
DISTANCE FEATURES FOR GENERAL GAME PLAYING AGENTS
Daniel Michulke
1
and Stephan Schiffel
2
1
Department of Computer Science, Dresden University of Technology, Dresden, Germany
2
School of Computer Science, Reykjav
´
ık University, Reykjav
´
ık, Iceland
Keywords:
General game playing, Feature construction, Heuristic search.
Abstract:
General Game Playing (GGP) is concerned with the development of programs that are able to play previously
unknown games well. The main problem such a player is faced with is to come up with a good heuristic
evaluation function automatically. Part of these heuristics are distance measures used to estimate, e.g., the
distance of a pawn towards the promotion rank. However, current distance heuristics in GGP are based on too
specific detection patterns as well as expensive internal simulations, they are limited to the scope of totally
ordered domains and/or they apply a uniform Manhattan distance heuristics regardless of the move pattern of
the object involved.
In this paper we describe a method to automatically construct distance measures by analyzing the game rules.
The presented method is an improvement to all previously presented distance estimation methods, because it
is not limited to specific structures, such as, Cartesian game boards. Furthermore, the constructed distance
measures are admissible.
We demonstrate how to use the distance measures in an evaluation function of a general game player and show
the effectiveness of our approach by comparing with a state-of-the-art player.
1 INTRODUCTION
While in classical game playing, human experts en-
code their knowledge into features and parameters of
evaluation functions (e.g., weights), the goal of Gen-
eral Game Playing is to develop programs that are
able to autonomously derive a good evaluation func-
tion for a game given only the rules of the game. Be-
cause the games are unknown beforehand, the main
problem lies in the detection and construction of use-
ful features and heuristics for guiding search in the
match.
One class of such features are distance features
used in a variety of GGP agents (e.g., (Kuhlmann
et al., 2006; Schiffel and Thielscher, 2007; Clune,
2007; Kaiser, 2007)). The way of detecting and con-
structing features in current game playing systems,
however, suffers from a variety of disadvantages:
• Distance features require a prior recognition of
board-like game elements. Current approaches
formulate hypotheses about which element of the
game rules describes a board and then either
check these hypotheses in internal simulations of
the game (e.g., (Kuhlmann et al., 2006; Schif-
fel and Thielscher, 2007; Kaiser, 2007)) or try
to prove them (Schiffel and Thielscher, 2009a).
Both approaches are expensive and can only de-
tect boards if their description follows a certain
syntactic pattern.
• Distance features are limited to Cartesian board-
like structures, that is, n-dimensional structures
with totally ordered coordinates. Distances over
general graphs are not considered.
• Distances are calculated using a predefined met-
ric on the boards. Consequently, distance values
obtained do not depend on the type of piece in-
volved. For example, using a predefined metric
the distance of a rook, king and pawn from a2
to c2 would appear equal while a human would
identify the distance as 1, 2 and ∞ (unreachable),
respectively.
In this paper we will present a more general ap-
proach for the construction of distance features for
general games. The underlying idea is to analyze the
rules of game in order to find dependencies between
the fluents of the game, i.e., between the atomic prop-
erties of the game states. Based on these dependen-
cies, we define a distance function that computes an
admissible estimate for the number of steps required
to make a certain fluent true. This distance function
127
Michulke D. and Schiffel S..
DISTANCE FEATURES FOR GENERAL GAME PLAYING AGENTS.
DOI: 10.5220/0003744001270136
In Proceedings of the 4th International Conference on Agents and Artificial Intelligence (ICAART-2012), pages 127-136
ISBN: 978-989-8425-95-9
Copyright
c
2012 SCITEPRESS (Science and Technology Publications, Lda.)

can be used as a feature in search heuristics of GGP
agents. In contrast to previous approaches, our ap-
proach does not depend on syntactic patterns and in-
volves no internal simulation or detection of any pre-
defined game elements. Moreover, it is not limited to
board-like structures but can be used for every fluent
of a game.
The remainder of this paper is structured as fol-
lows: In the next section we give an introduction
to the Game Description Language (GDL), which is
used to describe general games. Furthermore, we
briefly present the methods currently applied for dis-
tance feature detection and distance estimation in the
field of General Game Playing. In Section 3 we in-
troduce the theoretical basis for this work, so called
fluent graphs, and show how to use them to derive dis-
tances from states to fluents. We proceed in Section 4
by showing how fluent graphs can be constructed
from a game description and demonstrate their appli-
cation in Section 5. Finally, we conduct experiments
in Section 6 to show the benefit and generality of our
approach and discuss and summarize the results in
Section 9.
2 PRELIMINARIES
The language used for describing the rules of gen-
eral games is the Game Description Language (Love
et al., 2008) (GDL). GDL is an extension of Datalog
with functions, equality, some syntactical restrictions
to preserve finiteness, and some predefined keywords.
The following is a partial encoding of a Tic-Tac-
Toe game in GDL. In this paper we use Prolog syntax
where words starting with upper-case letters stand for
variables and the remaining words are constants.
1 role( xp l a yer ). role( o play e r ).
2
3 init( cell (1 ,1, b ) ) . init( cell (1 ,2 , b )).
4 init( cell (1 ,3, b ) ) . ...
5 init( cell (3 ,3, b ) ) .
6 init( co n t rol ( xp l a yer ) ) .
