
ADAPTIVE PREDICTIONS IN A USER-CENTERED
RECOMMENDER SYSTEM
Anne Boyer and Sylvain Castagnos
LORIA, Universit´e Nancy 2
Campus Scientifique B.P. 239
54506 Vandoeuvre-l
`
es-Nancy, France
Keywords:
Distributed Collaborative Filtering, Recommender Systems, Personalization, Grid Computing, Scalability,
Privacy.
Abstract:
The size of available data on Internet is growing faster than human ability to treat it. Therefore, it becomes
more and more difficult to identify the most relevant information, even for skilled people using efficient search
engines. A way to cope with this problem is to automatically recommend data in accordance with users’
preferences. Among others, collaborative filtering processes help users to find interesting items by comparing
them with users having the same tastes. This paper describes a new user-centered recommender system relying
on collaborative filtering and grid computing. Our model has been implemented in a Peer-to-Peer architecture.
It has been especially designed to deal with problems of scalability and privacy. Moreover, it adapts its
prediction computations to the density of the user neighborhood.
1 INTRODUCTION
In order to face the exponential growth of data on the
Internet, intelligent information retrieval assistants
becomes more and more popular and improve the
interactions between users and software. Those as-
sistants, such as recommendersystems relying on col-
laborative filtering, help efficiently people to find in-
teresting items by modeling their preferences and by
comparing them with users having the same tastes.
Nevertheless, there are a lot of problems to deal
with, when implementing a collaborative filtering al-
gorithm. In this paper, we particularly pay attention
to the following significant limitations for industrial
use:
• scalability and system reactivity: recommender
systems must take into account real industrial con-
straints. There are potentially several thousand
users and items to manage. Despite the large num-
ber of parameters, algorithms must compute vir-
tual communities of interests in real time;
• intrusions into privacy: by modeling user actions
and preferences in order to compute recommenda-
tions, intelligent systems access intimate informa-
tion about users. So, we have to be careful to be
as unintrusive as possible and at least to guaran-
tee the anonymity of users. Moreover, because of
the confidential nature of some data, users must be
aware of the prediction computation process and
explicitly choose the part of their profile to take
into account;
• novelty in predictions: according to the context,
users want to have more or less new recommen-
dations. This is why we introduce an adaptive
minimum-correlation threshold of neighborhood
which evolves in accordance with user expecta-
tions.
We propose an algorithm which is based on an
analysis of usage. It relies on a distributed user-based
collaborative filtering technique. Our model has been
integrated in a document sharing system called ”So-
foS”.
1
Our algorithm is implemented on a Peer-to-Peer
architecture because of the document platform con-
text. In a lot of companies, documents are referenced
using a common codification that may require a cen-
1
SofoS is the acronym for ”Sharing Our Files On the
System”.
51
Boyer A. and Castagnos S. (2007).
ADAPTIVE PREDICTIONS IN A USER-CENTERED RECOMMENDER SYSTEM.
In Proceedings of the Third International Conference on Web Information Systems and Technologies - Web Interfaces and Applications, pages 51-58
DOI: 10.5220/0001274300510058
Copyright
c
SciTePress

tral server
2
but are stored on users’ devices. The dis-
tribution of computations and contents matches the
constraints of scalability and reactivity.
In this paper, we will first present the related work
on collaborativefiltering approaches. We will then in-
troduce our Peer-to-Peer user-centered model which
offers the advantage of being fully distributed. We
called this model ”Adaptive User-centered Recom-
mender Algorithm” (AURA). It provides a service
which builds a virtual community of interests cen-
tered on the active user by selecting his/her near-
est neighbors. As the model is ego-centered, the
active user can define the expected prediction qual-
ity by specifying the minimum-correlation threshold.
AURA is an anytime algorithm which furthermore re-
quires very few computation time and memory space.
As we want to constantly improve our model and the
document sharing platform, we are incrementally and
modularly developing them on a JXTA platform
3
.
