
ON CHECKING TEMPORAL-OBSERVATION SUBSUMPTION IN
SIMILARITY-BASED DIAGNOSIS OF ACTIVE SYSTEMS
Gianfranco Lamperti, Federica Vivenzi and Marina Zanella
Dipartimento di Elettronica per l’Automazione, Via Branze 38, 25123 Brescia, Italy
Keywords:
Similarity-based diagnosis, discrete-event systems, temporal observations, subsumption.
Abstract:
Similarity-based diagnosis of large active systems is supported by reuse of knowledge generated for solving
previous diagnostic problems. Such knowledge is cumulatively stored in a knowledge-base, when the diag-
nostic session is over. When a new diagnostic problem is to be faced, the knowledge-base is queried in order
to possibly find a similar, reusable problem. Checking problem-similarity requires, among other constraints,
that the observation relevant to the new problem be subsumed by the observation relevant to the problem in
the knowledge-base. However, checking observation-subsumption, following its formal definition, is time and
space consuming. The bottleneck lies in the generation of a nondeterministic automaton, its subsequent trans-
formation into a deterministic one (the index space of the observation), and a regular-language containment-
checking. In order to speed up the diagnostic process, an alternative technique is proposed, based on the
notion of coverage. Besides being effective, subsumption-checking via coverage is also efficient because no
index-space generation or comparison is required. Experimental evidence supports this claim.
1 INTRODUCTION
Discrete-event systems (DESs) (Cassandras and
Lafortune, 1999) are dynamic systems, typically
modeled as networks of components. Each com-
ponent is a communicating automaton (Brand and
Zafiropulo, 1983) that reacts to input events by state-
transitions which possibly generate new events to-
wards other components. Diagnosis of DESs is a
challenging task that has been tackled since a decade
via different approaches, either based on artificial in-
telligence (Pencol´e, 2000; Roz´e and Cordier, 2002;
Console et al., 2002; Pencol´e and Cordier, 2005) or
automatic control techniques (Sampath et al., 1995;
Sampath et al., 1996; Chen and Provan, 1997; Sam-
path et al., 1998; Zad et al., 1999; Cassandras and
Lafortune, 1999; Lunze, 2000; Debouk et al., 2000;
Schullerus and Krebs, 2001). Within the domain of
a class of asynchronous DESs (Baroni et al., 1999;
Lamperti and Zanella, 2003; Lamperti and Zanella,
2004; Lamperti and Zanella, 2006b), called active
systems, a diagnosis approach has been proposed
that is based on similarity techniques (Lamperti and
Zanella, 2006a; Cerutti et al., 2007) with the aim of
pursuing reuse of knowledge when solving a diagnos-
tic problem. The idea is to store into a knowledge-
base the data structures generated for solving each di-
agnostic problem. When a new problem is to be faced,
instead of solving it from scratch, the knowledge-base
is first browsed in order to find a previously-solved
diagnostic problem that is ‘compatible’ with the new
one. If so, the knowledge relevant to the old problem
can be exploited to solve the new problem, thereby
speeding up the diagnostic process. Among other
constraints, such compatibility requires that the obser-
vation relevant to the problem in the knowledge-base
subsume the observation relevant to the new prob-
lem. Such an observation is temporal in nature, and
is represented by a DAG. The problem lies on the
mode in which subsumption is checked, which, ac-
cording to the definition of subsumption, is based on
a containment relationship between the regular lan-
guages of the index spaces of the observations. The
index space is a deterministic automaton whose gen-
eration (and comparison) may require considerable
computational resources. So, this paper proposes
an alternative, more efficient, approach for checking
observation-subsumptionthat avoids index-space ma-
nipulation, by reasoning on the specific properties of
the observations.
44
Lamperti G., Vivenzi F. and Zanella M. (2008).
ON CHECKING TEMPORAL-OBSERVATION SUBSUMPTION IN SIMILARITY-BASED DIAGNOSIS OF ACTIVE SYSTEMS.
In Proceedings of the Tenth International Conference on Enterprise Information Systems - AIDSS, pages 44-53
DOI: 10.5220/0001696200440053
Copyright
c
SciTePress

2 BACKGROUND
When an active system reacts, it generates a sequence
of observable labels, called the signature of the reac-
tion. However, what is actually perceived by the ex-
ternal observer is a relaxation of the signature S. Such
a relaxation is called a temporal observation. For-
mally, let L be the finite domain of all the observable
labels the active system can generate, possibly includ-
ing the null label ε. A temporal observation is a (not
necessarily connected) DAG
O = (N ,L ,A ) (1)
where N is the set of nodes, with each N ∈ N being
marked with a non-empty subset of L , and A : N 7→
2
N
is the set of arcs. A ‘≺’ temporal precedence re-
lationship among nodes of the graph is defined as fol-
lows:
• If N 7→ N
′
∈ A then N ≺ N
′
;
• If N ≺ N
′
and N
′
≺ N
′′
then N ≺ N
′′
;
• If N 7→ N
′
∈ A then ∄N
′′
∈ N (N ≺ N
′′
≺ N
′
).
The set of labels marking a node N is the extension of
N, written kNk. Thus, the relaxation of the signature
S into O involves three kinds of uncertainty:
• Logical uncertainty: each single observable label
in the signature S is instead perceived as a set of
candidate labels, possibly including the null label
ε. All labels in kNk but one are spurious, with just
one being the actual label.
1
• Temporal uncertainty: the absolute temporal or-
dering of the signature S is relaxed to partial tem-
poral ordering. If N ≺ N
′
in O , where ℓ and ℓ
′
are
the actual labels in N and N
′
, respectively, then
ℓ precedes ℓ
′
in S. However, not all precedence
relationships between nodes in N are known.
• Node uncertainty: additional spurious nodes that
involve ε (among other labels), are possibly in-
serted
2
.
As such, O implicitly incorporates several candidate
signatures, where each candidate is determined by se-
lecting one label from each node in N without vio-
lating the temporal constraints imposed by the prece-
dence relationships. The set of all the candidate sig-
natures of O is called the extension of O , written kO k.
Among such candidates is the actual signature S. Like
for nodes, all candidate signatures but one are spu-
rious. The mode in which the signature S demeans
1
If the actual label is ε, it means that no label was actu-
ally generated by the system. Note how the extension of a
node in N cannot be the singleton {ε}.
2
In a spurious node, the actual label is ε, with all the
other labels being spurious.
Figure 1: Observations O
1
(left) and O
2
(right).
to observation O is assumed to be unknown.
3
As
explained i,n (Lamperti and Zanella, 2002), such a
degradation may be caused by the multiplicity of the
communication channels that convey observable la-
bels from the system to the observer (temporal un-
certainty), and to noise (logical uncertainty). How-
ever, although unknown, S is assumed to be preserved
within O .
