
A SECURE AND EFFICIENT ORDER PRESERVING ENCRYPTION
SCHEME FOR RELATIONAL DATABASES
Hasan Kadhem
Department of Computer Science,Graduate School of Systems and Information Engineering
University of Tsukuba, Tsukuba, Japan
Toshiyuki Amagasa, Hiroyuki Kitagawa
Department of Computer Science,Graduate School of Systems and Information Engineering
Center for Computational Sciences, University of Tsukuba, Tsukuba, Japan
Keywords:
Order preserving encryption, Known plaintext attack, Statistical attack.
Abstract:
Encryption is a well-studied technique for protecting the confidentiality of sensitive data. However, encrypting
relational databases affects the performance during query processing. Preserving the order of the encrypted
values is a useful technique to perform queries over the encrypted database with a reasonable overhead. Un-
fortunately, the existing order preserving encryption schemes are not secure against known plaintext attacks
and statistical attacks. In those attacks, it is assumed that the attacker has prior knowledge about plaintext
values or statistical information on the plaintext domain.
This paper presents a novel database encryption scheme called MV-POPES (Multivalued - Partial Order Pre-
serving Encryption Scheme), which allows privacy-preserving queries over encrypted databases with an im-
proved security level. Our idea is to divide the plaintext domain into many partitions and randomize them in
the encrypted domain. Then, one integer value is encrypted to different multiple values to prevent statistical
attacks. At the same time, MV-POPES preserves the order of the integer values within the partitions to allow
comparison operations to be directly applied on encrypted data. Our scheme is robust against known plaintext
attacks and statistical attacks. MV-POPES experiments show that security for sensitive data can be achieved
with reasonable overhead, establishing the practicability of the scheme.
1 INTRODUCTION
Encryption is a well-studied technique to protect sen-
sitive data so that when a database is compromised
by an intruder, data remains protected even when a
database is successfully attacked or stolen. Recogniz-
ing the importance of encryption techniques, several
database vendors offer an integrated solution that pro-
vides standard encryption functionality in their prod-
ucts. Even though encrypting the database provides
important protection, performing queries over the en-
crypted databases becomes more challenging. En-
crypting database using a standard block cipher such
as AES, and DES causes undesirable performance
degradation during query processing. The reason is
that the standard encryption techniques do not pre-
serve the order of integers, so an entire table scan
would be needed to perform queries such as range
query. Thus the query execution can become unac-
ceptably slow.
Preserving the order of the encrypted values is a
useful technique to perform quires over the encrypted
database with a reasonable overhead. For instance,
given three integers {a,b,c}, such that (a<b<c), then the
encrypted values are (E
K
(a)<E
K
(b)<E
K
(c)). Here, E
K
(v)
denotes ciphertext value of v with encryption key K.
The order preserving encryption scheme OPES pro-
posed firstly by (Agrawal et al., 2004). The idea of
OPES is to take as input a user-provided target dis-
tribution and transform the plaintext values in such a
way that the transformation preserves the order while
the transformed values follow the target distribution.
The strength and novelty of OPES is that comparison
operations, equality and range queries as well as ag-
gregation queries involving MIN, MAX and COUNT
can be evaluated directly on encrypted data, with-
25
Kadhem H., Amagasa T. and Kitagawa H..
A SECURE AND EFFICIENT ORDER PRESERVING ENCRYPTION SCHEME FOR RELATIONAL DATABASES.
DOI: 10.5220/0003095700250035
In Proceedings of the International Conference on Knowledge Management and Information Sharing (KMIS-2010), pages 25-35
ISBN: 978-989-8425-30-0
Copyright
c
2010 SCITEPRESS (Science and Technology Publications, Lda.)

out decryption. Another encryption scheme proposed
by (Chung and Ozsoyoglu, 2006; Ozsoyoglu et al.,
2003), where a sequence of polynomial functions is
used to encrypt integer values while preserving the or-
der. The decryption is made by solving the inverses of
each polynomial function in the sequence in reverse
order.
Unfortunately, the previous order preserving en-
cryption (OPE) schemes are not secure against known
plaintext attacks and statistical attacks. In those at-
tacks, it is assumed that the attacker has a prior knowl-
edge about plaintext values or statistical information
on plaintext domain. The authors of the previous
OPE schemes either ignore those type of attacks oras-
sumed that the attacker does not have any information
about the plaintext domain. In reality, the attacker in
many cases may have general or advanced informa-
tion about plaintext domain. Here, the attacker who
has access to the encrypted values and has knowledge
about the plaintext can map both the plaintext and the
encrypted values and make use of them to obtain the
key. This is because the OPE schemes preserve the
order of all integers in the domain, so the order of en-
crypted values is exactly the order of plaintext values
(we called those schemes as full OPE).
This paper presents a new database encryption
scheme called MV-POPES (Multivalued - Partial Or-
der Preserving Encryption Scheme), which divide the
plaintext domain into many partitions and randomize
them in the encrypted domain. It allows one integer to
be encrypted to many values using the same encryp-
tion key while preserving the order of the integer val-
ues within the partitions. Here, still we can get ben-
efit from the partial order preserving in the encrypted
data to perform queries directly at the server without
decrypting data. At the same time, it prevents attack-
ers from inferring individual information from the en-
crypted database even if they have statistical and spe-
cial knowledge about the plaintext database. The rea-
son is that the encrypted values are totally in different
order compared with the plaintext values. The results
from an implementation of MV-POPES show that se-
curity for sensitive data can be achieved with reason-
able overhead, establishing the practicability of the
scheme.
Our threat model is same as the one in the pre-
vious OPE schemes (Agrawal et al., 2004) but with
more conservative approach. We assume that the at-
tacker not only has access to the encrypted database
files but also has special knowledge about the plain-
text database. However, the attacker does not have
access to the logs and the memory of the database
software. Figure 1 shows the system model where
the client sends a rewritten query using the metadata
Encrypted Database
Decrypt
Result
Rewrite
Query
Client
Metadata
Database Software
compile query and execute over
encrypted database
Figure 1: System model.
to the database software. Then the query is executed
on the encrypted database and return the results to
the client who decrypt them using same metadata.
