
USER BEHAVIOR UNDER THE MICROSCOPE
Can the Behavior Indicate a Web User’s Task?
Anne Gutschmidt and Clemens H. Cap
Computer Science Department, Albert-Einstein-Str. 21, 18059 Rostock, Germany
Keywords:
User tasks, user behavior, exploratory study, automatic user task identification.
Abstract:
The automatic recognition of a user’s current task by the surfing behavior requires detailed knowledge of the
relationship between task and behavior. An exploratory study was conducted where 20 participants performed
exercises on a given Web site. These exercises corresponded to the predefined user tasks Fact Finding, Infor-
mation Gathering and Just Browsing following present research on user activities. The resulting behavior was
recorded in detailed event log files which contain every action performed in the browser, such as mouse moves
and clicks, scrolling, the use of the back button etc. The analysis of variance indicates that the three tasks can
be differentiated with a combination of selected behavioral attributes.
1 INTRODUCTION
Recognizing the user’s current task only by the
behavior is an ambitious objective. If a user’s
task was known, various ways of support could be
achieved. Present personalization mechanisms, e.g.
recommender systems such as Amazon’s, work on the
basis of long term user behavior and information ex-
plicitly given, like product evaluations and purchases
(Linden et al., 2003). They do not take into consider-
ation the user’s current needs, e.g. if the user is look-
ing something up quickly or just searching for enter-
tainment, or if the person intends to collect informa-
tion about a topic. This knowledge could improve the
quality of many personalization mechanisms such as
link suggestions.
The problem is that not every little bit of the be-
havior, but only a selection of behavioral attributes, is
crucial in identifying the user’s task. An exploratory
study was conducted to determine which attributes
may be suitable for task recognition. Two aspects of
the study must be particularly emphasized:
First, the task is always known in the experiment
and, thus, represents the independent variable. The
behavior, in contrast, is considered dependent on the
task. This way, the participants’ intentions are always
known and the relationship between task and behavior
can be scrutinized. In later practice, the direction will
naturally be reverse with the user task being deduced
from the behavior.
Second, the behavior is recorded in form of a de-
tailed log containing every action processed in the
Web browser, like mouse clicks, scroll moves, the us-
age of single pages, tabs and even browser buttons
and menus. This allows various evaluations on the
data which go beyond plain click stream analyses, like
(Das et al., 2007) and (G
´
ery and Haddad, 2003).
The procedure of the study is based on three user
tasks following recent publications in this field such
as (Kellar et al., 2006): Fact Finding, Information
Gathering and Just Browsing. First evaluations on the
collected data indicate that there exist significant dif-
ferences between these tasks with regard to the overall
duration of a task, the average time a user was look-
ing at a page and the number of pages the user has
looked at per minute. As the experiment was con-
ducted on the Web site of an on-line newspaper, also
specific attributes of the behavior, like the number of
news categories visited, were investigated, which also
revealed significant differences between the tasks.
The paper is structured as follows: In the next
section the state of the art concerning user task tax-
onomies and task recognition is presented. After-
wards, the exploratory study is described followed by
first results of the analysis of variance and t-tests. At
the end a summary is given.
215
Gutschmidt A. and H. Cap C. (2008).
USER BEHAVIOR UNDER THE MICROSCOPE - Can the Behavior Indicate a Web User’s Task?.
In Proceedings of the Fourth International Conference on Web Information Systems and Technologies, pages 215-222
DOI: 10.5220/0001526202150222
Copyright
c
SciTePress

2 USER TASKS AND THEIR
RECOGNITION
The first step towards user task identification is the
definition of user tasks and bringing them into a tax-
onomy. Then it is possible to look for ways of recog-
nizing the tasks.
In the field of discovering user needs, several
branches have evolved. One branch deals with Web
search, where search engine queries are assigned to
certain goals which can be interpreted as user tasks.
(Broder, 2002) formulated three groups of informa-
tion needs in the context of Web queries: naviga-
tional (searching for a particular Web site), informa-
tional (searching for information about a topic, one
site is not sufficient) and transactional (finding sites
that enable transactions like shopping or downloads).
(Rose and Levinson, 2004) arrived at a similar tax-
onomy, only transactional was replaced by a more
general task, resource, comprising the subtasks ob-
tain, download, entertain and interact. Both (Broder,
2002) and (Rose and Levinson, 2004) do not yet pro-
vide an approach to automatic task identification, but
reinforce their taxonomies by manual classifications.
An approach to identifying tasks is to be found in
(Lee et al., 2005), where only the matching tasks of
(Broder, 2002) and (Rose and Levinson, 2004), nav-
igational and informational, are considered. Using
the features click distribution and anchor-link distri-
bution, good classification results were achieved with
a rate of 80% or more correct classifications, and 90%
when both features were used in combination.
