
DIFFERENTIATED ACCESS TO EHRS FROM EMERGENCY
MOBILE UNITS, CONSULTING ROOMS AND HOSPITALS
Cristina De Castro, Giacomo Leonardi and Paolo Toppan
IEIIT-CNR, Italian National Research Council, V.le del Risorgimento 2, Bologna, Italy
Keywords: Anamnesis, EHRs, network connections, transmission time, data scaling, LDAP.
Abstract: In this paper, a model is proposed for the support of anamnesis through Electronic Health Records (EHRs).
These data are stored on a hybrid LDAP-SQL system, available on the Internet and accessed from
Emergency Mobile Units (EMUs), consulting rooms and hospitals. Each of such scenarios corresponds to
different network technologies, i.e. UMTS on EMUs, DSL in consulting rooms, WiFi and wired/fiber within
a hospital. Furthermore, EHRs can be queried using heterogeneous devices, such as mobiles, PDAs, laptops
and desktops. In consequence, it is important to reach the best trade-off between quality/quantity of data and
reception rate. To this purpose, this paper proposes a possible methodology for choosing, scaling and
adapting the data format (and consequently dimensions and response time) to actual necessities and
technologies at disposal. Analytical calculations are also presented showing the download time in each
scenario.
1 INTRODUCTION
An appropriate anamnesis plays a fundamental role
in many medical contexts, ranging from hospital
visiting and medical consulting to emergency
medicine. The medical history of a patient, though,
is generally neither precisely known nor simply
available.
For instance, very rarely are such data collected
together, completely stored on digital devices and
accessible by means of an integrated environment.
Conversely, the availability, effective management
and efficient access to medical histories, possibly
stored on Electronic Health Records (EHRs), could
be of great help in the decision of which treatments
the patient should undergo. This could also be useful
in order to schedule resources in the best way, so as
to provide the most serious cases with the best and
quickest aids.
In this paper, the problem of EHRs as a support
to anamnesis and release of services is faced, taking
the following factors into consideration:
EHRs can be queried from at least three distinct
locations, i.e. Emergency Mobile Units
(EMUs), consulting rooms and hospitals;
these scenarios correspond to different network
connection modalities and speeds (UMTS,
DSL, WiFi, wired/fiber), as well as available
devices (mobiles, PDAs, laptops, desktops,
etc.);
such situations lead to distinct possible ranges
of medical intervention. For instance, no
retrospective analysis of CAT scans is feasible
from EMUs (meaning it can be made in an
acceptable time), since they have low-speed
connections.
In this context of heterogeneous access
modalities, it is essential to reach the best trade-off
between quality/quantity of information and
reception rate. To this purpose, a possible approach
is here proposed to reach an efficient access to data
in each network scenario.
This paper does not claim to be anyhow rigorous
in terms of medical concepts and procedures: it
simply aims at giving a guideline for an effective
management of information, facing the problem of
EHRs in heterogeneous environments.
As a matter of fact, even though EHR systems exist
from a long time [Smaltz & Berner, 2007, Dwight et
al, 2006, Yun et al, 2005], their effective world-wide
adoption and standardization are far from being
reality. Furthermore, as long as the authors know, no
precise criteria were fixed showing how such files
should be used and optimised in order to fit different
environments and connection technologies [Heier et
237
De Castro C., Leonardi G. and Toppan P. (2009).
DIFFERENTIATED ACCESS TO EHRS FROM EMERGENCY MOBILE UNITS, CONSULTING ROOMS AND HOSPITALS.
In Proceedings of the International Conference on Health Informatics, pages 237-244
DOI: 10.5220/0001542602370244
Copyright
c
SciTePress

al, 2002, Yuang et al 1994, Bronson et al, 1993,
Caouras et al, 2003].
The main point of the suggested methodology is
the following: the amount of data actually needed
does not generally correspond to the whole
information available on EHRs, so the only essential
information must be required and uploaded,
especially if low-speed connections are used.
For instance, treating an allergic reaction can require
the history of allergies and blood tests results in text
format, whereas past X-ray examinations are of no
interest. Again, if an EMU is transporting a patient
who was injured in a car accident, it can query name
and blood group. In contrast, all X-rays and MRI
scans can be needed when treating osteoporosis in
case of hospital consulting. In this situation, all the
available data are relevant for the definition of a
correct treatment plan.
The proposed solution allows to query EHRs in a
differentiated way (text-only modality, text and
images, etc.), on the basis of the information needed,
urgency and kind of network connection at disposal.
In other words, the three scenarios depicted above
are put in correspondence with as many types of
feasible requests.
Access to EHRs is optimised using such criteria and
access to services is made accordingly.
