
Information Theoretic Text Classification Methods
Evaluation
David Pereira Coutinho
1
and M´ario A. T. Figueiredo
2
1
Depart. de Engenharia de Electr´onica e Telecomunicac¸˜oes e de Computadores
Instituto Superior de Engenharia de Lisboa, 1959-007 Lisboa, Portugal
2
Instituto de Telecomunicac¸˜oes, Instituto Superior T´ecnico, 1049-001 Lisboa, Portugal
Abstract. Most approaches to text classification rely on some measure of (dis)si-
milarity between sequences of symbols. Information theoretic measures have
the advantage of making very few assumptions on the models which are con-
sidered to have generated the sequences, and have been the focus of recent in-
terest. This paper compares the use of the Ziv-Merhav method (ZMM) and the
Cai-Kulkarni-Verd´u method (CKVM) for the estimation of relative entropy (or
Kullback-Leibler divergence) from sequences of symbols when used as a tool for
text classification. We describe briefly our implementation of the ZMM based
on a modified version of the Lempel-Ziv algorithm (LZ77) and also the CKVM
implementation which is based in the Burrows-Wheeler block sorting transform
(BWT). Assessing the accuracy of both the ZMM and CKVM on synthetic Markov
sequences shows that CKVM yields better estimates of the Kullback-Leibler di-
vergence. Finally, we apply both methods in a text classification problem (more
specifically, authorship attribution) but surprisingly CKVM permforms poorly
while ZMM outperforms a previously proposed (alsoinformation theoretic) method.
1 Introduction
Defining a similarity measure between two finite sequences, without explicitly mod-
elling their statistical behavior, is a fundamental problem with many important applica-
tions in areas such as information retrieval or text classification.
Approaches to this problem include: various types of edit (or Levenshtein) distances
between pairs of sequences (i.e., the minimal number of edit operations, chosen from
a fixed set, required to transform one sequence into the other; see, e.g., [1], for a re-
view); “universal” distances (i.e. independent of a hypothetical source model) such as
the information distance [2]; methods based on universal (in the Lempel-Ziv sense)
compression algorithms [3] [4] and on the Burrows-Wheeler block sorting transform
[5].
2
This work was partially supported by Fundao para a Cincia e Tecnologia (FCT), under grant
PTDC/EEA-TEL/72572/2006.
Pereira Coutinho D. and A. T. Figueiredo M. (2008).
Information Theoretic Text Classification Methods Evaluation.
In Proceedings of the 8th International Workshop on Pattern Recognition in Information Systems, pages 77-85
Copyright
c
SciTePress

In this paper, we consider using the methods proposed by Ziv and Merhav (ZM)
[3] and by Cai, Kulkarni and Verd´u (CKV) [5] for the estimation of relative entropy,
or Kullback-Leibler (KL) divergence, from pairs of sequences of symbols, as a tool
for text classification. In particular, to handle the text authorship attribution problem,
Benedetto, Caglioti and Loreto (BCL) [4] introduced a “distance” function based on
an estimator of the relative entropy obtained by using the gzip compressor [6] and file
concatenation. This work follows the same idea of estimating a dissimilarity using data
compression techniques, but using both the ZM method [7] and the CKV method [5],
with the main purpose of comparing these two KL divergence estimators in this context.
We describe briefly our implementation of the ZM method based on a modified ver-
sion of the Lempel-Ziv algorithm (LZ77) and also the CKV method implementation
which is based in the Burrows-Wheeler block sorting transform (BWT) [8]. We as-
sess the accuracy of both the ZM and CKV estimators on synthetic Markov sequences,
showing that, for these sources, CKV yields better estimates of the KL divergence. Fi-
nally, we apply both ZM and CKV methods to an authorship attribution problem using
a text corpus similar to the one used in [4]. Results shows that CKV method permforms
poorly while ZM method outperforms the technique introduced in [4].