2 STATE-OF-THE-ART
In centralized collaborative filtering approaches, find-
ing the closest neighbors among several thousands of
candidates in real time may be unrealistic (Sarwar
et al., 2001). On the contrary, decentralization of data
is practical to comply with privacy rules, as long as
anonymity is fulfilled (Canny, 2002). This is the rea-
son why more and more researchers investigate var-
ious means of distributing collaborative filtering al-
gorithms. This also presents the advantage of giving
the ownership of profiles to users, so that they can
be re-used in several applications.
4
We can mention
research on P2P architectures, multi-agents systems
and decentralized models (client/server, shared data-
bases).
There are several ways to classify collaborativefil-
tering algorithms. In (Breese et al., 1998), authors
have identified, among existing techniques, two ma-
jor classes of algorithms: memory-based and model-
based algorithms. Memory-based techniques offer
the advantage of being very reactive, by immedi-
ately integrating modifications of users profiles into
the system. They also guarantee the quality of rec-
ommendations. However, Breese et al. (Breese et al.,
1998) are unanimous in thinking that their scalabil-
ity is problematic: even if these methods work well
2
This allows to have document IDs and to identify them
easily.
3
http://www.jxta.org/
4
As the owner of the profile, the user can apply it to dif-
ferent pieces of software. In centralized approaches, there
must be as many profiles as services for one user.
with small-sized examples, it is difficult to change to
situations characterized by a great number of docu-
ments or users. Indeed, time and space complexities
of algorithms are serious considerations for big data-
bases. According to Pennock et al. (Pennock et al.,
2000), model-based algorithms constitute an alterna-
tive to the problem of combinatorial complexity. Fur-
thermore, these models highlight some correlations in
data, thus proposing an intuitive reason for recom-
mendations or simply making the hypotheses more
explicit. However, these methods are not dynamic
enough and they react badly to insertion of new con-
tents into the database. Moreover, they require a pe-
nalizing learning phase for the user.
Another way to classify collaborative filtering
techniques is to consider user-based methods in op-
position to item-based algorithms. For example,
we have explored a distributed user-based approach
within a client/server context in (Castagnos and
Boyer, 2006). In this model, implicit criteria are used
to generate explicit ratings. These votes are anony-
mously sent to the server. An offline clustering al-
gorithm is then applied and group profiles are sent to
clients. The identification phase is done on the client
side in order to cope with privacy. This model also
deals with sparsity and scalability. The authors high-
light the added value of a user-based approach in the
situation where users are relativelystable, whereas the
set of items may often vary considerably. On the con-
trary, Miller et al.(Miller et al., 2004) show the great
potential of distributed item-based algorithms. They
propose a P2P version of the item-item algorithm.
In this way, they address the problems of portability
(even on mobile devices), privacy and security with
a high quality of recommendations. Their model can
adapt to different P2P configurations.
Beyond the different possible implementations,
we can see there are a lot of open questions
raised by industrial use of collaborative filtering.
Canny (Canny, 2002) concentrates on ways to provide
powerful privacy protection by computing a ”pub-
lic” aggregate for each community without disclos-
ing individual users’ data. Furthermore, his approach
is based on homomorphic encryption to protect per-
sonal data and on a probabilistic factor analysis model
which handles missing data without requiring default
values for them. Privacy protection is provided by
a P2P protocol. Berkovsky et al. (Berkovsky et al.,
2006) also deal with privacy concern in P2P recom-
mender systems. They address the problem by elect-
ing super-peers whose role is to compute an average
profile of a sub-population. Standard peers have to
contact all these super-peers and to exploit these aver-
age profiles to compute predictions. In this way, they
WEBIST 2007 - International Conference on Web Information Systems and Technologies
52

never access the public profile of a particular user.
We can also cite the work of Han et al.(Han et al.,
2004), which addresses the problem of privacy pro-
tection and scalability in a distributed collaborative
filtering algorithm called PipeCF. Both user database
management and prediction computation are split be-
tween several devices. This approach has been im-
plemented on Peer-to-Peer overlay networks through
a distributed hash table method.
In this paper, we introduce a new hybrid method
called AURA. It combines the reactivity of memory-
based techniques with the data correlation of model-
based approaches by using an iterative clustering al-
gorithm. Moreover, AURA is a user-based model
which is completely distributed on the user scale. It
has been integrated in the SofoS document platform
and relies on a P2P architecture in order to distrib-
ute either prediction computations, content or pro-
files. We design our model to tackle, among others,
the problems of scalability, and privacy.
