
RANDOM VS. SCENARIO-BASED VS. FAULT-BASED TESTING
An Industrial Evaluation of Formal Black-Box Testing Methods
Martin Weiglhofer and Franz Wotawa
Institute for Software Technology, Graz University of Technology, Inffeldgasse 16b/II, 8010 Graz, Austria
Keywords:
Formal Methods, Evaluation, Input/Output Conformance (ioco), Random Testing, Test Purposes, Fault-based
Testing, TGV, TorX.
Abstract:
Given a formal model of a system under test there are different strategies for deriving test cases from such
a model systematically. These strategies are based on different underlying testing objectives and concepts.
Obviously, their usage has impact on the generated test cases. In this paper we evaluate random, scenario-
based and fault-based test case generation strategies in the context of an industrial application and assess
the advantages and disadvantages of these three strategies. The derived test cases are evaluated in terms of
coverage and in terms of the detected errors on a commercial and on an open source implementation of the
Voice-Over-IP Session Initiation Protocol.
1 INTRODUCTION
Due to the complexity of todays software systems,
testing becomes more and more important. Espe-
cially, for safety-critical systems and for high avail-
ability systems software testing is essential. However,
software testing is a tedious, time consuming, expen-
sive and error prone task. Assessing the correctness
of a software system with respect to a textual spec-
ification or at least getting a high confidence of the
correctness requires systematic testing.
Model-based test case generation techniques
claim to address these issue, by deriving test cases
from a given formal model. There are different strate-
gies for generating the test cases. The simplest used
strategy is test generation based on randomness. The
test generation algorithm relies on random decisions
during test case synthesis. A second strategy is to
guide test case generation by user specified scenarios.
These scenarios tell the test generation tools for which
parts of the model they should generate test cases. A
third possible strategy is to use anticipated fault mod-
els in order to test for particular faults. Theoretically,
this allows to prevent a system from implementing
concrete faults at the specification level.
Mature research prototypes (e.g. TGV (Jard and
J
´
eron, 2005), TORX (Tretmans and Brinksma, 2003),
. . . ) and a sound underlying theory (Tretmans, 1996)
suggest the application of such formal methods for
black box testing in industrial projects. Existing case
studies (Fernandez et al., 1997; Kahlouche et al.,
1998, 1999; Laurencot and Salva, 2005; Philipps
et al., 2003; Kov
´
acs et al., 2003), report on the appli-
cation of formal testing techniques to different sized
applications. Basically, they report on the applica-
tion of a particular test generation technique to cer-
tain problems. In difference to that du Bousquet et al.
(2000) report on comparing the two tools TORX and
TGV when detecting faulty versions of an conference
protocol implementation. Pretschner et al. (2005)
provides a comparison of hand-crafted and automati-
cally generated test cases (using a single strategy) in
terms of error detection, model coverage and imple-
mentation coverage on an automotive network con-
troller. In difference to that, we focus on the evalua-
tion of different test generation strategies.
However, applying random, scenario-based and
fault-based test case generation techniques in an in-
dustrial settings raises some open questions of impor-
tance: (1) Which of the three strategies work best?
Does one of these strategies outperform the others?
(2) What are the benefits and drawbacks of these
strategies? (3) Given a formal specification what is
the additional effort needed to apply these techniques
to concrete industrial applications? In this paper we
assess the mentioned methods in order to provide
some answers to these three questions.
Of course, there are other aspects, beside the men-
115
Weiglhofer M. and Wotawa F. (2008).
RANDOM VS. SCENARIO-BASED VS. FAULT-BASED TESTING - An Industrial Evaluation of Formal Black-Box Testing Methods.
In Proceedings of the Third International Conference on Evaluation of Novel Approaches to Software Engineering, pages 115-122
DOI: 10.5220/0001764501150122
Copyright
c
SciTePress
tioned questions, which prevent companies from us-
ing formal methods within their software engineering
processes. These aspects include educating students
in writing formal specifications and increasing the us-
ability of the available tools as well as proving their
applicability to real-world systems. Even these prob-
lems have been known in the past they are still valid
today and have to be tackled. However, we belief that
providing proof of concepts studies and results ob-
tained from real world examples like in this paper will
help to increase the use of formal methods in practice.
This paper continues as follows: in Section 2 we
briefly introduce the underlying formal theory. The
used test case generation strategies and the available
tools are discussed in Section 3. Section 4 presents
the obtained figures and a discussion of our empiri-
cal evaluation. We draw our final conclusions in Sec-
tion 5.
2 USING FORMAL METHODS
FOR TEST CASE GENERATION
There are various techniques for automatic test case
generation using formal models. Among others,
test cases can be derived from finite state machines
(FSM), i.e. the formal model is represented as a FSM.
An overview of FSM based testing techniques is
given by Lee and Yannakakis (1996). Other methods
use model-checkers to automatically derive test cases
from formal models. Fraser et al. (2007) presents a
survey on state of the art model-checker based test
case generation.
