
COMBINING SHAPE DESCRIPTORS AND COMPONENT-TREE
FOR RECOGNITION OF ANCIENT GRAPHICAL DROP CAPS
Benoˆıt Naegel and Laurent Wendling
LORIA UMR 7503, Nancy University, 54506 Vandœuvre-l`es-Nancy, France
Keywords:
Component-tree, Segmentation, Classification, Mathematical morphology, Ancient graphical drop caps.
Abstract:
The component-tree structure allows to analyse the connected components of the threshold sets of an image
by means of various criteria. In this paper we propose to extend the component-tree structure by associating
robust shape-descriptors to its nodes. This allows an efficient shape based classification of the image connected
components. Based on this strategy, an original and generic methodology for object recognition is presented.
This methodology has been applied to segment and recognize ancient graphical drop caps.
1 INTRODUCTION
Many pattern recognition tasks rely on thresholding
techniques,which can be very efficient to performtwo
class classification between object and background
pixels (Weszka, 1978; Fu and Mui, 1981; Sahoo
et al., 1988; Trier and Jain, 1995; Trier and Taxt,
1995a; Sezgin and Sankur, 2004). However these
methods all rely on the choice of a threshold, either
global or local. Therefore, to avoid the threshold
computation, one strategy could consist to consider
the connected-components of all the image threshold
sets. These connected-components can be organized
in a tree called “component-tree”. Component-trees
(also called max-tree (Salembier et al., 1998), den-
drone (Chen et al., 2000), confinement-tree (Mattes
and Demongeot, 2000)) have been involved in many
image processing tasks, such as image simplifica-
tion (Salembier et al., 1998), object detection (Jones,
1999; Naegel et al., 2007), image retrieval (Mosorov,
2005), caption text detection (Le´on et al., 2005).
The component-tree has been used in mathematical
morphology to perform attribute filtering (Breen and
Jones, 1996), by storing an attribute into each node
of the tree. The notion of shape-based attributes has
been considered only recently (Urbach and Wilkin-
son, 2002; Urbach, 2005; Urbach, 2007) and this con-
cept has been applied to filament extraction in MR an-
giograms (Urbach and Wilkinson, 2002) and classifi-
cation of diatoms (Urbach, 2007). For both segmenta-
tion and detection purposes, shape-descriptors can be
used to perform efficient shape-based classification of
the nodes. In this paper we expose a method allow-
ing to perform both object segmentation and recogni-
tion based on the component-tree structure. Such an
approach has been experimented to perform ancient
drop cap recognition.
2 COMPONENT-TREE FOR
OBJECT RECOGNITION
2.1 Component-tree Definition
An attributed component-tree is defined as a triple
G = (V ,E ,δ), where V represents the set of nodes,
E is the set of edges and δ a function that assigns to
each node u ∈ V a set of attributes δ(u). A grey-level
image is defined as a function F : E → T, where E is
the domain of definition (E ⊆ Z
2
) and T ⊆ Z is the set
of values. As we consider only discreteimages having
discrete values, we set T = [0,M]. The i-th connected
component of the superior threshold sets X
t
(F) =
{p ∈ E | F(p) ≥ t} is denoted C
i
t
(F) (in the sequel
we write C
t
for designing such a component). The set
of all connected components of all superior threshold
sets is denoted C C (F) = {C
i
t
(F) | t ∈ T,i ∈ I} (this
set is denoted C C in the sequel). Inferior threshold
sets X
u
(F) = {p ∈ E | F(p) ≤ u} can be considered
as well, leading to the dual component-tree represen-
tation. The component-tree is constructed as follows.
A map m : V 7→ C C is defined between the set of ver-
tices and the set of components. For each C
t
∈ C C ,
297
Naegel B. and Wendling L.
COMBINING SHAPE DESCRIPTORS AND COMPONENT-TREE FOR RECOGNITION OF ANCIENT GRAPHICAL DROP CAPS.
