
Location through Proximity in RFID Systems
Daniele Biondo, Sergio Polito, Antonio Iera, Antonella Molinaro
and Massimiliano Mattei
University “Mediterranea” of Reggio Calabria - DIMET, Italy
Abstract. In this paper we introduce Location Estimation through Proximity In-
formation (LEPI), an algorithm that aims at locating portable RFID readers in
areas where active-RFID grids are settled. Location estimation is accomplished
through a proximity information, which the reader derives by performing tag in-
terrogation at increasing RF power levels. RFID tags surrounding the reader are
incrementally detected and their known positions are eventually averaged, this
providing an accurate estimation of the reader location. The performance of the
proposed approach is assessed by experimental trials, conducted in indoor en-
vironments. They testify both to the actual feasibility of such a solution and to
its better accuracy when compared to other reference RFID-based location tech-
niques.
1 Introduction
Radio Frequency IDentification (RFID) is rapidly emerging as a pervasive technology,
capable to spread over many different communications, industrial and entertainment
application fields. The working scenarios currently envisaged for RFID systems are
much broader than the initial one (simple replacement of optical bar-codes) and give
rise to the futuristic vision of an Internet of Things [1], where RFID tags are deployed
on a fairly ubiquitous basis. In such a dynamic environment, new ways to exploit RFID
potential are of major interest.
In this paper we will explore the operation of RFID as a technology to locate ob-
jects and people either in indoor or even in limited-area outdoor environments. More
specifically, we assume to work in a scenarios where, due to the presence of an ex-
cessive number of physical obstacles, classical localization solutions, such as Global
Positioning System (GPS) or ultrasound systems [10], turns to be unfeasible or too ex-
pensive. Based on the target of the location procedures that exploit RFID systems, we
distinguish between tag-oriented and reader-oriented positioning solutions. The former
aim at locating RFID tags, while the latter intend to find the position of portable RFID
readers. Both approaches are likely to be employed as a basis to implement ”location
based” services, although their application scenarios are reasonably much wider.
In fact, tag-oriented solutions require to equip the locating target with a simple
RFID tag, that usually can’t provide any further networking functions than standard
read/write operations. Thus, since there is no immediate way to process location infor-
mation directly at the locating target, such approaches are well suited for services that
Biondo D., Polito S., Iera A., Molinaro A. and Mattei M. (2008).
Location through Proximity in RFID Systems.
In Proceedings of the 2nd International Workshop on RFID Technology - Concepts, Applications, Challenges, pages 43-52
DOI: 10.5220/0001730300430052
Copyright
c
SciTePress

don’t require positioning information to be spread and exploited directly by the located
object. Rather, they can be employed to compute target locations and likely process
them in a centralized manner, i.e. with the aid of external information systems. Appli-
cations that could benefit from such solutions comprise objects/goods localization, e.g.
inventory management of goods in logistics systems, or even people positioning, e.g.
remote localization of people in special environments, such as hospitals or stores just
to make some examples. Key point in the envisaged scenarios is the use of a single
technology (RFID) for both identification and location purposes at the same time.
Differently, reader-oriented approaches require the locating target to hold a portable
RFID reader, larger and more expensive than a simple tag and usually (but not neces-
sarily) hosted by either a PDA, a laptop PC or a smart-phone. Such devices offer further
computational and networking capabilities and, thus, can provide more complex appli-
cations; these latter are, typically, built upon raw positioning data and enhanced through
either local or network-retrieved information. Thus, reader-oriented solutions fit peo-
ple/vehicle location services that require the locating target to obtain direct knowledge
of its position. Common examples of such services are: localized advertisement, guid-
ance/map provisioning (e.g. in museums, squares, large buildings), location of stock
mover cars in indoor warehouses.
In [2] we assessed the performance achievable by some reader-oriented approaches.
In this paper we propose and assess, by experimental trials, a reader-oriented location
algorithm called Location Estimation through Proximity Information (LEPI), that tries
to enhance the proximity information collected by a portable reader (i.e. the plain iden-
tification data concerning the set of active tags reachable through its interrogations) by
means of relevant RF power measures. These can help in selecting the actually closest
tags and, finally, are used to infer the reader location.
