
COEVOLUTIONARY ARCHITECTURES WITH STRAIGHT LINE
PROGRAMS FOR SOLVING THE SYMBOLIC REGRESSION
PROBLEM
Cruz Enrique Borges, C´esar L. Alonso
∗
, Jos´e Luis Monta˜na
Departamento de Matem´aticas, Estad´ıstica y Computaci´on, Universidad de Cantabria, 39005 Santander, Spain
∗
Centro de Inteligencia Artificial, Universidad de Oviedo, Campus de Viesques, 33271 Gij´on, Spain
Marina de la Cruz Echeand´ıa, Alfonso Ortega de la Puente
Departamento de Ingenier´ıa Inform´atica, Escuela Polit´ecnica Superior, Universidad Aut´onoma de Madrid, Madrid, Spain
Keywords:
Genetic programming, Straight-line programs, Coevolution, Symbolic regression.
Abstract:
To successfully apply evolutionary algorithms to the solution of increasingly complex problems we must de-
velop effective techniques for evolving solutions in the form of interacting coadapted subcomponents. In this
paper we present an architecture which involves cooperative coevolution of two subcomponents: a genetic pro-
gram and an evolution strategy. As main difference with work previously done, our genetic program evolves
straight line programs representing functional expressions, instead of tree structures. The evolution strategy
searches for good values for the numerical terminal symbols used by those expressions. Experimentation has
been performed over symbolic regression problem instances and the obtained results have been compared
with those obtained by means of Genetic Programming strategies without coevolution. The results show that
our coevolutionary architecture with straight line programs is capable to obtain better quality individuals than
traditional genetic programming using the same amount of computational effort.
1 INTRODUCTION
Coevolutionary strategies can be considered as an in-
teresting extension of the traditional evolutionary al-
gorithms. Basically, coevolution involvestwo or more
evolutionary processes with interactive performance.
Initial ideas on modelling coevolutionary processes
were formulatedin (Maynard, 1982), (Axelrod, 1984)
or (Hillis, 1991). A coevolutionary strategy consists
in the evolution of separate populations using their
own evolutionary parameters (i.e. genotype of the in-
dividuals, recombination operators, ...) but with some
kind of interaction between these populations. Two
basic classes of coevolutionary algorithms have been
developed: competitive algorithms and cooperative
algorithms. In the first class, the fitness of an indi-
vidual is determined by a series of competitions with
other individuals. Competition takes place between
the partial evolutionary processes coevolving and the
success of one implies the failure of the other (see,
for example, (Rosin and Belew, 1996)). On the other
hand, in the second class the fitness of an individual
is determined by a series of collaborations with other
individuals from other populations.
The standard approach of cooperative coevolution
is based on the decomposition of the problem into
several partial components. The structure of each
componentis assigned to a different population. Then
the populations are evolved in isolation from one an-
other but in order to compute the fitness of an individ-
ual from a population, a set of collaborators are se-
lected from the other populations. Finally a solution
of the problem is constructed by means of the combi-
nation of partial solutions obtained from the different
populations. Some examples of application of coop-
erative coevolutionary strategies for solving problems
can be found in (Wiegand et al., 2001) and (Casillas
et al., 2006).
This paper focuses on the design and the study
of several coevolutionary strategies between Ge-
netic Programming (GP) and Evolutionary Algo-
rithms (EA). Although in the cooperative systems the
coevolving populations usually are homogeneous(i.e.
with similar genotype representations), in this case
41
Enrique Borges C., L. Alonso C., Luis Montaña J., de la Cruz Echeandia M. and Ortega de la Puente A..
COEVOLUTIONARY ARCHITECTURES WITH STRAIGHT LINE PROGRAMS FOR SOLVING THE SYMBOLIC REGRESSION PROBLEM.
DOI: 10.5220/0003075100410050
In Proceedings of the International Conference on Evolutionary Computation (ICEC-2010), pages 41-50
ISBN: 978-989-8425-31-7
Copyright
c
2010 SCITEPRESS (Science and Technology Publications, Lda.)

we deal with two heterogeneous populations: one
composed by elements of a structure named straight
line program (slp) that represents programs and the
other one composed by vectors of real constants. The
coevolution between GP and EA was applied with
promising results in (Vanneschi et al., 2001). In that
case a population of trees and another one of fixed
length strings were used.
We have applied the strategies to solve symbolic
regression problem instances. The problem of sym-
bolic regression consists in finding in symbolic form
a function that fits a given finite sample set of data
points. More formally, we consider an input space
X = IR
n
and an output space Y = IR. We are given
a set of m pairs sample z = (x
i
,y
i
)
1≤i≤m
. The goal is
to construct a function f : X → Y which predicts the
value y ∈ Y from a given x ∈ X. The empirical error
of a function f with respect to z is:
ε
z
( f) =
1
m
m
∑
i=1
( f(x
i
) − y
i
)
2
(1)
which is known as the mean square error (MSE).
In our coevolutionary processes for finding the
function f, the GP will try to guess the shape of the
function whereas the EA will try to adjust the coeffi-
cients of the function. The motivation is to exploit the
following intuitive idea: once the shape of the sym-
bolic expression representing some optimal function
has been found, we try to determine the best values of
the coefficients appearing in the symbolic expression.
One simple way to exemplify this situation is the fol-
lowing. Assume that we have to guess the equation
of a geometric figure. If somebody (for example a GP
algorithm) tells us that this figure is a quartic func-
tion, it only remains for us to guess the appropriate
coefficients. This point of view is not new and it con-
stitutes the underlying idea of many successful meth-
ods in Machine Learning that combine a space of hy-
potheses with least square methods. Previous work in
which constants of a symbolic expression have been
effectively optimized has also dealt with memetic al-
gorithms, in which classical local optimization tech-
niques as gradient descent (Topchy and Punch, 2001),
linear scaling (Keijzer, 2003) or other methods based
on diversity measures (Ryan and Keijzer, 2003) were
used.
The paper is organized as follows: section 2 pro-
vides the definition of the structure that will represent
the programs and also includes the details of the de-
signed GP algorithm. In section 3 we describe the
EA for obtaining good values for the constants. Sec-
tion 4 presents the cooperative coevolutionary archi-
tecture used for solving symbolic regression problem
instances. In section 5 an experimental comparative
study of the performanceof our coevolutionarystrate-
gies is done. Finally, section 6 draws some conclu-
sions and addresses future research directions.