Behind the system lies a medical database which
stores EHRs, as well as information about services,
resources and their availability.
The main architecture of the whole system is
described in Section 2; the database structure is
discussed in Section 3; Section 4 deals with the
optimisation methodology for querying EHRs and
presents analytical calculations of response time in
each situation.
2 MAIN ARCHITECTURE
As depicted in Fig. 1, two main components are
considered: the “User-System Communication
Interface” (A) and the “Hospital System” (B).
As for the first component, it acts as an interface
between the user and the system. In this context, the
word user indicates an operator (physician,
paramedic, etc.) who queries EHRs or asks for
hospital services availability. Such functionality is
represented by the “Query Layer” module.
Figure 1: Communication and Hospital System.
The second role of the Communication Interface is
to optimise the data exchange quantity and format
between end users and the system, in order to fit
different connections and actual needs. This process
is represented by the “Data Adaptation” module.
As far as the Hospital System is concerned, it is
viewed as a collection of services and data: hospital
centres put services at disposal, such as consulting,
tests, emergency surgery, etc., and users are meant
to access an (ideally) integrated database storing
EHRs, tests' results, bookings, and so on.
This approach can be described in more detail by
means of the 4-layered architecture in Fig. 2, which
is increasingly enriched from the left to the right.
The vertical axis on the left reflects the classification
in Fig. 1; on the right, all the components are
expanded and represented with respect to their
interaction and to the data flow which takes place
among them.
The main purpose and features of each block and its
sub-modules are described in the following.
2.1 Communication Interface
This component must carry out the following tasks:
collect the user’s requests;
transform them on the basis of the user’s
devices (mobile, PDAs, laptops, etc.);
optimise access to data;
forward queries to the hospital system and
manage results;
HEALTHINF 2009 - International Conference on Health Informatics
238
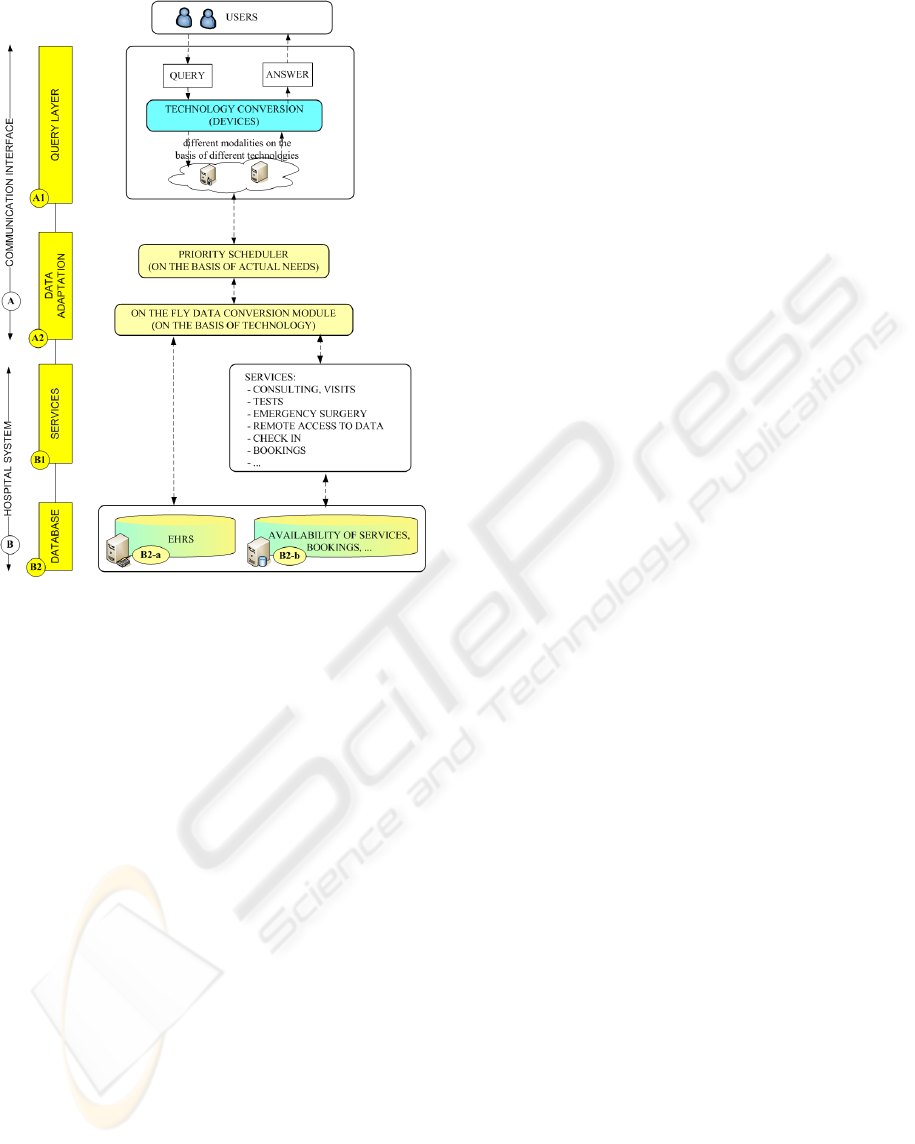
Figure 2: Main architecture.
