
SPEAKER RECOGNITION USING DECISION FUSION
M. Chenafa, D. Istrate
RMSE, ESIGETEL, 1 Rue du Port de Valvins, 77215 Avon-Fontainebleau, France
V. Vrabie, M. Herbin
CReSTIC, Universit
´
e de Reims Champagne-Ardenne, Chauss
´
ee du Port, 51000 Ch
ˆ
alons-en-Champagne, France
Keywords:
Biometrics, Speaker recognition, Speech recognition, Decision fusion, GMM/UBM.
Abstract:
Biometrics systems have gained in popularity for the automatic identification of persons. The use of the voice
as a biometric characteristic offers advantages such as: is well accepted, it works with regular microphones, the
hardware costs are reduced, etc. However, the performance of a voice-based biometric system easily degrades
in the presence of a mismatch between training and testing conditions due to different factors. This paper
presents a new speaker recognition system based on decision fusion. The fusion is based on two identification
systems: a speaker identification system (text-independent) and a keywords identification system (speaker-
independent). These systems calculate the likelihood ratios between the model of a test signal and the different
models of the database. The fusion uses these results to identify the couple speaker/password corresponding
to the test signal. A verification system is then applied on a second test signal in order to confirm or infirm the
identification. The fusion step improves the false rejection rate (FRR) from 21,43% to 7, 14% but increase also
the false acceptation rate (FAR) from 21, 43% to 28,57%. The verification step makes however a significant
improvement on the FAR (from 28, 57% to 14.28%) while it keeps constant the FRR (to 7,14%).
1 INTRODUCTION
Biometric recognition systems, which identify a per-
son on his/her physical or behavioral characteristics
(voice, fingerprints, face, iris, etc.), have gained in
popularity among researchers in signal processing
during recent years. Biometric systems are also use-
ful in forensic work (where the task is whether a given
biometric sample belongs to a given suspect) and law
enforcement applications (Atkins, 2001). The use of
the voice as a biometric characteristic offers the ad-
vantage to be well accepted by users whatever his cul-
ture. There are two categories in voice-based biomet-
ric systems: speaker verification and speaker identifi-
cation. In identification systems, an unknown speaker
is compared to the N known speakers stored in the
database and the best matching speaker is returned
as the recognition decision. Whereas in verification
systems, an identity is claimed by a speaker, so the
system compares the voice sample to the claimed
speaker’s voice template. If the similarity exceeds a
predefined threshold, the speaker is accepted, other-
wise is rejected. For each system two methods can be
distinguished: text-dependent and text-independent.
In the first case, the text pronounced by the speaker is
known beforehand by the system, while in the second
case the system does not have any information on the
pronounced text (Kinnunen, 2003).
It is well known that the performances of voice-
based biometric systems easily degrade in the pres-
ence of a mismatch between the training and testing
conditions (channel distortions, ambient noise, etc.).
One method that can be used to improve the perfor-
mances of these systems is to merge various infor-
mation carried by the speech signal. Several studies
on information fusion were led to improve the per-
formances of automatic speakers recognition system
(Higgins et al., 2001)(Mami, 2003)(Kinnunen et al.,
2004). However, the results are less successful com-
pared to biometric systems based on other modalities
(fingerprint, iris, face, etc).
In this paper a new fusion approach is proposed
by using two kinds of information contained in the
speech signal: the speaker (who spoke ?) and the key-
word pronounced (what was said ?). The aim of this
method is to use a first test signal to identify a couple
speaker/password corresponding to this signal. This
step is done by combining two identification systems
based on likelihood ratio approach: a speaker identi-
fication system (text-independent) and a speech iden-
267
Chenafa M., Istrate D., Vrabie V. and Herbin M. (2008).
SPEAKER RECOGNITION USING DECISION FUSION.
