
INTERACTIONS BETWEEN HEMISPHERES
WHEN DISAMBIGUATING AMBIGUOUS HOMOGRAPH
WORDS DURING SILENT READING
Zohar Eviatar
1
, Hananel Hazan
2
, Larry Manevitz
2
, Orna Peleg
1
and Rom Timor
2
1
Institute of Information Processing and Decision Making, University of Haifa, Haifa, Israel
2
Department of Computer Science, University of Haifa, Haifa, Israel
Keywords: Simulation, Neural network, Corpus collosum.
Abstract: A model of certain aspects of the cortex related to reading is developed corresponding to ongoing
exploration of psychophysical and computational experiments on how the two hemispheres work in
humans. The connectivity arrangements between modelled areas of orthography, phonology and semantics
are according to the theories of Eviatar and Peleg, in particular with distinctions between the connectivity in
the right and left hemisphere. The two hemispheres are connected and interact both in training and testing in
a reasonably "natural" way. We found that the RH (right hemisphere) serves to maintain alternative
meanings under this arrangement longer than the LH for homophones. This corresponds to the usual
theories (about homographs) while, surprisingly, the LH maintains alternative meanings longer then the RH
for heterophones. This allows the two hemispheres, working together to resolve ambiguities regardless of
when the disambiguating information arrives. Human experiments carried out subsequent to these results
bear this surprising result out.
1 INTRODUCTION
1
Neuropsychological studies have shown that both
cerebral hemispheres process written words, but they
do it in somewhat different ways (e.g., Iacoboni &
Zaidel, 1996, Grindrod & Baum, 2003).
Previous simulation work has examined the
activation of meanings of ambiguous words with
polarized meanings (where one meaning is much
more frequent (dominant) in the language) and has
shown that transfer of information from a 'right
hemisphere' (RH) network to a 'left hemisphere'
(LH) network, when context biasing to the
nondominant meaning is presented after the initial
presentation of the word, is the most efficient
mechanism for "recovery" from erroneous activation
of the dominant meaning. That is, there are
systematic cases where the LH purported
architecture could not recover by itself; nor could
the RH perform at high levels of performance (Peleg
et al., 2007, 2010). Other simulation work (Weems
& Regggia, 2004) suggests that different
connections can produce different results.
This paper examines different possible
connections between networks representing the two
hemispheres and how these differences affect the
results of processing homophones. (Monaghan &
Pollmann, 2003) shows that when stimuli have to be
matched in a complex task (such as whether two
letters have the same name), performance is better
when stimuli are presented across the hemispheres
of the brain. Furthermore, they argue that for
simpler tasks (such as whether two letters have the
same shape), better performance is achieved when
stimuli are presented unilaterally. They show that
this bilateral distribution advantage effect emerged
spontaneously in a neural network model learning to
solve simple and complex tasks with separate input
layers and separate, but interconnected, resources in
a hidden layer. They also show that relating
computational models to behavioral and imaging
data helps to understand hemispheric processing and
generating testable hypotheses.
This paper presents the computational advantage
of having two networks that can exchange
information: LH fully connected (Orthography,
1
The authors are listed in alphabetical order. This work appears as
p
art of the M.Sc. thesis of Rom Timor. We thank the Caesare
a
Rothschild Institute of University of Haifa for its support.
271
Eviatar Z., Hazan H., Manevitz L., Peleg O. and Timor R..
INTERACTIONS BETWEEN HEMISPHERES WHEN DISAMBIGUATING AMBIGUOUS HOMOGRAPH WORDS DURING SILENT READING .
DOI: 10.5220/0003059802710278
In Proceedings of the International Conference on Fuzzy Computation and 2nd International Conference on Neural Computation (ICNC-2010), pages
271-278
ISBN: 978-989-8425-32-4
Copyright
c
2010 SCITEPRESS (Science and Technology Publications, Lda.)

Phonology and Semantics) and RH lack of
connection between Orthography and Phonology.
2 BACKGROUND
Behavioral studies have shown that the LH is more
influenced by the phonological aspect of written
words whereas lexical processing in the RH is more
sensitive to visual form. A large amount of
psycholinguistic literature indicates that readers
utilize both frequency and context to resolve lexical
ambiguity (e.g., Titone, 1998 , Peleg et al., 2004).
Although hemispheric specialization for LH in
language processing is assumed, it is also assumed
that the RH plays a significant role in language
function, especially when ambiguous words are
presented in context (e.g. Burgess & Simpson,
1988).
Behavioral studies examining the disambiguation
of homophones (e.g., “bank”) suggest that all
meanings of an ambiguous word are initially
activated in both hemispheres, but at different
speeds. While the LH quickly activates both
meanings and then selects one alternative (the
contextually compatible meaning when prior
contextual information is biased, or the salient, more
frequent meaning when embedded in non-
constraining contexts), the RH activates the
nondominant meaning more slowly, and maintains
both alternate meanings (including less salient,
subordinate and contextually inappropriate
meanings).
Previous studies also suggests that exchange of
information between the LH and the RH networks
will produce better performance and can help the LH
recover the subordinate meaning, when it is
appropriate to the context (This task the LH could
not perform in isolation.)