The first two tasks concern the management of
queries and data with respect to the user’s device,
and are accomplished by the Query Layer. The last
two tasks concern data access optimisation and are
fulfilled by the Data Adaptation module.
As for the Query Layer, the problem of converting
data on the basis of available devices has not been
mentioned yet, but, when talking of data format, two
different - even not independent - operations must be
distinguished. First, data transformation due to the
type of device (data conversion on the basis of
technology, Query Layer). Second, data format
scheduling due to the type of network connection
and to the request of the only information really
needed (data adaptation on the basis of actual needs,
Data Adaptation module).
Since the system must communicate on the basis of
the user’s device, the user’s data must be converted
in a format that both the front-end to services and
the database system can understand.
This process will last the whole lifespan of the
medical assistance and can easily be done by means
of XML conversions. As a matter of fact, this is a
straightforward, general and effective way for
exchanging data between heterogeneous
environments.
As far as the Data Adaptation module is
concerned, in order to optimise response time in
each scenario, the following guidelines must be
taken into account:
data that contribute to an anamnesis have
different formats, ranging from text (e.g.:
allergies, remedies) to images (e.g.: X-rays,
CTs, etc.);
efficiency can be better achieved if physicians
themselves decide which kind of data they
really need (if simple text or images) and in
which detail (complete description, medium-
resolution images, high-resolution images,
etc.);
in the same way, the medical staff must be
aware of which data can be downloaded in a
reasonable time in each scenario;
This module requires the design of an
appropriate database schema and of an optimised
access methodology for filtering data on the basis of
actual needs and connection speed. For instance, a
consulting room will firstly download the main
medical parameters and then, if needed, some
images.
In more detail, on the basis of the user’s
scenario, the “Priority Scheduler” suggests him a
selection of data that can be downloaded in
acceptable times. According to such information,
data are accessed and returned to the “On the Fly
Data Conversion Interface”. On the basis of
connection speed, this module adapts the data
format, especially image resolution, and sends
results to the user.
A possible way for achieving such targets is the
core of Section 4.
2.2 Hospital System
As shown in Fig. 2, the Hospital System contains
both services and data.
As for data, they are mainly divided in EHRs
and data about bookings, availability of services and
so on. As far as services are concerned, the main
ones are consulting, visits, tests, emergency surgery,
remote access to data, check in, booking facilities,
check of nearest examinations' units, etc.
In this context, the focus is on the data flow
among the components of the proposed architecture.
In this representation, the database is accessed
according to the UML-like diagram in Fig. 3: the