The metadata, query rewriting, and result decryption
could be on the database software or on client side. In
this paper we consider them to be on client side. We
make the following contributions:
• We analyze the security of previous full OPE
schemes based on an attack model we define, con-
sisting of known plaintext attack and statistical at-
tack (Section 2).
• We propose our novel database encryption
scheme (MV-POPES) and the metadata used to
support encryption, decryption and efficient query
processing (Section 3).
• We explain how to translate a query condition
over a plaintext to corresponding conditions over
encrypted database (Section 4).
• We show how relational operators can be imple-
mented efficiently over encrypted relations (Sec-
tion 5).
• We analyze the security of our scheme based on
definitions and theorems we define in Section 2
(Section 6).
• We complement our analytical results with experi-
ments on differentdomains that measure the effect
of our encryption scheme on query processing ef-
ficiency, as well as the client post processing cost
(Section 7).
The related work is discussed in Section 8. We con-
clude with a summary and directions for future work
in Section 9.
2 SECURITY ISSUES
In this section we analyze the security of the full OPE
schemes based on two concepts, the mapping proba-
bility and similarity degree of statistics.
KMIS 2010 - International Conference on Knowledge Management and Information Sharing
26

2.1 Mapping Probability
The mapping probability is related to the known
plaintext attack. In this attack, it is assumed that the
attacker has both the plaintext and its encrypted ver-
sion (ciphertext) and makes use of them to obtain the
key used in the encryption process.
Definition 1. (Mapping Probability (µ)) Let ε be an
encryption scheme. Let ρ be the set of plaintext values
and ς be the corresponding set of ciphertext values
using ε. Let η be the number of possible mappings
between ρ and ς. Then, the mapping probability µ is
the probability to pickup the correct mapping among
η, so µ = 1/η.
Theorem 1. (Security against Known Plaintext At-
tack) Let ε be an encryption scheme. Let µ be the
mapping probability between the set of plaintext val-
ues ρ and the corresponding set of ciphertext values
ς using ε. Then, ε is secure against known plaintext
attack when µ is significantly small.
Note that the µ will be significantly small if η is
exponentially large. This theorem shows that by hav-
ing large η, it will be almost impossible for the at-
tacker to infer information about encryption scheme
and the key by the advantage of knowing both plain-
text and cipher text values.
Using a full OPE scheme, we can clearly see that
there is only one possible mappings (η = 1) between
ρ and ς, then µ = 1. The reason is that both the plain-
text and ciphertext values have exactly the same order.
So any full OPE scheme is not secure against known
plaintext attack.
2.2 Similarity Degree of Statistics
The Similarity Degree of Statistics is related to the
statistical attack. In this attack, the attacker tries to
find a match between the ciphertext values and plain-
text values based on some statistical information on
plaintext and make use of them to obtain the key.
Definition 2. (Similarity Degree of Statistics (∆)) Let
ε be an encryption scheme. Let Σ
ρ
be the statistics on
plaintext values and Σ
ς
be the statistics on the cor-
responding ciphertext values using ε. Then, ∆ is the
percentage of similarity between both Σ
ρ
and Σ
ς
.
The statistics here involvingfrequencies of values,
and aggregation functions such us MIN, MAX, SUM,
and COUNT.
Theorem 2. (Security against Statistical Attack) Let
ε be an encryption scheme. Let ∆ be the Similarity
Degree of Statistics between the statistics on plaintext
Σ
ρ
and the statistics on the corresponding ciphertext
Σ
ς
using ε. Then, ε is secure against statistical attack
when ∆ is significantly small.
Using a full OPE scheme, the aggregation func-
tion such as MIN, MAX, and COUNT are exactly the
same on both plaintext and ciphertext values. In addi-
tion, many previous full OPE schemes encrypt plain-
text value to another fixed value, so the frequencies of
values are same before and after encryption. The re-
sult will be high similarity degree of statistics ∆ which
means that the full OPE scheme is not secure against
statistical attack.
3 RELATIONAL ENCRYPTION
This section describes our encryption scheme in de-
tail.
3.1 An Overview of MV-POPES
When encrypting plaintext values in a column hav-
ing values in the range [D
min
,D
max
], first, we divide the
domain into n partitions and assign for each partition
a random number from 1 to n. This number will be
the order of partitions in the encrypted domain. We
change the order of partitions to hide the original or-
der of plaintext values. Then, we generate boundaries
for all integers in all partitions using an order preserv-
ing function. We preserve the order within the parti-
tion to be able to evaluate queries efficiently on en-
crypted database. The generated boundaries identify
the intervals. For instance, interval I
i
is identified by
[B
i
,B
i+1
). We then generate the encrypted values for in-
teger i as random values from the interval I
i
, so one
plaintext value is encrypted to many different values.
This will change the frequencies of the plaintext val-
ues to prevent the encrypted database against statisti-
cal attack.
3.2 Partitioning and Metadata
Here, we explain the partitioning function for each at-
tribute’s domain and what is stored in the metadata
for each domain. We first divide the plaintext domain
of values [D
min
,D
max
] into partitions {p
1
,...,p
n
}, such that
these partitions cover the whole domain and there is
no overlap between them. Then, we assign for each
partition a unique random number in the range of [1,n].
This number is the new order of partitions in the en-
crypted domain.
