
THE CAPLA MODEL FOR MULTI-CULTURAL ADAPTATION
OF LEARNING RESOURCES FOR ALZHEIMER’S DISEASE
Nathalie Bricon-Souf and Jean-Marie Renard
CERIM, University of Lille 2, France
Keywords: e-Learning, Adaptation, Context, Pervasive computing, Ubiquitous computing, Alzheimer’s disease.
Abstract: To share medical courses about Alzheimer’s disease, used by French doctors, with Malian doctors, we have
to perform cultural adaptation of the learning resources. We present the CAPLA model for adaptation. We
introduce why cultural adaptation is indispensable to transform useful resources for France into useful
resources for Mali. We introduce the notion of variability and why we think that the explicit knowledge of
the variability is useful. We describe the typology of the variability for our medical and multi-countries e-
learning situations and how it can help to index the variability of the content of the medical courses. Then,
we use the notion of “documentarisation” and “re-documentation” issued from “socio-semantic web”
concepts to describe the collective activity of adapting a course. Using the context is still difficult and we
propose to detect the manifesting aspects of context, thanks to the variability knowledge. The Alois
Software is described, it implements the CAPLA model, it helps to annotate the variability of a course. We
show how we use the XML openDocument descriptions obtained from the presentation documents (Impress
or Powerpoint) to help people to adapt their courses: thanks to the knowledge we have on the context and
the variability, we can mark all the slides that need an adaptation and we can indicate the reason why this
adaptation is needed. Next step is to use this knowledge for pervasive and ubiquitous learning.
1 INTRODUCTION
The production of learning resources is difficult and
takes a lot of time, especially in the medical area
where the quality is mandatory and where the
knowledge evolves rapidly. Supplying everyone
around the world with high quality information is
essential. But it is also indispensable to provide
information well suited for each specific context of
use. This article presents a new approach for
redesigning and adapting medical resources to
different application domain. We focus on e-learning
for Alzheimer disease. Some neurologists from
Lille, a french city, were asked to share their courses
about Alzheimer disease, to help doctors from Mali
to dispose from numerous e-learning materials.
These courses can be shared through the French
Virtual Medical University (UMVF) which already
proposes a portal that gathers medical learning
resources from more than 30 universities (all the
universities from France and some universities from
French speaking countries). But without adaptations,
courses that are created in France would be useless.
For example as the care infrastructure is not the
same, a RMI (nuclear Magnetic Resonance Imaging)
should not be proposed in Mali as often as in France,
or as the prevalence of a disease is not the same,
clinical investigation could change. Even if the main
ideas of a course remain the same, some parts of the
course must be modified to correspond to actual
care.
The Internet provides technologies and
infrastructures for information sharing. The issue is
now to provide pertinent information which depends
on the context of use. Different axes of research deal
with the semantic of the courses. The Semantic Web
approaches as well as the use of domain ontologies
are some of the promising research areas
(Bouzeghoub, 2007). Meta descriptions of the
documents are helpful to retrieve learning resources.
The UMVF indexes the learning resources through
metadata such as author, title, and so on, as proposed
by the Dublin Core and through medical concepts
thanks to the medical thesaurus Mesh. The resource
manager workflow (Renard 2007) in the UMVF
helps authors and librarians to enter such
characteristics for each medical resources added to
the French Virtual University. It informs about the
462
Bricon-Souf N. and Renard J. (2009).
THE CAPLA MODEL FOR MULTI-CULTURAL ADAPTATION OF LEARNING RESOURCES FOR ALZHEIMER’S DISEASE.
In Proceedings of the International Conference on Health Informatics, pages 462-465
DOI: 10.5220/0001548004620465
Copyright
c
SciTePress

medical area of each course, but even if some
medical semantics is added, the granularity of the
description is still global. It is not appropriate to
adapt on the contents of the courses, taking into
account their semantic and their cultural aspects.
This issue is not faced when using other standards
for educational purpose as LOM, or SCORM. We
wanted to add some contextual indexes on the
courses, so that we can adapt the information. In
particular, cultural difference should be treated.
Moreover, if we are able firstly to provide such
indexes and secondly to capture the context of use
for the resources, we can think about ubiquitous and
pervasive learning resources, able to dynamically
adapt themselves according to the settings in which
they are used. This paper will present the CAPLA
(Contextual Adaptation and Pervasive Learning for
Alzheimer) model for adaptation. Our model is used
to index the variability of the content of medical
courses. This work is part of a French national
project called p-LearNet (pervasive Learning
Network) whose objectives are to explore the human
learning potential, in the framework of pervasive
communication and the use of Technology
Enhanced Learning (TEL). Then will briefly
describe the Alois Software which is proposed for
indexing and re-creating the courses.