medical staff queries the database B2-a (EHRs) by
means of the Priority Scheduler. Once the most
convenient format has been decided, such data are
DIFFERENTIATED ACCESS TO EHRS FROM EMERGENCY MOBILE UNITS, CONSULTING ROOMS AND
HOSPITALS
239
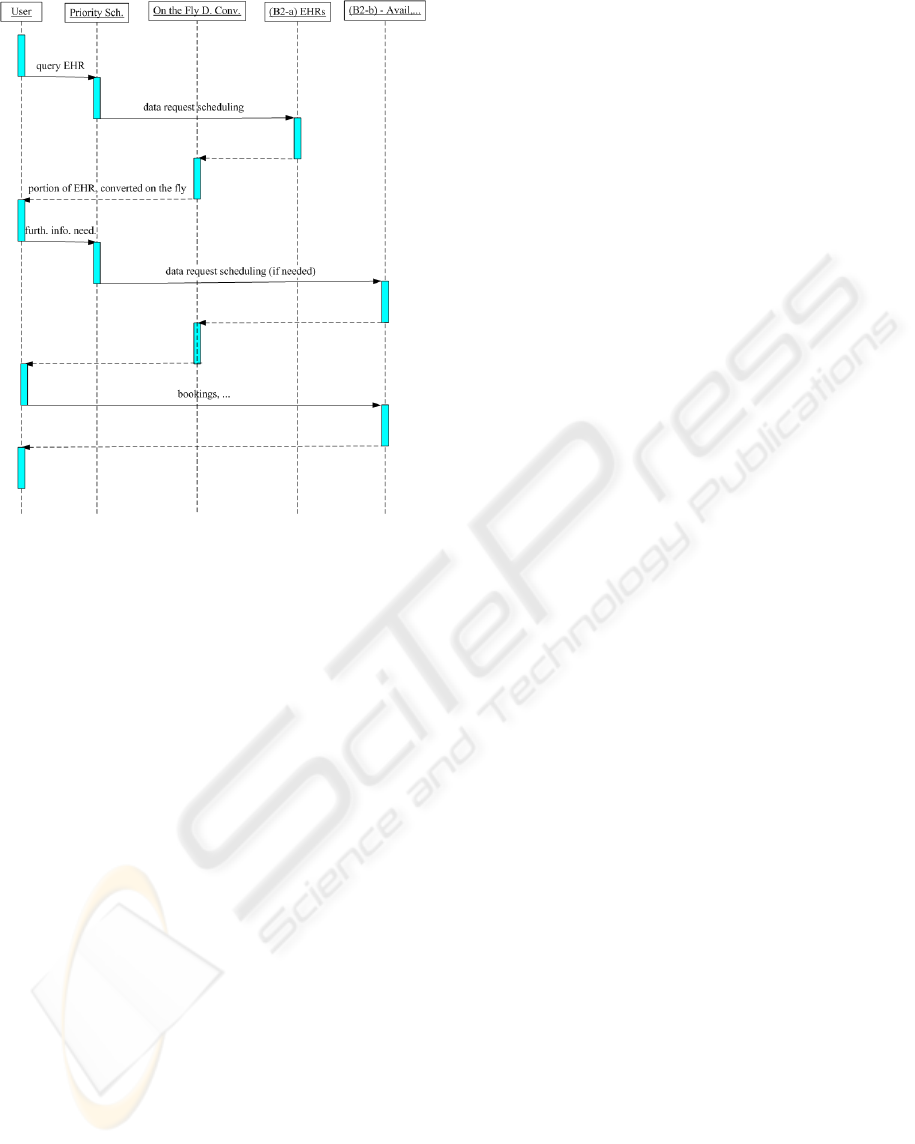
Figure 3: Data flow among modules.
processed by the On the Fly Data Conversion
Interface, scaled - in case of images - to a proper
resolution and returned to the user.
Such information helps physicians understand the
patient's anamnesis and guides the choice of further
data from EHRs or bookings, necessary tests to be
performed, etc.
This means accessing database B2-b and check
availability of services, book consultings, tests and
so on.
Once the physicians or medical staff have been
notified where and when such resources will be at
disposal, access to hospital services can be effected.
3 DATABASE SCHEMA
In this section, the following issues are faced: how
EHR are defined in the proposed model and which
systems should be adopted to develop them.
3.1 EHR Definition
Medical histories vary in depth and focus by nature.
For example, a simple checkup would require
registry data such as name and age, as well as
present conditions, pressure and blood tests. In
contrast, the history of a neoplastic pathology
involves many details about the patients’ life,
examinations, CAT scans and so on.
On the other hand, when the efficient access to data
is considered, the only information should be
queried which is really necessary and can be
received in an acceptable time.
According to these observations, EHRs should
be defined whose information is described at
different levels using different formats.
This can be done representing EHRs by means of
data of increasingly rich format (ranging from text to
images). For instance, in this approach, an X-ray
examination stores both a textual description of the
result and the X-ray image itself.
Using this kind of representation allows to meet both
requirements of actual necessity and efficiency.
In this model, an example of a possible structure
for EHRs is proposed, which includes:
demographics (data 1);
medical (data 2) and first aid (3) parameters,
such as:
examination and progress reports of
health and illnesses;
allergy lists, and immunisation status;
side-effects and interactions of remedies
used on the patient, etc.;
recommendations for specific medical
conditions; appointments, …
symptoms, diagnosis and prescribed treatments
(data 4) of past and current medical assistance.
main examinations (data 5): list (5a),
description of results in text format (5b) and
images (5c), if any, such as:
laboratory test results (blood tests, etc.);
radiology images (X-rays, CATs, MRIs,
etc.);
clinical photographs (endoscopy, etc.);
main operations (data 6): list (6a), description
of results in text format (6b) and images (6c),
if any;
In this model, images are stored with the best
resolution available and they can be queried and
downloaded at different levels of precision. In more
detail, if the medical staff reckons it sufficient or
technology does not allow a better solution, the Data
Adaptation Module scales resolution and returns
data consequently.