Another branch regarding user tasks deals with
general user activities on the Web. An early sug-
gestion for a user task taxonomy was introduced in
(Byrne et al., 1999). The activities they describe be-
long to a rather low level of abstraction, i.e. they de-
fine tasks like Locate (searching for something on a
Web page, like a word or a picture), Go To (look-
ing for a certain Web page), or Configure (changing
the state of the browser, e.g. through scrolling). More
suggestions of user task taxonomies at higher levels of
abstraction followed, like (Choo et al., 2000; Morri-
son et al., 2001; Sellen et al., 2002). (Kellar et al.,
2006) merged these three approaches and included
findings from their own studies. The resulting taxo-
nomy is described as follows:
• Fact Finding: The users have an exact target in
mind, they are looking for a keyword, a date or a
sentence. Activities belonging to this category are
usually of short duration.
• Information Gathering: The users are searching
for information on a topic, thus, the target is more
open, while still being restricted by the topic. In-
formation Gathering usually takes more time and
need not be completed within one session.
• Just Browsing: The users surf through the Inter-
net as they like and with no particular target in
mind. Activities like these may also be of longer
duration.
• Transaction: The users want to perform trans-
actions like on-line banking or checking their e-
mails on-line.
• Other: This category comprises all activities
which cannot be assigned to any of the other four
categories.
Based on this taxonomy, an attempt of automatic
task identification was made using classification. In
a study, (Kellar et al., 2006) collected log data con-
taining events like the usage of the back, forward and
reload buttons, as well as of bookmarks, hyperlinks,
and the history. One part of the data sets was classi-
fied and served as training data to classify the remain-
ing data sets. On the whole, only 53.8% of the data
sets were classified correctly. The authors see the rea-
son for these results in the strong impact individual
differences have on the surfing behavior (Kellar and
Watters, 2006). However, there may be further rea-
sons: First, differences between Web sites concerning
structure, layout and content certainly have an impact
on the way users surf. Second, the authors considered
only low-level events which probably do not describe
the task-dependent behavior in an appropriate way.
3 THE STUDY
3.1 Set-up
20 university students and employees from different
departments took part in the study. Their average age
was 26.6 years.
The experiment was conducted with each partici-
pant separately, with an investigator leading through
the procedure. The participants had to surf on one
version of a German on-line newspaper, Spiegel On-
line.
1
Exercises were set, where each exercise repre-
sented either Fact Finding, Information Gathering or
Just Browsing following the taxonomy of user tasks
suggested in (Kellar et al., 2006). However, the cat-
egory Transaction was not adapted as activities like
these were not likely to occur in the study. It was de-
cided to restrict the investigations to this Web site in
1
http://www.spiegel.de
WEBIST 2008 - International Conference on Web Information Systems and Technologies
216

order to eliminate the impact other Web sites of dif-
ferent structure and content might have on the users’
behavior. Spiegel Online is structured like many other
on-line newspapers with a start page containing the
latest headlines and links to the different news cate-
gories like politics or economics. For each news cat-
egory, extra index pages are offered, the articles each
span one or more pages.
While the participants were working on the
exercises, each of their actions within the browser
was captured. At the end of the experiment a file
containing all these actions in chronological order
was created. Finally, the participants had to answer a
few questions about their usage of the computer, the
Internet and on-line newspapers as well as about their
browser preferences.
3.2 Exercises
The participants had to go through four exercises
which corresponded to the user tasks Fact Finding,
Information Gathering and Just Browsing:
Exercise 1: The participants were asked to get
familiar with the pages and to browse the Web site
as they liked. The only restriction was to remain on
Spiegel Online. This warm-up phase was meant to
represent Just Browsing. No explicit time limit was
given, but the investigator interrupted the activities
after ten minutes if necessary.
Exercise 2: The participants had to look for a
weather forecast of a certain town for the next day
which corresponded to Fact Finding. The exercise
ended as soon as the target was reached.
Exercise 3: Another Fact Finding exercise was set
which was to find a certain football result.
Exercise 4: The test was concluded with an Informa-
tion Gathering exercise. The participants were asked
to collect information on the G8 summit. As the
newspaper version used for the experiment was from
June 8, 2007, the actual date of the summit, many ar-
ticles about the topic were offered on the Web site
at that time. To motivate the participants they were
informed that they would have to answer a few ques-
tions about the topic afterwards. A time limit of ten
minutes was given.
3.3 Data Collection
A Mozilla Firefox extension was used to capture
events concerning mouse, scrolling, opening and
closing pages and tabs, keyboard and the browser.
Beside mouse clicks, every move of the mouse was
recorded as well as the contact with page elements
like hyperlinks, pictures or headlines. The scroll
record also contained information on how much of the
page was above and below the current view. More-
over, page events, the appearance and disappearance
of pages, were captured. These events need not cor-
respond to the appearance and disappearance into the
user’s sight. Sometimes, users like to load pages in
tabs in the background, so that these pages are not
seen until the tab is selected. That is why tab events
are recorded as well. Furthermore, the usage of the
keyboard is contained in the log. Browser events com-
prise the usage of browser buttons, like “back”, “for-
ward” or “reload”, as well as the usage of all browser
menus.
