
DYNAMIC ONTOLOGY CO-CONSTRUCTION BASED ON
ADAPTIVE MULTI-AGENT TECHNOLOGY
Zied Sellami, Marie-Pierre Gleizes, Nathalie Aussenac-Gilles
IRIT (Institut de Recherche en Informatique de Toulouse), Toulouse University
118 Route de Narbonne, F-31062 Toulouse cedex 9, France
Sylvain Rougemaille
UPETEC (Emergence Technologies for Unsolved Problems), 10 avenue de l’europe, 31520 Ramonville, France
Keywords:
Ontology engineering, Multi-Agent System, Knowledge acquisition.
Abstract:
Ontologies have become an important means for structuring knowledge and defining semantic information
retrieval systems. Ontology engineering requires a significant effort, and recent researches show that human
language technologies are useful means to acquire or update ontologies from text. In this paper we present
DYNAMO, a tool based on a Multi-Agent System, which aims at assisting ontologists during the ontology
building and evolution processes. This work is carried out in the context of the DYNAMO project. The main
novelty of the agent system is to take advantage of text extracted terms and lexical relations together with some
quantitative features of the corpus to guide the agents when self-organizing. We exhibit the first experiment
of ontology building that shows promising results, and helps us to identify key issues to be solved to the
DYNAMO system behavior and the resulting ontology.
1 INTRODUCTION
One way to provide efficient search on a document re-
trieval system is to explicitly state the meaning of doc-
ument contents. On-going research in this area tries
to address the problem by tagging and indexing the
contents of documents thanks to an organised knowl-
edge representation called ontology.
Ontologies are often used to represent a specifi-
cation of domain knowledge by providing a consen-
sual agreement on the semantics of domain concepts,
or an agreement on the concepts required for a spe-
cific knowledge intensive application. An ontology
also defines rich relationshipsbetween concepts. It al-
lows members of a community of interest to establish
a shared formal vocabulary. In short, ontologies are
defined as a formal specification of a shared concep-
tualisation (Gruber, 1993) where formal implies that
the ontology should be machine-readable and shared
that it is accepted by a human group or community.
Further, it is restricted to the concepts and relations
that are relevant for a particular task or application.
Typically, ontologies are composed of a hierarchy
of concepts the meaning of which is expressed thanks
to their relationships and to axioms or rules that may
constrain the relations or that define new concepts as
formulas. Concepts may be labelled with terms that
are their linguistic realisations or linguistic clues of
their meaning.
Originally, ontologies were defined as rigid struc-
tures that are supposed to be stable over time. Nev-
ertheless, ontologies may need to evolve because do-
main knowledge changes, users’ needs may be differ-
ent or because the ontology could be used in a new
context or even reused in a new application (Haase
and Sure, 2004). Ontology maintenance may re-
sult difficult especially if their structural semantics is
complex, defining hundreds of concepts and relations.
Ontology engineering is a costly and complex task
(Maedche, 2002). In the last ten years, ontology engi-
neering from text has emerged as a promising way to
save time and to gain efficiency for building or evolv-
ing ontologies (Buitelaar et al., 2005). However, texts
do not cover all the required information to build a
relevant domain model, and human interpretation and
validation are required at several stages in this pro-
cess. So ontology engineering remains a particularly
complex task when it comes to the extraction or ob-
servation of both terminological and ontological rep-
resentations from a specific document corpus.
56
Sellami Z., Gleizes M., Aussenac-Gilles N. and Rougemaille S. (2009).
DYNAMIC ONTOLOGY CO-CONSTRUCTION BASED ON ADAPTIVE MULTI-AGENT TECHNOLOGY.
In Proceedings of the International Conference on Knowledge Engineering and Ontology Development, pages 56-63
DOI: 10.5220/0002302700560063
Copyright
c
SciTePress

Our motivation is to propose a tool facilitating on-
tology maintenance and evolution by the ontologist.
The principle is to provide a system that automati-
cally proposes solutions to be discussed and evalu-
ated. This system learns from the user’s feedback.
It can be seen as a virtual ontologist that helps the
“real one” to carry out ontology learning and evolu-
tion from text. We call this process a co-construction
or co-evolution.
In this article, we propose DYNAMO, a Multi-
Agent System that supports ontology co-construction
and evolution. After an overview of the DYNAMO
context (section 2), we detail the principles of this
MAS (section 3). In Section 5 we exhibit preliminary
results obtained when building an ontology with DY-
NAMO. These results are discussed in the next sec-
tion. Section 7 presents the improvements we plan to
bring to our work as well as our perspectives.