3 MODEL AND
IMPLEMENTATION
SofoS is a document platform, using a recommender
system to provide users with content. Once it is in-
stalled, users can share and/or search documents, as
they do on P2P applications like Napster. We con-
ceive it in such a way that it is as open as possible to
different existing kinds of data: hypertext files, docu-
ments, music, videos, etc. The goal of SofoS is also
to assist users to find the most relevant sources of in-
formation efficiently. This is why we add the AURA
recommender module to the system. We assume that
users can get pieces of information either by using our
system or by going surfing on the web. SofoS conse-
quently enables to take visited websites into account
in the prediction computations.
We are implementing SofoS in a generic envi-
ronment for Peer-to-Peer services, called JXTA. This
choice is motivated by the fact it is greatly used in our
research community.
In (Miller et al., 2004), the authors highlight the
fact that there are several types of possible architec-
tures for P2P systems. We can cite those with a cen-
tral server (such as Napster), random discovery ones
5
(such as Gnutella or KaZaA), transitive traversal ar-
chitectures, content addressable structures and secure
blackboards.
5
Some of these architectures are totally distributed. Oth-
ers mixed centralized and distributed approaches but elect
super-peers whose role is to partially manage subgroups of
peers in the system.
We conceived our model with the idea that it could
be adapted to different types of architectures. How-
ever, in this paper, we will illustrate our claims by
basing our examples on the random approach even if
others may have an added value. The following sub-
section aims at presenting the AURA Algorithm.
3.1 Recommender Module
3.1.1 Privacy
We presume that each peer in SofoS corresponds to
a single user on a given device.
6
For this reason, we
have conceived the platform in such a way that users
have to open a session with a login and a password be-
fore using the application. In this way, several persons
can use the same computer (for example, the different
members of a family) without disrupting their respec-
tive profiles. That is why each user on a given peer
of the system has his/her own profile and a single ID.
The session data remain on the local machine in order
to enhance privacy. There is no central server required
since sessions are only used to distinguish users on a
given peer.
For each user, we use a hash function requiring the
IP address and the login in order to generate his/her
ID on his/her computer. This use of a hash function H
is suitable, since it has the following features:
• non-reversible: knowing ”y”, it is hard to find ”x”
such as H(x) = y;
• no collision: it is hard to find ”x” and ”y” such as
H(x) = H(y);
• knowing ”x” and ”H”, it is easy to compute H(x);
• H(x) has a fixed size.
In this way, an ID does not allow identification of
the name or IP address of the corresponding user. The
communication module uses a IP multicast address to
broadcast the packets containing addressees’ IDs. In
order to reduce the information flow, we can option-
ally elect a super-peer which keeps a list of IDs whose
session is active: before sending a message, a peer can
ask if the addressee is connected. If the super-peer has
no signal from a peer for a while, it removes the cor-
responding ID from the list.
3.1.2 User-centered Predictions
Users can both share items on the platform and inte-
grate a feedback about websites they consult. Each
item has a profile on the platform. In addition to
6
We can easily distinguish devices since SofoS has to be
installed on users’ computers.
ADAPTIVE PREDICTIONS IN A USER-CENTERED RECOMMENDER SYSTEM
53
Adapted
Chan
formula:
Interest(item) = 1 + 2 . IsFavorite(item) + Recent(item) + Frequency(item) . Duration(item)
With: Recent(item) =
date(last visit) − date(log beginning)
date(present) − date(log beginning)
And: Duration(item) = max
consultations
time spent reading item
size of the item
(1)
Interest(item) must be rounded up to the nearest integer.
IsFavorite(item) equals 1 if the item has been explicitly and positively voted by the user (non-numerical vote) and 0 otherwise.