2.1 Research Goals
The main goal is to investigate how different types
of information (phonological, lexical and contextual)
are utilized during silent reading in the two
connected networks simulating the left and right
hemispheres. Specifically the results are crucial for
answers regarding inter-hemispheric relation during
the disambiguation process of homophones.
We achieved this goal by building a neural
network that can process word information
(phonological, lexical and contextual) and resolve
the meaning of ambiguous words in Hebrew. The
network is based on (Peleg et al., 2007 & 2010) LH
and RH networks architecture while adding
connections between regions (Orthography,
Phonology and Semantics) in various ways.
The connected networks after training,
demonstrate the effects of context and frequency on
the resolution of homophones. The computer model
consists of "weakly coupled" neural networks that
can deal with ambiguity of a written or a spoken
word in Hebrew. The main idea is to investigate
some questions regarding the "weakly coupled"
connection properties such as when, how and where
information is transferred and determines the degree
of transferred information while shedding light on
the division of labor between hemispheres. The
"weakly coupled" networks should support the same
properties when disconnected and additional or
improved properties when connected.
Furthermore, we measure the time it take for the
connected networks to resolve the meaning and the
paths the networks use to do so. Then we compare
the results to existing psycholinguistics theories of
how humans process the language. One of the
reasons to build computational models is the ability
to change parameters, aspects and connection
properties of the models in ways that are not
possible with human subjects. This provides us with
an insight into the mechanisms of reading and
understanding the meaning of words.
3 PREVIOUS WORK
3.1 Kawamoto’s network
Kawamoto (Kawamoto, 1993) designed his neural
network model in such a way that the entire word,
including its orthographic, phonological and
semantic features occurs as an “attractor” in the
recurrent network.
According to his model, the more frequent a
certain meaning of the word in a certain context is,
the stronger the attractor it will be, and the
completion of other features (semantic and
phonological) would usually fall into this attractor.
Another factor examined was the time lapse
between accessing the dominant meaning and the
time lapse of accessing the secondary (subordinate)
meaning (Kawamoto, 1993).
3.2 Hazan’s Network
Peleg, Eviatar, Hazan & Manevitz in (Peleg et al.,
2007 and (Peleg et al., 2010) designed a two-
hemisphere model based on Kawamoto’s model (see
ICFC 2010 - International Conference on Fuzzy Computation
272
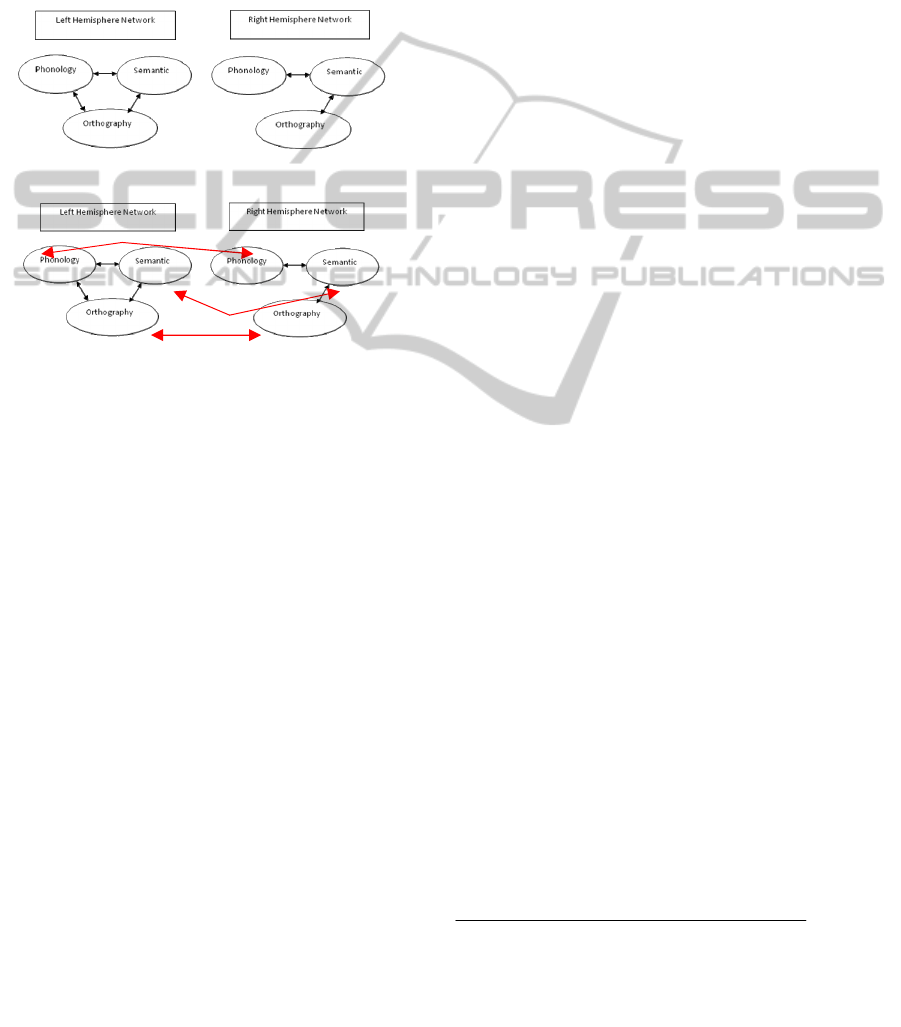
Figure 1). The model includes two separate
networks. One network incorporates Kawamoto’s
version, and successfully simulates the time course
of lexical disambiguation in the LH. In the other
network based on the behavior of the disconnected
RH of split brain patients (Zaidel & Peters, 1981), a
change was made in Kawamoto's architecture,
removing the direct connections between
orthographic and phonological units. (Peleg et al,
2010)
Figure 1: Hazan's network architecture.
