
INTEGRATION OF GENERATIVE LEARNING AND MULTIPLE
POSE CLASSIFIERS FOR PEDESTRIAN DETECTION
Hidefumi Yoshida
1
, Daisuke Deguchi
1
, Ichiro Ide
1
, Hiroshi Murase
1
,
Kunihiro Goto
2
, Yoshikatsu Kimura
2
and Takashi Naito
2
1
Nagoya University, Furo-cho, Chikusa-ku, Nagoya, Aichi 464-8601 Japan
2
Toyota Central Research & Development Laboratories, Inc., Nagakute, Aichi, 480-1192, Japan
Keywords:
Pedestrian Detection, Generative Learning, HOG, SVM.
Abstract:
Recently, pedestrian detection from in-vehicle camera images is becoming an important technology in ITS
(Intelligent Transportation System). However, it is difficult to detect pedestrians stably due to the variety of
their poses and their backgrounds. To tackle this problem, we propose a method to detect various pedestrians
from in-vehicle camera images by using multiple classifiers corresponding to various pedestrian pose classes.
Since pedestrians’ pose varies widely, it is difficult to construct a single classifier that can detect pedestrians
with various poses stably. Therefore, this paper constructs multiple classifiers optimized for variously posed
pedestrians by classifying pedestrian images into multiple pose classes. Also, to reduce the bias and the cost
for preparing numerous pedestrian images for each pose class for learning, the proposed method employs a
generative learning method. Finally, the proposed method constructs multiple classifiers by using the syn-
thesized pedestrian images. Experimental results showed that the detection accuracy of the proposed method
outperformed comparative methods, and we confirmed that the proposed method could detect variously posed
pedestrians stably.
1 INTRODUCTION
Recently, many research groups have proposed meth-
ods to detect pedestrians from an in-vehicle camera
image for driving assistance. The most successful
methods to detect pedestrians are methods that em-
ploy Histogram of Oriented Gradients (HOG) and
Support Vector Machine (SVM) (Dalal and Triggs,
2005; Enzweiler et al., 2009). Since the HOG is
robust against lighting condition changes and local
geometric changes, and the SVM classifier has a
high generalization ability, this combination is now
widely used for detecting objects from images for var-
ious applications. However, this method requires nu-
merous pedestrian images for training the classifier.
Then, gathering various samples comprehensively is
not feasible and its cost is quite expensive. In addi-
tion, since pedestrians’ pose varies widely, it is dif-
ficult to detect various pedestrians by using a single
classifier.
To overcome these problems, this paper proposes
a method to detect variously posed pedestrians by
using multiple classifiers optimized for each pedes-
trians’ pose. Although each classifier needs to be
trained by numerouspedestrian images corresponding
to each pose, it is very difficult to gather various ap-
pearances and also time-consuming to prepare these
images. Therefore, the proposed method reduces the
bias and the cost for preparing these images by intro-
ducing a “generative learning” method. Here, gen-
erative learning is a method to train a classifier by
synthesizing various training samples. This method
was successfully applied in several applications, such
as generic objects detection (Murase, 1996), traffic
sign detection (Doman et al., 2009), pavement marker
detection (Noda et al., 2009), and pedestrian detec-
tion (Enzweiler and Gavrila, 2008). The generative
learning method synthesizes various images by mod-
eling appearances of target objects in actual condi-
tions. Thus, we can control the appearances of them.
Although this method enables us to synthesize various
images without manual intervention, the quality of the
synthesized images is highly dependent on the gener-
ation model. Therefore, as used in (Enzweiler and
Gavrila, 2008), this paper employs Statistical Shape
Models (SSM, (Cootes et al., 1995)) to synthesize
variously posed pedestrian images. The main contri-
butions of this paper are:
567
Yoshida H., Deguchi D., Ide I., Murase H., Goto K., Kimura Y. and Naito T..