In Proceedings of the First International Conference on Bio-inspired Systems and Signal Processing, pages 267-272
DOI: 10.5220/0001065502670272
Copyright
c
SciTePress
Feature
Extraction
Speaker
Modeling
Pattern
Matching
Speaker
Model
Database
Decision
Training
Mode
Recognition
Mode
Speech Signal
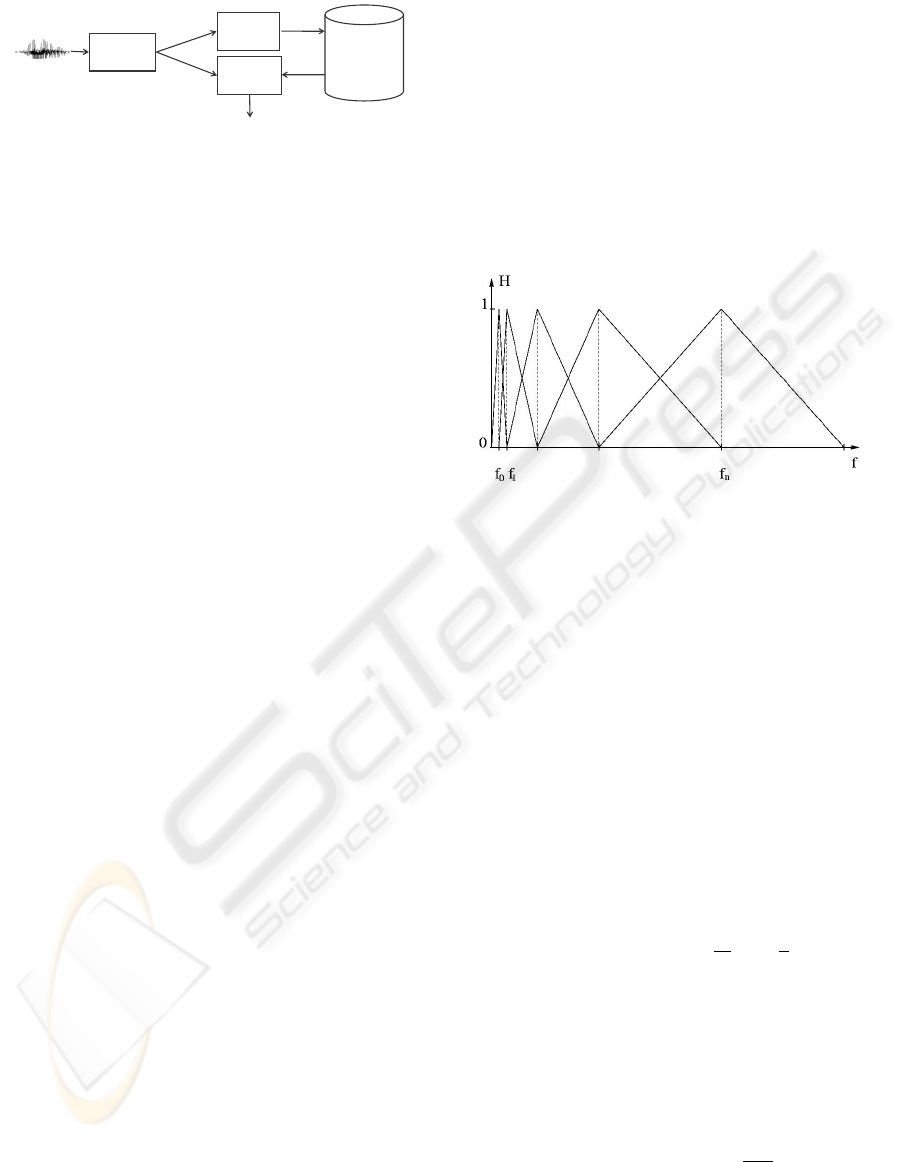
Figure 1: Components of a speaker recognition system.
tification system (speaker-independent). The speaker
identified by this fusion is then verified by a classi-
cal verification text dependent system using a second
test signal. In practical situations, the two test sig-
nals can be viewed as a composed password. The
system provides good improvements on the two types
of error usually computed for biometric systems: the
false rejection rate (FRR) and the false acceptation
rate (FAR). The experiments presented in this study
use the platform ALIZE developed by the LIA labo-
ratory (Bonastre et al., 2005).
