
ONTOLOGY BASED KNOWLEDGE MODELING
FOR THE TWO-STEP PERSONALIZED SERVICES IN NEXT
GENERATION NETWORKS
Aekyung Moon, Yoo-mi Park and Young-il Choi
Convergent Service Platform Research Department, ETRI, Korea
Keywords: Recommendation, Personalization, Network Knowledge.
Abstract: We propose ontology based knowledge modeling (OKM) that can support to provide the two-step
personalized services for the end users using network knowledge. The two-step personalization services are
consisted of service recommendation step and contents recommendation step. To achieve this, in this paper,
we classify network knowledge and build ontology to represent them including user profiles and user’s
preferences. Furthermore, we propose the efficient functions of learner and recommender. Learner makes
the user service usage model which consists of {context, services} pairs. Recommender is consisted of
service recommender and contents recommender for supporting two-step personalization.
1 INTRODUCTION
The significance of the personalization services
increases by the user requirement of differentiated
services. What is more, various attempts for
providing the personalized services considering a
situation and preference of a user are leading a new
paradigm of the next generation networks (WWRF,
2005), (Mihovska et al., 2007).
Taking this into consideration, we propose
ontology based knowledge modeling (OKM) to
recommend personalized services by two-step. First,
for handling network knowledge efficiently in OKM,
we classify user information on the networks to
three categories: context, profile, and preference. We
build ontology to represent network knowledge
including user profiles and user’s preference.
Especially we define preference ontology to
recommend two-step personalized services.
The two-step personalized services are consisted
of service recommendation step and contents
recommendation step. To achieve this, user’s
preference ontology of OKM is consisted of service
preference model and contents preference model.
The former is to recommend a weighted list of
useful service categories. The latter is to set up a
weighted list of specific contents according to the
service selected by a user. As a result, if user
selected TV service among service categories to be
recommended at the first step, it should match a
user’s desired TV programs and recommend TV
programs with high user preference at the second
step.
The remainder of this paper is organized as
follows. Section 2 presents related works. In Section
3, we describe network knowledge and build
ontology model. Section 4 proposes the system
architecture and operations to provide two-step
personalized services. Section 5 concludes this paper
with further issues.
2 RELATED WORK
Recently, the requirement on personalized services
using user behavior patterns and contexts has been
increased (MobiLife, 2004). Personalized services
have a role to identify the usefulness of service
categories in a given situation, and then proactively
discover and recommend services to the end-user
(MobiLife, 2004). Generally, the recommendation
approaches for service personalization are classified
into the following categories, based on how
recommendations are made (Adomavicus et al., 2005):
- Content-based recommendations: The user will
be recommended items similar to the ones the
user preferred in the past;
- Collaborative recommendations: The user will
be recommended items that people with similar
tastes and preferences liked in the past;
- Hybrid approaches: These methods combine
332
Moon A., Park Y. and Choi Y. (2009).
ONTOLOGY BASED KNOWLEDGE MODELING FOR THE TWO-STEP PERSONALIZED SERVICES IN NEXT GENERATION NETWORKS.
In Proceedings of the 4th International Conference on Software and Data Technologies, pages 332-337
DOI: 10.5220/0002280903320337
Copyright
c
SciTePress
collaborative and content-based methods
The studies of the vision of the personalized services
and the development of prototypes to verify
feasibility of the technologies have been performed
in some of European projects.
WWRF proposed the vision of the future
telecommunications services labeled as the I-Centric
Service (WWRF, 2005). According to the concept of
this service, the individual user, “I,” has to be put in
the center of service provisioning. WWRF offered
the reference network model and described the
requirements for providing this service. However,
they didn’t consider the modeling of the knowledge
that can be used for future service platform
architecture.
MobiLife proposed service architecture of I-
Centric Communications and made the outstanding
results which were next-generation mobile
communications service scenarios and requirements
(Mrohs et al., 2006). In the MobiLife, the activities
on service recommendation for user “I” include the
setup and maintenance of the decision policies for
the service recommendation. Especially, the learning
mechanism mainly extracts behavior patterns in the
same situation of the user or similar users.
3 KNOWLEDGE MODELING
To understand the proposed two-step personalized
services recommendation, we first illustrate a
scenario that is likely to occur in NGN. Figure 1
shows the flow of two-step recommendation.
