
Intended Boundaries detection in Topic Change
Tracking for Text Segmentation
Alexandre Labadi
´
e and Violaine Prince
LIRMM, 161 rue Ada, 34392 Montpellier, France
Abstract. This paper presents a topical text segmentation method based on in-
tended boundaries detection and compares it to a well known default boundaries
detection method, c99. Running the two methods on a corpus of twenty two
French political discourse and results showed that intended boundaries detection
performs better than default boundaries detection on well structured texts.
1 Introduction
Topical text segmentation is becoming an important issue in information retrieval (IR)
applications. It addresses the function of dividing texts into segments corresponding
to different topics. A direct application would be retrieving appropriate segments to a
query [1], [2], instead of complete texts, in which the user would not easily find the few
sentences concerning his/her specific need. Another is topical tagging of segments, to
create titles or subtitles, useful in applications where huge amounts of linear texts are
provided without sections. A third is using text topic segmentation (also called subtopic
segmentation in some papers) in automatic summarization [3].
This issue has been tackled by several researchers in both IR and natural language
processing (NLP). It could be summarized into two major actions: Either detecting
topical boundaries, i.e. finding where the topic changes [4], or detecting topics as such,
i.e, retrieving the sentences that have been recognized as ’speaking about’ a given topic
(an issue called topic detection and tracking, TDT). This paper focuses on topic change,
that is, how topical boundaries could be detected and thus lead to text segmentation.
Most methods in topic change detection are based on recognizing boundaries by default:
They assume that a topic border is to be drawn in the no man’s land between two topical
areas, ’where a large shift in the vocabulary occurs’[5]. The way these areas are defined
is generally by a similarity or a density measure. The area goes as long as similarity
(respectively density) are sufficiently respected. Two representatives of these methods
are presented in section 1. Their main liability relies on the proper NLP unit on which
they built their areas: They restrict their data to words, thus loosing the rhetorical and
syntactic information conveyed by texts. The issue tackled in this paper is thus the
following: Assuming that this information is not unuseful, could one produce a method
that takes it into account, and evaluate it on data? In other words, could we track a
topic boundary, not as a default choice, but as a deliberate one, thanks to the structural
information (rhetorical, syntactic) embedded in natural language output? This has lead
Labadié A. and Prince V. (2008).
Intended Boundaries detection in Topic Change Tracking for Text Segmentation.
In Proceedings of the 5th Inter national Workshop on Natural Language Processing and Cognitive Science, pages 13-21
DOI: 10.5220/0001728200130021
Copyright
c
SciTePress

us to define an intended boundary detection action, described and evaluated in section
2.
2 Text Segmentation by default Boundaries Detection: C99 and
DotPlotting
We chose to present two methods, among several others, detecting boundaries by de-
fault. We chose them because c99 is considered as very efficient, and Dotplotting be-
cause it is typical of the default boudary detection philosophy.
2.1 C99
Developed by Choi [6], c99 is text segmentation algorithm strongly based on the lexical
cohesion principle [7]. It is, at this time, one the best and most popular algorithms in
the text segmentation domain [8]. C99 uses similarity matrix of the text sentences. First
projected in a word vectorial space representation, sentences are then compared using
the cosine similarity measure (by the way, the most used measure). Similarity values
are used to build the similarity matrix. More recently, Choi improved c99 by using the
Latent Semantic Analysis (LSA) achievements to reduce the size of the word vectorial
space [9]. The author then builds a second matrix known as the rank matrix. The lat-
ter is computed by giving to each case of the similarity a rank equal to the number of
cases around the examined one (in a layer) which have a lesser similarity score. This
rank is normalized by the number of cases that were really inside the layer to avoid side
effects. C99 then finds topic boundaries by recursively seeking the optimum density of
matrices along the rank matrix diagonal. The algorithm stops when the optimal bound-
aries returned are the end of the current matrix or, if the user gave this parameter to the
algorithm, when the maximum number of text segments is reached.
2.2 DotPlotting
Another well known text segmentation algorithm is an adaptation of DotPlotting to text
segmentation proposed by [10]. This algorithm is based on a graphical representation of
the text, where each word is one or more dots on a bi-dimensional graphic. The number
and positions of dots depend on where and how many times the word appears in the
text. For example, a word appearing in sentence i and sentence j will be represented by
four dots : (i, i), (i, j), (j, i) and (j, j). Parts of the text where a strong term is repeated
appear on the graphic as dot clouds. Then, the algorithm try to regroup dots on the
graphic in clouds with an optimal density. These dots clouds are the topical segments.