2 GP WITH STRAIGHT LINE
PROGRAMS
In the GP paradigm, the evolved computer programs
are usually represented by directed trees with or-
dered branches (Koza, 1992). We use in this paper
a structure for representing programs called straight
line program (slp). A slp consists of a finite se-
quence of computational assignments where each as-
signment is obtained by applying some function to a
set of arguments that can be variables, constants or
pre-computed results. The slp structure can describe
complex computable functions using less amount of
computational resources than GP-trees, as they can
reuse previously computed results during the evalu-
ation process. Now follows the formal definition of
this structure.
Definition. Let F = { f
1
,..., f
n
} be a set of functions,
where each f
i
has arity a
i
, 1 ≤ i ≤ n, and let T =
{t
1
,...,t
m
} be a set of terminals. A straight line pro-
gram (slp) over F and T is a finite sequence of com-
putational instructionsΓ = {I
1
,...,I
l
}, where for each
k ∈ {1,...,l}, I
k
≡ u
k
:= f
j
k
(α
1
,...,α
a
j
k
);with f
j
k
∈
F, α
i
∈ T for all i if k = 1 and α
i
∈ T ∪ {u
1
,...,u
k−1
}
for 1 < k ≤ l.
The set of terminals T satisfies T = V ∪ C where
V = {x
1
,...,x
p
} is a finite set of variables and C =
{c
1
,...,c
q
} is a finite set of constants. The number of
instructions l is the length of Γ.
Observe that a slp Γ = {I
1
,...,I
l
} is identified
with the set of variables u
i
that are introduced by
means of the instructions I
i
. Thus the slp Γ can be de-
noted by Γ = {u
1
,...,u
l
}. Each of the non-terminal
variables u
i
represents an expression over the set of
terminals T constructed by a sequence of recursive
compositions from the set of functions F.
An output set of a slp Γ = {u
1
,...,u
l
} is any
set of non-terminal variables of Γ, that is O(Γ) =
{u
i
1
,...,u
i
t
}. Provided that V = {x
1
,...,x
p
} ⊂ T is
the set of terminal variables, the function computed
by Γ, denoted by Φ
Γ
: I
p
→ O
t
, is defined recursively
in the natural way and satisfies Φ
Γ
(a
1
,...,a
p
) =
(b
1
,...,b
t
), where b
j
stands for the value of the ex-
pression overV of the non-terminal variable u
i
j
when
we substitute the variable x
k
by a
k
; 1 ≤ k ≤ p.
Example. Let F be the set given by the three binary
standard arithmetic operations, F = {+,−, ∗} and let
T = {1, x
1
,x
2
} be the set of terminals. In this situation
ICEC 2010 - International Conference on Evolutionary Computation
42

any slp over F and T is a finite sequence of instruc-
tions where each instruction represents a polynomial
in two variables with integer coefficients. If we con-
sider the following slp Γ of length 5 with output set
O(Γ) = {u
5
}:
Γ ≡
u
1
:= x
1
+ 1
u
2
:= u
1
∗ u
1
u
3
:= x
2
+ x
2
u
4
:= u
2
∗ u
3
u
5
:= u
4
− u
3
(2)
the function computed by Γ is the polynomial
Φ
Γ
= 2x
2
(x
1
+ 1)
2
− 2x
2
Straight line programs have a large history in the
field of Computational Algebra. A particular class
of straight line programs, known in the literature as
arithmetic circuits, constitutes the underling compu-
tation model in Algebraic Complexity Theory (Bur-
guisser et al., 1997). They have been used in lin-
ear algebra problems (Berkowitz, 1984), in quantifier
elimination (Heintz et al., 1990) and in algebraic ge-
ometry (Giusti et al., 1997). Recently, slp’s have been
presented as a promising alternative to the trees in the
field of Genetic Programming, with a good perfor-
mance in solving some regression problem instances
(Alonso et al., 2008). A slp Γ = {u
1
,...,u
l
} over F
and T with output set O(Γ) = {u
l
} could also be con-
sidered as a grammar with T ∪ F as the set of termi-
nals, {u
1
,...,u
l
} as the set of variables, u
l
the start
variable and the instructions of Γ as the rules. This
grammar only generates one word that is the expres-
sion represented by the slp Γ. Note that this is not
exactly Grammar Evolution (GE). In GE there is a
user specified grammar and the individuals are inte-
ger strings which code for selecting rules from the
provided grammar. In our case each individual is a
context-free grammar generating a context-free lan-
guage of size one.
Hence we will work with slp’s over a set F of
functions and a set T of terminals. The elements of T
that are constants, i.e. C = {c
1
,...,c
q
}, they are not
fixed numeric values butreferences to numeric values.
Hence, specializing each c
i
to a fixed value we obtain
a specific slp whose corresponding semantic function
is a candidate solution for the problem instance.
For constructing each individual Γ of the initial
population, we adopt the following process: for each
instruction u
k
∈ Γ first an element f ∈ F is ran-
domly selected and then the function arguments of
f are also randomly chosen in T ∪ {u
1
,...,u
k−1
} if
k > 1 and in T if k = 1. We will consider popula-
tions with individuals of equal length L, where L is
selected by the user. In this sense, note that given a
slp Γ = {u
1
,...,u
l
} and L ≥ l, we can construct the
slp Γ
′
= {u
1
,...,u
l−1
,u
′
l
,...,u
′
L−1
,u
′
L
}, whereu
′
L
= u
l
and u
′
k
, for k ∈ {l,. . . ,L−1}, is any instruction. If we
consider the same output set for Γ and Γ
′
is easy to see
that they represent the same function, i.e. Φ
Γ
≡ Φ
Γ
′
.
Given a symbolic regression problem instance
with a sample set z = (x
i
,y
i
) ∈ IR
n
× IR, 1 ≤ i ≤ m,
and let Γ be a specific slp over F and T obtained by
means of the specialization of the constant references
C = {c
1
,...,c
q
}. In this situation, the fitness of Γ is
defined by the following expression:
F
z
(Γ) = ε
z
(Φ
Γ
) =
1
m
m
∑
i=1
(Φ
Γ
(x
i
) − y
i
)
2
(3)
That is, the fitness is the empirical error of the
function computed by Γ, with respect to the sample
set of data points z.