2 DYNAMIC ONTOLOGY
CO-CONSTRUCTION
2.1 Context
The study of ontology evolution is part of the DY-
NAMO
1
(DYNAMic Ontology for information re-
trieval) ANR
2
(Agence Nationale de la Recherche)
funded research project. DYNAMO addresses the im-
provementof semantic information retrieval drivenby
user satisfaction in a dynamic context. One of the
project originality is to take into account the potential
dynamics of the searched document collection, of the
domain knowledge as well as the evolution of users’
needs.
The DYNAMO project aims at proposing a
methodological approach and a set of tools that allow
the definition and the maintenance of ontological re-
sources from a set of unstructured documents. These
resources are used to facilitate information retrieval
within the corpus by means of a semantic indexing.
Several project partners propose domain specific
document collections. ACTIA
3
provides documents
covering the area of automobile diagnosis (automo-
bile components, symptom, engine failure, etc.) and
written in French, while ARTAL
4
corpus consists in
software bug reports written in English, and the part-
ners in charge of the ARKEOTEK
5
project are con-
1
http://www.irit.fr/DYNAMO/
2
http://www.agence-nationale-recherche.fr/
3
http://www.ACTIA.com
4
http://www.ARTAL.fr
5
http://www.ARKEOTEK.org
cerned by archaeological scientific research papers
structured as a set of rules. Thus, one point of im-
portance in DYNAMO tools, is the handling of a vari-
ety of heterogeneous document collections among the
projects (as for language support both in French and
English) for the co-evolution of ontological resources.
2.2 The Ontology Model
In DYNAMO, the ontology and its lexical component
form what we call a Terminological and Ontological
Resource (TOR). Such a resource is represented using
the OWL
6
-based TOR model proposed in (Reymonet
et al., 2007). This model recently evolved to become a
meta-model, where concepts and terms are two meta-
classes adapted from owl:class. In this TOR, model
ontological elements (concepts) are related to their
linguistic manifestations in documents (terms): a term
“denotate” at least one concept. This models form
the core of the DYNAMO project as longs as term in-
stances (which represent term occurrences), concept
instances and relations between instances are used to
represent document annotations.
The problem addressed in this paper is how a
multi-agent system can be used to build and update
a TOR represented with this meta-model and using
documents as information sources.
2.3 The Adaptive Multi-Agent System
(AMAS) Theory
Because of their local computation and openness,
MAS are known to be particularly well fitted to dy-
namic and complex problems. The design of an on-
tology from the analysis of a corpus is an obviously
complex task (as we discussed in the introduction).
The AMAS Theory (Capera et al., 2003) empha-
sises on the cooperation between agents to achieve
global adequacy by the way of self-organisation.
Each agent in the system tries to maintain a coop-
erative state, more precisely, it tries to avoid and re-
pair harmful situations (Non Cooperative Situations).
According to the AMAS principles, the agent co-
operative behaviour ensures that, during times, the
function realised by the system is always adapted to
the problem (functional adequacy). The main idea
of the work presented here is to take advantage of
the AMAS properties to propose an ontology co-
construction system that uses as information sources
the documents as well as the ontologist interactions.
As a result, the DYNAMO MAS proposes some
modifications to the ontologist because it evaluates
6
Web Ontology Language
http://www.w3.org/2004/OWL/
DYNAMIC ONTOLOGY CO-CONSTRUCTION BASED ON ADAPTIVE MULTI-AGENT TECHNOLOGY
57

that these modifications improve the ontology. The
system also benefits from the ontologist answers to
its proposals (basically acceptance or rejection), it al-
lows to strengthen or weaken the confidence in the
position of the involved agents.
3 PRINCIPLES
DYNAMO is a tool, based on an Adaptive Multi-
Agent System (AMAS) presented in Section 2.3, en-
abling the co-construction and the maintenance of an
ontology starting from a textual corpus and resulting
an OWL file. DYNAMO is a semi-automatic tool be-
cause the ontologist has to validate, refine or mod-
ify the organisation of concepts, terms and relations
between concepts until it reaches a satisfying state.
Figure 1 gives an overview of the DYNAMO system
components : DYNAMO Corpus Analyzer and DY-
NAMO MAS.
The DYNAMO Corpus Analyzer prepares the input of
the DYNAMO MAS. It contains the Corpus, the Pat-
tern Base, the Candidate Term Base and a set of NLP
tools. Those tools process the lexical relations extrac-
tion mechanism whose result is used to determine po-
tential semantic relations between candidate terms.
The DYNAMO MAS is composed of two agent
types: TermAgent and ConceptAgent which are de-
tailed further in Section 3.3. Thanks to the extracted
relations these agents try to self-organise in order to
find their proper location in the TOR hierarchy.
3.1 Syntactic Patterns
Many approaches for ontology learning from text are
based on Natural Language Processing (NLP) tech-
niques. We can quote two main groups: on the one
hand, statistical approaches (Harris, 1968), like clus-
tering, are interested in finding a semantic interpre-
tation to several kinds of term co-occurrences in cor-
pora; on the other hand, approaches based on linguis-
tics rely on a more or less fine-grained linguistic de-
scription of the language used in text to derive an in-
terpretation at the semantic level. Recent ontology
learning processes combine both approaches (Cimi-
ano, 2006).