2.3 Limits of Such Approaches
Default boundaries detection methods only regroup sentences into ’density bags’ (or
similar concepts) neglecting the text structure (be it topical, syntactic or semantic struc-
ture). This lack of structural information can lead to some mistakes, like missing the
transition between two different but close topics, for example.
14

Although favoring default boundaries detection, other methods, based on the concept
of lexical chains, try to introduce an ’intended boundary detection’. Lexical chains text
segmentation methods link multiple occurrences of the same term in a text to form a
chain. When the distance between two occurrences of a term is too important, the chain
is considered to be broken. This distance is generally the number of sentences between
two consecutive occurrences of one word. Segmenter from [3] and T extT iling from
[4] are two good examples of such methods.
Even when searching for lexical breaks, these methods do not really focus on under-
standing the nature of a transition between two topics. They only assume that a change
in the lexical field is a change of topic. If a change in the lexical field, most of the time,
leads to a change of topic, there can be change of topic without a significant change
in the lexical field. For instance, if we take the subsections of this section, there is no
significant change in vocabulary whereas one addresses a given method, the second an-
other method, and the third focuses on their liabilities. In fact, it is more a lexical first
occurrence (like the word ’cloud’ or ’dot’ in the second subsection) than a break in the
lexical chain (around the words ’text’, ’segment’ or ’algorithm’) that could be a clue for
a possible subtopic beginning [11].
We developed a text segmentation method, based on a vectorial representation of the
text and on distances between these vectors, concentrating on intentionally searching
for boundaries between topic segments, by defining these intended boundaries.
3 Intented Boundaries detection by Thematic Distance Computing
T ranseg, the method we developed, is based on a vectorial representation of the text
and on a precise definition of what we assume a transition between two text segments
should be.
3.1 Vectorial Representation of the Text
The first step of our approach is to convert each text sentence into a semantic vector
obtained using the French language parser SYGFRAN[12] (Any other parser for any
other language, providing a constituents and dependencies analysis would be compati-
ble with our approach). These vectors are Roget like semantic vectors ([13]), but using
the Larousse thesaurus ([14]) as a reference. Sentence vectors are recursively computed
by linearly combining sentence constituents, which are themselves computed by lin-
early combining word vectors. The weights of each word vectors are computed with a
formula relying on a constituents and dependencies syntactic analysis (The formula is
given in [15]). So, these vectors bear both the semantic and the syntactic information of
the sentence.
3.2 Transition Zones and Boundaries
In well written structured texts, the transition between a topic and the next one is
not abrupt. An author should conclude one topic before introducing another. This is
15
a rhetorical rule. We called this specific part of text between two segments the transi-
tion zone. Ideally, the transition should be composed of two sentences:
- The last sentence of the previous segment.
- The first sentence of the beginning new segment.
T ranseg tries to identify these two sentences in order to track topic boundaries.
Transition Score and beginning of a New Segment. The transition score of a sen-
tence represents its likelihood of being the first sentence of a segment. To compute this
score, we supposed that every sentence of the text is the first sentence of a ten sentences
long segment. We compared this ’potential segment’ with another potential segment
composed by the ten preceding sentences. This size of ten sentences for a segment was
chosen by observing results on the corpus of French political discourses we work on,
segmented by human experts. We saw that the average size of a segment was around
ten sentences (10.16) with a σ of 3.26. So, we decided to use this empirical value as the
standard segment size. However, this value has no impact on boundaries detection. Any
other might fit as well.