For each event additional information is saved,
e.g. in the case of a mouse click a description of the
element that was clicked is stored.
3.4 Data Analysis
First comparisons of the three user tasks Fact Finding,
Information Gathering and Just Browsing will be pre-
sented concerning the following behavioral attributes:
• The duration of the exercise which corresponded
to the user tasks
• The average duration of a page view
• The number of page views per minute
• The time spent on the newspaper’s start page in
proportion to the overall duration of the exercise
• The number of different news categories visited
A page view refers to the period of time a user is
looking at a Web page. Pop-up windows and the use
of different tabs are included in this concept; e.g. a
pop-up window ends the page view of the page behind
and starts a new page view for the pop-up window,
whereas loading tabs in the background does not start
a page view, but the selection of a tab does. The page
views were derived from the log together with their
duration and the URL.
The question is between which of the three tasks
significant differences exist considering each of the
five behavioral attributes. Analyses of variance with
repeated measures are applied to find out if such sig-
nificant differences are present. If this is the case, the
outcome will be a p-value smaller than 0.05. To reveal
USER BEHAVIOR UNDER THE MICROSCOPE - Can the Behavior Indicate a Web User’s Task?
217
where the actual differences lie, t-tests with paired
samples are used. Usually, the alpha level is also 0.05,
but as there are more than two groups to be compared,
the Bonferroni correction is applied, which is 1/3α
(0.0167) in this case, to avoid the alpha error cumula-
tion. This correction is applied to all t-tests and leads
to more conservative results. A significant difference
is a hint which behavioral attribute to concentrate on
for an automatic recognition of user tasks.
For the following evaluations, the respective val-
ues of exercise 2 and 3, both belonging to Fact Find-
ing, were merged by taking the average values to ob-
tain one single group for this task.
4 RESULTS
In this section, the results of the analysis of variance
and the t-tests concerning the five above-mentioned
behavioral attributes are presented. Moreover, des-
criptive data in the form of average values and stan-
dard deviations are given. Due to space constraints
only some frequency distributions are presented.
4.1 Task Duration
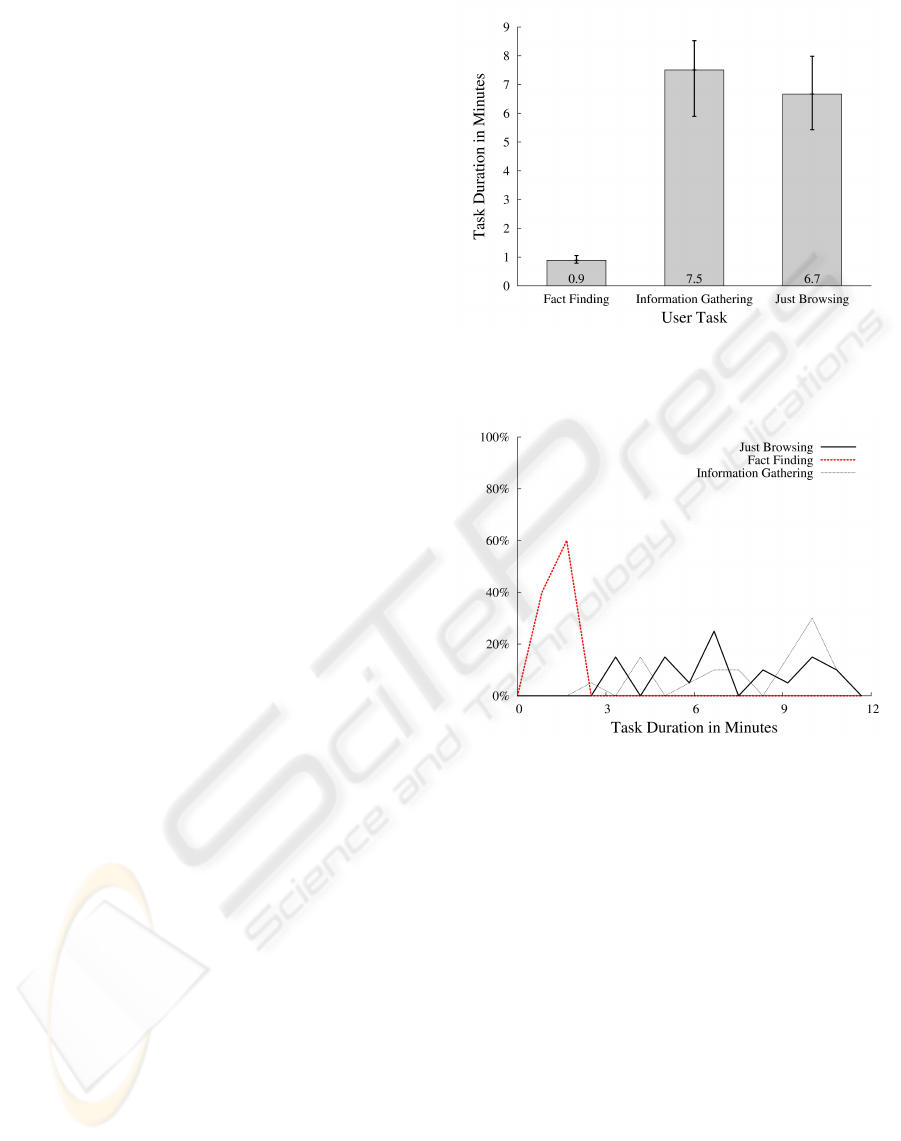
Figure 1 illustrates the average values of the task du-
ration, the time a participant worked on an exercise,
with the concrete values at the bottom of each bar.