DOI: 10.5220/0001775502970302
In Proceedings of the Fourth International Conference on Computer Vision Theory and Applications (VISIGRAPP 2009), page
ISBN: 978-989-8111-69-2
Copyright
c
2009 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
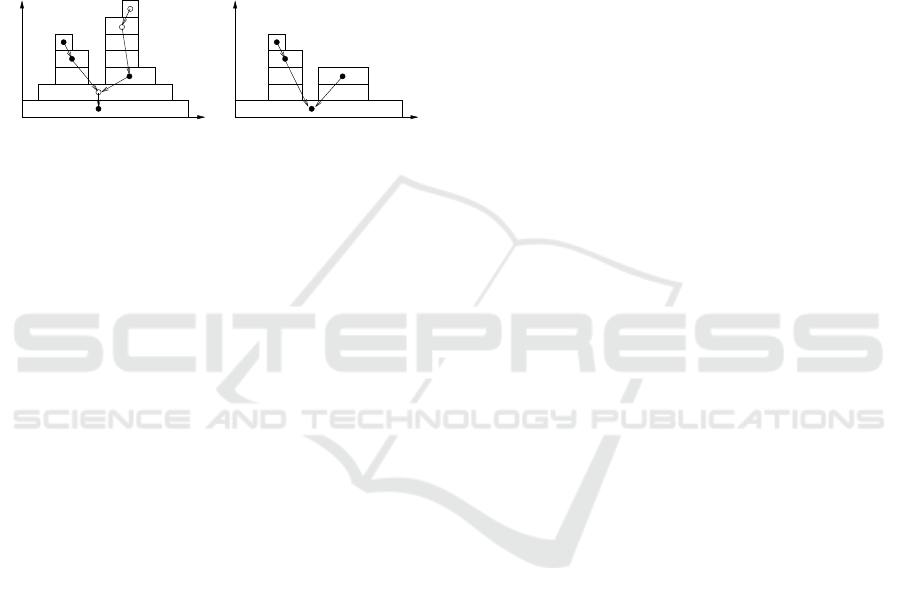
a node u ∈ V associated to this component is cre-
ated. An edge is created between each pair of vertices
(u,v) ∈ V × V if and only if:
• (i) u = m
−1
(C
t
),v = m
−1
(C
t+k
)(t,k ≥ 0);
• (ii) C
t+k
( C
t
;
• (iii) ∀l ≥ 0,C
t+l
( C
t
⇒ C
t+l
( C
t+k
,
and u is the father of v. The root of the tree is denoted
by the node r = m
−1
(C
0
). An example of component-
tree constructed from a 1D image is provided in Fig-
ure 1.
T
E
C
1
0
C
1
1
C
1
2
C
1
3
C
1
4
C
1
5
C
1
6
T
E
C
1
0
C
1
2
C
1
3
C
1
4
Figure 1: a) Component-tree of a 1D image. Empty circles
denote nodes that do not meet a criterion, b) Tree pruning.
In the reconstructed image (using direct decision), all irrel-
evant components C
t
have been removed.
2.2 Node Classification
Given a criterion D that accepts or rejects a node de-
pending on its attribute values, an attribute filter φ can
be defined by acting separately on the component-tree
nodes. Pruning the tree according to this classification
decision and constructingthe image obtainedfrom the
pruned tree allows to remove all the irrelevant con-
nected components of the threshold sets of an image.
This is the principle of attribute filters (Breen and
Jones, 1996; Jones, 1999). Pruning the component-
tree with respect to non-increasing criterion can lead
to remove nodes which have ancestors or descen-
dants that are not removed, which is problematic to
reconstruct an image. Therefore, various strategies
have been defined to reconstruct an image from a tree
pruning based on non-increasing criterion: min, max,
direct, subtractive (Salembier et al., 1998; Urbach,
2007). In an object detection purpose, image recon-
struction can be based on the direct decision (Salem-
bier et al., 1998), which is equivalent to keep only the
relevant connected components of the image (see Fig-
ure 1): φ(F)(x) = max{t | x ∈ C
t
,D(m(C
t
)) = true}.
2.3 Attributes
A set of attributes δ(u) is associated to each node
u ∈ V . For efficiency reasons, these attributes should
be computed incrementally: for each node, the com-
putation result of child attributes is used to compute
the current ones.
2.3.1 Scalar Attributes
Scalar attributes of various kinds can be associated
to nodes. Many attributes have been used in the lit-
erature such as component area, length of the short-
est path to a leaf node, cumulated sum of area of
all descendant nodes. Pruning the tree according to
criteria based on these attributes led respectively to
the area filter (Vincent, 1992; Vincent, 1993), the h-
min filter (Grimaud, 1992; Soille, 2003), and volu-
mic filter (Vachier, 1998), well known in mathemati-
cal morphology. Combination of scalar attributes can
also be used, leading to vectorial attributes (Urbach,
2005; Urbach, 2007; Naegel et al., 2007). However
these kinds of quantitative attributes are not descrip-
tive enough to perform a robust shape-based classifi-
cation of nodes.