Figure 2: Illustration of network that include CC
connections between Corresponding regions of LH & RH.
3.3 Weems & Reggia Network
Weems & Reggia tested hemispheric specialization
and independence for word recognition while
comparing three computational models: Callosal
Relay (strong right to left, minimal left to right
connectivity, output from LH), Direct Access
(minimal connectivity between hemispheres,
separate outputs) and Cooperative (strong
connection, single output) and showed advantage for
the Cooperative model together with a slight
performance dropdown (Weems & Reggia, 2004).
4 COMPUTATIONAL
SIMULATION
The simulation is based on (Peleg et al., 2007) LH
and RH network which includes the implementation
as described by (Kawamoto, 1993) with some
changes in the encoding. The simulation includes the
“Corpus Callosum” (CC) that was implemented as a
connection from LH units to RH units in a various
ways including "One to One
2
", "One to Many
3
",
within regions and between regions
4
(See Figure 2).
3.4 The Learning Stage
The network was trained with a simple error
correction algorithm (Kawamoto, 1993) taking into
consideration a learning constant and the magnitude
of the error determining a bipolar activity of a single
unit. This activity is determined by the input from
the environment, the units connected to it (within the
hemisphere and from the CC) and a decay in its
current level of activity. The learning process was
achieved by altering the weights between the units
of the network to minimize the error between the
activation level and the network input.
∆
,
n – Learning constant.
t
i
,
t
j
– target activation levels of unit i and j.
i
i
– net value of unit i.
In a learning trial an entry was selected randomly
from the lexicon. Dominant and subordinate
meanings were selected with a ratio of 5 to 3
roughly based on linguistic considerations. The
learning phase was divided to the following steps:
A. Initialization of units with random values.
B. Random order of sets of words.
C. The network was trained with 48 words.
D. The network was tested if more training is
needed. If so another 48 words were chosen to
continue the training. The testing had to fulfill
these conditions:
• Presenting the orthographic part of word leads
the network to select the dominant meaning.
• Presenting the orthographic part of word with a
clue to the subordinate meaning leads the
network to select the subordinate meaning.
The learning was stopped when the conditions
were fulfilled for each group of words (homophones,
hetrophones and normal words) separately or when
the training set ended.
In a learning trial an entry was selected randomly
from the lexicon. Dominant and subordinate
meanings were selected with a ratio of 5 to 3
roughly based on linguistic considerations. We
performed different experiments that include
different learning stages. First, the learning stage
2
One to One: each neuron from LH/RH is connected to the
corresponding neuron in the other hemisphere.
3
One to Many: each neuron from LH/RH is connected to a group o
f
neurons in the corresponding area of the other hemisphere.
4
Regions: Orthography, Phonology and Semantics.
INTERACTIONS BETWEEN HEMISPHERES WHEN DISAMBIGUATING AMBIGUOUS HOMOGRAPH WORDS
DURING SILENT READING
273
was done while the LH and RH are disconnected.
We connected them only while testing the model.
Second, the learning stage was done when the LH
and RH are connected via the CC. This was
performed in two manners: free learning (no
restriction on the CC weights) and restricted
learning. In the restricted learning the weights on the
CC did change but were limited to 0.1 - 0.3.
3.5 Testing the Model
After the networks were trained they were tested by
presenting just the orthographic part of the entry as
the input (to simulate neutral context) or by
presenting part of the semantic (subordinate
meaning) sub-vector after presenting the
orthography (to simulate contextual bias). In each
simulation the input sets the initial activation of the
units.
Each unit was influenced from the following
sources:
A. External stimuli (orthophonic part of word or
clues).
B. Previous values from the last iteration
multipled by the decay rate.
C. Sum of the inner connected units output
multipled by the weights.
D. Sum of the inter-hemispheric connected units
output (Simulates the CC).