Frequency(item) . Duration(item) must be normalized so that the maximum is 1.
the available documents, each peer owns 7 pieces of
information: a personal profile, a public profile, a
group profile and 4 lists of IDs (list ”A” for IDs of
peers belonging to its group, list ”B” for those which
exceed the minimum-correlation threshold s
x
as ex-
plained below, list ”C” for the black-listed IDs and
list ”O” for IDs of peers which have added the active
user profile to their group profile). An example of the
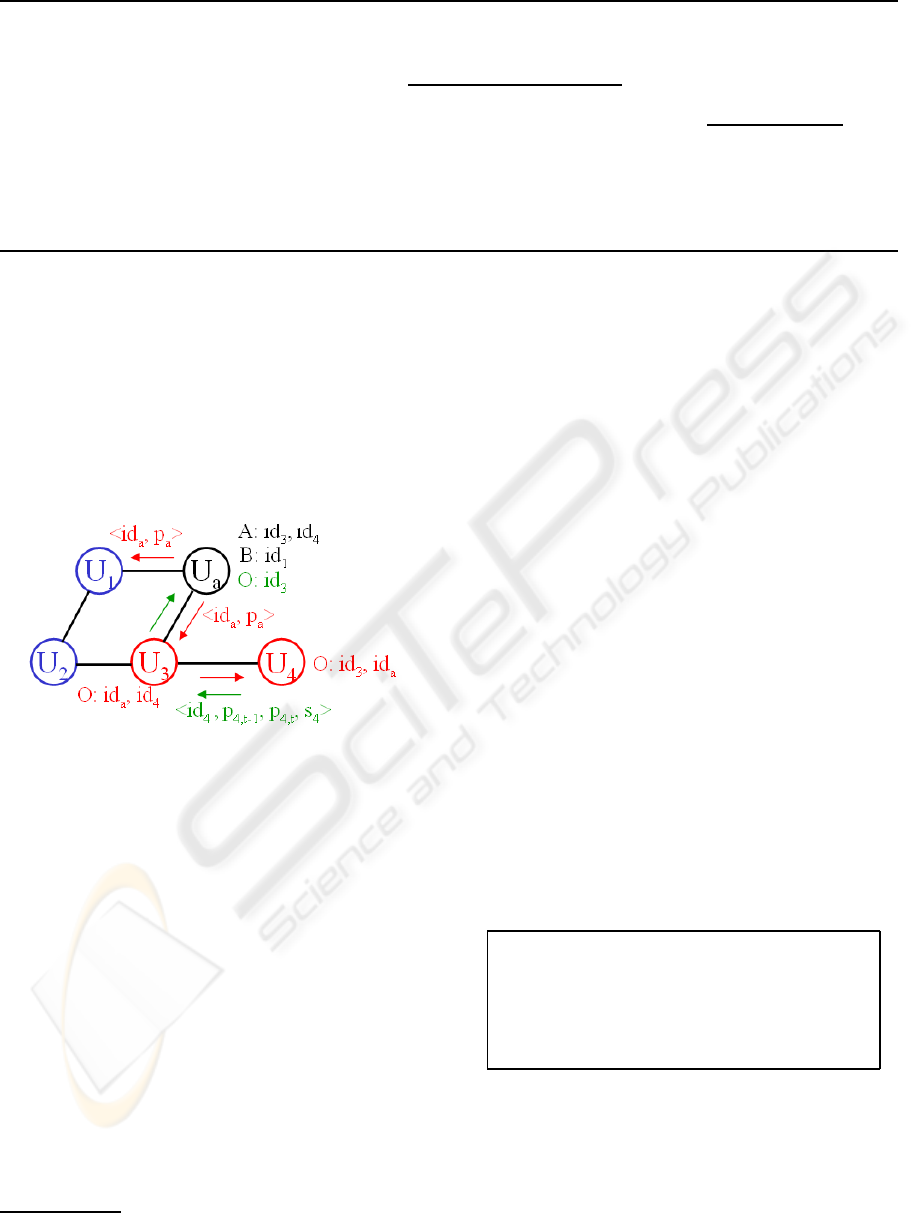
system run is shown on figure 1.
Figure 1: Exchanges of profiles p
x
between peers U
x
with
different IDs.
