
USE OF ADAPTIVE BOOSTING IN FEATURE SELECTION
FOR VEHICLE MAKE & MODEL RECOGNITION
I. Zafar, B. S. Acar and E. A. Edirisinghe
Department of Computer Science,Loughborough University, Ashby Road, Loughborough, U.K.
Keywords: Vehicle make & model recognition, Scale invariant feature transform, AdaBoost, Classification, Feature
matching.
Abstract: Vehicle Make and Model Recognition (Vehicle MMR) systems that are capable of improving the
trustworthiness of automatic number plate recognitions systems have received attention of the research
community in the recent past. Out of a number of algorithms that have been proposed in literature the use of
Scale Invariant Feature Transforms (SIFT) in particular have been able to demonstrate the ability to perform
vehicle MMR, invariant to scale, rotation, translation, which forms typical challenges of the application
domain. In this paper we propose a novel approach to SIFT based vehicle MMR in which SIFT features are
initially investigated for their relevance in representing the uniqueness of the make and model of a given
vehicle class based on Adaptive Boosting. We provide experimental results to show that the proposed
selection of SIFT features significantly reduces the computational cost associated with classification at
negligible loss of the system accuracy. We further prove that the use of more appropriate feature matching
algorithms enable significant gains in the accuracy of the algorithm. Experimental results prove that a 91%
accuracy rate has been achieved on a publically available database of car frontal views.
1 INTRODUCTION
Several vehicle recognition systems based on
correctly recognizing vehicle number plates, are in
widespread use at present. However reports by
police and media sources have indicated that
number-plate cloning, have been recently used to
breach the security provided by Automatic Number
Plate Recognition (ANPR) techniques. This problem
can be addressed by enhancing the reliability of
access control systems by the combined use of
ANPR and vehicle Make & Model Recognition
(MMR) techniques. A match between the vehicle
registration number and the make and model will
confirm the vehicles authenticity.
Vehicle MMR is a comparatively new research
area. A number of techniques that directly relate to
vehicle MMR have been proposed in literature.
(Petrović and Cootes, 2004) proposed techniques for
the recognition of cars, by extracting gradient
features from images. (Negri et al., 2006) proposed
an oriented-contour point based voting algorithm for
multiclass vehicle type recognition. (Zafar,
Edirisinghe and Acar, 2008) proposed the use of
localised directional feature maps in Contourlet
transforms for vehicle MMR. (Dlagnekov 2005;
Zafar, Edirisinghe and Acar, 2007; Cheung and Chu,
2008) explored the problem of MMR by using Scale
Invariant Feature Transforms (SIFT) (Lowe, 2004).
It is used to identify distinct points of interest in car
images, called keypoints, which are subsequently
utilized in matching. (Zafar, Edirisinghe and Acar,
2007) proposed a further improvement to this basic
approach via restricting the SIFT keypoint detection
to only query image and using a SIFT descriptors
belonging to all points within a maximum-likelihood
area of the candidate images, for matching. (Cheung
and Chu, 2008) improved the work of (Dlagnekov,
2005) by introducing improvements to keypoint
matching.
Although a number of different approaches have
been published in literature for vehicle MMR, the
search for a robust, efficient algorithm still remains
an open research problem. In this paper we attempt
to contribute to the current state-of-the-art in vehicle
MMR by addressing the shortcomings of the state-
of-the-art techniques in SIFT based vehicle MMR
(see Section 2).
142
Zafar I., Acar B. and Edirisinghe E.
USE OF ADAPTIVE BOOSTING IN FEATURE SELECTION FOR VEHICLE MAKE MODEL RECOGNITION.