Example 1. Shown in Fig. 1 are the graphs of two
(both logically and temporally uncertain) observa-
tions, namely, from left to right, O
1
= (N
1
,L
1
,A
1
)
and O
2
= (N
2
,L
2
,A
2
), where N
1
= {N
1
,...,N
5
}, N
2
= {N
′
1
,...,N
′
4
}, L
1
= {a,b,c, d, f,ε}, and L
2
= {a,b,
c,d,ε}. In O
2
, N
′
1
incorporates the first observable la-
bel, namely a. Then, either N
′
2
or N
′
3
follows, each
of which involves two candidate labels, where ε is the
null label. The last generated node is N
′
4
, with a and
ε being the final candidate labels. The extension of
the observation, namely kO
2
k, includes the candidate
signatures ac, ad, abc, abd, aca, ada, acb, adb, abca,
abda, acba, adba, each of which is obtained by se-
lecting one label for each node without violating the
temporal constraints, where the null label ε has been
removed.
Within the diagnostic process it is inconvenient
to reason on the observation O as is, mostly be-
cause the explanation-oriented diagnostic reasoning
requires some sort of observation-indexing. Such
an indexing is more naturally performed based on a
surrogate of the observation, called the index space,
namely Isp(O ). This is a deterministic automaton
with the property that its regular language is the ex-
tension of O ,
Lang(Isp(O )) = kO k. (2)
In other words, the set of strings generated by each
path in Isp(O ), from the initial state to a final state,
equals the set of candidate signatures relevant to O .
As detailed in (Cerutti et al., 2007), the generation of
the index space of O requires two steps, namely:
• Yielding the nondeterministic automaton, called
the prefix space of O , where each node identifies
the set of consumed nodes in N up to now;
3
Otherwise, in principle, we might distill S from O ,
thereby disregarding O in the diagnostic process.
ON CHECKING TEMPORAL-OBSERVATION SUBSUMPTION IN SIMILARITY-BASED DIAGNOSIS OF ACTIVE
SYSTEMS
45
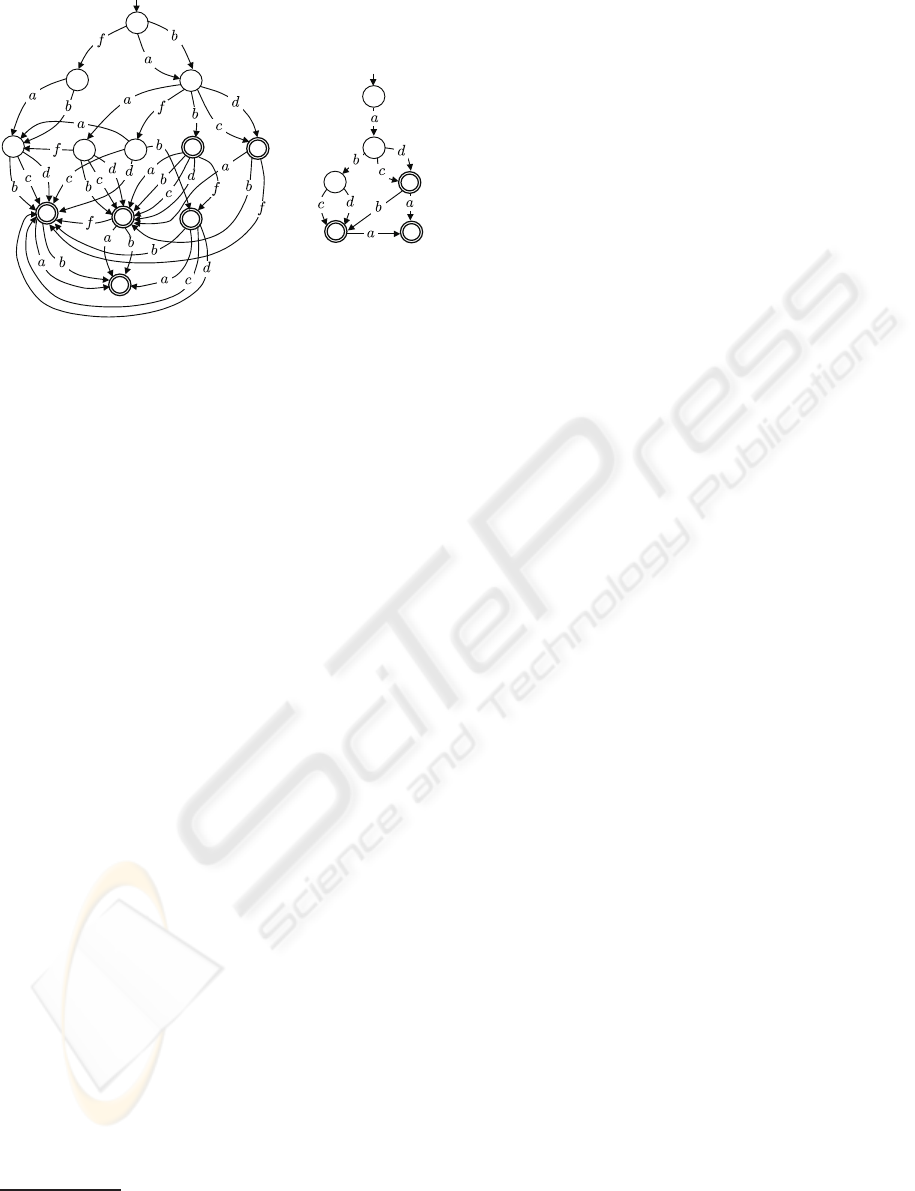
Figure 2: Index spaces Isp(O
1
) (left) and Isp(O
2
) (right) .
• Generating the deterministic automaton equiva-
lent to the prefix space, in fact the index space.
4
Furthermore, as explained shortly, the role of the in-
dex space comes into view for checking observation-
subsumption too.
Example 2. Shown in Fig. 2 are the index spaces
of observations O
1
(left) and O
2
(right) displayed in
Fig. 1. It is easy to check that the regular language of
each index space equals the extension of the relevant
observation (the set of candidate signatures), where
each string of the language corresponds to a path in
the index space, from the initial state to one of the fi-
nal states (with the latter being double circled in the
figure). In particular, Example 1 offers evidence that
Lang(Isp(O
2
)) = kO
2
k.
In similarity-based diagnosis of DESs (Lamperti
and Zanella, 2006a), it is essential to understand
whether the solution of the diagnostic problem ℘
′
at hand can be supported by the knowledge yielded
for solving a previous (different) diagnostic problem
℘, with the latter being stored in a knowledge-base.
Among other constraints, reuse of℘can be exploited
only if the observations O
′
and O relevant to ℘
′
and
℘, respectively, are linked by a subsumption relation-
ship,
O ⋑ O
′
(3)
namely, only if O subsumes O
′
. The subsumption re-
lationship is defined in terms of regular-languagecon-
tainment, relevant to the corresponding index spaces,
precisely:
Lang(Isp(O )) ⊇ Lang(Isp(O
′
)). (4)
4
Being equivalent, both the prefix space and the index
space share the same regular language (Hopcroft et al.,
2006).
This means that O subsumes O
′
iff the set of candidate
signatures of O includes all the candidate signatures
of O
′
.
The reason why observation subsumption sup-
ports reuse can be roughly explained as follows. The
solution of ℘ yields an automaton µ, a sort of diag-
noser, where each state is marked by a set of diag-
noses and each transition is marked by a label in L .