In order to build the personal profile of the ac-
tive user u
a
, we use both explicit and implicit crite-
ria. The active user can always check the list of items
that he/she shares or has consulted. He/She can ex-
plicitly rate each of these items on a scale of values
from 1 to 5. The active user can also initialize his/her
personal profile with a set of criteria
7
proposed in the
interface in order to partially face the cold start prob-
lem. This offers the advantage of completing the pro-
file with more consistency and of finding similarities
with other users more quickly, since everyone can fill
the same criteria rating form.
We assume that, despite the explicit voluntary
completion of profiles, there are a lot of missing data.
We consequently add to AURA a user modeling func-
tion based on the Chan formula (cf. formula 1).
This fonction relies on an analysis of usages. It tem-
7
Ideally, the set of items in the criteria set should cover
all the implicit categories that users can find on the platform.
porarly collects information about the active user’s
actions (frequency and duration of consultations for
each item, etc.) and transforms them into numeri-
cal votes. In order to preserve privacy, all pieces of
data as regards user’s actions remain on his/her peer.
The explicit ratings and the estimated numerical votes
constitute the active user’s personal profile. The pub-
lic profile is the part of the personal profile that the
active user accepts to share with others.
The algorithm also has to build a group profile. It
represents the preferences of a virtual community of
interests, and has been especially designed to be as
close as possible to the active user’s expectations. In
order to do that, the peer of the active user asks for the
public profiles of all the peers it can reach through the
platform. Then, for each of these profiles, it computes
a similarity measure with the personal profile of the
active user. The active user can indirectly define a
minimum-correlation threshold which corresponds to
the radius of his/her trust circle.
If the result is lower than this fixed threshold
which is specific to each user, the ID of the peer is
added to the list ”A” and the corresponding profile is
included in the group profile of the active user, using
the procedure of table 1.
Table 1: Add a public profile to the group profile.
Proc AddToGroupProfile(public profile of u
n
)
W = W + |w(u
a
,u
n
)|
for each item i do
(u
l,i
) = (u
l,i
) ∗ (W − |w(u
a
,u
n
)|)
(u
l,i
) = ((u
l,i
) + w(u