This paper is organized as follows. Section 2 pro-
vides a general description of a speaker recognition
system. Section 3 presents the proposed fusion sys-
tem. The experiments are discussed in Section 4, fol-
lowed by conclusions in the last section.
2 SPEAKER RECOGNITION
SYSTEM
Figure 1 shows the structure of an automatic speaker
recognition system. This system operates in two
modes (training and recognition) and can be used for
both identification or verification tasks. In the training
mode, a new speaker (with known identity) is enrolled
into the system’s database, while in the recognition
mode an unknown speaker gives a speech input and
the system makes a decision about the speaker iden-
tity.
2.1 Feature Extraction
Feature extraction is the first component in an auto-
matic speaker recognition system (Furui, 1997). This
phase consists of transforming the speech signal in
a set of feature vectors called also parameters. The
aim of this transformation is to obtain a new repre-
sentation which is more compact, less redundant, and
more suitable for statistical modeling and calculation
of distances. Most of the speech parameterizations
used in speaker recognition systems relies on a cep-
stral representation of the speech signal (Lee et al.,
1996).
2.1.1 MFCC and LFCC Parameters
The Mel-frequency cepstral coefficients (MFCC) are
motivated by studies of the human peripheral audi-
tory system. Firstly, the speech signal x(n) is di-
vided into Q short time windows which are converted
into the spectral domain by a Discret Fourier Trans-
form(DFT). The magnitude spectrum of each time
window is then smoothed by a bank of triangular
bandpass filters (Figure 2) that emulate the critical
band processing of the human ear.
Figure 2: Mel filter bank.
Each one of the bandpass filter H(k, m) computes
a weighted average of that subband, which is then log-
arithmically compressed:
X
0
(m) = ln
N−1
∑
k=0
|
X(k)
|
H(k,m)
!
(1)
where X(k) is the DFT of a time window of the
signal x(n) having the length N, the index k, k =
0,.. . , N −1, corresponds to the frequency f
k
= k f
s
/N,
with f
s
the sampling frequency, the index m, m =
1,.. . M and M << N, is the filter number, and the fil-
ters H(k,m) are triangular filters defined by the center
frequencies f
c
(m) (Sigurdsson et al., 2006). The log
compressed filter outputs X
0
(m) are then decorrelated
by using the Discrete Cosine Transform (DCT):
c(l) =
M
∑
m=1
X
0
(m)cos(l
π
M
(m −
1
2
)) (2)
where c(l) is the l
th
MFCC of the considered time
window. A schematic representation of this procedure
is given in Figure 3.
There are several analytic formulae for the Mel
scale used to compute the center frequencies f
c
(m).
In this study we use the following common mapping:
B( f ) = 2595 log
10
(1 +
f
700
) (3)
The LFCC parameters are calculated in the same
way as the MFCC, but the triangular filters use a linear
frequency repartition.
BIOSIGNALS 2008 - International Conference on Bio-inspired Systems and Signal Processing
268

Pre-emphasis
and windowing
DFT
Filterbank with
Mel frequency
Filterbank with
Linear frequency
Log |.| DCT
MFCC
LFCC
Signal
Figure 3: Extraction of MFCC and LFCC parameters.
2.1.2 ∆ and ∆∆ Parameters
After the cepstral coefficients have been calculated
and stored in vectors, a dynamic information about
the way these vectors vary in time is incorporate. This
is classically done by using the ∆ and ∆∆ parameters,
which are polynomial approximations of the first and
second derivatives of each vector (Kinnunen et al.,
2004).
2.2 Speaker Modeling
The training phase uses the acoustic vectors extracted
from each segment of the signal to create a speaker
model which will be stored in a database. In au-
tomatic speaker recognition, there are two types of
methods that give the best results of recognition: the
deterministic methods (dynamic comparison and vec-
tor quantization) and statistical methods (Gaussian
Mixture Model - GMM, Hidden Markov Model -
HMM), these last ones being the most used in this do-
main. In this paper, we have chosen to use a system
based on GMM-UBM. This choice was motivated by
two reasons: modeling by GMM is very flexible with
regard to the type of the signal and using the GMM
gives a good compromise between performances and
the complexity of the system.