The outline of the paper is has follows. In Section 2 we recall the fundamental
tools used in this approach: the concept of relative entropy and the relationship between
entropy and Lempel-Ziv coding. In Section 3 we describe briefly the BCL, ZM and
CKV methods. Section 4 presents the experimental results, while Section 5 concludes
the paper.
2 Data Compression and Similarity Measures
2.1 Kullback-Leibler Divergence and Optimal Coding
Consider two memoryless sources A and B producing sequences of binary symbols.
Source A emits a 0 with probability p (thus a 1 with probability 1 − p) while B emits
a 0 with probability q. According to Shannon [9], there are compression algorithms
that applied to a sequence emitted by A will be asymptotically able to encode the se-
quence with an average number bits per character equal to the source entropy H(A),
i.e., coding, on average, every character with
H(A) = −p log
2
p − (1 − p) log
2
(1 − p) bits. (1)
An optimal code for B will not be optimal for A (unless, of course, p = q). The av-
erage number of extra bits per character which are wasted when we encode sequences
emitted by A using an optimal code for B is given by the relative entropy (KL diver-
gence) between A and B (see, e.g., [9]), that is
D(A||B) = p log
2
p
q
+ (1 − p) log
2
1 − p
1 − q
. (2)
The observation in the previous paragraph points to the following possible way of
estimating the KL divergence between two sources: design an optimal code for source
B and measure the average code-length obtained when this code is used to encode

sequences from source A. The difference between this average code-length and the en-
tropy of A provides an estimate of D(A||B). Of course, the entropy of A itself can
be estimated by measuring the average code-length of an optimal code for this source.
This is the basic rationale underlying the approaches proposed in [4], [3], and [5]. How-
ever, to use this idea for general sources (not simply for the memoryless ones that we
have considered up to now for simplicity), without having to explicitly estimate models
for each of them, we need to use some form of universal coding. A universal cod-
ing technique (such as Lempel-Ziv [10] or BWT-based coding [11]) is one that is able
to asymptotically achieve the entropy rate lower bound without prior knowledge of a
model of the source (which, of course, does not have to be memoryless) [9].
2.2 Relationship between Entropy and Lempel-Ziv Coding
Assume a random sequence x = (x
1
, x
2
, ..., x
n
) was produced by an unknown order-
n stationary Markovian source, with a finite alphabet. Consider the goal estimating
the nth-order entropy, or equivalently the logarithm of the joint probability function
−(1/n) log
2
p(x
1
, x
2
, ..., x
n
) (from which the entropy could be obtained). A direct ap-
proach to this goal is computationally prohibitive for large n, or even impossible if n is
unknown. However, an alternative route can be taken using the following fact (see [9],
[12]): the Lempel-Ziv (LZ) code length for x, divided by n, is a computationally effi-
cient and reliable estimate of the entropy,and hence also of −(1/ n) log
2
p(x
1
, x
2
, ..., x
n
).
More formally, let c(x) denote the number of phrases in x resulting from the LZ incre-
mental parsing of x into distinct phrases, such that each phrase is the shortest sequence
which is not a previouslyparsed phrase. Then, the LZ code length for x is approximately
c(x) log
2
c(x) (3)
and it can be shown that this quantity converges (with n) almost surely to −(1/n)
log
2
p(x
1
, x
2
, ..., x
n
), as n → ∞ [3]. This fact suggests using the output of an LZ
encoder to estimate the entropy of an unknown source without explicitly estimating its
model parameters.
3 Information Theoretic Methods
3.1 The Method of Benedetto, Caglioti and Loreto
Benedetto et al [4] have proposed a particular way of using LZ coding to estimate the
KL divergence between two sources (in fact, sequences) A and B. They have used the
proposed method for context recognition and for classification of sequences. In this
subsection, we briefly review their method.