INTEGRATION OF GENERATIVE LEARNING AND MULTIPLE POSE CLASSIFIERS FOR PEDESTRIAN DETECTION.
DOI: 10.5220/0003817305670572
In Proceedings of the International Conference on Computer Vision Theory and Applications (VISAPP-2012), pages 567-572
ISBN: 978-989-8565-03-7
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)
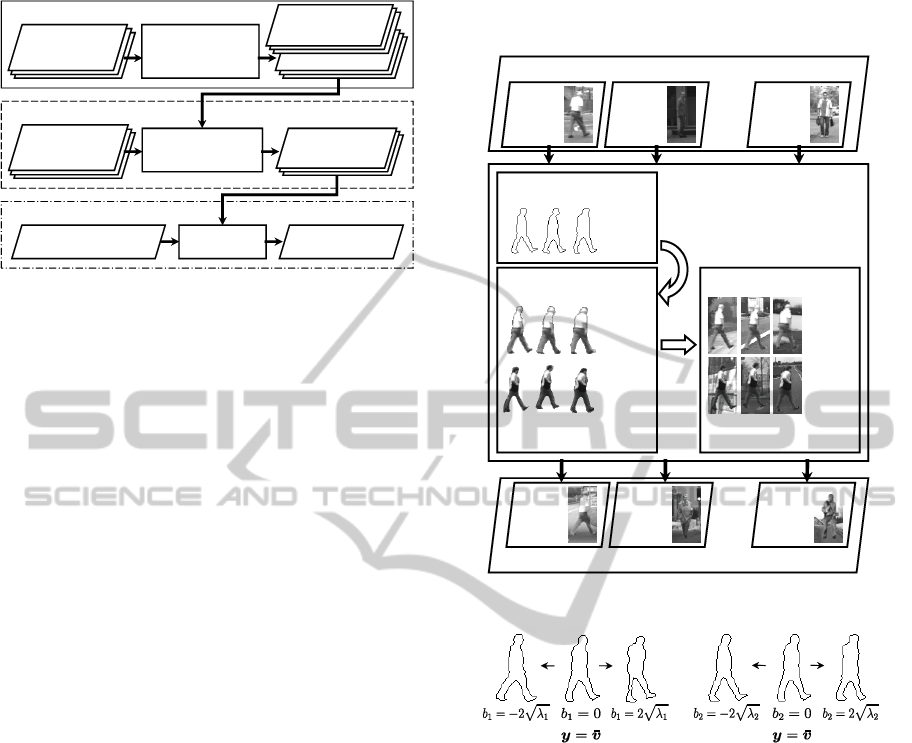
Generation phase
Training phase
Detection phase
Detection
Construction of
multiple classifiers
Initial pedestrian
images
Generation of
variously posed
pedestrian images
Synthesized images
Pose 1
Pose 2
…
In-vehicle camera image Pedestrian
1
Non-pedestrian
images
Classifiers
…
…
…
Figure 1: Process flow of the proposed method.
1. Generation of numerous pedestrian images la-
beled with their poses from only a small number
of them for training.
2. Construction of multiple classifiers optimized for
each pedestrians’ pose.
This paper is organized as follows. In section 2,
we describe the process flow of the proposed method
and explain the procedures for the synthesis of pedes-
trian images and the construction of multiple clas-
sifiers. Section 3 describes an experiment using in-
vehicle camera images. Finally, we conclude this pa-
per in section 4.
2 METHOD
Figure 1 shows the process flow of the proposed
method. As seen in Fig. 1, the proposed method con-
sists of three phases; (1) the generation phase, (2) the
training phase, and (3) the detection phase.
In the generation phase, inputs are only a small
number of pedestrian images, but numerous pedes-
trian images are synthesized from them. Here,
the proposed method employs SSM as a generation
model for obtaining variously posed pedestrian im-
ages with various textures. This phase is divided into
the shape generation, the texture generation, and the
background synthesis steps.
