
TEXT ANALYTICS AND DATA ACCESS AS SERVICES
A Case Study in Transforming a Legacy Client-server Text Analytics Workbench
and Framework to SOA
E. Michael Maximilien, Ying Chen, Ana Lelescu, James Rhodes, Jeffrey Kreulen and Scott Spangler
IBM Almaden Research Center
650 Harry Road, San Jose, CA, 95120, USA
Keywords:
SOA, Web services, Text Analytics, Text Mining, Software Engineering, Case Study.
Abstract:
As business information is made available via the intranet and Internet, there is a growing need to quickly
analyze the resulting mountain of information to infer business insights. For instance, analyzing a company’s
patent database against another’s to find the patents that are cross-licensable. IBM Research’s Business Insight
Workbench (BIW) is a text mining and analytics tool that allows end-users to explore, understand, and analyze
business information in order to come up with such insight. However, the first incarnation of BIW used a thick-
client architecture with a database back-end. While very successful, the architecture caused limitations in the
tool’s flexibility, scalability, and deployment. In this paper we discuss our initial experiences in converting
BIW into a modern Service-Oriented Architecture. We also provide some insights into our design choices and
also outline some lessons learned.
1 INTRODUCTION
The Web has transitioned into a collaborative plat-
form for casual end users and increasingly for busi-
nesses and organizations. Examples of this shift
to human collaborations are the wide and rapid
popularity of social networking platforms such as
MySpace.com (Hempel and Lehman, 2005), vari-
ous socially-centered news Web sites such as slash-
dot.org and digg.com, collaborative knowledge plat-
forms such as Wikipedia, and the myriad of individual
blogs currently available on wide ranging topics
1
.
Businesses and organizations have also experi-
enced this shift toward more collaboration using the
Web. They are increasingly making their employees
participate in the collaborative Web and engage their
customers using the same platform. For the more
internet-centric companies, the results of their cus-
tomers’ collaborations become a key asset to their
business. For example, eBay’s reputation system
(which is entirely customer-driven) is arguably eBay’s
1
As of 15 July 2006, Technorati.com listed more than
80 top-level blogging categories with more than 50,000 new
blogs listed per-day and tracking more than 50 million blogs
in tota.
most important asset.
One downside of this far-reaching, free-form, hu-
man collaboration and participation, is that informa-
tion is scattered in many different databases. Further,
the information is at time highly unstructured which
makes gathering knowledge and insights from it an in-
creasingly difficult problem. For example, in a large
organization, how can one identify the people with
the skills and knowledge on particular technologies,
tools, or techniques? In other words, how do you
identify experts when the information about people,
their expertise, and passions, is increasingly in the
forms of wikis, blogs, and other social collaborative
tools and platforms?
IBM’s Business Insight Workbench (BIW) is a
tool designed to address this problem and help answer
such questions. Using various mining techniques,
data ware-housing capabilities, and some proprietary
algorithms, the BIW tool has been widely deployed
to help gain insights into vast amount of unstructured
and structured information (Cody et al., 2002; Span-
gler et al., 2003). Using BIW a client gathers and
explores the data sets in question. Using searches and
operations, the user analyzes the results, which leads
to an understanding and then some insights. For ex-
581
Michael Maximilien E., Chen Y., Lelescu A., Rhodes J., Kreulen J. and Spangler S. (2007).
TEXT ANALYTICS AND DATA ACCESS AS SERVICES - A Case Study in Transforming a Legacy Client-server Text Analytics Workbench and
Framework to SOA.
In Proceedings of the Ninth International Conference on Enterprise Information Systems - DISI, pages 581-588
DOI: 10.5220/0002355805810588
Copyright
c
SciTePress

ample, using the BIW tool on a company’s internal
blogs and project databases we can identify employ-
ees with certain expertise, e.g., Java
TM
, UML, and
so on. Such information is useful when forming new
teams for new projects, as well as for cross-fertilizing
and balancing the workforce.
While the tool has been widely deployed and suc-
cessful, it has some important drawbacks. In par-
ticular the workbench is comprehensive, which also
makes it difficult to use and to integrate into a com-
pany’s business processes. Second, since the work-
bench is essentially a thick-client application, it re-
quires much of the resources from the machine where
it is running, making scalable deployment problem-
atic.
In this paper we present the architecture and
lessons learned from our experiences in transforming
the BIW tool from a thick-stand-alone client into a
modularized, Web application-centric, and domain-
specific, service-oriented architecture (SOA). The
new platform is a comprehensive information service
platform named Business Information Services on a
Network or BISON.
1.1 Organization
The rest of this paper is organized as follows. In
the next section we discuss additional motivation for
the BISON project; in particular we take a look at
some of the key use cases that have driven our ap-
proach. Section 3 lists some related work in the field
of both Service-Oriented Computing and information
data mining. Section 4 contrasts the previous archi-
tecture with the new modularized, service-centric ar-
chitecture. Section 5 shows a demonstration of one
AJAX-based Web application solution built using the
BISON services. Section 6 highlights the lessons
learned in moving to our new architecture (both tech-
nical and business lessons). Section 7 concludes with
a discussion of future work and directions for addi-
tional research.