Se r vi ce Usag e
History
Lear ner
User Behavior
Model
Co nt ext
Ser vice
Reco m mend e r
Reco m mend
Ser vice Li st s
Contents
Reco m m en d er
Reco m mend
Contents List s
1
2
3
4
5
6
7
Figure 1: The flow of two-step recommendation.
Example 1. Suppose that a user usually watches TV
when he enters living room and sits on the sofa after
work. The Learner can make a user behavior model
with behavior pattern extracted from the usage
history (①-②). When the usage pattern became
mature and service recommender catch his current
situation that he enters home after work ( ③ ),
Service recommender computes the preferred
service lists using user behavior model (④). When
received service lists, the user can select the TV
service among service lists (⑤-⑥). And then, the
contents recommender recommends the user’s
interest TV program lists (⑦). At this time, the
feedback is stored in the service usage history.
To complete this scenario, we classify user
information on the networks to three categories:
context, profile, and preference. We build ontology
to represent network knowledge including user
profiles and user’s preference.
3.1 Network Knowledge
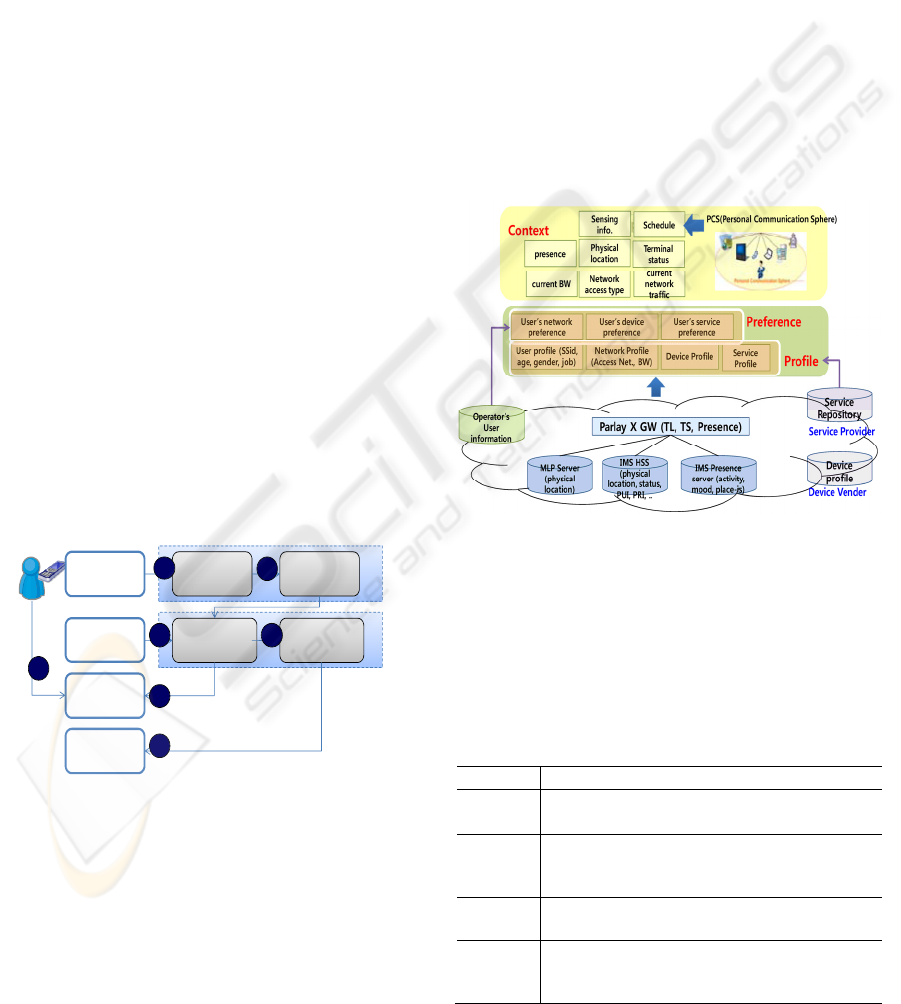
Fig. 2 shows how to get the network information
from the underlying network or environment and the
classification of network knowledge. All network
information is classified into three concepts: profile,
preference, and context.
Figure 2: Classification of network knowledge.