Next, the proposed method constructs multiple
classifiers in the training phase. Multiple classifiers
consist of a classifier optimized for each pedestrians’
pose which is trained by using pedestrian images syn-
thesized in the previous phase.
The last is the detection phase that detects pedes-
trians from in-vehicle camera images by using the
trained multiple classifiers. In this phase, outputs of
multiple classifiers are combined and used for the fi-
nal judgment of the pedestrian detection.
The following sections explain details of each
phase.
Shape generation
Shapes
Texture generation
Shapes
Background synthesis
Textures
Synthesize
pedestrian images
for each pose
Pose nPose 2Pose 1
…
…
…
Shapes
Textures
…
…
…
Synthesized images
Clustered images
Pose nPose 2Pose 1
…
Figure 2: Overview of the generation phase.
(a) s = 1 (b) s = 2
Figure 3: Examples of the synthesized pedestrian shapes by
using SSM. These shapes are synthesized by changing the
weight b
s
. The images (a) and (b) represent the synthesized
shapes by using a different principal component s. They
satisfy the condition b
i
= 0 (i 6= s). Images placed at the
center of each figure correspond to the mean shape
¯
v. The
left and the right images in each figure correspond to the
synthesized shape y using Eq.(1).
2.1 Generation Phase
As seen in Fig. 2, the proposed method synthesizes
variously posed pedestrian images with various tex-
tures from the initial pedestrian images classified into
a pose class. To synthesize various pedestrian im-
ages corresponding to each pose class, the proposed
method employs the framework proposed in (En-
zweiler and Gavrila, 2008). Inputs of this phase are
a small number of pedestrian images classified into
each pose class. This is done by extracting the con-
tours of pedestrians from the input images, and then
VISAPP 2012 - International Conference on Computer Vision Theory and Applications
568
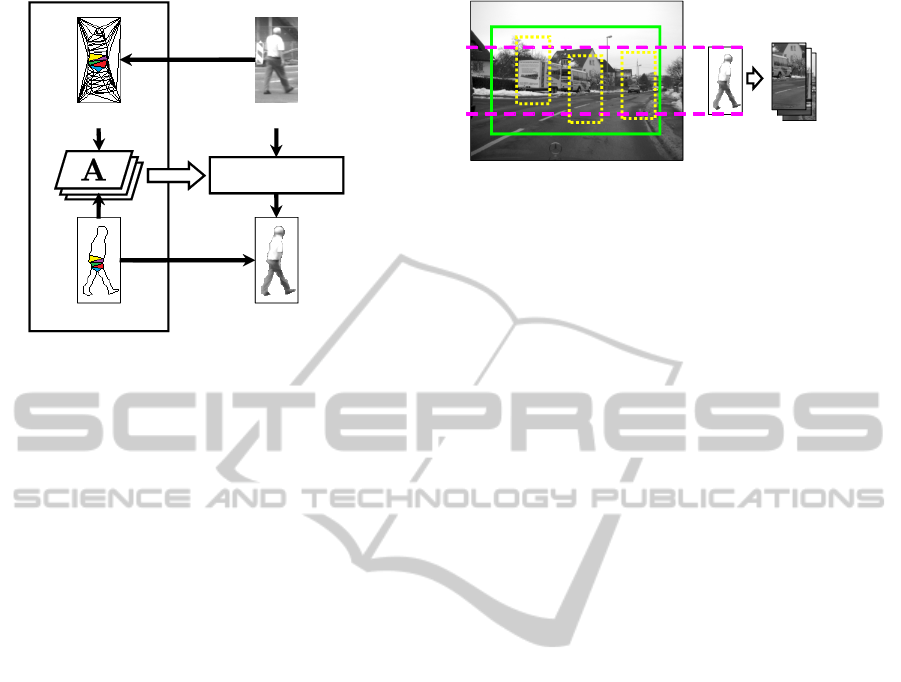
Synthesized shape
Texture mapped image
Triangulated plane Actual pedestrian image
Transformation
Figure 4: Texture mapping from an actual pedestrian image
to a synthesized shape. Here, A is an affine transformation
matrix.
by clustering them according to the distance between
the extracted contours (Gavrila and Giebel, 2001). Fi-
nally, the proposed method considers each cluster as
a pedestrian “pose”, and uses them in the following
process.