DOI: 10.5220/0001774501420147
In Proceedings of the Fourth International Conference on Computer Vision Theory and Applications (VISIGRAPP 2009), page
ISBN: 978-989-8111-69-2
Copyright
c
2009 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

2 RESEARCH MOTIVATION
Vehicle MMR approaches proposed in literature, are
based on an initial stage of feature detection, where
these detected features are subsequently used in
matching. Majority of these methods rely on edge
maps, smooth curves/contours as features. However,
even the best edge extractor could fail to identify all
edges that will be required in uniquely defining
make and model of a vehicle in cases where the
captured images of the vehicles are not clear, due to
adverse lighting effects, occlusion and pose/scale
variations etc. The SIFT based car MMR
approaches of (Dlagnekov, 2005; Zafar, Edirisinghe
and Acar, 2007; Cheung and Chu, 2008), promise to
address some of the above mentioned shortcomings
of traditional feature based approaches. Specifically
SIFT based approaches enable the extraction of
invariant features from images that results in more
robust feature based matching under occlusion, scale
and rotation invariance. Thus SIFT based
approaches have been particularly used in object
recognition, where the object being searched is
immersed in background clutter. The basic SIFT
based approach to vehicle MMR (Dlagnekov, 2005)
was based on matching the keypoints of a query
image to the keypoints of images in a database. One
shortcoming of this simple approach is that
keypoints from the background (i.e. outliers) of the
query and database images may dominate the
matching process thereby resulting in wrong
matches. As a solution to this problem (Cheung and
Chu, 2008) suggested the use of RANdom
SAmpling Consensus (RANSAC) (Fischler and
Bolles, 1981) to separate outliers from inliers.
However this approach involved the detection of the
vehicle boundary area using edge/contour detectors
and then using an iterative algorithm RANSAC. The
accuracy of this is highly dependent on the accuracy
of the segmentation of the object area and the
iterative process makes the approach time
consuming.
In order to resolve these problems we propose a
novel approach to SIFT based vehicle MMR. The
idea is based on the fact that humans are able to
identify a given vehicle’s make-model based on a
mental matching of each model’s unique features,
such as the shape of the grill, badge, shape of lights
etc. We show that after the keypoints have been
found, AdaBoost (Freund and Schapire, 1997) can
be used to select features that are most
representative of a given make-model enabling its
use in vehicle MMR. We provide experimental
results to prove the effectiveness of the proposed
algorithm.
For clarity of presentation, this paper is divided
into five sections. Apart from this section which
introduces the reader to the problem domain and
highlights open research issues in vehicle MMR,
section 2 introduces the fundamental theoretical
concepts required to support the introduction of
proposed methodology in section 3. Section 4,
provides results of a number of experiments
performed to prove the effectiveness of the proposed
approach. Finally section 5 concludes with an
insight to future improvements.
2.1 Theoretical Background
The proposed approach uses SIFT as the feature
detector (Lowe, 2004) and ‘AdaBoost’ for feature
selection. A summary of AdaBoost can be presented
as follows.
2.1.1 Adaptive Boosting (AdaBoost)
AdaBoost is an algorithm first introduced by (Freund
and Schapire, 1997). It is an adaptive algorithm that
can boost a sequence of classifiers. It gradually
improves the accuracy of a learning algorithm by
concentrating on the “hardest” examples (those most
often misclassified) over each round and combine
these weak prediction rules in to a single strong
prediction rule by taking the (weighted) majority
vote of these weak prediction rules.
The AdaBoost Algorithm: According to (Freund
and Schapire, 1997; Freund and Schapire, 1999),
pseudo code for boosting is:
• Given: Training set of
),(),...,,(
11 mm
yxyx where Xx
i
∈ are the
instances of some domain
X
, and
}1,1{
−
+
=
∈
Yy
i
are labels of the
instances.
• Initially all training samples are given equal
weights i.e.
m
iDw
i
1
)(
1
1
== for i=1,…,m
(1)
• For
Tt ,...,1
=
:
o Set
∑
=
=
m
i
t
i
t
t
w
w
D
1
(2)
o Train weak learner on
distribution
t
D .