2.2.1 GMM-UBM
In this research, the method used for speaker mod-
eling is the GMM using the universal background
model (UBM). The UBM has been introduced and
successfully applied by (Reynolds, 1995) in speaker
verification. This model is created by using all record-
ing speech of the database, the aim being to have a
general model of speakers which will be then used to
adapt each speaker model.
The matching function in GMM is defined in
terms of the log likelihood of the GMM (Bimbot et al.,
2004) given by:
p(X|λ) =
Q
∑
q=1
log p(x
q
|λ) (4)
where p(x
q
|λ) is the Gaussian mixture density of the
q
th
segment in respect to the speaker λ:
p(x
q
|λ) =
G
∑
i=1
p
i
f (x
q
|µ
(λ)
i
,Σ
i
) (5)
with the mixing weights constrained by:
G
∑
i=1
p
i
= 1 (6)
In these expressions x
q
is the D-dimensional
acoustic vector corresponding to the q
th
time window
of the input signal, p
i
, µ
(λ)
i
and Σ
i
(i = 1,...,G) are
the mixture weight, mean vector, and covariance ma-
trix of the i
th
Gaussian density function (denoted by
f ) of the speaker λ, while G denotes the number of
GMM used by the model.
The speaker model λ is thus given by:
λ =
n
p
i
,µ
(λ)
i
,Σ
i
|i = 1,. . .,G)
o
(7)
the UBM model having the same form:
UBM =
n
p
i
,µ
(UBM)
i
,Σ
i
|i = 1,. . .,G
o
(8)
The mean vectors of speaker model µ
(λ)
i
are
adapted to the training data of the given speaker from
the UBM, i.e. µ
(UBM)
i
, by using the Maximum a Pos-
teriori (MAP) adaptation method (Gauvain and Lee,
1994), the covariance matrices and mixture weights
remaining unchanged.
2.3 Pattern Matching and Decision
Given a segment of speech, Y , and a hypothesized
speaker, S, the task of speaker recognition system is
to determine if Y was spoken by S. This task can be
defined as a basic hypothesis test between
H
0
: Y is from the hypothesized speaker S
H
0
: Y is not from the hypothesized speaker S
To decide between these two hypotheses, the opti-
mum test is a likelihood ratio given by:
p(Y |H
0
)
p(Y |H
1
)
≥ θ Accept H
0
< θ Re ject H
0
(9)
where p(Y |H
i
) is the probability density function for
the hypothesis H
i
evaluated for the observed speech
segment Y , also referred to the likelihood of the hy-
pothesis H
i
. The decision threshold for accepting or
rejecting H
0
is θ. A good technique to compute the
values of the two likelihoods, p(Y |H
0
) and p(Y |H
1
)
is given in (Doddington, 1985).
3 PROPOSED SYSTEM
In this paper a new method for automatic speaker
recognition based on fusion information is proposed.
The architecture of this method is described in Fig. 4.