2.1.1 Shape and Texture Generation
The proposed method synthesizes various pedes-
trian shapes by using a Statistical Shape Model
(SSM) (Cootes et al., 1995), as shown in Fig. 3. This
generation process is applied to each pose class.
In the SSM, the synthesized shape y can be repre-
sented as
y =
¯
v+ Pb, (1)
where
¯
v is the mean vector corresponding to the shape
of each posed pedestrian, and Pb represents the shape
perturbation. Matrix P consists of eigenvectors ob-
tained by applying PCA to pedestrian shapes in each
pose class, and these eigenvectors are selected by
evaluating eigenvalues so that the cumulative contri-
bution ratio of eigenvalues exceeds 99%.
Textures of pedestrians are synthesized by apply-
ing a procedure similar to that in the shape generation
step. In this step, luminance values within a pedes-
trian region are represented by v. First, the proposed
method applies the Delaunay triangulation algorithm
to the control points placed at the contour of a pedes-
trian, and then obtains a set of triangles as shown in
the upper left image in Fig. 4. Then, the proposed
method computes an affine transformation matrix A
for each triangle by referring to the result of the shape
generation step. This transformation transforms ver-
tices of each triangle from an input pedestrian image
to the synthesized shape. Then, the texture inside each
Non-pedestrian image
Synthesized
pedestrian
image
Extracted
background
images
...
Figure 5: Examples of extracted background images.
triangle is mapped onto the synthesized shape by us-
ing this transformation matrix A. Finally, the pro-
posed method applies this texture mapping process
for all triangles obtained by the Delaunay triangula-
tion algorithm.
After applying the above process, variously tex-
tured pedestrian images for the same pose can be ob-
tained. By using these images, the proposed method
synthesizes various textures for each pose. First, the
proposed method represents intensities of each image
as an intensity vector. Then, by applying the SSM
algorithm to the intensity vectors, a new pedestrian
texture is obtained.
2.1.2 Background Synthesis
As the last step, the proposed method combines
the synthesized pedestrian image with various back-
ground images. In this step, the proposed method ex-
tracts background images from in-vehicle camera im-
ages containing no pedestrian by changing the param-
eters such as the clipping position and the size of the
clipping rectangle. Since we can assume that a pedes-
trian does not float in the sky nor lie on the road, the
proposed method sets the parameters for background
extraction so that an image is not composed of only
the sky or a road surface. Figure 5 shows examples
of the extracted background images. Finally, the pro-
posed method uses alpha blending for synthesizing a
pedestrian image super-imposed on a background im-
age.
2.2 Training Phase
In this phase, the proposed method constructs mul-
tiple classifiers optimized for each pedestrians’ pose
by using the synthesized pedestrian images. Here, the
multiple classifiers consist of simple two-class clas-
sifiers. The proposed method optimizes the perfor-
mance of each classifier so that each classifier can de-
tect each posed pedestrian.
First, the proposed method extracts HOG fea-
tures from the synthesized pedestrian images and non-
pedestrian images. Then, a linear SVM classifier is
INTEGRATION OF GENERATIVE LEARNING AND MULTIPLE POSE CLASSIFIERS FOR PEDESTRIAN
DETECTION
569

constructed for each pedestrians’ pose by using these
features. Here, libSVM
1
is used for constructing the
SVM classifiers.
2.3 Detection Phase
In the detection phase, pedestrians are detected from
in-vehicle camera images by using the trained classi-
fiers as seen in Fig. 6. In this phase, pedestrian de-
tection is performed by sliding a detection window
over the entire region of an image, and each detec-
tion window is evaluated by applying multiple clas-
sifiers. Here, the proposed method computes outputs
of multiple classifiers for each detection window, and
the maximum is used as a pedestrian likelihood F(i).