2 USE CASES AND
REQUIREMENTS
Generally the BISON project provides a services
framework to enable a domain expert to gain insights
into huge amount of unstructured information. Since
the research space is vast, we give two use cases
(which we have implemented) that cover two impor-
tant domains and problem classes that are well suited
for the BISON technology.
2.1 Root-Cause Analysis Use Case
Root Cause Analysis is a particular analysis scenario
using BISON capabilities applied to a data set of
problem tickets for some product or set of products.
In this scenario the user first begins with a query that
captures (for the most part) the kind of problem that
they wish to find the root cause of. This is assumed to
return a set of problem tickets that match the associ-
ated query.
Next the problem tickets are categorized using
standard text clustering techniques (Cody et al., 2002;
Spangler et al., 2003). This then produces a catego-
rization which the user can browse and edit until it
reflects the users view of how the query result should
be partitioned. Next the user selects those categories
that best match the original problem, discarding those
categories that are spurious or irrelevant matches.
The selected problems are then compared to a ran-
domly selected background population of the docu-
ments to detect any statistically significant differences
in either the structured or unstructured data fields.
Any such correlations are brought to the user’s atten-
tion along with ‘typical’ examples which should help
to indicate the ‘root cause’ of the original problem.
2.2 Expertise Locator Use Case
Fast and dynamic team building capability is criti-
cal to the success of a business consulting service
organization. To acquire such ability, one key com-
ponent is to be able to quickly identify appropriate
consulting team with appropriate expertise. Most
business consulting organizations maintain significant
amount of information in the form of texts in knowl-
edge bases which contain information on which con-
sultants might have been working on different types
of projects. Such information, if mined properly, can
give insights into the expertise of the consultants.
We list the high-level steps for identifying peo-
ple’s expertise using the BISON tools:
1. Search for documents containing expertise key-
words (e.g., ‘six sigma’)
2. Automatically generate an expertise taxonomy on
the query result set.
3. If there are meaningful structured fields such as
the authors of the documents that can be used to
create experts and expertise linkage, then:
(a) classify the result set by using such structured
fields;
(b) otherwise, a name-annotator is run to extract
names out of the documents;
ICEIS 2007 - International Conference on Enterprise Information Systems
582

(c) the extracted names are considered as a struc-
tured field; and
(d) the documents are then classified using the
structured name field.
4. Use co-occurrence analysis (Cody et al., 2002) to
generate a co-table that compares the refined doc-
ument taxonomy and the classification of names
or authors.
5. Find significantly related document categories to
people.
6. Plot the relationship using network graph analysis
to see who are related to which document cate-
gories; hence indicating a certain level of exper-
tise.
7. Identify people with similar expertise by exam-
ining highly related people names using network
graph analysis.
2.3 Requirements
In addition to enable the creation of rich text analyt-
ics Web applications for various domains, such as the
ones listed above, we also wanted to address various
shortcomings with the current architecture. In par-
ticular we wanted the BISON services framework to
facilitate the following requirements:
1. Scalability. This implies scalability in all parts of
the systems. Since the BISON users can be var-
ied and numbered, it is important that the system
be able to scale to a great number of simultane-
ous users. While much of the BISON core com-
ponents are involved in compute and data inten-
sive tasks, it is critical that individual user inter-
face components perform within Web application
acceptable responsiveness time.
2. Fine- and coarse-grained services. The BIW
tool divided its operations into three main cate-
gories: explore, understand, and analyze. While
such a high-level categorization works for com-
municating with experts and users of the BIW
tool, as we transform the tool to SOA, it became
apparent as we brain-stormed on the different ser-
vices to expose, that some services would be com-
posed of simpler more fine-grained ones. There-
fore, a clear goal was to provide different levels of
services which could be combined and integrated
into business processes and provide transparent
value, as well as enable the creation of end-user
Web applications (as discussed above).
3. Achieve reusable components. While the previ-
ous tool was successfully applied in wide-ranging
domains, it was clear to us that there are many
common components across the different solu-
tions. Therefore, another important requirement
is to make sure to modularize the components of
different solutions from the start, thereby encour-
aging reuse and sharing. This includes the views,
controllers (actions), and data models for each so-
lution.
4. Flexible data sources. Since a primary goal of
BISON is to enable the gathering and discovery
of insights from corporate and public data repos-
itories, we wanted to be very flexible in the types
of data sources we support. This means that our
new architecture should have provisions to ingest,
equally well, text and XML data files, as well as
relational databases.
5. Flexible deployment. Since a BISON solution
Web application can either be hosted or deployed
at the customer’s site. It’s important that our new
BISON framework allows for flexible and easy
component deployments.