Another important consideration in the design of
the database schema is that information can be
classified as follows:
(i) EHRs are static data, i.e. they are not meant to
be frequently updated;
HEALTHINF 2009 - International Conference on Health Informatics
240

(ii) availability of services, bookings, etc. are
dynamic data, i.e. they are time-varying by
nature;
3.2 Database Layer: the Hybrid LDAP-
SQL System
These requirements suggest the use of a hybrid
database structure for data storage: an LDAP
directory service [Yeong et al, 1995, Howes et al,
2003, Kandlur et al, 1998] for static data and a
relational DBMS for dynamic information.
LDAP (Lightweight Directory Access Protocol)
provides both a modelling and an implementation
tool, it is used in a wide number of applications,
including enterprise databases and network
configuration. LDAP is highly indicated for Internet
applications, both from the data representation
viewpoint and for an efficient access. Furthermore, it
is scalable, extendable and optimised for reading
operations, so it is particularly suitable for static
data. It also supports standards and interfaces of
many multimedia broadband applications, as well as
integrated access to services.
Another important feature is that the LDAP data
model uses a hierarchy of classes, each class
described by single-valued or multi-valued
attributes. This tree structure allows to organise and
navigate data in a very efficient, simple and user-
friendly way. Furthermore, LDAP schemes can be
very easily modified and extended in order to add
new attributes and new classes. Such operations, in
contrast, would be very time-consuming if
traditional database systems were used.
This feature can be very useful when designing
EHRs: as a matter of fact, new objects and new
attributes are very likely to be modified or added,
due to new needs, experiences or improvements
made by the people who are developing them.
Finally, LDAP was built for the integration of
distributed environments, so it suits the distributed
location of medical material and patients’ histories
very well.
As far as the dynamic part of the database is
concerned, it mainly concerns the time-varying
information. In more detail, the dynamic database
stores data about services, their scheduling,
bookings, etc. In this case, an SQL database is more
suitable. As a matter of fact, such models are
optimised for reading/writing operations and time-
varying data. The connection between the LDAP
and the SQL databases are LDAP object identifiers
which, used as user identifiers, guide the joint
navigation of LDAP and SQL data.
3.3 LDAP Schema for EHRs
The approach sketched in 3.1 can be formalised by
means of the LDAP tree structure in Fig. 4, where an
EHR is defined by means of the following hierarchy.
The 0-level class describes the EHR in general and
addresses all its items, such as different
examinations. This class stores the EHR identifier,
the data source of each item (e.g.: the database of
another hospital from which an examination comes
from) and dimension of the component in KB (e.g.:
dimension of an X-ray image).
The 1-level classes are demographics and
medical data.
The former stores the patient’s name, contacts and
similar data.
The latter is defined by the following attributes: type
of data, description, date, physician, paramedic,
technician. A possible instance is: (examination,
chest X-ray, June 24
th
2008, Dr Robert Hill, --, Mr
John Green), meaning that the information concerns
a chest X-ray examination made on June 24
th
2008,
prescribed by Dr Robert Hill and made by the
technician Mr John Green.
The medical data class has as many subclasses as
the types of medical information in EHRs. In
particular: medical parameters, such as blood group;
first aid parameters, such as the list of allergies; data
about past and current assistance, such as symptoms,
diagnosis and prescriptions.
Further subclasses are examinations and operation,
here represented as a single class. By means of the
subclasses text result and images, results of
examinations and operations are stored in text
format and images, if available.
For instance, the examination class, which inherits
all the attributes of the parent classes, has two
subclasses text results and image result. Possible
instances of such subclasses are (fracture of the first
and second ribs) and the available images
respectively. A further subclass other was defined in
case other data were needed.
3.4 SQL Schema for Accessing Services
Even if this issue is not the focus of the work, the
main objects that must be represented in the
dynamical part of the database are services, their
availability and their booking. Roughly speaking,
this means representing four classes of information:
DIFFERENTIATED ACCESS TO EHRS FROM EMERGENCY MOBILE UNITS, CONSULTING ROOMS AND
HOSPITALS
241

Figure 4: proposed LDAP structure for EHRs.
patients, medical staff, services at disposal and
relationships among them. Data concerning people
are stored in the LDAP tree and are meant to be
retrieved from it using LDAP identifiers.
At least two main tables must be defined: Services
(service_id, service_name, description, …),
Bookings(patient_id, physician_id, service_id, date,
time,…), where patient_id and physician_id
correspond to patients (EHRs) and physicians within
the LDAP tree.
4 PRIORITY SCHEDULER AND
ANALYTICAL CALCULATIONS
Coming back to optimisation, let us consider again
the Data Adaptation block in Fig. 2, as reported in
Fig. 5. The “Priority Scheduler” suggests the user a
feasible selection of data he can download. The “On
the Fly Data Conversion Module” adapts the image
resolution to the network connection at disposal, and
returns data accordingly.
Figure 5: Data Adaptation Module.