The bars are furthermore enhanced with an error bar
depicting the standard deviation. The error bar is
weighted to the top and to the bottom by the propor-
tion of the sum of the squared deviations from the av-
erage value. As can be seen in Figure 1, the overall
duration of the exercises for Fact Finding is shorter
than for the other two tasks. Information Gathering
and Just Browsing seemed to require clearly more
time. This impression is confirmed by the results
of the analysis of variance with repeated measures
with a significance indicated by p < 0.001 (df = 2,
F = 56,405). T-tests with paired samples with an
alpha level of α = 0.0167 reveal significant differ-
ences between Fact Finding and Information Gath-
ering (p < 0.001, df = 19, T = −10.963) and be-
tween Just Browsing and Fact Finding (p < 0.001,
df = 19, T = 9.681). A significant difference between
Just Browsing and Information Gathering is not given
(p = 0.315, df = 19, T = −1.033).
These results match with the picture of the fre-
quency distributions in Figure 2. The Figure also
shows that the frequency distribution for Fact Finding
already comes close to normal distribution whereas
the other two tasks seem to be uniformly distributed.
Figure 1: Overall duration of the exercises depending on the
user task, σ
FF
= 0.27, σ
IG
= 2.6, σ
JB
= 2.5.
Figure 2: The frequency distributions for the attribute task
duration.
Regarding the low number of values, however, this
cannot be considered as certain.
4.2 Average Page View Duration
Looking at Figure 3, Information Gathering is on top
concerning the average duration a user spends on a
Web page. Just Browsing shows a smaller average
page view duration, but the latter is still greater than
the time Fact Finders spend on a single page on av-
erage. The analysis of variance indicates significant
differences between the three user tasks (p < 0.001,
df = 2, F = 11,37). According to the t-tests, these
differences lie between Fact Finding and Informa-
tion Gathering (p = 0.001, df = 19, T = −3.729)
and between Just Browsing and Fact Finding (p =
0.005, df = 19, T = 3.143). With regard to the aver-
age page view duration, Just Browsing and Informa-
tion Gathering do not seem to be significantly differ-
WEBIST 2008 - International Conference on Web Information Systems and Technologies
218
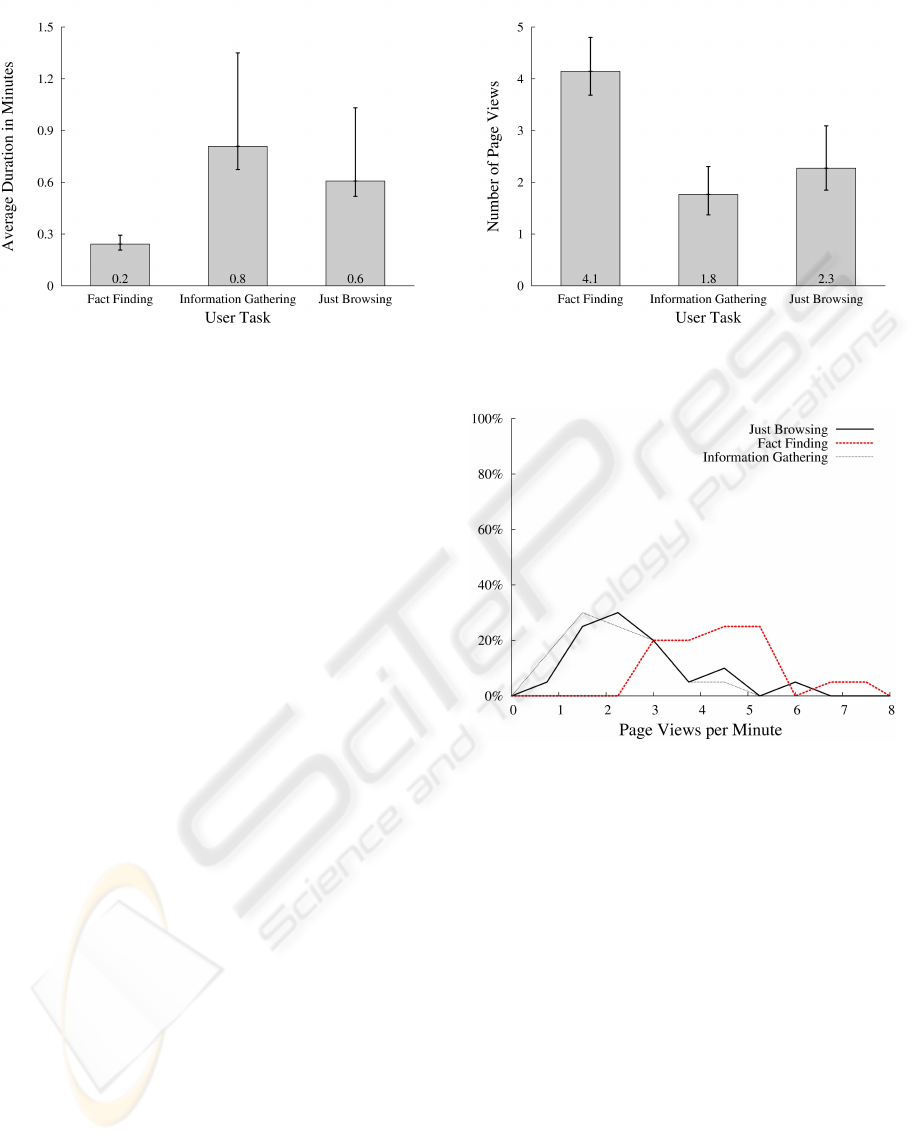
Figure 3: Average page view duration depending on the user
task, σ
FF
= 0.1, σ
IG
= 0.7, σ
JB
= 0.5.
ent (p = 0.026, df = 19, T = −2.414).
The high values of the standard deviations in the