a
,u
n
) ∗ (u
n,i
))/W
end for
With: (u
l,i
) the rating for item i in the group profile;
(u
n,i
) the rating of user n for item i;
W the sum of |w(u
a
,u
i
)|, which is stored;
w(u
a
,u
n
) the correlation coefficient between
the active user u
a
and u
n
.
We used the Pearson correlation coefficient to
compute similarity, since the literature shows it works
WEBIST 2007 - International Conference on Web Information Systems and Technologies
54
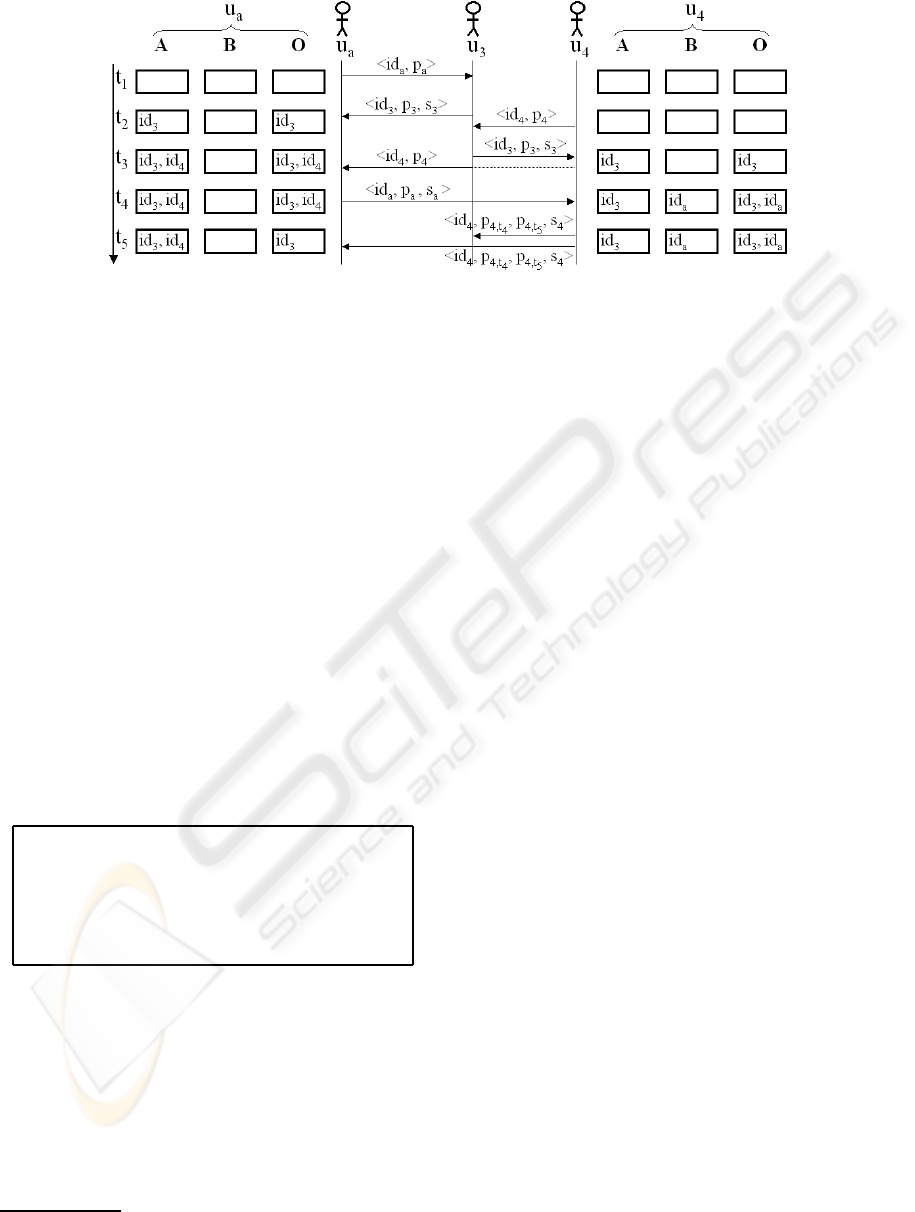
Figure 2: Example of user interactions.
well (Shardanand and Maes, 1995). Of course, if this
similarity measure is higher than the threshold, we
add the ID of the peer to the list ”B”. The list ”C”
is used to systematically ignore some peers. It en-
ables to improve trust – that is to say the confidence
that users have in the recommendations – by identify-
ing malicious users. The trust increasing process will
not be considered in this paper.
When his/her personal profile changes, the active
user has the possibility to update his/her public profile
p
a
. In this case, the active peer has to contact every
peer
8
whose ID is in the list ”O”. Each of these peers
re-computes the similarity measure. If it exceeds the
threshold, the profile p
a
has to be removed from the
group profile, using the procedure of table 2. Other-
wise, p
a
has to be updated in the group profile, that
is to say the peer must remove the old profile and add
the new one.
Table 2: Remove a public profile from the group profile.
Proc RemoveToGroupProfile(old profile of u
n
)
W = W − |w(u
a
,u
n
)|
for each item i do
(u
l,i
) = (u
l,i
) ∗ (W + |w(u
a
,u
n
)|)
(u
l,i
) = ((u
l,i
) − w(u
a
,u
n
) ∗ (u
n,i
))/W
end for
By convention, we use the notation < id, p > for
the peer-addition packet, that is to say new arrivals.
< id, p,s > corresponds to the packet of a peer which
is already connected and sends data to a new arrival.
”s” is the threshold value. There is no need to spec-
ify the threshold value in the peer-addition packet,
since there is a default value (|correlation| >= 0). At
last, < id, p
t−1
, p
t
,s > is the notation for the update
packet. In each of these packets, the first parameter
8
A packet is broadcasted with an heading containing
peers’ IDs, the old profile and the new public profile.
corresponds to the ID of the source of the message.
In order to simplify the notation, we do not include
the addressees’ ID in figure 2.
Figure 2 illustrates how the system works. In this
example, we consider 3 of the 5 users from figure 1.