6. Reuse of previous code. An important criterion
driving our architectural, design, and implemen-
tation decisions is the goal of reusing and leverag-
ing the good aspects of the previously successful
BIW tool and framework.
3 RELATED WORKS
We could not find much previous works in the litera-
ture dealing with comprehensive SOA tool or frame-
work for business insights such as ours. However,
our work builds on various standard SOA ideas and
data mining techniques (Agrawal, 1999). There have
also been various efforts in exposing data and knowl-
edge as services, which at their core, are similar to our
overall goals with BISON.
We divide the related works into: (1) database,
data mining, and information as services; and (2) gen-
eral approaches to architect and design service-based
systems and solutions.
3.1 Databases, Data Mining, and
Information as Services
(Kumar et al., 2006) outline and motivate the impor-
tance of achieving distributed data-mining, as well as
the use of standard Internet protocols, and SOA for
achieving scalable solutions. Our approach fits quite
well into this overall vision. (Cheung et al., 2006)
describe an architecture and framework for data min-
ing using the Business Process Execution Language
TEXT ANALYTICS AND DATA ACCESS AS SERVICES - A Case Study in Transforming a Legacy Client-server Text
Analytics Workbench and Framework to SOA
583

(BPEL) (Curbera et al., 2002). Our approach cur-
rently differs from theirs in that we have a simple
workflow mechanisms based on top level tasks (or
steps), which themselves aggregate calls to various
Web services invocations. However, since we ex-
pose various levels of Web services (fine- and coarse-
grained) we could also make use languages such as
BPEL to help create composed services out of the
simpler ones.
(Guedes et al., 2006) propose a SOA-based ar-
chitecture for distributed data mining called Anteater.
The Anteater architecture, as ours, distribute the func-
tions of data severs and mining servers to different
nodes in the network and use Web services as inter-
faces. The architecture uses a distributed mining algo-
rithms which can operate in parallel in the distributed
mining servers.
Salesforce.com’s AppExchange platform
2
as well
as Amazon.com’s Alexa
3
and ECS
4
Web services
are examples of information and database as services.
Since these Web services expose information from
databases as a series of Web services, there is a rela-
tionship to our services and also generally point to the
trend of making data available as services on the Web.
However, we should note that our approach and ser-
vices focus on creating general data-mining Web ser-
vices which can take many data sources and help ex-
pose the content of these sources to help create busi-
ness intelligence solutions.
3.2 Design and Architecture of
Service-Based Systems and
Solutions
Another set of related works are in the approaches
to convert existing tools or frameworks into service-
oriented architectures. These include processes, tech-
niques, and methods.
An example of a comprehensive method for archi-
tecting SOA-based systems is the Service-Oriented
Method Architecture (SOMA) from IBM (Arsanjani,
2005). Our resulting SOA design and architecture de-
cisions did not result from the SOMA approach; in-
stead, we used a more agile technique of creating a
cross-section of the system (or a spike (Beck and An-
dres, 2005)) by implementing two comprehensive so-
lutions and abstracting the various services from the
different layers that we anticipated and had to create.
Other approaches in building SOA typically take
a model-driven approach to the design. That is, they
2
http://www.salesforce.com/appexchange
3
http://aws.amazon.com/awis
4
http://aws.amazon.com/
envision the abstract model of the different compo-
nents and determine the components’ remote inter-
faces, and then they decide which component can be
exposed as Web services. Examples of this approach
are the Sonic SOA Workbench (Sonic, 2006), Exal-
tec’s b+ J2EE-SOA Application Generator (Exaltec,
2006), and IBM’s SOA Solutions workbench.
4 ARCHITECTURE
As mentioned before, the previous BIW architecture
was implemented as a thick Swing Java client appli-
cation connected to a database back-end. While this
allowed for a rich user interface, there are many prob-
lems with this approach.
1. A thick-client architecture means that all of the
text analytics engine and algorithms run on the
client. Since these algorithms are compute-
intensive the client has to absorb all of the costs
(CPU and memory).
2. There is no easy way to integrate parts of the client
functionality into some external business process.
This is especially useful when the results of the
analysis are repeatable and just need to be run on
newer data.
3. The current application aggregates all of the ca-
pabilities of the BIW framework. This makes the
user interface comprehensive but also difficult to
use.
4. The current architecture was designed with a sin-
gle user in mind. There are no facilities to ac-
commodate multiple and simultaneous users, nor
are there any means for preventing access to some
functions at a user-level.
5. The current architecture does not have facilities
for monitoring and for metering user activities.
Metering usage is important if we want to even-
tually use the resulting solutions in a pay-as-you-
use business model.
To address the issues listed above and also with
the implicit goals of reusing as much of the previous
code-base and functionality as possible, we have cre-
ated a new SOA-based architecture for the new incar-
nation of BIW or the BISON project.