Let |X| denote the length in bits of the uncompressedsequence X, let L
X
denote the
length in bits obtained after compressing sequence X (in particular,[4] uses gzip, which
is an LZ-based compression algorithm [6]), and let X + Y stand for the concatenation
of sequences X and Y (with Y after X). Let A and B be “long” sequences from sources

A and B, respectively, and let b be a “short” sequence from source B. As proposed by
Benedetto et al, the relative entropy D(A||B) (per symbol) can be estimated by
b
D(A||B) = (∆
Ab
− ∆
Bb
)/|b|, (4)
where ∆
Ab
= L
A+b
− L
A
and ∆
Bb
= L
B+b
− L
B
. Notice that ∆
Ab
/|b| can be seen
as the code length (per symbol) obtained when coding a sequence from B (sequence b)
using a code optimized for A, while ∆
Bb
/|b| can be interpreted as an estimate of the
entropy of the source B.
To handle the text authorship attribution problem, Benedetto, Caglioti and Loreto
(BCL) [4] defined a simplified “distance” function d(A, B) between sequences,
d(A, B) = ∆
AB
= L
A+B
− L
A
, (5)
which we will refer to as the BCL divergence. As mention before, ∆
AB
is a measure of
the description length of B when the coding is optimized to A, obtained by subtracting
the description length of A from the description length of A+B. Hence, it can be stated
that d(A, B
′′
) < d(A, B
′
) means that B
′′
is more similar to A than B
′
. Notice that the
BCL divergence is not symmetric.
More recently, Puglisi et al [13] studied in detail what happens when a compression
algorithm, such as LZ77 [10], tries to optimize its features at the interface between two
different sequences A and B, while compressing the sequence A + B. After having
compressed sequence A, the algorithm starts compressing sequence B using the dictio-
nary that it has learned from A. After a while, however, the dictionary starts to become
adapted to sequence B, and when we are well into sequence B the dictionary will tend
to depend only on the specific features of B. That is, if B is long enough, the algorithm
learns to optimally compress sequence B. This is not a problem when the sequence B
is sufficiently short for the the dictionary not to become completely adapted to B, but
is a serious problem arises for a long sequence B. The Ziv-Merhav method, described
next, does not suffer from this problem, this being what motivated us to consider it for
sequence classification problems [7].
3.2 Ziv-Merhav Empirical Divergence
The method proposed by Ziv and Merhav [3] for measuring relative entropy is also
based on two Lempel-Ziv-type parsing algorithms:
– The incremental LZ parsing algorithm [12], which is a self parsing procedure
of a sequence into c(z) distinct phrases such that each phrase is the shortest se-
quence that is not a previously parsed phrase. For example, let n = 11 and z =
(01111 000110), then the self incremental parsing yields (0, 1, 11, 10, 00, 110),
namely, c(z) = 6.
– A variation of the LZ parsing algorithm described in [3], which is a sequential pars-
ing of a sequence z with respect to another sequence x (cross parsing). Let c(z|x)
denote the number of phrases in z with respect to x. For example, let z as before
and x = (10010100110);then, parsing z with respect to x yields (011, 110, 00110 ),
that is c(z|x) = 3.
Ziv and Merhav have proved that for two finite order (of any order) Markovian
sequences of length n the quantity
∆(z||x) =
1
n
[ c(z|x) log
2
n − c(z) log
2
c(z) ] (6)
converges, as n → ∞, to the relative entropy between the two sources that emitted the
two sequences z and x. Roughly speaking, we can observe(see (3)) that c(z) log
2
c(z) is
the measure of the complexity of the sequencez obtained by self-parsing, thus providing
an estimate of its entropy, while (1/ n) c(z|x) log
2
n can be seen as an estimate of the
code-length obtained when coding z using a model for x. From now on we will refer to
∆(z||x) as the ZM divergence.