A model is now described which guides the
differentiated access to EHRs on the basis of these
factors: (a) scenario, meaning connection speed; (b)
data types and their dimensions; (c) order in which
data are required in each scenario.
As for connection speed, four situations are
considered, where EHRs are accessed through
different technologies (Tab. 1). In this context,
download speed should be more properly called
goodput, i.e. throughput at application level.
Table 1: Scenarios and connection speeds.
Scenario Technology Download
speed
EMUs UMTS 200 Kbps
consulting
rooms
DSL 2.6 Mbps
hospitals wired/fiber 60 Mbps
physicians
moving
within the
hospital
WiFi 8 Mbps
As for the data types and dimensions fixed in this
model, they are summed up in Tab. 2, where images
at different resolution are also considered. As a
matter of fact, EHRs store images with the best
resolution available, but, if the medical staff judges
it sufficient, they can be queried and downloaded at
different levels of precision.
Identifiers 5c_high, 5c_med and 5c_low in Tab. 2
indicate images of type 5c at high, medium and low
resolution respectively, and 6c_high, 6c_med and
6c_low represent 6c.
Table 2: Dimensions in KB of data in EHRs.
Identifiers Data Dim(KB)
1 demographics 100
2 medical parameters 300
3 first aid parameters 200
4 symptoms, diagnos.,.. 1000
5a list of examinations 200
5b results (in text format) 500
5c_high image of ex. (each) 600000
5c_med image of ex. (each) 300000
5c_low image of ex. (each) 100000
6a list of operations 200
6b results (in text format) 500
6c_high image of op. (each) 600000
6c_med image of op. (each) 300000
6c_low image of op. (each) 100000
Factor (c) is the key to an optimised access to
EHRs: as a matter of fact, on the basis of urgency
HEALTHINF 2009 - International Conference on Health Informatics
242
and connection speed, the medical staff is assumed
to query data in different quantity and order.
The download priority in Tab. 3 is supposed to
be obeyed. Medical data are enumerated as in Tab.
2: 3 represents first aid parameters, etc.
EMUs (with UMTS) are expected to require first
aid and medical parameters before any other
information. Furthermore, using a low-speed
technology, they are supposed to be aware they
would not receive images in an acceptable time.
This is why the download priority in Tab. 1 is 3, 2,
1, 5a (first aid parameters, medical parameters,
demographics, list of examinations and results in
text format respectively).
Table 3: Download priority on the basis of connection.
Scenario Download order
EMUs 3, 2, 1, 5a, 6a
consulting
rooms
1, 2, 3, 4, 5a, 5b, 5c_low
hospitals 1- 4, 5a, 5b, 6a, 6b, 4x5c_high,
4x6c_high
physicians
moving
within the
hospital
1- 4, 5a, 6a, 2x5c_med
If consulting rooms (with DSL connection) are
considered, some images - even not extremely
detailed – can be downloaded. In this context, a
physician does not generally need to receive
information with extreme urgency, so, beside all the
data 1-6a in text format, he can query an image at
medium resolution (5c_med), or wait for further
ones.
In hospitals (with wired/fiber connection, the
fastest possible), the whole EHR can be
downloaded. A physician moving within the hospital
with his laptop can use a WiFi connection, faster
than a DSL and much slower than a wired/fiber. In
this case, he downloads all the textual data and some
images at medium resolution.
4.1 Numerical Results
The considerations above are formalised in Figg. 6-
9, which show respectively the download time in the
four scenarios.
The information is supposed to be downloaded
progressively, as indicated in Tab. 3. The x-axis
represents download time, the y-axis represents the
amount of information.
