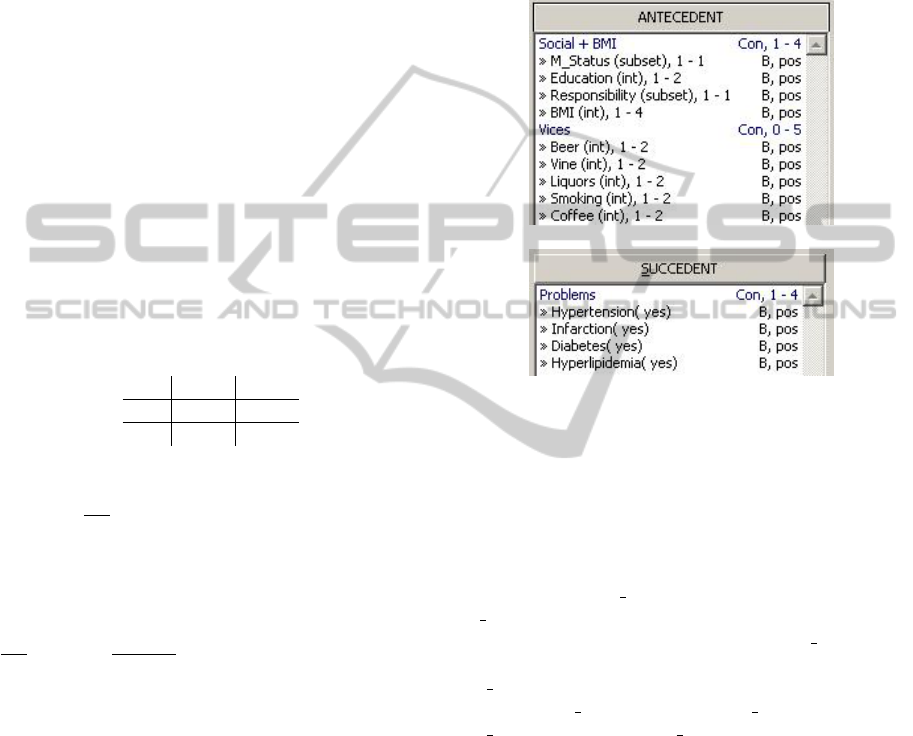
The set B(Social + BMI) is defined in the frame
ANTECEDENT in Fig 2 in row Social + BMI Conj,
1-4 and in four consecutive rows. Each ϕ
S
is a con-
junction of 1 - 4 basic Boolean attributes derived from
particular attributes of the group Social + BMI.
Set of basic Boolean attributes derived
from attribute M Status is defined by the row
M Status(subset), 1-1 B, pos. It means
that all basic Boolean attributes M Status(α)
where α is a subset of all categories of attribute
M Status containing just one category are gen-
erated: M Status(married), M Status(divorced),
M Status(single), and M Status(widower). Set of
basic Boolean attributes derived from attribute
Responsibility is defined similarly.
Set of basic Boolean attributes derived
from attribute Education is defined by the row
Education(int), 1-2 B, pos. Thus, all 7 basic
Boolean attributes Education(α) where α is a set
of 1 or 2 consecutive categories (i.e. interval of
categories) are generated. Education(basic school),
Education(basic school, apprentice school) are
examples.
Set of all Boolean attributes derived from the at-
tribute BMI is defined by the row BMI(int), 1-4
B, pos. It means that all Boolean attributes BMI(α)
where α is a set of 1 - 4 consecutive categories (i.e.
UsingDomainKnowledgeinAssociationRulesMining-CaseStudy
107

interval of categories) are generated. The Boolean at-
tributes BMI(< 22) and BMI (22, 23, 24, 25) are ex-
amples. 46 basic Boolean attributes are defined this
way and more than 6 500 conjunctions ϕ
S
are defined
altogether.
The set B(Vices) is defined similarly, see row
Vices Conj, 0-5 and five consecutive rows in the
frame ANTECEDENT in Fig 2. The number 0 in this
row means that the attribute ϕ
V
can be skipped. Al-
together, there are more than 11 000 conjunctions ϕ
V
and more than 73 × 10
6
conjunctions ϕ
S
∧ ϕ
V
.