For instance, lexico-syntactic patterns can be used ei-
ther for concept or semantic relation extraction, but
what they actually identify in text are terms or lexi-
cal relations (Hearst, 1992). The extraction process
then includes pattern adaptation to the corpus to be
parsed, lexical relations extraction on each document,
phrase interpretation and finally term and relation ex-
traction (Barri`ere and Akakpo, 2006). An extra step
would be to define concepts and semantic relations
from those items. Systems like Text-to-Onto (Cimi-
ano and V¨olker, 2005) or OntoLearn (Velardi et al.,
2005) propose a fully automatic run from pattern-
matching to ontology learning, while systems like
Prom´eth´ee (Morin, 1999) and Cam´el´eon (Chagnoux
et al., 2008) support a supervised process when the
ontologist may validate or modify the concepts and
relations proposed by the analysis tool.
In keeping with results established by V. Malais´e
(Malaise, 2005) we have experimentallyobservedthat
a statistical processing is not very effective on small
corpora with little redundancy, which is the case for
the three DYNAMO specific applications. Not only
the corpora have a relatively modest size (ACTIA cor-
pus: 46000 words, ARTAL’s corpus: 13000 words,
ARKEOTEK corpus: 106000 words), but each doc-
ument is of very short length and deals with a spe-
cific subject. For all these reasons, we adopted a
pattern-based approach to obtain relevant information
on terms and their relationships, and then to define
concepts and semantic relations from these evidences.
3.2 Semantic Relations
In DYNAMO, we are interested in four types of lexi-
cal relations:
1. Hyperonymy expresses a generic-specific relation
between terms. This may lead to define a class-
subclass (is a) relation between the concepts de-
noted by these terms.
2. Meronymy means a parthood relation between
terms, which may lead to define a part of seman-
tic relation between concepts, or an ingredient of
relation or domain-specific adaptations of part-
hood like has members in biology for instance.
3. Synonymy relates semantically close terms that
should denote the same concept.
4. Functional relations: which are any other kind
of lexical relations that will lead to a specific
set of semantic relations, either general ones like
causes, leads to, ... or task specific relations like
has fault, is an evidence for or domain specific re-
lations like has skills in archaeology.
In our system, linguistics manifestation of seman-
tic relations are used by agents as clues for self-
organisation. We call them triggers.
3.3 Agents Behaviour
The Multi-Agent System is constituted of two differ-
ent types of agent: one representing the terminolog-
ical part of the TOR (TermAgent) and the other, the
KEOD 2009 - International Conference on Knowledge Engineering and Ontology Development
58
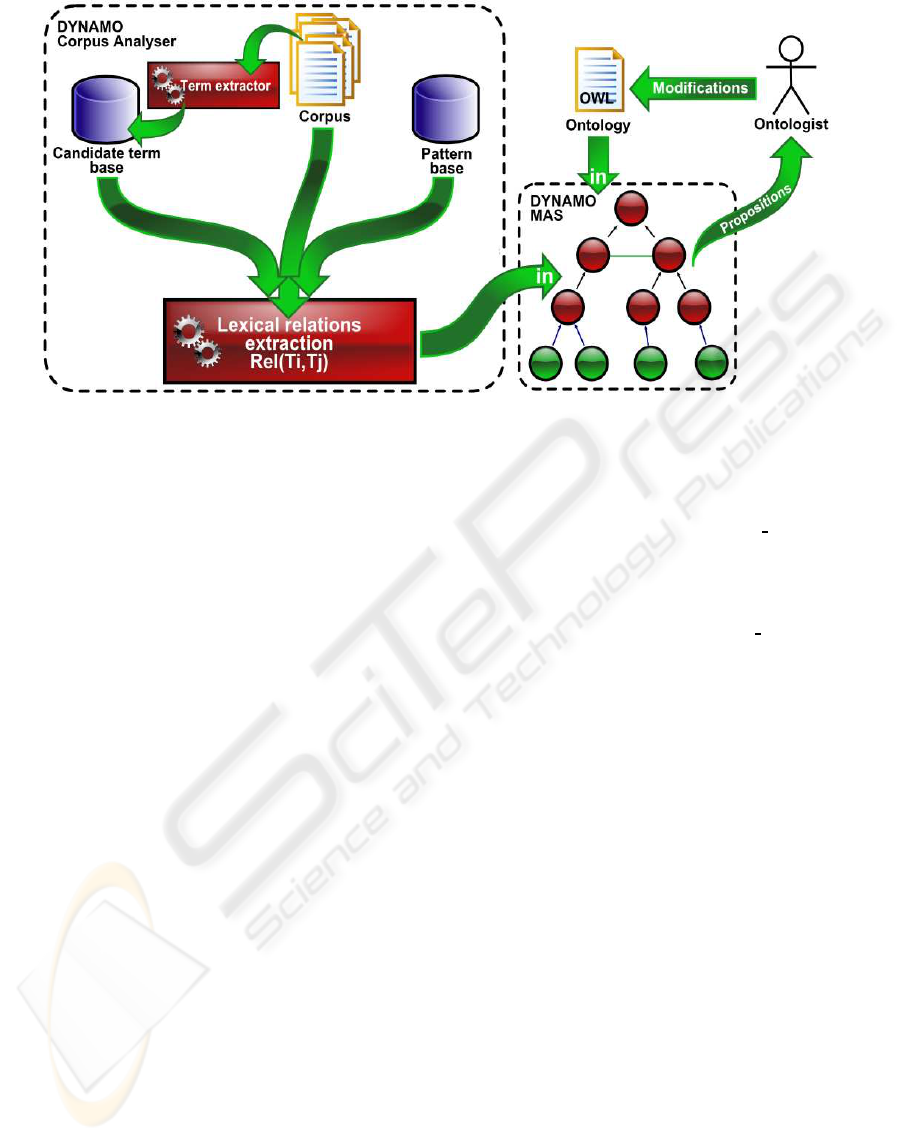
Figure 1: Relations between the DYNAMO Corpus Analyzer, the DYNAMO MAS and the ontologist.
conceptual part (ConceptAgent). Considering an on-
tology as the MAS organisation, the aim of our system
is to reach a stable organisation of terms and concepts
according to the semantic relations extracted from the
considered corpus. This is mainly achieved through
a cooperative self-organisation process between the
agents encapsulating all these elements.
3.3.1 TermAgent Behaviour