The language of µ is the subset of the signatures rel-
evant to O that comply with the model of the system,
namely, Lang(µ) ⊆ kO k. The same applies to a new
problem ℘
′
relevant to O
′
. However, if O ⋑ O
′
, that
is, kO k ⊇ kO
′
k, then Lang(µ) ⊇ Lang(µ
′
). In other
words, µ contains all the signatures of µ
′
. This allows
the diagnostic engine to reuse µ in order to generate
µ
′
based on O
′
. The advantage stems from the fact
that such an operation is far more efficient than gen-
erating µ
′
from scratch, which would require heavy
model-based reasoning.
Example 3. With reference to observations O
1
and
O
2
outlined in Fig. 1, and the relevant index spaces in
Fig. 2, it is easy to check that O
1
⋑ O
2
, that is, kO
1
k ⊇
kO
2
k. In other words, each string in Lang(Isp(O
2
)) is
also a string in Lang(Isp(O
1
)).
The problem with observation-subsumption
checking lies on the fact that, establishing whether
we can exploit the knowledge for solving ℘, in
order to solve ℘
′
, requires a considerable amount
of computational resources. Specifically, we need
first generate Isp(O
′
) and, subsequently, compare
Lang(Isp(O
′
)) with each Lang(Isp(O )) in the
knowledge-base, in the hope of finding a subsuming
observation O . Such an approach, based on the gen-
eration of the index space and on regular-language
containment-checking, may be prohibitive in real
applications. In order to cope with this complexity,
we need some alternative checking-techniques.
3 CHECKING SUBSUMPTION
The systematic nature of checking based on the for-
mal definition of subsumption stems primarily on its
lack of prospection (short-sightedness). As a mat-
ter of fact, such a systematic technique does not per-
form any kind of reasoning on the given observations.
Assume the problem of testing O ⋑ O
′
, namely the
checking problem. The idea is to find out some condi-
tions that either imply or are implied by such a re-
lationship. If these conditions can be checked us-
ing a reasonable amount of computational (space and
time) resources, then chances are that we can give an
answer to the checking problem efficiently. Specif-
ically, if a necessary condition N
c
is violated, then
ICEIS 2008 - International Conference on Enterprise Information Systems
46

the answer to the checking problem will be no. Du-
ally, if a sufficient condition S
c
holds, then the an-
swer will be yes. However, if either N
c
holds or S
c
is violated, then the checking problem remains unan-
swered. Necessary conditions and sufficient condi-
tions relevant to the checking problem are given in
Theorem 1 and Theorem 2, respectively. As shown
shortly, these conditions are eventually incorporated
within Algorithm 1 (see below).
Theorem 1. Let O = (N ,L , A ) and O
′
=
(N
′
,L
′
,A
′
) be two temporal observations. Let
n and n
′
be the number of nodes in N and N
′
,
respectively. Let n
ε
and n
′
ε
be the number of nodes
that include the null label ε in N and N
′
, respec-
tively. Let M and M
′
be the multisets of observable
labels occurring in O and O
′
, respectively. Then, O
subsumes O
′
only if the following conditions hold:
n ≥ n
′
(5)
n
ε
− n
′
ε
≥ n− n
′
(6)
M ⊇ M
′
. (7)
Proof. The proof is by contradiction. To prove con-
dition (5), we have to show that O ⋑ O
′
⇒ n ≥ n
′
.
Assume the contrary, namely n
′
> n. Since ∀N
′
∈
N
′
(kN
′
k 6= {ε}), we can make up a temporal se-
quence T by selecting a label ℓ 6= ε for each N
′
∈ N
′
,
where |T| = n
′
. Clearly, T /∈ kIsp(O )k because tem-
poral sequences relevant to O are long at most n.
Hence, kIsp(O )k 6⊇ kIsp(O
′
)k, that is, O 6⋑ O
′
, a con-
tradiction.
To prove condition (6), we have to show that O ⋑
O
′
⇒ n
ε
− n
′
ε
≥ n − n
′
. Assume the contrary, namely
n− n
′
> n
ε
− n
′
ε
or, in other terms,
n− n
ε
> n
′
− n
′
ε
. (8)
Let N
′
ε
= {N
′
| N
′
∈ N
′
,ε ∈ kN
′
k}. Now, consider a
sequence L
′
of labels selected from all nodes of N
′
,
in such a way that ε is chosen for all nodes in N
′
ε
.
Let T
′
be the temporal sequence corresponding to L
′
.
Clearly, |T
′
| = n
′
−n
′
ε
. In consequence, T
′
/∈ kIsp(O )k
because each temporal sequence T relevant to O is
such that |T| ≥ n− n
ε
, that is, based on equation (8),
|T| > n
′
− n
′
ε
, hence, |T| > |T
′
|. Thus, kIsp(O )k 6⊇
kIsp(O
′
)k, that is, O 6⋑ O
′
, a contradiction.
To prove condition (7), we have to show that
O ⋑ O
′
⇒ M ⊇ M
′
. Assume the contrary, namely
M 6⊇ M
′
, that is, M
′
⊃ M . This means that M
′
will
contain k
′
≥ 1 occurrences of a label ℓ, with M in-
cluding k ≥ 0 occurrences of the same label, where
k
′
> k. Choose L
′
so as to include all k
′
occurrences
of ℓ in O
′
. Hence, T
′
will contain exactly k
′
occur-
rences of ℓ. On the other hand, no temporal sequence
L can be composed in O to include the same number
of occurrences of ℓ. Thus, kIsp(O )k 6⊇ kIsp(O
′
)k, that
is, O 6⋑ O
′
, a contradiction.
Corollary 1.1. O subsumes O
′
only if
L ⊇ L
′
. (9)
Proof. Condition (9) is entailed by condition (7) of
Theorem 1, with the latter being necessary for O ⋑
O
′
to hold. Hence, condition (9) too is a necessary
condition for observation subsumption.
Example 4. In Example 3 we have shown that O
1
subsumes O
2
, where such observations are displayed
in Fig. 1. Hence, the conditions relevant to The-
orem 1 are expected to hold for O
1
and O
2
. We
have n
1
= 5, n
2
= 4, n
1
ε
= 3, n
2
ε
= 2. As a mat-
ter of fact, both conditions (5) and (6) hold. More-
over, since M
1
= [a,a, a,b,b,b,b, c, d, f,ε,ε,ε] and
M
2
= [a,a,b,c, d,ε,ε], condition (7) holds too.
The conditions necessary for subsumption stated
in Theorem 1 can be easily checked. Thus, they cor-
respond to the first actions of the checking algorithm.
If one of them is violated, the check terminates im-
mediately with a negative answer. Otherwise, the
check continues by testing a sufficient condition of
subsumption based on the notion of coverage given
in Definition 1 below. Roughly, O covers O
′
when O
is a relaxation of O
′
, inasmuch as an observation is a
relaxation of a system signature.
