
Describing the Where – Improving Image Annotation and
Search through Geography
Ross S. Purves, Alistair Edwardes and Mark Sanderson
Department of Geography, University of Zurich, Suiss
Department of Information Science, University of Sheffield, UK
Abstract. Image retrieval, using either content or text-based techniques, does
not match up to the current quality of standard text retrieval. One possible
reason for this mismatch is the semantic gap – the terms by which images are
indexed do not accord with those imagined by users querying image databases.
In this paper we set out to describe how geography might help to index the
where facet of the Pansofsky-Shatford matrix, which has previously been
shown to accord well with the types of queries users make. We illustrate these
ideas with existing (e.g. identifying place names associated with a set of
coordinates) and novel (e.g. describing images using land cover data)
techniques to describe images and contend that such methods will become
central as increasing numbers of images become georeferenced.
1 Introduction and Motivation
1.1 Image Retrieval and the Semantic Gap
The performance of image retrieval systems is currently recognized as lagging behind
that of text retrieval in terms of both the quality of the results returned for individual
queries and the overall ubiquitousness of image retrieval techniques as a first port of
call for search for a particular illustration [11]. The two main approaches to image
retrieval – content-based image retrieval (CBIR) and retrieval of images based on text
surrogates [13] have significant limitations. In general, CBIR techniques work best
within domains where the expected structures and forms of the images are limited, for
example in the retrieval of medical images [7]. However, at the time of writing, CBIR
is not in a state where it can be applied to large collections of what might be termed
“general photographs”, such as those typically held in large stock image collections.
Text-based image retrieval (TBIR) is predicated on the use of appropriate terms to
describe an image. These terms can be drawn from a range of possible sources,
including terms freely chosen by indexers [1]; terms selected by indexers from some
controlled keyword list and text thought to be related to the content of an image (e.g.
figure captions or filenames associated with images embedded in documents).
Although in principle images annotated in such a way are amenable to identical
approaches to those applied in full text document search, the quality of TBIR is
handicapped by the quality of the annotation. This appears to be primarily due to the
relative sparseness of the description of an image, which will tend to be based on the
S. Purves R., Edwardes A. and Sanderson M. (2008).
Describing the Where – Improving Image Annotation and Search through Geography.
In Metadata Mining for Image Understanding, pages 105-114
DOI: 10.5220/0002338401050114
Copyright
c
SciTePress

purpose for which the image itself was being indexed and the cultural background of
the indexer. This in turn means that image search requires that users are, for example,
familiar with the controlled keyword lists used to describe images or that they have
similar backgrounds and expectations to those describing images with free text. A
similar mismatch between user expectations and indexing methods has been identified
in the context of CBIR, where it is termed the semantic gap. Smeulders et al. [24]
defined this gap as follows:
“…the lack of coincidence between the information that one can extract from the
visual data and the interpretation that the same data have for a user in a given
situation.” (p.1353)
In effect, the key problem with image search is centered on this mismatch between
the data describing content and the expectations of those searching for content. In
contrast to document search, both CBIR and TBIR index images using proxies for
content, which it is hoped will describe the images indexed as fully as possible. Thus,
a key challenge in image retrieval must be to develop methods which will describe
images in as universal and rich a way as possible, in order to bridge this semantic gap.
1.2 Describing Images
Clearly, if we wish to describe images universally, we must first formalize the ways
in which images may be described. Shatford [21] set out to do exactly this, refining
the work of Pansofsky to develop the Pansofsky-Shatford facet matrix (Table 1). This
matrix contains three levels, termed the specific of, the generic of and about. Each of
these levels has four associated facets: who, what, where and when. We will term
individual entries in the matrix (e.g. “who/specific of”) as elements.
Table 1. The Pansofsky-Shatford facet matrix (Shatford [21], p. 49).
Facets
Specific Of Generic Of About
Who?
Individually named
persons, animals, things
Kinds of persons,
animals, things
Mythical beings, abstraction
manifested or symbolised by
objects or beings
What? Individually named events Actions, conditions
Emotions, abstractions
manifested by actions
Where?
Individually named
geographic locations
Kind of place
geographic or
architectural
Places symbolised, abstractions
manifest by locale
When?