As an example, Figure 2 shows the partitions
metadata for the domain [1,100]. The domain is divided
into 5 partitions: [1,20],[21,40],[41,60],[61,80],[81,100]. (F), (L)
A SECURE AND EFFICIENT ORDER PRESERVING ENCRYPTION SCHEME FOR RELATIONAL DATABASES
27
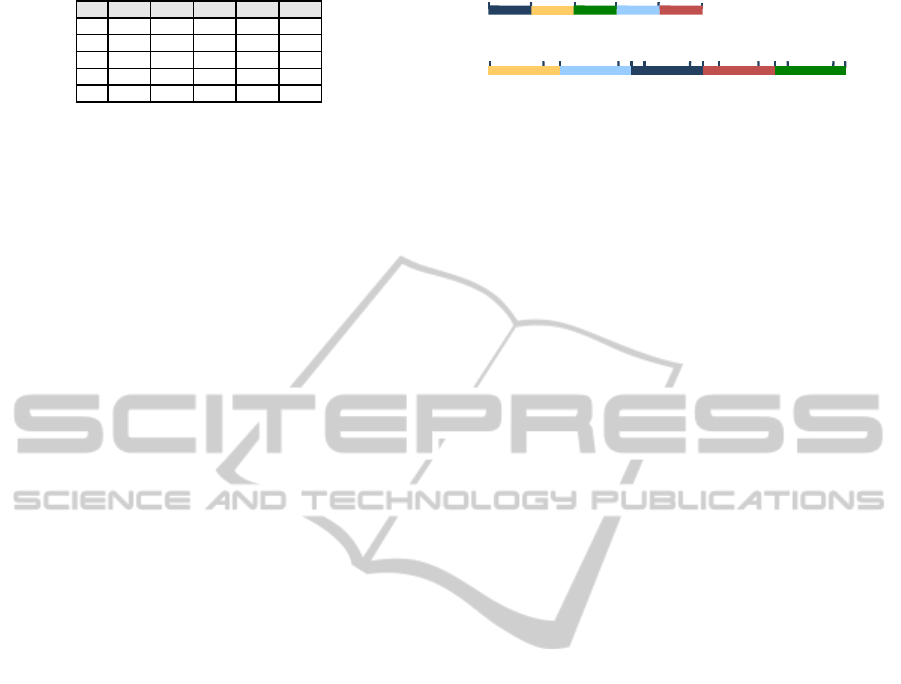
PID EPID PREV F L NEXT
1 3 80 1 20 81
2 1 - 21 40 61
3 5 100 41 60 101
4 2 40 61 80 1
5 4 20 81 100 41
Figure 2: Partitioning metadata.
are the first and last number in the partition. The par-
tition identifier (PID) represents the original order of
partitions in plaintext domain. The encrypted parti-
tion identifier (EPID) represents the order of partition
in the encrypted domain. (PREV) and (NEXT) are the
previous and the next number in the encrypted domain
for a partition. For instance, the partition [61,80] where
PID=4, and EPID=2, the (PREV) will be the last number
for the partition with EPID=1 (which is 40), and the
(NEXT) will be the first number for the partition with
EPID=3 (which is 1).
The metadata is used to generate bucket bound-
aries, encryption/decryption and query translation. It
contains all the secret information about partitions so
must be a well-kept secret, as well as the key.
3.3 Generation of Bucket Boundaries
Any order preserving function with suitable security
properties can be used to generate the bucket bound-
aries for all integers in the plaintext domain based on
the encrypted order of partitions. Here, we propose
an order preserving function based on secret variables
and a sequence of random numbers.
We are given a domain [D
min
,D
max
], with (D
max
−D
min
+
1) integers: {D
min
,D
min+1
,...,D
max
}. Initially, we choose
the starting (initial) point from the domain. We then
compute the boundary for the initial point using the
following function:
B
initial
=Enc
K
(initial)
where Enc is the function used to encrypt the (initial)
value using key K. Any block cipher algorithm such as
DES (DES, 1977), TDES, Blowfish (Schneier, 1994),
AES (AES, 2001), RSA (Rivest et al., 1978), or a
hashing function can be used to encrypt the value.
To preserve the order of the integers, we use two
functions to generate boundaries. First, boundaries
for values greater than the initial point are gener-
ated by an increasing function. Second, a decreas-
ing function is used to generate boundaries for values
less than the initial point. The goal for the increas-
ing/decreasing function is to create encrypted inter-
val scales for all integers in the domain with differ-
ent sizes. Differences in intervals size are ensured
by predefined percentage and a sequence of random
numbers.
Given the initial point (initial), the interval size IS,
B
1
B
2
B
20
B
81
B
82
B
100
B
41
B
42
B
60
B
101
B
80
B
61
B
21
B
40
1
20
40
60
80
100
……….. …………… ……….. ………..
………..
a) Plaintext domain.
b) Encrypted domain.
Figure 3: Plaintext domain and the boundaries in the en-
crypted domain.
and the difference percentage on the encrypted inter-
val size DP, the boundaries are derived by the follow-
ing function:
B
i
=
(
B
i+1
−Enc
K
(IS)(1+DP∗R
i
), D
min
≤i<initial
B
i−1
+Enc
K
(IS)(1+DP∗R
i
), initial<i≤D
max+1
where R
i
is a sequence of random numbers in the range
[−1,1]. There are many pseudorandom number gener-
ators with useful security properties (Blum and Mi-
cali, 1984; Menezes et al., 1996). The DP used in the
formula to control the differences between intervals
size that will be in the range [−Enc
K
(IS)∗DP,Enc
K
(IS)∗DP].
Note that B
i+1
will be the (NEXT ) when i is the last num-
ber in the partition and B
i−1
will be the (PREV) when i
is the first number in the partition. Figure 3 shows the
plaintext domain and the boundaries generated in the
encrypted domain for the metadata shown in Figure
2.
3.4 Encryption Function
Here we discuss how to encrypt a plaintext relation R.