Another approach which has been used for the
evaluation presented in this paper, relies on input-
output labeled transition systems (IOLTS) for test
case generation.
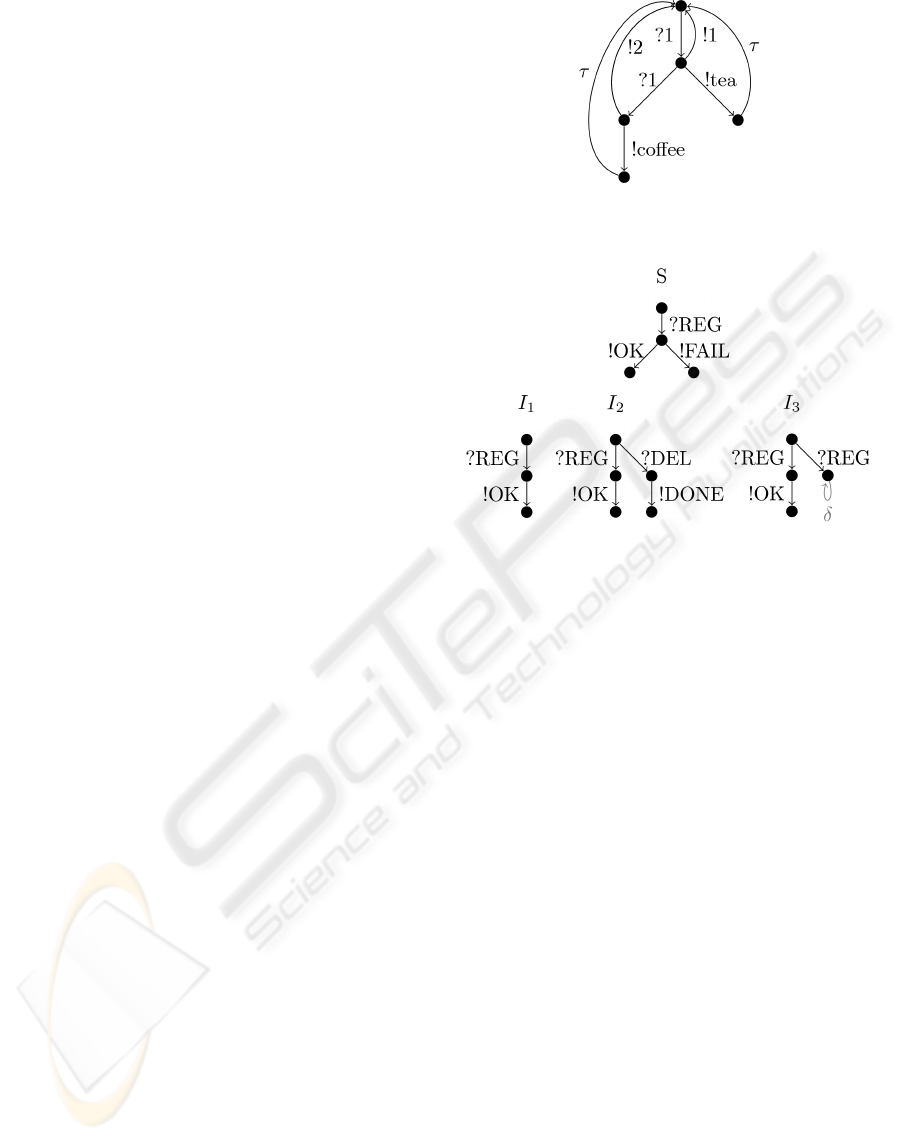
Figure 1 illustrates an example IOLTS, represent-
ing a vending machine that gives tea (!tea) if one coin
(?1) is inserted or returns the inserted coin (!1). If it
gives tea the machine cleans the internal pipes and re-
sets itself to the initial state. This cleaning action is
unobservable (τ). If a user inserts successively two
coins (!1, !1) it either gets coffee or the machine re-
turns the two inserted coins (!2). Again, after dispens-
ing coffee the machine (invisibly) cleans its pipes in
order to get ready for new orders.
In general, an IOLTS consists of a finite set of
states and labeled edges connecting these states. La-
bels are either input-labels, denoted by ?, or output-
labels, expressed by !. The label τ represents an un-
observable action.
The input-output conformance testing theory of
Tretmans (1996) uses a conformance relation between
Figure 1: Example of a labeled transition system represent-
ing a vending machine.
Figure 2: Specification and three different implementations
of a simple registration protocol.
IOLTSs in order to express the conformance between
implementations and their specifications. This the-
ory says that an implementation under test (IUT) con-
forms to a specification (S), iff the outputs of the IUT
are outputs of S after an arbitrary suspension trace of
S. The examples of Figure 2 serve to illustrate this
conformance relation.