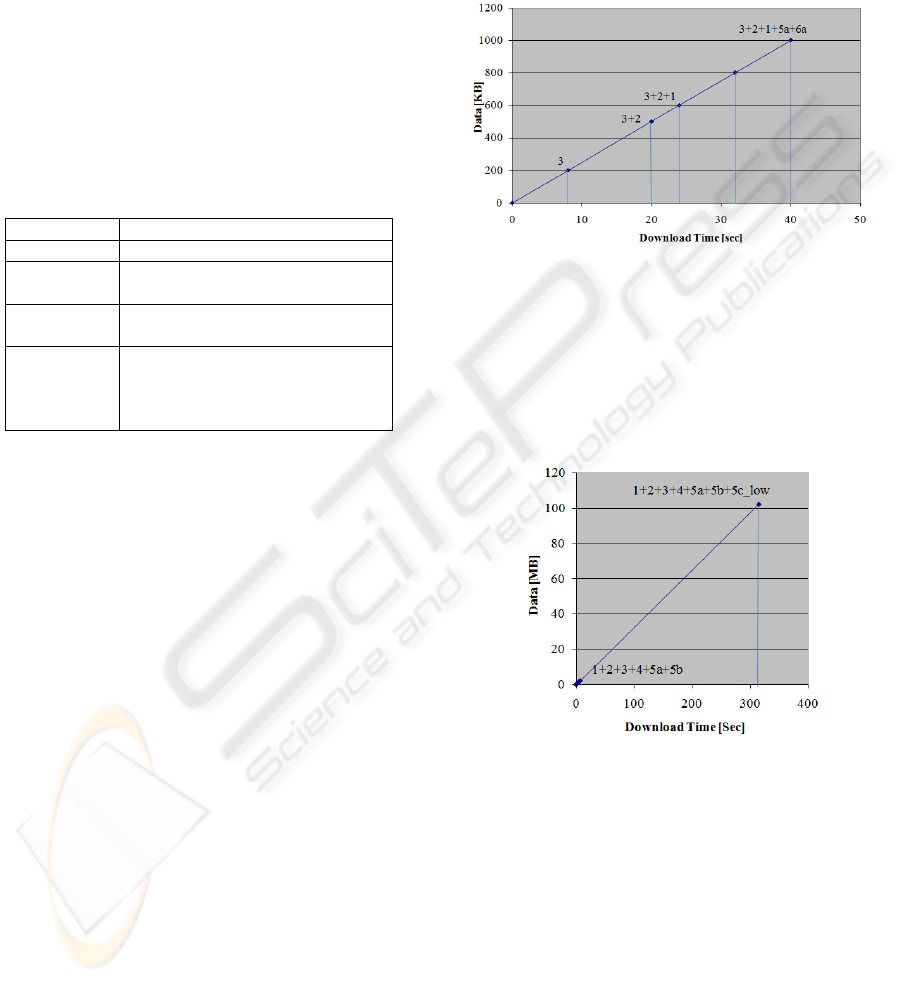
As for EMUs (Fig. 6), first aid parameters (3 in
Tab. 3) can be at disposal in 8 seconds; if further
medical parameters (2) and demographics (1) are
also requested, 24 seconds are necessary. The list of
examinations and operations (5a and 6a) will require
further 16 seconds. Downloading an image – even a
low resolution one – would require more than 60
minutes.
Figure 6: Download time on EMUs (UMTS technology).
As for consulting rooms (Fig. 7), downloading
demographics, medical and first aid parameters,
symptoms and diagnosis, lists of examinations and
results in text format (1-4+5a+5b) requires 7
seconds, but, if an image at low resolution is
requested, more than 5 minutes will be necessary.
Figure 7: Download time in consulting rooms (DSL).
If a wired/fiber connection is used within a
hospital (Fig. 8), the whole EHR can be downloaded
in a few minutes. All the data in text format,
including examinations, operations and descriptions
of results can be available in less than one second;
an image at high resolution in 80 seconds; further
images 80 seconds each.
If a WiFi connection is used by a physician
moving within a hospital (Fig. 9), it takes less than a
second to download the main parameters,
demographics and the list of examinations and
operations, and 300 more seconds for each medium-
resolution image.
DIFFERENTIATED ACCESS TO EHRS FROM EMERGENCY MOBILE UNITS, CONSULTING ROOMS AND
HOSPITALS
243
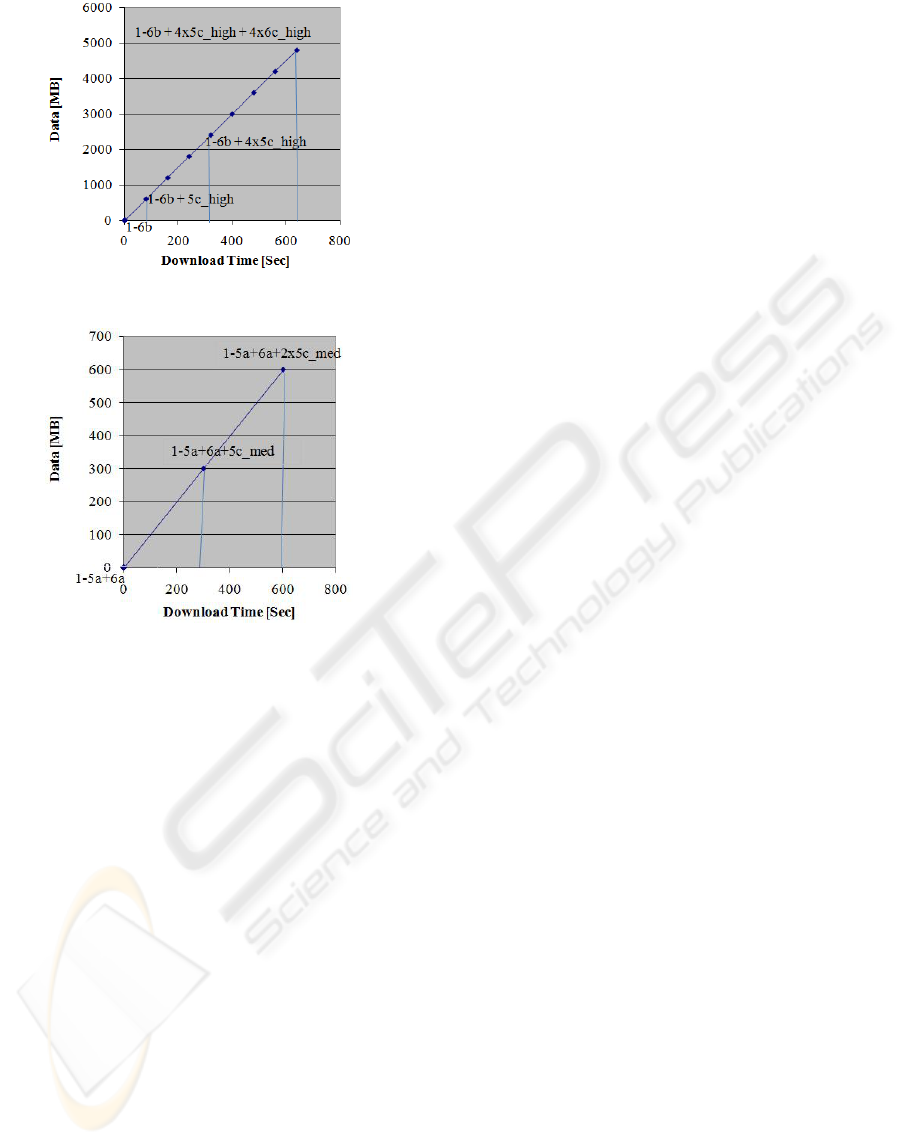
Figure 8: Download time in hospitals (wired/fiber).
Figure 9: download time in hospitals (WiFi).
5 CONCLUSIONS
In this paper, a possible approach to EHR utilisation
was proposed, based on the location from where data
are accessed and the kind of use.
In particular, a selective access to a EHR was
suggested, based on three degrees of detail of
information: textual data; results in text format
(descriptions); results by means of images at
different resolution.
Computations were also presented which should