USE OF ADAPTIVE BOOSTING IN FEATURE SELECTION
FOR VEHICLE MAKE & MODEL RECOGNITION
143
o Find a weak hypothesis/classifier
}1,1{:
−
+→Xh
t
with small error
|)(|)(
1
iit
m
i
tt
yxhiD −=∈
∑
=
(3)
o Select
⎟
⎟
⎠
⎞
⎜
⎜
⎝
⎛
∈
∈−
=
t
t
t
1
ln
2
1
α
(4)
o Update
t
t
t
Z
iD
iD
)(
)(
1
=
+
⎪
⎩
⎪
⎨
⎧
×
−
t
t
e
e
α
α
if
if
)(
)(
i
xt
it
h
xh
i
i
y
y
≠
=
t
ititt
Z
xhyiD
))(exp()(
α
−
=
(5)
where,
t
Z is a normalization factor.
• Output the final hypothesis which is a
weighted majority vote of the T weak
hypothesis.
)(xH
=
⎟
⎟
⎠
⎞
⎜
⎜
⎝
⎛
∑
=
T
t
tt
xhsign
1
)(
α
(6)
3 PROPOSED APPROACH
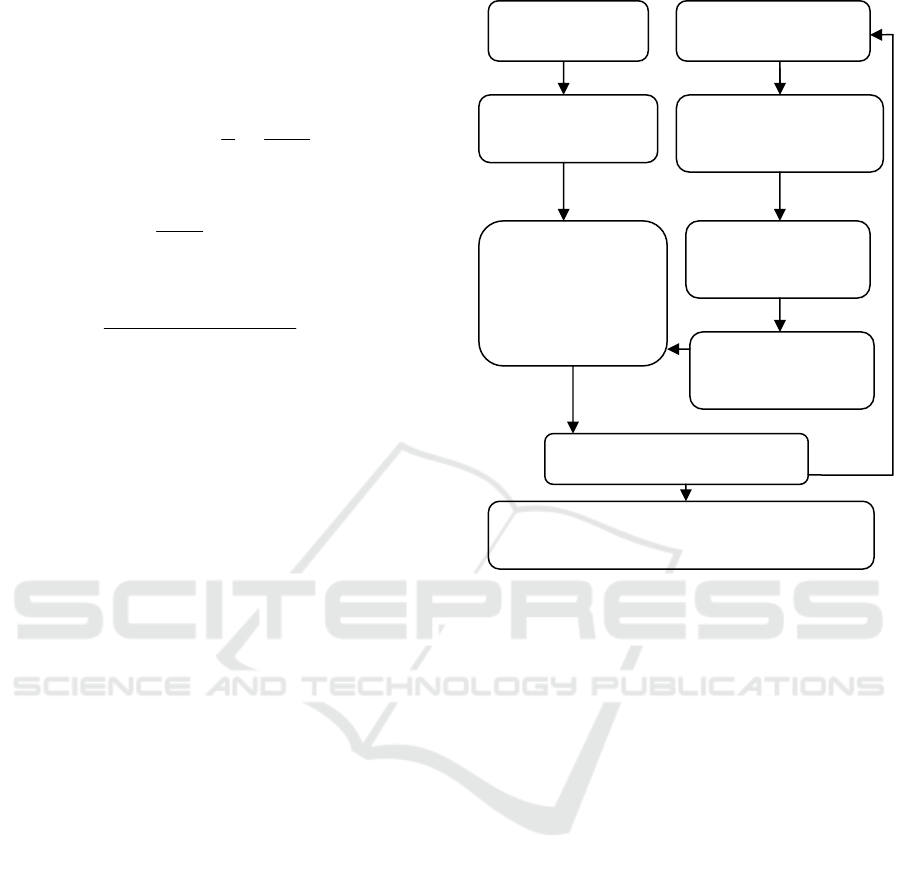
Figure 1 illustrates the block diagram of the
proposed approach to vehicle MMR. The basic idea
is to match the keypoints of a query image against
selection of unique and most representative feature
set selected from each make-model.
The stages involved can be detailed as follows:
3.1 Dataset Preparation
Two sets of training images are collected. In the first
set, images from the training and test sets are
cropped to include only the front grill, lights and
bumper area of all cars using the cropping approach
proposed in (Petrović and Cootes, 2004). Second set
consists of frontal views of cars that include
background clutter such as other cars, parking slot
markings, tarred surfaces, lamp posts etc. The
test/query images consist of cropped frontal views of
images of cars without background.
