
INEXACT GRAPH MATCHING THROUGH GRAPH COVERAGE
Lorenzo Livi, Guido Del Vescovo and Antonello Rizzi
Department of Information Engineering, Electronics and Telecommunications, SAPIENZA University,
Via Eudossiana 18, 00184 - Rome, Italy
Keywords:
Inexact graph matching, Graph kernels, Tensor product, Graph classification system.
Abstract:
In this paper we propose a novel inexact graph matching procedure called graph coverage, to be used in su-
pervised and unsupervised data driven modeling systems. It relies on tensor product between graphs, since
the resulting product graph is known to be able to encode the similarity of the two input graphs. The graph
coverage is defined on the basis of the concept of graph weight, computed on the weighted adjacency matrix
of the tensor product graph. We report the experimental results concerning two distinct performance evalu-
ations. Since for practical applications the computing time of any inexact graph matching procedure should
be feasible, the first tests have been conceived to measure the average computing time when increasing the
average size of a random sample of fully-labeled graphs. The second one aims to evaluating the accuracy of
the proposed dissimilarity measure when used as the core of a classification system based on the k-NN rule.
Overall the graph coverage shows encouraging results as a dissimilarity measure.
1 INTRODUCTION
A great number of Pattern Recognition problems
coming from real world applications must cope with
structured patterns, such as digital images, audio sig-
nals and chemical compounds, for instance. As a
result, each pattern can be represented as a labeled
graph, where vertices and edges are equipped with
complex labels, able to encode different kind of in-
formation. Indeed, developing classification systems
able to cope with labeled graphs is a fundamental
step. Consequently, the field of Graph-based Pattern
Recognition is growing fast, and is aimed to the estab-
lishment of efficient and effective Pattern Recognition
techniques on the domain of graphs. The generaliza-
tion capability of any classification system (being a
particular data driven modeling problem) strictly de-
pends on the way the inductive logic inference is de-
fined and computed, which in turn is fixed by choos-
ing a dissimilarity (or similarity) measure between in-
put patterns. Such a measure is therefore the most
important procedure in any inductive modeling sys-
tem. When dealing with graphs as input patterns, the
way we define a dissimilarity measure is not trivial,
especially in the case of fully-labeled graphs, where,
in general, vertices and edges can be even labeled
with complex data structures (text excerpts, audio se-
quences, images, and so on). Therefore, any dissim-
ilarity measure for graphs must be able to cope with
both topological and labels related information.
A labeled graph is a tuple G = (V, E, µ, ν) , where
V is the (finite) set of vertices, E ⊆ V ×V is the set of
edges, µ : V → L
V
is the vertex labeling function, with
L
V
the vertex-labels set and ν : E → L
E
is the edge la-
beling function, with L
E
the edge-labels set. The car-
dinalities of V and E are called the order and the size
of the graph, respectively. The adjacency matrix of
the graph is denoted with A, and if vertices, say v
i
, v
j
,
are connected by an edge e
i j
, we have A
i j
= 1, oth-
erwise 0. A (labeled) graph is said to be weighted if
L
E
⊆ R, with W
i j
= ν(e
i j
) known as the weighted ad-
jacency matrix. In the current scientific literature it is
possible to distinguish three mainstream approaches
for the inexact graph matching problem: Graph Edit
Distance (Neuhaus et al., 2006; Riesen and Bunke,
2009), Graph Embedding (Del Vescovo and Rizzi,
2007; Riesen and Bunke, 2010) and Graph Kernels
(Borgwardt et al., 2005; G
¨
artner, 2008). In the fol-
lowing we propose a dissimilarity measure between
graphs named Graph Coverage by defining a particu-
lar way to perform an inexact graph matching proce-
dure belonging to the graph kernels based family.
The paper is organized as follows. We explain the
proposed inexact graph matching procedure in Sec-
tion 2. In Section 3 we describe and discuss the tests
performed to evaluate performances considering both
269
Livi L., Del Vescovo G. and Rizzi A. (2012).
INEXACT GRAPH MATCHING THROUGH GRAPH COVERAGE.
In Proceedings of the 1st International Conference on Pattern Recognition Applications and Methods, pages 269-272
DOI: 10.5220/0003732802690272
Copyright
c
SciTePress

qualitative and quantitative indexes. Conclusions are
drawn in Section 4, where we give also possible future
directions for enhancing the computation efficiency.