guide the medical staff in the choice of the priority
of information that can be feasibly downloaded or
not.
Further work will be devoted to the design of a
complete environment for a simulation.
REFERENCES
Evans, D. C., Nichol, W. P., & Perlin, J. B., 2006. Effect
of the implementation of an enterprise-wide Electronic
Health Record on productivity in the Veterans Health
Administration, Health Economics, Policy and Law, 1,
163-169, Cambridge University Press.
Smaltz, D. H., & Berner, E. S., 2007. The Executive's
Guide to Electronic Health Records, Health
Administration Press.
Yun, H.Y., Yoo, S.K., & Kim, D.K., 2005. Performance
Evaluation of Telemedicine System based on
multicasting over Heterogeneous Network,
Engineering in Medicine and Biology Society IEEE-
EMBS 2005. 27th Annual International Conference of
the, 2175 – 2177.
Heier, S., Heinrichs, D., & Kemper, A., 2002.
Performance evaluation of Internet applications over
the UMTS radio interface, Vehicular Technology
Conference, IEEE VTC 2002, 4,1834-1838.
Yuang, M.C., & Hsu, S.J., 1994. LAN protocol modelling
and performance evaluation, Communications, ICC
94, SUPERCOMM/ICC '94, IEEE International
Conference on Serving Humanity Through
Communications, 2, 685 - 689.
Bronson, G., Pahlavan, K., & Rotithor, H., 1993.
Performance evaluation of wireless LANs in the
indoor environment, 18th Conference on Local
Computer Networks, 1993, 452 – 460.
Caouras, N., Freda, M., Monfet, F., Aldea, V.S., Naeem,
O., Tho L., & Champagne, B., 2003. Performance
evaluation platform for xDSL deployment in a
complex multi-segment environment, Canadian
Conference on Electrical and Computer Engineering,
2003. IEEE CCECE 2003, 1, 61 – 64.
Howes, T., Smith M., & Good G., (2003). Understanding
and Deploying LDAP Directory Services, Addison
Wesley 2003, 2^ ed.
Kandlur, D., H. Schulzrine, H., Verma, D., & Wang, X.,
1998. Measurement and Analysis of LDAP
Performance, Network Systems Department - IBM
T.J. Watson Research Center.
HEALTHINF 2009 - International Conference on Health Informatics
244