Thus,
F(i) = max{ f
1
(i), f
2
(i), ..., f
K
(i)}, (2)
where f
k
(i) is a two-class classifier corresponding to
each posed pedestrian, and i represents an extracted
HOG feature. Finally, if F(i) is larger than a thresh-
old ε, the proposed method outputs that the detection
window contains a pedestrian.
3 EXPERIMENT
We evaluated the performance of the proposed
method by using in-vehicle camera images. The fol-
lowing sections describe details of the dataset used
in the experiment and the results of the proposed
method.
3.1 Dataset
In this experiment, the proposed method was eval-
uated by using the “Daimler Pedestrian Detection
Benchmark”
2
dataset which consists of 15,660 pedes-
trian images and 6,745 non-pedestrian images. We
manually selected 200 pedestrian images in daylight
conditions from this dataset as inputs of the genera-
tion phase. Also, we prepared 35,500 non-pedestrian
images in various scales by gathering false positives
from a weak detector constructed through a prelim-
inary experiment on this dataset (Fig. 7). For vali-
dation, we prepared 1,016 in-vehicle camera images
including 1,110 pedestrians. The resolution of the in-
vehicle camera images was 640× 480 pixels.
1
LIBSVM A Library for Support Vector Machines,
http://www.csie.ntu.edu.tw/˜cjlin/libsvm/
2
http://www.gavrila.net/Research/Pedestrian Detection
/Daimler Pedestrian Benchmarks/Daimler Pedestrian Dete
ction B/daimler pedestrian detection b.html
Classifier f
1
Pose 1 vs. non-ped.
In-vehicle camera image
Classified result
Select the maximum score of
classification results
...
Classifier f
2
Pose 2 vs. non-ped.
Classifier f
K
Pose K vs. non-ped.
Figure 6: Overview of the multiple classifiers.
Figure 7: Examples of the pedestrian and non-pedestrian
images used for training.
Figure 8: Examples of the synthesized pedestrian images.
3.2 Generation of Pedestrian Images
First of all, 200 pedestrian images were divided into
eleven pose classes corresponding to each pedestri-
ans’ pose. In this step, the contours of all pedestrian
images were extracted manually. Then, 15,660 pedes-
trian images were synthesized by using these images
as seeds. We assumed a uniform distribution for the
a parameter b. Figure 8 shows the examples of the
synthesized pedestrian images.
3.3 Performance Evaluation
The performance was evaluated by ROC curves rep-
resenting the relationship between the detection rate
and the false positives per frame. The detection rate
was measured by evaluating the overlap between the
detection result and the ground-truth labeled manu-
ally. The ROC curves were drawn by changing the
threshold ε introduced in section 2.3.