7
8 legal(P , mark (X , Y ) ) : -
9 true( c ontr o l ( P )) , true( c e l l ( X , Y , b )).
10 legal(P , noop ) : -
11 role(P ) , not true( c o n trol ( P ) ) .
12
13 next( cell (X ,Y , x )) : -
14 does( x p l a y e r , m a r k ( X , Y ) ) .
15 next( cell (X ,Y , o )) : -
16 does( o p l a y e r , m a r k ( X , Y ) ) .
17 next( cell (X ,Y , C )) : -
18 true( c e l l ( X , Y , C )) , distinct(C , b ) .
19 next( cell (X ,Y , b )) : - true( c e l l ( X , Y , b )) ,
20 does(P , m a r k ( M , N )) ,
21 (distinct( X , M ) ; distinct(Y, N ) ) .
22
23 goal( xplayer , 100 ) : - line (x ).
24 ...
25 terminal : -
26 l i n e ( x) ; line (o ) ; not open .
27
28 line ( P ) :-
29 true( c e l l ( X ,1 , P )) ,
30 true( c e l l ( X ,2 , P )) ,
31 true( c e l l ( X ,3 , P )).
32 ...
33 open : - true( c e l l ( X ,Y ,b )).
The first line declares the roles of the game. The
unary predicate init defines the properties that are
true in the initial state. Lines 8-11 define the legal
moves of the game with the help of the keyword legal.
For example, mark(X,Y) is a legal move for role P if
control(P) is true in the current state (i.e., it’s P’s turn)
and the cell X,Y is blank (cell(X,Y,b)). The rules for
predicate next define the properties that hold in the
successor state, e.g., cell(M,N,x) holds if xplayer marked
the cell M,N and cell(M,N,b) does not change if some cell
different from M,N was marked
1
. Lines 23 to 26 define
the rewards of the players and the condition for termi-
nal states. The rules for both contain auxiliary pred-
icates line(P) and open which encode the concept of a
line-of-three and the existence of a blank cell, respec-
tively.
We will refer to the arguments of the GDL key-
words init, true and next as fluents. In the above
example, there are two different types of fluents,
control(X) with X ∈ {xplayer, oplayer} and cell(X, Y, Z)
with X, Y ∈ {1, 2, 3} and Z ∈ {b, x, o}.
In (Schiffel and Thielscher, 2009b), we defined a
formal semantics of a game described in GDL as a
state transition system:
Definition 1. (Game). Let Σ be a set of ground terms
and 2
Σ
denote the set of finite subsets of Σ. A game
over this set of ground terms Σ is a state transition
system Γ = (R,s
0
,T,l, u,g) over sets of states S ⊆ 2
Σ
and actions A ⊆ Σ with
• R ⊆ Σ, a finite set of roles;
• s
0
∈ S , the initial state of the game;
• T ⊆ S , the set of terminal states;
• l : R × A × S , the legality relation;
• u : (R 7→ A ) × S → S , the transition or update
function; and
• g : R × S 7→ N, the reward or goal function.
This formal semantics is based on a set of ground
terms Σ. This set is the set of all ground terms over
1
The special predicate distinct(X,Y) holds if the terms
X and Y are syntactically different.
ICAART 2012 - International Conference on Agents and Artificial Intelligence
128
the signature of the game description. Hence, fluents,
actions and roles of the game are ground terms in Σ.
States are finite sets of fluents, i.e., finite subsets of
Σ. The connection between a game description D and
the game Γ it describes is established using the stan-
dard model of the logic program D. For example, the
update function u is defined as
u(A,s) = { f ∈ Σ : D ∪ s
true
∪ A
does
|= next( f )}
where s
true
and A
does
are suitable encodings of the
state s and the joint action A of all players as a logic
program. Thus, the successor state u(A,s) is the set
of all ground terms (fluents) f such that next( f ) is
entailed by the game description D together with the
state s and the joint move A. For a complete definition
for all components of the game Γ we refer to (Schiffel
and Thielscher, 2009b).
3 FLUENT GRAPHS
Our goal is to obtain knowledge on how fluents evolve
over time. We start by building a fluent graph that
contains all the fluents of a game as nodes. Then we
add directed edges ( f
i
, f ) if at least one of the prede-
cessor fluents f
i
must hold in the current state for the
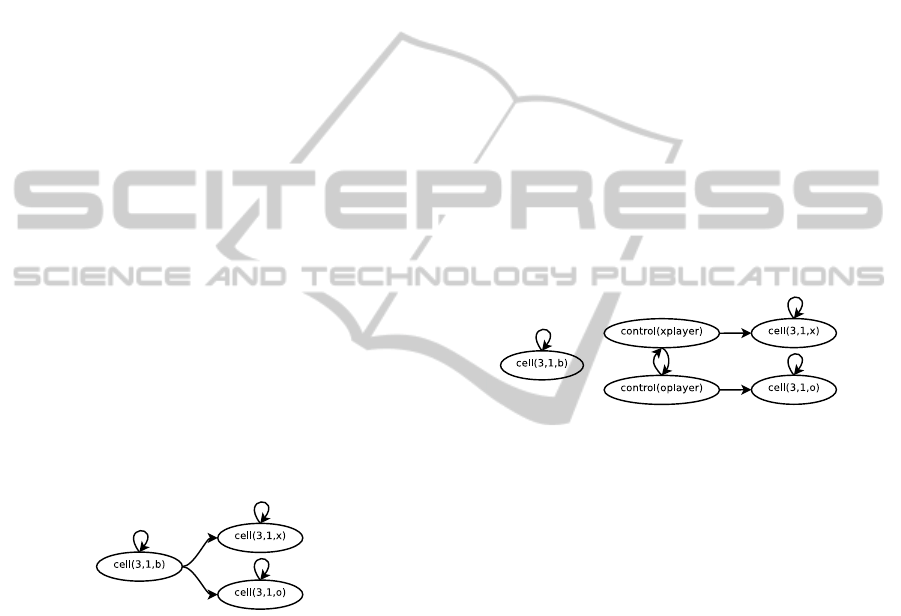
fluent f to hold in the successor state. Figure 1 shows
a partial fluent graph for Tic-Tac-Toe that relates the
fluents cell(3,1,Z) for Z ∈ {b, x, o}.