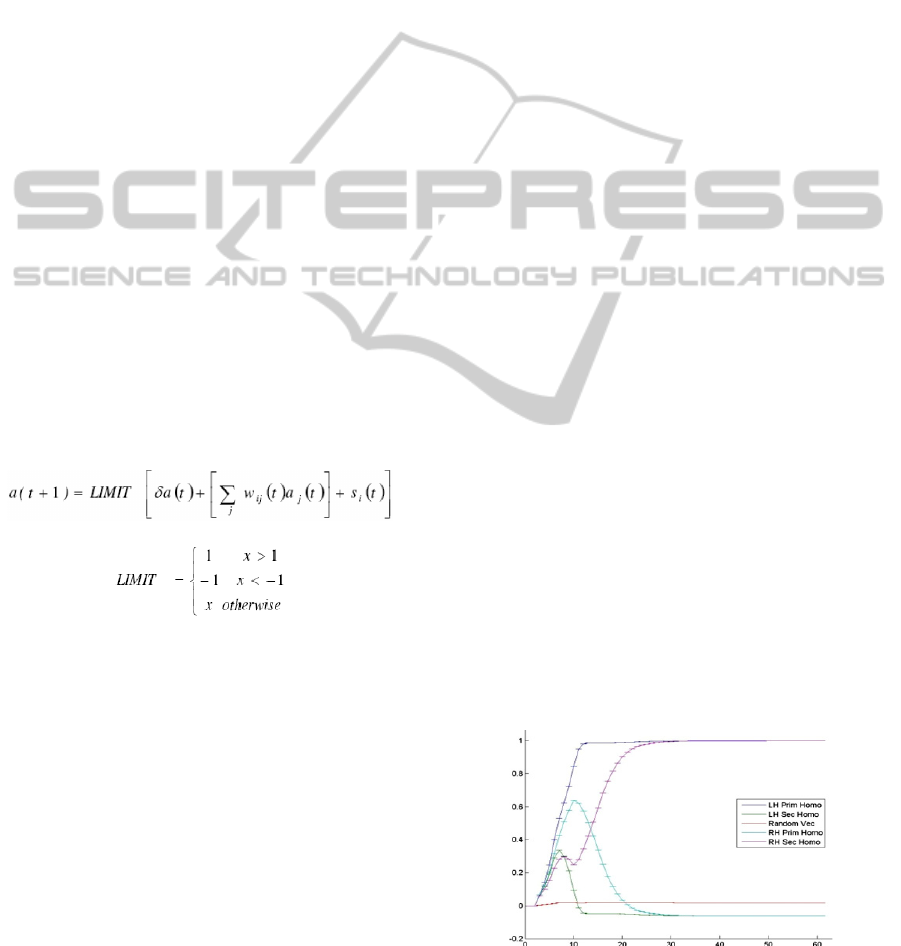
The activity of unit a at time t+1 is:
where:
δ – the decay variable.
The decay variable was set dynamically starting
from 0.6 , increasing while network is progressed
and ending at value of 1 when the run is completed.
In order to assess lexical access, the number of
iterations through the network requiered for all the
units in the spelling, pronunciation or meaning fields
to become saturated, was measured. A response was
considered an error if the pattern of activity did not
correspond with the input; non convergent if all the
units did not saturate after 50 iterations.
Testing was done after training the connected LH
and RH or after setting fixed weights on the CC. In
the latter case in different experiments the weights
were fixed uniformly at values that varied between
0.05 to 0.50 or one value was chosen for the weights
from LH to RH and a different one for RH to LH.
In order to test the maintenance of alternative
meanings, tests were run where no semantic clues
were given for various numbers of iterations (and
thus the networks started to converge towards the
dominant choice), and then clues for the subordinate
meaning were given. The differences in recovery of
the RH and LH in the different cases were measured.
3.6 Results and Analysis
In each simulation, 12 identical networks were used
to simulate 12 subjects in an experiment by varying
their training randomly. During the testing phase the
network received various inputs. First the
orthography of a word and then the inputs including
clues from the word meaning. The level was set to
+0.25 if the corresponding input feature was
positive, -0.25 if it was negative and 0 otherwise.
Result of each trial was recorded including the
number of iterations needed for coverage and the
total number of errors. The data was separated for:
• Group of words (homophones , hetrophones and
normal words).
• Type of clues (to subordinate or to dominate).
• Number of clues.
• CC weights or weight limitation.
• Mean and standard deviations were calculated.
In this work the focus was on the different type
of connections in the different ambiguity task
(hetrophonic vs. homophonic).
3.7 Results
Previous results of (Peleg et al., 2007 & 2010)
indicated that without transfer of data between LH
and RH the LH cannot recover to the subordinate
meaning after receiving semantic clues and thus
selects the dominant meaning. The RH was able to
perform this recovery and select the subordinate
meaning (See Figure 3). This phenomenon was
called the "Change of heart".
Figure 3: Network performance without CC. Only RH can
perform the "Change of heart" for homophones.