Our implementation of the ZM divergence [7] uses the LZ78 algorithm to make the
self parsing procedure. To perform the cross parsing, we designed a modified LZ77-
based algorithm where the dictionary is static and only the lookahead buffer slides over
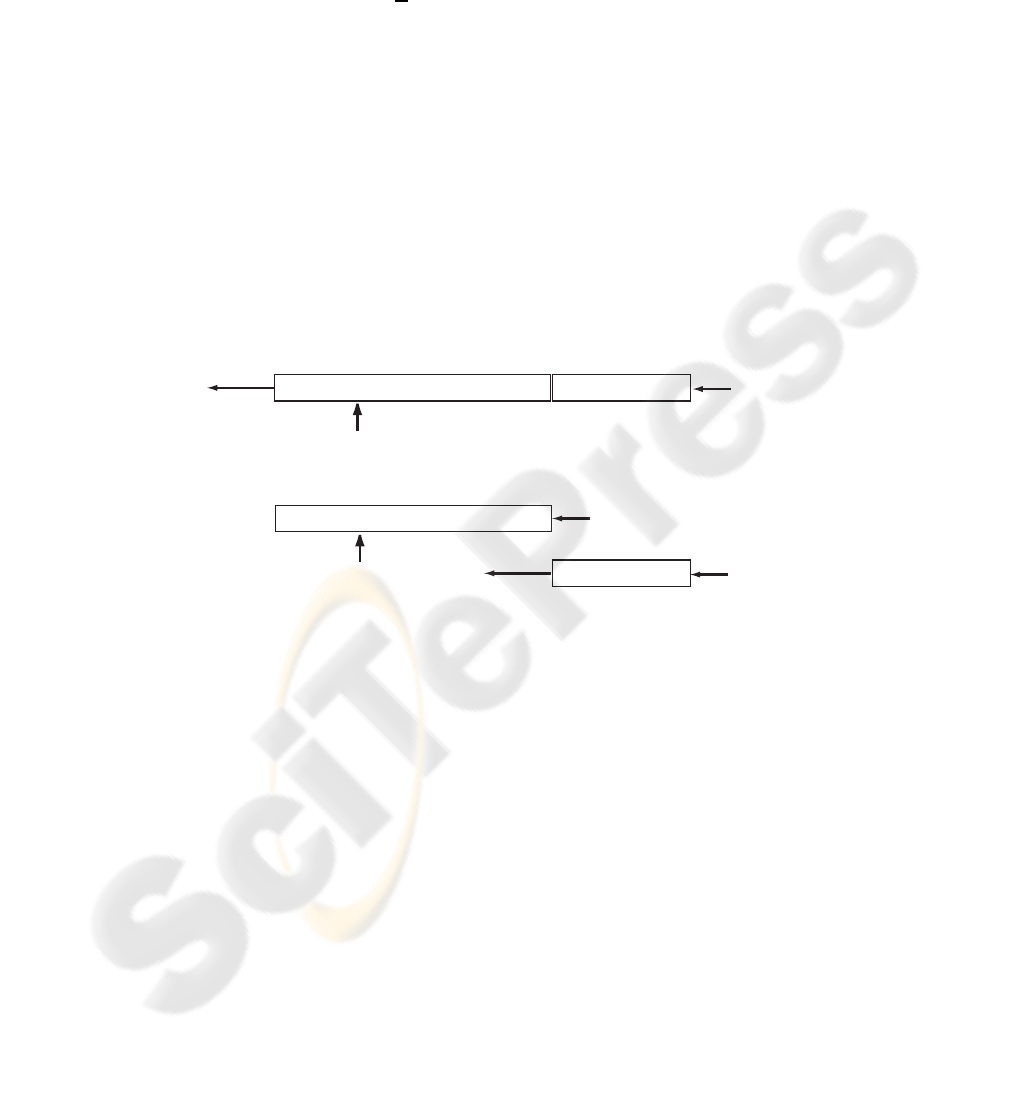
the input sequence, as shown in Figure 1.
LZ77
Ziv-Merhav
Dictionary
Dictionary
LAB
LAB
input
sequence
...this brave new world...
brave woman
brave woman
input
sequence
...this brave man...
match found
match found
reference sequence
(model)
Fig.1. The original LZ77 algorithm uses a sliding window over the input sequence to get the
dictionary updated, whereas in the Ziv-Merhav cross parsing procedure the dictionary is static
and only the lookahead buffer (LAB) slides over the input sequence.