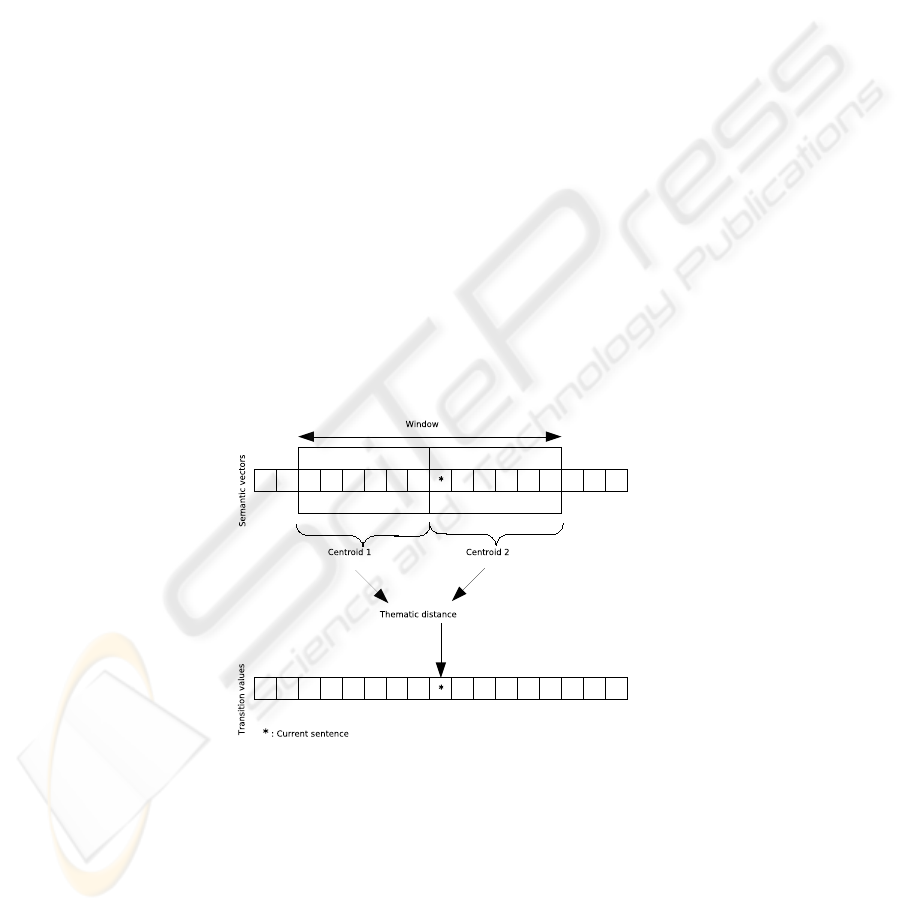
To compute the score of each sentence of the text, we slide a twenty sentences long win-
dow along the text, considering each half of the window as a potential segment. Each
potential text segment is then represented by one vector, which is a weighted barycen-
ter of its sentence vectors. We added a stylistic information by giving a better weight
to first sentences, relying on the fact that introductions bear the important information
([16],[17]). Then we calculate a distance (called thematic distance) between the two
barycenters, and consider it as the window central sentence transition score (figure 1).
Fig. 1. The transition score of a sentence represent its likelihood of being the first sentence of a
segment.
In our first experiments, we used the angular distance between two vectors as a
thematic distance, but found it not discriminant enough (although better than a cosine,
because the latter does not equally cover the two halves of a 90 degree angle). We now
16

use the augmented concordance distance, which has been designed to be as discriminant
as possible.
Augmented Concordance Distance. Semantic vectors resulting from the analysis
have 873 components and most of them are not even activated. With so many null
values in the vector, angular distance is not really representative of a shift in direction.
The goal of the concordance distance is to be more discriminant by not only considering
the vectors components values, but their ranks too.
Considering two vectors A and B, we sorted their values from the most activated to the
less activated and chose to keep only the first values of the new vectors (
1
3
of the orig-
inal vector). A
sr
and B
sr
are respectively the sorted and reduced versions of A and
B. Obviously A
sr
and B
sr
could have no common strong component (so the distance
will be 1), but if they have some we can compute two differences :
- THE RANK DIFFERENCE: if i is the rank of C
t
a component of A
sr
and ρ(i) the rank
of the same component in B
sr
, we have :
E
i,ρ(i)
=
(i − ρ(i))
2
Nb
2
+ (1 +
i
2
)
(1)
Where Nb is the number of values kept.