2 THE PROPOSED INEXACT
GRAPH MATCHING MEASURE
In this section we will explain the proposed inexact
graph matching method, that fits well in the domain
of graph kernels. For this purpose, we will give a
briefly introduce the context of graph kernels and ten-
sor product of graphs.
A symmetric continuous function k : X × X → R
is called a positive definite kernel if
∑
n
i, j
c
i
c
j
k(x
i
, x
j
) ≥
0 holds, with c
i
, c
j
∈ R, for each finite n ≥ 2. Graph
kernels are functions defined over the domain of
graphs, X = G. They rely on the representation of the
graph in an implicitly defined high dimensional fea-
ture space. The reproducing property of valid kernel
functions is of fundamental importance in Machine
Learning and Pattern Recognition domains, and the
relation k(x, z) = hΦ(x), Φ(z)i, ∀x, z ∈ X , is referred
as the kernel trick (Sch
¨
olkopf and Smola, 2002). So,
the effort should be focused only to the definition of a
valid kernel function for the specific input domain X
(e.g. graphs, X = G).
The tensor product (also called direct product)
(Imrich and Klav
ˇ
zar, 2000) of two graphs G
1
and G
2
,
denoted with G
×
= G
1
⊗ G
2
, is defined as
V
×
={(v
i
, u
r
) : v
i
∈ V
1
, u
r
∈ V
2
} (1)
E
×
={((v
i
, u
r
), (v
j
, u
s
)) : (v
i
, v
j
) ∈ E
1
∧ (u
r
, u
s
) ∈ E
2
}
In the following, we will call G
×
the tensor prod-
uct graph. In the context of Pattern Recognition, the
key issue is to define a meaningful dissimilarity mea-
sure between patterns. Consequently, the standard
tensor product formulation have been adapted, taking
into account also the similarities of the labels of both
vertices and edges (Borgwardt et al., 2005). The re-
sulting adjacency matrix of the tensor product graph
G
×
can be computed using a valid kernel function,
k(·, ·), defined as a product of three different valid ker-
nel functions for vertex and edge labels
k((u
i
, u
j
), (v
r
, v
l
)) = (2)
= k
V
(u
i
, u
j
) · k
E
((u
i
, v
r
), (u
j
, v
l
)) · k
V
(v
i
, v
j
)
For example, k
V
(·, ·) and k
E
(·, ·) can be evaluated
as Gaussian Radial Basis kernels of the type
k
V
(u
i
, u
j
) = exp
−
d(µ(u
i
), µ(u
j
))
2
2σ
2
V
(3)
where d(·, ·) is a suitable dissimilarity for the specific
labels domain.
2.1 Graph Coverage
Given two input arbitrarily labeled graphs, say G
1
and G
2
, we compute the tensor product graph G
×
as
shown in Equation 2, using the product of three Gaus-
sian kernel functions, as the basic similarity scheme.
If G
×
is the resulting graph of this operation, we an-
alyze its characteristics with respect to the optimal
tensor product graph achievable from the two input
graphs. Given two input graphs G
1
and G
2
, three
tensor product graphs are possible, namely G
(1,2)
×
=
G
1
⊗G
2
, G
(1,1)
×
= G
1
⊗G
1
and G
(2,2)
×
= G
2
⊗G
2
. The
graphs G
(1,1)
×
and G
(2,2)
×
are the best matching tensor
product graphs, that is, they represent the cases where
G
2
is exactly equal to G
1
and viceversa. Now we in-
troduce the notion of weight for a graph.
Definition 1. (Weight of the Graph). Given a
weighted graph G of order n, we define its weight,
denoted with W (G), as
W (G) =
n
∑
i=1
n
∑
j=1
W
i j
≥ 0
Our tensor product graph G
×
is actually a
weighted graph, with ν(e
i j
) ∈ [0, 1], ∀e
i j
∈ E(G
×
).