4.1 Overview of Architecture
Our architecture is principally based on the layered ar-
chitecture style documented in (Bass et al., 1998). A
well known advantage of layered architectures is the
ICEIS 2007 - International Conference on Enterprise Information Systems
584
decoupling of subsystems. There are also other well-
known characteristics; for instance, each horizontal
layer:
1. depends on layers below it;
2. exposes its own set of service interfaces (local or
remote);
3. can be developed separately; and
4. can be deployed independently.
Additionally, one can add vertical layers for com-
mon components that span across layers. For our
case, we decided to divide our architecture into five
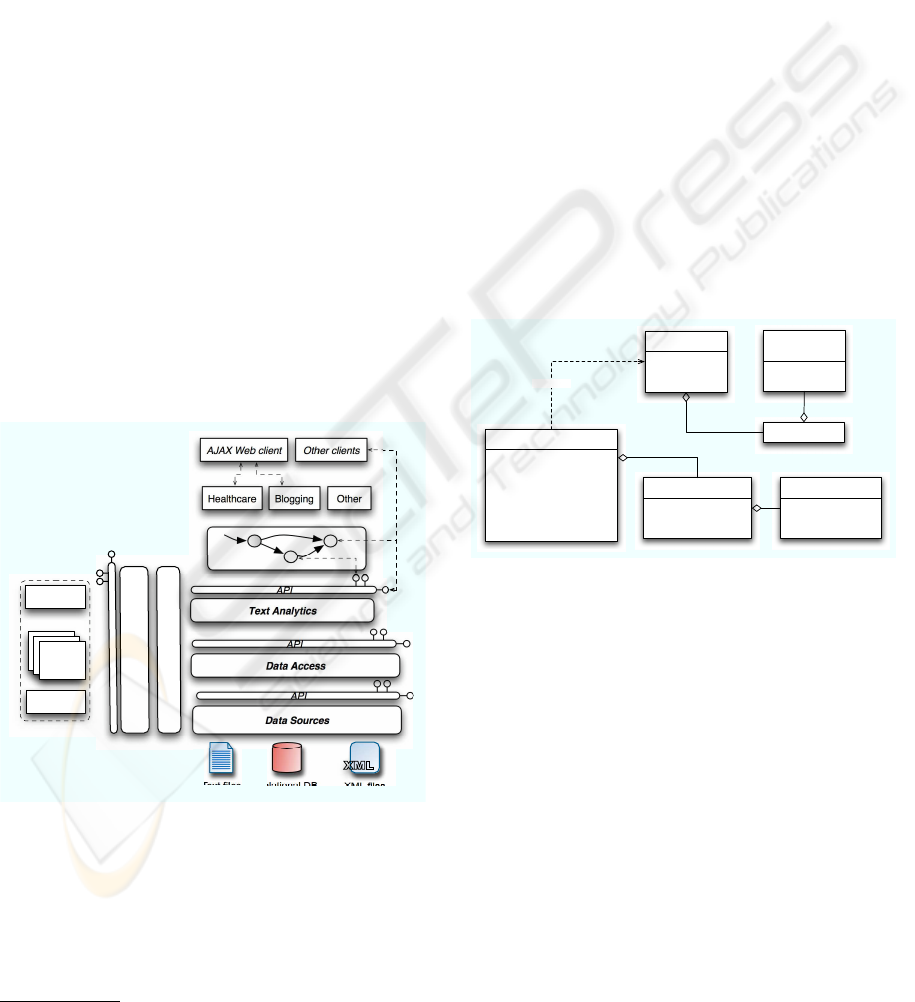
horizontal layers and one common vertical layer. Fig-
ure 1 illustrates our architecture.
Each horizontal layer can be independently de-
ployed and comprise of a remote and local service
API. The APIs are identical, except that the remote
API is a Web service with exposed WSDL
5
. At de-
ployment time, clients of each layer (which can also
be another layer) configures their use of the API to
bind locally or remotely. This allows clients to be
flexibly deployed and take advantage of a faster local
API if it is deployed on the same node on the network.
Our vertical layer takes care of administration, me-
tering, security, logging, and other cross-cutting con-
cerns. In the following sections we discuss each layer
in details.
AJAX Web client Other clients
Healthcare Blogging Other
Text Analytics
Data Access
Data Sources
API
API
API
Relational DB
Text files
XML files
<?xml v
<ref:
<gr
XML
Administration, monitoring,
metering
Security, users, profiles, ...
API
Pricing
model
Pricing
model
Pricing
models
Statistics
AdminWs
Figure 1: BISON layered SOA.
4.2 Common Vertical Layer
As illustrated in Figure 1, our layered architecture
comprises of independently deployable horizontal
layers and one vertical layer. The vertical layer is
5
http://www.w3.org/TR/wsdl
meant for common components. In particular our ver-
tical layer comprises the following key features:
1. Administration. These include user management
functions, including authorization, authentication,
user profiles, and general user management facil-
ities, e.g., add and remove users.
2. Security. Designed to manage secure access to
data sources and text mining and analysis objects.
For instance, any intermediary and final objects
are associated with a user and can only be ac-
cessed by that user.