The first implementation I
1
of Figure 2 is input-
output conform to the specification S, since the def-
inition says, that outputs of I have to be allowed by
the specification, which is obviously true for any pos-
sible trace of S. Also the second implementation I
2
is
an implementation of S. Since, the input-output con-
formance relation (ioco) only argues over all possible
traces of S an implementation may behave arbitrary
on traces that are unspecified in S. This reflects the
practical fact, that specifications may be incomplete.
I
3
non-deterministically answers with !OK or does not
answer at all (right branch after ?REG). In order to de-
tect such faulty behavior, ioco introduces quiescence.
A quiescent state is a state which either does not have
any output (!) edges nor any internal edges (τ). Such
states are marked with a special edge labeled with δ.
The suspension traces used by the ioco relation are
traces possibly containing δ actions. Thus, I
3
is not
conforming to the specification S, because the out-
puts of I
3
after the trace ?REG are {!OK, δ} while the
specification only allows {!OK, !FAIL}.
ENASE 2008 - International Conference on Evaluation of Novel Approaches to Software Engineering
116

In summary, the ioco relation seems to be appli-
cable to industrial sized problems because: (1) it is
suited to handle incomplete specifications, and (2)
it allows for using non-deterministic specifications.
Both issues are important because there are hardly
deterministic or complete specifications available in
practice. Non-determinism is typically introduced
by abstracting from unnecessary real-world details
within specifications. Nevertheless, the ioco relation
relies on two assumptions. First, it assumes that qui-
escence can be detected, which is usually done by us-
ing timeouts. Second, it requires that the application
accepts any input at any time, which is often true for
robust protocols, but may cause some problems for
other applications.
Based on this conformance relation we can gener-
ate test cases that examine whether an implementation
conforms to a given specification or not.
3 THREE TECHNIQUES FOR
MODEL-BASED TESTING
There are several strategies for deriving test cases
from models with respect to input-output confor-
mance testing. Among others, commonly used strate-
gies are: (1) random testing, (2) scenario-based test-
ing using test purposes, and (3) fault based testing.
Thus, we focus on these three techniques.
3.1 TORX - Random
The TORX tool (Tretmans and Brinksma, 2003) ex-
amines an implementation under test by traversing
a specification’s state space randomly. In each state
TORX randomly selects between sending an stimulus
to the system under test (SUT) or waiting for an re-
sponse from the SUT if both options are allowed by
the formal specification. If only sending stimuli is al-
lowed TORX chooses randomly one of the possible
stimuli. Otherwise TORX waits for an response from
the system under test.
This procedure is continued until a difference be-
tween the implementation and the specification is de-
tected or until a certain test sequence length has been
reached.
3.2 TGV - Scenario-based
The TGV tool (Jard and J
´
eron, 2005), which comes
with the CADP toolbox (Garavel et al., 2002), uses
test purposes for focusing the test generation process.
A test purpose allows to cut parts of the specification
which are not relevant for a particular testing scenario.
By the use of a set of test purposes test generation
can be focused on relevant scenarios. Thus, we have
control over the generated test cases.
For a given test purpose TGV either derives one
test case equipped with Pass, Fail and Inconclusive
states or a complete test graph representing all test
cases corresponding to the given test purposes.
When the testing activity ends in an Inconclusive
state the implementation has not done anything
wrong, but the system’s response leads to a part of
the specification that has been cut by the test purpose.
3.3 TGV - Fault-based
Aichernig and Delgado (2006) propose a technique
that allows to generate test purposes based on antici-
pated fault models. By the use of mutation operators
they generate faulty version, i.e. mutants, from the
original specification. Then they construct the IOLTS
S
τ
for the original specification and minimize S
τ
to S.
This minimization removes all unobservable τ actions
from S
τ
. In addition, Aichernig and Delgado (2006)
construct a minimized IOLTS S
M
for every mutant
M. An equivalence check between an mutant’s IOLTS
and the specification’s IOLTS gives a discriminating
sequence if there is an observable difference between
S and S
M
. This discriminating sequence is used as a
test purpose which leads to a test case that fails on
implementations that implement the mutant.
This procedure suffers from scalability issues, be-
cause it requires the construction of the complete state
spaces for the specification and the mutant. Aichernig
et al. (2007a) overcome this issue by exhibiting the
knowledge of the position of the injected fault in or-
der to search for a discriminating sequence on the rel-
evant parts of the state spaces only.
4 COMPARING THESE THREE
TECHNIQUES IN PRACTISE
We use the session initiation protocol (SIP) for the
evaluation of the three discussed test case genera-
tion strategies. In order to assess the different test-
ing strategies we executed the generated test cases
against the open source implementation OpenSER
and against a commercial implementation of the SIP
Registrar. We conducted all our experiments on a PC
with an AMD Athlon(tm) 64 X2 Dual Core Processor
4200+ and 2GB RAM.