Definition 1. (Coverage) Let O = (N , L , A ) and
O
′
= (N
′
,L
′
,A
′
) be two temporal observations,
where N = {N
1
,...,N
n
} and N
′
= {N
′
1
,...,N
′
n
′
}. We
say that O covers O
′
, written O D O
′
, iff there ex-
ists a subset
¯
N of N , with
¯
N = {
¯
N
1
,...,
¯
N
n
′
} hav-
ing the same cardinality as N
′
, such that, denoting
N
ε
=
N −
¯
N
, we have:
(1) (ε-coverage): ∀N ∈ N
ε
(ε ∈ kNk);
(2) (logical coverage): ∀i ∈ [1..n
′
] (k
¯
N
i
k ⊇ kN
′
i
k);
(3) (temporal coverage): For each path
¯
N
i
¯
N
j
=
h
¯
N
i
,N
ε
1
,...,N
ε
s
,
¯
N
j
i in O , where
¯
N
i
∈
¯
N ,
¯
N
j
∈
¯
N ,
s ≥ 0, ∀k ∈ [1.. s]
N
ε
k
∈ N
ε
, the following holds
in O
′
: N
′
i
≺ N
′
j
.
Example 5. With reference to the observations dis-
played in Fig. 1, it is easy to show that O
1
D O
2
. As-
sume the subset of N
1
being
¯
N
1
= {N
1
,N
2
,N
4
,N
5
}.
Hence, N
ε
1
= {N
3
}. Clearly, ε-coverage holds, as ε ∈
kN
3
k. Logical coverage holds too, as kN
2
k ⊇ kN
′
1
k,
kN
1
k ⊇ kN
′
2
k, kN
4
k ⊇ kN
′
3
k, and kN
5
k ⊇ kN
′
4
k. It
is easy to check that temporal coverage occurs. For
instance, for hN
1
,N
3
,N
5
i, where N
3
∈ N
ε
1
, we have
N
′
2
≺ N
′
4
in O
2
.
Theorem 2 and Note 1 offer evidence that cover-
age is only sufficient for subsumption, not necessary.
ON CHECKING TEMPORAL-OBSERVATION SUBSUMPTION IN SIMILARITY-BASED DIAGNOSIS OF ACTIVE
SYSTEMS
47

However, in practice, if coverage does not hold, it is
unlikely for subsumption to hold. Note that, since
coverage entails subsumption, the conditions in The-
orem 1 are necessary for coverage too.
Theorem 2. Coverage entails subsumption:
O D O
′
=⇒ O ⋑ O
′
. (10)
Proof. The proof is based on Definition 1 and Defi-
nition 2 (the latter given below).
Definition 2. (Sterile sequence) Let
˜
N =
h
˜
N
1
,...,
˜
N
n
′
i be an ordering
5
of nodes in
¯
N .
The sterile sequence of
˜
N ,
N
ε
0
,N
ε
1
,...,N
ε
n
′
(11)
is a sequence of subsets of N
ε
, called sterile sets, in-
ductively defined as follows:
• (Basis) N
ε
0
is defined by the following two rules:
(1) If N ∈ N
ε
, N is a root of O , then N ∈ N
ε
0
,
(2) If N ∈ N
ε
, all parents of N are in N
ε
0
, then
N ∈ N
ε
0
;
• (Induction) Given N
ε
i
, i ∈ [0..(n
′
− 1)], the suc-
cessive sterile set N
ε
i+1
is defined by the following
two rules:
(3) If N ∈ N
ε
, all parents of N are in
N
∗
i
∪
˜
N
i+1
, then N ∈ N
ε
i+1
,
(4) If N ∈ N
ε
, all parents of N are in
N
∗
i
∪
˜
N
i+1
∪ N
ε
i+1
, then N ∈ N
ε
i+1
,
where N
∗
i
, i ∈ [0.. n
′
], is recursively defined as fol-
lows:
N
∗
i
=
N
ε
0
if i = 0
N
∗
i−1
∪
˜
N
i
∪ N
ε
i
otherwise.
(12)
To prove the theorem, it suffices to show that each
candidate signature S in the index space of O
′
is also
a candidate signature in the index space of O , namely:
∀S ∈ kIsp(O
′
)k (S ∈ kIsp(O )k ). (13)
According to Theorem 1 in (Lamperti and Zanella,
2002), S is the sequence of labels obtained by select-
ing, without violating the precedence constraints of
A
′
, one label from each node in N
′
, and by removing
all the null labels ε. Let
N
′
= h
˜
N
′
1
,...,
˜
N
′
n
′
i (14)
be the ordering of N
′
relevant to the choices of such
labels. Accordingly, the sequence L
′
of the chosen
labels can be written as
L
′
= hℓ | ℓ ∈ k
˜
N
′
i
k,i ∈ [1..n
′
]i (15)
5
An ordering of a set is asequence involving all and only
the elements in the set, without duplicates.
while the candidate signature S is in fact
S = hℓ | ℓ ∈ L
′
,ℓ 6= εi. (16)
We need to show that there exists an ordering N of
N fulfilling the precedence constraints imposed by
A , from which it is possible to select a sequence L of
labels,
L = hℓ
1
,ℓ
2
,...,ℓ
n
i (17)
such that the subsequence of non-null labels in L
equals S:
hℓ | ℓ ∈ L,ℓ 6= εi = S. (18)
Note how N (as well as any other ordering of N ) can
be represented as a sequence of nodes in
¯
N , with each
node being interspersed with (possibly empty) subse-
quences N
ε
i
of nodes in N
ε
, specifically
N = N
ε
0
∪ h
˜
N
1
i ∪ N
ε
1
∪ h
˜
N
2
i ∪ N
ε
2
...h
˜
N
n
′
i ∪ N
ε
n
′
(19)
where
n
′
[
i=1
{
˜
N
i
} =
¯
N ,
n
′
[
i=0
N
ε
i
= N
ε
,
n
′
\
i=0
N
ε
i
=
/
0. (20)
The proof is by induction on L
′
. Let L
′
i
denote the
subsequence of L
′
up to the i-th label, i ∈ [1..n
′
].
Let L
i
denote the subsequence of L relevant to the
choices of labels performed in correspondence of
the labels in L
′
i
. Let S
i
and S
′
i
denote the candidate
signatures corresponding to L
i
and L
′
i
, respectively.
6
(Basis) No label is chosen in O
′
, that is, L
′
0
= hi. We
choose a sequence of empty labels for all the nodes
in N
ε
0
, which is clearly possible according to the
property that N
ε
0
is a sterile set composed of nodes
having ancestors in N
ε
only. In other words, N
ε
0
is
an ordering of N
ε
0
, while L
0
= hε,ε,... ,εi, hence,
S
0
= S
′
0
= hi.
(Induction) We assume that L
i
and L
′
i
,
i ∈ [0..(n
′
− 1)], are such that S
i
= S
′
i
. We also as-
sume that, given the sequence h
˜
N
′
1
,...,
˜
N
′
i
i of chosen
nodes in O
′
, the corresponding sequence of chosen
nodes in O is N
ε
0
∪h
˜
N
1
i∪ N
ε
1
∪h
˜
N
2
i∪ N
ε
2
...h
˜
N
i
i∪ N
ε
i
,
where, ∀k ∈ [1..i], if
˜
N
′
k
is the node N
′
h
in N
′
, then
˜
N
k
is the node
¯
N
h
in
¯
N , and each N
ε
k
is an ordering
of N
ε
k
. We have to show that, once chosen the next
label ℓ ∈ k
˜
N
′
i+1
k, thereby determining L
′
i+1
and
S
′
i+1
, it is possible to choose a node
˜
N
i+1
∈
¯
N that
includes ℓ, and N
ε
i+1
as an ordering of N
ε
i+1
from
which ε is chosen, thereby determining L
i+1
such
that S
i+1
= S
′
i+1
.