The set Ψ i.e. B(Problems) of relevant succedents
is defined in row Problems Conj, 1-4 and four con-
secutive rows in the frame SUCCEDENT in Fig 2. Each
ϕ
P
∈ B(Problems) is a conjunction of 1 - 4 ba-
sic Boolean attributes derived from attributes of the
group Problems. There is only one basic Boolean at-
tribute derived from attribute Hypertensions i.e. Hy-
pertensions(yes), see Hypertension(yes) B, pos.
The same is true for remaining attributes of the group
Problems. Thus, there are 15 relevant succedents.
In addition, there are more than 10
9
association
rules ϕ
S
∧ ϕ
V
≈ ϕ
P
where ϕ
S
∈ B(Social + BMI),
ϕ
V
∈ B(Vices), ϕ
P
∈ B(Problems) and ≈ is a 4ft-
quantifier.
4.3 True Relevant Association Rules
We used three runs of the 4ft-Miner procedure to get
sets True(Entry,Φ, ≈, Ψ) of all rules ϕ ≈ ψ which are
true in Entry, see the second step in section 3. We
used Φ and Ψ defined in the previous section.
The 4ft-quantifier ⇒
0.9,30
defined by the condi-
tion
a
a+b
≥ 0.9 ∧ a ≥ 30 (see section 4.1) was used
first. The task was solved in 4 minutes (PC with
2GB RAM and Intel T7200 processor at 2 GHz)
and 3.35 × 10
6
association rules were generated and
tested. Various optimization techniques are imple-
mented in the 4ft-Miner procedure, see (Rauch and
ˇ
Sim
˚
unek, 2005). Thus, not all > 10
9
rules are truly
generated and tested. However, no true rules was
found, i.e. True(Entry, Φ, ⇒
0.9,30
, Ψ) =
/
0.
Thus we used 4ft-quantifier ⇒
0.3,30
instead of
⇒
0.9,30
. This setting led to 24 true rules. In other
words, the set True(Entry,Φ, ⇒
0.3,30
, Ψ) contains 24
rules. The strongest rule is the rule (we denote this
rule as R ) BMI(≥ 30) ∧ Γ ⇒
0.314,32
Hpt(yes) with
4ft-table 4 f t(BMI(≥ 30) ∧ Γ, Hpt(yes), Entry) shown
in Figure 3. We write Hpt (yes) instead of Hyperten-
Entry Hpt(yes) ¬Hpt(yes)
BMI(≥ 30) ∧ Γ 32 70
¬(BMI(≥ 30) ∧ Γ) 187 1118
Figure 3: 4 f t(BMI(≥ 30) ∧ Γ, Hpt(yes), Entry).
sions(yes). Γ abbreviates Beer(not, ≤ 1) ∧ Vine(not,
≤ 0.5) ∧ Liquors(not, ≤ 100).
Rule R says that relative frequency of pa-
tients satisfying Hpt(yes) among patients satisfying
BMI(≥ 30) ∧ Γ (i.e. confidency) is 0.314 and that
there are 32 patients satisfying both BMI(≥ 30) ∧ Γ
and Hpt(yes).
We also used 4ft-quantifier ∼
+
0.1,30
instead of
⇒
0.9,30
. This settings led to 3 754 true rules, which
means that the set True(Entry, Φ, ∼
+
0.1,30
, Ψ) contains
3 754 rules. Succedents of 3 749 of them are equal
to Hypertensions(yes). The strongest rule (what con-
cerns lift related to 0.1 in the 4ft-quantifier ∼
+
0.1,30
,
see below) is the rule (we denote this rule as
R
1
) BMI(≥ 31) ∧ Γ
1
∼
+
1.02,31
Hpt(yes) with 4ft-table
4 f t(BMI(≥ 31) ∧ Γ
1
, Hpt(yes), Entry) shown in
Fig. 4. Hpt(yes) means the same as above, Γ
1
abbreviates M Status(married) ∧ Vine(not, ≤ 0.5) ∧
Liquors(not, ≤ 100) ∧ Coffee(not, 1-2).
Entry Hpt(yes) ¬Hpt(yes)
BMI(≥ 31) ∧ Γ
1
31 68
¬(BMI(≥ 31) ∧ Γ
1
) 187 1119
Figure 4: 4 f t(BMI(≥ 31) ∧ Γ
1
, Hpt(yes), Entry).