2.3.2 Shape Descriptors
To use the component-tree for pattern recognition,
shape descriptors can be associated to nodes. In-
deed, shape descriptors allow compact description of
a shape, while being robust against noise and pose
variations. There is a large choice of shape descrip-
tors available in the literature (see (Zhang and Lu,
2004) for a survey). In this paper, we compare the
performance of two descriptors, chosen for their ro-
bustness and their performance in content-based im-
age retrievalsystems: the R-transform and the generic
Fourier descriptor (GFD).
R-Transform. The R-transform (Tabbone et al.,
2006) is a shape descriptor based on the Radon trans-
form. The Radon transform of an image f (x,y) is de-
fined by:
T
R
f
(ρ,θ) =
Z
∞
−∞
Z
∞
−∞
f(x, y)δ(xcosθ+ysinθ−ρ)dxdy,
where δ is the Dirac delta-function (δ(x) = 1 if x = 0
and δ(x) = 0 elsewhere), θ ∈ [0, π[ and ρ ∈] − ∞,∞[.
The R-transform is defined by:
R
f
(θ) =
Z
∞
−∞
T
2
R
f
(ρ,θ)dρ
The R-transform is invariant under translation and
scaling if the transform is normalized by a scaling
factor (the area of the R-transform). However the R-
transform is not invariant under rotation (a rotation of
the shape implies a translation of the transform).
Generic Fourier Descriptor. Generic Fourier de-
scriptors (GFD)(Zhang and Lu, 2002) belong to stan-
dard MPEG-7. They are defined from polar discrete
VISAPP 2009 - International Conference on Computer Vision Theory and Applications
298

transform. It is similar to Fourier transform, but con-
sidering the polar image in a polar space as a rectan-
gular image in a Cartesian space:
PF(ρ, φ) =
∑
x
∑
y
f(x, y).e
h
2jπ
r(x,y)
R
ρ+v(x,y)φ
i
The GFD is defined as follows:
GFD =
n
|PF(0,0)|
M
11
,
|PF(0,1)|
|PF(0,0)|
,.. .
|PF(m,n)|
|PF(0,0)|
o
GFD is invariant to rotation and translation by defi-
nition. Invariance to scale factor is ensured by divid-
ing the first term by area value M
11
and the others by
|PF(0, 0)|.
Incremental Computation. Computing shape de-
scriptors for all the threshold components leads to a
high computational burden. In order to compute effi-
ciently GFD or R-transform for each node, it is desir-
able to find an incremental scheme allowing to use the
results of the child nodes to compute the result of the
current node. This can be done by using accumulator
arrays. The computation of the GFD was based on
an incremental scheme, by taking as origin the image
barycenter for all the nodes.
3 RECOGNITION OF ANCIENT
GRAPHICAL DROP CAPS
In recent years, large digitalization campaigns of an-
cient printed document collections led to recurrent
problems such as data archiving, classification and
efficient retrieval. Due to the handwritten nature of
ancient books, recognition of ancient characters can-
not be easily achieved by using modern optical char-
acter recognition (OCR) systems. Ancient graphical
drop caps segmentation has been addressed by Ut-
tama (Uttama et al., 2005), where the image is sepa-
rated into its textural and homogeneous parts. How-
ever the problem of drop cap recognition has not been
addressed due to the difficulty of extracting the drop
cap’s uppercase.
3.1 Data
The Madonne database OLDB (Ornamentals Letters
DataBase) consists of graphical decorative initials ex-
tracted from archival documents
1
. This corpus is part
1
We would like to thank the “Centre d’´etudes
Sup´erieures de la Renaissance” for the permission to use
their archival documents.
of a study performed by French research teams
2
on
historical documents. The database is composed of
more than 6000 drop caps. To conduct our experi-
ments, we have selected from this database a subset
of 200 images representing 20 different uppercases.
The test set has been constructed to be representative
of the various styles of drop caps (see examples on
Figure 2). Drop cap images are grey-scale, composed
of the letter (uppercase) part and texture part. Size of
images is between 150 × 150 and 750× 750. Due to
the digitalization process, the letter is approximately
centered and vertical. Drop cap images are noisy and
contain artifacts such as superimposed text, coming
from following book pages.