This paper is organized as follows. In Section 2 we provide an overview of previous
works on localization through RFID systems and discuss the main benefits and limi-
tations. In Section 3 we report in detail the rationale of our approach and describe the
LEPI operational behavior from a general perspective. Subsequently, Section 4 focuses
on the experimental results obtained as the output of field tests that aim at comparing
our approach with other RFID localization solutions and at evaluating the impact some
system parameters have on the location accuracy. Finally, in Section 5 we draw our
conclusions and envisage possible evolutions of the research.
2 Related Work
In the last few years, RFID based localization techniques have been investigated from
the point of view of several specific applications. As introduced in the previous section,
we suggest a classification into two main design approaches, depending on the actual
target of the positioning procedures: RFID tag-oriented location solutions, which aim
at locating RFID tags, and RFID reader-oriented location solutions, which intend to
provide a portable reader with an estimate of its own position.
Earlier work on the former class of solutions is well synthesized by LANDMARC
[3], which proposes to locate an active RFID tag through RF-power distances with re-
spect to other RFID tags, used as reference tags and deployed at fixed, known locations.
44

More specifically, spatial maps of Received Signal Strength (RSS) measures are build
dynamically, thanks to the presence of the reference tags. Through the k-nearest neigh-
bor algorithm applied in the RSS space, the k closest reference tags are selected and the
location of the target tag is finally estimated as a suitable average among the positions
of such nearest reference tags. In our previous work [2], we conducted a wide cam-
paign to evaluate the actual performance of LANDMARC under general experimental
conditions, while considering both indoor and outdoor scenarios. We concluded that
such tag-oriented algorithms require highly expensive infrastructures, including numer-
ous RFID tags and RFID readers/antennas, if satisfactory positioning accuracies are
required, especially in indoor environments.
As for reader-oriented location solutions, [4] proposes to spread a very large num-
ber of passive RFID tags, that can act as reference tags, over the area of interest, thus
creating a so-called Super-distributed RFID tag infrastructure. A portable reader po-
sition can be inferred either through the identification of the closest reference tag sur-
rounding it or, in case of multiple tags identification, even by simple averaging the
positions of the identified tags. As a possible application, the authors suggest to track
the trajectory of a moving reader over a super-distributed RFID tags grid. Similar ap-
proaches have also been studied in the field of assistance to blind people [5, 6] and in
robot localization [7]. In [5,6] RFID readers, embedded in shoes or in walking sticks
of visually impaired people, are used to collect proximity information from RFID tags
spread across the operating area. The main emphasis in the cited papers is on defining
application scenarios, rather than on conducting in-depth analyses on location proce-
dures and on their best operational and project parameters. In robotics, the issue of
locating RFID readers has been investigated in [7], where statistical filters are exploited
to enhance odometry information by means of RFID tag identification.
In [9] a classification similar to the one introduced in the present paper is shown. In
particular, the Active scheme aiming at providing the localization of a portable reader
and the Passive scheme for localization of a tagged item are outlined. The target position
is assessed through a nonlinear optimization method that minimize an error objective
function.
The activescheme requires a number of tags with known position placed on the floor
and on the ceiling as minimum infrastructure. The passive scheme, instead, requires one
tags grid placed on the floor or on the ceiling and a number of fixed reader (at least 4).
Several simulations are carried out by the authors to evaluate the performance of the
proposed schemes. In particular, they study the impact of parameters such as the density
of the references tag grid, the number of the antennas (radiation elements), and the
irregularity of transmission signal pattern quantified by a value that takes into account
the maximum variation of the reader transmission. The scenario in which simulations
are conducted is similar to a typical 40 X 8 X 8 feet container; 640 tags in the active
scheme, and 8 reader with the addition of a tag grid for the passive scheme, are required
to obtaining high location precision.
The approach introduced in the present paper is not comparable to the one previ-
ously cited for two main reasons: we show results obtained through experimental trials,
while in [9] the performance evaluation of the proposal is simulated; furthermore, the
experimental results shown to demonstrate the effectiveness of positioning schemes
45

does not give enough details to allow carrying out comparisons. More specifically, our
algorithm gathers incremental proximity information from regular grids of RFID active
tags, by operating a suitable control over the RF-power of reader’s interrogations. The
main aim is to select tags that are actually the closest to the reader’s location and, then,
to average their positions and get a final position estimate.