3.2 Feature Detection
As the first step of the proposed processing
algorithm, we investigated the use of interest point
Figure 1: Proposed System. overview.
detection technique: Scale-Invariant Feature
Transform (SIFT) (Lowe, 2004). SIFT defines
interest points as minima and maxima of the
difference of Gaussians that occur at multiple scales,
allowing a consistent detection of features on images
of cars.
In the proposed application of SIFT, keypoints
from all training images of a make-model are pooled
together. Similarly we detect keypoints for the test
images. Figure 2 illustrates the detected SIFT
features from two individual training images(Audi
A4) and the projection of all keypoints from all
training images on
an image of a selected image of
an Audi A4 car. It shows that the keypoints
concentrate near the grill, lights, badge and front
bumper areas.
3.3 Feature Selection
Images of cars in practical situations are assumed to
be taken on streets or in parking lots. This presents
the problem of having a background scene in the
image that can greatly affect the
relevance of
interest points that are detected. Within our present
research context, the method proposed to eliminate
Find keypoints of all
training images of the
given class
Find the keypoints
of the query image
Place keypoints from
all training images
together
Extract the inliers
that best represent
the make-model
Pair keypoints from
query image to that
of a particular
make-model. Find
goodness of match.
Repeat for all make-models
Select make-model with maximum number of
correct matches as the class label of the query
Take a query car
image
Take all training images
of a single make-model
VISAPP 2009 - International Conference on Computer Vision Theory and Applications
144

Figure 2: Detected SIFT features of individual images (top
row) and projected keypoints of a particular make-model
on a sample image
outliers, i.e. the interest points not associated with a
car, is to use AdaBoost (Freund and
Schapire, 1997;
Freund and Schapire, 1999)
According to (Freund and Schapire, 1999), a
useful property of AdaBoost is its ability to identify
examples that are either mislabelled in the training
data or which are inherently ambiguous and hard to
categorize. These are thus called ‘hard’ points,
whereas robust points are called ‘easy’ points. As
AdaBoost focuses its weight on the hardest
examples, the examples with the highest weights
often turn out to be outliers. Further according to
(Caprile, 2002), Entropy (Information Entropy,
2008) is used as a measure for separating ‘easy
points’ from ‘hard’ points based on weight values.
Exploiting this, we have proposed the use of feature
selection based on weight values attached to the
keypoints of the training images of a particular
make-model.
During the training phase, keypoints from
training images of a particular make-model are
compared against rest of the classes. This is repeated
for all make-models (Note that we have also
introduced a class in training set, which only
consists of typical background area). We keep track
of weight values attached to all keypoints of
particular make-model up to certain number of
iterations of boosting. After each iteration weights
associated with keypoints are updated in order to
focus the algorithms attention on the hard points.
Entropy is then calculated for the stored weights
as: The interval [0, 1] is partitioned into L
Subintervals of length
L
1
and the entropy value is
computed as:
-
i
L
i
i
ff
2
1
log
∑
=
(7)
Where
i
f is the relative frequency of weight values
falling in the
thi
−
subinterval 0log0(
2
is set to 0).
For our experiments,
L was set to 500. These
entropy values are first sorted and keypoints with
lowest
N percent of entropy values are
subsequently selected as the valid features for a
particular car make-model. These selected features
are the best representative features of a class (i.e. car
make-model) as they have low uncertainty factor in
being classified in the right class.
3.4 Interest Point Matching
We have investigated two different methods for
matching interest points. The first is the original
SIFT feature matching procedure proposed by
(Lowe, 2004).In this approach the keypoints from
the test /query image are matched against each of the
selected keypoint from a particular model using
Euclidean distance as a measure. Pair of interest
points that match are considered to be those having
the minimum Euclidean distance. The model in the
database with highest inliers count will be labelled
as being the best matching image to the query
image, and the corresponding make-model category
will be used to label the query image. Second
approach adopted for matching is based on the SIFT
matching algorithm proposed in (Zafar, Edirisinghe
and Acar, 2007). In this approach SIFT descriptors
(Lowe, 2004) of the keypoints of every training
image is compared with SIFT descriptors of points
within a maximum likelihood area of the test
images, centred at the point that corresponds
location wise to the keypoint of the training image.