Figure 1: Partial fluent graph for Tic-Tac-Toe.
For cell (3,1) to be blank it had to be blank before.
For a cell to contain an x (or an o) in the successor
state there are two possible preconditions. Either, it
contained an x (or o) before or it was blank.
Using this graph, we can conclude that, e.g., a
transition from cell(3,1,b) to cell(3,1,x) is possible
within one step while a transition from cell(3,1,o) to
cell(3,1,x) is impossible.
To build on this information, we formally define a
fluent graph as follows:
Definition 2. (Fluent Graph). Let Γ be a game over
ground terms Σ. A graph G = (V, E) is called a fluent
graph for Γ iff
• V = Σ ∪ {
/
0} and
• for all fluents f ∈ Σ, two valid states s and s
0
(s
0
is a successor of s) ∧ f
0
∈ s
0
(1)
⇒ (∃ f )( f , f
0
) ∈ E ∧ ( f ∈ s ∪ {
/
0})
In this definition we add an additional node
/
0
to the graph and allow
/
0 to occur as the source of
edges. The reason is that there can be fluents in
the game that do not have any preconditions, for
example the fluent g with the following next rule:
next(g) :- distinct(a,b). On the other hand, there
might be fluents that cannot occur in any state, be-
cause the body of the corresponding next rule is un-
satisfiable, for example: next(h) :- distinct(a,a). We
distinguish between fluents that have no precondition
(such as g) and fluents that are unreachable (such as
h) by connecting the former to the node
/
0 while un-
reachable fluents have no edge in the fluent graph.
Note that the definition covers only some of the
necessary preconditions for fluents, therefore fluent
graphs are not unique as Figure 2 shows. We will
address this problem later.
Figure 2: Alternative partial fluent graph for Tic-Tac-Toe.
We can now define a distance function ∆(s, f
0
) be-
tween the current state s and a state in which fluent f
0
holds as follows:
Definition 3. (Distance Function). Let ∆
G
( f , f
0
) be
the length of the shortest path from node f to node
f
0
in the fluent graph G or ∞ if there is no such path.
Then
∆(s, f
0
) = min
f ∈s∪{
/
0}
∆
G
( f , f
0
)
That means, we compute the distance ∆(s, f
0
) as
the shortest path in the fluent graph from any fluent in
s to f
0
.
Intuitively, each edge ( f , f
0
) in the fluent graph
corresponds to a state transition of the game from a
state in which f holds to a state in which f
0
holds.
Thus, the length of a path from f to f
0
in the fluent
graph corresponds to the number of steps in the game
between a state containing f to a state containing f
0
.
Of course, the fluent graph is an abstraction of the
actual game: many preconditions for the state tran-
sitions are ignored. As a consequence, the distance
∆(s, f
0
) that we compute in this way is a lower bound
on the actual number of steps it takes to go from s
to a state in which f
0
holds. Therefore the distance
DISTANCE FEATURES FOR GENERAL GAME PLAYING AGENTS
129

∆(s, f
0
) is an admissible heuristic for reaching f
0
from
a state s.
Theorem 1. (Admissible Distance). Let
• Γ = (R,s
0
,T,l, u,g) be a game with ground terms
Σ and states S ,
• s
1
∈ S be a state of Γ,
• f ∈ Σ be a fluent of Γ, and
• G = (V,E) be a fluent graph for Γ.
Furthermore, let s
1
7→ s
2
7→ . .. 7→ s
m+1
denote a legal
sequence of states of Γ, that is, for all i with 0 < i ≤ m
there is a joint action A
i
, such that:
s
i+1
= u(A
i
,s
i
) ∧ (∀r ∈ R)l(r, A
i
(r), s)
If ∆(s
1
, f ) = n, then there is no legal sequence of
states s
1
7→ .. . 7→ s
m+1
with f ∈ s
m+1
and m < n.
Proof. We prove the theorem by contradiction. As-
sume that ∆(s
1
, f ) = n and there is a a legal sequence
of states s
1
7→ ... 7→ s
m+1
with f ∈ s
m+1
and m < n.