3 Proposed Approach: Location Estimation through Proximity
Information (LEPI)
In this section we propose a location estimation approach, called Location Estimation
through Proximity Information (LEPI), that aims at assessing the position of a portable
RFID reader device over a grid of RFID tags. More specifically, the reader’s location is
estimated as a weighted linear combination of the coordinates of those RFID tags that
the portable reader recognizes as the nearest ones. We analyze the impact of different
weighting functions, based on RF power measures, on the determination of the actually
closest tags among those detected by reader interrogations.
The operation of LEPI is based on these intuitive observations: (i) the transmission
power of scan requests emitted by the reader determines the size of the interrogation
area and, consequently, the number of RFID tags that are able to respond; (ii) RFID
tags that are physically closer to the RFID reader are more likely to respond to inter-
rogations generated at lower transmission powers compared to the farther ones; (iii) by
adding little increments to the transmission power of the scan requests, we are confident
to always collect sets of RFID tags that are supersets of those collected with lower pow-
ers;(iv) by suitably averaging the coordinates of the RFID tags sensed as the nearest we
can guess the actual reader’s position.
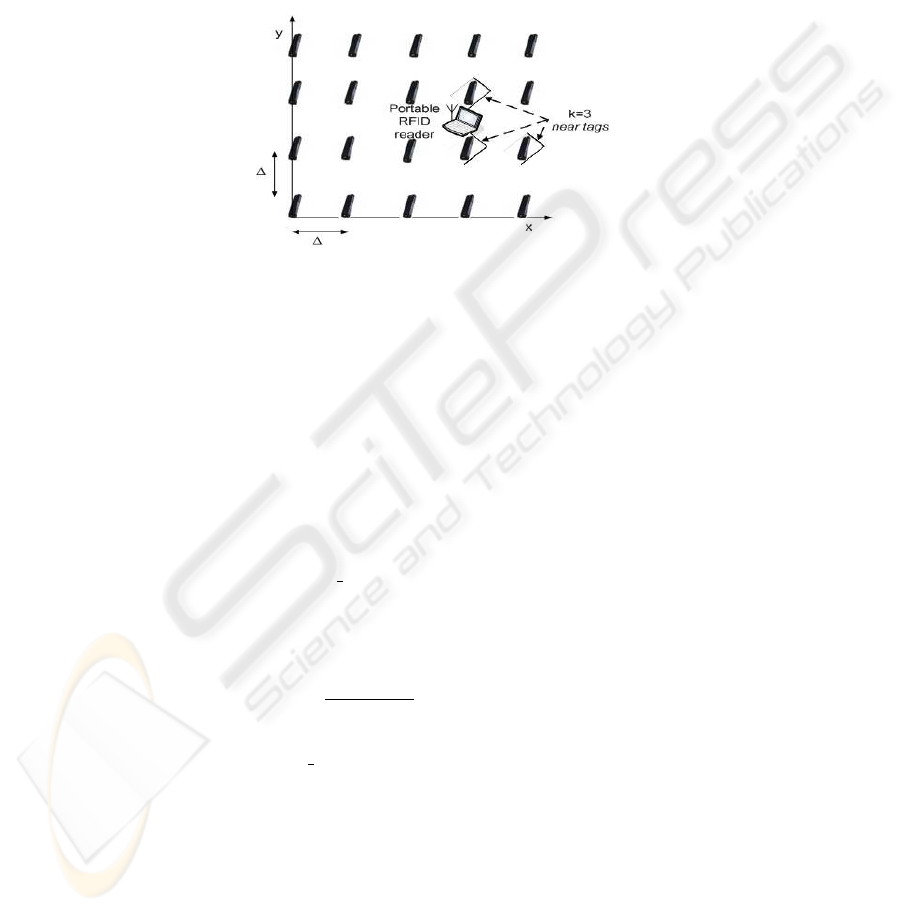
We propose to deploy a two-dimensional grid of RFID tags, called reference tags,
that are evenly spread over the area of interest, as shown in Fig.1. Each reference tag
is associated to its own position on the grid either directly, by storing its coordinates
into its memory, or indirectly, through a suitable mapping between IDs and positions
provided by external information systems (e.g. a database available to the reader).