TermAgents represent terms that have been extracted
from the corpus. Each extracted term is related to one
or many other terms by either syntactic relations or
lexical relations, which are linguistic manifestations
of semantic relations. These relations have been de-
tected thanks to the lexical relations extraction mech-
anism (essentially using specific triggers).
The system is initialised by creating one TermA-
gent from each extracted term. The agent behaviour
consists then in processing all the extracted relations
that connect it with other terms. Each relation has a
confidence degree which is computed from the fre-
quency of occurrences of the corresponding pattern.
Using this confidence degree TermAgents are related
with each other (see 3.2).
Initially the MAS is only composed of TermA-
gents which are linked by these valued relations. Each
TermAgent takes into account the most important re-
lation (which has the greatest confidence value) ac-
cording to its type:
1. Synonymy relation between two TermAgents
leads to the creation of a ConceptAgent linked to
the corresponding TermAgents.
2. Hyperonymy relation between two TermAgents
causes the creation of two ConceptAgents linked
to the corresponding TermAgents. The two new
ConceptAgents are related by an is a relation.
3. Meronymy relation between two TermAgents im-
plies the creation of two ConceptAgents linked to
the corresponding TermAgents. The new Concep-
tAgents are associated with a part of relation.
4. Functional relation between two TermAgents
leads to the creation of two ConceptAgent linked
to their corresponding TermAgents. The two new
ConceptAgents are then related by this relation.
TermAgents send a request to create ConceptAgents
and link with it. Additionally, when a ConceptAgent
previously exists, it is not created a second time.
3.3.2 ConceptAgent Behaviour
This agent type represents concepts that have been
created by TermAgents. ConceptAgents behaviour
leads to the optimisation of the ontology by treating
a set of Non Cooperative Situations (NCS) derived
from specific data about the three relations type (hy-
peronymy, meronymy and functional) as well as their
link to terminological data (TermAgent denotation).
An example of these situations can be found in the
election of a concept label. Typically, each Concep-
tAgent has to choose among its related terms the one
that is the more representative to become its label. To
do so, a ConceptAgent selects the denotation relation
on which it is the most confident, and proposes to the
designated TermAgent to become its label. However,
conflicts may appear in this process. As a single Ter-
mAgent could denote several ConceptAgents it may
DYNAMIC ONTOLOGY CO-CONSTRUCTION BASED ON ADAPTIVE MULTI-AGENT TECHNOLOGY
59

receive several label requests. This situation is quoted
as an NCS (a conflict one), it is detected by a TermA-
gent and should be treated by a ConceptAgent. Sev-
eral solutions could be adopted at this stage:
• If there is only one common TermAgent (the la-
bel) linked to the concerned ConceptAgents, they
should be merged.
• If there are several other TermAgents linked to the
ConceptAgents, ConceptAgents have to chose an-
other label in their TermAgents pool. The TermA-
gent that detects the situation kept as a label by
one of the ConceptAgents depending on its simi-
larity to other designated TermAgents.