By Definition 2, for every two consecutive states s
i
,
s
i+1
of the sequence s
1
7→ ... 7→ s
m+1
and for ev-
ery f
i+1
∈ s
i+1
there is an edge ( f
i
, f
i+1
) ∈ E such
that f
i
∈ s
i
or f
i
=
/
0. Therefore, there is a path
f
j
,. .., f
m
, f
m+1
in G with 1 ≤ j ≤ m and the following
properties:
• f
i
∈ s
i
for all i = j,...,m + 1,
• f
m+1
= f , and
• either f
j
∈ s
1
(e.g., if j = 1) or f
j
=
/
0.
Thus, the path f
j
,. .., f
m
, f
m+1
has a length of at most
m. Consequently, ∆(s
1
, f ) ≤ m because f
j
∈ s
1
∪ {
/
0}
and f
m+1
= f . However, ∆(s
1
, f ) ≤ m together with
m < n contradicts ∆(s
1
, f ) = n.
4 CONSTRUCTING FLUENT
GRAPHS FROM RULES
We propose an algorithm to construct a fluent graph
based on the rules of the game. The transitions of
a state s to its successor state s
0
are encoded fluent-
wise via the next rules. Consequently, for each f
0
∈ s
0
there must be at least one rule with the head next(f’).
All fluents occurring in the body of these rules are
possible sources for an edge to f
0
in the fluent graph.
For each ground fluent f
0
of the game:
1. Construct a ground disjunctive normal form φ of
next( f
0
), i.e., a formula φ such that next( f
0
) ⊃ φ.
2. For every disjunct ψ in φ:
• Pick one literal true( f ) from ψ or set f =
/
0 if
there is none.
• Add the edge ( f , f
0
) to the fluent graph.
Note, that we only select one literal from each dis-
junct in φ. Since, the distance function ∆(s, f
0
) ob-
tained from the fluent graph is admissible, the goal is
to construct a fluent graph that increases the lengths of
the shortest paths between the fluents as much as pos-
sible. Therefore, the fluent graph should contain as
few edges as possible. In general the complete fluent
graph (i.e., the graph where every fluent is connected
to every other fluent) is the least informative because
the maximal distance obtained from this graph is 1.
The algorithm outline still leaves some open is-
sues:
1. How do we construct a ground formula φ that is
the disjunctive normal form of next( f
0
)?
2. Which literal true( f ) do we select if there is
more than one? Or, in other words, which pre-
condition f
0
of f do we select?
We will discuss both issues in the following sec-
tions.
4.1 Constructing a DNF of next(f
0
)
A formula φ in DNF is a set of formulas {ψ
1
,. .., ψ
n
}
connected by disjunctions such that each formula ψ
i
is a set of literals connected by conjunctions. We pro-
pose the algorithm in Figure 1 to construct φ such that
next( f
0
) ⊃ φ.
The algorithm starts with φ = next( f
0
). Then,
it selects a positive literal l in φ and unrolls this lit-
eral, that is, it replaces l with the bodies of all rules
h:-b ∈ D whose head h is unifiable with l with a most
general unifier σ (lines 9, 10). The replacement is re-
peated until all predicates that are left are either of the
form true(t), distinct(t
1
,t
2
) or recursively defined.
Recursively defined predicates are not unrolled to en-
sure termination of the algorithm. Finally, we trans-
form φ into disjunctive normal form and replace each
disjunct ψ
i
of φ by a disjunction of all of its ground
instances in order to get a ground formula φ.
Note that in line 4, we replace every occurrence
of does with legal to also include the preconditions
of the actions that are executed in φ. As a conse-
quence the resulting formula φ is not equivalent to
next( f
0
). However, next( f
0
) ⊃ φ, under the as-
sumption that only legal moves can be executed, i.e.,
does(r,a) ⊃ legal(r, a). This is sufficient for con-
structing a fluent graph from φ.
Note, that we do not select negative literals for un-
rolling. The algorithm could be easily adapted to also
unroll negative literals. However, in the games we
encountered so far, doing so does not improve the ob-
tained fluent graphs but complicates the algorithm and
increases the size of the created φ. Unrolling negative
ICAART 2012 - International Conference on Agents and Artificial Intelligence
130

Algorithm 1: Constructing a formula φ in DNF with
next( f
0
) ⊃ φ.
Input: game description D, ground fluent f
0
Output: φ, such that next( f
0
) ⊃ φ
1: φ := next( f
0
)
2: f inished := f alse
3: while ¬ finished do
4: Replace every positive occurrence of
does(r,a) in φ with legal(r, a).
5: Select a positive literal l from φ such that l 6=
true(t), l 6= distinct(t
1
,t
2
) and l is not a re-
cursively defined predicate.
6: if there is no such literal then
7: f inished := true
8: else
9:
ˆ
l :=
W
h:-b∈D,lσ=hσ
bσ
10: φ := φ{l/
ˆ
l}
11: end if
12: end while
13: Transform φ into disjunctive normal form, i.e.,
φ = ψ
1
∨ .. . ∨ ψ
n
and each formula ψ
i
is a con-
junction of literals.
14: for all ψ
i
in φ do
15: Replace ψ
i
in φ by a disjunction of all ground
instances of ψ
i
.
16: end for
literals will mainly add negative preconditions to φ.
However, negative preconditions are not used for the
fluent graph because a fluent graph only contains pos-
itive preconditions of fluents as edges, according to
Definition 2.