In Fig. 2 we describe how LEPI approach is executed. First, the reader generates
a sequence of interrogations (i.e. of broadcast scan messages that wake up the reach-
able tags and query their IDs), each one transmitted with an increasing level of trans-
mission power. We suppose to start interrogating at the lowest admitted transmission
power and to stop when the highest allowed power is reached; thus actually increasing
the reader detection range from the smallest to the largest available. During the inter-
rogation phase, the reader associates to each identified tag the RF power of the first
interrogation that woke it up (i.e. the lowest power transmitted by the reader that is ca-
pable to switch the tag on). We call such a value identification power and use it as an
index of the proximity between tag and reader. Specifically, we assume that the lower
the identification power, the closer the detected tag to the reader location (with a high
probability). The interrogation cycle is stopped as soon as one of these conditions is
met:
– (At least) a suitable, predefined number k of near tags has answered the interro-
gations, thus been detected. In case of detection of more tags than expected, then
46
the first k tags are selected, based on the RSS of their answers as measured by the
reader.
– The reader reached its highest transmission power. In such a case the currently
detected tags are selected as near tags, whichever their number.
Finally, the reader’s location is assessed as a linear combination of the positions of such
k near tags, that can take into account the relevant identification power measures.
Fig.1. LEPI configuration with RFID tags placed as reference points over a regular grid and a
portable RFID reader.
The number k of the admitted near tags is a key parameter in the protocol design.
Depending on k, the target position is evaluated as coincident with the reference tag
that was detected first, if k = 1, or as a suitable point over the line or polygon whose
vertexes fall on the k near tags, if k > 1. In order to average among such vertexes, we
propose to distinguish among different weighting functions:
– Center of mass (CM), the simplest weighting method, consists in estimating the
reader’s location as the center of mass of the near tags’ positions. In so doing, the
same weight is given to all selected near tags.
– Transmission power (TX pow), that assigns a weight to the selected near tags
based on their identification power, defined above as the RF transmission power of
the first interrogation that woke them up. Since we consider higher identification
power measures as an index of longer distances between reader and tags, we choose
to assign lower weights to tags associated to higher identification powers. Thus, we
define weights as w
i
=
1/IP
i
P
k
l=1
1/IP
l
, i = 1, ..., k where IP
i
is the identification
power of the i
th
near tag.
– Reception power (RX pow) considers a different RF power value associated to
each near tag, called reception power; this is defined as the RSS of the response
signal emitted by a tag following an interrogation, and it is measured by the reader
antenna. Such a metric is complementary to the identification power we have used
so far, since it takes into account the return link of the communication between
reader and tags. To a first approximation, a higher value of reception power for
a tag can be associated to a higher proximity to the reader, thus we can assign a
47

const int K; //predefined value of the near-tags
int tx_power = MINIMUM_TX_POW; //transmission power of the reader
Tags_array detected_tags;
while(detected_tags.length < K && tx_power <= MAXIMUM_TX_POW) {
/
*
broadcast an interrogation with tx_power power
and get the array of detected tags
*
/
detected_tags = exec_interrogation(tx_power);
tx_power += TX_POWER_STEP;
//increase reader tx_power at a fixed step
}
reader_position = average_positions(detected_tags);}
Fig.2. Pseudocode description of LEPI algorithm.
higher weight to it. In formulas, the weight associated to the i
th
near tag is w
i
=
RP
i
P
k
l=1
RP
l
, i = 1, ..., k, where RP
i
is its respective reception power.
By selecting the reference tags detected with low RF-power interrogations as the
nearest to the reader, the LEPI approach translates closeness (in the radio signal prop-
agation space) into proximity (in the actual - i.e. physical, space). However, there are
many well known issues affecting the propagation of radio waves in indoor environ-
ments [8] that don’t allow for direct correlation between RF-power and physical dis-
tance. Further, it is necessary to take into account effects like false-negative readings,
i.e. unsuccessful detection of tags that are actually in the reader range, and false-positive
readings, i.e. detection of tags that are far away from the reader and should fall out of
its expected interrogation range [7]. Consequently, it is conceivable that the results of
interrogations can bring to the selection of near tags that are not physically close to
the target location; this leading to positioning errors. The LEPI approach tries to miti-
gate such an effect by selecting more than one near tag, thus distributing the impact of
possible errors among them.
4 Experimental Results
In this section we will show performance results of the proposed approach, by ana-
lyzing some design parameters and by drawing a comparison with LANDMARC [3]
(widely considered as a reference for location algorithms based on RFID systems). In
order to carry out performance comparisons with LANDMARC, we implemented LEPI
approach through an active RFID system, although cheaper passive RFID tags could fit
as well to deploy LEPI solution.