The maximum theoretical achievable weight for such
a tensor product graph G
×
is clearly upper bounded
by its size, that is W(G
×
) ≤ |E
×
|. Given two in-
put labeled graphs G
1
and G
2
, the maximum theo-
retical weight for G
×
= G
1
⊗ G
2
is certainly achiev-
able if and only if |L
V
| = |L
E
| = 1 holds. The aim of
the graph coverage measure is in understanding how
much the two given input graphs G
1
and G
2
over-
lap, considering both the topologies and labels. This
is done confronting the weight of the tensor product
graph G
(1,2)
×
with respect to the real maximum achiev-
able weight considering G
1
and G
2
. Formally,
Definition 2. (Graph Coverage). Given two arbi-
trarily labeled graphs G
1
and G
2
, let G
(1,2)
×
, G
(1,1)
×
and G
(2,2)
×
be their respective possible tensor product
graphs. We define the coverage of G
1
and G
2
as
κ(G
1
, G
2
) =
W (G
(1,2)
×
)
max{W (G
(1,1)
×
), W(G
(2,2)
×
)}
(4)
It is easy to see that the function shown in Equa-
tion 4 is symmetric and normalized in [0, 1]. It is sym-
metric because the tensor product ⊗ and max{·, ·} op-
erators are both commutative. This is indeed a valid
kernel function, because it basically consists in prod-
ucts and sums between valid kernel functions of the
type shown in Equation 2. It can be also converted
ICPRAM 2012 - International Conference on Pattern Recognition Applications and Methods
270
very easily into a dissimilarity just setting, for exam-
ple
d(G
1
, G
2
) = 1 −κ(G
1
, G
2
) (5)
If two graphs are equal, their coverage is maximal,
that is 1. Conversely, if they are completely different,
their coverage tends to 0. A dual behavior is valid
for the dissimilarity formulation shown in Equation
5. The number of parameters on which it depends is
derived from the nature of the basic similarity func-
tions, that is from the particular kernel functions used
in Equation 2. The computational complexity of the
graph coverage is dominated by the computation of
the tensor product between the two input graphs, that
is between their adjacency matrices. If n and m are,
respectively, the order of G
1
and G
2
, then the compu-
tational complexity of the tensor product between G
1
and G
2
is of the order O(n
2
m
2
). Therefore, the com-
putational complexity of the graph coverage is given
by O(d(n
4
+m
4
+n
2
m
2
)), where d is the cost for each
basic kernel computation. So, from the computational
complexity point of view, the graph coverage formu-
lation is faster than other graph kernels based on the
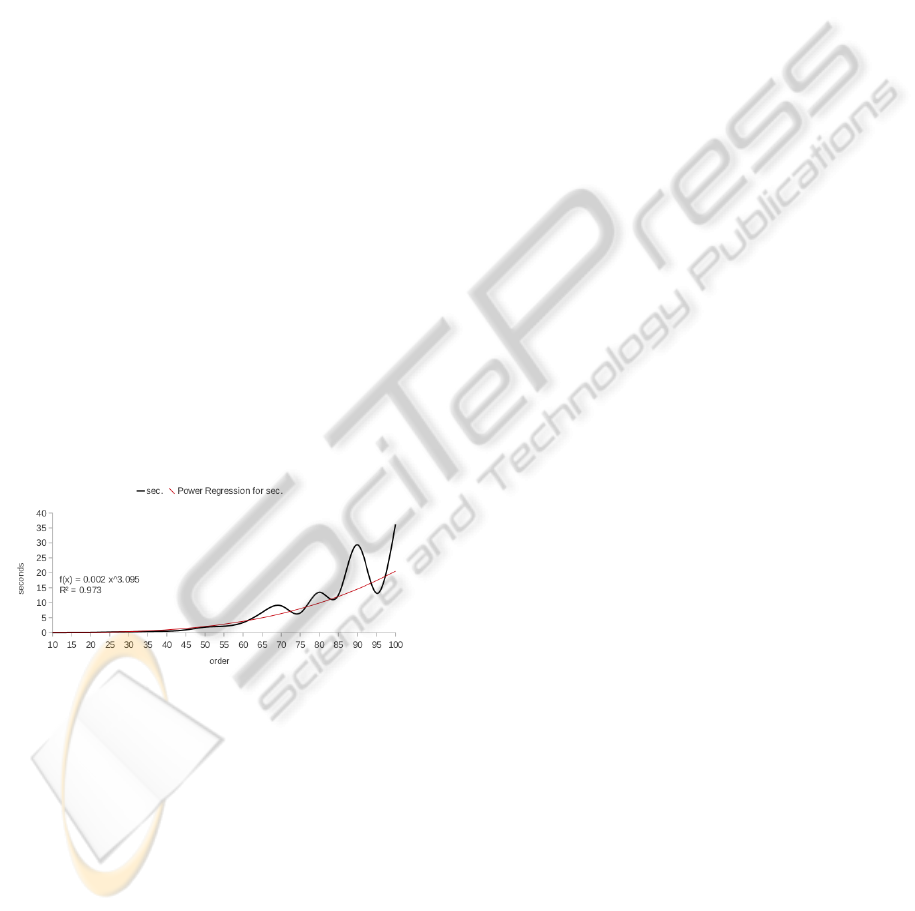
convolution of (random) walks. In Figure 1 is shown
the computing time achieved over a random sample
of graphs with 10 and 20-dimensional real vectors for
vertices and edges labels, respectively. As it is possi-
ble to observe, up to an order of 45, with an average
size of 256, the average computation time remains un-
der 1 second.