4.2 Selecting Preconditions for the
Fluent Graph
If there are several literals of the form true( f ) in a
disjunct ψ of the formula φ constructed above, we
have to select one of them as source of the edge in
the fluent graph. As already mentioned, the distance
∆(s, f ) computed with the help of the fluent graph is
a lower bound on the actual number of steps needed.
To obtain a good lower bound, that is one that is as
large as possible, the paths between nodes in the fluent
graph should be as long as possible. Selecting the best
fluent graph, i.e., the one which maximizes the dis-
tances, is impossible. Which fluent graph is the best
one depends on the states we encounter when playing
the game, but we do not know these states beforehand.
In order to generate a fluent graph that provides good
distance estimates, we use several heuristics when we
select literals from disjuncts in the DNF of next( f
0
):
First, we only add new edges if necessary. That
means, whenever there is a literal true( f ) in a dis-
junct ψ such that the edge ( f , f
0
) already exists in the
fluent graph, we select this literal true( f ). The ratio-
nale of this heuristic is that paths in the fluent graph
are longer on average if there are fewer connections
between the nodes.
Second, we prefer a literal true( f ) over true(g)
if f is more similar to f
0
than g is to f
0
, that is
sim( f , f
0
) > sim(g, f
0
).
We define the similarity sim(t,t
0
) recursively over
ground terms t,t
0
:
sim(t,t
0
) =
1 t,t
0
have arity 0 and t = t
0
∑
i
sim(t
i
,t
0
i
) t = f (t
1
,. ..,t
n
) and
t
0
= f (t
0
1
,. ..,t
0
n
)
0 else
In human made game descriptions, similar fluents
typically have strong connections. For example, in
Tic-Tac-Toe cell(3,1,x) is more related to cell(3,1,b)
than to cell(b,3,x). By using similar fluents when
adding new edges to the fluent graph, we have a bet-
ter chance of finding the same fluent again in a dif-
ferent disjunct of φ. Thus we maximize the chance of
reusing edges.
5 APPLYING DISTANCE
FEATURES
For using the distance function in our evaluation func-
tion, we define the normalized distance δ(s, f ).
δ(s, f ) =
∆(s, f )
∆
max
( f )
The value ∆
max
( f ) is the longest distance ∆
G
(g, f )
from any fluent g to f , i.e.,
∆
max
( f )
def
= max
g
∆
G
(g, f )
where ∆
G
(g, f ) denotes the length of the shortest path
from g to f in the fluent graph G.
Thus, ∆
max
( f ) is the longest possible distance
∆(s, f ) that is not infinite. The normalized distance
δ(s, f ) will be infinite if ∆(s, f ) = ∞, i.e., there is no
path from any fluent in s to f in the fluent graph. In
all other cases it holds that 0 ≤ δ(s, f ) ≤ 1.
Note, that the construction of the fluent graph and
computing the shortest paths between all fluents, i.e.,
the distance function ∆
G
, need only be done once for a
game. Thus, while construction of the fluent graph is
more expensive for complex games, the cost of com-
puting the distance feature δ(s, f ) (or ∆(s, f )) only de-
pends (linearly) on the size of the state s.
DISTANCE FEATURES FOR GENERAL GAME PLAYING AGENTS
131

5.1 Using Distance Features in an
Evaluation Function
To demonstrate the application of the distance mea-
sure presented, we use a simplified version of
the evaluation function of Fluxplayer (Schiffel and
Thielscher, 2007) implemented in Prolog. It takes the
ground DNF of the goal rules as first argument, the
current state as second argument and returns the fuzzy
evaluation of the DNF on that state as a result.
1 ev a l ( ( D1 ; ...; Dn ), S , R ) : - ! ,
2 e v a l ( D1 , S , R1 ) , ..., e v al ( Dn , S , Rn ) ,
3 R is sum ( R1 , ..., Rn ) -
4 p rod u c t (R1 , ..., Rn ).
5 ev a l ( ( C1 , ..., Cn ), S , R ) : - ! ,
6 e v a l ( C1 , S , R1 ) , ..., e v al ( Cn , S , Rn ) ,
7 R is pr o d uct ( R1 , ... , Rn ).
8 ev a l (not( P ) , S , R) : - ! ,
9 e v a l ( P , S , Rp ) , R is 1 - Rp .
10 ev a l (true( F ) , S , 0 . 9 ) : - oc c u r s (F , S ) , !.
11 ev a l (true( F ) , S , 0 . 1 ).
Disjunctions are transformed to probabilistic
sums, conjunctions to products, and true statements
are evaluated to values in the interval [0, 1], basically
resembling a recursive fuzzy logic evaluation using
the product t-norm and the corresponding probabilis-
tic sum t-conorm. The state value increases with each
conjunct and disjunct fulfilled.
We compare this basic evaluation to a second
function that employs our relative distance measure,
encoded as predicate delta. We obtain this distance-
based evaluation function by substituting line 11 of
the previous program by the following four lines:
1 ev a l (true( F ) , S , R) : -
2 d e lta (S , F , D i stan c e ),
3 D ist a n ce = < 1 , ! ,
4 R is 0.8*(1 - Dis t ance ) + 0.1.
5 ev a l (true( F ) , S , 0).
Here, we evaluate a fluent that does not occur in the
current state to a value in [0.1,0.9] and, in case the
relative distance is infinite, to 0 since this means that
the fluent cannot hold anymore.