RANDOM VS. SCENARIO-BASED VS. FAULT-BASED TESTING - An Industrial Evaluation of Formal Black-Box
Testing Methods
117

Figure 3: Simple Call-Flow of the registration process.
4.1 System under Test: Session
Initiation Protocol
The Session Initiation Protocol (SIP) handles commu-
nication sessions between two end points. The focus
of SIP is the signaling part of a communication ses-
sion independent of the used media type between two
end points. More precisely, SIP provides communica-
tion mechanisms for user management and for session
management. User management comprises the deter-
mination of the location of the end system and the
determination of the availability of the user. Session
management includes the establishment of sessions,
transfer of sessions, termination of sessions, and mod-
ification of session parameters.
SIP defines various entities that are used within a
SIP network. One of these entities is the so called
Registrar, which is responsible for maintaining loca-
tion information of users.
An example call flow of the registration process
is shown in Figure 4.1. In this example, Bob tries to
register his current device as end point for his address
Bob@home.com. Because the server needs authen-
tication, it returns “401 Unauthorized”. This mes-
sage contains a digest which must be used to re-send
the register request. The second request is encrypted
using the HTTP-Digest method described by Franks
et al. (1999). This request is accepted by the Registrar
and answered with “200 OK”. The full description of
SIP is given by Rosenberg et al. (2002).
In cooperation with our industry partner’s do-
main experts we developed a formal specification
covering the full functionality of a SIP Registrar.
This obtained LOTOS specification comprises approx.
3KLOC (net.), 20 data types (contributing to net.
2.5KLOC), and 10 processes. Note, that the Registrar
determines response messages through evaluation of
the request data fields rather than using different re-
quest messages. Thus, our specification heavily uses
the concept of abstract data types. Details of our SIP
Registrar specification can be found in (Weiglhofer,
2006).
4.2 Benefits and Drawbacks of the
Three Techniques
Table 1 gives a general overview of using the differ-
ent techniques in a practical setting. This table shows
for each of the three techniques (1st column) whether,
given a specification, the test generation can be fully
automated or if some additional manual work is nec-
essary (2nd column). The 3rd column shows the av-
erage length of the executed test sequences. The next
columns depict, the average time needed to generate
a single test case (4th column) and the overall number
of generated test cases (5th column). Note, that we
used different numbers of test runs for random test-
ing. While Table 1 only contains results for 5000
test runs, Section 4.3 lists detailed information on
the different experiments. In addition, Table 1 shows
the code coverage
1
on the open source implementa-
tion in terms of function coverage (6th column), con-
dition/decision coverage (7th column), and decision
coverage (8th column). Because of technical reasons
we are not able to provide coverage measurements for
the commercial implementation.
In addition, Table 1 illustrated the number of de-
tected faults within the open source implementation
(9th column) and within the commercial SIP Registrar
(10th column). Finally, the 11th column illustrates
whether all known faults of the implementations are
found by a particular technique.
As it can be seen from that table, the average
length of the executed test cases is approximately
twice as long for the random testing strategy as for
the other two techniques. Note, that we limited the
maximum length of test sequences to 25 steps for ran-
dom testing. However, the generation of fault-based
test cases requires much more time than random or
scenario based testing.
The code coverage shows some interesting prop-
erties of the generated test cases. First of all, ran-
dom testing covers less functions than the test cases
derived from our scenarios. This is because there
is a complex scenario which require a particular se-
quence of test messages in order to put the Registrar
into a certain state. If the Registrar is in this state it
uses additional functions for processing REGISTER
requests. Unfortunately, the random test generation
never selected this sequence from the formal specifi-
cation.