Figure 2: Drop cap samples of a subset of the OLDB (Or-
namentals Letters DataBase) database.
3.2 Image Processing
Using the methodology exposed in Section 2 for drop
cap recognition requires to make the assumption that
at least one connected component C
t
of the supe-
rior threshold sets X
t
(F) corresponds to the uppercase
part. By making this assumption, the letter part of the
drop cap must appear white on dark background. This
assumption does not always hold, since drop caps up-
percases can also appear black on a white background
(see Figure 2). It is hence necessary to consider not
only the connectedcomponentsof the superior thresh-
old sets, but also those of the inferior threshold sets.
To this aim, the dual component-tree (the component-
tree of the inferior level sets) is computedfor each im-
age. It is obtained by computing the component-tree
of the negative image. In the test set, many drop caps
contain a distinct component corresponding to the let-
ter part. However in some cases the letter part is con-
nected to other image parts (texture or background).
In order to ensure that at least one component corre-
sponds to the letter part we process each image us-
ing morphological openings (Soille, 2003), to remove
thin connections between components. Due to the
stack property of morphological operators, applying a
morphological grey-scale opening is equivalent to ap-
plying a binary opening on all of its superior threshold
sets. Therefore, for each drop cap image F, we com-
pute the set:
S(F) = {F,F
c
,{γ
B
i
(F)}
1≤i≤r
max
,{γ
B
i
(F
c
)}
1≤i≤r
max
},
2
see http://l3iexp.univ-lr.fr/madonne/
COMBINING SHAPE DESCRIPTORS AND COMPONENT-TREE FOR RECOGNITION OF ANCIENT GRAPHICAL
DROP CAPS
299

where F
c
is the image complement (negative), γ de-
notes the morphological opening, B
i
∈ P (E) is the
disk structuring element of radius i, and r
max
is the
maximal value of the radius. For each image F
i
∈ S is
computed the corresponding component-tree G
i
.
From an algorithmic point of view, Salembier’s
algorithm (Salembier et al., 1998) was used to com-
pute efficiently the component-tree, using a recursive
scheme
3
.
3.3 Training Set
A set of letters has been segmented using interactive
method based on the choice of the most relevant con-
nected component of the threshold sets, using area
and compacity criteria to prune the component-tree.
The GFD signatures associated to the component-
tree nodes have been computed using an efficient in-
cremental method (Section 2). As a consequence, the
GFD signatures are not translation invariant, since the
same origin has been taken for all the components.
Although the uppercases are approximately centered,
slight translation variations can occur between letters
of similar classes. This can be addressed by adding in
the training set translated versions of segmented let-
ters along the x-axis.
We chosed a cluster head for each class and com-
puted two translated images by a vector v = (v
x
,0),
with v
x
= {±0.1 dx}, dx denoting the image width.
Each class of the training set is then composed of a
segmented image and its two translations.
3.4 Recognition Process
For each tree node u is retrieved the least Euclidian
distance between the node attributes and the training
set samples attributes. From all these distances, the
k least distances are retained, as well as the k corre-
sponding classes. The recognition is performed by
considering the most represented class from these k
classes (here k = 30).
4 RESULTS
4.1 Validation Protocol
We have compared the following methods. The three
first onesrely on the component-treecomputation; the
3
According to (Najman and Couprie, 2006), Salembier’s
algorithm is quadratic in the worst case; however it is gen-
erally twice as fast as Najman’s one in practical cases when
the image range is [0...255].
fourth is based on global grey-scale GFD computa-
tion. The last one is based on a binarization strategy.
1. CT+scalar. Component-tree based recognition
using scalar attributes. In this method, we con-
sider for each node u ∈ V the set of scalar at-
tributes δ(u) = (a
1
,a
2
) with:
• a
1
= area/(image size) the normalized area of
the component with respect to the image size;
• a
2
= 4π∗area/perimeter
2
an attribute related to
the compacity of the component.
2. CT+GFD. Component-tree based recognition us-
ing GFD. The GFD has been computed using
m = 5 radial and n = 5 angular frequencies.
3. CT+RT. Component-tree based recognition using
R-Transform. The R-Transform has been com-
puted using r = 10 radial and t = 10 angular sam-
ples.