Between these two cases a mid-term solution have to
be found, by considering the number of TermAgents
linked to each ConceptAgents, the similarity between
these TermAgents, the relation held by the denoted
ConceptAgent, etc. This is achieved through coop-
eration and thanks to the ontologist actions. The co-
operation at the system level is the purpose of the fol-
lowing section.
3.3.3 Collective Behaviour
The DYNAMO MAS is a real time system that uses a
corpus that implies the creation of several hundreds of
TermAgents and ConceptAgents. We need to be sure
that the system converges and outputs at least a solu-
tion. This convergence is guaranteed by the AMAS
theory. In short, because agents are implemented in
such a way that they can be considered as coopera-
tive, their cooperation ensures that the whole set will
stabilize after a large set of iterations for information
exchange. In fact, the collective process stops when
each agent reaches a local equilibrium. This equilib-
rium occurs when its remaining NCS levels are lower
than the NCS levels of its neighbourhood (agents that
are related to it). For example, let us consider a given
TermAgent looking at its relations with other TermA-
gents which are not currently in the TOR:
• If a neighbour agrees to take their relationship into
account, the MAS changes the ontology by adding
the new relationship. This modification is pro-
posed later to the ontologist for agreement. If the
ontologist disagrees the MAS stores this informa-
tion to avoid the same request one more time.
• If related neighbours disagrees, about this modifi-
cation because of contradictions with other more
critical situations in its own neighbourhood, no
change occurs.
Furthermore, we considered a minimum confidence
threshold in the algorithm, in order to dismiss a
large number of non-significantsemantic relations ex-
tracted from the corpus. The confidence degree of
any relation could evolve when new documents are
analysed. By this means, relations that were set apart
could be later taken into account providing that their
confidence degree reaches the threshold. This sim-
ple rule also avoids processing relations considered
as analysis noise.
The collective solving process of agents is also
very efficient for algorithmic reasons:
• the AMAS algorithm assumes a monotonic de-
creasing of NCS level: typically three or four
agent activations are sufficient to obtain a local
equilibrium;
• when new information arrives in the MAS (com-
ing from new corpus analysis or the ontologist)
only the considered agents work. Thus the pertur-
bation process is very limited inside the MAS.
4 EXPERIMENTS
We experimented our system using the ARTAL cor-
pus defined in the DYNAMO project. The objective
of the experiment is to evaluate the ontology built up
with Agents, and, from this analyse, to improve the
TermAgent and ConceptAgent behaviour.
The pattern base was fed with some of the trig-
gers defined in the TerminoWeb project (Barri`ere and
Akakpo, 2006). These triggers are used to extract re-
lations between terms from a corpus (see 3.1). The
following list presents some of the chosen triggers:
• for hyperonymy relations: such as, and other, in-
cluding, especially;
• for meronymy relations: is a part of, elements of,
components of;
• for synonymy relations: another term for, also
called, also known as, synonym.
The precise numbers of triggers used for each relation
type are presented in Table 1. We also used specific
triggers for functional relations such as: when, if, at,
on, before, after.
Table 1: Number of triggers for relation extraction.
Semantic Relation Number of Triggers
SYNONYMY 12
HYPERONYMY 21
MERONYMY 23
FUNCTIONAL 16
Due to the small number of triggers, we estimate
potential semantic relations between terms by the fol-
KEOD 2009 - International Conference on Knowledge Engineering and Ontology Development
60
lowing rule: if it is possible to find two terms sharing
the same contexts in the corpus (i.e. often situated
among same words), then these terms could be con-
sidered as potential semantically related. The confi-
dence of this relation is calculated using the Jacquard
Formula based on the shared context cardinality. For
example, the DYNAMO Corpus Analyser considered
“Web”, “Applet” and “Service” as potential hyper-
onymy of the concept “Application” because they
share same context.
Finally, we filled the Candidate terms base with
the terminological part of the ARTAL TOR which
contains 692 terms.
5 RESULTS AND ANALYSIS
For the experiment, we have used a strict matching
of terms on the corpus, we haven’t looked for any of
their orthographic variations. This option explains the
relatively small number of matched relations and fa-
cilitates the readability of MAS results. Using DY-
NAMO Corpus Analyser, we have extracted 476 rela-
tions between 503 terms. Table 2 gives the number of
relations detected using triggers.
Table 2: Number of matched relations in the ARTAL cor-
pus.
Semantic Relation Number of matched relations
SYNONYMY 2
HYPERONYMY 68
MERONYMY 36
FUNCTIONAL 370
The small amount of synonymy, hyperonymy
and meronymy relations is due to the use of generic
triggers that are obviously not fit to the corpus. On the
opposite, we use specific triggers to extract functional
relations and this is why we get the best result. This
point highlights the main feature of pattern based
approaches which is the strong dependencies of the
results on the definition of pattern.