Rule R
1
says that relative frequency of pa-
tients satisfying Hpt(yes) among patients satisfying
BMI(≥ 31) ∧ Γ
1
(i.e.
31
31+68
) is 102 per cent higher
than relative frequency of patients satisfying Hpt(yes)
among all patients (i.e.
31+187
31+68+187+1119
) and that there
are 31 patients satisfying both BMI(≥ 31) ∧ Γ
1
and
Hpt(yes).
Let us note that the value 0.1 in the 4ft-quantifier
∼
+
0.1,30
means that
a
a+b
≥ (1 + 0.1)
a+c
a+b+c+d
, see sec-
tion 4.1. This correspond to the fact that lift of the
association rule in question is ≥ 1.1.
5 CONSEQUENCES OF ITEMS
OF DOMAIN KNOWLEDGE
Runs of the 4ft-Miner procedure resulted into two
non-empty sets – True(Entry, Φ, ⇒
0.3,30
, Ψ) contain-
ing 24 rules and True(Entry, Φ, ∼
+
0.1,30
, Ψ) with 3 754
rules. We define a set Cons(BMI ↑
+
Hpt(yes), ≈) of
all rules ϕ ≈ ψ which can be considered as conse-
quences of BMI ↑
+
Hpt(yes) for both ⇒
0.3,30
and
∼
+
0.1,30
, see section 3.
The set Cons(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) of all
rules ϕ ⇒
p,B
ψ which can be considered as conse-
quences of BMI ↑
+
Hpt(yes) is defined in four steps:
1) A set AC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) of atomic
consequences of BMI ↑
+
Hpt(yes) for ⇒
0.3,30
is de-
fined as a set of simple rules BMI(δ) ⇒
p
0
,B
0
Hpt(yes)
KDIR2013-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
108

such that p
0
≥ 0.3, B
0
≥ 30 and BMI(δ) is a ba-
sic Boolean attribute expressing (informally speak-
ing) that BMI is high enough.
2) A set AgC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) of
agreed consequences of BMI ↑
+
Hpt(yes) for ⇒
0.3,30
is defined. A rule ρ ⇒
p,B
σ belongs to the set
AgC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) if the following con-
ditions are satisfied:
• ρ ⇒
p,B
σ 6∈ AC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
)
• there is no κ ⇒
p
0
,B
0
λ belonging to
AC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) such that ρ ⇒
p,B
σ
logically follows from κ ⇒
p
0
,B
0
λ.
• there is κ ⇒
p
0
,B
0
λ belonging to
AC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) such that, accord-
ing to a domain expert, it is possible to agree
that ρ ⇒
p,B
σ says nothing new in addition to
κ ⇒
p
0
,B
0
λ.
3) A set LgC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) of log-
ical consequences of BMI ↑
+
Hpt(yes) for ⇒
0.3,30
is defined. A rule ϕ ⇒
p,B
ψ belongs to the set
LgC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) if the following con-
ditions are satisfied:
• ϕ ⇒
p,B
ψ 6∈ (AC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) ∪
AgC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
))
• there is τ ⇒
p
0
,B
0
ω belonging to the set
AC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) ∪
AgC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) such that
ϕ ⇒
p,B
ψ logically follows from τ ⇒
p
0
,B
0
ω.
4) We define Cons(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) =
AC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) ∪
AgC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) ∪
LgC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
).
We give more details to particular steps 1) – 3).
1) The set AC(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) is de-
fined as a set of all rules BMI(δ) ⇒
p,B
Hpt(yes)
where p
0
≥ 0.3, B
0
≥ 30 and BMI(δ) is a basic
Boolean attribute expressing that BMI is high enough.
Procedure 4ft-Miner has a simple tool facilitating a
definition of a set of basic Boolean attributes BMI(δ)
expressing that BMI is high enough, see Fig. 5. This
is a contingency table of the attributes BMI and Hy-
pertension. Based on this table we can decide in
co-operation with a domain expert that we will con-
sider all basic Boolean attributes BMI(δ) such that
δ ⊂ {28, 29, 30, 31, 32, > 32}. It is crucial that this
definition is stored and further used.
2) An association rule ϕ
0
⇒
p,B
ψ
0
logically fol-
lows from a rule ϕ ⇒
p,B
ψ if the following is true:
If ϕ ⇒
p,B
ψ is true in a given data matrix M then
ϕ
0
⇒
p,B
ψ
0
is also true in M . It is easy to prove that
the association rule BMI(δ)∧χ ⇒
0.3,30
Hpt(yes) does
not logically follow from BMI(δ) ⇒
0.3,30
Hpt(yes).