Profiles are a collection of structured data that
describe the static properties of an object. Table 1
shows the types of profile and example considered
in network knowledge. Preferences are user’s
conditional choices of service characteristics of an
object depending on context and ambient information.
Table 1: Definition of Profile in Network Knowledge.
Type Definition
User
Profile
User-related information. social security id,
name, age, gender, job, etc
Device
profile
Device-related information generated by
manufacturer. device model, type,
capabilities (input/output modality), etc
Network
profile
Network capabilities information. operator,
coverage, bandwidth, access technologies, etc
Service
profile
Service-related information. service category,
service fees, service provider, location where
the service is available, etc
ONTOLOGY BASED KNOWLEDGE MODELING FOR THE TWO-STEP PERSONALIZED SERVICES IN NEXT
GENERATION NETWORKS
333
User preference consists of a set of policies
{condition, actions} in order to apply that it can be
dynamically changed according to the user’s
situation. User has three basic types of preference
shown in Fig 3. Specially, we focused on service
preference, which is a set of information related to
user’s preferred services, and service usage
preference acquired by learning mechanism.
Domain Specific Knowledge Model
Core Knowledge Model
Figure 3: Ontology modeling of network knowledge.
Based on the definition of context by Dey et al.
(Dey, 2001), context is any information that can be
used to characterize the situation of an entity. An
entity is a person, place, or object that is considered
relevant to the interaction between a user and an
application, including the user and applications
themselves. We consider that sensed information
from PCS (personal communication Sphere), current
network bandwidth and user’s current location, etc.
3.2 Ontology Modeling
3.2.1 Core Knowledge Modeling
In this section, we describe the results of ontology
modeling in OKM. Fig. 3 shows the ontology
modeling of network knowledge. As shown in Fig.
3, we made 10 classes (User, Preference, Group,
Network, Device, Service, Location, Activity,
Schedule, and Presence) and 13 major object
properties from the relationship between classes. In
addition to, there are knows for the relationship
among users, belongToPlace for the relationship
between location and 39 data-type properties for
predefined classes such as user_id and user_name
for User class. Actually, User, Device, Network and
Service class represents profiles as previous
mentioned in Table 1.
Our ontology model is consisted of core and
domain-specific parts of the network knowledge.
The core parts are comprised of the Device, Service,
User, Network and Location classes, which represent
contexts and profiles. The domain specific parts are
comprised of Preference, Group, Activity, Schedule,
and Presence, which are to provide personalized
services according to application domains. The
information of this part will be gathered from a
variety of data sources.
3.2.2 Domain Specific Knowledge Modeling
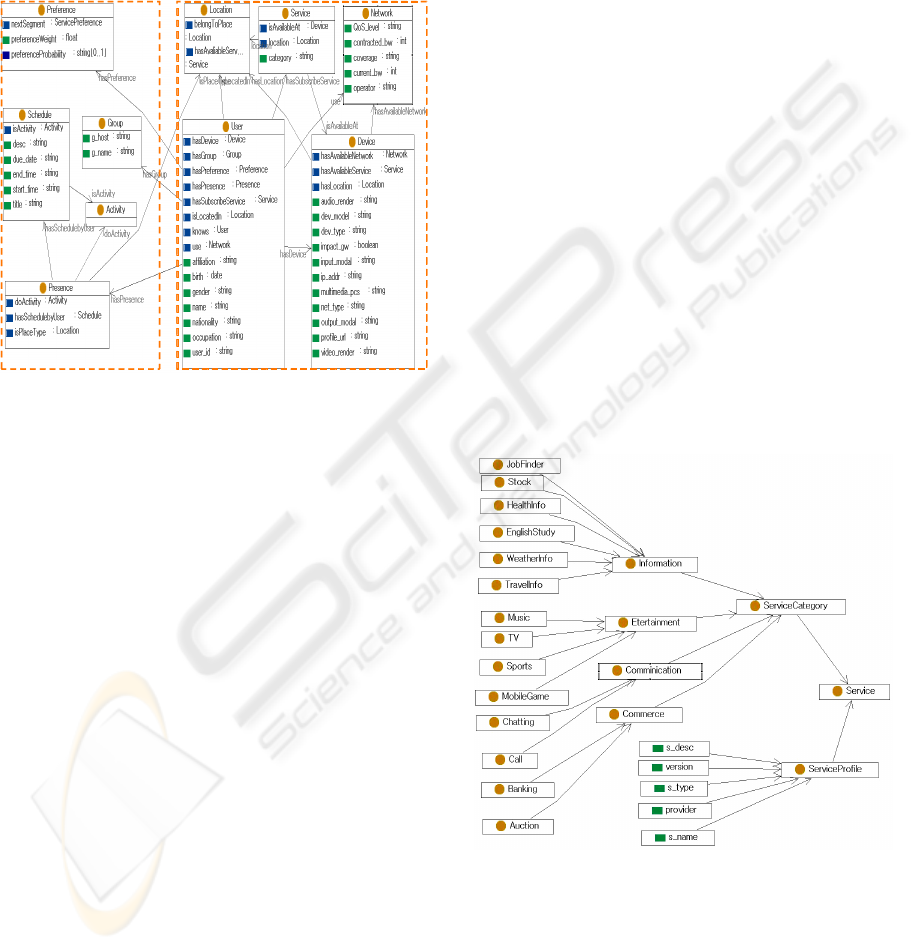
Service ontology is consisted of service profile and
service category. The service main categories at the
topmost level describe in general what services are
for. The subsequent sub-categories clearly specify
the functionality of services.