Two important parameters of the algorithm are the dictionary size and the maximum
length of a matching sequence found in the LAB; both influence the parsing results and
determine the compressor efficiency [6]. The experiments reported in the Experiments
section were performed using a 65536 byte dictionary and a 256 byte long LAB.
3.3 The BWT-based Method
The divergence estimator proposed by Cai, Kulkarni and Verd´u applies the Burrows-
Wheeler transform (BWT) to the concatenation of the two sequences for which the
estimation divergence is wanted.
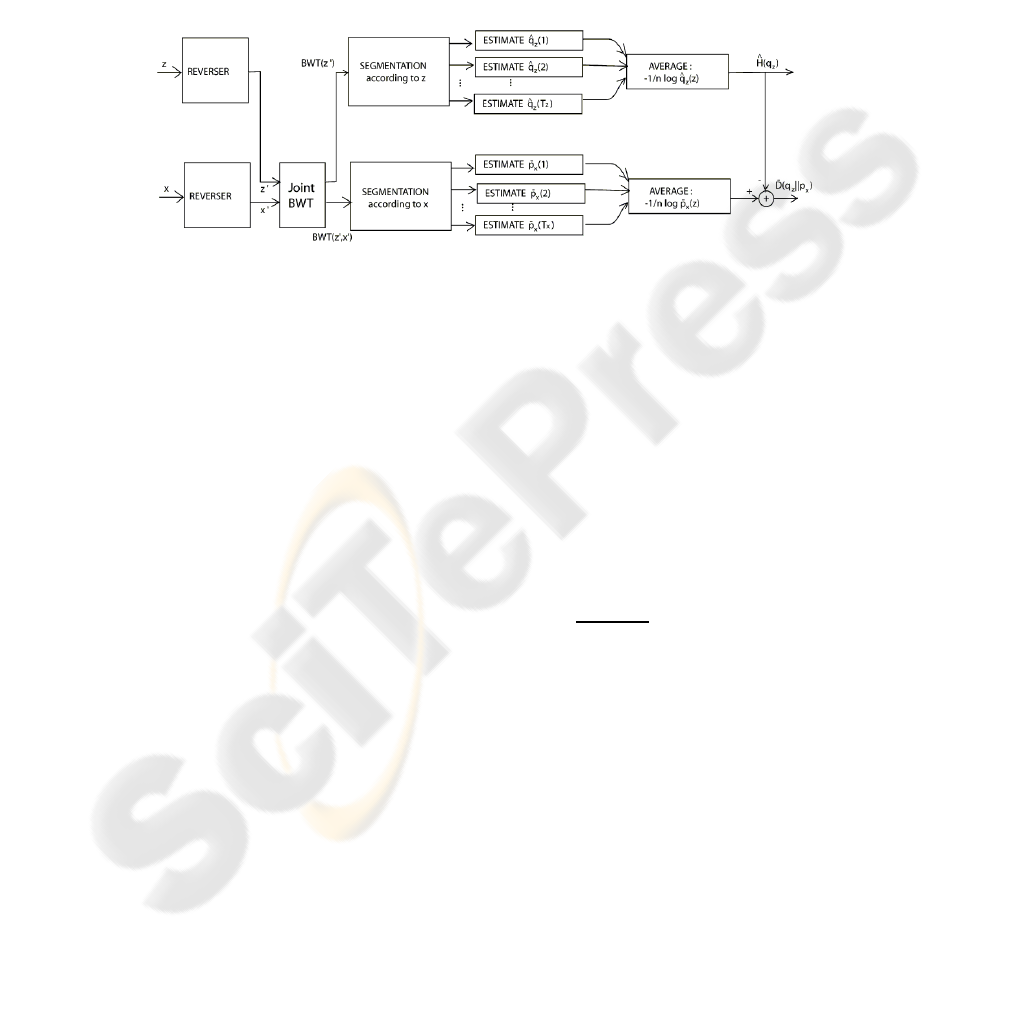
The BWT is a reversible block-sorting algorithm [8]. It operates on a sequence of
symbols, produces all cyclic shifts of the original sequence, sorts them lexicographi-
cally, and outputs the last column of the sorted table. For finite-memory sources, per-
forming the BWT on a reversed data sequence groups together symbols in the same
state. Using the BWT followed by segmentation is the basic idea behind the entropy
estimation in [14]. This idea was extended to divergence estimation [5] introducing the
joint BWT of two sequences as illustrated in Figure 2.