groups Just Browsing and Information Gathering are
remarkable. A reason for this result may be that the
participants were differently motivated when taking
part in the experiment. Another reason could be gen-
eral individual differences in the surfing behavior. If
further tests, however, confirm strong differences be-
tween the individual users, this might turn out to be a
problem for the identification of the user task by this
attribute.
4.3 Number of Page Views Per Minute
Figure 4 indicates that Fact Finders seem to look at
more pages during one minute than it is the case in the
other two groups. This seems self-evident, because
it is probable that users skim rather than read when
looking for a fact. In contrast, the participants seemed
to read more carefully when doing Just Browsing and
Information Gathering. The analysis of variance re-
sults in a p-value p < 0.001 (df = 2, F = 28.349).
The t-tests show significant differences between Fact
Finding and Information Gathering (p < 0.001,
df = 19, T = 7) and between Just Browsing and
Fact Finding (p < 0.001, df = 19, T = −5.293).
There is no significant difference between Just Brows-
ing and Information Gathering (p = 0.111, d f = 19,
T = 1.673).
Figure 5 shows the frequency distributions for all
three tasks. As can be seen, the curves indicate nor-
mal distributions.
Figure 4: The number of page views per minute depending
on the user task, σ
FF
= 1.1, σ
IG
= 0.9, σ
JB
= 1.2.
Figure 5: The frequency distributions for the attribute page
views per minute.
4.4 Time Spent on the Start Page
The behavioral attributes considered so far are quite
general and can be referred to other Web sites as
well. The time spent on the start page compared to
the overall duration, however, is an attribute very spe-
cific to on-line newspapers. As can be seen in Fig-
ure 6, a clear difference shows between Information
Gathering and Just Browsing. It was common with
Just Browsing as well as with Information Gather-
ing that the participants had a few pages which con-
tained a set of useful links and to which they fre-
quently went back to try further interesting links. In
the case of Just Browsing, the start page was such
an important page, whereas pages more specialized
to the given topic were used for Information Gather-
ing. The outcome of the analysis of variance is a p-
value of p = 0.008 (df = 2, F = 5.446), the concrete
significant differences lie, according to the t-tests,
USER BEHAVIOR UNDER THE MICROSCOPE - Can the Behavior Indicate a Web User’s Task?