Fig. 4 shows the example of Service Ontology for
user’s Preference which represents four service
categories: commerce, information, entertainment,
communication. The subclass of each category is
shown in Fig. 4. For example, TV class is modeled
as subclass of Entertainment. TV class includes
user’s preferred TV genre related to IPTV domain.
The instance of TV class related to genre is made
reference to TV-anytime forum (S-3 On: Metadata,
2001).
Figure 4: Example of service domain ontology.
The user preference model is to store user’s
service preference. This model is represented by
ontology while referencing Service ontology shown
in Fig 4. Fig. 5 represents the example the
preference model of user “hong”, which uses n-ary
relation in OWL.
ICSOFT 2009 - 4th International Conference on Software and Data Technologies
334
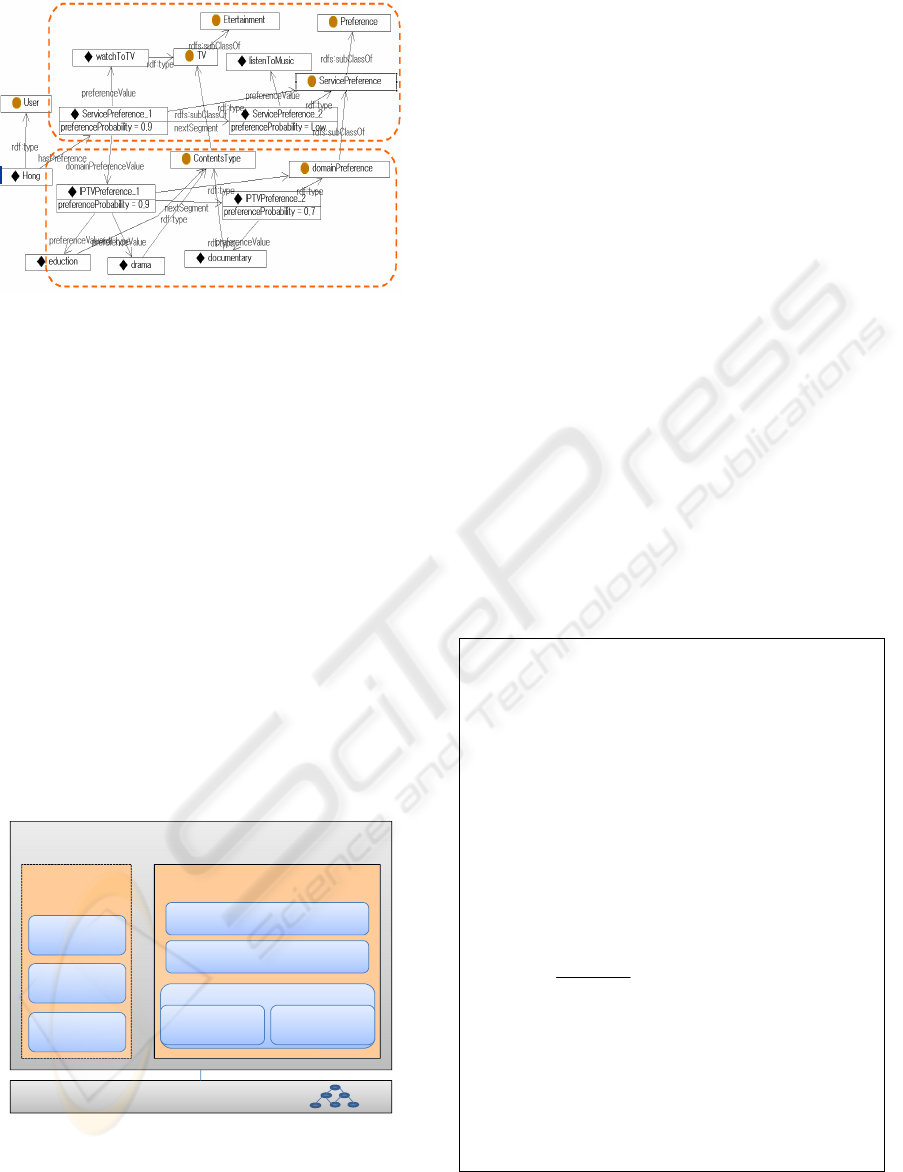
Service Category Preference Model
Contents Preference Model
Figure 5: Example of user preference ontology.