Linear time; dates or
periods
Cyclical time;
seasons, time of day
Emotions or abstraction
symbolised by or manifest by
The Pansofsky-Shatford matrix has been extensively used in information science,
particularly in the classification of image queries. For example, Armitage and Enser
[3] examined queries posed to a number of image libraries, and allocated each query
to one or more elements of the matrix (e.g. the query “Churchill’s funeral” is
allocated to the “specific of/ what” element). Armitage and Enser demonstrated that
both the “specific of” and “generic of” levels were commonly used in queries
submitted to image archives, whilst those represented by the more abstract “about”
level were rarely identified.
106106

The matrix suggests a variety of ways in which images might be queried or
indexed. For example, CBIR techniques capable of face recognition [27] might allow
us to annotate the “specific of/ who” element (a picture of Jim), whilst CBIR
techniques capable of face spotting [30] would allow annotation of the “generic of/
who” element (a picture of some people). Moreover, the matrix also suggests how
proxy data might be profitably be used to help us describe images – for instance use
of a time-stamp and location associated with an image and a local almanac would
allow generation of annotation related to the “generic of/ when” (a picture at night).
Such tools, taking account of ancillary information to annotate images have been
developed as part of, for example, the MediAssist and NameSet projects [21, 20, 19].
The where facet is, we would argue, particularly interesting and relevant to image
annotation for a number of reasons. Firstly, previous studies have shown that location
is an important element in both indexing and searching for images (e.g. [3]).
Secondly, the volume and content of spatial data describing the semantics of locations
has grown exponentially in recent years, providing a wide variety of potential sources
of ancillary data to describe the where facet. Thirdly, and crucially, images
increasingly carry information related to where within metadata created at the time of
capture, storing at a minimum a set of image coordinates, but potentially also
information about the camera’s orientation (azimuth, pitch and roll).
In this paper we aim to briefly introduce ideas from existing work on the notion of
place from a geographic perspective, which provides a potential theoretical
framework in considering how location can be used to annotate images. We then
explore existing work from a variety of research areas which has attempted to
described locations and introduce ongoing research within the European Project
Tripod which aims specifically to describe images through their location. All of this
research is positioned within the framework of the where facet of the Pansofsky-
Shatford matrix which we contend, together with an understanding of place, will
allow us to address challenge of developing methods to richly and universally
describe images.
2 Geographic Perspectives on Place
The explosion of devices which are location aware and of resources which contain
references to location has led to a wide variety of research in, for example, Location-
Based Services and Geographic Information Retrieval. In general, much of this
research has been dominated by researchers from computing, information and
geographic information science and has paid relatively little attention to more
theoretical work deriving mainly from human geography. This has in turn, led to a
conflation of terminology with location, place and space being used interchangeably
by many researchers and generally being considered to be represented by the
assignment of a set of geometric coordinates or a toponym
1
to a resource.
However, in geography place is considered to lie at one end of a continuum of
viewpoints with the other extreme being space. Place relates geography to human
existence, experiences and interaction and therefore cannot be considered as purely an
1
Toponyms are names allocated to some location on the Earth’s surface
107107

abstract property of a set of geometric coordinates [9]. Space on the other hand
encompasses a more abstract and objective geometric view of the world, such as is
typically encoded in spatial data stored in computers. Thus a key challenge in
describing images is to include not only the objective and geometric notion of space
but also the more subjective and potentially everyday idea of place.
3 Methods to Describe Where
We set out here to consider a range of methods to achieve our aim of describing both
space and place, and consider how these methods can be positioned within the
Pansofsky-Shatford matrix. These methods can be considered to be a means of
addressing many of the issues set out by Egenhofer in his discussion of a semantic
geospatial web [7].
3.1 Methods to Describe “Where/ Specific of”
“Where/ specific of” is characterized in the Pansofsky-Shatford matrix as the use of
terms describing “individually named geographic locations”. Thus, a caption which
associates a toponym with an image (e.g. “A church in Bristol” can be considered to
be describing this matrix element. An initial challenge in deriving image metadata
from geographic information is therefore simply to find the most appropriate toponym
to describe an image. This task at first seems trivial, requiring a database lookup to
identify the nearest place name from a gazetteer
2
and applying the selected toponym
to the image. However, typical gazetteer data will include objects of widely varying
granularities (varying from individual houses to the centroids of large administrative
regions) and representing very different feature types (from mountain summits to the
names of individual pubs). Research on salience in navigation, that is to say
perceptually or cognitively prominent objects, has an important role to play in
deciding which toponym is most appropriate in the labeling of an image. However, to
date most research in this area has focused on objects of similar, relatively fine
granularities which are appropriate to navigational systems.