ICFC 2010 - International Conference on Fuzzy Computation
274
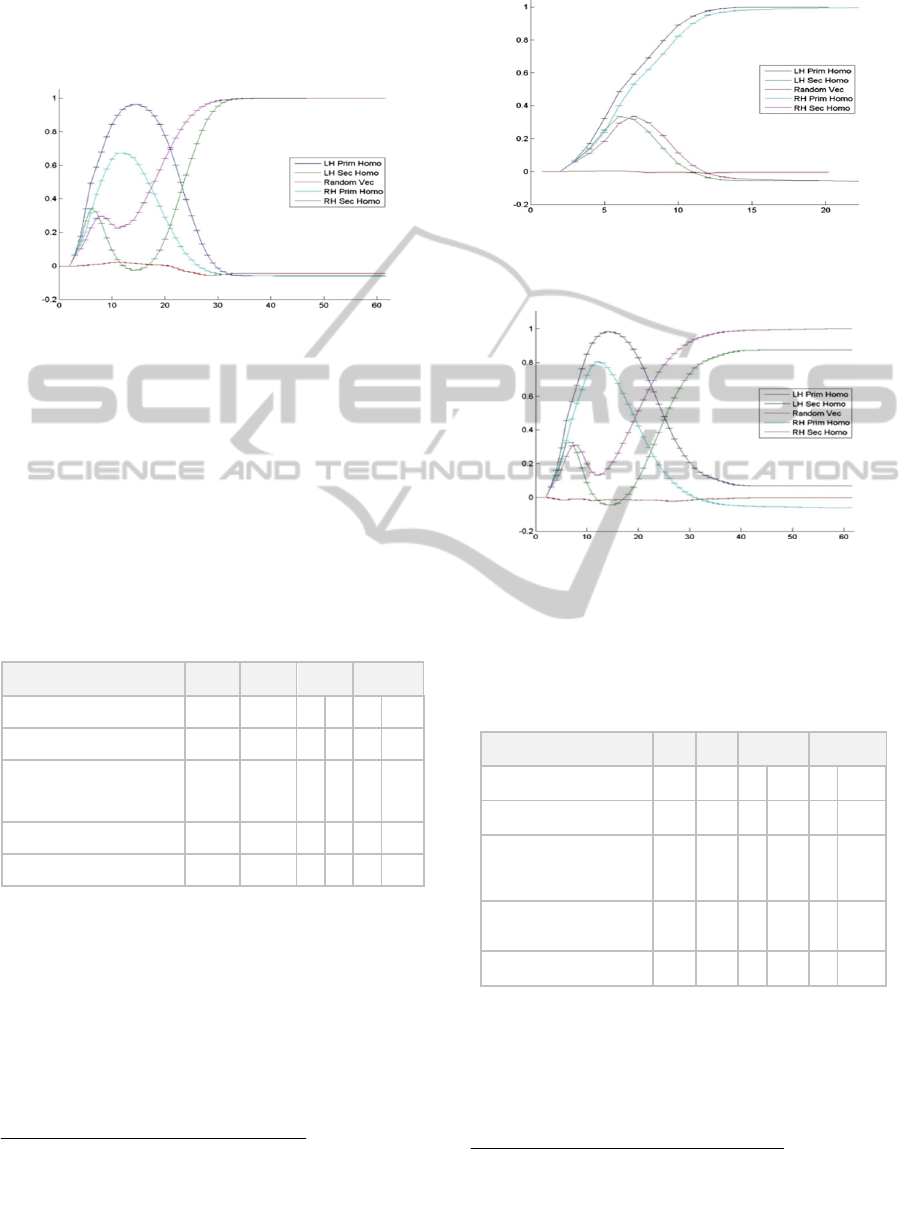
Our initial results indicated that when setting the
weights of CC from RH to LH to 0.25 in a "One to
One" connection the transfer of data from RH to LH
can help the LH perform the "Change of heart" and
select the subordinate meaning (See Figure 4).
Figure 4: Network performance with CC. RH & LH can
perform the "Change of heart" for homophones.
3.7.1 Homophones
Table 1 shows the results of average convergence
time
5
for LH and RH when presenting a homophonic
word without clues, the recovery status (in general)
when presenting a word with clues
6
to the
subordinate meaning and the sum of errors and non-
convergences.
Table 1: RH & LH convergence time (in iterations)
Homophones with no context (* Errors and Non-conv are
out of 96 in each hemisphere).
Network architecture LH RH
Errors*
LH/RH
Non-conv*
LH/RH
Without CC
40.32
(3.42)
41.54
(4.19)
29 0 37 0
With CC: Weights fixed at 0.25
(RH to LH)
39.18
(3.24)
41.06
(2.93)
11 0 14 0
With CC: Weights fixed at 0.25
(LH phonology to RH
phonology, RH semantics to LH
semantics).
39.77
(4.21)
40.69
(4.48)
23 12 19 7
With CC: Weights fixed at 0.25
RH to LH and 0.10 LH to RH.
39.84
(5.33)
40.14
(4.77)
21 9 17 11
With CC: Weights fixed at 0.25
(All, Both ways)
40.36
(6.03)
40.79
(5.64)
31 24 33 19
Connected learning yield the following results:
A. Free learning of CC weights caused the LH and
RH to lose their special properties. LH became
slower while selecting the dominant meaning and
the RH lost its ability to perform the "Change of
heart" when presented with clues to the
subordinate meaning (See Figure 5).
B. Restricted learning was able us to cause the LH
and RH to not lose their special properties. Both
RH and LH performed the "Change of heart" but
LH recovery is partial (See Figure 6).
Figure 5: Network performance with CC (Free learning).
RH & LH cannot perform the "Change of heart" for
homophones.
Figure 6: Network performance with CC (CC weights are
fixed at 0.25). RH & LH can perform the "Change of
heart". Note LH recovery is partial.
Table 2: Network performance in resolving hetrophone
(various architectures) [*Errors and Non-conv are out of
96 in each hemisphere]. Case 2 in this table above seems
to be the optimum for resolving hetrophone ambiguity.