For each tuple t=(A
1
,A
2
,...,A
n
) in R, the encrypted rela-
tion R
E
stores a tuple:
(E(A
1
),E(A
2
),...,E(A
n
))
where E is the function used to encrypt an attribute
value of the tuple in the relation. The encryption func-
tion E(i) is applied by choosing a random number in
the interval I
i
, which is identified by [B
i
,B
i+1
). Note
that B
i+1
will be the (NEXT) when i is the last number
in the a partition. Using the example shown in Fig-
ure 3, E(81) will be a random number in the interval
[B
81
,B
82
) while E(80) will be a random number in the
interval [B
80
,B
1
).
3.5 Decryption Functions
Given the operator E, which encrypts a plaintext value
to many ciphertext values, we define its inverse op-
erator D, which decrypts the ciphertext value to its
corresponding plaintext value. Simply, the decryp-
tion function D in MV-POPES searches for the inter-
val where the encrypted value is located. Specifically,
to decrypt an encrypted value C, the decryption func-
tion searches for the closer boundary B
p
that is greater
than C, then returns the plaintext value, which is the
left boundary p−1. Details about choosing the initial
KMIS 2010 - International Conference on Knowledge Management and Information Sharing
28

point for generating boundaries, the random distribu-
tions used for choosing encrypted values and decryp-
tion algorithms are given by (Kadhem et al., 2010).
4 CONDITIONS TRANSLATION
This section explains how to translate a query condi-
tion C over a plaintext database in operations (such as
selection and join) to corresponding conditions over
encrypted database C
E
. We consider query conditions
characterized by the following grammar rules:
• Condition Attribute θ Value
• Condition Attribute θ Attribute
• Condition (Condition ∨ Condition)|(Condition ∧ Condition)
|(⇁ Condition)
where θ is a binary operation in the set {=,<,≤,>,≥}.
4.1 Partition Identification Functions
Before we discuss the translation of conditions, let us
first define the necessary functions on the partitions
identifiers. Those functions will be used to translate
conditions that contain comparison operations.
Let A be an attribute, v be a value in the domain and
i be a partition identifier. Table 1 shows the partition
identification functions. Using the running example,
PID
<
A
(50)={1,2} and PID
>
A
(50)={4,5}.
Table 1: Partition Identification Functions.
PID
A
set of PID for attribute A
PID
A
(v) PID to which value v belongs in the
domain of A
PID
<
A
(v) set of PID for attribute A that are
less than the partition that contains
v
PID
>
A
(v) set of PID for attribute A that are
greater than the partition that con-
tains v
PID
<i
A
set of PID for attribute A that are
less than i
PID
>i
A
set of PID for attribute A that are
greater than i
4.2 Translation of (Attribute θ Value)
Conditions
Attribute = Value: such condition arises in selection
operations. The translation is defined as follows:
A=v A
E
BETWEEN B
v
and (B
v+1
−1)
The BETWEEN condition allows the retrieval of values
within a range of two values (inclusive). Since the
right boundary B
v+1
is not included in the interval (I
v
),
the second value in the BETWEEN condition will be
the right boundary minus 1 (B
v+1
−1).
Attribute < Value: such condition arises in selection
operations. Since the MV-POPES preserves the order
of the encrypted values within the partition ( v
i
<v
j
→
E
K
(v
i
)<E
K
(v
j
), v
i
and v
j
belong to the same PID), the
translation of (A<v) is as follows:
(A
E
<B
v
∧ A
E
≥B
F(PID
A
(v))
)
W
W
i∈PID
<
A
(v)
(A
E
≥B
F(i)
∧ A
E
>B
NEXT(i)
)
where F(i) is the first integer in the partition i, and
NEXT(i) is the next integer of the partition i. Simply,
the result contains all encrypted values that are less
than the left boundary (B
v
) of the interval (I
v
) within
the partition that contains v. In addition, all partitions
whose PID are less than the partition of v are included
in the result. For example, the translation condition
for the condition (A<55) is:
(A
E
<B
55
∧A
E
≥B
50
)∨(A
E
≥B
1
∧A
E
<B
81
)∨(A
E
≥B
21
∧A
E
<B
61
)
Attribute ≤ Value: The difference between this con-
dition and the previous one is that this condition in-
cludes all the encrypted values for v, in addition to
those values that are less than the left boundary (B
v
).
So, instead of (A
E
<B
v
), the condition will be (A
E
<
B
v+1
).
For conditions Attribute > Value and Attribute
≥ Value, translation is the same as the translation of
A<v and A≤v, as described above but in the opposite
direction.
4.3 Translation of (Attribute θ Attribute)
Conditions
When comparing two different attribute values in
query processing, a straightforward approach is to de-
crypt the ciphertext first, then compare the plaintext
values, which may lead to performance degradation.
Instead, we try to make it possible to compare cipher-
text without decryption.
In this work, we introduce a calculated distance
MaxDif f , which is the maximum distance (among all
intervals in the domain) between value P in the pri-
mary key table and value F in the foreign key tables.
The idea is to check if a value being compared is con-
tained within the range of [P−MaxDif f,P+MaxDif f ] (in
case of equality), instead of comparing the value with
P’s bucket boundaries. Notice that it may result in a
false positive, which should be eliminated in a post-
processing.
A SECURE AND EFFICIENT ORDER PRESERVING ENCRYPTION SCHEME FOR RELATIONAL DATABASES
29

MaxDiff
MaxDiff
P
F
False positive
False positive
Figure 4: Overlap in connecting primary key with foreign
key values based on equality condition.
Given a condition (P θ F), such that P and F have
same domain, P is the primary key and F is a foreign
or primary key. The translation for this condition is
discussed next.