Fig.2. Block diagram of the divergence estimator via the BWT.
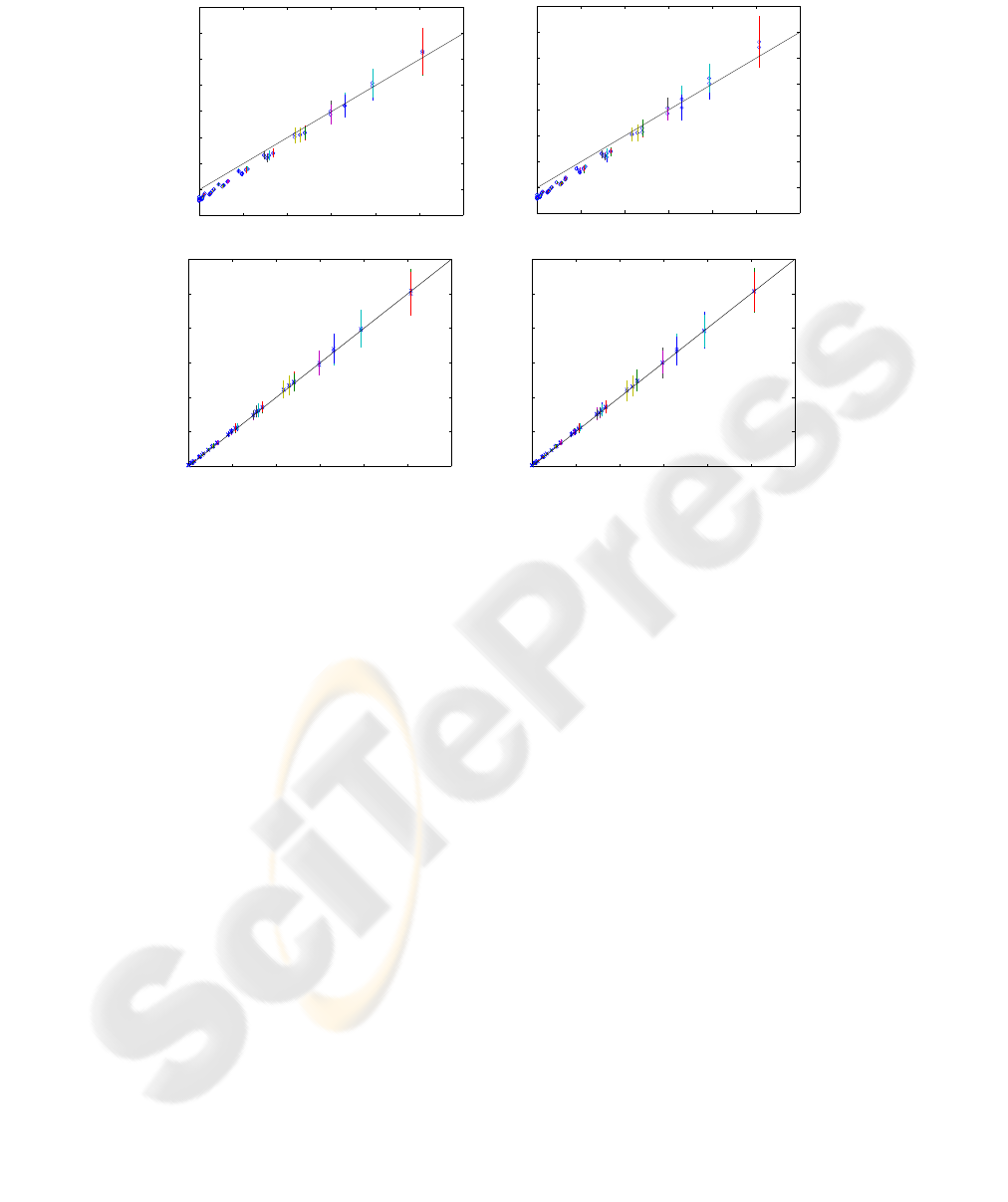
4 Experiments
4.1 Synthetic Data: Binary Sources
The purpose of our first experiments is to compare the theoretical values of the KL
divergence with the estimates produed by the ZM and the CKV methods, on pairs of
binary sequences with 100, 1000 and 10000 symbols. The sequences were randomly
generated from simulated sources using both memoryless and order-1 Markov models.