4 KNOWLEDGE MANAGEMENT
PLATFORM
This section describes the system architecture and
operations of two-step Personalized Services and
describes the results of simulation.
4.1 System Architecture
The system architecture is shown in Fig. 6. This
platform consists of profile manager and knowledge
manager. The profile manager is consisted of a user
profile, user preference model and user service
usage model. In the case of user profile is
represented by User class of ontology model shown
in Fig. 3. The user preference model is represented
by service preference and contents preference model
shown in Fig. 5.
Knowledge Management Platform
orm
Knowledge Manager
Sit uation Reasoner
Pr o file
Manager
User Pro file
User Service
Usage Model
User
Preference
Model
Recommender
Contents
Recommender
Ser vi ce
Recommender
Usage Pattern Learner
Network Knowledge Model
Figure 6: System Architecture of Knowledge Management
Platform.
User service usage model sets up and maintains
service usage behavior model using learning
mechanism. In particular, the context information
influences user behavior model because it contains a
pair of user behavior (service usage) and a user
situation consisted of contexts. The user service
usage model is updated by user pattern learner that
analyzes user behavior history. The proposed user
service usage which consists of {context, service}
pair can be acquired by the context and the service
usage of a user; it then can be used to recommend
personalized services according to user’s situation.
The detailed learner algorithm is shown in section 4.2.
Situation reasoner has the capability deducing new
information from available information using a
predefined schema and interprets the situation based
on the contextual information.
4.2 Learner
Learner makes the user service usage which consists
of {context, services} pairs, called by C-TBL. Since
that the state S is defined as three elements of [user
activity, place, time], three C-TBL are needed. If
user wakes up early morning, then he request
“NewsInfo”. The value of the C-TBL [morning]
[news] is calculated by a following algorithm. The
detailed algorithm of the learning phase is as follows.
In the Step 1, reward value R may be defined
according to user feedback.
Step 1 is initialization phase for new context c
k
.
Initialize new C-TBL for c
k
, set 0 to
C-TBL[a
k,j
][ ac
k
], for each a
k,,j
∈ Attributes(c
k
),
ac
k
∈Action Classes. Initialize value of R for R ∈
{r
s
, r
p
, r
n
}. R is reward value.
Step 2 repeats the following learning steps.
Step 2-1. Input current situation s
(t)
, s
(t)
is
consisted of {a
1,i
(t)
,...,a
n,j
(t)
}, where a
k,i
(t)
∈
Attributes(c
k
). If a
k,i
t)
is continuous value, min-
max normalization performs a linear
transformation on the original data. Suppose that
min
a
and max
a
are the minimum and the
maximum values of a
k,i
(t)
.
aaa
aa
aik
ik
t
ik
newnewnew
a
aa min_)min_max_(
minmax
min
,
'
,
)(
,
+−
−
==
Step 2-2. Input an current action ac(t) by user
selection. Determine R(t) according to user
behavior information. Update the C-TBL as
following rules:
for each c
i
in C-TBL[a
i,k
(t)
][ ac
(t)
] do
C-TBL[a
i,k
][ac
(t)
] ← C-TBL[a
i,k
(t)
][ac
(t)
]+γR
(t)
,
where γ is the discount factor and c
i
∈ States.