It is noted that images are cropped and normalised
before the matching method is used.
4 EXPERIMENTAL RESULTS
AND ANALYSIS
Two experiments were conducted to evaluate the
performance of the proposed algorithm. These
experiments were conducted on two datasets.
The first dataset consisted of 50 images of cars
(frontal views) belonging to 5 different classes.
These images were cropped at the top (only) to
remove the clutter in background due to foreign
objects, particularly other cars. However, some
background clutter is visible in the sides.
USE OF ADAPTIVE BOOSTING IN FEATURE SELECTION
FOR VEHICLE MAKE & MODEL RECOGNITION
145

This dataset was collected in order to prove that ada-
boosting can be used to identify features unique to a
given make-model (see Figure 3) in the presence of
other key-points in the training images.
The second dataset consisted of 300 images of
cars (frontal views) belonging to 25 different
classes. Each training class consisted of at least 8
images of different cars belonging to the same make
and model. [Note: the number of cars in each class
was not equal]. The images were cropped (Petrović
and Cootes, 2004) in all four sides (as appropriate)
to remove background clutter.
Initially an experiment was designed and
conducted on the second dataset to determine the
number of iterations
T, required for the AdaBoost
algorithm to obtain a stable result of classification
(discussed in section 2.1.1). In this experiment
descriptors of all keypoints of all BMW-3 cars were
labelled to be of one class and all other descriptors
from all other models were labelled to be of another
class. An accurate classification result was noted
when either a true positive or a true negative result
was obtained. Experiments revealed that
after
200=T , there is only a negligible decrease in
accuracy and the stabilisation accuracy was held
constantly at approximately 91%. A similar level of
accuracy was obtained for other make-models at
similar number of iterations.
A second experiment was designed to determine
the effects of applying the proposed technique for
feature selection from a pool of features obtained
from car images of a particular make-model. To
better visualise the effect of applying the proposed
technique in feature selection, we first applied the
idea on the first dataset. As this dataset consists of
areas from the background, it is useful in
demonstrating the fact that Adaboost will be able to
separate features unique to each make-model from
the feature points of the background areas. Further
note that the keypoints of a class associated with low
entropy measures indicate low uncertainty in
classification and are thus best to be used in
classification.
Therefore by selecting the keypoints associated with
the lowest entropy figures, only the most unique
features of a car make-model will be identified.
These can be subsequently used in vehicle make-
model recognition (see Figure 3).
It is obvious from the results illustrated in Figure
3 that keypoints with lowest entropy values
represent the inliers. We have experimented to
determine a suitable threshold value for the entropy
and found that keeping 25% of lowest entropy gives
the best accuracy.
A further experiment was conducted on the
second set of data (database of 300 images) to obtain
the overall classification accuracies. Keypoints
whose entropy values were within the lowest 25%
were selected for subsequent processing. Since the
second dataset consists of cropped images (from all
sides), the feature selection process helps to separate
keypoints of the class which are likely to be easily
confused with keypoints belonging to other classes.
In other words the features selection strategy
adopted will be able to identify unique feature points
that are distinctive for each make-model.
After the selection of keypoints that are able to
best represent unique features of all make-models,
the data will be ready for testing. Two methods were
used for matching the keypoints of the test image
with those of the given make-model classes; the
original SIFT keypoint matching algorithm proposed
in (Lowe, 2004) and the improved SIFT keypoint
matching scheme proposed in (Zafar, Edirisinghe
and Acar, 2007). Matching results are based on
selected features with lowest 25% entropy are
illustrated in Figure 4. Note the high degree of
correspondence between the matching keypoint.
The accuracy of classification achieved when the
proposed Adaboost based feature selection method
was adopted with the original SIFT (Lowe, 2004)
keypoint matching scheme, was 82% as compared to
83% when all keypoints were considered in
matching.