5.2 Tic-Tac-Toe
state s
1
state s
2
Figure 3: Two states of the Tic-Tac-Toe. The first row is
still open in state s
1
but blocked in state s
2
.
Although on first sight Tic-Tac-Toe contains no
relevant distance information, we can still take advan-
tage of our distance function. Consider the two states
as shown in Figure 3. In state s
1
the first row con-
sists of two cells marked with an x and a blank cell.
In state s
2
the first row contains two xs and one cell
marked with an o. State s
1
has a higher state value
than s
2
for xplayer since in s
1
xplayer has a threat of
completing a line in contrast to s
2
. The corresponding
goal condition for xplayer completing the first row is:
1 li n e ( x ) : - true( c e l l (1 ,1 , x )) ,
2 true( c e l l (2 ,1 , x )) , true( c ell (3 ,1 , x ) ) .
When evaluating the body of this condition using
our standard fuzzy evaluation, we see that it cannot
distinguish between s
1
and s
2
because both have two
markers in place and one missing for completing the
line for xplayer. Therefore it evaluates both states to
1 ∗ 1 ∗ 0.1 = 0.1.
However, the distance-based function evaluates
true(cell(3,1,b)) of s
1
to 0.1 and true(cell(3,1,o)) of s
2
to 0. Therefore, it can distinguish between both states,
returning R = 0.1 for S = s
1
and R = 0 for S = s
2
.
5.3 Breakthrough
The second game is Breakthrough, again a two-player
game played on a chessboard. Like in chess, the
first two ranks contain only white pieces and the last
two only black pieces. The pieces of the game are
only pawns that move and capture in the same way
as pawns in chess, but without the initial double ad-
vance. Whoever reaches the opposite side of the
board first wins.
2
Figure 4 shows the initial position
for Breakthrough. The arrows indicate the possible
moves, a pawn can make.
The goal condition for the player black states that
black wins if there is a cell with the coordinates X,1
and the content black, such that X is an index (a number
from 1 to 8 according to the rules of index):
1 goal( black , 100) : -
2 i n dex (X ),true( c ell h o lds ( X , 1 , black )).
Grounding this rule yields
1 goal( black , 100) : -
2 true( c ell h old s (1 , 1 , bla c k ) ; ...;
3 true( c ell h old s (8 , 1 , bla c k )).
We omitted the index predicate since it is true for all 8
ground instances.
2
The complete rules for Breakthrough as well as Tic-
Tac-Toe can be found under http://ggpserver.general-game-
playing.de/.
ICAART 2012 - International Conference on Agents and Artificial Intelligence
132

The standard evaluation function cannot distin-
guish any of the states in which the goal is not reached
because true(cellholds(X, 1, black)) is false in all of
these states for any instance of X.
The distance-based evaluation function is based
on the fluent graph depicted in Figure 5.
Figure 4: Initial position in Breakthrough and the move op-
tions of a pawn.
Figure 5: A partial fluent graph for Breakthrough, role
black.
Obviously it captures the way pawns move in
chess. Therefore evaluations of atoms of the form
true(cellholds(X, Y, black)) have now 9 possible values
(for distances 0 to 7 and ∞) instead of 2 (true and
false). Hence, states where black pawns are nearer
to one of the cells (1,8), .. ., (8,8) are preferred.
Moreover, the fluent graph, and thus the distance
function, contains the information that some locations
are only reachable from certain other locations. To-
gether with our evaluation function this leads to what
could be called “strategic positioning”: states with
pawns on the side of the board are worth less than
those with pawns in the center. This is due to the fact
that a pawn in the center may reach more of the 8 pos-
sible destinations than a pawn on the side.
6 EVALUATION
For evaluation, we implemented our distance function
and equipped the agent system Fluxplayer (Schiffel
and Thielscher, 2007) with it. We then set up this
version of Fluxplayer (“flux distance”) against its ver-
sion without the new distance function (“flux basic”).
We used the version of Fluxplayer that came in 4th
in the 2010 championship. Since flux basic is already
endowed with a distance heuristic, the evaluation is
comparable to a competition setting of two compet-
ing heuristics using distance features.
We chose 19 games for comparison in which we
conducted 100 matches on average. Figure 6 shows
the results.
pawn_whopping
battle
breakthrough
3pffa
four_way_battle
chinesecheckers3
point_grab
lightsout
catch_a_mouse
doubletictactoe
tictactoe
racetrackcorridor
smallest_4player
chickentictactoe
capture_the_king
chinesecheckers2
nim4
breakthroughsuicide_v2
knightthrough
-60 -40 -20 0 20 40 60
pawn_whopping
battle
breakthrough
3pffa
four_way_battle
chinesecheckers3
point_grab
lightsout
catch_a_mouse
doubletictactoe
tictactoe
racetrackcorridor
smallest_4player
chickentictactoe
capture_the_king
chinesecheckers2
nim4
breakthroughsuicide_v2
knightthrough
-60 -40 -20 0 20 40 60
Figure 6: Advantage in Win Rate of flux distance.