6
Note how L
′
i
includes exactly i labels, while, owing to
the ε selected for nodes in N
ε
, the number of labels in L
i
is
possibly greater than i.
ICEIS 2008 - International Conference on Enterprise Information Systems
48

Let N
′
j
be the node in N
′
= {N
′
1
,...,N
′
n
′
} cor-
responding to
˜
N
′
i+1
. According to logical cover-
age in Definition 1, there exists a node
¯
N
j
in
¯
N =
{
¯
N
1
,...,
¯
N
n
′
} such that k
¯
N
j
k ⊇ k
¯
N
′
j
k, in other words,
¯
N
j
includes ℓ. We consider
˜
N
i+1
= N
j
. In order for
¯
N
j
to be actually chosen, we have to show that each
parent node N of
¯
N
j
in O was already considered, that
is, N belongs to the prefix of
˜
N relevant to L
i
. Two
cases are possible for N:
(a) N is a node
¯
N
k
∈
¯
N . On the one hand, owing
to temporal coverage,
¯
N
k
7→
¯
N
j
in O entails N
′
k
≺
N
′
j
in O
′
. On the other, since N
′
j
was chosen in
O
′
, all its parent nodes must have been considered
already, that is, N
′
k
∈ h
˜
N
′
1
,...,
˜
N
′
i
i. Since, based
on the assumption of Induction, we always choose
for each node in N
′
m
∈ N
′
the corresponding node
¯
N
m
∈
¯
N , it is possible to claim that
¯
N
k
was already
considered in O , that is,
¯
N
k
∈ h
˜
N
1
,...,
˜
N
i
i.
(b) N ∈ N
ε
. We consider each path N
a
N in O such
that N
a
is the first ancestor of N (possibly N itself),
where either N
a
is a root of O or N
a
∈
¯
N . Let N
a
be the set of such ancestors. We show that each
node N
a
∈ N
a
has been considered already. Two
cases are possible: either N
a
∈ N
ε
or N
a
∈
¯
N . In
the first case, N
a
is a node in the sterile set N
ε
0
and, hence, it has been considered in N
ε
0
already
(see Basis). In the second case (N
a
∈
¯
N ), let
¯
N
h
be
the node in
¯
N correspondingto N
a
. We consider a
path
¯
N
h
N 7→
¯
N
j
. Since between
¯
N
h
and
¯
N
j
are
only nodes in N
ε
, temporal coverage implies that
N
′
h
≺ N
′
j
in O
′
, where N
′
h
is the node in N
′
corre-
sponding to
¯
N
h
. Thus, N
′
h
was already considered
in O
′
. As, based on the assumption in Induction,
we always choose in O the corresponding node of
that chosen in O
′
, this implies that
¯
N
h
was already
considered in O too. We conclude that all nodes
in N
a
have been considered. Now, it is clear that
N is either in N
a
or N is a node belonging to the
sterile set of some node in N
a
. In either case, ow-
ing to the assumption of Induction, N must have
been considered already. In other words, all par-
ents of
¯
N
j
have been chosen already, thereby al-
lowing
¯
N
j
itself, alias
˜
N
i+1
, to be chosen. Further-
more, based on the definition of sterile sequence,
we may also consider an ordering N
ε
i+1
of N
ε
i+1
and choose label ε for each of such nodes, thereby
leading to the conclusion that S
i+1
= S
′
i+1
.
Note 1. Coverage is stronger than subsumption,
namely:
O ⋑ O
′
6⇒ O D O
′
. (21)
To be convinced, it suffices to show an example in
which subsumption holds while coverage does not.
Consider two observations, O = (N , L , A ) and O
′
=
(N
′
,L
′
,A
′
), where N = {N
1
,N
2
}, N
′
= {N
′
1
,N
′
2
},
L = L
′
= {a}, A = {N
1
7→ N
2
}, A
′
=
/
0, and kN
1
k =
kN
2
k = kN
′
1
k = kN
′
2
k = {a}, as displayed in Fig. 3.
Figure 3: Observations O (left) and O
′
(right).
Clearly,
¯
N = N and N
ε
=
/
0. Note how, unlike O ,
since A
′
=
/
0, O
′
does not force any temporal con-
straint between N
1
and N
2
. Incidentally, both observa-
tions involvejust one candidate signature, namely S =
ha,ai. Thus, since kIsp(O )k = kIsp(O
′
)k = {ha,ai},
both observations subsume each other, in particular
O ⋑ O
′
. However, it is easy to realize that O does not
cover O
′
, namely O 6D O
′
. In fact, due to the sym-
metry of O
′
, we can choose any of the two possible
associations between nodes in O and nodes in O
′
, for
instance,
¯
N = {N
1
,N
2
}. Based on Definition 1, on
the one hand, both ε-coverage and logical coverage
hold. On the other, temporal coverage is missing, as
for N
1
7→ N
2
in O , we have N
′
1
6≺ N
′
2
. The same neg-
ative result occurs for
¯
N = {N
2
,N
1
}. In other terms,
O 6D O
′
.
4 TESTING COVERAGE
In this section we give an abstract, pseudo-coded
implementation of subsumption-checking via cover-
age. Specifically, Algorithm 1 tests both the neces-
sary conditions of Theorem 1 and the coverage rela-
tionship. A tracing of the algorithm on observations
in Fig. 1 is provided in Example 6.