For the memoryless sources, the KL divergence is given by expression (2), while for
the order-1 sources it is given by
D(p||q) =
X
x
1
,x
2
p(x
1
, x
2
) log
2
p(x
2
|x
1
)
q(x
2
|x
1
)
. (7)
Results for these experiments using 10000 symbols are shown in Figure 3. Each
plot compares the true KL divergence with the ZM and CKV estimates, over a varying
range of source symbol probabilities. The results show that, for this type of source, the
CKV method provides a more accurate KL divergence estimate than the ZM technique
(which may even return negative values when the sequences are very similar).
4.2 Text Classification
Our next step is to compare the performance of the ZM and CKV estimators of the KL
divergence with the BCL divergence on the authorship attribution problem. We use the
0 0.5 1 1.5 2 2.5 3
−0.5
0
0.5
1
1.5
2
2.5
3
3.5
D(A||B) − divergence theoretical value
d(A||B) − divergence estimated value
Memoryless source
0 0.5 1 1.5 2 2.5 3
−0.5
0
0.5
1
1.5
2
2.5
3
3.5
D(A||B) − divergence theoretical value
d(A||B) − divergence estimated value
1st−order Markov source
state transition matrix
p 1−p
p 1−p
[
]
0 0.5 1 1.5 2 2.5 3
0
0.5
1
1.5
2
2.5
3
D(A||B) − divergence theoretical value
d(A||B) − divergence estimated value
Memoryless source
CKV method
0 0.5 1 1.5 2 2.5 3
0
0.5
1
1.5
2
2.5
3
D(A||B) − divergence theoretical value
d(A||B) − divergence estimated value
1st−order Markov source
CKV method
state transition matrix
p 1−p
p 1−p
[ ]
Fig.3. KL divergence estimates obtained by the ZM and CKV methods, versus the theoretical
values. Each circle is the sample mean value and the vertical bars the sample standard deviation
values, evaluated over 100 pairs of sequences (of length 10000). For the 1st-order Markov source
we use the state transition matrix shown and consider a range of values of p ∈ [0, 1].
same text corpus that was used by Benedetto et al [4]. This corpus contains a set of 86
files of several Italian authors, and can be downloaded from www.liberliber.it. Since we
don’t know exactly which files were used in [4], we apply also BCL method to this new
corpus of Italian authors. In this experiment, each text is classified as belonging to the
author of the closest text in the remaining set. In other words, the results reported can
be seen as a full leave-one-out cross-validation (LOO-CV) performance measure of a
nearest-neighbor classifier built using the considered divergence functions.
The results of this experiment, which are presented in Table I, show that the ZM
divergence outperforms the other divergences over the very same corpus. Our rate of
success using the ZM divergence is 95.4%, while the BCL and the CKV divergence
achieves rate of success of 90.7% and 38.4% respectively. Notice that the CKV rate
of success will improve to 47.7% if each text is classified as belonging to one of the
authors of the two closest texts in the remaining set.
5 Conclusions
We have compared the Cai-Kulkarni-Verd´u (CKV) [5] and the Ziv-Merhav (ZM) [3]
methods for Kullback-Leibler divergence estimation, and assessed their performance as

Table 1. Classification of Italian authors: for each author, we report the number of texts consid-
ered and three values of classification success rate, obtained using the method of Benedetto,
Caglioti and Loreto (BCL), the Ziv-Merhav method (ZM) and the method proposed by Cai,
Kulkarni and Verd´u (CKV).