The condition/decision (C/D) coverage achieved
by random testing is higher than the C/D coverage
from scenario-based testing. That means, that random
1
For coverage measurements we use the Bullseye Cov-
erage Tool: http://www.bullseye.com
ENASE 2008 - International Conference on Evaluation of Novel Approaches to Software Engineering
118
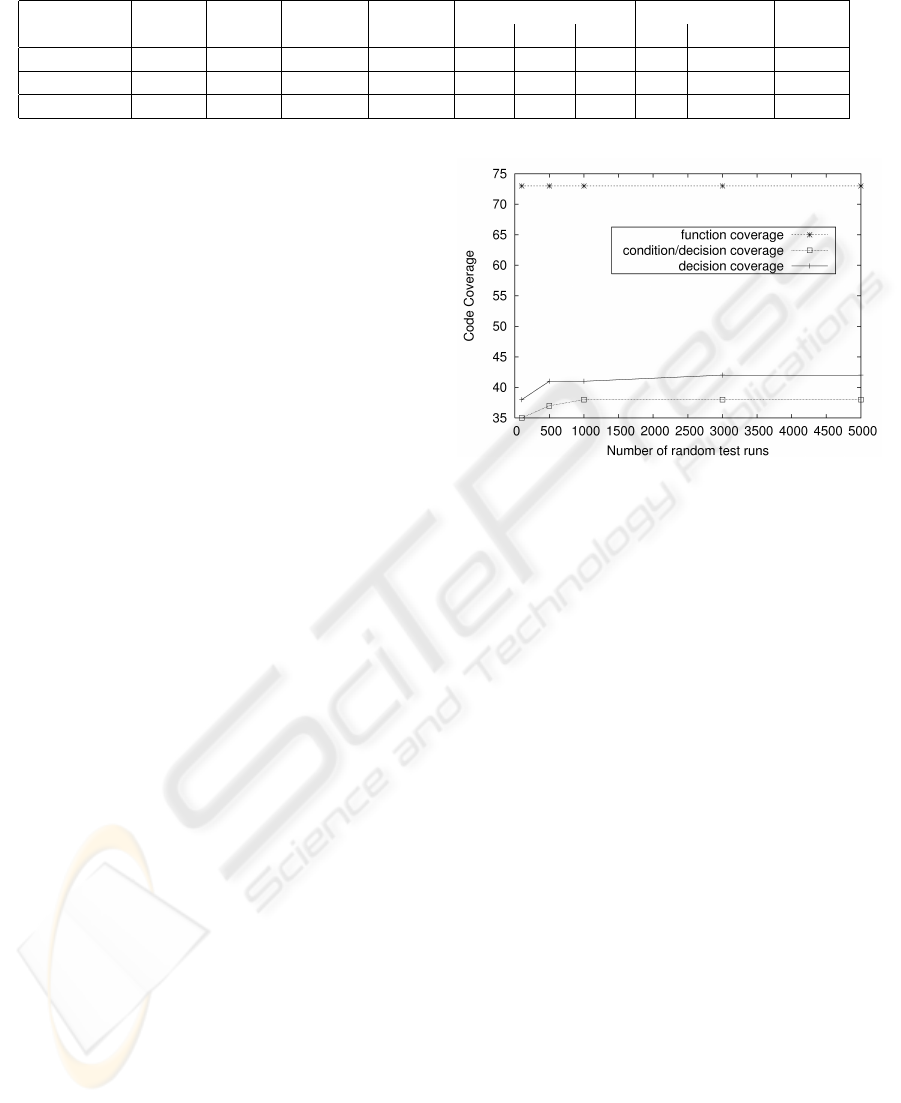
Table 1: Overview of the main results using random, scenario-based and fault-based test case generation techniques.
Technique
auto-
mated
seq.
length
test
gen.time
test
cases
avg. coverage detected faults all
faultsF C/D D o.s. comm.
random 3 10.95 4s 5000 73% 38% 42% 4 5 7
scenarios 7 4.53 1s 5408 78% 36% 40% 4 9 7
fault-based 3 4.78 45m33s 72 70% 30% 32% 4 6 7
testing has inspected the covered functions more thor-
oughly. Our fault-based test cases achieve less code
coverage than the other two approaches. However,
we only need to execute 72 test cases which requires
less effort for the analysis of the test results.
All applied test cases together detected 11 differ-
ent faults in the commercial implementation and 5
different discrepancies between the open source im-
plementation and our specification. The faults de-
tected by the fault-based test cases are also detected
by the scenario based approach. The random testing
approach revealed in both implementations one fault
that has not been detected by the other two techniques.
The detected faults occur on messages sequences that
have not been selected within the scenario based test-
ing. Also the fault-based test case generation ap-
proach did not come up with this sequences.
Overall, the results illustrated by this table are
disappointing, because there is no single technique
which found all known faults, i.e. the faults detected
by all three techniques together, on both implementa-
tions. Thus, each technique has its different strengths
and weaknesses when applied in an industrial project,
which will be analyzed in the following.
4.3 TORX- Random
In order to test a certain application using TORX and
a given specification, a test driver needs to be imple-
mented. The aim of a test driver is to convert abstract
test messages to concrete stimuli for the system un-
der test (SUT) and to transform responses from the
SUT to abstract events that match within the specifi-
cation. Because writing test drivers is a time consum-
ing task we implemented a more generic test driver
based on the rule-based rewriting system of Peischl
et al. (2007).
Random Testing based on the input-output con-
formance relation using TorX basically has following
advantages and disadvantages:
3 Testing may result into test sequences of arbitrary
length (up to a certain bound)
3 Given a specification and a test driver, testing is
fully automated
Figure 4: Code coverage on the source code when using
different numbers of random test runs on the open source
implementation.
3 Since, the relevant states of the specification are
constructed during test execution, TORX is appli-
cable to huge specifications
7 There is no possibility for guiding the testing pro-
cess, e.g. in order to get good model coverage
Figure 4 illustrates the evolvement of different
coverage criteria when increasing the number of ran-
dom test runs on the source code of the OpenSER
Registrar. This diagram shows, that the function cov-
erage does not increase at all when increasing the
number of random test runs on the open source Regis-
trar. This is basically, because the called functions are
almost always the same for most of the REGISTER
message. However, the code coverage within these
functions (reflected by condition/decision and by de-
cision coverage) increases if we use more random test
sequences.