Naaman et al.[20] took the problem of identifying appropriate toponyms to
describe images one step further, and asked the question, “given a set of diverse
geographic coordinates, find a textual name that describes them best”. Their system,
NameSet, identified appropriate toponyms from a polygon-based dataset by testing
for containment within regions such as cities and parks and nearby cities. They
included a proxy for salience by using what they termed the “Google count” (number
of documents in Google that match a query word) and the population for individual
city names to weight distances, allowing locations with larger populations and higher
Google counts to have a larger zone of influence.
Typically when we describe locations we do so with qualifiers which represent the
spatial relationship between the object of interest and the referencing toponym. These
spatial relationships may be metric (10 km from Edinburgh), directional (north of
2
A gazetteer is a dictionary of toponyms, usually with associated coordinates and a hierarchy of related
toponyms
108108

Berlin), topological (in Belgium) or vague (near Bern). In practice, combinations of
spatial relationships in natural language are used to reduce ambiguity and refine
information (e.g. 10 km east of Edinburgh on the A1 road). Representing metric
spatial relationships is straightforward and was implemented in the NameSet
prototype [20]. However, the representation of vague spatial relationships is less
trivial and requires development of both computational techniques to represent and
process vagueness and empirical research to identify how people use spatial
relationships [29].
Typically, in everyday language we commonly use vernacular names which are
not found in gazetteers and whose spatial extent is ill-defined [18]. This problem has
been recognized by those working on administrative gazetteers as a pressing issue
[14]. Recent research has used datamining techniques to identify toponyms with
entries in gazetteers which co-occur with known vernacular names and to define
potential spatial extents related to vernacular names [16]. However, most work has so
far addressed relatively large regions (such as Mid-Wales or the South of France),
though work is currently ongoing on the automated identification and definition of
vernacular names with finer granularities [22]. The techniques so far developed have
not reached a level of accuracy such that they can be used to automatically generate
appropriate vernacular names for any given set of coordinates, and also do not address
the issue of identifying vernacular names.
3.2 Methods to Describe “Where/ Generic of”
The “where/generic of” element of the Pansofsky-Shatford matrix is characterized as
representing “kinds of geographic place or architecture”. The first task in defining
this element is therefore to understand what “kinds of geographic place or
architecture” are, before we consider how we can develop techniques to annotate
images.
A logical first step is to identify basic levels of geographic kinds – that is to say
informative exemplars which particularly characterize a geographic scene in terms of,
for example, typical attributes, types of related activities and component parts [28].
Within geography, previous research has examined the terms most commonly used as
basic levels in empirical experiments by asking subjects to give exemplars of natural
earth formations, with a number of researchers finding that “mountain” was a
particularly popular term [4, 26]. The advent of large volunteered datasets as part of
Web 2.0 gives rise to a new sources of data for investigating such questions. We have
been experimenting with data obtained from Geograph (www.geograph.org.uk), a
project with the aim to collect “geographically representative photographs and
information for every square kilometer of the UK and the Republic of Ireland.” The
project allows contributors to submit photographs representing individual 1km grid
squares, and after moderation these images are uploaded together with descriptions to
a publicly available web site. Using these data, we have identified the most commonly
given terms from a set of basic levels derived from earlier empirical research [8].
Table 2 illustrates the top 20 nouns identified in the Geograph data, together with
their frequencies in the collection. Here, we assume that a reference to a road, whilst
possibly naming a specific location (e.g. “London Road”) is also, in most cases, likely
109109
to illustrate a generic example of the matrix element. Further work will be necessary
to test this assumption.
Table 2. Most common terms occurring in Geograph and their frequencies.