P = F: This condition is translated using the MaxDif f
to:
F
E
BETWEEN (P
E
−MaxDif f ) and (P
E
+MaxDif f )
Here, MaxDif f is used to ensure that all foreign key
values located in same interval are connected to the
related primary key. Intervals differ, so some foreign
key values from neighbor intervals might connect to
false primary keys (false positive). Figure 4 shows
the process for connecting equal values between a pri-
mary key and foreign key. The total number of false
positives (TFP) can be expressed as:
D
min
∑
i=D
max
|{ f | f ∈F∧(P
i
−MaxDi f f ≤ f<B
i
∨B
i+1
≤ f<P
i
+MaxDi f f )}|
P < F: The translation for this condition can be per-
formed as follow:
W
i∈PID
P
(P
E
≥B
F(i)
∧P
E
<B
NEXT(i)
)∧(P
E
<F
E
)
W
W
j∈PID
<i
P
(P
E
≥B
F(i)
∧P
E
<B
NEXT(i)
)∧(F
E
≥B
F( j)
∧F
E
<B
NEXT( j)
)
Simply, we check for each partition (i) in the domain,
the values where P<F and include all values in the par-
titions ( j) that PID is greater than the partition (i).
P ≤ F: This condition should be translated in such a
way that all foreign key values that are greater than
or equal to the primary key can be connected to the
related primary key. The translation of this condi-
tion is same as the previous condition but we use
MaxDif f to ensure all equal values are connected to-
gether. So, instead of P
E
<F
E
the condition will be
(P
E
+MaxDif f ) ≤ F
E
.
The translation for P > F and P ≥ F is the same
as the translation of P<F and P≤F as described above,
but in the reverse direction.
4.4 Translation of Composite
Conditions
Two composite conditions are translated directly over
the encrypted domain by translating each condition
individually. The translation is given as follows:
C1 ∨ C2 C1
E
∨ C2
E
, C1 ∧ C2 C1
E
∧ C2
E
The result based on two composite conditions
might contain false positives when at least one con-
dition is from (Attribute θ Attribute). When both condi-
tions are from (Attribute θ Value) the result will be exact.
Note that the translation of comparison operators on
same attribute will be either the union (∪) between
sets of PIDs (in case of C1 ∨ C2) or the intersection (∩)
between sets of PIDs (in case of C1 ∧ C2).
Translation of (⇁Condition) depends on the condi-
tion type. When the condition is in the form of
(Attribute θ Value), the translation is straightforward:
⇁ C ⇁C
E
The result based on this condition will be exact
(without any false positives). However, when C is in
the form of (Attribute θ Attribute), this condition (⇁ C) can-
not be translated directly because of the false positive
result. This paper does not discuss this translation.
Neither are conditions that involve more than one at-
tribute and operator discussed.
5 RELATIONAL OPERATORS
This section describes the process of implementing
relational operators (such as selection, projection, and
sorting) in the proposed scheme. The relational oper-
ators are implemented, as much as possible, to be ex-
ecuted over the encrypted database. However, when a
condition of the form (Attribute θ Attribute) is attached to
the operator, the returned answers might contain false
positives. These answers are then filtered in client-
side after decryption to generate the exact result. Be-
yond that, some operators cannot be performed fully
on the encrypted relations. When that happens, a
post process operation is performed on the result af-
ter decryption. We attempt to minimize the amount of
work done in post process operations. Table 2 shows
the implementation of the operators over encrypted
databases. The E on the operators emphasizes the fact
that the operator is to be executed over the encrypted
database. The L
E
refers to the encrypted attributes.
Query Splitting. We split the computation of a query
Q across the server and the client. The client will use
the implementation of the relational operators to send
part of the query Q
s
to the server to be executed on
the encrypted database. The second part, which is
client query part Q
c
, is performed on the decrypted
data. Query splitting is as follows:
op (R)
|{z}
Q
= op
c
D
|{z}
Q
c
(op
E
(R
E
)
| {z }
Q
s
)
where op
c
refers to operations performed on the client
side, and op
E
is operations performed on encrypted
KMIS 2010 - International Conference on Knowledge Management and Information Sharing
30

Table 2: Implementation of the operators over encrypted
databases.
Operator op op
E
Selection (σ) σ
C
(R) D(σ
E
C
E
(R
E
))
Join (⊲⊳) R
⊲⊳
C
T σ
C
D(R
E
⊲⊳
E
C
E
T
E
)
Sorting (τ) τ
L
(R) τ
L
D(τ
E
L
E
(R
E
))
Projection (π) π
L
(R) D(π
E
L
E
(R
E
))
Grouping and
Aggregation (γ)
γ
L
(R) γ
L
D(τ
E
LG
E
(R
E
))
Duplicate
Elimination (δ)
δ(R) δ
D(τ
E
L
E
(R
E
))
Union (∪) R∪T D(R
E
∪
E
T
E
) (based on bag)
δ
D(τ
E
L
(R
E
∪
E
T
E
))
(set)
Difference (−) R−T D(τ
E
LR
E
(R
E
))−D(τ
E
LT
E
(T
E
))
relations R
E
on the server side.
6 SECURITY ANALYSIS
We can prove the security of our scheme against
known plaintext attack and statistical attack by using
the security definitions and theorems we defined in
Section 2. For m distinct plaintext values and n corre-
sponding distinct ciphertext values using our encryp-
tion scheme. The number of possible mappings (η) in
an order preserving way is determined by the number
of ways of partitioning the set of plaintext values into
k non-empty partitions and the order of partitions in
the encrypted domain. This number is:
η =
n−1
m−1
∑
m
i=1
(
m−1
i−1
i!)
where
∑
m
i=1
(
m−1
i−1
i!) is the possible ways to partition-
ing the plaintext domain and the possible orders for
those partitions, and
n−1
m−1
is the possible frequencies
for the ciphertext values compared with the plaintext
values in an order preserving way. We can clearly see
that (η) is exponentially large even for small plain-
text domain, so the mapping probability (µ) is signifi-
cantly small. By ignoring the number of possible par-
titions and their orders which means considering just
the new order for the plaintext values in the encrypted
domain, the number of possible mappings is:
η =
n−1
m−1
m!