Figure 5: Frequencies of categories of BMI.
The core of the proof is the fact that if there
are at least B rows of a data matrix M satisfying
BMI(δ) ∧ Hpt(yes) then there still can be no row
of M satisfying BMI(δ) ∧ χ ∧ Hpt(yes).
However, in some cases it can be reasonable
from the point of view of a domain expert to agree
that BMI(δ) ∧ χ ⇒
0.3,30
Hpt(yes) is a consequence
of BMI(δ) ⇒
0.3,30
Hpt(yes). Then we call the rule
BMI(δ) ∧ χ ⇒
0.3,30
Hpt(yes) an agreed consequence
of the rule BMI(δ) ⇒
0.3,30
Hpt(yes).
The rule BMI(δ) ∧ Beer(not) ⇒
0.3,30
Hpt(yes)
is an example of an agreed consequence of
BMI ↑
+
Hpt(yes) because the truthfulness of Boolean
attribute Beer(not) has no influence on the relation of
BMI and Hpt(yes). The same is true for all basic
Boolean attributes we can derive from the attributes
of the groups Social + BMI and Vices (except BMI).
3) A criterion making possible to decide if
an association rule ϕ
0
⇒
p,B
ψ
0
logically follows
from a rule ϕ ⇒
p,B
ψ is proved in (Rauch, 2013).
It is, e.g., easy to prove that BMI(δ) ⇒
0.3,30
Hpt(yes) ∨ Infarction(yes) logically follows from
BMI(δ) ⇒
0.3,30
Hpt(yes).
Let us emphasize that the same approach can be
used to get the set Cons(BMI ↑
+
Hpt(yes), ∼
+
0.1,30
).
In addition, it is important that the 4ft-Miner proce-
dure has tools making possible to apply this approach
to get a set Cons(Ω, ≈) of all rules ϕ ≈ ψ which can be
considered as consequences of an item Ω of domain
knowledge for a 4ft-quantifier ≈. This is possible for
various types of items Ω of domain knowledge and
many important 4ft-quantifiers ≈. Results on deduc-
tion rules of the form
ϕ≈ψ
ϕ
0
≈ψ
0
(Rauch, 2013) are used.
6 INTERPRETING RESULTS
We have two non-empty sets of rules –
True(Entry, Φ, ⇒
0.3,30
, Ψ) containing 24 rules
UsingDomainKnowledgeinAssociationRulesMining-CaseStudy
109

and True(Entry,Φ, ∼
+
0.1,30
, Ψ) containing 3754 rules,
see section 4.3. We interpret these sets according
the point 4 introduced in section 3. The 4ft-Miner
procedure makes possible to easy compare these
sets with sets Cons(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) and
Cons(BMI ↑
+
Hpt(yes), ∼
+
0.1,30
) respectively. Re-
sults of comparison are summarized in Table 3. Here
C (Ω, ≈) abbreviates Cons(BMI ↑
+
Hpt(yes), ≈).
Table 3: 4ft table 4 f t(ϕ, ψ, M ) of ϕ and ψ in M .
≈ in C (Ω, ≈) not in C (Ω, ≈) Σ
⇒
0.3,30
24 0 24
∼
+
0.1,30
1 407 1 347 3 754
The first row in the body of Table 3 means that all
rules in True(Entry, Φ, ⇒
0.3,30
, Ψ) can be considered
as consequences of BMI ↑
+
Hpt. Thus we can con-
clude that there are no interesting rules ϕ ⇒
0.3,30
ψ
true in data matrix Entry such that ϕ is a Boolean char-
acteristics of the groups Social + BMI and Vices, ψ is
a Boolean characteristics of the group Problems, and
ϕ ⇒
0.3,30
ψ cannot be considered as a consequence of
BMI ↑
+
Hpt(yes).
The second row in the body of Table 3 means that
there are 1 347 interesting rules ϕ ∼
+
0.1,30
ψ true in
data matrix Entry such that ϕ is a Boolean charac-
teristics of the groups Social + BMI and Vices, ψ is
a Boolean characteristics of the group Problems, and
ϕ ∼
+
0.1,30
ψ cannot be considered as a consequence of
BMI ↑
+
Hpt(yes).