2 THE CAPLA MODEL FOR
ADAPTATION
2.1 The CAPLA Needs for Adaptation
We notice there is room for a specific description of
the variability of the resources. When we move from
a context (e.g. Country=France) to another context
(e.g. Country=Mali), pertinent adaptation of the
content are often necessary. In this paper, we will
illustrate it by the “vaccum-cleaner example”: to
detect Alzheimer, during cognitive tests it is not
pertinent to propose to an individual living in the
bush in Mali to recognize a vacuum-cleaner even if a
French resource proposes to do so. The concept of
“recognize a vacuum cleaner” as “an easy task to
do” depends on culture. Introducing such a resource
in a course induces cultural variability. In fact the
need for adaptation is very frequent.
Two different notions must be distinguished.
Variability: it describes criteria which induce
change. For example, each time the notion of the
prevalence of a disease appears in a course, it
induces variability as the prevalence is not the same
everywhere; the related information can depend on a
geographic and/or epidemiological context.
Context: it describes the environment
: when,
who, where an individual is producing/using a
course are some of the obvious context knowledge.
(Example of context description: a course, written
for France, for a general practitioner, the teacher will
use it in an amphitheatre equipped with a data
projector and a PC with high speed broadband
network).
We have made the following hypothesis to
propose our model: (i)Indexing the resources with
variability could help to explicit some knowledge on
these resources (e.g. it’s interesting to notice that
"vacuum-cleaner" is not always easy to understand
according to the culture); (ii) Once a resource is
indexed with variability, it should ease the
adaptation to another context (for example, someone
from Senegal could benefit from the indexation
made for Mali); (iii) The explicit knowledge of
variability AND of context can help to propose a
smart adaptation of the courses (“vacuum cleaner”
as “culturally variable” will be changed for Mali but
not for Belgium);. (iv) pervasive learning can use
such models and be proposed as soon as we are able
to detect the context.
2.2 Variability and Courses
Re-Documentation
With the emergence of the Web2.0 applications,
documents are more and more used in collective
practice. Zacklad focuses on situations where
documents serve to coordination (Zacklad, 2006),
we use his work for our model.
Documentarisation
can be made on this course,
in our case through the annotation of the variability.
“Documentarisation consists of endowing the
substrates with specific attributes making it possible:
(i) to manage them along with other substrates, (ii)
to handle them physically, which is a prerequisite to
be able to browse semantically among the semiotic
content, and lastly, (iii) to guide not only the
recipients, but also the producers themselves to an
increasing extent, around the substrate by providing
one or several maps of the semiotic contents”
(Zacklad, 2006). It doesn’t affect the document. We
use some annotation of the variability to enrich the
knowledge we have on the semiotic content of a
document. In this paper, we focus on the specific
area of our multi-countries e-learning application but
other criteria can come from more general
knowledge. We propose a first typology for the
variability of the Alzheimer’s disease domain,
THE CAPLA MODEL FOR MULTI-CULTURAL ADAPTATION OF LEARNING RESOURCES FOR ALZHEIMER’S
DISEASE
463

thanks to different meetings with French doctors and
Malian doctors.
Invariant
: seems to be acceptable for everyone
(Everyone accepts that a great number of people
suffer from Alzheimer’s disease in the world)
Non adaptable
(Elderly people stay at home in
Mali, specific French legislation for elderly medical
houses is completely useless)
Adaptable
: in that case we found the main
following criteria justifying variability:
Environment: Epidemiology-Geography
Culture: Family or Patient-Health
Professionals - Legislation
Care: Technical environment-Availability of
medication - Infrastructure
Public: Skills -Objectives
The annotation with variability (e.g. “to use a
vacuum-cleaner depends on culture") is then seen as
a documentarisation of the document.
Redocumentarisation
allows making a new
documentarisation, the user can rearticulate the
semiotics contents according to his own
interpretation. One of the possible actions for the re
documentarisation of a course is to display it with an
easy-to-interpret representation of the variability: the
proto document.
Redocumentation
aims to rearrange the initial
document, allowing to add or to delete some parts, to
reformulate or to reorganise the document. The
objective is then to rewrite the variable parts of the
resources according to their future use.