45768 road
21119 farm
17242 lane
16232 hill
16157 church
15815 bridge
14737 river
14150 square
13690 house
12707 village
9892 railway
9829 building
9327 centre
9240 park
9234 footpath
9060 line
8563 valley
8532 station
8416 way
8331 track
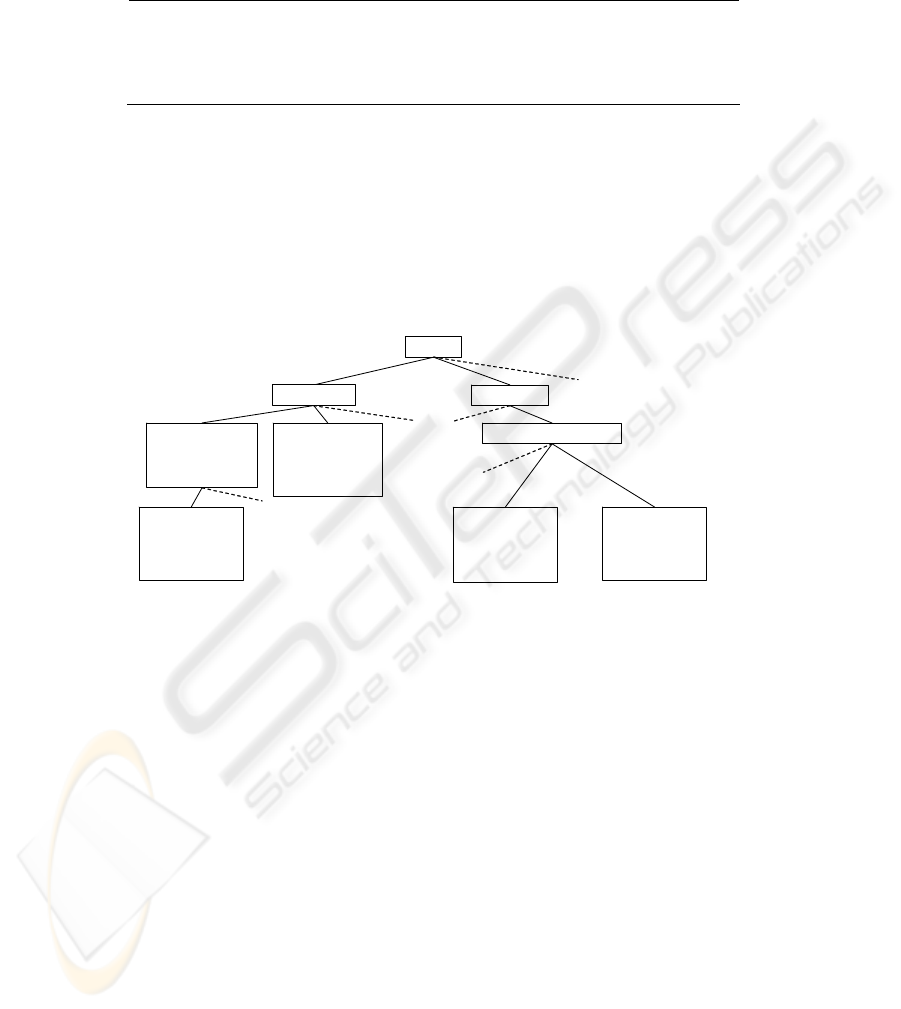
Within the Tripod project, we are currently developing an ontology of scene types
together with their relationships, qualities, elements and related activities through a
three-pronged approach utilizing analysis of existing datasets such as Geograph,
empirical experiments where subjects are asked to describe images and a literature
study of previous work from a diverse range of fields ranging from landscape
architecture through psychology to remote sensing in order to explore how landscapes
are classified and described. This concept ontology can be seen as a description of the
“where/ generic of” and is illustrated in Fig. 1 for land cover and landforms.
Conce
p
t
Land cover Landforms
Agricultural land
crops
farmland
agriculture
Forest
plantation
wood
woods
…
Arable land
field
fields
wheat
…
To
p
o
g
ra
p
hic eminences
Mountains
beinn
mountain
sgurr
....
Hills
hill
down
cnoc
....
Fig. 1. Excerpt from a concept ontology – dashed lines indicate that other concepts exist at this
level, and indented terms were identified in Geograph.
Our working hypothesis is that using such a concept ontology, it will be possible to
develop methods which exploit spatial data to describe “where/ generic of”. This
hypothesis can be illustrated through two examples, one exploring the identification
of land cover and land forms.