We will use the following recombination opera-
tors for the slp structure.
slp-crossover. Let Γ = {u
1
,...,u
L
} and Γ
′
= {u
′
1
,
...,u
′
L
} be two slp’s over F and T. For the construc-
tion of an offspring, first a position k in Γ is randomly
selected; 1 ≤ k ≤ L. Let S
u
k
= {u
j
1
,...,u
j
m
} be the set
of instructions of Γ involved in the evaluation of u
k
.
Assume that j
1
< ... < j
m
. Next we randomly select a
position t in Γ
′
with m ≤ t ≤ L and we substitute in Γ
′
the subset of instructions {u
′
t−m+1
,...,u
′
t
} by the in-
structions of Γ in S
u
k
suitably renamed. The renaming
function R applied to the elements of S
u
k
is defined
as R (u
j
i
) = u
′
t−m+i
, for all i ∈ {1,...,m}. With this
process we obtain the first offspring of the crossover
operation. For the second offspring we analogously
repeat this strategy, but now selecting first a position
k
′
in Γ
′
.
The underlying idea of the slp-crossover is to in-
terchange subexpressions between Γ and Γ
′
. The fol-
lowing example illustrates this fact.
Example. Let us consider two slp’s:
Γ ≡
u
1
:= x+ y
u
2
:= u
1
∗ u
1
u
3
:= u
1
∗ x
u
4
:= u
3
+ u
2
u
5
:= u
3
∗ u
2
Γ
′
≡
u
1
:= x∗ x
u
2
:= u
1
+ y
u
3
:= u
1
+ x
u
4
:= u
2
∗ x
u
5
:= u
1
+ u
4
If k = 3 then S
u
3
= {u
1
,u
3
} (in bold font). t must be
selected in {2,. . . , 5}. Assumed that t = 3, then the
first offspring is:
Γ
1
≡
u
1
:= x∗ x
u
2
:= x+ y
u
3
:= u
2
∗ x
u
4
:= u
2
∗ x
u
5
:= u
1
+ u
4
that contains the subexpression of Γ represented by
u
3
, and the rest of its instructions are taked from Γ
′
.
COEVOLUTIONARY ARCHITECTURES WITH STRAIGHT LINE PROGRAMS FOR SOLVING THE SYMBOLIC
REGRESSION PROBLEM
43

For the second offspring, if the selected position in Γ
′
is k
′
= 4, then S
u
4
= {u
1
,u
2
,u
4
}. Now if t
′
= 5, the
second offspring is:
Γ
2
≡
u
1
:= x+ y
u
2
:= u
1
∗ u
1
u
3
:= x∗ x
u
4
:= u
3
+ y
u
5
:= u
4
∗ x
Mutation. When mutation is applied to a slp Γ, the
first step consists in selecting an instruction u
i
∈ Γ at
random. Then a new random selection is made within
the argumentsof the function f ∈ F that appears in the
instruction u
i
. Finally the selected argument is substi-
tuted by another one in T ∪ {u
1
,...,u
i−1
} randomly
chosen.
As it is well known, the reproduction operation
applied to an individual returns an exact copy of the
individual.
3 THE EA TO ADJUST THE
CONSTANTS
In this section we describe an EA that provides
good values for the numeric terminal symbols C =
{c
1
,...,c
q
} appearing in the populations of slp’s that
evolve during the GP process. Assume a population
P = {Γ
1
,...,Γ
N
} constituted by N slp’s over F and
T = V ∪C. Let [a,b] ⊂ IR be the search space for the
constants c
i
, 1 ≤ i ≤ q. In this situation, an individual
c is represented by a vector of floating point numbers
in [a,b]
q
.
There are several ways of defining the fitness of
a vector of constants c, but in all of them the cur-
rent population P of slp’s that evolves in the GP pro-
cess is needed. So, given a sample set z = (x
i
,y
i
) ∈
IR
n
×IR, 1 ≤ i ≤ m, thatdefines a symbolic regression
instance, and given a vector of valuesfor the constants
c = (c
1
,...,c
q
), we could define the fitness of c with
the following expression:
F
EA
z
(c) = min{F
z
(Γ
c
i
); 1 ≤ i ≤ N} (4)
where F
z
(Γ
c
i
) is computed by equation 3 and repre-
sents the fitness of the slp Γ
i
after the specialization
of the references in C to the corresponding real values
of c.
Observe that when the fitness of c is computed by
means of the above formula, the GP fitness values of
a whole population of slp’s are also computed. This
could be a lot of computational effort when the size
of both populations increases. In order to prevent the
above situation new fitness functionsfor c can be con-
sidered, where only a subset of the population P of
the slp’s is evaluated. Previous work in cooperative
coevolutionary architecturessuggests two basic meth-
ods for selecting the subset of collaborators (Wiegand
et al., 2001): The first one in our case consists in the
selection of the best slp of the current population P
corresponding the GP process. The second one se-
lects two individuals from P: the best one and a ran-
dom slp.
Crossover. We will use arithmetic crossover (Schwe-
fel, 1981). Thus, in our EA, the crossover of two indi-
viduals c
1
and c
2
∈ [a,b]
q
produces two offsprings c
′
1
and c
′
2
which are linear combinations of their parents.
c
′
1
= λ·c
1
+(1−λ)·c
2
; c
′
2
= λ·c
2
+(1−λ)·c
1
(5)
In our implementation we randomly choose λ ∈
(0,1) for each crossover operation.
Mutation. A non-uniform mutation operator adapted
to our search space [a,b]
q
, which is convex, is used
(Michalewiczet al., 1994). The following expressions
define our mutation operator, with p = 0.5.
c
t+1
k
= c
t
k
+ ∆(t,b− c
t
k
), with probability p (6)
and
c
t+1
k
= c
t
k
− ∆(t,c
t
k
− a), with probability 1− p (7)
k = 1,...,q and t is the current generation. The func-
tion ∆ is defined as ∆(t,y) = y · r · (1 −
t
T
) where r
is a random number in [0,1] and T represents the
maximum number of generations. Note that function
∆(t,y) returnsa value in [0,y] such that the probability
of obtaining a value of ∆(t,y) close to zero increases
as t increases. Hence the mutation operator searchs
the space uniformly initially (when t is small), and
very locally at later stages.