Note that the smallest number of η will be in the case
of primary key attribute where n = m. The reason is
that the possible frequencies in such case are 1. How-
ever, still η is large enough (η = m!) because still an
attacker should figure out the new order of the plain-
text in the encrypted domain. Thus, based on theorem
1, our scheme is secure against the known plaintext
attack because the mapping probability (µ) is signifi-
cantly small in all cases.
In our scheme, it is clear that the frequencies of
encrypted values and plaintext values are different be-
cause one value is encrypted to many different values.
Also, the statistical functions such as MIN, MAX,
SUM are totally different on ciphertext and plaintext
values. Thereby, the statistics on plaintext values Σ
ρ
is diverse from the statistics on the corresponding ci-
phertext values Σ
ς
using MV-POPES. Based on theo-
rem 2, MV-POPES is secure against statistical attack
because the similarity degree of statistics (∆) is sig-
nificantly small. Note that the aggregation functions
(MIN, MAX, COUNT) are still evaluated directly on
the encrypted database using the metadata. For exam-
ple, MIN value for a domain will be the minimum en-
crypted value within the first partition and MAX value
will be the maximum encrypted value within the last
partition.
7 EXPERIMENTS
This section evaluates the performance of our encryp-
tion scheme. We have conducted many experiments
to examine the validity and effectiveness of the archi-
tecture proposed in this paper. However, because of
space limitations, we will discuss just four sets of ex-
periments.
7.1 Experimental Setup
The experiments were conducted by implementing
MV-POPES on MS SQL Server 2008. The algorithms
were implemented in VB.NET as a client side appli-
cation. The experiments were run using version 3.0
of the Microsoft.Net framework and on a Microsoft
XP workstation with a 2.6 GHz Intel Core 2 pro-
cessor and 3 GB of memory. The results sketched
in this section are the average for at least 10 execu-
tions. The sets of evaluations was performed on dif-
ferent domains {10,10
2
,10
3
,10
4
,10
5
} and various number
of partitions (small and large number of partitions)
with difference percentage (DP=0.05). The records on
tables picked randomly from a uniform distribution
between D
min
and D
max
. We used eqi-width as parti-
tioning method.
7.2 Performance for Generating
Boundaries
The first set of evaluations was performed to examine
the time needed to generate boundaries. The graph
in Figure 5 shows the execution time for generating
boundaries using the first integer in the encrypted do-
main as the initial point. The results show that we have
A SECURE AND EFFICIENT ORDER PRESERVING ENCRYPTION SCHEME FOR RELATIONAL DATABASES
31

0
0.05
0.1
0.15
0.2
1 2 3 4 5 6 7 8 9 10
Time per boundary (ms)
Number of partitions
10
100
1000
10000
100000
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
1
50
100
150
200
250
300
350
400
450
500
Time per boundary (ms)
Number of partitions
10000
100000
a) Small number of partitions. b) Large number of partitions.
Figure 5: Time per boundary (in ms) required to generate
boundaries.
0
0.1
0.2
0.3
0.4
0.5
0.6
1
2
3
4
5
6
7
8
9
10
plaintext
AES
Time per tuple (ms)
Number of partitions
10
100
1000
10000
100000
0
0.1
0.2
0.3
0.4
0.5
0.6
1
50
100
150
200
250
300
350
400
450
500
plaintext
AES
Time per tuple (ms)
Number of partitions
10000
100000
b)
Large
number of partitions.
a)
Small number of partitions.
Figure 6: Time per tuple (in ms) required to insert tuples.
slightly better performance when the domain is large.
That is because the time needed to encrypt initial point
is divided by larger number in case of large domain.
Generally, the number of partitions (both small and
large) does not affect the performance of generating
the boundaries.
7.3 Performance for Encryption
The second set of evaluations studied the encryption
performance in our scheme using different domains
and various numbers of partitions. Also, we com-
pare the performance of our scheme with a database
encrypted using AES. The table holds 100,000 records
picked randomly from a uniform distribution between
D
min
and D
max
. Figure 6 shows the times for encryp-
tion and inserting values in the tables for different do-
mains. The results show that AES takes the longest
time to insert tuple since the encryption time is much
more than in MV-POPES. The small difference in
time shown in the figure between plaintext and our
scheme is the cost of encryption. The figure shows
that this overhead is negligible. Also, figure 6(a,b)
shows that the encryption cost of our scheme does not
change by increasing the number of partitions.
7.4 Performance for Equijoin
In the equijoin operation, we studied the percentage
of false positives returned by performing a join oper-
ation over encrypted relations. Also, we studied the
overhead on both the server and client sides. Two ta-
bles were used to perform this evaluation. The first
0
5
10
15
20
25
30
35
1 2 3 4 5 6 7 8 9 10
False positive (%)
Number of partitions
10
100
1000
10000
100000
0
5
10
15
20
25
30
35
1
50
100
150
200
250
300
350
400
450
500
False positive (%)
Number of partitions
10000
100000
0
0.01
0.02
0.03
0.04
0.05
0.06
1
2
3
4
5
6
7
8
9
10
PT
AES
Time (ms) per tuple
Number of partitions
10
100
1000
10000
100000
0
0.01
0.02
0.03
0.04
0.05
0.06
1
50
100
150
200
250
300
350
400
450
500
PT
AES
Time (ms) per tuple
Number of partitions
10000
100000
0
0.005
0.01
0.015
0.02
0.025
1
2
3
4
5
6
7
8
9
10
AES
Time (ms) per tuple
Number of partitions
10
100
1000
10000
100000
0
0.005
0.01
0.015
0.02
0.025
1
50
100
150
200
250
300
350
400
450
500
AES
Time (ms) per tuple
Number of partitions
10000
100000
a)
False positive percentage.
b
) Query execution time in server side.
c
) Decryption and filtering cost in client side.