For the GFD and the R-Transform, a perfor-
mance evaluation of the shape descriptors follow-
ing different discretization parameters has been
performed. In both cases, increasing the param-
eters beyond the chosen ones did not improve the
results while increasing the processing time. In
the latter methods based on the component-tree,
the maximal radius for the morphological open-
ings has been set to r
max
= 3.
4. Grey-scale GFD. Classification based on grey-
scale GFD computation. A training set composed
of one head drop cap for each class has been con-
structed. Each tested image was classified accord-
ing to the closest training set GFD.
5. Entropy+GFD. Binarization method based on
entropy. A powerful binarization method which
performs a fuzzy partition on a bidimensional his-
togram of the image (Cheng and Chen, 1999)
has been experimented. The partition criteria are
based on the optimization of the fuzzy entropy.
This approach is threshold free and it has been
shown that the results obtained are better than for
the 2D non fuzzy approach. The image is classi-
fied according to the GFD of the remaining con-
nected components, using the same method (train-
ing set and classification strategy) than CT+GFD.
4.2 Results on 8 Classes
In a first experiment, we tested the methods on a sub-
set of 80 drop caps divided in 8 classes. The selected
classes correspond to the most frequent letters in the
whole database. Table 1 shows a comparison of the
segmentation and classification results between meth-
ods.
VISAPP 2009 - International Conference on Computer Vision Theory and Applications
300
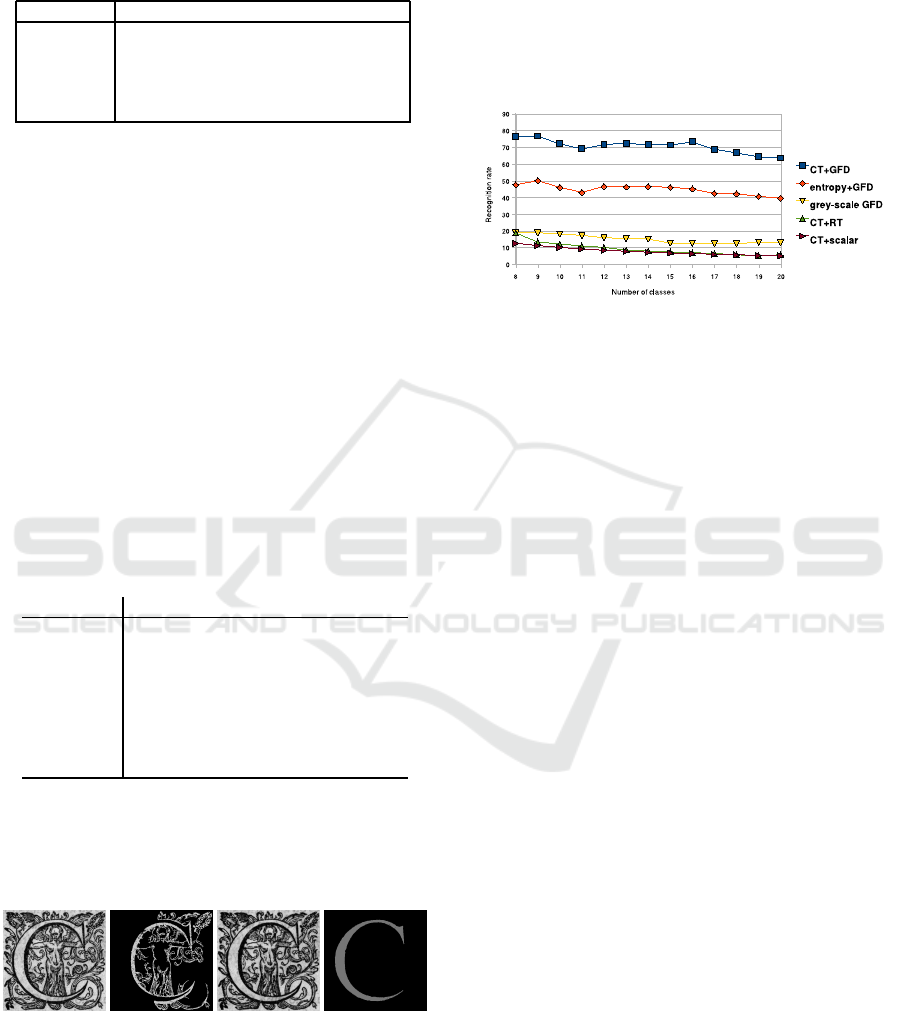
Table 1: Comparison of segmentation, recognition rates
and computational time (in s) of methods on 80 drop caps
from 8 classes.