219
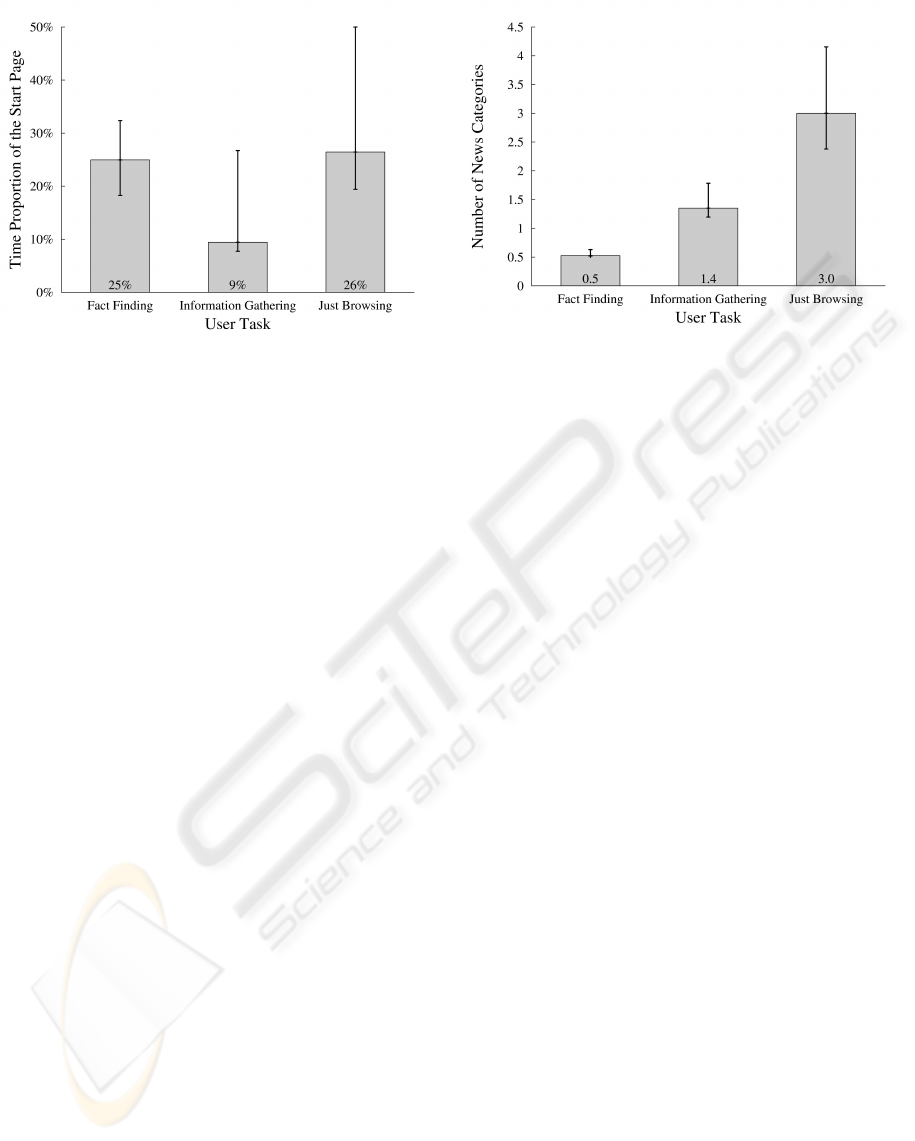
Figure 6: The time proportion of start page visits depending
on the user task, σ
FF
= 14%, σ
IG
= 19%, σ
JB
= 24%.
between Fact Finding and Information Gathering
(p = 0.014, df = 19, T = 2.711) and between Just
Browsing and Information Gathering (p = 0.007,
df = 19, T = 3,051). This time, there is no significant
difference between Just Browsing and Fact Finding
(p = 0.802, df = 19, T = 0.255). Again, the standard
deviations are very high and have to be scrutinized in
further tests.
4.5 Number of News Categories
Another behavioral attribute which is specific to on-
line newspapers is the number of news categories
the users are visiting to reach their goal. The news
categories correspond to the categories presented in
the navigation menu of the considered newspaper,
such as politics, economics, sports etc. Figure 7 in-
dicates differences between all three tasks which is
confirmed by the analysis of variance (p < 0.001,
df = 2, F = 32.351) and the t-tests revealing signifi-
cant differences between Fact Finding and Informa-
tion Gathering (p < 0.001, df = 19, T = −6,020),
Just Browsing and Fact Finding (p < 0.001, d f =
19, T = 6.322) as well as between Just Browsing
and Information Gathering (p < 0.001, df = 19,
T = 4.714). In contrast to Information Gathering and
Fact Finding, Just Browsing meant that the partici-
pants were interested in several different news cat-
egories as they did not have a concrete target and
surfed as they wished. Fact Finding was restricted to a
specific service, the weather forecast, which does not
belong to a news category, and one category, sports.
That is why an average value of 0.5 occurs. The In-
formation Gathering task could have led to different
news categories like politics, economics and culture,
the participants, however, mostly surfed on only one
Figure 7: The number of news categories visited depending
on the user task, σ
FF
= 0.1, σ
IG
= 0.6, σ
JB
= 1.8.
or two categories.
Due to high standard deviations and a lack of a
greater number of realistical Fact Finding and Infor-
mation Gathering examples further tests should be
made to confirm the results of the t-tests. However,
the tendencies revealed here seem promising for the
testing of hypotheses like “Just Browsing involves
more news categories than the other tasks.”
4.6 Conclusions
The analyses of variance and the t-tests indicate
that Fact Finding, Information Gathering as well as
Just Browsing can be distinguished using the above-
mentioned behavioral attributes. It depends on the ob-
served attribute, however, between which tasks signif-
icant differences can be found.