Author
No. of texts BCL ZM CKV
Alighieri 8 7 7 7
Deledda
15 15 15 0
Fogazzaro 5 3 5 4
Guicciardini 6 6 5 0
Macchiavelli
12 11 11 5
Manzoni 4 4 3 4
Pirandello 11 9 11 3
Salgari
11 11 11 8
Svevo
5 5 5 1
Verga 9 7 9 1
Total 86 78 82 33
a tool for text classification. Computational experiments showed that the CKV method
yields better estimates of the KL divergence on synthetic Markov sequences. However,
when both methods were applied to a text classification problem (specifically, author-
ship attribution), the CKV method was clearly outperformed by ZM method, which also
outperforms the method introduced by Benedetto, Caglioti and Loreto [4]
Future work will include further experimental evaluation on other text classification
tasks, as well as the development of more sophisticated text classification algorithms.
Namely, we plan to define information-theoretic kernels based on these KL divergence
estimators and use them in kernel-based classifiers such as support vector machines
[15].
Acknowledgements
The authors would like to thank Haixiao Cai for providing his implementation of the
CKV method and for his comments about our work.
References
1. D. Sankoff and J. Kruskal, Time Warps, String Edits, and Macromolecules: The Theory and
Practice of Sequence Comparison. Reading, MA: Addison-Wesley, 1983.
2. C. Bennett, P. Gacs, M. Li, P. Vitanyi, and W. Zurek, “Information distance,” IEEE Transac-
tions on Information Theory, vol. 44, pp. 1407–1423, 1998.
3. J. Ziv and N. Merhav, “A measure of relative entropy between individual sequences with
application to universal classification,” IEEE Transactions on Information Theory, vol. 39,
pp. 1270–1279, 1993.
4. D. Benedetto, E. Caglioti, and V. Loreto, “Language trees and zipping,” Physical Review
Letters, 88:4, 2002.
5. H. Cai, S. Kulkarni, and S. Verdu, “Universal divergence estimation for finite-alphabet
sources,” IEEE Transactions on Information Theory, vol. 52, pp. 3456–3475, 2006.

6. M. Nelson and J. Gailly, The Data Compression Book. M&T Books, New York, 1995.
7. D. Pereira Coutinho and M. Figueiredo, “Information theoretic text classification using the
Ziv-Merhav method,” 2nd Iberian Conference on Pattern Recognition and Image Analysis –
IbPRIA’2005, 2005.
8. M. Burrows and D. Wheeler, “A block-sorting lossless data compression algorithm,” Tech.
Rep. 124, Digital Systems Research Center, 1994.
9. T. Cover and J. Thomas, Elements of Information Theory. John Wiley & Sons, 1991.
10. J. Ziv and A. Lempel, “A universal algorithm for sequential data compression,” IEEE Trans-
actions on Information Theory, vol. 23, no. 3, pp. 337–343, 1977.
11. M. Effros, K. Visweswariah, S. Kulkarni, and S. Verdu, “Universal lossless source cod-
ing with the Burrows-Wheeler transform,” IEEE Trans. on Information Theory, vol. 48,
pp. 1061–1081, 2002.
12. J. Ziv and A. Lempel, “Compression of individual sequences via variable-rate coding,” IEEE
Transactions on Information Theory, vol. 24, no. 5, pp. 530–536, 1978.
13. A. Puglisi, D. Benedetto, E. Caglioti, V. Loreto, and A. Vulpiani, “Data compression and
learning in time sequences analysis,” Physica D, vol. 180, p. 92, 2003.
14. H. Cai, S. Kulkarni, and S. Verdu, “Universal estimation of entropy via block sorting,” IEEE
Transactions on Information Theory, vol. 50, pp. 1551–1561, 2004.
15. J. Shawe-Taylor and N. Cristianini, Kernel Methods for Pattern Recognition. Cambridge
University Press, 2004.