4.4 TGV - Scenario-based
For our specification, we identified five relevant sce-
narios within the RFC (Rosenberg et al., 2002). For
each scenario we wrote a single test purpose for which
we generated all test cases using the algorithm of
Aichernig et al. (2007b).
During test execution, we reset the implementa-
tion under test before running a certain test case in
RANDOM VS. SCENARIO-BASED VS. FAULT-BASED TESTING - An Industrial Evaluation of Formal Black-Box
Testing Methods
119
Table 2: Test execution results of using test case derived
from five manually written test purposes on the two differ-
ent SIP Registrar implementations.
Test gen. OpenSER Comm.
Purpose time pass fail pass fail
notfound 12s 880 0 0 880
invalid req. 12s 1008 320 0 1328
unauth. 15s 130 302 260 172
ok 12s 1104 384 1104 384
delete 1h57m 1148 132 16 1264
Total 1h58m 4270 1138 1380 4028
order to ensure a particular system state.
A closer look on this technique leads to following
advantages and disadvantages:
3 Using test purposes gives the test engineer more
or less precise control over the generated test
cases
3 Due to an incremental test case generation TGV
does not require the complete specification’s state
space, which makes this technique applicable to
large sized (infinite) specifications.
7 Test purposes allow to specify refuse states, which
cut the search space and consequently decrese the
test generation time. If test purposes lack of such
states test generation may become slow.
7 Given a specification, some additional time is
needed to develop a set of test purposes
7 To our best knowledge, there are currently no
techniques available to evaluate the quality of test
purposes
7 Depending on the test purposes this procedure
may lead to many test cases possibly failing be-
cause of the same root causes.
The results of executing the derived test cases
against the two different implementations are illus-
trated in Table 2. This table shows the test generation
time in seconds (2nd column), for each test purpose
(1st column). In addition, this table contains the num-
ber of passed (3rd and 5th column) and the number of
failed test cases (4th and 6th column) for the open
source implementation (3rd and 4th column) and the
commercial implementation (5th and 6th column).
As there can be seen, we have many failed test
cases. Analyzing this failed test cases leads to 9 dif-
ferent faults on the commercial implementation and
4 different faults on the open source Registrar. Thus,
many test cases fail because of the same errors, which
makes test result analysis a time consuming task.
Table 3: Test execution results of using fault-based test
cases on the two different SIP Registrar implementations.
Mutation OpenSER Commercial
Operator pass fail inc. pass fail inc.
EIO 0 7 18 3 20 2
EIO+ 1 7 27 9 23 3
ESO 0 4 1 0 4 1
MCO 0 5 2 0 2 5
EIO/a 8 0 17 6 0 19
EIO+/a 8 0 27 8 0 27
ESO/a 2 1 2 3 1 1
MCO/a 0 5 2 0 5 2
Total 19 29 96 29 55 60
4.5 TGV - Fault-based
We developed a mutation tool that takes a LOTOS
specification and uses some mutation operators (as-
sociation shift operator [ASO], event drop operator
[EDO], event insert operator [EIO], event swap op-
erator [ESO], missing condition operator [MCO]) of
Black et al. (2000) and of Srivatanakul et al. (2003)
in order to generate faulty versions (mutants) of the
specification for each possible mutation. In addition,
our mutation tool inserts markers such that we are
able to extract the specification’s relevant part only
(see Section 3.3).
By the use of this mutation tool we generated 95
faulty versions of our specification. 23 of this 95 mu-
tants do not exhibit an observable fault, thus we get
72 test purposes using the fault based test purpose
generation technique. For a fault-based test purpose
it is sufficient to use a single test case derived from
this test purpose, since every test case of the test pur-
pose will fail if the faulty specification has been im-
plemented.
The average time needed to derive a test case from
a faulty version of the specification is approximately
40 minutes. This average is high because of some
complex mutants. Anyway, for the majority of mu-
tants (94%) the corresponding test case is generated
within 16 minutes.
All fault-based generated test cases follow the
same structure. They start with some preamble which
brings the implementation to a particular state that
possibly exhibits the faulty behavior. There they try
to observe whether or not the faulty specification has
been implemented.
Table 3 show the obtained results when executing
the derived test cases on our two implementations of
the SIP Registrar. This table lists for each mutation
operator (1st column), the number of passed (2nd and
5th column), failed (3rd and 6th column) and incon-
ENASE 2008 - International Conference on Evaluation of Novel Approaches to Software Engineering
120

clusive (4th and 7th column) test cases for the open
source (2nd, 3rd and 4th column) and the commercial
Registrar (5th, 6th and 7th column).