Network architecture LH RH
Errors*
LH/RH
Non-conv*
LH/RH
Without CC
30.39
(4.88)
28.07
(5.14)
0 11 0 5
With CC: Weights fixed at
0.25 (LH to RH)
30.14
(5.11)
27.51
(5.37)
0 7 0 3
With CC: Weights fixed at
0.25 (RH phonology to LH
phonology, LH semantics to
RH semantics).
29.77
(6.52)
29.23
(5.93)
7 13 5 9
With CC: Weights fixed at
0.25 LH to RH and 0.10 RH
to LH.
29.63
(7.13)
28.36
(7.20)
9 16 4 2
With CC: Weights fixed at
0.25 (All, Both ways)
29.32
(9.31)
29.95
(8.67)
19 18 12 15
3.7.2 Hetrophones
Table 2 shows the results of average convergence
time
7
for LH and RH when presenting a hetrophonic
word without clues, the recovery status (in general)
when presenting the word with clues
8
to the
5
Standard deviation in parentheses.
6
Using different number of clues changed the results but in a unifor
m
way when comparing the results of different architectures. Th
e
result presented is for 4 clues out of 8.
7
Standard deviation in parentheses.
8
Using different number of clues changed the results but in a uniform
way when comparing the results of different architectures. The
result presented is for 4 clues out of 8.
INTERACTIONS BETWEEN HEMISPHERES WHEN DISAMBIGUATING AMBIGUOUS HOMOGRAPH WORDS
DURING SILENT READING
275
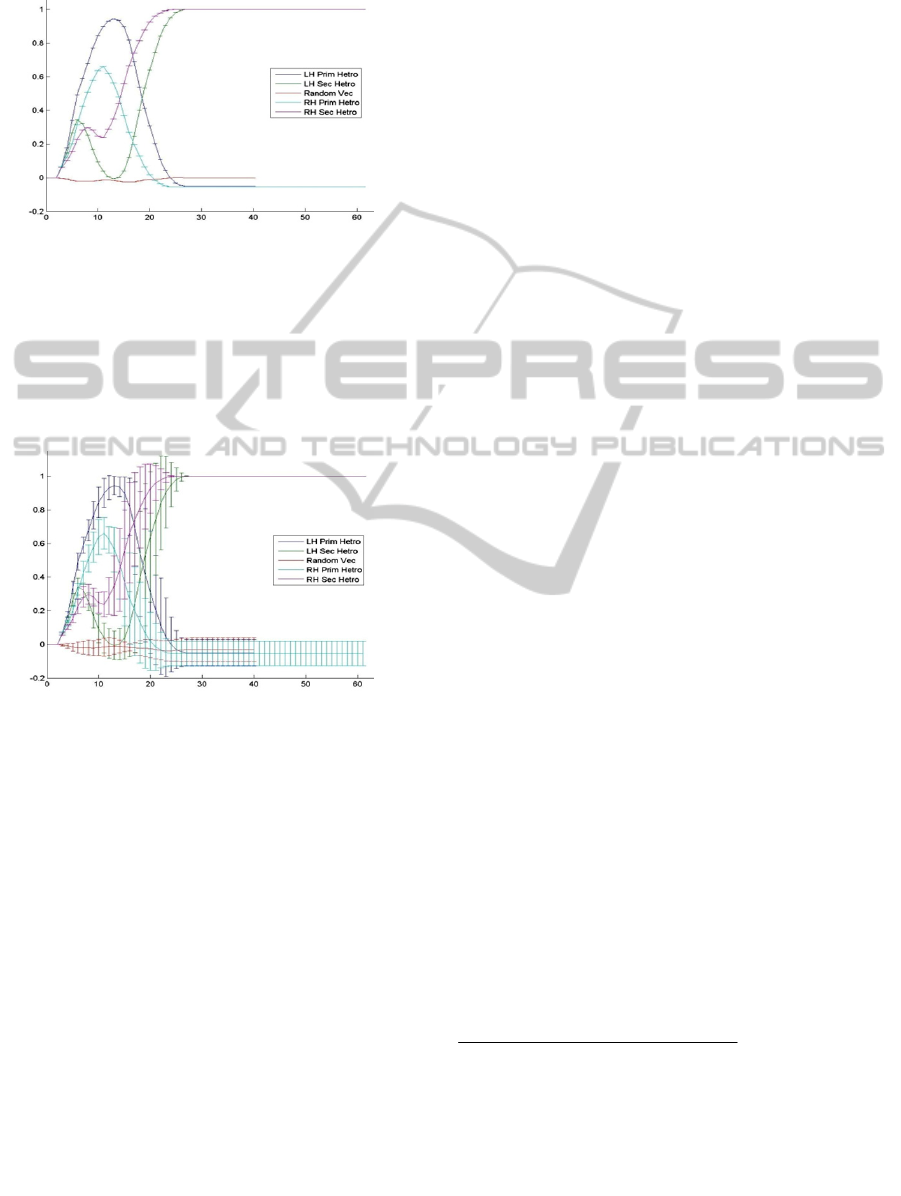
subordinate meaning and the sum of errors and non-
convergences.
Figure 7: Network performance when weights on CC are
fixed at 0.25 (LH to RH). Both LH and RH can perform
the "change of heart" for heterophones.