Algorithm 1. (COVERS) The Covers function (lines
1–41) takes as input two observations, O and O
′
, and
outputs a Boolean value indicating whether or not O
covers O
′
. The body of Covers is outlined in lines
30–41. In lines 31–32, the observation parameters for
O and O
′
are set. Then, at line 33, conditions (5) and
(6) of Theorem 1, along with condition (9) of Corol-
lary 1.1, are checked. In lines 36–38, the multisets
M and M
′
of instances of labels are created, with
the former decremented by d = (n − n
′
) instances of
label ε, which is the cardinality of (N − N
′
). This
allows the algorithm to retain a sufficient number of
spare nodes in N that contain ε, namely N
ε
in Def-
inition 1. At line 39, condition (7) of Theorem 1 is
ON CHECKING TEMPORAL-OBSERVATION SUBSUMPTION IN SIMILARITY-BASED DIAGNOSIS OF ACTIVE
SYSTEMS
49

checked. The algorithm yields
¯
N , the subset of N
that is associated with N
′
in Definition 1, by build-
ing the set R of associations through the call to the
auxiliary function CovStep at line 40. The specifica-
tion of CovStep is given in lines 3–29. Besides O ,
O
′
, M , and M
′
, it takes as input C and C
′
, the set of
nodes already considered in O and O
′
, respectively,
along with d, the number of nodes in N
ε
not yet con-
sidered, and R , the set of associations made up so
far. The body of CovStep starts at line 10, where the
cardinality of R is tested: if R contains n
′
pairs, it
means that all nodes in N
′
have been considered and
¯
N is completed, thereby, coverage holds. Otherwise,
a new node N
′
in O
′
is considered at line 11, such that
all its parent nodes have been considered already. At
line 12, the set F of nodes in O is created, which in-
cludes the unconsidered nodes of O with all parents
already in C . A loop for each node N in F is iterated
in lines 13–27. First, logical coverage and contain-
ment relationship of labels are tested (line 14). Then,
the set N
a
of the nearest ancestors
7
of N which have
been already involved in the associations of R is in-
stantiated (line 15). This allows temporal-coverage
checking (line 16). If the latter succeeds, CovStep is
recursively called at line 17, with new actual param-
eters: the sets C and C
′
of considered nodes are ex-
tended with N and N
′
, respectively, the multisets M
and M
′
are decremented by the labels in N and N
′
,
respectively, while R is extended with the new pair
(N,N
′
). If such a call succeeds, the current activation
of CovStep succeeds too (line 18). If not, or either log-
ical or temporal coverage fails, a chance still remains
by assuming N ∈ N
ε
: this is viable only on condition
that N include ε, there exists at least one spare node
in N
ε
(d > 0), and the multiset M contains M
′
once
decremented by the labels of N, ε aside (line 22)
8
. If
so, a different recursive call to CovStep is performed
at line 23, with the changed parameters being the (ex-
tended) set C of consumed nodes in O , the (decre-
mented) multiset M , and the decremented value of d.
If such a call succeeds, the current activation of Cov-
Step succeeds too. If not, the loop is iterated and a
new node in F is tried. If the computation exits the
loop in a natural way, it means that no node can be
associated with N
′
within this computational context,
thereby causing the current activation of CovStep to
fail (line 28).
7
The nearest ancestors of a node are not necessarily its
parents, since a parent node may not belong to R (N ), as it
is included in N
ε
.
8
When a spare node is consumed, ε is retained in M
because. at line 38, all instances of ε relevant to spare nodes
were removed from M already.
1. function Covers(O ,O
′
): Bool
2. O = (N , L ,A ), O
′
= (N
′
,L
′
,A
′
): observations;
3. function CovStep(O , O
′
,C ,C
′
,M ,M
′
,d,R ): Bool
4. O = (N , L ,A ), O
′
= (N
′
,L
′
,A
′
): observations,
5. C ,C
′
: the set of consumed nodes for O and O
′
,
6. M ,M
′
: the multisets of labels in O and O
′
,
7. d: the number of nodes in N that can still be in N
ε
,
8. R ⊆ N × N
′
: a relation on N and N
′
;
9. begin {CovStep}
10. if |R | = n
′
then return true end-if;
11. Pick up a node N
′
∈ (N
′
− C
′
) with parents in C
′
;
12. F := {N | N ∈ (N −C ), all parents of N are in C };
13. for each N ∈ F do
14. if kNk ⊇ kN
′
k ∧ (M − kNk) ⊇ (M
′
− kN
′
k) then
15. N
a
:= the set of nearest ancestors of N in R (N );
16. if ∀N
a
∈ N
a
,(N
a
,N
′
a
) ∈ R (N
′
a
≺ N
′
) then
17. if CovStep(O ,O
′
,C ∪ {N}, C
′
∪ {N
′
},M − kNk,
M
′
− kN
′
k,d,R ∪ {(N,N
′
)}) then
18. return true
19. end-if
20. end-if
21. end-if;
22. if ε ∈ kNk ∧ d > 0 ∧ (M − (kNk − {ε})) ⊇ M
′
then
23. if CovStep(O ,O
′
,C ∪ {N},C
′
,
M − (kNk − {ε}),M
′
,d −1, R ) then
24. return true
25. end-if
26. end-if
27. end-for;
28. return false
29. end {CovStep};
30. begin{Covers}
31. n := |N |; n
ε
:= {N | N ∈ N , ε ∈ kNk};
32. n
′
:= |N
′
|; n
′
ε
:= {N
′
| N
′
∈ N
′
,ε ∈ kN
′
k};
33. if n < n
′
∨ n
ε
− n
′
ε
< n− n
′
∨ L 6⊇ L
′
then
34. return false
35. end-if:
36. Create the multisets M and M
′
of labels in O , O
′
;
37. d := n− n
′
;
38. Remove d instances of label ε from M ;
39. if M 6⊇ M
′
then return false end-if;
40. return CovStep(O ,O
′
,
/
0,
/
0,M , M
′
,d,
/
0)
41. end {Covers}.
Example 6. With reference to the observations in
Fig. 1, consider the run of Covers(O
1
,O
2
). Since, ac-
cording to Example 4, all the necessary conditions of
Theorem 1 hold, we focus our attention on the first
call to CovStep at line 40.
Depicted in Fig. 4 is the tree of the recursive ac-
tivations to CovStep, where each node i corresponds
to the i-th call (dashed nodes correspond to calls at
line 23, with the others corresponding to line 17).
Figure 4: Activation tree for CovStep in Example 6.
ICEIS 2008 - International Conference on Enterprise Information Systems
50
Table 1: Tracing of Covers(O
1
,O
2
) in Example 6.
Id C C
′
M M
′
d R
1
/
0
/
0 {a,a,a,b,b,b,b,c, d, f,ε, ε} {a,a,b,c,d,ε, ε} 1
/
0
2 {1}
/
0 {a,a,b,b,b,c,d, f, ε,ε} {a,a,b,c,d,ε,ε} 0
/
0
3 {1,2} {1
′
} {a,b,b,c,d, f, ε,ε} {a,b,c,d,ε,ε} 0 {(2,1
′
)}
4 {2} {1
′
} {a,a,b,b,b,c,d, f, ε,ε} {a,b,c,d,ε,ε} 1 {(2,1
′
)}
5 {1,2} {1
′
,2
′
} {a,b,b,c,d, f, ε} {a,c,d,ε} 1 {(2,1
′
),(1,2
′
)}
6 {1,2,3} {1
′
,2
′
} {a,b,b,c,d,ε} {a,c,d,ε} 0 {(2,1
′
),(1,2
′
)}
7 {1,2,3,4} {1
′
,2
′
,3
′
} {a,b,ε} {a,ε} 0 {(2,1
′
),(1,2
′
),(4,3
′
)}
8 {1,2,3,4,5} {1
′
,2
′
,3
′
,4
′
}
/
0
/
0 0 {(2,1
′
),(1,2
′
),(4,3
′
),(5,4
′
)}
Relevant details are given in Table 1, with Id being
the identifier of the call, while the other columns in-
dicate the actual parameters of the call (observation
nodes are identified by the corresponding subscripts).
The computation is described by the following steps,
where item numbers stand for activation identifiers,
namely Id.
1. N
′
= 1
′
, F = {1, 2}. Within the loop (line 13),
choosing N = 1 makes the multiset containment
false (line 14). However, since condition at line 22
holds for N, a recursive call to CovStep is per-
formed at line 23 (see Id = 2 in Table 1).