Note, that we executed the derived test cases
against the implementations using two different con-
figurations. The results from the 2nd to the 5th row
show the results when authentication was turned off,
while the results from the 6th to the 9th row show
the results for the Registrars when authentication was
turned on.
The used EIO+ operator is a derivative of the EIO
operator but inserts an output event instead of insert-
ing an event by duplicating a previous event. This
generates more observable faults, since the EIO op-
erator may duplicate τ events which results into an
unobservable difference between the mutant and the
specification.
We identified following advantages and disadvan-
tages of the fault-based approach:
3 The fault-based test case generation strategy al-
lows to test for the absence of particular faults at
the level of the specification.
3 Given a formal specification the test generation
can be fully automated.
3 We need only one test case per mutant which re-
sults into manageable test suite sizes.
7 The overall test case generation process, espe-
cially the test purpose generation, is a time con-
suming task.
7 If the generated test cases fail to execute their
preambles, testing for a specific fault may be in-
feasible, i.e., test cases terminate with inconclu-
sive verdicts.
5 CONCLUSIONS
In this paper we have evaluated random, scenario-
based and fault-based test generation techniques, by
testing two implementations of an Session Initiation
Protocol Registrar. A closer look on the empirical re-
sults allows to answer the initially stated questions.
Which of the Three Strategies Work Best? Our
evaluation shows that no one of these three
methods outperforms the others. The fault-based
approach works worst and reveals no additional
failures. The random and the scenario-based ap-
proach perform almost equal and detect failures
that are not found by the other approaches.
What are the Benefits and Drawbacks. Basically,
all of the evaluated testing strategies allow to
systematically derive test cases for industrial-
sized specifications. The quality and the number
of the derived test cases differ. Fault-based test
generation gives a low number of test cases with
a code coverage lower than that of the other
two techniques. Random testing may require a
long time to find particular failures, but possibly
finds failures overseen by scenario-based testing.
Scenario-based testing uses user specified scenar-
ios to guide the test generation process. In that
case, the overall quality of the test cases depend
on the quality of the specified scenarios.
What are the Additional Efforts. The model-based
testing techniques start from a formal model. Typ-
ically, the industry refuses from writing such
models since they belief that this is a time con-
suming. Reasons for that are the complexity of
nowadays formal modelling languages and the
lack of good tool support. As concluded by
Pretschner et al. (2005), we also belief that the use
of models pay off in terms of failure detection. In
addition, to the formal model a test driver which
converts test messages to concrete system inputs
is needed in order to execute the derived test cases.
However, given a formal specification and a test
driver, fault-based testing and random testing can
be completely automated. For scenario based test-
ing the user needs to specify test purposes manu-
ally. These test purposes allow to control the test
generation process, but require additional work.
Finally, we have to mention that we were able to
reveal several differences between the specification
and its implementations. Since the implementations
are deployed in industrial Voice-over-IP networks this
case study shows the relevance of model-based testing
for industry.
ACKNOWLEDGEMENTS
The research herein is partially conducted within
the competence network Softnet Austria (www.soft-
net.at) and funded by the Austrian Federal Ministry
of Economics (bm:wa), the province of Styria, the
Steirische Wirtschaftsf
¨
orderungsgesellschaft mbH.
(SFG), and the city of Vienna in terms of the center
for innovation and technology (ZIT).
We are grateful to Alexander Pilz for his help with
the implementation of the TORX adapter module.
RANDOM VS. SCENARIO-BASED VS. FAULT-BASED TESTING - An Industrial Evaluation of Formal Black-Box
Testing Methods
121

REFERENCES
Aichernig, B. K. and Delgado, C. C. (2006). From faults via
test purposes to test cases: On the fault-based testing
of concurrent systems. In Proceedings of the 9th Inter-
national Conference on Fundamental Approaches to
Software Engineering, volume 3922 of LNCS, pages
324–338. Springer.
Aichernig, B. K., Peischl, B., Weiglhofer, M., and Wotawa,
F. (2007a). Protocol conformance testing a SIP reg-
istrar: An industrial application of formal methods.
In Hinchey, M. and Margaria, T., editors, Proceed-
ings of the 5th IEEE International Conference on Soft-
ware Engineering and Formal Methods, pages 215–
224, London, UK. IEEE.
Aichernig, B. K., Peischl, B., Weiglhofer, M., and Wotawa,
F. (2007b). Test purpose generation in an industrial
application. In Proceedings of the 3rd International
Workshop on Advances in Model-Based Testing, pages
115–125, London, UK.
Black, P. E., Okun, V., and Yesha, Y. (2000). Mutation op-
erators for specifications. In Proceedings of the 15th
IEEE International Conference on Automated Soft-
ware Engineering, pages 81–88, Grenoble, France.