The values indicate the difference in win rate, e.g.,
a value of +10 indicates that flux distance won 55%
of the games against flux basic winning 45%. Obvi-
ously the proposed heuristics produces results com-
parable to the flux basic heuristics, with both having
advantages in some games. This has several reasons:
Most importantly, our proposed heuristic, in the way
it is implemented now, is more expensive than the
distance estimation used in flux basic. Therefore the
evaluation of a state takes longer and the search tree
can not be explored as deeply as with cheaper heuris-
tics. This accounts for three of the four underper-
forming games. For example in nim4, the flux basic
DISTANCE FEATURES FOR GENERAL GAME PLAYING AGENTS
133

distance estimation provides essentially the same re-
sults as our new approach, just much cheaper. In chi-
nesecheckers2 and knightthrough, the new distance
function slows down the search more than its better
accuracy can compensate.
On the other hand, flux distance performs better
in complicated games. There the higher accuracy of
the heuristics typically outweighs the disadvantage of
the heuristics being slower.
Interestingly the higher accuracy of the new dis-
tance heuristics is the reason for flux distance los-
ing in breakthrough suicide. The game is exactly the
same as breakthrough, however, the player to reach
the other side of the board first does not win but loses.
The heuristics of both flux basic and flux distance
are not good for this game since both are based the
minimum number of moves necessary to reach the
goal while the optimal heuristic would depend on
the maximum number of moves available to avoid
losing. However, since flux distance is more ac-
curate, flux distance selects even worse moves that
flux basic. Specifically, flux distance tries to maxi-
mize (a much more accurate) minimal distance to the
other side of the board, thereby allowing the opponent
to capture its advanced pawns. This behavior, how-
ever, results in a smaller maximal number of moves
until the game ends and forces to advance the few
remaining pawns quickly. Thus, the problem in this
game is not the distance estimate but the fact that the
heuristic is not suitable for the game.
Finally, in some of the games no changes
were found since both distance estimates performed
equally well. However, rather specific heuristics and
analysis methods of flux basic could be replaced by
our new general approach. For example, the original
Fluxplayer contains a special method to detect when
a fluent is unreachable, while this information is au-
tomatically included in our distance estimate.
Apart from the above results, we intended to use
more games for evaluation, however, we found that
the fluent graph construction takes too much time in
some games where the next rules are complex. We
discuss these issues in Section 8.
7 RELATED WORK
Distance features are part of classical agent program-
ming for games like chess and checkers in order to
measure, e.g., the distance of a pawn to the promotion
rank. A more general detection mechanism was first
employed in Metagamer (Pell, 1993) where the fea-
tures “promote-distance” and “arrival-distance” rep-
resented a value indirectly proportional to the distance
of a piece to its arrival or promotion square. However,
due to the restriction on symmetric chess-like games,
boards and their representation were predefined and
thus predefined features could be applied as soon as
some promotion or arrival condition was found in the
game description.
Currently, a number of GGP agent sys-
tems apply distance features in different forms.
UTexas (Kuhlmann et al., 2006) identifies order
relations syntactically and tries to find 2d-boards with
coordinates ordered by these relations. Properties
of the content of these cells, such as minimal/max-
imal x- and y-coordinates or pair-wise Manhattan
distances are then assumed as candidate features
and may be used in the evaluation function. Flux-
player (Schiffel and Thielscher, 2007) generalizes
the detection mechanism using semantic properties
of order relations and extends board recognition to
arbitrarily defined n-dimensional boards.
Another approach is pursued by Clune-
player (Clune, 2007) who tries to impose a symbol
distance interpretation on expressions found in
the game description. Symbol distances, however,
are again calculated using Manhattan distances on
ordered arguments of board-like fluents, eventually
resulting in a similar distance estimate as UTexas and
Fluxplayer.
Although not explained in detail, Ogre (Kaiser,
2007) also employs two features that measure the dis-
tance from the initial position and the distance to a
target position. Again, Ogre relies on syntactic detec-
tion of order relations and seems to employ a board
centered metrics, ignoring the piece type.
All of these approaches rely on the identification
of certain fixed structures in the game (such as game
boards) but can not be used for fluents that do not
belong to such a structure. Furthermore, they make
assumptions about the distances on these structures
(usually Manhattan distance) that are not necessarily
connected to the game dynamics, e.g., how different
pieces move on a board.
In domain independent planning, distance heuris-
tics are used successfully, e.g., in HSP (Bonet and
Geffner, 2001) and FF (Hoffmann and Nebel, 2001).
The heuristics h(s) used in these systems is an ap-
proximation of the plan length of a solution in a re-
laxed problem, where negative effects of actions are
ignored. This heuristics is known as delete list re-
laxation. While on first glance this may seems very
similar to our approach, several differences exist:
• The underlying languages, GDL for general game
playing and PDDL for planning, are different. A
translation of GDL to PDDL is expensive in many
games (Kissmann and Edelkamp, 2010). Thus,
ICAART 2012 - International Conference on Agents and Artificial Intelligence
134

directly applying planning systems is not often not
feasible.
• The delete list relaxation considers all (positive)
preconditions of a fluent, while we only use one
precondition. This enables us to precompute the
distance between the fluents of a game.
• While goal conditions of most planning prob-
lems are simple conjunctions, goals in the general
games can be very complex (e.g., checkmate in
chess). Additionally, the plan length is usually not
a good heuristics, given that only the own actions
and not those of the opponents can be controlled.
Thus, distance estimates in GGP are usually not
used as the only heuristics but only as a feature in
a more complex evaluation function. As a conse-
quence, computing distance features must be rel-
atively cheap.