We built a regular grid of RFID tags, as shown in Fig.1, in an indoor scenario con-
sisting of a lecture room in which we added different pieces of furniture to simulate
the required harsh environment. The grid is composed of 25 i-Q RFID tags produced
by Identec Solutions [11], capable of up to 100m identification range, that are put at a
48

fixed distance ∆ of 120cm on both axes. Such choice for ∆ was driven by the need to
find a suitable compromise between the accuracy required by common indoor location
services, that would ask for denser tags grids, and the operational costs of the location
infrastructure, that increase when deploying thicker tag distributions.
The portable RFID reader, an Identec i-Card3 PCMCIA reader, was mounted on
a laptop PC programmed to run LEPI and was moved on 32 positions, spanning the
whole grid. The i-Card3 reader can generate interrogations with different values of RF
transmission power, ranging between −60dbm and −10dbm. In our implementation of
LEPI, we started to send interrogation messages at the lowest available transmission
power and increased it with a step of 1dbm a time, until either the predefined number k
of near tags was detected or the highest transmission power was reached, as expressed
in the LEPI formulation.
As for LANDMARC operation, we used two i-Port3 fixed RFID readers [11], that
drove 8 antennas positioned at the edges of the grid of Fig.1. Differently from LEPI ap-
proach, LANDMARC is a tag-oriented location approach, thus we performed a further
sequence of interrogations, by placing a RFID tag at the same positions in the grid we
had previously selected to run LEPI, and leaving unaltered the remaining setup.
The positioning accuracy is assessed by determining the location error, defined as
the Euclidean distance between the actual target location, i.e. the position of the RFID
reader, and the one returned by the LEPI algorithm.
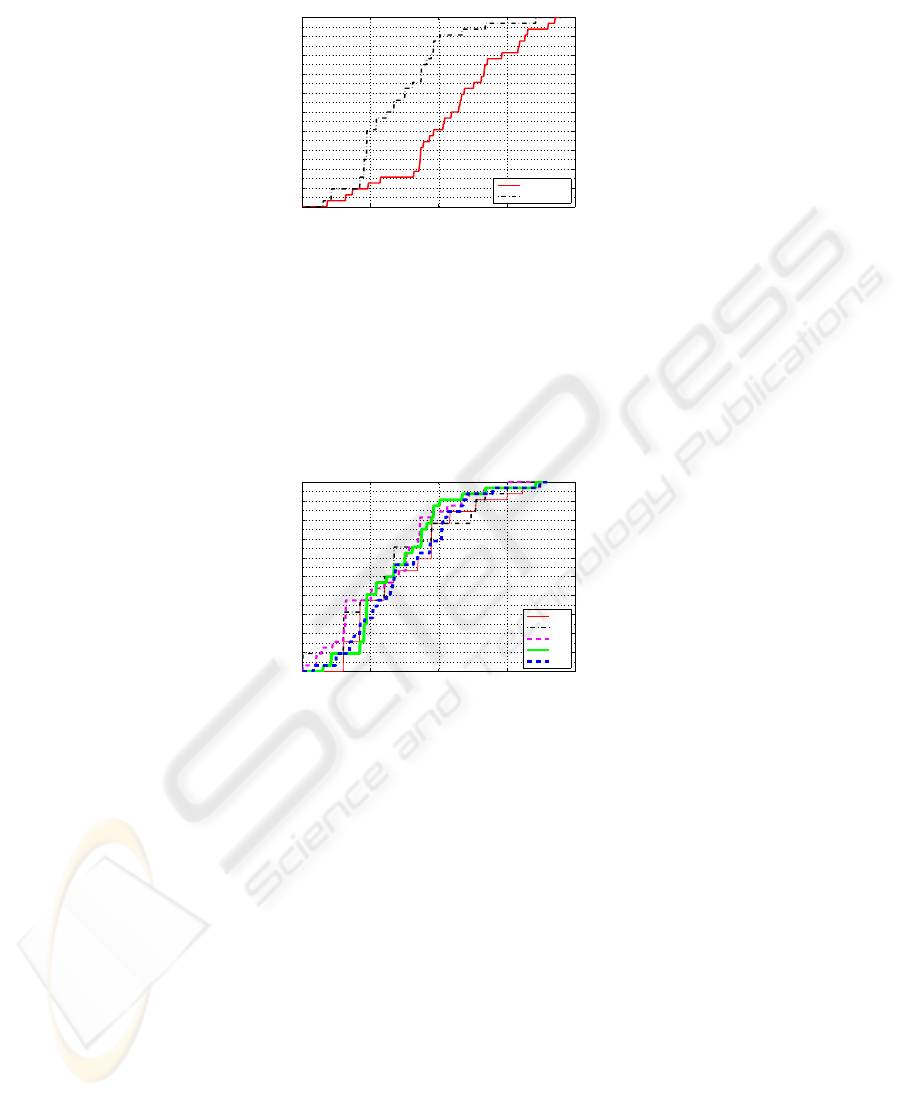
The first analysis we carried out is a comparison between LEPI and LANDMARC
approaches, whose results are shown in Fig. 3. The reported curves represent the exper-
imental cumulative distributions of the location errors of LEPI and LANDMARC algo-
rithms, when k = 4 reference tags are selected as near tags and center of mass is used as
the averaging function among near tags. We can observe that, under this configuration,
LEPI attains lower location errors both on the average, with errors of about 130cm ,
and with reference to higher percentages of experiments, like 90% of measurements,
where errors not greater than 200cm are accomplished. Differently, LANDMARC ex-
periences far higher errors, that compromise the use of the estimated positions. Such
results, attained indoors for LANDMARC approach, are consistent with our previous
analysis [2] and testify to the limitations of location methods based on direct RF power
measurements in indoor scenarios. LEPI approach, that leverages on the detection of
incremental proximity information, seems more capable of filtering out ”false near”
reference tags.
A further analysis can be conducted about the optimal number k of near tags that