Thanks to the Jaccard formula we have extracted
650 potential semantic relations between terms. The
MAS input is formed by 657 candidate terms and
1124 instance of relations.
Firstly, all terms are agentified and every agent
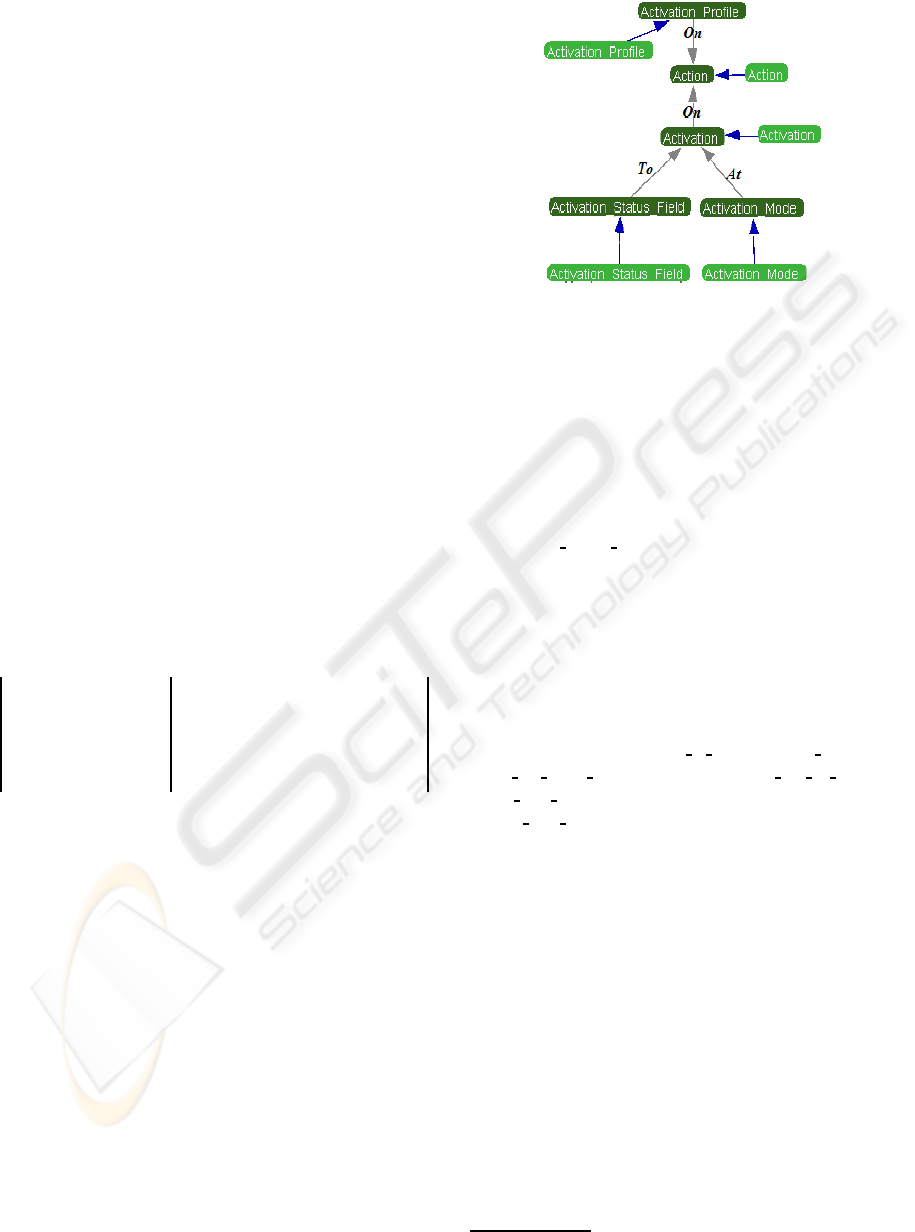
tries to be related with a ConceptAgent. In Figure
2, links without label represent denotation relations
between TermAgents and ConceptAgents. In the on-
tology model, each term can denote several concepts.
Each labelled link represents the functional relation
Figure 2: Functional relations established between Concep-
tAgents.
discovered between terms. For example, Action and
Activation concepts are related by a link labelled On.
In the considered domain (software bug reports)
the presented subgraph means that an Action trig-
gers two kinds of activation. The Activation pos-
sessed several modes which can be selected and
modifies the status of the associated component
(Activation status field). This representation is close
to the one proposed by the ontologist, but expresses
also some new functional relations.
Figure 3 presents a result obtained with Ter-
mAgent reasoning only with Jaccard Formula.
Five TermAgents are related to the “Application”
ConceptAgent who is related to the top concept.