Method Segmentation Recognition Time
CT+scalar 7.5% 12.5% 52
CT+RT 5% 18.8% 575
CT+GFD 62.5% 76.3% 332
ent.+GFD 38.7% 47.5% 534
gr. GFD - 18.8% 40
The method based on the component-tree and
GFD descriptor outperformed the others, with a
recognition rate of 76.3%. This result is promis-
ing, since the method has not been specifically tuned
for the drop cap recognition. Component-tree meth-
ods based on other attributes (scalar or R-transform)
performed poorly on the considered dataset. The
method based on entropy binarization gave interest-
ing results; howeverin 25% of the images, the method
chosed a wrong threshold, leading to nearly black
or white images. Moreover this method is slower
than CT+GFD, due to the computation of the opti-
mal threshold. Grey-scale GFD gave poor results,
since the drop caps show many texture and contrast
variations. The confusion matrix obtained with the
CT+GFD method is given in Table 2.
Table 2: Confusion matrix of the classification results using
the CT+GFD method on 8 classes.
Uppercase A C E I L P Q S
A 8 1 0 0 0 0 1 0
C 0 8 0 0 0 0 2 0
E 0 0 6 1 1 0 1 1
I 0 0 0 7 1 0 0 2
L 0 1 0 1 7 0 0 1
P 0 0 2 0 2 6 0 0
Q 0 0 0 0 0 0 10 0
S 0 0 0 1 0 0 0 9
In the tree based methods, morphological open-
ing allowed to disconnect the uppercase from texture
parts as illustrated on figure 3, therefore increasing
the recognition rate.
Figure 3: a) Original drop cap image, b) Segmentation of
(a) (letter recognized as ”S”), c) Opened image (the upper-
case is disconnected from the background), d) Segmenta-
tion of (c) (letter properly recognized).
4.3 Scalability of the Approach
The number of classes has been gradually increased,
by decreasing order of their frequencies in the whole
database. The Figure 4 summarizes the results ob-
tained with the different methods and shows the good
behaviour of the proposed approach.
Figure 4: Recognition percentages of the methods with re-
spect to the number of considered classes.
4.4 Discussion
The method based on entropy binarization and GFD
classification is less robust than the method CT+GFD,
due to the inaccurate image binarization in some
cases. These results demonstrate that method based
on the component-tree structure extended with robust
shape-descriptors allows to analyse all the threshold
components, therefore avoiding to chose a specific
binarization threshold. Hence, the method CT+GFD
reached the best results, achieving a recognition rate
of 63.5% on 20 classes.
5 CONCLUSIONS
In this paper we have proposed to combine the
component-tree representation of an image with ro-
bust shape-descriptors, in order to perform object
recognition. Based on this strategy, we have ex-
posed a methodology for ancient graphical drop cap
recognition. The best recognition rate was 76.3%
on 8 classes and 63.5% on 20 classes. These re-
sults, although perfectibles, are interesting since the
method has not been specifically tuned for this appli-
cation. Moreover, the computation of the attributed
component-tree could be done offline, leading to effi-
cient recognition tasks.
In future works we will investigate the clas-
sification strategies offered by the combination of
component-tree and shape descriptors. More specifi-
cally, we plan to use more deeply the information car-
ried by the component-treestructure to performimage
recognition and spotting.
COMBINING SHAPE DESCRIPTORS AND COMPONENT-TREE FOR RECOGNITION OF ANCIENT GRAPHICAL
DROP CAPS
301

REFERENCES
Breen, E. and Jones, R. (1996). Attribute openings, thin-
nings, and granulometries. CVIU, 64(3):377–389.
Chen, L., Berry, M., and Hargrove, W. (2000). Using den-
dronal signatures for feature extraction and retrieval.
International Journal of Imaging Systems and Tech-
nology, 11(4):243–253.
Cheng, H.-D. and Chen, Y.-H. (1999). Fuzzy partition
of two-dimensional histogram and its application to
thresholding. Pattern Recognition, 32(5):825–843.
Fu, K. S. and Mui, J. K. (1981). A Survey on Image Seg-
mentation. Pattern Recognition, 13:3–16.
Grimaud, M. (1992). New measure of contrast: dynamics.
In Gader, P., Dougherty, E., and Serra, J., ed., Image
Algebra and Morphological Image Processing III, vol.
SPIE-1769, pages 292–305. SPIE.