- THE INTENSITY DIFFERENCE: We also have to compare the intensity of common
strong components. If a
i
is the intensity of an i rank component from A
sr
and b
ρ(i)
the
intensity of the same component in B
sr
(its rank is ρ(i)), we have:
I
i,ρ(i)
=
a
i
− b
ρ(i)
Nb
2
+ (
1+i
2
)
(2)
These two differences allow us to compute an intermediate value P :
P (A
sr
, B
sr
) = (
P
Nb−1
i=0
1
1+E
i,ρ(i)
∗I
i,ρ(i)
Nb
)
2
(3)
As P concentrates on components intensities and ranks, we introduce the overall com-
ponents direction by mixing P with the angular distance. If δ(A, B) is the angular
distance between A and B, then we have:
∆(A
sr
, B
sr
) =
P (A
sr
, B
sr
) ∗ δ(A, B)
β ∗ P (A
sr
, B
sr
) + (1 − β) ∗ δ(A, B)
(4)
Where β is a coefficient used to give more weight (or less) to P . ∆(A
sr
, B
sr
) is
the concordance distance, presented in [15]. It is easy to prove that neither P nor
∆(A
sr
, B
sr
) are symmetric. But in our context of text segmentation we needed a sym-
metric value. So we augmented the concordance distance:
D(A, B) =
∆(A
sr
, B
sr
) + ∆(B
sr
, A
sr
)
2
(5)
17
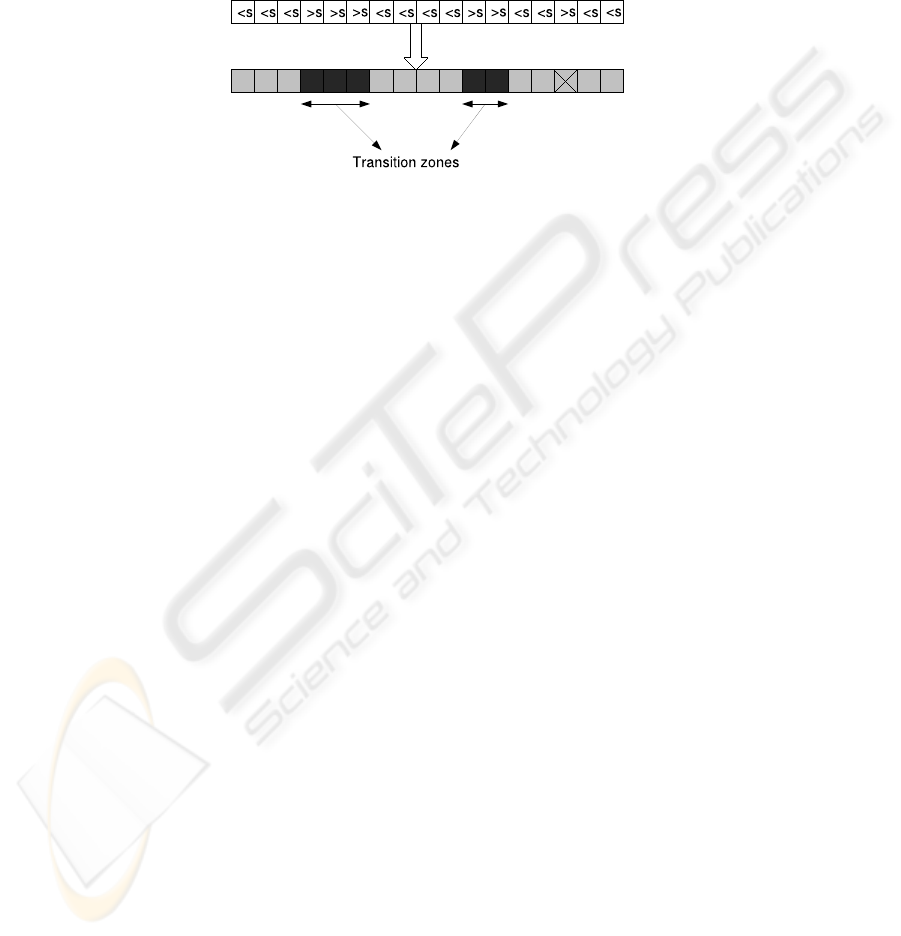
Transition Zones. Once each sentence has a transition score, we identify parts of
the text where boundaries are likely to appear. These transition zones are successive
sentences with a transition score greater than a determined threshold (figure 2). As we
defined the ideal transition zone as a two sentences long text segment, isolated sentences
are ignored.
Fig. 2. Identifying transition zones.