Figure 1: Time Performance Plot.
3 K-NN CLASSIFICATION
In this section, we provide the evaluations over the
IAM dataset (Riesen and Bunke, 2008). The tests are
executed on a machine with an Intel(R) Core(TM)2
Quad CPU Q6600 2.40GHz and 4 Gb of RAM over
a Linux OS. The graph coverage is implemented in
C++, as well as the other software components of
the SPARE library (Del Vescovo et al., ). The exe-
cution time in each test is computed using the clock()
function defined in ctime. To be able to evaluate the
pure performance of the graph coverage measure, we
have tested the accuracy of the classification using
the k-NN classifier of the SPARE library over some
IAM datasets. The k-NN classifier is a very sim-
ple tool that relies totally on the dissimilarity evalu-
ation of the input patterns, so the classification per-
formance of the graph coverage can be evaluated di-
rectly. In Table 1 are shown the results achieved over
some IAM datasets, namely Letter LOW, Letter MED,
Letter HIGH, AIDS, Fingerprint and COIL-DEL. The
datasets Letter LOW, Letter MED and Letter HIGH
are composed of a triple of training, validation and
test sets, each of 750 patterns. The first dataset is
composed of letters with a low level of distortion. The
patterns of the second and the third dataset are af-
fected by medium and high level of distortions. Each
dataset contains equally-distributed patterns from 15
different classes. The AIDS dataset is a not-equally
distributed two-class set of graphs with 250, 250 and
1500 samples for the training, validation and test
set, respectively. The Fingerprints dataset contains
graphs from four different classes with 500, 300 and
2000 samples for the training, validation and test set,
respectively. The graphs are not equally distributed
among the four different classes. Finally, the COIL-
DEL dataset is composed of 2400, 500 and 1000
graphs for the training, validation and test set, re-
spectively, that are equally distributed among 100
classes. The last column of Table 1, labeled ms, con-
tains the average computation time, expressed in mil-
liseconds, for each single graph coverage computa-
tion. The results are shown for ten different values
of the k parameter of the nearest neighborhood clas-
sifier (for k = 1 → 10). The results shown in Table
1 are obtained learning the three different σ parame-
ters of the Gaussian RBF of Equation 3 with a genetic
algorithm-based optimization procedure carried out
over the validation set. It is possible to see a generic
stable behavior for different values of k. In particu-
lar we observe very good results on the three Letters
and the AIDS datasets. Conversely, on COIL-DEL and
Fingerprint we observe a low classification accuracy.
This result is, in some sense, not expected, consider-
ing the average achieved results. However, it is worth
to perform a deeper analysis and we will proceed with
further investigations aiming to better characterize the
effectiveness of the proposed graph matching proce-
dure with respect to classification problems proper-
ties.
In Table 2 are shown the best results, taken
from (Riesen and Bunke, 2009, Table 2), achieved
by different algorithms over some of the IAM
graphs databases. The algorithm named Heuristic-
A
∗
(Neuhaus et al., 2006) computes the exact GED
INEXACT GRAPH MATCHING THROUGH GRAPH COVERAGE
271

Table 1: Classification Accuracy with k-NN.
Dataset K=1 K=3 K=5 K=7 K=10 ms
Letter L 98.80 98.40 97.73 98.93 98.80 0.103
Letter M 80.53 79.60 79.86 81.86 82.93 0.105
Letter H 74.00 71.86 75.60 75.87 78.40 0.153
AIDS 96.06 94.40 93.53 93.00 89.94 2.338
Fingerprints 39.67 37.38 38.95 39.15 38.24 0.573
COIL-D 37.50 12.50 12.50 12.50 12.50 32.94
using heuristic information. The algorithm named
Beams(10) is one of its approximated variation pro-
posed in (Neuhaus et al., 2006). Note that 10 is the
value of the parameter s chosen for the algorithm ex-
ecution. The algorithm named BP is a fast bipartite
graph matching procedure proposed in (Riesen and
Bunke, 2009). Finally, GC stands for the Graph Cov-
erage algorithm. Note that in Table 2 the Heuristic-
A
∗
algorithm is unable to achieve any result for some
dataset, due to its computational limit.