Small
Number of
Partitions
Large
Number of
Partitions
Figure 7: Equijoin cost.
table is the primary key table, which contains all in-
tegers in the domain. The second table is the foreign
key table, which holds 100,000 records. The percentage
of false positives shown in Figure 7(a) increases with
the domain size. That results due to the increase in the
overlap between intervals in the encrypted scale when
performing a join operation based on MaxDif f. How-
ever, the false positive percentage is same with small
and large number of partitions. That because the over-
lap between intervals is not related to the number of
partitions. From Figure 7(b), we can easily see that
the time required to perform a join operation on the
server side in our scheme increases according to the
size of domain and its approximately same as the join
operation on the plaintext (PT) database. While the
cost of join operation using AES is much more than
our scheme. This is especially when using large do-
mains (>10
3
) since the index is essentially unusable
for many operations (including join) which turn into
full table scans (Hsueh, 2008). Figure 7(c) shows the
client side performance to decrypt and filter the result
returned by performing a join operation on the server
side. The figure shows that our scheme has only small
overhead on the client side. We also observe that the
time slightly increases as the domain, because of in-
creased false positives. The results show that using
small or large number of partitions does not affect the
overhead on both server and client side. On the other
hand, we can see the performance degradation when
using AES compared with our scheme.
KMIS 2010 - International Conference on Knowledge Management and Information Sharing
32
0
0.005
0.01
0.015
0.02
1 2 3 4 5 6 7 8 9 10 PT
Time (ms) per tuple
Number of partitions
10
100
1000
10000
100000
0
0.005
0.01
0.015
0.02
1
50
100
150
200
250
300
350
400
450
500
PT
Time (ms) per tuple
Number of partitions
10000
100000
0
0.005
0.01
0.015
0.02
1
2
3
4
5
6
7
8
9
10
AES
Time (ms) per tuple
Number of partitions
10
100
1000
10000
100000
0
0.005
0.01
0.015
0.02
1
50
100
150
200
250
300
350
400
450
500
AES
Time (ms) per tuple
Number of partitions
10000
100000
a
) Query execution time in server side.
b
) Decryption cost in client side.
Small
Number of
Partitions
Large
Number of
Partitions
Figure 8: Range query.
7.5 Performance for Range Query
The last sets of experiments studied the performance
of range queries on MV-POPES. The query used in
those experiments is retrieving all records that are
greater than (domain size/2). Figure 8(a) shows the range
query execution times on plaintext, MV-POPES, and
AES. The figure illustrates that query response time is
approximately the same in plaintext and our scheme
by using small number of partitions. In our scheme,
using large number of partitions will cause more over-
head on server side because the condition becomes
more complicated. However, we think that the over-
head on server side can be optimized by simplifying
the translated condition. We will investigate that in
details in future work. Figure 8(b) shows the decryp-
tion cost on client side using MV-POPES. We can
see clearly that the decryption overhead is small and
approximately fixed in our scheme using small and
large number of partitions. The Figure also shows
the time required to perform same range query on the
database encrypted using AES. Here the time repre-
sents the decryption time and the time for performing
the range query on the decrypted data. That is because
the range query cannot be executed over the databases
encrypted using AES. Using AES, range query takes
much more time than our scheme on the client side
because of decryption cost.
8 RELATED WORK
Many full OPE schemes (Agrawal et al., 2004; Chung
and Ozsoyoglu, 2006; Ozsoyoglu et al., 2003; Wang
and Lakshmanan, 2006) have been proposed, but no
work discussed the security of the encryption schemes
against known plaintext attack and statistical attack.
Only (Wang and Lakshmanan, 2006) considered the
frequency-based attack which is part of statistical at-
tack in their encryption scheme. (Wang and Lak-
shmanan, 2006) proposed a new encryption scheme
(Order preserving encryption with splitting and scal-
ing (OPESS)) based on the OPES to index the en-
crypted values in the outsourced XML databases. The
idea in OPESS is to map the same plaintext values to
different ciphertext values to protect the data against
frequency-based or statistical attacks. However, this
scheme still preserve the order for all encrypted val-
ues so it is possible to estimate at least the top and
bottom parts of the plaintext domain. One of the lim-
itations of OPESS is that security achieved by scaling
encrypted data causes an increase in data size. Also,
this approach is not efficient in insertions and updates
becausehe encryption method is mainly based on the
number of occurrences. OPESS proposed mainly for
XML database but it is not applicable for relational
database. The reason behind that is the different
in executing queries on the relational and the XML
databases such as the join operation between differ-
ent encrypted values.
The bucketing approach (Hore et al., 2004;
Hacig¨um¨us¸ et al., 2002) is closely related to our
scheme in sense of dividing the plaintext domain into
many partitions (buckets). The encrypted database
is augmented with additional information (the index
of attributes), thereby allowing query processing to
some extent at the server without endangering data
privacy. The encrypted database in the bucketing ap-
proach contains etuples (the encrypted tuples) and
corresponding bucket-ids (where many plaintext val-
ues are indexed to same bucket-id). In this scheme,
executing a query over the encrypted database is
based on the index of attributes. The result of this
query is a superset of records containing false positive
tuples. These false hits must be removed in a post fil-
tering process after etuples returned by the query are
decrypted. Because only the bucket id is used in a join
operation, filtering can be complex, especially when
random mapping is used to assign bucket ids rather
than order preserving mapping. The number of false
positive records depends on the number of buckets in-
volved. Using a small number of buckets will hide the
real values within the bucket index, but the filtering
overhead can become excessive. On the other hand, a
large number of buckets will reduce the filtering over-
head, but the scheme will be vulnerable to estimation
exposure. In bucketing, the projection operation is not
implemented over the encrypted database, because a
row level encryption is used. In addition, updating at-
tributes in the bucketing approach requires that two
attributes be updated, the bucket-id and the etuple.
This means that all attributes in the row must be re-
A SECURE AND EFFICIENT ORDER PRESERVING ENCRYPTION SCHEME FOR RELATIONAL DATABASES
33

encrypted, thereby increasing overhead for the update
query.