SPEAKER RECOGNITION USING DECISION FUSION
269
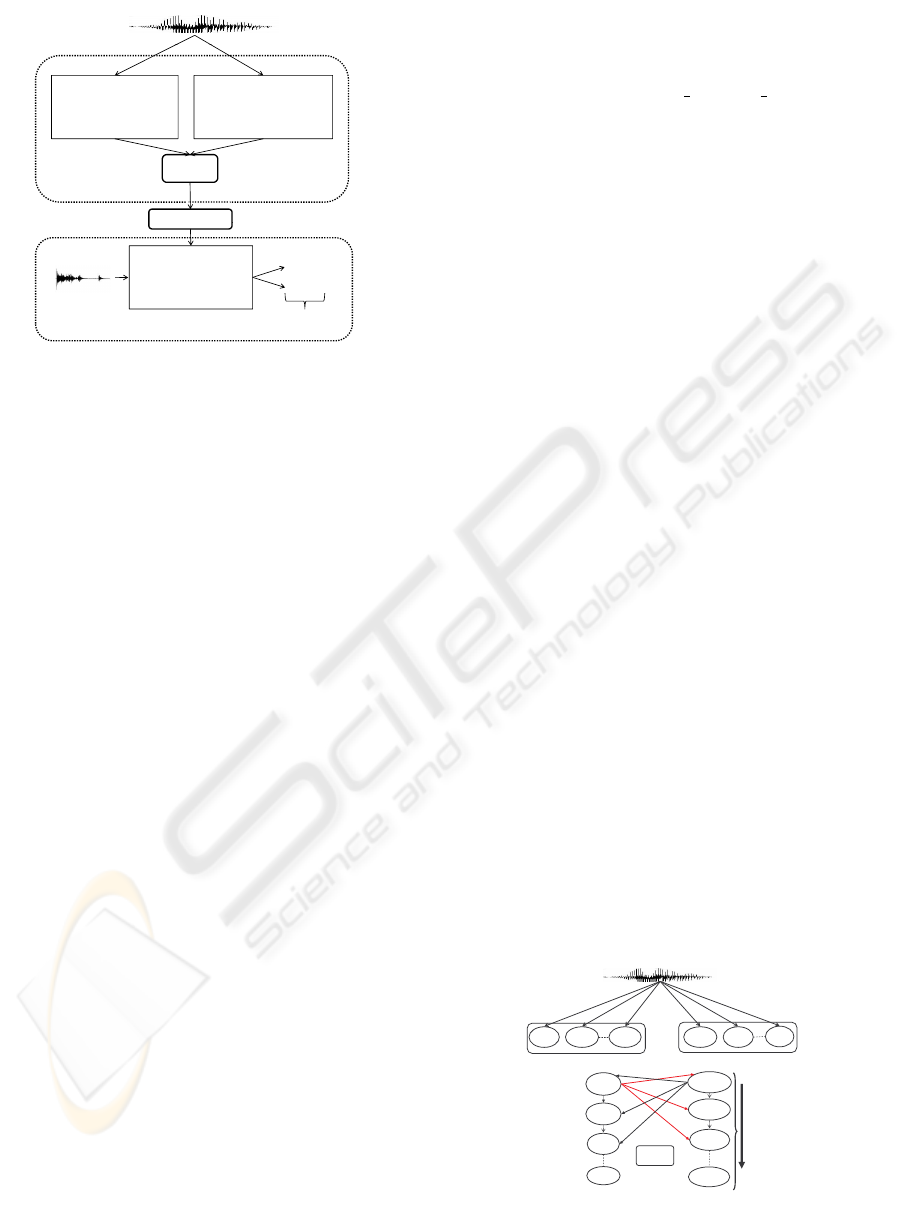
1
st
signal
Siifii
Siifii
S
peaker
i
dent
ifi
cat
i
on
system
(Text-independent)
S
peech
i
dent
ifi
cat
i
on
system
(Speaker-independent)
Fusion
Module 1
Speaker :
Sp
k
Result
Speaker verification
t
i
2
nd
Accept
2
nd
si
g
nal
Speaker
:
Sp
k
sys
t
em us
i
ng
2
nd
psw
of Spk
(Text-dependent)
Accept
Reject
g
Module 2
Decision
Figure 4: Global system architecture.
This system is composed by two blocks, the first
one made up by two classifiers (speaker and password
classifiers) and the second one made up by a verifica-
tion system using the decision result of the first block.
Each speaker is identified by two passwords: the first
one is used by both speaker and password identifica-
tion systems, while the second one by the verification
system. In practical situations, these two passwords
can be viewed as a composed password.
The identification systems (speakers and pass-
words identification) are used in open-set (no infor-
mation available on the possible speakers and pass-
words). Both systems calculate the likelihood ratio on
a first test signal by using equation (4). We used here
a normalization model UBM, as presented in section
2.2.1. This means that during the creation of the mod-
els (speaker, password), each model is adapted by the
MAP method to the UBM model.
The verification system is a classical speaker veri-
fication system which is used to confirm or infirm the
speaker identified previously by using a second test
signal (the second password).