Figure 7 and 8 shows the time course of
convergence corresponding to case 2 in the table
above. Trails where performed for various CC
weights between 0.1 to 0.3 (with 0.05 intervals), one
way or both way, same regions or between regions.
Figure 8: The same diagram as the previous figure but
presented here with standard deviation.
4 DISCUSSION
4.1 Homophones vs. Hetrophones
Previous work (Peleg et al., 2007 & 2010) showed
that in the homophone case running the LH without
data transfer from RH has substantially worse
performance, both in number of iterations to
convergence and in the ability to perform the
"Change of heart" when presented with clues to the
subordinate meaning.
(Peleg et al., 2010) demonstrated the above by
transferring the data between the hemispheres
artificially. After some iterations the data from the
RH was copied to the LH and was clamped for
further iterations. Transfer of data from RH to LH in
homophones yieled better performance for the LH
even in cases when the RH has failed to perform the
recovery.
This work shows that:
1. Connecting the LH and RH in a more natural
way draws the same conclusions in
homophones (See Table 1 - Row 2 and Figure
3).
2. Data transfer in homophones is more beneficial
when done from RH to LH (See Table 1 - Row
2 compared to Table 1 Row 3-5).
3. Data transfer in hetrophones can be more
beneficial when done from LH to RH (See
Table 2 - Row 2 compared to Table 1 Row 3-
5). Note that results are less conclusive.
4. Connection between the hemispheres via the
CC is "weakly coupled" as compared to the
inner hemisphere connections (See Table 1 and
Table 2 Rows 2-5)
9
.
Word processing is different in LH and RH when
comparing different tasks such as homophone and
hetrophone disambiguate resolution. In homophones
the RH has less error and non-convergence cases
then LH but in the cost of convergence time.
Whereas in hetrophone the LH has less error and
non-convergence cases then RH but again in the cost
of convergence time
10
.
The convergence time
drawback in performance is an advantage when
trying to perform the "change of heart" from
dominate to subordinate meaning because then the
subordinate meaning is still available in the “slower”
hemisphere. This ability to perform the "change of
heart" more efficiently helps when transferring data
between hemispheres. The diffrence in convergence
time is due to the networks architectures.
4.2 Connected Learning vs. Separate
Learning
Results of connected learning also point out some
interesting facts. In general connected learning has
better performance in convergence time then with
separate learning.
Further, it is shown that free learning of the CC
weights causes the network to lose the "weakly
coupled" proportions and therefore the LH and RH
lose their special properties (convergence time and
9
Weights on the CC must be more than 0.05 in order to make
a
difference and less than 0.30 to prevent non convergence. Note that,
in contrast, inner hemispheric weights vary from -1 to 1, and forms
a relative strong intra-hemispheric connection between the
hemispheric regions orthography , phonology and semantics.
10
Note that in hetrophones the different time course of the LH is no
t
so significant than in homophones and therefore the results are no
t
as conclusive as in homophones.
ICFC 2010 - International Conference on Fuzzy Computation
276

"Change of heart"). Furthermore, learning with
bounded weights on the CC produces the desired
properties only if the CC bounded weights are less in
proportion to the interior hemispheric natural
boundary of weights (1 to -1), thus forming a
"weakly coupling" between the hemispheric
networks.
Results of LH and RH after connected learning
are slightly different then in separate learning. In
performance variables such as convergence time
there is a slight advantage to connected learning but
in errors measurements connected learning shows
worse results (in comparison to the results
demonstrated in separate learning).
As mentioned above the LH and RH has a
different time course and that each hemisphere has a
different time course in homophones and
heterophones. In separate learning it is shown that
the different between homophone and hetrophones
in the RH are not significant but are significant in
the LH. Further, separate learning shown than the
RH has a longer time course both in homophones
and in hetrophones. The different time course is
maintained in connected learning but it is noted that
the significant difference between homophones and
hetrophones is more prominent and that in the
connected learning the time course of RH is longer
only in homophones while in hetrophones the LH
has a longer time course.
In connected learning we can see that there is an
advantage to transfer data from RH to LH in
homophones and help the LH recover where in
hetrophone the transfer of data from LH to RH has
no significant effect. Note that in hetrophones
transfer of data from RH to LH has a negative effect
on the LH ability to recover.
4.3 Consequences for Human
Experiments
Recently, behavioral studies have been performed by
Peleg and Eviatar (Peleg & Eviatar, 2007 & 2010)
designed to test certain intra-hemispheric
connectivity assumptions that they put forward.
These studies combined divided visual field (DVF)
techniques with a semantic priming paradigm.
The behavioral studies were conducted in
Hebrew and combined a divided visual field (DVF)
technique with a semantic priming paradigm.
Subjects were asked to focus on the center of the
screen and to silently read sentences that were
presented centrally in two stages. First, the sentential
context was presented for 1500 ms and then the final
ambiguous prime was presented for 150 ms. After
the prime disappeared from the screen a target word
was presented to the left visual field (LVF) or the
right visual field (RVF) for the subject to make a
lexical decision. Targets were either related to the
dominant or the subordinate meaning or unrelated.