2. N
′
= 1
′
, F = {2, 3}. With N = 2, a recursive call
is performed at line 17 (Id = 3 in Table 1).
3. N
′
= 2
′
, F = {3,4}. With N = 3, logical coverage
fails, as kNk 6⊇ kN
′
k. Besides, although ε ∈ kNk,
condition at line 22 is false because d = 0 (no fur-
ther spare nodes to assume in N
ε
). Thus, a new it-
eration of loop at line 13 is performed with N = 4:
logical coverage fails, while condition at line 22 is
false (since d = 0 and ε /∈ kNk). This causes the
control to return to the second call, where condi-
tion at line 22 is false. Therefore, a new iteration
of loop at line 13 is performed, now with N = 3.
Since both checks at lines 14 and 22 fail, the con-
trol returns to the first call, where N = 2 is cho-
sen: this allows the fourth recursive call at line 17
(Id = 4).
4. N
′
= 2
′
, F = {1, 4}. With N = 1, a recursive call
is performed at line 17 (Id = 5).
5. N
′
= 3
′
, F = {3,4}. With N = 3, logical coverage
fails. However, since condition at line 22 holds, a
recursive call is performed at line 23 (Id = 6).
6. N
′
= 3
′
, F = {4}. With N = 4, a recursive call is
performed at line 17 (Id = 7).
7. N
′
= 4
′
, F = {5}. With N = 5, a recursive call is
performed at line 17 (Id = 8).
8. At line 10, since |R | = 4, CovStep succeeds.
Proposition 1. Algorithm 1 is a sound and complete
implementation of coverage:
Covers(O ,O
′
) ⇐⇒ O D O
′
. (22)
Proof (sketch). To prove equivalence (22), we first
show
Covers(O ,O
′
) =⇒ O D O
′
. (23)
Assuming Covers(O ,O
′
) succeeding means that the
call to CovStep at line 40 returns true. Function Cov-
Step recursively instantiates the set R of associations
of nodes (N,N
′
), for which both logical coverage (line
14) and temporal coverage (line 16), required by Def-
inition 1, hold. Moreover, ε-coverage is supported by
conditions at line 22 and the initialization at lines 36–
38, which allow for retaining the (n− n
′
) nodes of N
ε
once R is completed (line 10). In other words, entail-
ment (23) holds. Then, we have to show
O D O
′
=⇒ Covers(O ,O
′
). (24)
The proof is by contradiction. Assume that O D O
′
,
while Covers(O , O
′
) = false. Based on Definition 1,
let R
∗
= {(
¯
N
1
,N
′
1
),...,(
¯
N
n
′
,N
′
n
′
)} denote the relation
between
¯
N and N
′
. Based on a run of Covers, we
show that Covers necessarily makes up R = R
∗
. The
proof is by induction on R . Note how we can restrict
our analysis to the recursive call to CovStep, as lines
31–39 simply check the necessary conditions of
subsumption stated by Theorem 1 and Corollary 1.1.
In fact, since coverage entails subsumption (Theo-
rem 2), such conditions are necessary for coverage
too, in other words, the computation surely reaches
the call to CovStep at line 40. Moreover, such call
is supposed to return false (owing to the assumption
Covers(O ,O
′
) = false).
(Basis) Focus on the first call to CovStep, where C ,
C
′
, and R are empty, and consider the (first) node N
′
chosen at line 11. Let N
′
correspond to the j-th node
in N
′
, namely N
′
j
. Let
¯
N
j
be the node in
¯
N associated
with N
′
j
in R
∗
, namely (
¯
N
j
,N
′
j
) ∈ R
∗
. Based on
Definition 1, temporal coverage requires that, for
each path
¯
N
i
¯
N
j
in O , where all intermediate
nodes in the path are in N
ε
, we have N
′
i
≺ N
′
j
in O
′
.
However, none of such paths exists, as N
′
= N
′
j
is
chosen with C
′
=
/
0, that is, N
′
has no parent nodes.
Consequently, all ancestors of
¯
N
j
in O (if any) are
in N
ε
, that is, they contain label ε. Since CovStep
ON CHECKING TEMPORAL-OBSERVATION SUBSUMPTION IN SIMILARITY-BASED DIAGNOSIS OF ACTIVE
SYSTEMS
51

is supposed to fail, it will try all choices of N in F .
Two cases are possible: either
¯
N
j
is a root of O or all
ancestors of
¯
N
j
are in N
ε
. In the first case, N =
¯
N
j
is associated in R with N
′
= N
′
j
within the recursive
call to CovStep at line 17. In the second case, the
same association will be created after a number of
recursive calls of CovStep at line 23, as all calls
to CovStep are assumed to fail (including the one
creating such association). Thus, in any case, the first
choice of N
′
will led to an association (N,N
′
) which
is in R
∗
too.
(Induction) Assume, in the current call to CovStep,
R = {(
¯
N
c
1
,N
′
c
1
),...,(
¯
N
c
k
,N
′
c
k
)}, where R ⊂ R
∗
, that
is, all associations yielded by CovStep are in R
∗
too.
Let
¯
N
c
and N
′
c
denote the projections of R on N
and N
′
, respectively. Now, consider the next choice
of N
′
at line 11. Let N
′
correspond to the j-th node in
N
′
, namely N
′
j
. Let
¯
N
j
be the node in
¯
N associated
with N
′
j
in R
∗
, namely (
¯
N
j
,N
′
j
) ∈ R
∗
. Based on
Definition 1, temporal coverage requires that, for
each path
¯
N
i
¯
N
j
in O , where all intermediate nodes
in the path are in N
ε
, N
′
i
≺ N
′
j
holds in O
′
. This
implies that all N
′
i
are in N
′
c
and, in consequence of
the inductive assumption, all
¯
N
i
are in
¯
N
c
. Hence,
following the same argumentation outlined in Basis,
¯
N
j
can be considered and associated with N
′
j
. Thus,
(
¯
N
j
,N
′
j
) is inserted into R . This leads to the claim
that (R ∪ {(
¯
N
j
,N
′
j
)}) ⊆ R
∗
, which concludes the
proof of Induction. Thus, equation (24) is proved.
5 EXPERIMENTAL RESULTS
A number of experiments were carried out in order to
assess the coverage approach to subsumption check-
ing based on different classes of observations. We ran
subsumption checking using two different algorithms
prototyped in Haskell functional language (Thomp-
son, 1999), namely Subsumes and Covers. The for-
mer is strictly based on the definition of subsumption
and requires testing index-space (automaton) contain-
ment. We considered three classes of observations,
namely disconnected, connected, and linear. In dis-
connected observations, no temporal constraints are
given among nodes, thereby maximizing temporal un-
certainty. Instead, in connected observations, each
node is temporally linked with other nodes. Linear
observations are a subclass of connected observations
where no temporal uncertainty occurs. The experi-
mental results in this paper refer to connected obser-
vations. In order to stress the computation, we chose
observations for which subsumption hold, so that the
necessary conditions in Theorem 1 always hold.