Figure 5 shows the fusion between speaker and
speech (password) identification systems.
After sorting the log likelihood ratios (for the
first test signal) calculated with regard to the speak-
ers model LLK(X|Sp
i
), i = 1, N (N is the number of
speakers stored in the database) and to the passwords
model LLK(X|Psw
i
),i = 1,N (N is the number of
passwords stored in the database), a first test consists
of comparing the most likely speaker given by the
speaker classifier with the first three identified pass-
words given by the password classifier. If his pass-
word was found between the three identified pass-
words, a couple (speaker/password) was thus identi-
fied. A second test consists of comparing the most
likely password with the first three identified speak-
ers. If this password belongs to one of them, another
couple (password/speaker) is identified. In the cases
where two couples are identified, the couple with the
biggest likelihood ratio (Lk Sp + Lk P) is retained.
The system can reject directly a recording if there are
no identified couples.
Once the first test signal is associated to a speaker,
a classical verification is then launched using the sec-
ond test signal pronounced by the speaker identified
previously. If the likelihood ratio of this verification
is smaller than the smallest likelihood ratio of the first
two recordings used in the training phase, the identity
of the speaker is confirmed, otherwise the speaker is
rejected.
4 EXPERIMENTS
4.1 Data Base
In order to evaluate the proposed system a corpus of
specific keywords has been recorded. This corpus
contains the recordings of 15 isolated words (French
language) and 11 numbers (from 0 to 10).
The recordings were stored in WAV format, with a
sampling rate f
s
= 16 kHz. The parameterization
was realized by using MFCC parameters for the pass-
words identification system and LFCC for speaker
identification and verification systems. We have opti-
mized the acoustic parameter for this application; all
the 8 ms the signal is characterized by a vector made
up of 16 ceptrals coefficients c(l) (see Eq. (2)) and
their derivative ∆∆.
4.2 Training and Test Data
For both identification systems (speaker and pass-
word) the first password recording is used for the
Likelihood
Ratio sorted
In descending
order
Fusion
1
st
signal
Speakers
Model
Passwords
Model
Lk_Spn
Lk_Sp4
Lk_Sp7
Lk_Sp1
Lk_Pswn
Lk_Psw9
Lk_Psw3
Lk_Psw1
Sp1 Sp2 Spn Psw1 Psw2
Pswn
Identification
Figure 5: Fusion system architecture(Module 1).
BIOSIGNALS 2008 - International Conference on Bio-inspired Systems and Signal Processing
270
training mode. The verification system uses the sec-
ond password for the training mode. The speakers
database is divided into two equals groups: 7 clients
and 7 impostors. Therefore, in the test stage the num-
ber positive and negative tests are equals.
1. The speaker identification system (text-
independent) uses two recordings of 14 words
of the 7 clients for the training phase. For the
recognition phase, the system uses one recording
of 14 words of the 7 clients and 3 recordings of
14 words of 7 impostors.
2. The password identification system (speaker-
independent) uses two recordings of 7 clients for
the training phase. For the recognition phase, the
system uses one recording of 7 clients and all
recordings of the impostors.
3. The verification system uses two recordings of the
second passwords of every client for the training
phase and a recording of 7 clients as well as all
the recordings of 7 impostors for the recognition
phase.
4. The reference system uses for the training phase 7
speakers, two recordings of 14 words. For recog-
nition phase we used a recording of 14 speak-
ers passwords and 3 recordings of 14 impostors
words.
4.3 Reference System
The results obtained by the global system are com-
pared to a classical verification system (Bimbot et al.,
2004). In the training phase of the reference system
a speaker model is created from the feature vectors
(16 LFCC + ∆∆) using two recordings of all the pass-
words to model speakers; However the recognition
phase uses all passwords of the speakers pronounced
by impostor and other words.
We have optimized the number of GMM for this ap-
plication; the optimal value is G = 16.