The 4ft-Miner procedure has additional tools en-
abling the following conclusions:
(i) There are only 4 rule concerning Infarc-
tion(yes) and 1 rule concerning Hyperlipidemia(yes)
among the mentioned 1 347 rules, all remaining 1 342
rules concern Hpt(yes). This is because frequencies
of attributes Infarction(yes), Hyperlipidemia(yes),
and Diabetes(yes) are very low, see Table 1.
(ii) Among remaining 1 342 rules concern-
ing Hpt(yes), there are 411 rules which can
be written as BMI(δ) ∧ τ ∼
+
0.1,30
Hpt(yes) where
δ ⊂ {24, 25, 26}. This means that these rules are not
consequences of BMI ↑
+
Hpt(yes) in the sense of the
definition in section 5. They can be seen as candi-
dates of exceptions from the item BMI ↑
+
Hpt(yes).
However, a deeper discussion on this topic is out of
the scope of this paper.
These conclusions are made under the assump-
tions that the sets of interesting rules are de-
fined in the way described in section 4.2
and that the sets Cons(BMI ↑
+
Hpt(yes), ⇒
0.3,30
) and
Cons(BMI ↑
+
Hpt(yes), ∼
+
0.1,30
) defined in section 5
are used. Let us emphasize that all these definitions
can be modified in various ways and thus various vari-
ants of these conclusions can be formulated.
Let us also emphasize that rules with minimal con-
fidence 0.3 used above are not too much suitable to
express interesting relations. We use them here only
to show principles of the presented approach. In ad-
dition, there are lot of rules with stronger quantifiers
than ∼
+
0.1,30
in the set True(Entry, Φ, ∼
+
0.1,30
, Ψ) con-
taining 3 754 rules. The strongest one is a rule with
quantifier ∼
+
1.02,31
(i.e. lift 2.02).
7 ADDITIONAL RESULTS
The analytical questions QAR
1
solved above can be
modified to the question QAR
2
(note that attribute
BMI is not involved):
QAR
2
: In the Entry data matrix, are there any
interesting true association rules ϕ ≈ ψ such that ϕ
is a Boolean characteristics of the groups Vices and
Examinations, ψ is a Boolean characteristics of the
group Problems, ≈ is a suitable 4ft-quantifier?
To solve this question, we used a run of the 4ft-
Miner procedure with the definition of relevant an-
tecedents according to Fig. 6, the definition of rele-
vant succedents according to Fig. 2, and the quantifier
∼
+
0.5,30
(i.e. lift = 1.5). This resulted to 71 true rules,
all of them concern Hpt(yes).
Figure 6: Definition of relevant antecedents for QAR
2
.
If we define a set of atomic consequences of
Subsc ↑
+
Hpt as a set of all rules Subsc(δ) ∼
+
0.5,30
Hpt
where δ ⊂ {(20; 25i, (25; 30i, (30; 55i} (see ”> 20” in
the row Subsc of Table 4) and if we use an analogous
approach as described in Section 5, we can conclude
that there are 28 rules which can be considered as
consequences of Subsc ↑
+
Hpt and 1 rule which can-
not be considered as a consequence of Subsc ↑
+
Hpt.
In addition there are 29 rules concerning the attribute
Subsc, see row Subsc of Table 4. There are analogous
information for attributes Tric and Cholesterol which
is abbreviated as Chol, see Table 4.
We can conclude that there are lot of rules which
can be considered as consequences of the SI-formula
Subsc ↑
+
Hpt and only one rule which cannot be con-
KDIR2013-InternationalConferenceonKnowledgeDiscoveryandInformationRetrieval
110

Table 4: Summary of results for QAR
2
.
Attribute Atomic ∈ Cons 6∈ Cons Total
Subsc > 20 28 1 29
Tric > 10 7 4 11
Chol ≥ 240 18 12 30
sidered as a consequence of this SI-formula. Thus
it seems reasonable to try to confirm the hypothe-
sis Subsc ↑
+
Hpt. In addition, we can conclude that
there are no strong indications of Tric ↑
+
Hpt and
Chol ↑
+
Hpt.