In our EA we will use q-tournament as the selec-
tion procedure.
4 THE COEVOLUTIONARY
ARCHITECTURE
In our case the EA for tuning the constants is subor-
dinated to the main GP process with the slp’s. Hence,
several collaborators are used during the computation
of the fitness of a vector of constants c, whereas only
the best vector of constants is used to compute the fit-
ness of a population of slp’s.
A basic cooperative coevolutionary strategy be-
gins with the initialization of both populations. First
the fitness of the individuals of the slp’s population
are computed considering a randomly selected vector
of constants as collaborator. Then alternative genera-
tions of both cooperative algorithms in a round-robin
ICEC 2010 - International Conference on Evolutionary Computation
44

fashion are performed. This strategy can be general-
ized in a natural way by the execution of alternative
turns of both algorithms. We will consider a turn as
the isolated and uninterrupted evolution of one popu-
lation for a fixed number of generations. Note that if
a turn consists of only one generation we obtain the
basic strategy. We display below the algorithm de-
scribing this cooperative coevolutionary architecture:
begin
Pop_slp := initialize_GP-slp_population
Pop_const := initialize_EA-constants_population
Const_collabor := random(Pop_const)
evaluate(Pop_slp,Const_collabor)
While (not termination condition) do
Pop_slp := turn_GP(Pop_slp,Const_collabor)
Collabor_slp := {best(Pop_slp),
random(Pop_slp)}
Pop_const := turn_EA(Pop_const,Collabor_slp)
Const_collabor := best(Pop_const)
end
5 EXPERIMENTATION
5.1 Experimental Settings
The experimentation consists in the execution of the
proposed cooperative coevolutionary strategies, con-
sidering several types of target functions. Two exper-
iments were performed.
For the first experiment two groups of tar-
get functions are considered: the first group in-
cludes 100 randomly generated univariate polyno-
mials whose degrees are bounded by 5 and the
second group consists of 100 target functions rep-
resented by randomly generated slp’s over F =
{+,−,∗, /,sqrt,sin,cos,ln,exp} and T = {x,c}, c ∈
[−1,1], with length 16. We will name this second
group “target slp’s”.
A second experiment is also performed solving
symbolic regression problem instances associated to
the following three multivariate functions:
f
1
(x,y,z) = (x+ y+ z)
2
+ 1 (8)
f
2
(x,y,z,w) =
1
2
x+
1
4
y+
1
6
z+
1
8
w (9)
f
3
(x,y) = x y+ sin((x− 1) (y+ 1)) (10)
For every execution the sample set is constituted
by 30 points. In the case of the functions that belong
to the first experiment, the sample points are in the
range [−1, 1]. For the functions f
1
and f
2
the points
are in the range [−100,100] for all variables. Finally
function f
3
varies in the range [−3,3] along each axis.
The individuals are slp’s over F =
{+,−,∗, /,sqrt} in the executions related to the
100 generated polynomials and to the functions f
1
and f
2
. The function set F is incremented with the
operation sin for the problem instance associated to
f
3
and also with the operations cos, ln and exp for
the group of target slp’s.
Besides the variables, the terminal set also in-
cludes two referencesto constants for thepolynomials
and only one reference to a constant for the rest of the
target functions. The constants take values in [−1,1].
The particular settings for the parameters of the
GP process are the following: population size: 200,
crossover rate: 0.9, mutation rate: 0.05, reproduc-
tion rate: 0.05, 5-tournament as selection procedure
and maximum length of the slp’s: 16. In the case of
the EA that adjusts the constants, the population in-
cludes 100 vector of constants, crossover rate: 0.9,
mutation rate: 0.1 and 2-tournament as selection pro-
cedure. For all the coevolutionary strategies, the com-
putation of the fitness of an slp during the GP process
will use the best vector of constants as collaborator,
whereas in order to compute the fitness of a vector of
constants in the EA process, we consider a collabo-
rator set containing the best slp of the population and
another one randomly selected. Both processes are
elitist and a generational replacement between pop-
ulations is used. But in the construction of the new
population, the offsprings generated do not necessar-
ily replace their parents. After a crossover we have
four individuals: two parents and two offsprings. We
select the two best individuals with different fitness
values. Our motivation is to prevent premature con-
vergence and to maintain diversity in the population.
We compare the standard GP-slp strategy with-
out coevolution with three coevolutionary strategies
that follow the general architecture described in sec-
tion 4. We have implemented and executed over the
same sets of problem instances, the well known GP-
tree strategy with the standard recombination opera-
tors. Thus the obtained results are included in the
comparative study.
The first coevolutionary strategy, named Basic
GP-EA (BGPEA), consists in the alternative execu-
tion of one generation of each cooperative algorithm.
The second strategy, named Turns GP-EA (TGPEA),
generalizes BGPEA by means of the execution of al-
ternative turns of each algorithm. Finally, the third
strategy executes first a large turn of the GP algo-
rithm with the slp’s and then follows the execution
of the EA related with the constants until termination
condition was reached. This strategy is named Sep-
arated GP-EA (SGPEA). In the case of TGPEA we
have considered a GP turn as the evolution of the pop-
ulation of slp’s during 25 generations. On the other
hand, an EA turn consists of 5 generations in the evo-
COEVOLUTIONARY ARCHITECTURES WITH STRAIGHT LINE PROGRAMS FOR SOLVING THE SYMBOLIC
REGRESSION PROBLEM
45

lution of the population related to the constants. In
SGPEA strategy we divide the computational effort
between the two algorithms: 90% for GP and 10%
for EA. The computational effort (CE) is defined as
the total number of basic operations that have been
computed up to that moment.
In the first experiment one execution for each
strategy has been performed over the 200 generated
target functions. On the other hand, in the second ex-
periment we have executed all strategies 100 times for
each of the three multivariate functions f
1
, f
2
and f
3
.
For all the executions the evolution finished after 10
7
basic operations have been computed.