4.4 Results and Discussion
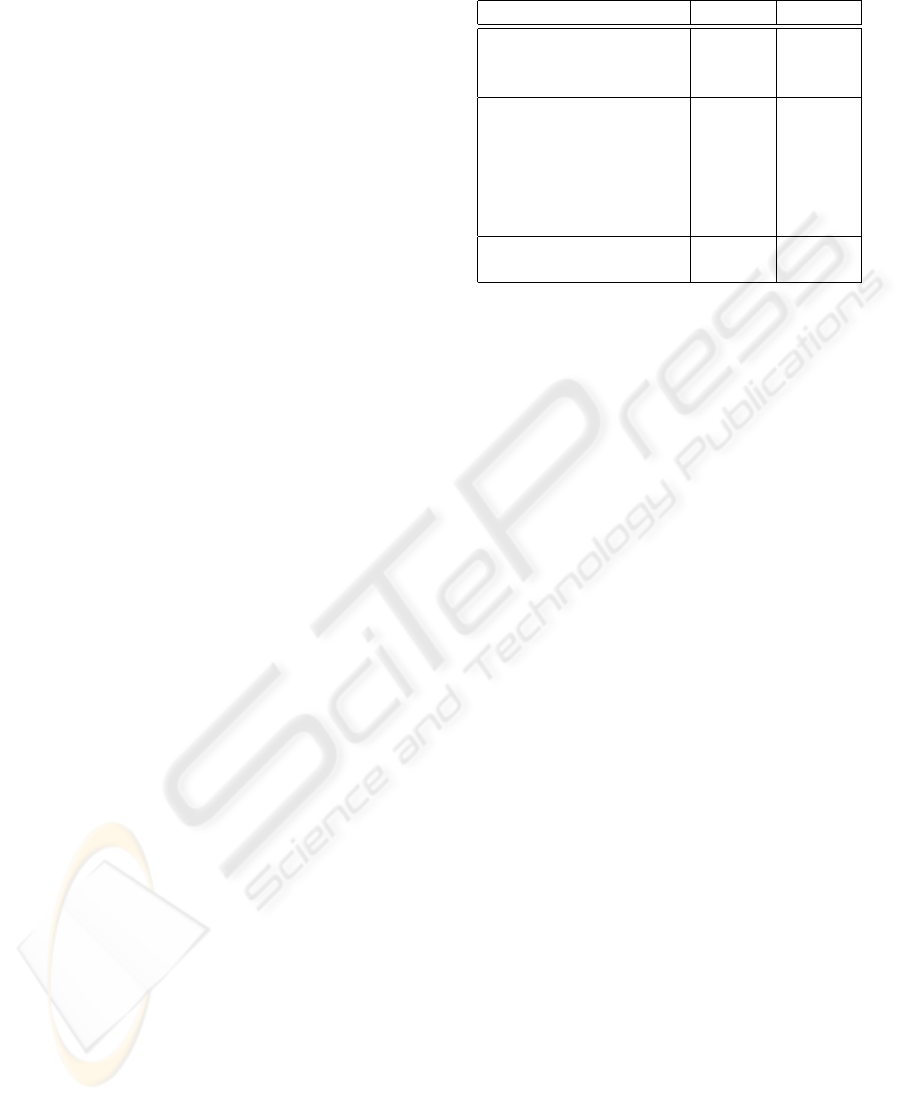
Table 1 shows the false rejection rate (FRR) and the
false acceptation rate (FAR) of the reference system,
the first module of the new system and the global
system proposed.
The best equal error rate obtained for the refer-
ence system is 21.43%, which is high enough but can
be justified by the small size of the database. After
the fusion of the results between the speaker identifi-
cation system and the password identification system,
we notice that the FAR increases to 28.57% (that is
Table 1: performances of different systems.
Systems FRR FAR
Reference System
21.43% 21.43%text dependent
(16 LFCC + ∆∆)
Fusion System between
7.14% 28.57%
speakers identification
(16 LFCC+∆∆)
and passwords
identification
(16 MFCC + ∆∆)
Verification after fusion 7.14% 14.28%
(16 LFCC + ∆∆)
due to the password identification system which in-
creases the chance of impostors to be accepted be-
cause the password is well recognized), while the
FRR decreases to 7.14%. By using a verification sys-
tem, which uses the results of this fusion, we improve
the FAR (from 28.57% to 14.28%) while the FRR
remains the same one (7.14%) because the verifica-
tion system was adapted to recognize the clients. The
global system thus makes an improvement of 43.47%
of the FRR and 65.69% of the FAR. Note again that
these values are high enough due to the small size of
the database.