4.3 Recommender
We propose two types recommender for providing
ONTOLOGY BASED KNOWLEDGE MODELING FOR THE TWO-STEP PERSONALIZED SERVICES IN NEXT
GENERATION NETWORKS
335

two-step personalized services. Service
recommender is responsible for service
recommendation; hence, it is to set up a weighted
list of useful services according to user behavior
patterns in the current situation and user’s service
preference shown in Fig. 5. Equation (1) shows
user’s preference for service recommender. That is
to say, for user u, the preference value of service i is
computed by equation (1). Contents recommender is
responsible for contents recommendation according
to selected service domain. As previous mentioned
in Fig. 5, IPTV is included in this case.
Preference
u,
i
=
α
×Preference
(Up)
u,i
+
β
×Preference
(Us)
u,i
u : user, i : services
Preference
u,i
: The preference value of user u about item i
Preference
(Up)
u,i
: The preference of user preference model
Preference
(Us)
u,i
: The preference of user service usage
model
α : The weight of user preference model
β : The weight of user service usage model
(1)
4.3.1 Service Recommendation Function
The service recommender fuction is as following
equation (2). Equation (2) is applied to learner and
preference ontology modeling.
P
reference
u,
j
=
α
×preferenceProbalility(u, S
j
)
+
β
×(w
k
×C-TBL[a
k,i
][S
j
] )
u : user, S
j
: j
th
services item
Preference
u,j
: The preference value of user u about
service item S
j
preferenceProbalility(u, S
j
): The preference of user
preference model by ontology shown in Fig. 5.
C-TBL[a
k,i
][S
j
]: The preference of user service
usage model by learner
a
k,i
: the attribute value of C
k
w
k :
the weight of context C
k
α : The weight of user preference model
β : The weight of user service usage model
(2)
According to Equation (2), weighted list of preferred
services is to set up and notifies to user. Suppose
that “watch TV” service is recommended. If user
selected TV service among service categories to be
recommended at the first step, it should match a
user’s desired TV programs and recommend TV
programs with high user preference by contents
recommender according to information of shown in
Fig. 5.
4.3.2 Contents Recommendation Function
For contents recommendation of TV domain, we
choose content-based approaches in order that
sparsity and cold-start (Papagelis et al., 2005)
problems are solved. The sparsity problem has a
major negative impact on the effectiveness of a
collaborative filtering approach. Because of sparsity,
it is impossible that the similarity between two users
cannot be defined, rendering collaborative filtering
useless. Even when the evaluation of similarity is
possible, it may not be very reliable, because of
insufficient information processed. Cold-start refers
that it cannot be recommended unless it has been
rated by a substantial number of users.
This is preference model for TV application
domain. The content of TV programs can be
represented in these items: identification information
(ID/title), category information (genres/subgenres),
broadcast information (channel/the starting time and
ending time of the program), content ratings and
keywords. To compute user preference, the TV
model is divided into three types of information
about TV content: “genre”, “channel” and
“companion”.
Companion: with whom the TV was seen (alone,
with friends, with family). It is possible to be
included in common model.
To collect this information about the user’s
interests, the system can ask a user manually
indicate his/her interests by giving GUI. The
function of TV specific model consists of computing
the preference of genre, channel and person, and
multiplying the each result by weights as equation
(3). The previous mentioned Fig. 6 shows the
example of ontology model of TV genre preferences.
P
u,i
=W
g
×
P
genre
u,p
+ W
c
×
P
channel
u,p
+W
c
×P
companion
u,p
u : user, i : items p: TV broadcasting program
W
g
: weight of genre, W
c
: weight of channel,
W
c
: weight of companion
(3)
4.4 Performance of Functions
To evaluate function, we chose the following the
data set; Create Approval, Balance and balloon in
UCI depository. In the case of the create approval of
UCI data, this consists of 15 contexts which has 9
categorical attributes and 6 continuous attributes),
and two action classes as show in Table 2.
Table 2: Example of UCI data for simulation.