Figure 3: Left to right: First image shows all keypoints from the training set of a class projected onto one selected image.
Middle image represent 20% of feature selection based on highest entropy whereas last image represents feature selection
with 20% lowest entropy values.
VISAPP 2009 - International Conference on Computer Vision Theory and Applications
146

Note that testing was carried out on a random set
of 100 images, belonging to all classes. Note that by
using Adaboost based feature selection we have
been able to reduce the number of feature points
used in classification by 75%. Thus we have
achieved similar classification accuracy at a
significant reduction of computational cost during
testing. The matching accuracy can be further
improved to 91% by applying the matching scheme
of (Zafar, Edirisinghe and Acar, 2007). It is noted
that this scheme is more appropriate to be used
within the proposed approach as the selected
keypoints of the training image set now consists
25% of the most representative keypoints of the
model, thus decreasing the use of keypoints from the
background and from non-representative areas of the
model concerned, in training.
5 CONCLUSIONS
In this paper we have proposed the use of adaptive
boosting in selecting the most representative SIFT
features of a given car in vehicle MMR. We have
shown that the proposed selection of the most
appropriate SIFT features allows a significant gain
in the computational cost of previous SIFT based
approaches to vehicle MMR at negligible cost to the
algorithmic accuracy. We have further shown that
the adaptation of more relevant feature matching
techniques allows significant relative gains in
accuracy. The algorithm has been tested on a
publically available database of car frontal views to
enable easy comparison with existing and future
vehicle MMR algorithms.
REFERENCES
Petrović, V., Cootes, T. 2004.Analysis of features for rigid
structure vehicle type recognition. In: BMVC,
September7-9, Kingston.
Dlagnekov,L. 2005. Video-based car surveillance:
license plate make and model recognition. Masters
thesis, California University.
Zafar,I.,Edirisinghe,E.A,Acar,S. 2008.Vehicle make and
model identification in contourlet domain using
localised directional feature maps.In:Proceeding
Visualization, imaging, and Image Processing, Palma
de Mallorca, Spain, Villanueva, J.J.(eds.), ISBN 978-
0-88986-760-4, September 2008.
Lowe, D.G. 2004. Distinctive Image Features from Scale-
Invariant Keypoints. International Journal of
Computer Vision, 60(2) pp. 91-110.
Zafar, I., Edirisinghe, E.A, Acar, B. S. 2007. Vehicle
Make & Model Identification using Scale Invariant
Transforms .In: Proceeding (583) Visualization,
Imaging, and Image Processing, Palma de Mallorca,
Spain, , Villanueva, J.J.(eds), ISBN 978-0-88986-692-
8, August 2007.
Negri, P., Clady, X., Milgram, M., Poulenard, R. 2006.An
Oriented-Contour Point Based Voting Algorithm for
Vehicle Type Classification. In: Proceedings of the
18th International Conference on Pattern Recognition
pp. 574-577.
Cheung,S., and Chu,A. 2008. Make and Model
Recognition of Cars. CSE 190A Projects in Vision and
Learning, Final Report. California University
Fischler, M.A., and Bolles, R.C. 1981.Random sample
consensus: A paradigm for model fitting with
application to image analysis and automated
cartography. Communications of the ACM, 24(6)
pp.381-395.
Freund, Y., and Schapire, R. 1999. A short introduction to
boosting. Journal of Japanese Society for Artificial
Intelligence 14(5) September pp. 771–780.
Freund, Y., and Schapire, R. 1997. A decision-theoretic
generalization of on-line learning and an application
boosting. Journal of Computer and System
Sciences,55(1) August,pp.119-139.
Caprile,B. 2002.Multiple classifier systems, Springer
Berlin/Heidelberg.pp. 663-668.
Information Entropy.2008. [Internet].Available from
<http://en.wikipedia.org/wiki/Information_entropy >
[Accessed September 11 2008].
Figure 4: Matching results.
USE OF ADAPTIVE BOOSTING IN FEATURE SELECTION
FOR VEHICLE MAKE & MODEL RECOGNITION
147