The achieved results, using the k-NN rule over the
IAM datasets, clearly show the validity of the pro-
posed method, with respect to some of the state of
the art methodologies.
Table 2: Classification Results over the Letter LOW (L-L),
Letter MED (L-M), Letter HIGH (L-H), AIDS, Fingerprints
(F) and COIL (C) Datasets.
Algorithm Datasets
L-L L-M L-H AIDS F C
Heuristic-A
∗
91.0 77.9 63.0 - - 93.3
Beam(10) 91.1 78.5 63.9 96.2 84.6 93.3
BP 91.1 77.6 61.6 97.0 78.7 93.3
GC 98.9 83.2 78.4 96.0 39.6 37.5
4 CONCLUSIONS AND FUTURE
DIRECTIONS
In this paper we have proposed a novel inexact graph
matching procedure. It is simple in its formulation
and at the same time effective, relatively fast and
flexible. This is, indeed, the real interesting contri-
bution introduced by the proposed method, consid-
ering the other available graph kernels. In fact, it
is worth to stress that the graph coverage is able to
deal also with fully-labeled graphs, where vertices
and edges labels can be even complex data struc-
tures, once valid kernel functions defined in these do-
mains, to be used as similarity measures, are pro-
vided. The proposed procedure shows interesting pre-
liminary results, considering both classification accu-
racy and computational performance. We are plan-
ning to test this algorithm over more shared bench-
marking graph-based datasets. Moreover, the pro-
posed inexact graph matching procedure is based on
tensor product between graphs. This product is a
mathematically solid and properties-rich operation,
that is basically founded on multiple product between
matrices and scalars. Therefore, the procedure is well
suited to be implemented in relatively inexpensive
parallel computing devices, such as Graphic Process-
ing Units (GPUs) or Field Programmable Gate Array
(FPGA). Taking advantage of these technologies, our
effort will be focused on the formulation of a more
efficient graph coverage procedure, able to deal with
graphs of order of 200 and beyond in a reasonable
computing time.
REFERENCES
Borgwardt, K. M., Ong, C. S., Sch
¨
onauer, S., Vish-
wanathan, S. V. N., Smola, A. J., and Kriegel, H.-P.
(2005). Protein function prediction via graph kernels.
Bioinformatics, 21:47–56.
Del Vescovo, G., Livi, L., Rizzi, A., and Frattale Mascioli,
F. M. Spare: Something for pattern recognition. Sub-
mitted for publication at: Journal of Machine Learn-
ing Research, Microtome Publishing.
Del Vescovo, G. and Rizzi, A. (2007). Automatic classi-
fication of graphs by symbolic histograms. In Pro-
ceedings of the 2007 IEEE International Conference
on Granular Computing, GRC ’07, pages 410–416,
San Jose, CA, USA. IEEE Computer Society.
G
¨
artner, T. (2008). Kernels for structured data. Number v.
72 in Kernels For Structured Data. World Scientific.
Imrich, W. and Klav
ˇ
zar, S. (2000). Product graphs, struc-
ture and recognition. Wiley-Interscience series in dis-
crete mathematics and optimization. Wiley.
Neuhaus, M., Riesen, K., and Bunke, H. (2006). Fast sub-
optimal algorithms for the computation of graph edit
distance. In Structural, Syntactic, and Statistical Pat-
tern Recognition. LNCS, pages 163–172. Springer.
Riesen, K. and Bunke, H. (2008). Iam graph database repos-
itory for graph based pattern recognition and machine
learning. In Proceedings of the 2008 Joint IAPR Inter-
national Workshop on Structural, Syntactic, and Sta-
tistical Pattern Recognition, SSPR & SPR ’08, pages
287–297, Berlin, Heidelberg. Springer-Verlag.
Riesen, K. and Bunke, H. (2009). Approximate graph
edit distance computation by means of bipartite graph
matching. Image Vision Comput., 27:950–959.
Riesen, K. and Bunke, H. (2010). Graph Classification and
Clustering Based on Vector Space Embedding. Se-
ries in Machine Perception and Artificial Intelligence.
World Scientific Pub Co Inc.
Sch
¨
olkopf, B. and Smola, A. (2002). Learning with ker-
nels: support vector machines, regularization, opti-
mization, and beyond. Adaptive computation and ma-
chine learning. MIT Press.
ICPRAM 2012 - International Conference on Pattern Recognition Applications and Methods
272