Land cover is typically described in spatial data which ensure that every location is
allocated a single land cover value. Within Europe, the CORINE project has produced
a dataset describing land cover for 12 countries at a nominal scale of 1:100000, with a
resolution of 100m. CORINE has 3 levels of description, a top level with 5 classes, an
intermediate level with 15 classes and a detailed level with 44 classes. Given either a
point location, or a bounding box it is possible to retrieve the associated land cover
classes with this location. Fig. 2 shows a set of georeferenced images taken in
Peloponnes, Greece and the land cover classes associated with the point locations of
these images. In these 3 cases, it can be seen that the land cover classes describe, to
different degrees, the content of the image. The third image which lies in coniferous
forest clearly illustrates some of the challenges of this approach. Firstly, the position
110110

of the photographer is different from that which was photographed and the
photographer’s location may not reflect the image contents. Secondly, this image
contains two dominant land covers – natural grassland and coniferous forest, and a
method purely based on associating a point with a land cover cannot represent
multiple land covers. Thirdly, this simple approach does not consider errors either in
GPS position or classification and the likely cumulative error in the associated land
cover. The first picture illustrates a further problem – CORINE has a resolution of
100m and an associated scale of 1:100000 – therefore close-up images of objects such
as this fallen tree are not represented.
Fig. 2. Comparing Corine landcover classes with images from georeferenced images
Peloponnes, Greece.
To assess more quantitatively whether this approach can represent the “where/
generic of” we carried out a preliminary study to rate the accordance of land cover
classes with images for 225 georeferenced images from Greece, Italy and the
Netherlands. For the top level descriptions (5 classes), we found that 73% of land
cover classes had a good or fair accordance with the images whilst for the detailed
descriptions (44 classes) 47% of land cover classes had a good or fair accordance with
the images.
Although data sets describing land cover at a European scale exist, this is not the
case for land forms (e.g. mountains, valleys, plains, etc). Research to, for example,
answer the question “Which locations within this region can we delineate as
mountains?” has investigated “mountainousness” through empirical studies [25],
methods which seek to delineate features using digital elevation models (DEM)
3
[15]
and methods which recognize that the scale at which one observes the surface of the
earth influences the nature of the features that can be identified [12]. At the simplest
level it is possible to assign an image whose coordinates lie at the peak of a mountain
3
A Digital Elevation Model (DEM) is a regular, usually gridded, tessellation of space where each grid cell
represents a single height value. Attributes of topography such as gradient and aspect can easily be
derived from DEMs)
111111

(and thus are near to a toponym representing an object belonging to the feature class
mountain) to the class mountain. However, at what point do we move from being on a
mountain to being in a valley? Research to investigate this issue must consider
perceived properties of mountains from a particular viewpoint and aim to provide a
probability function describing the extent to which a location belongs to the class
mountain for a set of users with a particular background.
3.3 Methods to Describe “Where/ About”
The “where/about” element of the Pansofsky-Shatford matrix is described as
representing “places symbolized, abstractions manifest by locale”. In their analysis of
queries submitted to image libraries Armitage and Enser [3] found that the abstract
facet in general was a rarely used query form. However, they emphasized that this
result is probably related to the nature of the image archives studied, and suggested
that for stock-photo libraries providing images to, for example, advertising agencies,
abstract concepts, such as “peaceful scenes”, are important. Such qualities are good
examples of abstract properties of place and also relate closely to the geographic
notion of place as being related to experience and interaction.
Although at first glance it may appear unlikely to be possible to describe such
qualities using spatial data, there are in fact a number of examples of research to
define such qualities. For instance, a recent study in the UK has, through participative
research, firstly explored what tranquility is, and secondly attempted to map variation
in tranquility within the UK [17]. Other, similar studies have explored how qualities
such as wilderness can be modeled in space [5]. A common factor of such research is
that locations are placed on a continuous scale describing some relative quality, but
that the identification of a location as being, for instance, tranquil is dependent on the
perceptions and experiences of those who visit a location.
We have attempted to explore abstract qualities of locations which might describe
the notion of place by investigating the co-occurrence of adjectives commonly used to
describe landscapes [6] with typical classes which we have identified in our concept
ontology (Fig 1.). For example, the following 10 adjectives were mostly commonly
used in the Geograph dataset in conjunction with the land cover class beach: sandy;
deserted; eroded; soft; rocky; warm; glacial; low; beautiful and lovely [8]. Thus, a
protypical beach picture might represent abstract qualities such as being deserted.