3. Metering. Keeps information about user accesses
to various parts of the system. The metering infor-
mation is important for costing; for instance, for
keeping track of service accesses and to appropri-
ately charging users.
4. Statistics. Aggregates metering information into
useful statistics needed for the cost models, e.g.,
average service method access for any service, av-
erage query length and results, as well as many
other statistics.
+ deregisterUser( User ): void
+ registerUser( User ): void
+ getRegisteredUsers(): User[]
+ ...
+ hasMetering( User ) : boolean
+ getMetering( User ) : Metering
+ getMeterings( serviceName ):
Metering[]
+ ...
<<service>>
AdminWs
+ email: String
+ firstName: String
+ lastName: String
+ ...
<<bean>>
User
<<uses>>
<<bean>>
UserProfile
1
1
+ name: String
+ dbName: String
+ ...
<<bean>>
DataSource
Config
*
1
+ totalCost: float
+ totalInvocationCount: int
+ totalFailureCount: int
+ serviceName: String
<<bean>>
Metering
+ cost: float
+ failureCount: int
+ invocationCount: int
+ methodName: String
<<bean>>
MethodMetering
*
1
*
1
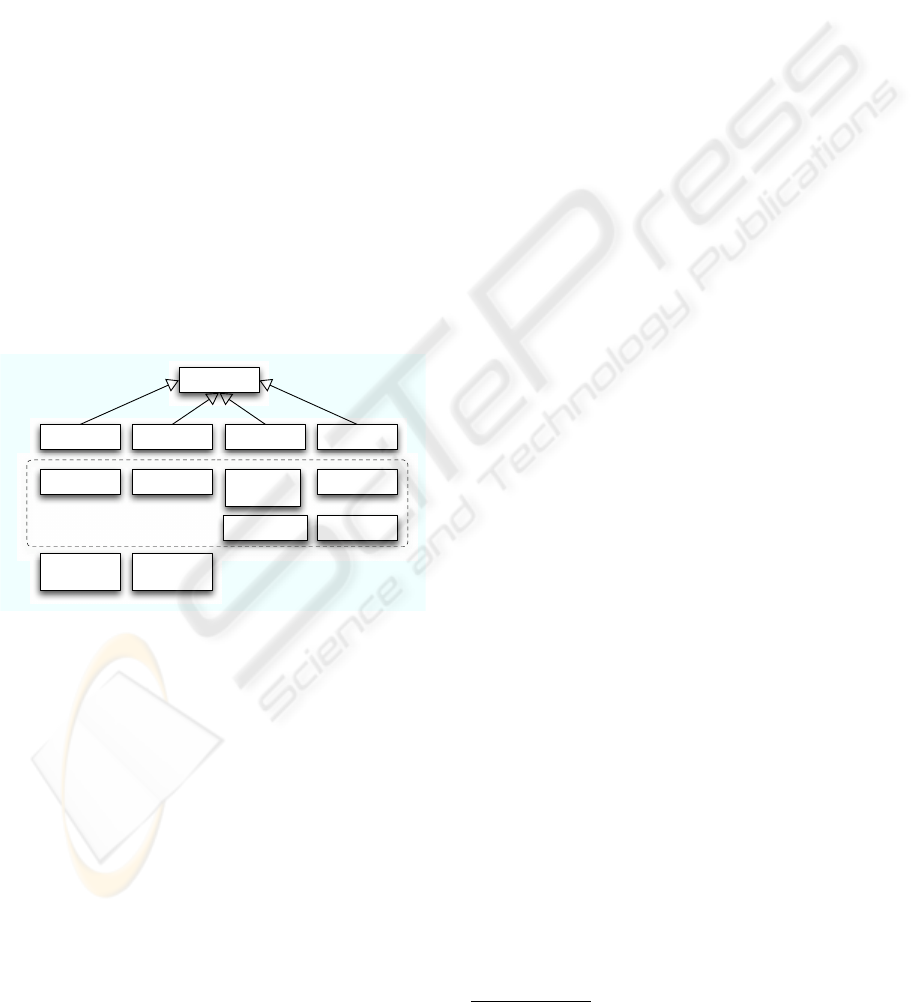
Figure 2: BISON Meetering component design.
Figure 2 shows a high-level overview of the meter-
ing and user information components. The AdminWs
is the main Web service exposing administrative ac-
cess and functions to the horizontal layers. This Web
service returns metering information for any Web ser-
vice on any layer for a user.
4.3 Domain and Client Layers
The domain and client layer contains components
and services to ease the creation of domain-specific
solutions. In particular we have created a simple
workflow-based approach to easily add solutions to
our BISON framework. For instance, we have a se-
ries of simple steps for common part of any solutions
that can then be combined to create full solutions.
For example in the use cases discussed in Section 2,
the query, taxonomy editing, and correlation analysis
TEXT ANALYTICS AND DATA ACCESS AS SERVICES - A Case Study in Transforming a Legacy Client-server Text
Analytics Workbench and Framework to SOA
585
steps are common components across the two differ-
ent use cases.