5.2 Experimental Results
Frequently, when different Genetic Programming
strategies for solving symbolic regression instances
are compared, the quality of the final selected model
is evaluated by means of its corresponding fitness
value over the sample set. But with this quality mea-
sure it is not possible to distinguish between good
executions and overfiting executions. Then it makes
sense to consider another new set of unseen points,
called the validation set, in order to give a more
appropriate indicator of the quality of the selected
model. So, let (x
i
,y
i
)
1≤i≤n
test
a validation set for the
target function g(x) (i.e. y
i
= g(x
i
)) and let f(x) be
the model estimated from the sample set. Then the
validation fitness vf
n
test
is defined by the mean square
error (MSE) between the values of f and the true val-
ues of the target function g over the validation set:
vf
n
test
=
1
n
test
n
test
∑
i=1
( f(x
i
) − y
i
)
2
(11)
An execution will be considered successful if the
final selected model f has validation fitness less than
10% of the range of the sample set z = (x
i
,y
i
)
1≤i≤30
.
That is:
vf
n
test
≤ 0.1
max
1≤i≤30
y
i
− min
1≤i≤30
y
i
(12)
On the other hand, an execution will be spurious
if the validation fitness of the selected model verifies:
vf
n
test
≥ 1.5|Q
3
− Q
1
| (13)
Were Q
1
and Q
3
represent, respectively, the first and
third quartile of the empirical distribution of the exe-
cutions in terms of the validation fitness. The spurious
executions will be removed from the experiment.
In what follows we shall present a complete statis-
tical comparative study about the performance of the
described coevolutionary strategies. For both experi-
ments we will show the empirical distribution of the
Table 1: Spurious and success rates for each strategy and
group of target functions.
P
R
5
[X] spurious success
SGPEA 13% 100%
TGPEA 8% 99%
BGPEA 11% 100%
GP− slp 12% 100%
GP−tree 12% 100%
SLP(F,T) spurious success
SGPEA 16% 98%
TGPEA 13% 99%
BGPEA 13% 98%
GP− slp 14% 96%
GP−tree 14% 99%
non-spurious executions as well as the values of the
mean, variance, median, worst and best execution in
terms of the validation fitness. We also present sta-
tistical hypothesis tests in order to determine if some
strategy is better than the others. We consider a val-
idation set of 200 new and unseen points randomly
generated.
5.2.1 Experiment 1
We shall denote the polynomial set as P
R
5
[X] and the
set of target slp’s over F and T as SLP(F,T). Table
1 displays for each strategy the spurious and success
rates of the executions. Note that the success rate
is computed after removing the spurious executions.
Figure 1 presents the empirical distribution of the ex-
ecutions over the two groups of generated target func-
tions. This empirical distribution is displayed using
standard box plot notation with marks at best execu-
tion, 25%, 50%, 75% and worst execution, consider-
ing the validation fitness of the selected model. Ta-
ble 2 specifies the values of the validation fitness for
the worst, median and best execution. Finally Table 3
shows the means an variances. Note that for these two
groups of functions one execution per target function
was performed.
Analyzing the information given by the above ta-
bles and figure we could deduce the following facts:
1. All methods have a similar rate of spurious execu-
tions and also the success rate is almost equal for
all strategies.
2. The empirical distributions of the non-spurious
runs are again very similar for all the studied
strategies. Probably for the group of polynomials,
SGPEA is slightly better than the others. Observe
in figure 1 that this strategy has the corresponding
box smaller and a little below than the other meth-
ods. SGPEA also has the best mean and variance
ICEC 2010 - International Conference on Evolutionary Computation
46
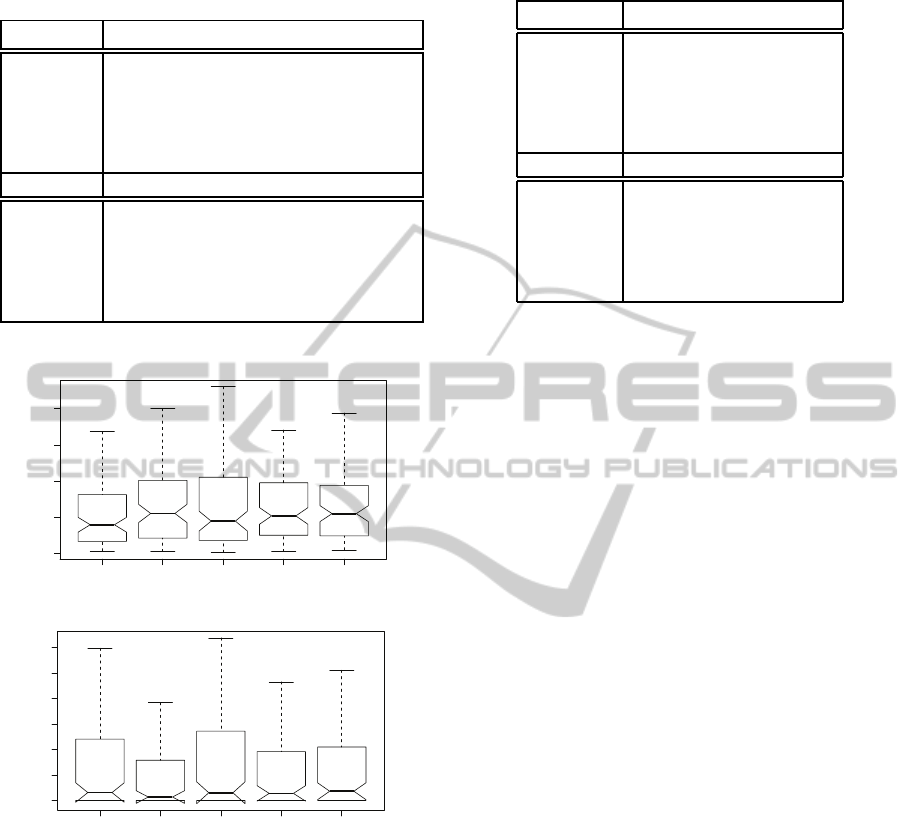
Table 2: Minimal, median and maximal values of the vali-
dation fitness for each method and group of target functions.