This property could be modeled using a similar approach to that adopted by Carver et
al. [5], using, for instance, accessibility models. Images identified as belonging to the
“where/generic of” element associated with beaches, through use of, for example,
land cover data as discussed in §3.2, might then be rated in terms of their accessibility
and thus assigned a probability of representing the abstract quality of desertion.
4 Conclusions
We have set out in this paper to consider how Text-based Image Retrieval (TBIR)
might be improved through the use of index terms describing the where facet of the
Pansofsky-Shatford matrix. We contend that such methods will become not only
112112

possible, but indispensable, as increasing numbers of images are georeferenced
4
.
Indeed, we would contend that the WorldExplorer system [1], implicitly describes the
where facet of the Pansofsky-Shatford matrix by aggregating Flickr tags from
multiple users to generate useful labels for groups of pictures. We have illustrated
how a wide range of existing methods might be used to describe images not only in
terms of their locations (as represented through a set of coordinates), but also in terms
of the notion of place. Broadly speaking, methods which go beyond analyzing
notionally objective datasets, such as administrative gazetteers or land cover data, can
be considered to address place-based geography. Thus, for example, methods to
identify vernacular names or describe prototypical scene types and their qualities rely
on the development of methods which can, for instance, exploit volunteered datasets
representing experiential data. However, an important note of caution must also be
sounded here – descriptions of place derived from such datasets are inevitably
situated according to the perspective of their contributors. This in turn requires that if
we wish to develop methods describing both space and place that we do so critically.
Acknowledgements
This research reported in this paper is part of the project TRIPOD supported by the
European Commission under contract 045335. Simone Bircher is thanked for her hard
work on image collection and the Corine experiments. We would also like to
gratefully acknowledge contributors to Geograph British Isles, see http://
www.geograph.org.uk/credits/2007-02-24, whose work is made available under the
following Creative Commons Attribution-ShareAlike 2.5 Licence (http://
creativecommons.org/licenses/by-sa/2.5/).
References
1. Ahern, S., Naaman, M., Nair, R., Yang, J.: World Explorer: Visualizing Aggregate Data
from Unstructured Text in Geo-Referenced Collections. In Proceedings, Seventh
ACM/IEEE-CS Joint Conference on Digital Libraries, (JCDL 07), June 2007, Vancouver,
British Columbia, Canada. (2007)
2. Ahn L. von, Dabbish, L.: Labeling Images with a Computer Game. In ACM Conference on
Human Factors in Computing Systems. ACM, New York (2004) 319-326
3. Armitage, L.H., Enser, P.G.B.: Analysis of user need in image archives. J. Info. Sci. 23
(1997) 287–299
4. Battig, W. F., Montague, W. E.: Category norms for verbal items in 56 categories: a
replication and extension of the Connecticut Norms. J. Expt. Psych. 80 (1969) 1–46.
5. Carver, S., Evans, A.J., Fritz, S.: Wilderness attribute mapping in the United Kingdom.
International Journal of Wilderness. 8 (2002) 24-29
6. Craik, K.H.: Appraising the Objectivity of Landscape Dimensions. In: Krutilla, J.V. (ed):
Natural Environments: Studies in Theoretical and Applied Analysis. John-Hopkins Uni.
Press, Baltimore (1971) 292–346
7. Deselaers, T., Müller, H., Clough, P., Ney, H., Lehmann. T.M.: The CLEF 2005 Automatic
Medical Image Annotation Task. International Journal of Computer Vision. 74 (2007) 51-58
8. Edwardes, A.J and Purves, R.S. A theoretical grounding for semantic descriptions of place.
To appear in Proceedings of W2GIS.