This first graph represents a potential hyperonymy
relation between Agents. In the second graph five
TermAgents (Impossible to send, Not activated,
Have the same name, can not be change,
Https port number) are related to the
“Https port number” ConceptAgent. The rela-
tion established between this ConceptAgent and the
first four TermAgent represents a potential functionnal
relation (affects). In the considered domain (software
bug reports), the relation means that http port can
have several bugs like a non-activation problem.
To improve our results, we need to define more
precise patterns by using regular expressions rather
than triggers which only detect possible relations be-
tween words situated on their both sides. We are also
investigating on the use of external information re-
sources (dictionary, generic ontology such as Word-
Net
7
, other domain related corpus, etc.) to deal with
the limitation of corpus based approaches.
To improve the agents behaviour, we can also
combine the Pattern-based approach with a statistical
approach by using the Jaccard Formula. For example,
a TermAgent can improve its own trust in a relation
7
http://wordnet.princeton.edu/
DYNAMIC ONTOLOGY CO-CONSTRUCTION BASED ON ADAPTIVE MULTI-AGENT TECHNOLOGY
61

Figure 3: Example of semantic relation between TermAgents and ConceptAgents identified with jaccard Formula.
when the same relation is also detected using Jaccard
Formula.
As it has been expressed in Section 3.3, we do
not have completely specified the ConceptAgent be-
haviour, this prototyping phase is part of the ADELFE
methodology (Bernon et al., 2005). The aim of this
specific task is to obtain the first draft of the sys-
tem that allows to highlight more efficiently the NCS.
Thanks to these first experiments, we have been able
to quote some NCS as, for instance, the label conflict
described in Section 3.3.2.
6 RELATED WORKS
6.1 The Earlier DYNAMO Prototype
The objective of DYNAMO is to facilitate ontology
engineering from text thanks to a combination of Nat-
ural Language Processing and a cooperative Multi-
Agent System. Our research is inspired from DY-
NAMO first prototype (Ottens et al., 2008) that used
a statistical approach to build up a taxonomy from
large text corpora. In this prototype, agents imple-
ment a distributed clustering algorithm that identify
term clusters. These clusters lead to the definition of
concepts as well as their organisation into a hierar-
chy. Each agent represents a candidate term extracted
from the corpus and estimates its similarity with oth-
ers thanks to statistical features. Several evaluation
tests conducted with this DYNAMO first prototype
proved its ability to build the kernel of a domain on-
tology from a textual corpus.
6.2 Ontology Engineering from Text in
Dynamic Environments
Two on-going major IST European projects, SEKT
8
and NEON
9
aim at similar goals with a more am-
8
http://www.sekt-project.com/
9
http://www.neon-project.org/web-content/
bitious scope. Both of them are building up tool-
kits that should give access to a panel of technolo-
gies, including several Human Language Technolo-
gies among which NLP plays a major role. SEKT
and NEON want to advance the state of the art in us-
ing ontologies for large-scale semantic applications in
distributed organisations and dynamic environments.
Particularly, they aim at improving the capability to
handle multiple networked ontologies that exist in a
particular context, they are created collaboratively,
and might be highly dynamic and constantly evolv-
ing. Human Language and Ontology Technologies
are combined to produce semi-automatic tools for the
creation of ontologies, the population of those ontolo-
gies with metadata, and the maintenance and evolu-
tion of the ontologies and associated metadata. Al-
though agents technology is not used at all in these
projects, their scope is very similar to the one of DY-
NAMO.
The ambition of SEKT is to offer this variety of
technologies to develop not only ontologies and an-
notations, but full knowledge management or knowl-
edge intensive applications. Argumentation among
ontology authors who locally update an ontology is
considered as a key stage of the evolution process
of shared ontologies. The NEON project highlights
the role of NLP when updating ontologies in dy-
namic environments together with their related se-
mantic metadata. NEON toolkit offers a tool suite
that extends OntoStudio baseline and connects it with
GATE. GATE used to propose Prot´eg´e as a plug-in
for ontology development from text analysis. The
new GATE version includes a module that manages
its own ontology representation, a plug-in for ontol-
ogy population and text annotation.
7 CONCLUSIONS
DYNAMO is a Multi-Agent System allowing the co-
construction and evolution of ontologies from text.
DYNAMO MAS uses result from lexical relations
extraction mechanism to construct ontologies. We
KEOD 2009 - International Conference on Knowledge Engineering and Ontology Development
62

shown in Section 5 that the system is able to create an
ontology draft containing both ontological and termi-
nological elements and enriches several dimensions
of the previous prototype (see Section 6):
1. It is able to deal with richer linguistic information
as long as agents take into account lexical rela-
tions found by matching patterns on texts.
2. The result is much richer: DYNAMO builds up a
TOR which includes a hierarchy of concepts with
their related terms, and labelled semantic relations
between concepts. A set of terms denotes each
particular concept, which is useful for the docu-
ment annotation activity.
3. The current DYNAMO system is able to deal
either with French or English language text,
whereas the first prototype was previously limited
to French language.