9
0
1000
2000
3000
4000
Time[s]
0 10 20
Observation nodes
0
1
2
3
4
Time[s]
0 10 20
Observation nodes
Figure 5: Checking subsumption: time response.
Shown in Fig. 5 is the response time for the two
algorithms, with the x-axis marked by the number of
nodes in the involved observations. Precisely, the y-
axis indicates the time for Subsumes (dashed line, on
the left) and Covers (plain line, on the right) to emit
the relevant verdict. Considering the different scale
of the y-axis, the comparison is striking in favor of
Covers. Displayed in Fig. 6 is the maximum space
allocation for the two algorithms, which shows how
no considerable difference exists between them.
1
2
3
Space[MB]
0 10 20
Observation nodes
Figure 6: Checking subsumption: space allocation.
6 CONCLUSIONS
A technique for checking observation-subsumptionin
diagnosis of DESs has been proposed. This check is
required to pursue similarity-based diagnosis, where
the solution of a diagnostic problem is possibly sup-
ported by the solution of a previously-solved prob-
lem stored in a knowledge-base. The solution to such
checking-problem can be provided strictly based on
the definition of observation-subsumption, which re-
quires the generation and comparison of the index
spaces of the two observations, where an index space
is an acyclic automaton. Since index-space genera-
tion and processing are computationally complex, an
alternativetechnique has been envisagedand formally
defined in this paper, which exploits a number of nec-
essary conditions, as well as a sufficient condition, for
9
In fact, when one of such conditions is violated, Covers
is increasingly more efficient than Subsumes.
ICEIS 2008 - International Conference on Enterprise Information Systems
52

subsumption to hold. The latter is based on the notion
of coverage, which allows the direct comparison of
the two observations without any index-space gener-
ation or manipulation. The new approach has been
tested and compared with the previous (systematic)
approach. Experimental results indicate that the tech-
nique is considerably worthwhile as to time complex-
ity. However, since the implementation is based on
a pure functional language, chances are that imple-
menting it through a more efficient general-purpose
language is bound to still better figures.
REFERENCES
Baroni, P., Lamperti, G., Pogliano, P., and Zanella, M.
(1999). Diagnosis of large active systems. Artificial
Intelligence, 110(1):135–183.
Brand, D. and Zafiropulo, P. (1983). On communicating
finite-state machines. Journal of ACM, 30(2):323–
342.
Cassandras, C. and Lafortune, S. (1999). Introduction to
Discrete Event Systems, volume 11 of The Kluwer In-
ternational Series in Discrete Event Dynamic Systems.
Kluwer Academic Publisher, Boston, MA.
Cerutti, S., Lamperti, G., Scaroni, M., Zanella, M., and
Zanni, D. (2007). A diagnostic environment for au-
tomaton networks. Software – Practice and Experi-
ence, 37(4):365–415. DOI: 10.1002/spe.773.
Chen, Y. and Provan, G. (1997). Modeling and diagnosis
of timed discrete event systems - a factory automation
example. In American Control Conference, pages 31–
36, Albuquerque, NM.
Console, L., Picardi, C., and Ribaudo, M. (2002). Process
algebras for systems diagnosis. Artificial Intelligence,
142(1):19–51.
Debouk, R., Lafortune, S., and Teneketzis, D. (2000). Co-
ordinated decentralized protocols for failure diagnosis
of discrete-event systems. Journal of Discrete Event
Dynamic Systems: Theory and Application, 10:33–86.
Hopcroft, J., Motwani, R., and Ullman, J. (2006). Introduc-
tion to Automata Theory, Languages, and Computa-
tion. Addison-Wesley, Reading, MA, third edition.
Lamperti, G. and Zanella, M. (2002). Diagnosis of discrete-
event systems from uncertain temporal observations.
Artificial Intelligence, 137(1–2):91–163.
Lamperti, G. and Zanella, M. (2003). Diagnosis of Active
Systems – Principles and Techniques, volume 741 of
The Kluwer International Series in Engineering and
Computer Science. Kluwer Academic Publisher, Dor-
drecht, NL.
Lamperti, G. and Zanella, M. (2004). A bridged diagnostic
method for the monitoring of polymorphic discrete-
event systems. IEEE Transactions on Systems, Man,
and Cybernetics – Part B: Cybernetics, 34(5):2222–
2244.
Lamperti, G. and Zanella, M. (2006a). Flexible diagnosis of
discrete-event systems by similarity-based reasoning
techniques. Artificial Intelligence, 170(3):232–297.
Lamperti, G. and Zanella, M. (2006b). Incremental pro-
cessing of temporal observations in supervision and
diagnosis of discrete-event systems. In Eighth Inter-
national Conference on Enterprise Information Sys-
tems – ICEIS’2006, pages 47–57, Paphos, Cyprus.
Lunze, J. (2000). Diagnosis of quantized systems based on
a timed discrete-event model. IEEE Transactions on
Systems, Man, and Cybernetics – Part A: Systems and
Humans, 30(3):322–335.
Pencol´e, Y. (2000). Decentralized diagnoser approach: ap-
plication to telecommunication networks. In Eleventh
International Workshop on Principles of Diagnosis –
DX’00, pages 185–192, Morelia, MX.
Pencol´e, Y. and Cordier, M. (2005). A formal framework
for the decentralized diagnosis of large scale discrete
event systems and its application to telecommunica-
tion networks. Artificial Intelligence, 164:121–170.
Roz´e, L. and Cordier, M. (2002). Diagnosing discrete-event
systems: extending the ‘diagnoser approach’ to deal
with telecommunication networks. Journal of Dis-
crete Event Dynamic Systems: Theory and Applica-
tion, 12:43–81.
Sampath, M., Lafortune, S., and Teneketzis, D. (1998). Ac-
tive diagnosis of discrete-event systems. IEEE Trans-
actions on Automatic Control, 43(7):908–929.
Sampath, M., Sengupta, R., Lafortune, S., Sinnamohideen,
K., and Teneketzis, D. (1995). Diagnosability of
discrete-event systems. IEEE Transactions on Auto-
matic Control, 40(9):1555–1575.
Sampath, M., Sengupta, R., Lafortune, S., Sinnamohideen,
K., and Teneketzis, D. (1996). Failure diagnosis using
discrete-event models. IEEE Transactions on Control
Systems Technology, 4(2):105–124.
Schullerus, G. and Krebs, V. (2001). Diagnosis of a class of
discrete-event systems based on parameter estimation
of a modular algebraic model. In Twelfth International
Workshop on Principles of Diagnosis – DX’01, pages
189–196, San Sicario, I.
Thompson, S. (1999). Haskell – The Craft of Functional
Programming. Addison-Wesley, Harlow, UK.
Zad, S., Kwong, R., and Wonham, W. (1999). Fault di-
agnosis in timed discrete-event systems. In 38th IEEE
Conference on Decision and Control – CDC’99, pages
1756–1761, Pheonix, AZ. IEEE, Piscataway, NJ.
ON CHECKING TEMPORAL-OBSERVATION SUBSUMPTION IN SIMILARITY-BASED DIAGNOSIS OF ACTIVE
SYSTEMS
53