To confirm the performance of the proposed
method, we compared the proposed method with
VISAPP 2012 - International Conference on Computer Vision Theory and Applications
570
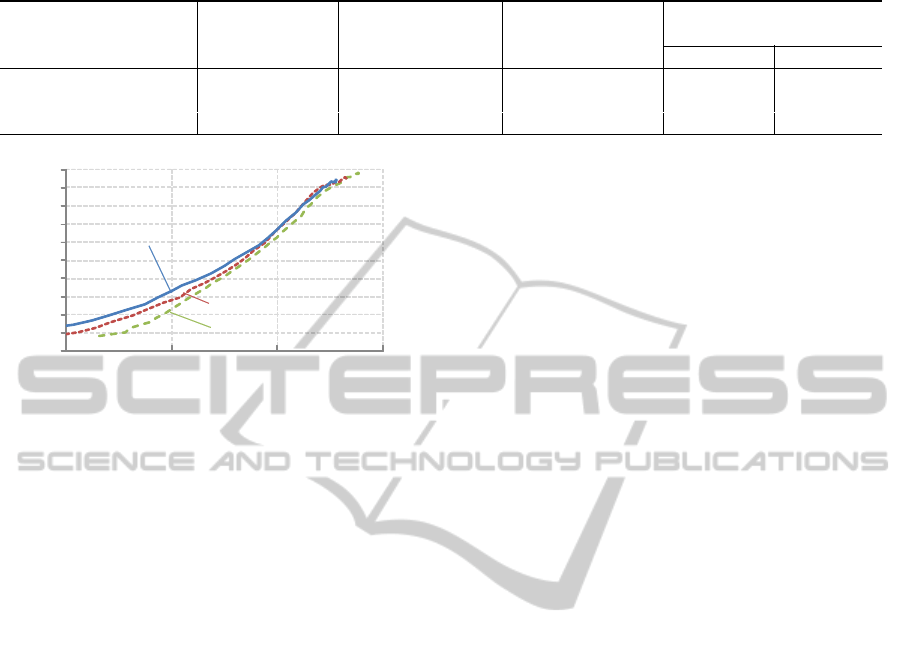
Table 1: Specifications of the proposed method and the comparative methods.
Methods Generation of Classifier Initial inputs of Num. of images used for
training images pedestrian images construction of classifiers
Ped. Non-Ped.
Proposed method yes multiple two-class 200 15,660 35,500
Comparative method 1
yes simple two-class 200 15,660 35,500
Comparative method 2
no simple two-class 15,660 15,660 35,500
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
0.01 0.10 1.00 10.00
Detection rate
False positive per frame
Comparative method 1
Proposed method
Comparative method 2
Figure 9: ROC curves of the proposed method and the com-
parative methods.
three comparative methods. Table 1 shows the spec-
ifications of the proposed method and the compara-
tive methods. The proposed method used 15,660 syn-
thesized pedestrian images (generated from only 200
pedestrian images) and 35,500 non-pedestrian images
to construct the multiple classifiers. Although the
comparative method 1 used the same images with
the proposed method, it applied a simple two-class
classifier. The comparative method 2 used 15,660
pedestrian images including the initial inputs of the
proposed method obtained manually. These methods
were simpler versions of a previous work (Enzweiler
et al., 2009), where they did not employ bootstrapping
iteration when gathering negative samples, compared
to the original method. Since it is difficult to segment
pedestrian regions manually from 15,660 pedestrian
images due to its cost, we could not compare the per-
formance with their multiple classifier versions using
all pedestrian images.
3.4 Results and Discussions
Figure 9 shows the ROC curves of the three methods.
The proposed method and the comparative method
1 outperformed the comparative method 2. Fig-
ure 10 shows examples of the detection results where
the proposed method and the comparative method 1
could detect pedestrians correctly but the comparative
method 2 could not. Here, each result is the result
from a classifier giving the highest performance (F-
measure) for each method.
As can be seen in the first and the second columns
of Fig. 10, although the comparative method 2 could
not detect pedestrians, the proposed method and the
comparative method 1 could detect pedestrians cor-
rectly. In general, to detect pedestrians with complex
backgrounds, the classifier should be trained by us-
ing various training samples including complex back-
grounds. Since the comparative method 2 could not
train various complex backgrounds, it could not de-
tect such pedestrians. In contrast, since the proposed
method and the comparative method 1 synthesized
various pedestrian images with various backgrounds,
these pedestrians could be detected correctly. Also,
the proposed method and the comparative method 1
synthesized variously posed pedestrians for training.
Therefore, these method could also detect pedestrians
whose poses were not included in the initial pedes-
trian images. Thus, we can say that the generative
learning method outperformed the simple gathering
method for the controlled synthesis.
As can be seen in Fig. 9, the performance of
the proposed method outperformed the comparative
method 1. The detection results of these methods
are shown in Fig. 10. From these results, we can
say that the proposed method could detect variously
posed pedestrians in comparison with the comparative
method 1. Especially, it can be observed that the pro-
posed method could detect not only walking pedes-
trians but also standing posed pedestrians. Since the
proposed method constructed multiple classifiers op-
timized for various poses, the detection performance
improved against variously posed pedestrians.