The threshold we chose is 0.45. As for the standard size of a segment, this value
has been deduced from our corpus. In order to know whether it is corpus dependant or
not, we browsed two other corpora segmented by human experts, belonging to the fields
of computer science an law (these corpora were available for the DEFT06 competition
on text segmentation participants. [18]). The threshold seemed to remain constant on
these data. This is not a proof that it is completely corpus independant, and needs to be
further investigated. However, at a first attempt, it resisted variation, and we assumed it
to be representative of a ’natural trend’ of topical discrimination, among other criteria,
of course. We computed augmented concordance distances between all identified text
segments and as a result we have an average distance of 0.45 with a σ of 0.08.
Ending Sentences and breaking Score. To identify boundaries inside transition zones
we needed another information. We defined the transition score of a sentence as its
likelihood of being the first sentence of a segment. The breaking score is a sentence
likelihood of being the last sentence of a segment.
We supposed that the last sentence of a topic should conclude the topic and more or
less introduce the next topic. So the thematic distance of this sentence to its segment
should be quite equal to the thematic distance of this sentence to the next segment. The
breaking score B
i
of the i sentence is:
B
i
= 1 − |D
p
− D
n
| (6)
Where D
p
is the thematic distance of the sentence to the previous segment and D
n
the
thematic distance of the sentence to the next segment. The closer D
p
and D
n
are to
each other, the closer to 1 B
i
is.
The last step of our method consists in multiplying the transition score of of each sen-
tence of a transition zone with the breaking score of the previous sentence. The higher
score has high probabilities of being the first sentence of a new segment.
18

3.3 Experiments
We compared Transeg to the popular c99 algorithm [6] by running them on twenty two
French political discourses of our corpus. These discourses have been extracted from
the original corpus because they were far cleaner and more usable than the average of
the corpus. To be safe from any implementation errors, we used the LSA augmented
c99 algorithm implementation proposed by Choi himself (http://www.lingware.co.uk/
homepage/freddy.choi/software/software.htm). The results of our experiment are pre-
sented in table 1.
They show that in 16 texts over 22, Transeg has a better Fscore value than c99. Knowing
that the corpus is composed of political discourses where syntax and rhetoric are impor-
tant elements, this gives credit to the assumption that neglecting them would possibly
reduce the topical segmentation efficiency. In the 6 texts where c99 performed better,
we noticed that they were either short, one topic texts, and then Transeg over-segmented
them, or they contained enumerations of different actions, and therefore, sensitivity to
lexical shifting is more efficient than to structural information. However, the proportion
indicates that most texts are complex structures, and convey precious indications going
beyond the sole use of words.
Table 1. Comparison between c99 and Transeg.
Words Sentences Transeg c99
Precision Recall FScore Precision Recall FScore
Text 1 617 22 50 33.33 20 33.33 33.33 16.67
Text 2 3042 100 33.33 37.5 17.65 50 12.5 10
Text 3 2767 92 42.86 85.71 28.57 20 14.29 8.33
Text 4 1028 40 33.33 33.33 16.67 20 33.33 12.5
Text 5 4532 157 12.5 18.18 7.41 16.67 9.09 5.88
Text 6 5348 212 8.7 18.18 5.88 20 18.18 9.52
Text 7 1841 47 100 42.86 30 100 14.29 12.5
Text 8 1927 74 60 33.33 21.43 100 11.11 10
Text 9 1789 53 75 100 42.86 25 16.67 10
Text 10 1389 31 33.33 20 12.5 100 20 16.67
Text 11 2309 81 30 50 18.75 33.33 16.67 11.11
Text 12 7193 211 15.38 6.25 4.44 33.33 3.13 2.86
Text 13 6097 305 20.59 33.33 12.73 17.65 14.29 7.89
Text 14 1417 57 40 33.33 18.18 100 16.67 14.29
Text 15 3195 79 40 8 6.67 66.67 8 7.14
Text 16 1995 60 66.67 28.57 20 57.14 57.14 28.57
Text 17 558 16 33.33 33.33 16.67 50 66.67 28.57
Text 18 696 25 100 37.5 27.27 40 25 15.38
Text 19 678 26 33.33 33.33 16.67 50 66.67 28.57
Text 20 1388 57 50 66.67 28.57 100 16.67 14.29
Text 21 3127 110 62.5 25 17.86 40 10 8
Text 22 1618 40 60 75 33.33 100 25 20
19

4 Conclusions
In this paper we have considered that topic change detection methods, for text seg-
mentation, generally rely on lexical information, and tend to discard other types of
information existing in texts, e.g., rhetorical, stylistic and syntactic information, gener-
ally subsumed under the label of structural information. They also favor default topical
boundaries detection, whereas focused detection on intended boundaries suggest other
possible tracks for asserting topic change. Assuming that structural information has a
role to play in detecting intended boundaries, we built a segmenter, called Transeg,
based on spotting transition zones between topics in texts. This paper has focused on
transition zones definition and the appropriate actions to detect them, by assigning a
transition score and a breaking score to each sentence of the text. The transition score
indicates its ability to play the role of the first sentence of a segment, and the breaking
score, its likelihood of being the last one. With values over a given threshold, transition
and breaking score become representative of an intended topical boundary. To deter-
mine the efficiency of Transeg, we evaluated it by running it on the same corpus as c99,
a popular default boundaries detection algorithm. Results have shown that structural
information has an impact on segmentation efficiency.