• Computing the plan length of the relaxed planning
problem is NP-hard, and even the approximations
used in HSP or FF that are not NP-hard require to
search the state space of the relaxed problem. On
the other hand, computing distance estimates with
our solution is relatively cheap. The distances
∆
G
( f ,g) between all fluents f and g in the fluent
graph can be precomputed once for a game. Then,
computing the distance ∆(s, f
0
) (see Definition 3)
is linear in the size of the state s, i.e., linear in the
number of fluents in the state.
8 FUTURE WORK
The main problem of the approach is its computa-
tional cost for constructing the fluent graph. The most
expensive steps of the fluent graph construction are
grounding of the DNF formulas φ and processing the
resulting large formulas to select edges for the fluent
graph. For many complex games, these steps cause
either out-of-memory or time-out errors. Thus, an im-
portant line of future work is to reduce the size of for-
mulas before the grounding step without losing rele-
vant information.
One way to reduce the size of φ is a more selec-
tive expansion of predicates (line 5) in Algorithm 1.
Developing heuristics for this selection of predicates
is one of the goals for future research.
In addition, we are working on a way to construct
fluent graphs from non-ground representations of the
preconditions of a fluent to skip the grounding step
completely. For example, the partial fluent graph in
Figure 1 is identical to the fluent graphs for the other
8 cells of the Tic-Tac-Toe board. The fluent graphs
for all 9 cells are obtained from the same rules for
next(cell(X,Y,_), just with different instances of the
variables X and Y. By not instantiating X and Y, the gen-
erated DNF is exponentially smaller while still con-
taining the same information.
The quality of the distance estimates depends
mainly on the selection of preconditions. At the mo-
ment, the heuristics we use for this selection are intu-
itive but have no thorough theoretic or empiric foun-
dation. In future, we want to investigate how these
heuristics can be improved.
Furthermore, we intend to enhance the approach
to use fluent graphs for generalizations of other types
of features, such as, piece mobility and strategic posi-
tions.
9 SUMMARY
We have presented a general method of deriving dis-
tance estimates in General Game Playing. To obtain
such a distance estimate, we introduced fluent graphs,
proposed an algorithm to construct them from the
game rules and demonstrated the transformation from
fluent graph distance to a distance feature.
Unlike previous distance estimations, our ap-
proach does not rely on syntactic patterns or internal
simulations. Moreover, it preserves piece-dependent
move patterns and produces an admissible distance
heuristic.
We showed on an example how these distance fea-
tures can be used in a state evaluation function. We
gave two examples on how distance estimates can im-
prove the state evaluation and evaluated our distance
against Fluxplayer in its most recent version.
Certain shortcomings should be addressed to im-
prove the efficiency of fluent graph construction and
the quality of the obtained distance function. Despite
these shortcomings, we found that a state evaluation
function using the new distance estimates can com-
pete with a state-of-the-art system.
REFERENCES
Bonet, B. and Geffner, H. (2001). Planning as heuristic
search. Artificial Intelligence, 129(1–2):5–33.
Clune, J. (2007). Heuristic evaluation functions for general
game playing. In AAAI, Vancouver. AAAI Press.
Hoffmann, J. and Nebel, B. (2001). The FF planning sys-
tem: Fast plan generation through heuristic search.
JAIR, 14:253–302.
Kaiser, D. M. (2007). Automatic feature extraction for
autonomous general game playing agents. In Pro-
ceedings of the Sixth Intl. Joint Conf. on Autonomous
Agents and Multiagent Systems.
DISTANCE FEATURES FOR GENERAL GAME PLAYING AGENTS
135

Kissmann, P. and Edelkamp, S. (2010). Instantiating gen-
eral games using prolog or dependency graphs. In
Dillmann, R., Beyerer, J., Hanebeck, U. D., and
Schultz, T., editors, KI, volume 6359 of Lecture Notes
in Computer Science, pages 255–262. Springer.
Kuhlmann, G., Dresner, K., and Stone, P. (2006). Automatic
Heuristic Construction in a Complete General Game
Player. In Proceedings of the Twenty-First National
Conference on Artificial Intelligence, pages 1457–62,
Boston, Massachusetts, USA. AAAI Press.
Love, N., Hinrichs, T., Haley, D., Schkufza, E., and Gene-
sereth, M. (2008). General game playing: Game de-
scription language specification. Technical Report
March 4, Stanford University. The most recent ver-
sion should be available at http://games.stanford.edu/.
Pell, B. (1993). Strategy generation and evaluation for
meta-game playing. PhD thesis, University of Cam-
bridge.
Schiffel, S. and Thielscher, M. (2007). Fluxplayer: A suc-
cessful general game player. In Proceedings of the
National Conference on Artificial Intelligence, pages
1191–1196, Vancouver. AAAI Press.
Schiffel, S. and Thielscher, M. (2009a). Automated theorem
proving for general game playing. In Proceedings of
the International Joint Conference on Artificial Intel-
ligence (IJCAI).
Schiffel, S. and Thielscher, M. (2009b). A multiagent se-
mantics for the game description language. In Fil-
ipe, J., Fred, A., and Sharp, B., editors, Interna-
tional Conference on Agents and Artificial Intelli-
gence (ICAART), Porto. Springer.
ICAART 2012 - International Conference on Agents and Artificial Intelligence
136