Many researchers have investigated the problem
of keywords searching on encrypted data using either
symmetric encryption (Song et al., 2000), asymmet-
ric encryption (Boneh et al., 2004) or a combination
of symmetric, asymmetric encryption and hash func-
tions (Dong et al., 2008). In spite of security vul-
nerabilities (like statistical attack (Song et al., 2000))
and significant overhead (Boneh et al., 2004; Dong
et al., 2008), these encryption schemes are possibly
useful in searching for keywords in a file, document
or email. However, these solutions can not be applied
to the problem of efficiently querying encrypted re-
lational databases. Especially, we discuss in this pa-
per the problem of encrypting integer data, executing
range queries and implementing relational operations
over encrypted database.
9 CONCLUSIONS
We propose a novel order preserving encryption
scheme (MV-POPES) that is robust against known
plaintext attack and statistical attack. In MV-POPES,
we change the order of the plaintext values by por-
tioning the domain into many partitions and assign a
unique random number to each partition that repre-
sents the order in the encrypted domain. MV-POPES
allows one integer to be encrypted to many different
values using the same encryption key. It also pre-
serves the order of the integer values within each par-
tition to allow comparison operation to be directly
applied to the encrypted data. We have developed
techniques so that most processes in executing SQL
queries can be done on encrypted databases. In some
cases, a small amount of work to filter false positives
or perform relational operations is needed on the de-
crypted data. Experiments on MV-POPES showed
that security for sensitive data can be achieved with
reasonable overhead, confirming the feasibility of the
scheme. In the future, we will investigate the opti-
mal algorithm for domain partitioning that minimize
performance overhead in query processing and ensure
high privacy. We also plan to study the encryption of
non-integer data such as strings.
ACKNOWLEDGEMENTS
This research has been supported in part by the
Graint-in-Aid for Scientific Research from MEXT
(#21013004) and Grant-in-Aid for Young Scientists
(B) (#21700093) by JSPS.
REFERENCES
AES (2001). Advanced encryption standard. National In-
stitute of Science and Technology, FIPS 197.
Agrawal, R., Kiernan, J., Srikant, R., and Xu, Y. (2004).
Order preserving encryption for numeric data. In
SIGMOD ’04: Proceedings of the 2004 ACM SIG-
MOD international conference on Management of
data, pages 563–574, New York, NY, USA. ACM.
Blum, M. and Micali, S. (1984). How to generate crypto-
graphically strong sequences of pseudo-random bits.
SIAM J. Comput., 13(4):850–864.
Boneh, D., Crescenzo, G. D., Ostrovsky, R., and Per-
siano, G. (2004). Public key encryption with key-
word search. In EUROCRYPT 2004: Proceedings
of International Conference on the Theory and Appli-
cations of Cryptographic Techniques, pages 506–522.
Springer.
Chung, S. S. and Ozsoyoglu, G. (2006). Anti-tamper
databases: Processing aggregate queries over en-
crypted databases. In ICDEW ’06: Proceedings of
International Conference on Data Engineering Work-
shops, page 98, Washington, DC, USA. IEEE Com-
puter Society.
DES (1977). Data encryption standard. Federal Information
Processing Standards Publication, FIPS PUB 46.
Dong, C., Russello, G., and Dulay, N. (2008). Shared
and searchable encrypted data for untrusted servers.
In Proceeedings of the 22nd annual IFIP working
conference on Data and Applications Security, pages
127–143, Berlin, Heidelberg. Springer-Verlag.
Hacig¨um¨us¸, H., Iyer, B., Li, C., and Mehrotra, S. (2002).
Executing SQL over encrypted data in the database-
service-provider model. In SIGMOD ’02: Proceed-
ings of the 2002 ACM SIGMOD international confer-
ence on Management of data, pages 216–227, New
York, NY, USA. ACM.
Hore, B., Mehrotra, S., and Tsudik, G. (2004). A privacy-
preserving index for range queries. In VLDB ’04: Pro-
ceedings of the 30th international conference on Very
large databases, pages 720–731. VLDB Endowment.
Hsueh, S. (February 2008). Database encryption in SQL
server 2008 enterprise edition. Microsoft White Pa-
pers, SQL Server 2008.
Kadhem, H., Amagasa, T., and Kitagawa, H. (2010).
MV-OPES: Multivalued - order preserving encryption
scheme: A novel scheme for encrypting integer value
to many different values. IEICE Transactions, 93-
D(9):accepted.
Menezes, A. J., Vanstone, S. A., and Oorschot, P. C. V.
(1996). Handbook of Applied Cryptography. CRC
Press, Inc., Boca Raton, FL, USA.
Ozsoyoglu, G., Singer, D. A., and Chung, S. S.
(2003). Anti-tamper databases: Querying encrypted
databases. In 17th Annual IFIP Working Conference
on Database and Applications Security, Estes Park,
pages 4–6.
KMIS 2010 - International Conference on Knowledge Management and Information Sharing
34

Rivest, R. L., Shamir, A., and Adleman, L. (1978). A
method for obtaining digital signatures and public-key
cryptosystems. Commun. ACM, 21(2):120–126.
Schneier, B. (1994). Description of a new variable-
length key, 64-bit block cipher (Blowfish). In Fast
Software Encryption, Cambridge Security Workshop,
pages 191–204, London, UK. Springer-Verlag.
Song, D. X., Wagner, D., and Perrig, A. (2000). Practical
techniques for searches on encrypted data. In SP’00:
Proceedings of the 2000 IEEE Symposium on Security
and Privacy, page 44, Washington, DC, USA. IEEE
Computer Society.
Wang, H. and Lakshmanan, L. V. S. (2006). Efficient se-
cure query evaluation over encrypted XML databases.
In VLDB ’06: Proceedings of the 32nd international
conference on Very large databases, pages 127–138.
A SECURE AND EFFICIENT ORDER PRESERVING ENCRYPTION SCHEME FOR RELATIONAL DATABASES
35