Magnitude of priming was calculated by subtracting
reaction time (RT) for related targets from RT to un-
related targets. The most interesting results were
observed in the subordinate-biasing context
condition (“The fisherman sat on the bank”): At 250
SOA both meanings (money and river) were still
activated in both hemispheres (Peleg & Eviatar,
2009). However, 750 ms later (1000 SOA), a
different pattern of results was seen in the two visual
fields. For homophones (e.g., “bank”), previous
results were replicated: the LH selected the
contextually appropriate meaning, whereas both
meanings were still activated in the RH These
studies, although limited to reaction time did
succeed in implying different patterns of activation
of both meanings in the two hemispheres. Our
simulations correspond to their intra-hemispheric
connectivity assumptions and produce results that fit
well with those human experiments and thereby
further support the theoretical underpinnings of
Peleg and Eviatar (Peleg & Eviatar, 2009). Here the
interpretation of the similarity of activation to
dominant and subordinate meanings at iterations is
taken as parallel to maintenance of the
corresponding meanings in the hemispheres.
Our work suggests a refinement of these
experiments to check as well the connectivity
strength between hemispheres. One possible method
to do this, would be to use Dynamic Causal
Modeling (Friston et al., 2003) to test the effective
connectivity between hemispheres during fMRI
studies. Such an experiment is currently being
prepared.
Our prediction as indicated above is that the RH
is functionally connected to the LH and vice versa
but in an asymmetric manner, with (1) the RH being
more strongly connected to LH than vice versa and
(2) the inter-hemispheric connections are relatively
weak compared to the intra-hemispheric
connections. In addition, our experiments indicate
that the major learning changes should be intra-
hemispheric.
5 SUMMARY
We implemented a model of both the RH and LH,
with architectural differences between the
hemispheres as proposed by the theories of Peleg
INTERACTIONS BETWEEN HEMISPHERES WHEN DISAMBIGUATING AMBIGUOUS HOMOGRAPH WORDS
DURING SILENT READING
277

and Eviatar (Peleg & Eviatar, 2009). The
hemispheres are linked together in a natural fashion,
both during learning and functioning. The results of
the simulations show that the connections between
the hemispheres allow additional functionality for
the LH as observed in humans ("change of heart");
and the hemispheres also perform at comparative
speeds that also qualitatively match human DVF
experiments.
Further, our work predicts connectivity strength
between the two hemispheres in architectural
regions; and thus suggests new human experiments.
REFERENCES
Iacoboni M, Zaidel E (1996). Hemispheric independence
in word recognition: evidence from unilateral and
bilateral presentations. Brain Lang 53:121–140 14.
Grindrod, C., & Baum, S. (2003). Sensitivity to local
sentence context information in lexical ambiguity
resolution: Evidence from left-right-hemisphere-
damaged individuals, Brain & Language, 85, 502-523.
Peleg, O., Eviatar, Z., Hazan, H, & Manevitz, L. (2007).
Differences and Interactions between Cerebral
Hemispheres When Processing Ambiguous
Homographs. Lecture Notes in Computer Science
(LNAI) publication no.4840, 'Attention in Cognitive
Systems', L. Paletta and E. Rome, Eds., pp. 367–380.
Weems, S. & Reggia, J. (2004). Hemispheric
specialization and independence for word recognition:
Acomparison of three computational models, Brain
and Language 89 554-568.
Monaghan, P. & Pollmann, S. (2003). Division of labour
between the hemispheres for complex but not simple
tasks: An implemented connectionist model. Journal
of Experimental Psychology: General, 132, 379-399.
Titone, D. A. 1998. Hemispheric differences in context
sensitivity during lexical ambiguity resolution. Brain
and Language, 65, 361-394.
Peleg, O., Giora, R., & Fein, O. (2004). Contextual
strength: The Whens and hows of context effects. In I.
Noveck & D. Sperber (Eds.), Experimental
Pragmatics (pp.172-186). Basingstoke: Pagrave.
Burgess, C., & Simpson, G. B. (1988). Cerebral
hemispheric mechanisms in the retrieval of ambiguous
word meanings. Brain and Language, 33 (pp. 86-103).
Kawamoto, A. H. (1993). Nonlinear dynamics in the
resolution of lexical ambiguity: A parallel distributed
processing account. Journal of Memory and
Language, 32, 474-516.
Zaidel, E., & Peters, A. M. (1981). phonological encoding
and ideographic reading by the disconnected right
hemisphere: Two case Studies. Brain & Language, 14,
205- 234.
Peleg O. and Eviatar Z (2009). Semantic asymmetries are
modulated by phonological asymmetries: Evidence
from the disambiguation of homophonic versus
heterophonic homographs. Brain and Cognition 70
(pp. 154–162).
Friston K. J., Harrison L. and Penny W. (2009). Dynamic
causal modelling. Neuroimage 2003 Aug;19(4) (pp.
1273-302).
Peleg, O., Manevitz, L., Hazan, H., Eviatar, Z., (2010).
Two Hemispheres - Two Networks A Computational
Model Explaining Hemispheric Asymmetries While
Reading Ambiguous Words. Annals of Mathematics
and Artificial Intelligence (AMAI). – to appear.
ICFC 2010 - International Conference on Fuzzy Computation
278