P
R
5
[X] min med max
SGPEA 3.25· 10
−3
3.33· 10
−2
0.17
TGPEA 2.27· 10
−3
4.58· 10
−2
0.2
BGPEA 1.25· 10
−3
3.58· 10
−2
0.23
GP− slp 2.26· 10
−3
4.48· 10
−2
0.17
GP−tree 4.64· 10
−3
4.42· 10
−2
0.19
SLP(F,T) min med max
SGPEA 0 1.6· 10
−3
0.12
TGPEA 0 1.66· 10
−3
7.69· 10
−2
BGPEA 0 2.84· 10
−3
0.13
GP− slp 0 1.61· 10
−3
9.32· 10
−2
GP−tree 0 4.29· 10
−3
0.1
SGPEA TGPEA BGPEA GP−slp GP−tree
0.00 0.05 0.10 0.15 0.20
Polynomials
SGPEA TGPEA BGPEA GP−slp GP−tree
0.00 0.04 0.08 0.12
slp
Figure 1: Empirical distributions of the non-spurious exe-
cutions for both groups of functions and for each strategy.
values (table 3). Nevertheless for the group of tar-
get slp’s it seems that the best method is TGPEA.
3. All strategies perform quite well over the tar-
get functions of this experiment, specially for the
group of target slp’s. Considering the values of
mean and variance and the fact that for each func-
tion only one execution was performed, probably
the BGPEA method is a little worse than the oth-
ers.
With the objective of justify the comparative quality
of the studied strategies we have made statistical hy-
pothesis tests between them, which results are showed
Table 3: Values of means and variances.
P
R
5
[X] µ σ
SGPEA 4.39· 10
−2
3.83· 10
−2
TGPEA 6.03· 10
−2
5.23· 10
−2
BGPEA 5.49· 10
−2
5.22· 10
−2
GP− slp 5.19· 10
−2
3.82· 10
−2
GP−tree 5.62· 10
−2
4.26· 10
−2
SLP(F,T) µ σ
SGPEA 1.62· 10
−2
2.79· 10
−2
TGPEA 1.14· 10
−2
1.78· 10
−2
BGPEA 1.96· 10
−2
3· 10
−2
GP− slp 1.49· 10
−2
2.33· 10
−2
GP−tree 1.5 · 10
−2
2.23· 10
−2
in table 4. Roughly speaking, the null-hypothesis in
each test with associated pair (i, j) is that strategy i is
not better than strategy j. Hence if value a
ij
of the el-
ement (i, j) in table 4 is less than a significance value
α, we can reject the corresponding null-hypothesis.
From the results presented in table 4 and with sig-
nificance values of α between 0.05 and 0.1, we can
conclude that for the group of polynomials the best
strategy is SGPEA whereas there is no clear winner
strategy for the group of target slp’s.
5.2.2 Experiment 2
In this experiment, the multivariate functions de-
scribed by the expressions 8, 9 and 10 have been con-
sidered as target functions. We have performed 100
executions for each strategy and function. In the fol-
lowing tables and figures we present for the new func-
tions the same results as those presented for the target
functions of experiment 1.
In termsof success rates, the coevolutionarymeth-
ods are of similar performance and they seem to be
better than the standard GP-slp strategy without co-
evolution. Nevertheless we can see that all the strate-
gies outperform the standard GP-tree procedure. This
fact is moreclear after observingin figure 2 the empir-
ical distributions of the non-spurious executions. For
the multivariate polynomialof degree two, f
1
, the best
strategy is SGPEA whereas for the linear polynomial
f
2
with four variables, TGPEA seems to be better than
the other strategies. In the case of the trigonometric
function f
3
it is not clear which is the best method.
But in any case, the standard GP-tree method is the
worst of the studied strategies.
In table 6 it can be seen that the validation fit-
ness has a big range, specially for functions f
1
and
f
2
. Hence, the mean and variance, displayed in ta-
ble 7, have also big values for the above two target
functions. Indeed the values are very big for f
1
, al-
COEVOLUTIONARY ARCHITECTURES WITH STRAIGHT LINE PROGRAMS FOR SOLVING THE SYMBOLIC
REGRESSION PROBLEM
47
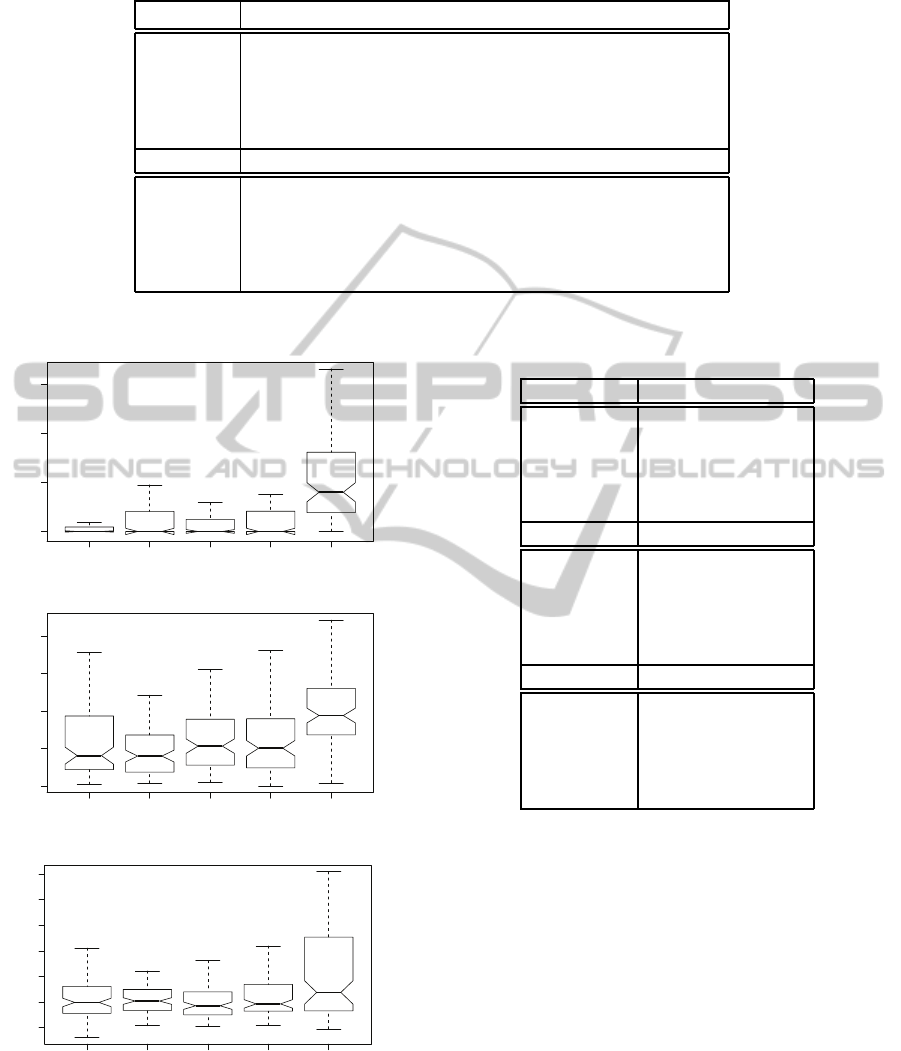
Table 4: Results of the crossed statistical hypothesis tests about the comparative quality of the studied strategies.