We show the registers of the active user u
a
and the
user u
4
. At time t
1
, the active user u
a
tries to con-
tact, for the first time, other peers by sending his/her
public profile and his/her ID to neighbors. This is the
packet < id
a
, p
a
>. u
3
receives the packet and an-
swers at t
2
. u
a
computes the distance between the
public profiles p
3
and p
a
. As the Pearson coeffi-
cient is inevitably within the default threshold limit,
u
a
adds id
3
to his/her list ”A”. If the computed cor-
relation coefficient is higher than ”s
3
” which is the
threshold of u
3
, u
a
adds id
3
to his/her list ”O”. Mean-
while, some of the reached peers will add p
a
to their
list ”A” if the correlation is higher than their thresh-
old (this is the case for u
3
). At time t
2
, u
4
arrives
on the platform and sends a packet to u
3
. At time t
3
,
u
3
replies to u
4
and sends the packet of u
4
to peers
that he/she already knows. u
a
receives it and adds
id
4
to his/her list ”A”. He/She also adds id
4
to the
list ”O”, since u
4
is a new arrival and has a default
threshold. At time t
4
, u
a
consequently gives his/her
public profile to u
4
. At the same time, u
4
has changed
his/her threshold and considers that u
a
is too far in
the user/item representation space, that is to say the
correlation coefficient between u
a
and u
4
exceeds the
limit. Thus, u
4
adds id
a
in the list ”B”. In the packet
< id
a
, p
a
,s
a
>, ”s
a
” allows u
4
to know that he/she
must complete the list ”O” with id
a
. At last, u
4
up-
dates his/her public profile. Afterwards, he/she noti-
fies the change to the IDs in the list ”O”. This is the
packet < id
a
, p
4,t
4
, p
4,t
5
,s
4
>. p
4,t
4
and p
4,t
5
are re-
spectively the old and new public profiles of u
4
. When
u
a
receives this packet, he/she updates the list ”O” by
removing id
4
since s
4
is too high for him/her.
ADAPTIVE PREDICTIONS IN A USER-CENTERED RECOMMENDER SYSTEM
55

3.2 Adaptive Minimum-correlation
Threshold
As shown in the previous subsection, the active user
can indirectly define the minimum-correlationthresh-
old that other people must reach in order to be a mem-
ber of his/her community. Concretely, a high corre-
lation threshold means that users taken into account
in prediction computations are very close to the ac-
tive user. Recommendations will be consequently ex-
tremely similar to his/her own preferences. On the
contrary, a low correlation threshold sets forth the will
of the active user to stay aware of generalist informa-
tion by integrating distant users’ preferences. In this
way, the user avoids freezed suggestions by accept-
ing novelty. In the SofoS interface, a slide bar allows
the active user to ask for personalized or generalist
recommendations. This allows AURA to know the
degree to which it can modify the threshold
9
. The de-
fault threshold value is 0, which means that we take all
the peers into account. The default step of threshold is
0.1, but it can be adapted to the density of population.
As shown in figure 3, we split the interval of
the Pearson coefficient’s possible values [−1;+1] into
subsets. For each subset, we keep the count of peers
which have got in touch with the active user and
whose correlation coefficient is contained in the in-
terval corresponding to the subset. Thus, when a user
sends a packet to u
a
, the Pearson coefficient is com-
puted in order to know if the active user’s group pro-
file has to be updated according to the threshold value.
At the same time, we update the corresponding values
in the population distribution histogram. For exam-
ple, if u
a
receives an update packet and the Pearson
coefficient changes from 0.71 to 0.89, we decrement
the register of the interval [0.7;0.8) and we increment
the register of the interval [0.8;0.9). In this way, we
constantly have the population density for each inter-
val.
When the total number of users whose Pearson
coefficient is higher than (threshold + 0.1) exceeds a
given limit (dashed line on figure 3), we increase the
threshold. If there are too many users in the next sub-
set, the threshold increase is lower. For the moment,
the maximum threshold value is 0.2 for users who
want a high degree of novelty and 0.9 for those who
expect recommendations close to their preferences.
10
These values have been arbitrarily chosen. We plan
9
By ”threshold”, we mean the minimum absolute value
of Pearson coefficients to consider in the group profile com-
putation. For example, if the system sets the threshold to
0.1, it means that only peers u
i
whose correlation coeffi-
cient |w(u
a
,u
i
)| is higher than 0.1 will be included in the
group profile of the active user.