Jones, R. (1999). Connected filtering and segmentation us-
ing component trees. CVIU, 75(3):215–228.
Le´on, M., Mallo, S., and Gasull, A. (2005). A tree
structured-based caption text detection approach. In
Fifth IASTED International Conference Visualisation,
Imaging and Image Processing, pages 220–225.
Mattes, J. and Demongeot, J. (2000). Efficient algorithms
to implement the confinement tree. In Borgefors, G.,
Nystr¨om, I., and di Baja, G. S., ed., DGCI’00, vol.
1953 of LNCS, pages 392–405. Springer.
Mosorov, V. (2005). A main stem concept for image match-
ing. Pattern Recognition Letters, 26:1105–1117.
Naegel, B., Passat, N., Boch, N., and Kocher, M. (2007).
Segmentation using vector-attributes filters: method-
ology and application to dermatological imaging. In
Bannon, G., Barrera, J., and Braga-Neto, U., ed.,
ISMM 2007, Brazil., vol. 1, pages 239–250. INPE.
Najman, L. and Couprie, M. (2006). Building the compo-
nent tree in quasi-linear time. IEEE Trans. on Image
Processing, 15(11):3531–3539.
Sahoo, P. K., Soltani, S., Wong, A. K. C., and Chen, Y. C.
(1988). A survey of thresholding techniques. CVGIP,
41(2):233–260.
Salembier, P., Oliveras, A., and Garrido, L. (1998). Anti-
extensive connected operators for image and se-
quence processing. IEEE Trans. on Image Processing,
7(4):555–570.
Sezgin, M. and Sankur, B. (2004). Survey over image
thresholding techniques and quantitative performance
evaluation. Journal of Electronic Imaging, 13(1):146–
165.
Soille, P. (2003). Morphological Image Analysis: Princi-
ples and Applications. Springer-Verlag Berlin Heidel-
berg, 2nd edition.
Tabbone, S., Wendling, L., and Salmon, J.-P. (2006). A
new shape descriptor defined on the radon transform.
CVIU, 102:42–51.
Trier, Ø. and Taxt, T. (1995a). Evaluation of Binarization
Methods for Document Images. IEEE Transactions
on PAMI, 17(3):312–315.
Trier, Ø. D. and Jain, A. K. (1995). Goal-Directed Evalua-
tion of Binarization Methods. IEEE Trans. on PAMI,
17(12):1191–1201.
Urbach, E. (2005). Vector attribute filters. In ISMM’05 -
International Symposium on Mathematical Morphol-
ogy, vol. 30 of Computational Imaging and Vision,
pages 95–104. Springer SBM.
Urbach, E. (2007). Connected shape-size pattern spectra
for rotation and scale-invariant classification of gray-
scale images. IEEE Trans. on PAMI, 29(2):272–285.
Urbach, E. and Wilkinson, M. (2002). Shape-only granu-
lometries and gray-scale shape filters. In ISMM’02,
pages 305–314. CSIRO Publishing.
Uttama, S., Ogier, J., and Loonis, P. (2005). Top-down seg-
mentation of ancient graphical drop caps: Lettrines.
In Proceedings of the 6th GREC, pages 87–96.
Vachier, C. (1998). Utilisation d’un crit`ere volumique pour
le filtrage d’image. In RFIA’98, pages 307–315.
Van Droogenbroeck, M. and Talbot, H. (1996). Fast com-
putation of morphological operations with arbitrary
structuring elements. Pattern Recognition Letters,
17(14):1451–1460.
Vincent, L. (1992). Morphological Area Openings and
Closings for Grey-Scale Images. In Shape in Picture:
Nato Workshop, pages 197–208. Springer.
Vincent, L. (1993). Grayscale area openings and clos-
ings, their efficient implementations and applications.
In EURASIP Workshop on Mathematical Morphology
and its Applications to Signal Processing, pages 22–
27.
Weszka, J. S. (1978). A survey of threshold selection tech-
niques. Computer Graphics and Image Processing,
7:259–265.
Zhang, D. and Lu, G. (2002). Shape-based image retrieval
using generic Fourier descriptor. Signal Processing:
Image Communication, 17:825–848.
Zhang, D. and Lu, G. (2004). Review of shape representa-
tion and description techniques. Pattern Recognition,
37(1):1–19.
VISAPP 2009 - International Conference on Computer Vision Theory and Applications
302