shall be chosen by LEPI as the closest to the target location. In Fig. 4 we report the ex-
perimental cumulative distribution of location errors obtained when varying k between
1 and 5 and using the center of mass as the weighting function among the selected near
tags. Although the curves intersect in some points within the area of low probabilities,
we still can distinguish an interesting behavior with reference to higher probabilities,
that correspond to a high degree of confidence on the experimental result. If, for in-
stance, we focus on a probability of 0.9, we can notice that the use of either 3, 4 or even
5 near tags results to be effective in terms of location performance, differently from
the cases of either k = 1 or k = 2. In other words, trusting in more reference tags to
estimate the target location seems to allow for a reduction of positioning errors. We in-
49
0 100 200 300 400
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
location error (cm)
probability
Landmarc
LEPI
Fig.3. Comparison of location error between LANDMARC and LEPI, with k = 4 reference
points selected as near tags.
terpret this result by observing that incorrect selections of near tags can seriously affect
location accuracy when a few tags are employed (k = 1, 2), while the use of more near
tags can mitigate such effect.
0 100 200 300 400
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
location error (cm)
probability
k=1
k=2
k=3
k=4
k=5
Fig.4. Experimental cumulative distribution of location error when varying the number k of near
tags in LEPI.
On the other hand, It is easy to argue that the higher the number of near tags,
the longer is the time needed to complete localization procedures. In fact, a higher
number of interrogations, emitted with increasing transmission power, is likely to be
needed in order to detect higher numbers of tags. Our preliminary analysis on timing
issues of LEPI approach, reported in Table 1, shows the average time needed to finalize
positioning procedures with different numbers k of near tags, when using a fixed step
of 1dbm for the reader transmission power. We can observe that the average location
time increases with k, according to a non-linear law, and becomes as high as 12.41s
when k = 5.
Starting from these results, we deduce that selecting the best value for near tags
requires not only the evaluation of the achievable accuracy , but also an evaluation of
the maximum tolerated delays associated to the location service of interest. Different
50

policies and considerations can be conceived, based on special characteristics of each
reader-oriented positioning application (e.g. degree of the reader’s mobility, demanded
location accuracy,...), in order to find the most suitable operational configurations. For
instance, delay-sensitive location services, e.g. tracking of fast mobile devices, could
not benefit from the higher accuracies achievable by using more near tags, since they
would heavily be affected by the resulting delays. Due to space limitations, we leave
more detailed studies on such an issue as a further research activity.