To enable the creation of richer client based on
AJAX we have created common components to help
move data from the AJAX server and the browser and
to help cache text analytics data, e.g., categories, tax-
onomy, co-occurrence data, and so on. This common
AJAX caching scheme allows client code to focus on
how to best display data to users and elicit user input
rather than managing communications to the Web ser-
vices and caching of data. Section 5 is an example of
a complete solution built using the domain and client
layers.
4.4 Text Analytics Services Layer
The text analytics services (TAS) layer exposes ser-
vices to enable the creation of client and domain
text mining and analytics steps. For instance, co-
occurrence table analysis assumes the creation of a
taxonomy on a datastore by running a particular clus-
tering analysis algorithm. All of these functions are
provided as part of TAS and are exposed via indepen-
dent WSDL. Each operation for each service takes a
User object to allow for security and metering.
<<service>>
DomainWs
<<service>>
ConfigWs
<<service>>
QueryWs
<<service>>
OperationWs
<<service>>
ReportWs
<<service>>
AdminWs
<<service>>
SoapiWs
<<service>>
DataSource
Ws
<<service>>
DataStore
Ws
<<service>>
Correlation
AnalysisWs
<<service>>
DictionaryWs
<<service>>
DocumentWs
<<service>>
TaxonomyWs
Fine-grained services
Figure 3: Text Analytics Services (TAS) architecture.
The TAS can be divided into two primary groups
of services. Figure 3 illustrates this decomposition.
First, a series of fine-grained low-level text mining
and analysis services; for instance, we have services
such as:
1. TaxonomyWs exposes operations to create, access
attributes, and modify (edit) taxonomies. A tax-
onomy is used by all TAS services so this service
is key to using TAS.
2. CorrelationAnalysisWs exposes operations to
perform correlation analysis and access co-
occurrence data.
3. DictionaryWs and DocumentWs enable adding
custom dictionary terms to a corpus of data as well
as access the documents of that corpus
4. SoapiWs is a generic service that gives access to
other parts of the TAS which do not fit in the other
services.
The second set of services exposed by the TAS
composes the fine-grained services. These coarse-
grained services are used directly in the creation of
the steps for the client and domain layers. Exam-
ples services are ConfigWs, QueryWs, and ReportWs,
which are used to respectively configure data sources,
to query datastore, and to generate reports.
4.5 Data Access/Sources Services
Layers
The final layer in the BISON stack is the one dealing
with extracting, loading, and transforming (ETL) data
sources into a form that can be used for text analytics.
The Data Source Services and Data Access Services
(DSS/DAS) operate on either text files or relational
databases. The DSS abstracts the data into a com-
mon set of operations and query interface. The DAS
expose the resulting data sources as a series of Web
services, which can be used by TAS to enable the text
mining and analysis services describe in Section 4.4.
An important design point of the DSS/DAS lay-
ers is to provide a uniform interface to different data
sources. In particular they give a generic query in-
terface to both file based data and relational databases
and provide secure access to the data. Finally, another
aspect of the DAS is the creation of common data
warehousing facilities (independent of data sources).
That is, after ETL the data sources are loaded into a
star-schema in the DSS/DAS to allow different types
of OLAP (Codd et al., 1998)
6
operations and queries
to be performed. These OLAP capabilities are impor-
tant features needed to implement the TAS.
5 DEMONSTRATION
As an initial demonstration of our architecture we
now briefly discuss the details of how we imple-
mented the Root Cause Analysis (RCA) solution dis-
cussed in Section 2.1.