Often, high standard deviations occurred. Their
origin cannot yet be explained: either the participants
were differently motivated in the experiment or their
individual way of surfing is too different or there is
a completely different reason. Further investigations
with higher samples will hopefully bring more insight
into this problem. Individual differences in the behav-
ior might make the respective attribute impossible to
use for the automatic identification of user tasks. On
the other hand, it is interesting to know which behav-
ioral aspects are more than others influenced by the
individual.
With regard to three of five attributes, Fact Find-
ing was always best to differentiate from the other
two user tasks. The differences between Informa-
tion Gathering and Just Browsing were not signifi-
cant with these three attributes, although the differ-
ence concerning the average page view duration ap-
pears promising (p = 0.026).
WEBIST 2008 - International Conference on Web Information Systems and Technologies
220

The attribute describing the time spent on the
start page in proportion to the overall duration indi-
cated a difference between Information Gathering and
Just Browsing which supplements the other three at-
tributes. The number of news categories even showed
significant differences between all three user tasks.
Until now, the identification of user tasks seems to
depend on attributes which are connected to the type
of Web site; e.g. the number of news categories vis-
ited. It will be interesting to find out if this is still
the case when more aspects of the behavior will have
been included.
Up to now, the potential of the collected data
has not yet been exhausted as this is still a work in
progress. Further analyses are necessary. They will
be devoted to aspects like the scroll behavior; e.g.
maybe slow scrolling to the bottom of the page in-
dicates careful reading which might belong to Infor-
mation Gathering. Another aspect is the touching of
page elements, like pictures and titles. It is known
that the position of the mouse cursor is often near the
spot a user is looking at (Chen et al., 2001). More-
over the complexity of the page content, e.g. reflected
in the amount of text, should be included in the anal-
ysis of page view durations. Page revisitations may
also play an important role and should be considered
as well. The list of analyses planned for the future is
obviously long.
Based on the findings presented here and those
further detailed analyses, hypotheses will be formu-
lated which must be tested in a field study. This study
will have to be conducted in a more natural setting;
i.e. the recording tool has to be installed on the partic-
ipants’ computers and watch them in everyday activi-
ties with no exercises being set. The hypotheses will
be like “Fact Finding shows shorter page views than
Just Browsing”, “Fact Finding shows shorter page
views than Information Gathering” and “Just Brows-
ing and Information Gathering are equal in page view
duration.” Confirming and refuting these hypotheses
in a field study will draw a clearer picture of the task-
dependent user behavior and bring us closer to auto-
matic user task recognition.
To sum up, the findings indicate that the behav-
ioral attributes presented here can be useful for an
identification of the user tasks, yet, there is still more
potential in the collected data for further analyses.
5 LIMITATIONS
The study was conducted with only 20 participants as
it was only meant to be exploratory. The output of this
study cannot be generally valid statements; it does,
however, reveal tendencies which will be translated
into hypotheses that allow a more exact investigation
on the relationship between user task and behavior.
The experiment was, moreover, conducted on one
Web site of an on-line newspaper. This was done
to reduce external influences on the behavior and to
guarantee that the test setting is as similar as possible
for each single participant. In a further study more
Web sites will have to be included as well as a wider
range in the age and the professional field of the par-
ticipants.
Due to the age of the newspaper version a few
pages, mostly videos, were no longer available. In
this case, no page view was started as these situations
only lasted for a few seconds and the participants had
nothing to look at. Moreover, interactions with Flash
could not be captured, this involved, however, only
few multi-media pop-ups. Furthermore, changes of
a page’s content in the form of embedded JavaScript
or video were not recorded as these changes did not
really alter the page view itself.
Until now, security and privacy aspects have not
been considered as the data was collected locally. For
a remotely conducted study encrypted transfer of the
event logs has to be implemented. Moreover, a func-
tionality will be added to the event logging software
with which the users can control when they allow the
recording and on which Web sites. Concerning the fu-
ture application, the best protection could be guaran-
teed when the task derivation is realized on the local
computer and only the task name is sent to the Web
site where the personalization takes place.
6 SUMMARY
A study was presented which investigated the rela-
tionship between the task and the behavior of Internet
users. The study was exploratory as the main objec-
tive was to find out which attributes of the behavior
are essential for a differentiation of user tasks. Mul-
tiple restrictions were set to guarantee that the partic-
ipants faced the same conditions. The investigation
focused on one version of an on-line newspaper to re-
duce the number of external influences in the form of
content and structure of the Web site. Three user tasks
were investigated, namely Fact Finding, Information
Gathering and Just Browsing, which were represented
as exercises the participants had to perform during
the experiment. By setting the tasks, the switching
between tasks and other distractions were prevented
and an unambiguous impression of the connection be-
tween behavior and task could be gained.
In this paper five behavioral attributes were intro-
USER BEHAVIOR UNDER THE MICROSCOPE - Can the Behavior Indicate a Web User’s Task?
221

duced, among them the average page view duration
and the number of news categories visited by the par-
ticipants. For each attribute at least two pairs of user
tasks showed a significant difference. Using these at-
tributes, it is possible to differentiate between all three
tasks.