IEEE.
du Bousquet, L., Ramangalahy, S., Simon, S., Viho, C.,
Belinfante, A., and de Vries, R. G. (2000). Formal
test automation: The conference protocol with TGV/-
TORX. In Proceedings of 13th International Confer-
ence on Testing Communicating Systems: Tools and
Techniques, volume 176 of IFIP Conference Proceed-
ings, pages 221–228, Dordrecht. Kluwer Academic
Publishers.
Fernandez, J.-C., Jard, C., J
´
eron, T., and Viho, C. (1997).
An experiment in automatic generation of test suites
for protocols with verification technology. Science of
Computer Programming, 29(1-2):123–146.
Franks, J., Hallam-Baker, P., Hostetler, J., Lawrence, S.,
Leach, P., Luotonen, A., and Stewart, L. (1999).
HTTP authentication: Basic and digest access authen-
tication. RCF 2617, IETF.
Fraser, G., Wotawa, F., and Ammann, P. (2007). Testing
with model checkers: A survey. Technical Report
SNA-TR-2007-P2-04, Competence Network Softnet
Austria.
Garavel, H., Lang, F., and Mateescu, R. (2002). An
overview of CADP 2001. European Association for
Software Science and Technology Newsletter, 4:13–
24.
Jard, C. and J
´
eron, T. (2005). TGV: theory, principles and
algorithms. International Journal on Software Tools
for Technology Transfer, 7(4):297–315.
Kahlouche, H., Viho, C., and Zendri, M. (1998). An indus-
trial experiment in automatic generation of executable
test suites for a cache coherency protocol. In 11th In-
ternational Workshop on Testing Communicating Sys-
tems, IFIP Conference Proceedings, pages 211–226.
Kluwer.
Kahlouche, H., Viho, C., and Zendri, M. (1999). Hard-
ware testing using a communication protocol confor-
mance testing tool. In Proceedings of the 5th Interna-
tional Conference Tools and Algorithms for Construc-
tion and Analysis of Systems, volume 1579 of LNCS,
pages 315–329. Springer.
Kov
´
acs, G., Pap, Z., Viet, D. L., Wu-Hen-Chang, A., and
Csopaki, G. (2003). Applying mutation analysis to
sdl specifications. In Proceedings of the 11th Interna-
tional SDL Forum, LNCS, pages 269–284, Stuttgart,
Germany. Springer.
Laurencot, P. and Salva, S. (2005). Testing mobile and dis-
tributed systems: Method and experimentation. In
Higashino, T., editor, Proceedings of the 8th Inter-
national Conference on Principles of Distributed Sys-
tems, volume 3544 of LNCS, pages 37–51. Springer.
Lee, D. and Yannakakis, M. (1996). Principles and methods
of testing finite state machines - a survey. Proceedings
of the IEEE, 84(8):1090–1123.
Peischl, B., Weiglhofer, M., and Wotawa, F. (2007). Execut-
ing abstract test cases. In Model-based Testing Work-
shop in conjunction with the 37th Annual Congress of
the Gesellschaft fuer Informatik, pages 421–426, Bre-
men, Germany. GI.
Philipps, J., Pretschner, A., Slotosch, O., Aiglstorfer, E.,
Kriebel, S., and Scholl, K. (2003). Model-based test
case generation for smart cards. Electronic Notes in
Theoretical Computer Science, 80:1–15.
Pretschner, A., Prenninger, W., Wagner, S., K
¨
uhnel, C.,
Baumgartner, M., Sostawa, B., Z
¨
olch, R., and Stauner,
T. (2005). One evaluation of model-based testing
and its automation. In Proceedings of the 27th Inter-
national Conference on Software Engineering, pages
392 – 401, St. Louis, Missouri, USA. ACM.
Rosenberg, J., Schulzrinne, H., Camarillo, G., Johnston, A.,
Peterson, J., Sparks, R., Handley, M., and Schooler, E.
(2002). SIP: Session initiation protocol. RFC 3261,
IETF.
Srivatanakul, T., Clark, J. A., Stepney, S., and Polack, F.
(2003). Challenging formal specifications by muta-
tion: a csp security example. In Proceedings of the
10th Asia-Pacific Software Engineering Conference,
pages 340–350. IEEE.
Tretmans, J. (1996). Test generation with inputs, outputs
and repetitive quiescence. Software - Concepts and
Tools, 17(3):103–120.
Tretmans, J. and Brinksma, E. (2003). TorX: Automated
model based testing. In Hartman, A. and Dussa-
Zieger, K., editors, Proceedings of the 1st European
Conference on Model-Driven Software Engineering,
pages 13–25, Nurnburg, Germany.
Weiglhofer, M. (2006). A LOTOS formalization of SIP.
Technical Report SNA-TR-2006-1P1, Competence
Network Softnet Austria, Graz, Austria.
ENASE 2008 - International Conference on Evaluation of Novel Approaches to Software Engineering
122