2.3 The CAPLA Model of Context
Modelling and using context remains complex, even
in the medical domain which is said to be a good
area for context (Bricon-Souf , 2007). Lot of works
have been done around context (Dey, 2001;
Winograd, 2001). In particular, representing context
with multiple points of view has been proposed
(Kirsh-Pinheiro, 2004). Our model is able to detect
that “something is context because of the way it is
used in interpretation” as Winograd said.
We refer to Sato’s work (Sato, 2004) who proposes
the following definitions: Manifesting aspects of
context take significant roles in forming situations
for the current action; latent aspects of context
become irrelevant to the current action. Situation is a
collective condition at the scene of the interaction
that is composed of relations among variables of
conditions such as environmental states, contexts,
systems and users’ states. The analysis of the
multicultural e-learning situation allows us to
determine some main attributes for context such as
user, pedagogic activities, device and localization. In
order to detect which aspects of context are
manifest, we use the variability mentioned on the
documentarisation of the course. So, when part of
the course is tagged as “variable due to
environment”, the aspects of context which are
semantically linked with the notion of environment
become manifest. For example, if a course item
mentions a “vacuum cleaner” and is marked as
depending on the culture (cultural variability), it is
important to know if the course is used in a country
with the same culture as the one in which it has been
written : the Country aspect of context becomes
manifest. Some rules are written to express the
relations between variability and context. In the
current state of work, we use simple rules which
verify if the context of the initial course is the same
as for the future adapted course. (e.g, as the context
of “country” is manifest for the “vacuum cleaner”
we will verify if the countries are the same).
3 IMPLEMENTATION
The Alois Software is written in java, it helps people
(i) to annotate the variability of the courses; (ii) to
generate the proto-course to make the actual
adaptation of the course. The medical staffs provide
us courses in Powerpoint or openOffice presentation
format and we choose to use them through the XML
provided by the openDocument description. When
parsing such documents, we can extract enough
information about the slides to feed the Alois tool. A
MySQL database is used to index each slide of the
courses, and to manage the information about the
variability of each slide. Thanks to this database, the
variability annotation part of the tool (Figure 1)
proposes a representation of the existing slides, the
current variability annotation already provided and
proposes a user interface for the variability
annotation (java, swing).
The proto-course generation tool (Figure 2) uses
the variability information in order to generate an
openDocument with: (i) an hyperlink to the original
slide; (ii) a tag informing about the necessity of
careful examination of the slide.
HEALTHINF 2009 - International Conference on Health Informatics
464
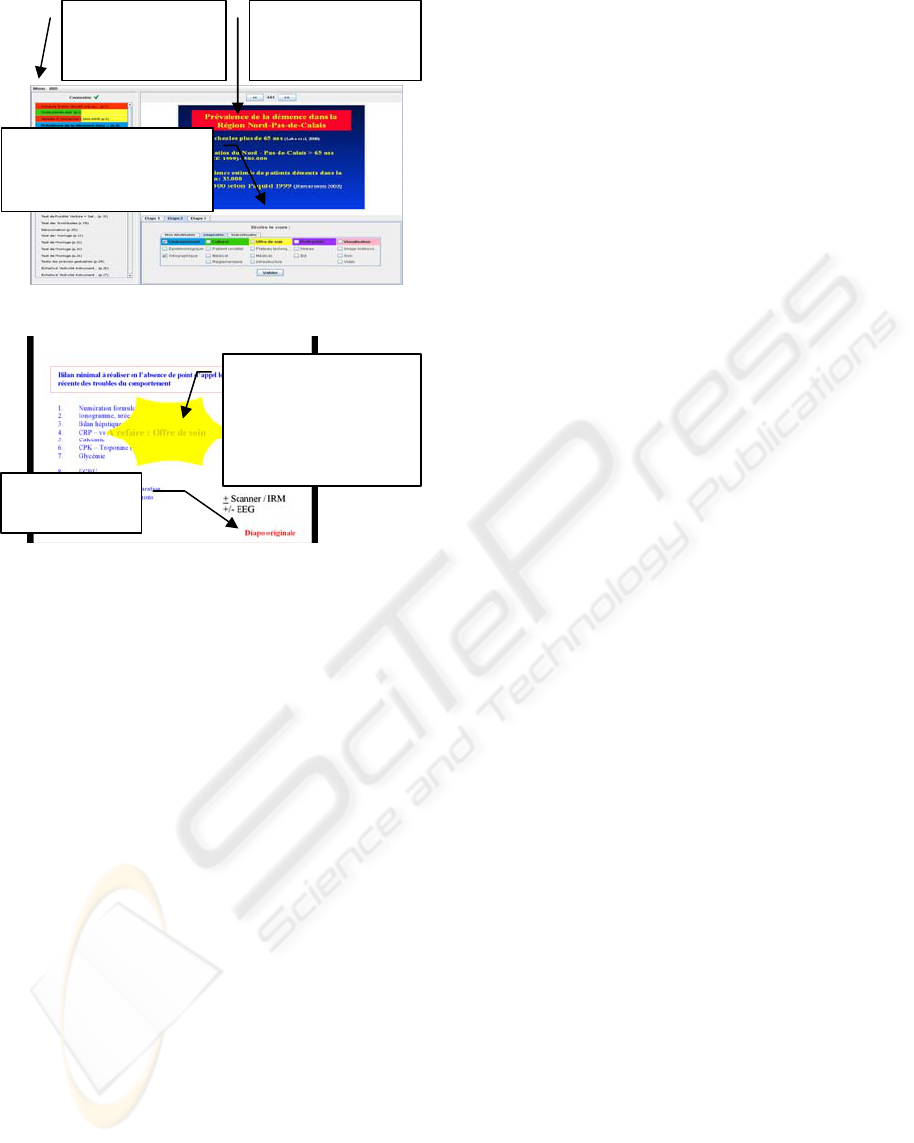
Figure 1: The Alois Tool.