However, there are various possibilities of mod-
ifications of parameters of the set of relevant an-
tecedents, modifications of the quantifier ∼
+
0.5,30
and
modifications of the definitions of sets of conse-
quences of Tric ↑
+
Hpt and Chol ↑
+
Hpt. This can
lead to revision of the introduced conclusions.
8 CONCLUSIONS
We have presented a new way of dealing with domain
knowledge in association rules data mining. This is
based on mapping items of domain knowledge to sets
of association rules which can be considered as their
consequences. It was shown that there is both nec-
essary theory based on logic of association rules and
the 4ft-Miner procedure realizing relevant operations
with data, items of knowledge and rules. This makes
possible to formulate interesting analytical questions
and answer them in an efficient way. There is a very
fine way to define sets of relevant association rules.
These association rules, when true in data, can be con-
sidered as the smallest possible indications of more
complex dependences among related attributes.
However, there is still a challenge concerning sen-
sitivity of the presented approach to various param-
eters. There is also a challenge of combining of the
4ft-Miner procedure for mining the presented syntac-
tically rich association rules with additional data min-
ing procedures, namely with procedures of the LISp-
Miner system dealing with various contingency tables
(H
´
ajek et al., 2010). These topics are subjects of fur-
ther work.
ACKNOWLEDGEMENTS
The work described here has beeen supported by the
grant IGA 20/2013 of the University of Economics,
Prague.
REFERENCES
Agrawal, R., Mannila, H., Srikant, R., Toivonen, H., and
Verkamo, A. I. (1996). Fast discovery of association
rules. In Advances in Knowledge Discovery and Data
Mining, pages 307–328. AAAI/MIT Press.
Brossette, S. E., Sprague, A. P., Hardin, J. M., Waites, K. B.,
Jones, W. T., and Moser, S. A. (1998). Research pa-
per: Association rules and data mining in hospital in-
fection control and public health surveillance. JAMIA,
5(4):373–381.
Delgado, M., Ruiz, M., and Sanchez, D. (2011). New
approaches for discovering exception and anoma-
lous rules. International Journal of Uncertainty and
Knowledge-based Systems, 19(2):361–399.
Delgado, M., Sanchez, D., Martin-Bautista, M., and Vila,
M. (2001). Mining association rules with improved
semantics in medical databases. Artificial Intelligence
in Medicine, 21(1–3):241–245.
H
´
ajek, P. and Havr
´
anek, T. (1978). Mechanizing Hypothesis
Formation (Mathematical Foundations for a General
Theory. Springer–Verlag, Berlin Heidellberg New
York, 1st edition.
H
´
ajek, P., Hole
ˇ
na, M., and Rauch, J. (2010). The GUHA
method and its meaning for data mining. Journal of
Computer and System Science, 76(1):34–48.
Ordonez, C., Ezquerra, N., and Santana, C. A. (2006). Con-
straining and summarizing association rules in medi-
cal data. Knowledge and Information Systems (KAIS),
9(3):259–283.
Rauch, J. (2011). Consideration on a formal frame for data
mining. In Hong, T.-P., Kudo, Y., Kudo, M., Lin, T. Y.,
Chien, B.-C., Wang, S.-L., Inuiguchi, M., and Liu, G.,
editors, GrC, pages 562–569. IEEE.
Rauch, J. (2013). Observational Calculi and Association
Rules, volume 469 of Studies in Computational Intel-
ligence. Springer.
Rauch, J. and
ˇ
Sim
˚
unek, M. (2005). An alternative approach
to mining association rules. In Lin, T. Y., Ohsuga, S.,
Liau, C.-J., Hu, X., and Tsumoto, S., editors, Founda-
tions of Data Mining and knowledge Discovery, vol-
ume 6 of Studies in Computational Intelligence, pages
211–231. Springer.
Rauch, J. and
ˇ
Sim
˚
unek, M. (2011). Applying domain
knowledge in association rules mining process - first
experience. In Kryszkiewicz, M., Rybinski, H.,
Skowron, A., and Ras, Z. W., editors, ISMIS, volume
6804 of Lecture Notes in Computer Science, pages
113–122. Springer.
Roddick, J. F., Fule, P., and Graco, W. J. (2003). Ex-
ploratory medical knowledge discovery: experiences
and issues. SIGKDD Explorations, 5(1):94–99.
UsingDomainKnowledgeinAssociationRulesMining-CaseStudy
111