P
R
5
[X] SGPEA TGPEA BGPEA GP− slp GP− tree
SGPEA 1 2.51· 10
−2
0.27 8.9· 10
−2
6.1· 10
−2
TGPEA 0.78 1 0.8 0.53 0.45
BGPEA 0.9 0.3 1 0.12 0.17
GP− slp 0.99 0.28 0.59 1 0.4
GP−tree 1 0.61 0.77 0.75 1
SLP(F,T) SGPEA TGPEA BGPEA GP− slp GP− tree
SGPEA 1 0.82 0.44 0.82 0.39
TGPEA 0.54 1 0.14 0.44 0.28
BGPEA 0.99 1 1 0.93 0.7
GP− slp 0.74 0.93 0.49 1 0.39
GP−tree 0.82 0.99 0.49 0.9 1
SGPEA TGPEA BGPEA GP−slp GP−tree
0.0e+00 5.0e+07 1.0e+08 1.5e+08
f
1
(x, y, z)
SGPEA TGPEA BGPEA GP−slp GP−tree
0 200 400 600 800
f
2
(x, y, z, w)
SGPEA TGPEA BGPEA GP−slp GP−tree
0.4 0.5 0.6 0.7 0.8 0.9 1.0
f
3
(x, y)
Figure 2: Empirical distributions of the non-spurious exe-
cutions.
though the best execution over this function has val-
idation fitness equal to zero for all methods. Note
that for the above two functions the points are in the
Table 5: Spurious and success rates of the executions over
the multivariate functions.
f
1
(x,y,z) spurious success
SGPEA 25% 74%
TGPEA 13% 69%
BGPEA 19% 66%
GP− slp 11% 62%
GP−tree 5% 12%
f
2
(x,y,z,w) spurious success
SGPEA 7% 42%
TGPEA 7% 49%
BGPEA 6% 41%
GP− slp 7% 39%
GP−tree 12% 14%
f
3
(x,y) spurious success
SGPEA 8% 100%
TGPEA 14% 100%
BGPEA 9% 100%
GP− slp 9% 100%
GP−tree 20% 100%
range [− 100,100] for all variables. Considering the
results that appear in these two tables, we could say
that the coevolutionary strategies outperform the non-
coevolutionary ones.
Finally, as it was done in experiment 1, we have
made for the three functions the crossed statistical
hypothesis tests between all pairs of the considered
strategies and the results are showed in table 8. Con-
sidering a significant value α = 0.05 it seems that
for the function f
1
SGPEA is the best strategy but
there is no clear winner coevolutionary strategy for
the functions f
2
and f
3
. Nevertheless such results con-
firm that the coevolutionary methods are promising
strategies for solving symbolic regression problem in-
stances and that the slp structure is clearly better for
representing the models than the tree structure.
ICEC 2010 - International Conference on Evolutionary Computation
48
Table 8: Results of the crossed statistical hypothesis tests.
f
1
(x,y,z) SGPEA TGPEA BGPEA GP− slp GP−tree
SGPEA 1 3.39· 10
−4
1.41· 10
−3
9.23· 10
−5
4.53· 10
−31
TGPEA 1 1 1 0.44 7.13· 10
−19
BGPEA 0.97 0.12 1 2.66· 10
−2
7.46· 10
−24
GP− slp 0.91 0.43 0.9 1 3.47· 10
−15
GP−tree 1 1 1 1 1
f
2
(x,y,z,w) SGPEA TGPEA BGPEA GP− slp GP− tree
SGPEA 1 0.84 0.14 0.16 8.16· 10
−9
TGPEA 0.12 1 2.53· 10
−2
3.07· 10
−2
4.29· 10
−12
BGPEA 0.82 0.91 1 0.67 3.77· 10
−6
GP− slp 0.76 0.84 0.87 1 1.38· 10
−6
GP−tree 1 1 0.99 1 1
f
3
(x,y) SGPEA TGPEA BGPEA GP − slp GP− tree
SGPEA 1 0.41 0.96 0.28 2.06· 10
−2
TGPEA 0.32 1 0.84 0.37 5.23· 10
−3
BGPEA 0.35 4.65· 10
−2
1 2.84· 10
−2
1.29· 10
−2
GP− slp 0.44 0.51 0.99 1 5.86· 10
−2
GP−tree 0.93 0.42 0.88 0.34 1
Table 6: Minimal, median and maximal values of the vali-
dation fitness for each method and target function.
f
1
(x,y,z) min med max
SGPEA 0 1 94412.42
TGPEA 0 1 4.74· 10
7
BGPEA 0 1 2.8· 10
7
GP− slp 0 1 3.75· 10
7
GP− tree 3.91· 10
−24
3.38· 10
7
1.65· 10
8
f
2
(x,y,z,w) min med max
SGPEA 10.53 156.64 710.84
TGPEA 17.3 148.17 484.58
BGPEA 21.76 193.92 621.22
GP− slp 2.4 184.95 723.69
GP− tree 18.73 359.32 859.69
f
3
(x,y) min med max
SGPEA 0.36 0.49 0.71
TGPEA 0.41 0.49 0.62
BGPEA 0.41 0.48 0.66
GP− slp 0.41 0.48 0.72
GP− tree 0.39 0.51 1.01
6 CONCLUSIONS
We have designed several cooperative coevolution-
ary strategies between a GP and an EA. The genetic
program evolves straight line programs that represent
functional expressions whereas the evolutionary al-
gorithm optimizes the values of the constants used
by those expressions. Experimentation has been per-
formed on several groups of target functions and we
Table 7: Values of means and variances.