Data Instance Attr.(Categorical) ActionClass
Create Approva
l
665 15(9) 2
B
alloons 20 4(4) 2
B
alance 625 4(4) 3
And also, we chose machine learning algorithms
from the Weka tool-kit (http://www.cs.
waikato.ac.nz/ml/weka/): J48, ZeroR, NaiveBayes
(Louis and Shankar, 2004).The performance
evaluation metric in this experiment is the
ICSOFT 2009 - 4th International Conference on Software and Data Technologies
336

accuracy (precision). When R is being the number
recommended as a user and the RP
(Recommended Preference) is being the number
which a user actually prefers, precision is
calculated as the RP / R and showed by the %
.
The k-fold cross validation is used in order to
raise the confidence of experiments. However,
when computing by equation (2), the user
preference by the ontology and contents
preferences was not considered in order to
experiment in same condition with the
comparison algorithm. w
k
is calculated by the
entropy of context through the information gain
(Mitchell, 1997).
Fig. 7 shows the precision of each algorithm
according to categorical context only. Our
approch is better than other algorithms in the
aspect of Create Approval. The precision of our
approach is 86.8% at create approval. All
experiments our approach is better than ZeroR
with 1.5times.
0
20
40
60
80
100
120
createApproval Balance balloon
OurApproch J48 ZeroR NaïveBayses
Figure 7: Results of evaluation.
5 CONCLUSIONS
In this paper, we propose ontology based knowledge
modeling (OKM) that can support to provide the
two-step personalized services for the end users by
means of evolving network knowledge. To achieve
this, OKM is consisted of service category
preference model and contents preference model.
Moreover, we propose knowledge management
platform that can support to provide two-step
personalized services. Proposed platform has
two
major functions: leaner and recommender.
Learner
makes the user service usage model which consists
of {context, services} pairs. Recommender is
consisted of service recommender and contents
recommender.
We evaluated the learner and service
recommender functions in proposed platform using
UCI depository and Weka tool-kit.
Our approach is
better than other algorithms in the most of
experiments.
As a result, we expect that the
platform will be an essential component in next
generation networks. For further study, we have a
plan to provide wholly implementation for providing
two-step personalized services includes exposure
layer.
ACKNOWLEDGEMENTS
This research is supported by the IT R&D program
of MKE/IITA of South Korea. (2009-F-048-01,
Development of Customer Oriented Convergent
Service Common Platform Technology based on
Network).
REFERENCES
WWRF, 2005. Technologies for the Wireless Future: Wire-
less World Research Forum (WWRF), John Wiley&Son.
Albena Mihovska et al., 2007. “Towards the Wireless
2010 Vision: a Technology Roadmap,” Wireless
Personal Communications, vol.42, 2007, pp.303-336.
Yoo-mi Park, Aekyung Moon, Young-il Choi, and Sangha
Kim, 2009. “Value-added Knowledge layer for the
Context-aware Personalized Services in the Next
Generation Networks,” The 3rd Intl. Conference on
Knowledge Generation, Communication and
Management, in press.
IST-2004-511607, MobiLife D27b (D4.1b) v1.0, 2004.
G. Adomavicus, R. Sankaranarayanan, S. Sen and A.
Tuzhilin, 2005. “Incorporating Contextual Information
in Recommender Systems Using a Multidimensional
Approach”, ACM Transactions on Information
Systems, 23(1), pp. 103-145.
Bernd Mrohs et al., 2006. “MobiLife Service
Infrastructure and SPICE Architecture Principles,” In
Proc. of IEEE Vehicular Technology Conf., Montreal,
Canada, pp. 3047-3051.
Dey AK, 2001. “Understanding and Using Context,”
Journal of Personal and Ubiquitous Computing,
Vol.5, No.1, pp.4-7.
The TV-Anytime Forum, Specification Series: S-3 On:
Metadata, 2001.
M. Papagelis, D. Plexousakis and T. Kutsuras, 2005.
“Alleviating the Sparsity Problem of Collaborative
Filtering Using Thrust Inferences,” iTrust, LNCS, pp.
224-239.
S. Louis, A. Shankar, 2004. “Context Learning Can
Improve User Interaction, Information Reuse and
Integration,” IEEE conf. IRI, pp. 115-120.
Mitchell, 1997. Machine Learning, McGraw-Hill.
ONTOLOGY BASED KNOWLEDGE MODELING FOR THE TWO-STEP PERSONALIZED SERVICES IN NEXT
GENERATION NETWORKS
337