References
1. Kaszkiel, M., Zobel, J.: Passage retrieval revisited. Proceedings of theTwentieth International
Conference on Research and Development in Information Access (ACMSIGIR) (1997) 178–
185
2. Prince, V., Labadi
´
e, A.: Text segmentation based on document understanding for information
retrieval. In Proceedings of NLDB’07 (2007) 295–304
3. Kan, M., Klavans, J.L., McKeown, K.R.: Linear segmentation and segment significance.
Proceedings of WVLC-6 (1998) 197–205
4. Hearst, M.A.: Text-tilling : segmenting text into multi-paragraph subtopic passages. Com-
putational Linguistics (1997) 59–66
5. Pevzner, L., Hearst, M.: A critique and improvement of anevaluation metric for text segmen-
tation. Computational Linguistics (2002) 113–125
6. Choi, F.Y.Y.: Advances in domain independent linear text segmentation. Proceedings of
NAACL-00 (2000) 26–33
7. Morris, J., Hirst, G.: Lexical cohesion computed by thesaural relations as an indicator of the
structure of text. Computational Linguistics 17 (1991) 20–48
8. Bestgen, Y., Pi
´
erard, S.: Comment
´
evaluer les algorithmes de segmentation automatiques ?
essai de construction d’un matriel de r
´
ef
´
erence. Proceedings of TALN’06 (2006)
9. Choi, F.Y.Y., Wiemer-Hastings, P., Moore, J.: Latent semantic analysis for text segmentation.
Proceedings of EMNLP (2001) 109–117
10. Reynar, J.C.: Topic Segmentation: Algorithms and Applications. Phd thesis, University of
Pennsylvania (1998)
11. Passonneau, R.J., Litman, D.: Lintention-based segmentation: Humanreliability and corre-
lation with linguistic cues. Proceedings of the 31st Annual Meeting of theAssociation for
Computational Linguistics, (1993) 148–155
12. Chauch
´
e, J.: Un outil multidimensionnel de l’analyse du discours. Proceedings of Coling’84
1 (1984) 11–15
13. Roget, P.: Thesaurus of English Words and Phrases. Longman, London (1852)
20

14. Larousse: Th
´
esaurus Larousse - des id
´
ees aux mots, des mots aux id
´
ees. Larousse, Paris
(1992)
15. Chauch
´
e, J., Prince, V.: Classifying texts through natural language parsing and semantic
filtering. In Proceedings of LTC’03 (2007)
16. Labadi
´
e, A., Chauch
´
e: Segmentation th
´
ematique par calcul de distance s
´
emantique. Pro-
ceedings of DEFT’06 1 (2006) 45–59
17. Lelu, A., M., C., Aubain, S.: Coop
´
eration multiniveau d’approches non-supervises et super-
vises pour la d
´
etection des ruptures th
´
ematiques dans les discours pr
´
esidentiels franc¸ais. In
Proceedings of DEFT’06 (2006)
18. Az
´
e, J., Heitz, T., Mela, A., Mezaour, A., Peinl, P., Roche, M.: Pr
´
esentation de deft’06 (defi
fouille de textes). Proceedings of DEFT’06 1 (2006) 3–12
21