f
1
(x,y,z) µ σ
SGPEA 1345.95 10899.09
TGPEA 6.11· 10
6
1.37· 10
7
BGPEA 1.98· 10
6
5.09· 10
6
GP− slp 6.5 · 10
6
1.11· 10
7
GP−tree 4.72· 10
7
4· 10
7
f
2
(x,y,z,w) µ σ
SGPEA 211.05 150.71
TGPEA 175.2 116.59
BGPEA 221.29 133.87
GP− slp 229.7 157.18
GP−tree 362.58 160.8
f
3
(x,y) µ σ
SGPEA 0.5 6.41· 10
−2
TGPEA 0.5 4.79· 10
−2
BGPEA 0.49 5.86 · 10
−2
GP− slp 0.51 6.65· 10
−2
GP−tree 0.55 0.13
have compared the performance between the stud-
ied strategies. In all cases the computational ef-
fort is fixed to a maximum number of evaluations.
The quality of the selected model after the execution
was measured considering a validation set of unseen
points randomly generated, instead of the sample set
used for the evolution process. A complete statistical
study of the experimental results has been done. It
has been shown that the coevolutionary architectures
are promising strategies that in many cases are better
than the traditional GP algorithms without coevolu-
COEVOLUTIONARY ARCHITECTURES WITH STRAIGHT LINE PROGRAMS FOR SOLVING THE SYMBOLIC
REGRESSION PROBLEM
49

tion. We have also confirmed that the straight line
program structure clearly outperforms the traditional
tree structure used in GP to codify the individuals.
In future work we wish to study the behavior of
our coevolutionary model without assuming previous
knowledge of the length of the slp structure. To this
end new recombination operators must be designed.
On the other hand we could include some local search
procedure into the EA that adjusts the constants. Also
the fitness function could be modified, including sev-
eral penalty terms to perform model regularization
such as complexity regularization using the length of
the slp structure. Finally we might optimize the con-
stants of our slp’s by means of classical local opti-
mization techniques such as gradient descent or linear
scaling, as it was done for tree-based GP in (Keijzer,
2003) and (Topchy and Punch, 2001), and compare
the results with those obtained by the computational
model described in this paper.
ACKNOWLEDGEMENTS
This work is partially supported by spanish grants
TIN2007-67466-C02-02, MTM2004-01167 and
S2009/TIC-1650.
REFERENCES
Alonso, C. L., Montana, J. L., and Puente, J. (2008).
Straight line programs: a new linear genetic program-
ming approach. In Proc. 20th IEEE International
Conference on Tools with Artificial Intelligence (IC-
TAI), pages 517–524.
Axelrod, R. (1984). The evolution of cooperation. Basic
Books, New York.
Berkowitz, S. J. (1984). On comomputing the determinant
in small parallel time using a small number of pro-
cessors. In Information Processing Letters 18, pages
147–150.
Burguisser, P., Clausen, M., and Shokrollahi, M. A. (1997).
Algebraic Complexity Theory. Springer.
Casillas, J., Cordon, O., Herrera, F., and Merelo, J. (2006).
Cooperative coevolution for learning fuzzy rule-based
systems. In Genetic and Evolutionary Computation
Conference (GECCO 2006), pages 361–368.
Giusti, M., Heintz, J., Morais, J., Morgenstern, J. E., and
Pardo, L. M. (1997). Straight line programs in ge-
ometric elimination theory. In Journal of Pure and
Applied Algebra 124, pages 121–146.
Heintz, J., Roy, M. F., and Solerno, P. (1990). Sur la com-
plexite du principe de tarski-seidenberg. In Bulletin de
la Societe Mathematique de France, 118, pages 101–
126.
Hillis, D. (1991). Co-evolving parasites improve simulated
evolution as an optimization procedure. In Artificial
Life II, SFI Studies in the Sciences Complexity 10,
pages 313–324.
Keijzer, M. (2003). Improving symbolic regression with
interval arithmetic and linear scaling. In Procceedings
of EuroGP 2003, pages 71–83.
Koza, J. R. (1992). Genetic Programming: On the Pro-
gramming of Computers by Means of Natural Selec-
tion. The MIT Press, Cambridge, MA.
Maynard, J. (1982). Evolution and the theory of games.
Cambridge University Press, Cambridge.
Michalewicz, Z., Logan, T., and Swaminathan, S. (1994).
Evolutionary operators for continuous convex param-
eter spaces. In Proceedings of the 3rd Annual Confer-
ence on Evolutionary Programming, pages 84–97.
Rosin, C. and Belew, R. (1996). New methods for compete-
tive coevolution. In Evolutionary Computation 5 (1),
pages 1–29.
Ryan, C. and Keijzer, M. (2003). An analysis of diversity of
constants of genetic programming. In Procceedings of
EuroGP 2003, pages 409–418.
Schwefel, H. P. (1981). Numerical Optimization of Com-
puter Models. John Wiley and Sons, New-York.
Topchy, A. and Punch, W. F. (2001). Faster genetic pro-
gramming based on local gradient search of numeric
leaf values. In Proceedings of the 2001 conference
on Genetic and Evolutionary Computation (GECCO),
pages 155–162.
Vanneschi, L., Mauri, G., Valsecchi, A., and Cagnoni,
S. (2001). Heterogeneous cooperative coevolution:
Strategies of integration between GP and GA. In Proc.
of the Fifth Conference on Artificial Evolution (AE
2001), pages 311–322.
Wiegand, R. P., Liles, W. C., and Jong, K. A. D. (2001).
An empirical analysis of collaboration methods in co-
operative coevolutionary algorithms. In Proceedings
of the 2001 conference on Genetic and Evolutionary
Computation (GECCO), pages 1235–1242.
ICEC 2010 - International Conference on Evolutionary Computation
50