The next step will be to examine further behav-
ioral aspects, e.g. the scrolling. A question of par-
ticular importance will be whether the attributes nec-
essary to recognize a user task are general or can be
applied to only one kind of Web site. In the worst
case this would mean that a task recognition strategy
has to be developed for each type of Web site sepa-
rately with specialized attributes added to the general
attributes.
The findings of this study will be used for the
formulation of hypotheses describing the relationship
between user task and behavior. A further study in a
more natural surrounding with more participants and
thus more data will be conducted to prove these hy-
potheses. On the basis of the outcomes of this next
study, methods of automatic user task recognition can
be developed which will lead to a new quality of
user support. Knowing the user’s task means that the
user’s current needs are revealed. According to the
task, different services could be offered. Fact Find-
ers would certainly welcome a search functionality,
whereas forums concerning the topic which the users
are interested in can be offered when performing In-
formation Gathering. In the case of Just Browsing,
entertainment and distraction play an important role,
thus, these users might be interested in pictures and
videos. Moreover, the method with which link recom-
mendations are found could be altered; in the case of
Fact Finding, text mining is applicable whereas meth-
ods like the association rule mining can be used for
the other two tasks. However, Information Gathering
requires that the recommendations refer to the topic
which is currently of interest. These are only a few
of the manifold applications of user task recognition
which makes clear how important further investiga-
tions on this topic are.
ACKNOWLEDGEMENTS
We would like to thank Friedemann W. Nerdinger and
Stefan Melchior from the chair of Economic Psychol-
ogy at the University of Rostock for their support in
the study design. We also want to thank the peo-
ple who took part in the experiment. This work was
funded by the DFG (Graduate School 466).
REFERENCES
Broder, A. (2002). A taxonomy of web search. SIGIR Fo-
rum, 36(2):3–10.
Byrne, M. D., John, B. E., Wehrle, N. S., and Crow, D. C.
(1999). The tangled web we wove: a taskonomy of
www use. In CHI ’99: Proceedings of the SIGCHI
conference on Human factors in computing systems,
pages 544–551, New York, NY, USA. ACM Press.
Chen, M. C., Anderson, J. R., and Sohn, M. H. (2001).
What can a mouse cursor tell us more?: correlation
of eye/mouse movements on web browsing. In CHI
’01: CHI ’01 extended abstracts on Human factors in
computing systems, pages 281–282, New York, NY,
USA. ACM Press.
Choo, C. W., Detlor, B., and Turnbull, D. (2000). Infor-
mation seeking on the web: An integrated model of
browsing and searching. First Monday, 5(2).
Das, A., Datar, M., and Garg, A. (2007). Google news per-
sonalization: Scalable online collaborative filtering.
In Proceedings of the 16th international conference
on World Wide Web, pages 271–280. ACM Press.
G
´
ery, M. and Haddad, H. (2003). Evaluation of web usage
mining approaches for user’s next request prediction.
In WIDM ’03: Proceedings of the 5th ACM interna-
tional workshop on Web information and data man-
agement, pages 74–81, New York, NY, USA. ACM
Press.
Kellar, M. and Watters, C. (2006). Using web browser inter-
actions to predict task. In WWW ’06: Proceedings of
the 15th international conference on World Wide Web,
pages 843–844, New York, NY, USA. ACM Press.
Kellar, M., Watters, C., and Shepherd (2006). The impact
of task on the usage of web browser navigation mech-
anisms. In Proceedings of Graphics Interface (GI
2006), pages 235–242, Quebec City, Canada. Cana-
dian Information Processing Society.
Lee, U., Liu, Z., and Cho, J. (2005). Automatic identifi-
cation of user goals in web search. In WWW ’05:
Proceedings of the 14th international conference on
World Wide Web, pages 391–400, New York, NY,
USA. ACM Press.
Linden, G., Smith, B., and York, J. (2003). Amazon.com
recommendations - item-to-item collaborative filter-
ing. Internet Computing, IEEE, 7(1):76–80.
Morrison, J. B., Pirolli, P., and Card, S. K. (2001). A taxo-
nomic analysis of what world wide web activities sig-
nificantly impact people’s decisions and actions. In
CHI ’01: CHI ’01 extended abstracts on Human fac-
tors in computing systems, pages 163–164, New York,
NY, USA. ACM Press.
Rose, D. E. and Levinson, D. (2004). Understanding user
goals in web search. In WWW ’04: Proceedings of
the 13th international conference on World Wide Web,
pages 13–19, New York, NY, USA. ACM Press.
Sellen, A. J., Murphy, R., and Shaw, K. L. (2002). How
knowledge workers use the web. In CHI ’02: Pro-
ceedings of the SIGCHI conference on Human factors
in computing systems, pages 227–234, New York, NY,
USA. ACM Press.
WEBIST 2008 - International Conference on Web Information Systems and Technologies
222