5.1 Root Cause Analysis Solution
We implemented the RCA solution using the BISON
services discussed in Sections 4.4 and 4.5. Figure 4
shows the first screen presented to a user who is con-
figured to use the RCA solution and has decided to
6
http://en.wikipedia.org/wiki/OLAP
ICEIS 2007 - International Conference on Enterprise Information Systems
586
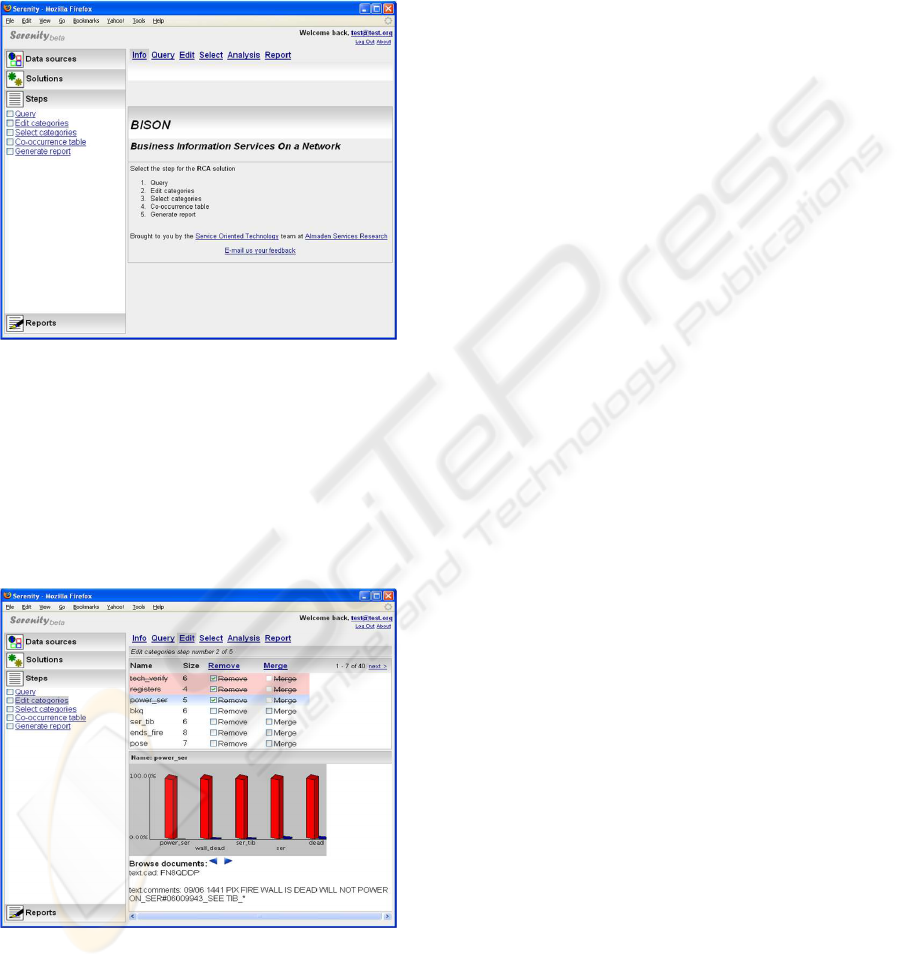
start doing so. Each of the steps on the left hand
side (also implemented as tabs) associates to some
domain or combination of fine-grained service invo-
cations. For instance, in the Query step results in ac-
cessing a datastore, creation of an intuitive taxonomy
cluster on its documents, and a search for the query
phrase over the taxonomy (all using the TAS).
Figure 4: RCA Web application screen shot.
To make the UI more responsive we created an
AJAX-based client layer which allows us to invoke
some of the text analytics services asynchronously
from the user’s browser. Figure 5 shows the taxon-
omy editing step which showcases the value of this
AJAX UI. The categories and documents (which can
be very large) are paged to the client for fast access
by loading remaining results as needed.
Figure 5: RCA taxonomy editing screen shot.
6 LESSONS LEARNED
We can divide the initial lessons learned from the BI-
SON project into three broad categories: (1) service
architecture and design, (2) API design, and (3) deal-
ing with legacy issues. For each category, we give
some specifics and generalizations of what we have
learned.
As we started the BISON project, we debated a
fair amount on how much of the previous code-base
we should reuse and how to tackle the move to SOA.
We have taken a use-case driven, grass-root, bottoms-
up, and iterative approach. Essentially, by taking one
important use-case, we have dissected the previous
code base and exposed an initial API. This API was
then remoted (making necessary adjustments, e.g., to
allow serialization of large objects) and then we added
the layers on top to build a Web application realizing
the use-case. After two or three iterations of the same
use case, we saw some patterns in the API and Web
applications. We refactored (Fowler et al., 1999) the
resulting code and design and evolved the architecture
into the layered version illustrated in Figure 1.
Another important lesson we have learned was in
deciding how fine- or coarse-grained the APIs should
be. We found that this question answered itself as
we iterated and implemented more use cases. For in-
stance, after implementing a complete first use-case,
we had refactored the code enough that we it be-
came trivial to add new coarser-grained services as
they could be built with the primitive, fine-grained
services.
SOA is generally seen as a means for breathing
new life into legacy systems. However, this can be
problematic if the legacy systems have inherent short-
comings or are difficult to abstract as APIs. This was
partly our case; nonetheless, instead of throwing away
completely our old code-base, by following the itera-
tive approach (discussed above) and abstracted legacy
objects into interfaces and using some strategic pat-
terns, such as Factory and Fac¸ade (Gamma et al.,
1995) we were able to gradually reuse the legacy
code while having the capability of fully replacing it
in the future. We should also note that the layered
architectural-style tremendously helped in that tasks
as it gave some module-level components that formed
the boundaries for our APIs.
We were able to create a modern, AJAX-based
Web application, text analytics solution using our ex-
posed Web services. This initial set of results vali-
dates our architecture and also helps validate our evo-
lutionary, use-case-driven architectural approach.