Figure 2 : This slide comes from the proto-document. The
star shaped tag indicates why the author must look at this
slide (in that case: care infrastructure should differ).
4 RESULTS AND CONCLUSIONS
Based on actual need for sharing learning materials
on Alzheimer diseases, we propose a new approach
for redesigning and adapting medical resources. We
propose a model to take into account some semantic
aspects of the learning contents that are often
neglected. Using such explicit knowledge should
help the adaptation. We mainly used PowerPoint
presentations as courses and slides as items of
courses, obviously courses are not limited to this and
we will have to introduce in our model some more
complex representation of learning resources as
proposed in the literature. A Software has been
proposed, it is currently in test for some adaptation
of Alzheimer courses for Mali and for Chili.
ACKNOWLEDGEMENTS
Thanks to Pr Florence Pasquier from Lille hospital
(Neurology), as well as to Dr Cheik Guinto, GP in
Mali for their helpful discussions, comments, as well
as for their e-learning materials. The work has been
supported by the GIP UMVF and the national
research project p-LearNet .
REFERENCES
Bouzeghoub A., Do K.N. and Lecocq C., 2007.
Contextual Adaptation of Learning Resources, IADIS
International conference Mobile Learning 2007,
ISBN: 978-972-8924-36-2, p.p.41-48, Lisbonne, 5-7
Bricon-Souf N., Newman C. , 2007. Context awareness in
health care : A review Int J Med Inform. Jan;76(1):2-
12.
Dey A., Abowd G., Salber D. , 2001. A conceptual
framework and toolkit for supporting the rapid
prototyping of context-aware applications in special
issue on context_aware computing, Human computer
Interaction Journal Vol 16 (2-4), pp97-166
Kirsch-Pinheiro M., Gensel J., Martin H., 2004.
Representing Context for an Adaptative Awareness
Mechanism . CRIWG: 339-348
MESH : http://www.nlm.nih.gov/mesh/
Renard JM., Bourde A., Cuggia M., Garcelon N., Souf N.,
Darmoni S. et al. 2007. An Internet supported
workflow for the publication process in UMVF
(French Virtual Medical University) . Int J Med
Inform; 76(5-6): 363-368.
Sato, K., 2003. Context Sensitive Interactive Systems
Design : A Framework for representations of contexts,
in proceedings of the 10
th
International Conf. on Hum-
Comput Inter.. Vol3 : Human-Centered computing. 3
1323-1327
UMVF : www.umvf.org
Winograd, T., 2001. Architecture for context, Human
Computer Interaction Vol 16(2-4).
Zacklad M. 2006. Documentarisation Processes in
Documents for Action (DofA): The Status of
Annotations and Associated Cooperation
Technologies in Computer Supported Cooperative
Work (CSCW), Volume 15, Numbers 2-3, pp. 205-
228(24)
This tag indicates
the variability
reason so that it
should be remake:
“To redo : care”
Hyperlink to
ori
g
inal slide
A representation
of the original
item of course
The choice of the
criteria for the
variabilit
y
annotation
Visualization of
the encoding
already done.
THE CAPLA MODEL FOR MULTI-CULTURAL ADAPTATION OF LEARNING RESOURCES FOR ALZHEIMER’S
DISEASE
465