Table 1. Average time required to complete LEPI location when varying the number k of near
tags.
k 1 2 3 4 5
time (secs) 0.68 1.35 4.29 8.55 12.41
Last point it is worth highlighting concerns the weighting functions among near
tags. In Fig. 5 we analyze the positioning accuracy achieved when using the three av-
eraging methods introduced in the previous section. More specifically, we reported lo-
cation errors obtained in 90% of the conducted field measurements, for each weighting
function and with different numbers of near tags. Clearly, abscissa values start from
k = 2, instead of k = 1, since different weighting functions don’t influence the results
when a single near tag is selected. We can notice that the use of different weighting
functions does not exhibit a plain impact on the location accuracy, when varying the
number of near tags. Therefore, we cannot determine a general benefit coming from
a particular solution. Based on such considerations, we can conclude that smart aver-
aging policies, even based on RSS measures, cannot significantly help in improving
the location performance; being this latter mainly driven by the correct selection of the
near tags. Thus, it is preferable, and strongly suggested, to rely on the simplest of the
proposed averaging solutions, that is the center of mass.
5 Conclusions
In this paper we conducted an analysis of location solutions based on RFID systems,
providing a basic distinction between tag-oriented and reader-oriented approaches. Be-
sides, we proposed a reader-oriented positioning algorithm called Location Estima-
tion through Proximity Information (LEPI). We assessed the location accuracy of LEPI
through an experimental campaign conducted indoor; it showed that such a positioning
approach is more advantageous when compared to other tag-oriented solutions. We also
detailed the impact of key project parameters affecting the resulting location accuracy,
in order to determine the best operational conditions.
Future research perspectives comprise: (i) testing LEPI in a more dynamic envi-
ronment with large mobile objects, (ii) the enhancement of the proposed localization
technique toward tracking applications, where a stronger emphasis is put on dynamic
positioning of moving people over a known area. In such a scenario, the time required
51

2 3 4 5
0
50
100
150
200
250
300
k, number of near tags
location error (cm)
CM
TX_pow
RX_pow
Fig.5. Location error in 90% of positioning experiments when varying the number k of near tags
and the weighting functions in LEPI.
to complete the positioning procedures plays a significant role too, besides location
accuracy.
References
1. International Telecommunication Union: “ITU Internet Report 2005: The Internet of Things”
(2005).
2. Polito S., Biondo D., Iera A., Mattei M., and Molinaro A.: Performance evaluation of active
RFID location systems based on RF power measures. In: Proc. of Personal, Indoor and Mobile
Radio Communications, PIMRC ’07, Athens, Sept. (2007).
3. Ni L. M., Liu Y., LauY.C., and Patil A. P.: LANDMARC: Indoor location sensing using active
RFID. In: Springer Wireless Networks. vol. 10, no. 6, pp. 701–710, (2004).
4. Bohn J.: Prototypical implementation of location-aware services based on Super-Distributed
RFID tags. In: Proc. of the 19th International Conference on Architecture of Computing Sys-
tems (ARCS’06), Frankfurt, Germany, number 3894 in LNCS, pp. 69–83, Springer-Verlag
(2006).
5. Hirose M., and Amemiya T.: Wearable finger-braille interface for navigation of deaf-blind in
ubiquitous barrier-free space. In: 10th International Conference on Human-Computer Interac-
tion (HCI International 2003), Crete, Greece (2003).
6. Willis S., and Helal S.: RFID information grid for blind navigation and wayfinding. In: Proc.
of Ninth IEEE International Symposium on Wearable Computers, ISWC ’05, Washington,
DC, USA, pp. 34–37, IEEE Computer Society (2005).
7. Hhnel D., Burgard W., Fox D., Fishkin K., and Philipose M.: Mapping and localization with
rfid technology. In: Proc. of IEEE Int. Conference on Advanced Robotics, ICAR (2004).
8. Pahlavan K., Xinrong L., and Makela J. P.: Indoor geolocation science and technology. In:
Communications Magazine, IEEE, vol. 40, no. 2, pp. 112–118, (2002).
9. C. Wang, H. Wu, and N.-F. Tzeng.: RFID-Based 3-D Positioning Schemes. In: Proc. of IEEE
INFOCOM (2007).
10. Balakrishnan H., Baliga R., Curtis D., Goraczko M., Miu A., Priyantha N., Smith A., Steele
K., Teller S., and Wang K.: Lessons from developing and deploying the Cricket indoor location
system (2003).
11. “http://www.identecsolutions.com,” Identec Solutions official web site.
52