TEXT ANALYTICS AND DATA ACCESS AS SERVICES - A Case Study in Transforming a Legacy Client-server Text
Analytics Workbench and Framework to SOA
587

7 FUTURE DIRECTIONS
The primary direction for future research is in val-
idating and refining the architecture with other use
cases. Since the original BIW tool was deployed in
a wide-ranging set of domains, from heath-care and
drug discovery to blogs and patent databases, we ide-
ally would like to be able to add one example per
domain which would helpfully validate our APIs and
services. Such exercises would also allow us to refac-
tor and better structure the different API layers. We
would expect more abstractions of common interfaces
and also further aggregation and specialization of the
domain-specific portions. In the end, we expect to
evolve our APIs into common and domain-specific
text mining ‘languages’.
Another direction of our research is in improving
our pricing models. Currently our metering infras-
tructure captures some basic usage data. This en-
abled us to create an initial pricing model to charge
customers of BISON on frequency of usage, i.e., fre-
quency of API calls. However, this pricing model is
limited, in particular, for most domain applications of
text analytics and text mining, the end-user actions are
very iterative and repetitive. This means that a model
that measures frequency of usage may not accurately
reflect the value the end-user got from the services.
Instead of simple frequency usage measurements we
need to have means for measuring usage patterns as
well as meter the results from the service calls.
In addition, coarser-grained pricing models, such
as a subscription pay-as-you go or a per-user-session
pay-as-you-use model may be more appropriate for
many of our use cases. To that end, we have made
the pricing model component flexible and pluggable.
This will allow us to experiment with various models
for different clients and domains.
Finally, another important direction is in the user
interfaces and user experience aspects of the entire
BISON stack. In particular we want to create an ini-
tial set of reusable UI views that we can use to as-
semble new solutions. Also, since in general, as men-
tioned before, the process of mining for insights is
very iterative and repetitive, it would be beneficial if
the end-users are able to collaborate and provide feed-
back to the tool; for example, enabling the ability to
tag particular documents in a result set or the abil-
ity to rate documents, entities, and other aspects of
a BISON application. By aggregating the feedback
we could improve the experience of users of common
data sources, e.g., enterprise users mining enterprise
data. The BISON engine could also use this aggre-
gated feedback to improve some of the clustering and
mining operations.
REFERENCES
Agrawal, R. (1999). Data Mining: Crossing the Chasm.
In Proceedings of 5th ACM SIGKDD International
Conference on Knowledge Discovery and Data Min-
ing (KDD-99), San Diego, CA.
Arsanjani, A. (2005). Service-Oriented Modeling and Ar-
chitecture. Technical report, IBM Global Services.
Bass, L., Clements, P., and Kazman, R. (1998). Software
Architecture in Practice. Addison-Wesley, Boston,
MA.
Beck, K. and Andres, C. (2005). eXtreme Programming
Explained: Embrace Change, 2nd Edition. Addison-
Wesley, Boston, MA.
Cheung, W., Zhang, X., Wong, H., Liu, J., Luo, Z., and
Tong, F. (2006). Service-Oriented Distributed Data
Mining. IEEE Internet Computing, 4(10):44–54.
Codd, E. F., Codd, S. B., and Salley, C. T. (1998). Providing
OLAP to User-Analyts: An IT Mandate. Technical
report, E.F. Codd Associates.
Cody, W., Kreulen, J. T., Krishna, V., and Spangler, W. S.
(2002). The Integration of Business Intelligence
and Knowledge Management. IBM Systems Journal,
4(41).
Curbera, F., Goland, Y., Klein, J., Leymann, F.,
Roller, D., Thatte, S., and Weerawarana, S.
(2002). Business Process Execution Lan-
guage for Web Services, Version 1.0. www-
128.ibm.com/developerworks/library/specification/ws-
bpel/.
Exaltec (2006). Exaltec’s b+ J2EE-SOA Application Gen-
erator. www.exaltec.com/appgenerator.html.
Fowler, M., Beck, K., Brant, J., Opdyke, W., and Roberts,
D. (1999). Refactoring: Improving the Design of Ex-
isting Code. Addison-Wesley, Boston, MA.
Gamma, E., Helm, R., Johnson, R., and Vlissides, J.
(1995). Design Patterns: Elements of Reusable
Object-Oriented Software. Addison-Wesley, Reading,
MA.
Guedes, D., Meira, W. J., and Ferreira, R. (2006).
Anteater: A Service-Oriented Architecture for High-
Performance Data Mining. IEEE Internet Computing,
4(10):36–43.
Hempel, J. and Lehman, P. (2005). The MySpace Genera-
tion. Technical report, Business Week Online.
Kumar, A., Kantardzik, M., and Madden, S. (2006). Dis-
tributed Data Mining: Frameworks and Implementa-
tions. IEEE Internet Computing, 4(10):15–18.
Sonic (2006). Sonic SOA Workbench.
www.sonicsoftware.com/products/sonic
workbench.
Spangler, W. S., Cody, W., Kreulen, J. T., and Krishna,
V. (2003). Generating and Browsing Multiple Tax-
onomies over a Document Collection. Journal of
Management and Information Systems, 4(19):191–
212.
ICEIS 2007 - International Conference on Enterprise Information Systems
588