4
For example, by 3 Nov., ‘07, over 30 million Flickr images were associated with coordinates
113113

9. Edwardes, A.J.: Re-placing Location: Geographic Perspectives in Location Based Services,
Ph.D Thesis, University of Zurich (2007)
10. Egenhofer, M.J.: Toward the semantic geospatial web. In: Voisard, A. and Chen, S.C.
(eds.): Proceedings of the 10
th
ACM International Symposium In Geographic Information
Systems. ACM Press, New York (2002) 1–4
11. Enser, P.: Visual image retrieval: seeking the alliance of concept-based ad content-based
paradigms. Journal of Information Science. 26 (2000) 199-210
12. Fisher, P., Wood, J., Cheng, T.: Where is Helvellyn? Fuzziness of Multiscale Landscape
Morphometry. Transactions of the Institute of British Geographers. 29 (2004) 106-128
13. Goodrum, A. A.: Image Information Retrieval: An Overview of Current Research.
Informing Science. 3 (2000), 64–67
14. Hill, L.L., Frew, J., Zheng, Q.: Geographic names. The implementation of a gazetteer in a
georeferenced digital library. Dig. Lib. 5 (1999)
15. Iwahashi, J., Pike, R.J.: Automated classifications of topography from DEMs by an
unsupervised nested-means algorithm and a three-part geometric signature.
Geomorphology. 86 (2007) 409-440
16. Jones, C.B., Purves, R.S., Clough, P.D AND Joho, H.: Modelling Vague Places with
Knowledge from the Web. Int. J. of Geog. Info. Sci. (In press)
17. MacFarlane, R., Haggett, C., Fuller, D., Dunsford, H. and Carlisle, B. (2004). Tranquillity
Mapping: developing a robust methodology for planning support, Report to the Campaign
18. Montello, D., Goodchild, M., Gottsegen, J., Fohl, P.: Where's Downtown?: Behavioral
Methods for Determining Referents of Vague Spatial Queries. Spatial Cognition and
Computation 3 (2003)185–204.
19. Naaman, M., Harada, S., Wang, Q., Garcia-Molina, H., and Paepcke, A.: Context data in
geo-referenced digital photo collections. In: Proceedings of the 12th Annual ACM
international Conference on Multimedia (MULTIMEDIA '04) ACM Press, NY (2004) 196-203.
20. Naaman, M., Song, Y.J., Paepcke, A., Garcia-Molina, H: Assigning textual names to sets of
geographic coordinates, Comp. Env. and Urban Sys. 30 (2006) 418-435
21. O'Hare, N., Lee, H., Cooray, S., Gurrin, C., Jones, G.J.F., Malobabic, J., O'Connor, N.E.
Smeaton, A.F., Uscilowski, B.: MediAssist: Using Content-Based Analysis and Context to
Manage Personal Photo Collections. In: Proceedings of the 5th International Conference on
Image and Video Retrieval (CIVR 2006). Tempe, AZ, U.S.A., (2006) 529-532
22. Pasley, R.C., Clough, P. and Sanderson, M.: Geo-Tagging for Imprecise Regions of
Different Sizes. In: Proceedings of GIR07. ACM, New York (2007) 77-82.
23. Shatford, S: Analyzing the subject of a picture: a theoretical approach. Catalog. and Class.
Quart. 6 (1986) 39–62
24. Smeulders A.W.M., Worring, M., Santini, S., Gupta, A. Jain, R.: Content-Based Image
Retrieval at the End of the Early Years, IEEE Trans. on PAMI 22 (2000) 1349–1380
25. Smith B., Mark D. M.: Do mountains exist? Towards an ontology of landforms.
Environment and Planning B: Planning and Design. 30 (2003) 411-427
26. Smith, B. and Mark, D.M.: Geographical categories: an ontological investigation. Int. J. of
Geog. Info. Sci. to Protect Rural England, Countryside Agency, North East Assembly,
Northumberland Strategic Partnership, Northumberland National Park Authority and
Durham County Council, Centre for Environmental & Spatial Analysis, Northumbria
University. 15(2001) 59–612
27. Turk, M.A., Pentland, A.P.: Face Recognition Using Eigenfaces. In: Proceedings of the
Conference on Computer Vision and Pattern Recognition (CVPR). (1991) 586-591.
28. Tversky, B. and Hemenway, K., Categories of Environmental Scenes. Cogn. Psych. 15 (1983)
121–149.
29. Worboys, M. F., Nearness relations in environmental space. Int. J. of Geog. Info. Sci. 15 (2001)
633–651
30. Yang, M-H., Kriegman, D.J.; Ahuja, N.: Detecting faces in images: a survey. IEEE
Transactions on Pattern Analysis and Machine Intelligence. 24 (2002) 34-58
114114