5 CONCLUSIONS
In this paper, we presented several experiments to
improve the performances of a voice-based biomet-
ric system using decision fusion. The fusion of the
speaker identification and the passwords identifica-
tion was firstly proposed. We show that the fact of
modeling the passwords pronounced by the speakers
brings improvements in the false reject rate but in the
same time it increases the number of the impostors
accepted by the system. The second experience pro-
poses an automatic speaker verification using the re-
sult (speaker identified) of the first experience. The
aim here is to confirm the results returned by the fu-
sion of speaker and password classifiers. This second
experience allows us to reduce the number of impos-
tors accepted by the system and improves the results
of the fusion by decreasing the FAR from 28.57% to
14.28%. So the global system improves the perfor-
mances in term of FAR and FRR with regard to the
reference system. This study encourages us to con-
tinue the experimentation on a corpus with more im-
portant size and to consider other kind of fusion such
as weigthed ranks.
SPEAKER RECOGNITION USING DECISION FUSION
271

REFERENCES
Bimbot, F., Bonastre, J.-F., Fredouille, C., Gravier, G.,
Chagnolleau, I., Meignier, S., Merlin, T., Garciya, J.,
Delacrtaz, D., and Reynolds, D. (2004). A tutorial
on text-independent speaker verification. EURASIP
Journal on Applied Signal Processing, 4:430–451.
Bonastre, J.-F., Wils, F., and Meignier, S. (2005). Alize,
a free toolkit for speaker recognition. In Proceed-
ings of IEEE International Conference on Acoustics,
Speech, and Signal Processing (ICASSP), volume 1,
pages 737–740.
Doddington, G. (1985). Speaker recognition - identifying
people by their voices. In Proc. of the IEEE, vol-
ume 73, pages 1651–1664.
Furui, S. (1997). Recent advances in speaker recogni-
tion. In Proc. of the First International Conference
on Audio- and Video-Based Biometric Person Authen-
tication, volume 1206, pages 237–252.
Gauvain, J.-L. and Lee, C.-H. (1994). Maximum a posteri-
ori estimation for multivariate gaussian mixture obser-
vations of markov chains. In IEEE Trans. on Speech
and Audio, volume 2, pages 291–298.
Higgins, J. E., Damper, R. I., and Harris, C. J. (2001). In-
formation fusion for subband-hmm speaker recogni-
tion. In International Joint Conference on Neural Net-
works, volume 2, pages 1504–1509.
Kinnunen, T. (2003). Spectral Features for Automatic Text-
Independent Speaker Recognition. PhD thesis, Uni-
versity of Joensuu, Finland.
Kinnunen, T., Hautamki, V., and Fr
´
’anti, P. (2004). Fusion
of spectral feature sets for accurate speaker identifi-
cation. In 9th International Conference Speech and
Computer (SPECOM), pages 361–365.
Lee, C. H., Soong, F., and Paliwal, K. (1996). Automatic
Speech and Speaker Recognition. Springer, London,
UK, 2nd edition edition.
Mami, Y. (2003). Reconnaissance de locuteurs par locali-
sation dans un espace de locuteur de reference. PhD
thesis, ENST Paris, France.
Reynolds, D. (1995). Speaker identification and verifica-
tion using gaussian mixture speaker models. Speech
Communication, 17:91–108.
Sigurdsson, S., Petersen, K. B., and Lehn-Schiøler, T.
(2006). Mel frequency cepstral coefficients: An eval-
uation of robustness of mp3 encoded music. In Pro-
ceedings of the Seventh International Conference on
Music Information Retrieval (ISMIR), pages 286–289.
BIOSIGNALS 2008 - International Conference on Bio-inspired Systems and Signal Processing
272