In the proposed method, outputs of the con-
structed multiple classifiers were simply combined by
taking the maximum of the detection scores. How-
ever, the detection performance may be highly af-
fected by an incorrect output of a classifier. There-
fore, we will investigate other methods for combining
the outputs from multiple classifiers.
4 CONCLUSIONS
This paper proposed a novel method for detecting var-
iously posed pedestrians. The proposed method con-
structed multiple classifiers optimized for each pose
INTEGRATION OF GENERATIVE LEARNING AND MULTIPLE POSE CLASSIFIERS FOR PEDESTRIAN
DETECTION
571

(a)
(b)
(c)
Figure 10: Comparison of the detection results; (a) Proposed method, (b) Comparative method 1, and (c) Comparative method
2.
of pedestrians. Also, the proposed method introduced
a generative learning method to reduce the bias and
the cost for preparing numerous pedestrian images for
each pose.
Next, we evaluated the performance of the pro-
posed method by applying it to in-vehicle camera
images, where the proposed method outperformed
the performance of the comparative methods. We
also confirmed that the proposed method could detect
pedestrians with various poses stably.
Future work includes the evaluation of the perfor-
mance by changing the number of initial pedestrian
images and the investigation of other methods for
combining the outputs of multiple classifiers by con-
sidering the actual distribution of pedestrian poses.
ACKNOWLEDGEMENTS
We give a special thanks to the members of Murase
laboratory at Nagoya University. Parts of this re-
search were supported by JST CREST and MEXT
Grant-in-Aid for Scientific Research. This work
was developed based on the MIST library (http://
mist.murase.m.is.nagoya-u.ac.jp/).
REFERENCES
Cootes, T. F., Taylor, C. J., Cooper, D. H., and Graham, J.
(1995). Active shape models. Their training and ap-
plication. Computer Vision and Image Understanding,
61:38–59.
Dalal, N. and Triggs, B. (2005). Histograms of oriented gra-
dients for human detection. In Proceedings of 2005
IEEE Computer Society Conference on Computer Vi-
sion and Pattern Recognition, volume 1, pages 886–
893.
Doman, K., Deguchi, D., Takahashi, T., Mekada, Y., Ide,
I., and Murase, H. (2009). Construction of cascaded
traffic sign detector using generative learning. In Pro-
ceedings of 4th International Conference on Innova-
tive Computing, Information and Control, pages 889–
892.
Enzweiler, M. and Gavrila, D. M. (2008). A mixed
generative-discriminative framework for pedestrian
classification. In Proceedings of 2008 IEEE Computer
Society Conference on Computer Vision and Pattern
Recognition, pages 1–8.
Enzweiler, M., Member, S., IEEE, and Gavrila, D. M.
(2009). Monocular pedestrian detection: Survey and
expreriments. IEEE Transactions on Pattern Analysis
and Machine Intelligence, 31(12):2179–2195.
Gavrila, D. M. and Giebel, J. (2001). Virtual sample gener-
ation for template-based shape matching. In Proceed-
ings of 2001 IEEE Computer Society Conference on
Computer Vision and Pattern Recognition, volume 1,
pages 676–681.
Murase, H. (1996). Learning by a generation approach
to appearance-based object recognition. In Proceed-
ings of the 13th International Conference on Pattern
Recognition, volume 1, pages 24–29.
Noda, M., Takahashi, T., Deguchi, D., Ide, I., Murase, H.,
Kojima, Y., and Naito, T. (2009). Recognition of road
markings from in-vehicle camera images by a genera-
tive learning method. In Proceedings of the 11th IAPR
Conference on Machine Vision Applications, pages
514–517.
VISAPP 2012 - International Conference on Computer Vision Theory and Applications
572