According to the project schedule we need to improve
the software during the next year. To do so we plan
to:
• introduce the cooperative behaviour of ConceptA-
gents (specification of NCS and their treatment);
• provide an adaptive patterns learning process
based on the AMAS theory;
• provide specific interfaces to enable ontologists
collaboration;
• apply the DYNAMO MAS to all the project do-
mains (archeology, car diagnosis, software bug re-
ports).
REFERENCES
Barri`ere, C. and Akakpo, A. (2006). Terminoweb: A soft-
ware environment for term study in rich contexts. In
Proceedings of International Conference on Terminol-
ogy, Standardization and Technology Transfer, pages
103–113, Beijing. Encyclopedia of China Publishing
House.
Bernon, C., Camps, V., Gleizes, M.-P., and Picard, G.
(2005). Engineering Adaptive Multi-Agent Systems:
The ADELFE Methodology . In Henderson-Sellers,
B. and Giorgini, P., editors, Agent-Oriented Method-
ologies, volume ISBN1-59140-581-5, pages 172–202.
Idea Group Pub, NY, USA.
Buitelaar, P., Cimiano, P., and Magnini, B. (2005). On-
tology Learning From Text: Methods, Evaluation and
Applications. IOS Press.
Capera, D., Georg´e, J.-P., Gleizes, M.-P., and Glize, P.
(2003). The AMAS Theory for Complex Problem
Solving Based on Self-organizing Cooperative Agents
. In TAPOCS 2003 at WETICE 2003, Linz, Austria,
09/06/03-11/06/03. IEEE CS.
Chagnoux, M., Hernandez, N., and Aussenac-Gilles, N.
(2008). An interactive pattern based approach for ex-
tracting non-taxonomic relations from texts. In Buite-
laar, P., Cimiano, P., Paliouras, G., and Spilliopoulou,
M., editors, Workshop on Ontology Learning and
Population (associated to ECAI 2008) (OLP), Patras
(Greece), 22/07/08, pages 1–6.
Cimiano, P. (2006). Ontology Learning and Population
from Text: Algorithms, Evaluation and Applications.
Springer.
Cimiano, P. and V¨olker, J. (2005). Text2onto - a framework
for ontology learning and data-driven change discov-
ery. In Montoyo, A., Munoz, R., and Metais, E., ed-
itors, Proceedings of the 10th International Confer-
ence on Applications of Natural Language to Informa-
tion Systems (NLDB), volume 3513 of Lecture Notes
in Computer Science, pages 227–238, Alicante, Spain.
Springer.
Gruber, T. R. (1993). A Translation Approach to Portable
Ontology Specifications. Knowledge Acquisition,
5(2):199–221.
Haase, P. and Sure, Y. (2004). D3.1.1.b state-of-the-art on
ontology evolution. Technical report, Institute AIFB,
University of Karlsruhe.
Harris, Z. S. (1968). Mathematical Structures of Language.
Wiley, New York.
Hearst, M. A. (1992). Automatic acquisition of hyponyms
from large text corpora. In COLING, pages 539–545.
Maedche, A. (2002). Ontology learning for the Semantic
Web, volume 665. Kluwer Academic Publisher.
Malaise, V. (2005). M´ethodologie linguistique et
terminologique pour la structuration d’ontologies
diff´erentielles `a partir de corpus textuels. PhD thesis,
Paris 7 Denis Diderot University.
Morin, E. (1999). Using lexico-syntactic patterns to extract
semantic relations between terms from technical cor-
pus. In 5th International Congress on Terminology
and Knowledge Engineering (TKE), pages 268–278,
Innsbruck, Austria. TermNet.
Ottens, K., Hernandez, N., Gleizes, M.-P., and Aussenac-
Gilles, N. (2008). A Multi-Agent System for Dynamic
Ontologies. Journal of Logic and Computation, Spe-
cial Issue on Ontology Dynamics, 19:1–28.
Reymonet, A., Thomas, J., and Aussenac-Gilles, N. (2007).
Modelling ontological and terminological resources in
OWL DL. In Buitelaar, P., Choi, K.-S., Gangemi,
A., and Huang, C.-R., editors, OntoLex07 - From Text
to Knowledge: The Lexicon/Ontology Interface Work-
shop at ISWC07 6th International Semantic Web Con-
ference, Busan (South Korea), 11/11/07.
Velardi, P., Navigli, R., Cucchiarelli, A., and Neri, F.
(2005). Evaluation of OntoLearn, a Methodology for
Automatic Learning of Domain Ontologies. In Buite-
laar, P., O. Cimiano & B. Magnini (eds.). IOS Press,
Amsterdam.
DYNAMIC ONTOLOGY CO-CONSTRUCTION BASED ON ADAPTIVE MULTI-AGENT TECHNOLOGY
63