10
That is to say they want to retrieve items that they have
high-rated
Figure 3: Adaptive threshold based on density.
to do statistical tests to automatically determine the
ideal thresholds according to the context.
4 DISCUSSION
In order to define the degree of privacy of our rec-
ommender system, we refer to 4 axes of personal-
ization (Cranor, 2005). Cranor assumes that an ideal
system should be based on an explicit data collection
method, transient profiles, user-initiated involvment
and non-invasive predictions. In our system, the users
have complete access to their preferences. They have
an effect on what and when to share with others. Only
numerical votes are exchanged and the logs of user
actions are transient. Even when the active user did
not want to share his/her preferences, it is possible to
do predictions since public profiles of other peers are
temporarily available on the active user device. Each
user has a single ID, but the anonymity is ensured by
the fact that there is no table linking IDs and iden-
tities. This privacy-enhanced process requires more
network traffic than in (Berkovsky et al., 2006), but
it allows the system to perform user-centered rather
than community-centered predictions.
As regards scalability, our model no longer suffers
from limitations since the algorithms used to compute
group profiles and predictions are in o(b), where b is
the number of commonly valuated items between two
users, since computations are made incrementally in
a stochastic context. In return, AURA requires quite
a lot of network traffic. This is particularly true if
we use a random discovery architecture. Other P2P
structures can improve communications (Miller et al.,
2004).
Furthermore, we assume that quality of predic-
tions in real situation should be better – providing
that we found enough neighbors – since the virtual
community of interests on each peer is centered on
the active user. We can influence the degree of per-
sonalization by adjusting the threshold according to
the density of the active user’s neighborhood. The
system just has to increase the threshold in order to
ensure users to retrieve the items that they have high-
WEBIST 2007 - International Conference on Web Information Systems and Technologies
56

rated among their recommendations. To highlight this
phenomenon, we generated a rating matrix of 1,000
users and 1,000 items. The votes follow a gaussian
law and we can see the average number of neighbors
as regards Pearson coefficient scaling on figure 4. We
randomly removed 20% of these votes and applied
the AURA algorithm. Then, we compute the Recall
which measures how often a list of recommendations
contains an item that the user have already rated in
his/her top 10. When increasing the threshold in the
system, this measure becomes higher.
Figure 4: On the left, average distribution of users as re-
gards Pearson coefficient. On the right, recall as threshold
grows.
We have also evaluated our model in terms of pre-
diction relevancy. We used the Mean Absolute Error
(
MAE
).
MAE
is a widely used metric which shows the
deviation between predictions and real user-specified
values. Consequently, we computed the average er-
ror between the predictions and 100,000 ratings of the
GroupLens test set
11
as shown in formula 2.
MAE =
∑
N
i=1
|p
i
− q
i
|
N
(2)
We simulate arrivals of peers by progressively
adding new profiles. As shown on figure 5, we get
predictions as good as using the PocketLens algo-
rithm (Miller et al., 2004). PocketLens relies on a dis-
tributed item-based approach. This comparison con-
sequently demonstrates that AURA provides as rele-
vant results as a performant item-based collaborative
filtering.
Figure 5: MAE as neighborhood size grows.
11
http://www.grouplens.org/
At last, we compared our recommender system
with two centralized algorithms (Item-Item (Sarwar
et al., 2001) and the Correlation-based Collaborative
Filter CorrCF (Resnick et al., 1994)) to illustrate the
added value of the distributed approach. In order to
determine the computation times of these algorithms,
we have generated random public profiles with differ-
ent numbers of items. In this simulation, the votes
of each user follow a Gaussian distribution centered
on the middle of the representation space. Moreover,
only 1% of data in the generated profiles is missing.
12
Since the Item-Item and CorrCF are centralized, we
first aggregate the profiles in a vote matrix.
The results of the tests in term of computation
time are shown in the table 3. The announced times
for the AURA algorithm do not include the duration
required to scan the network in search of public pro-
files. Of course, the difference between AURA and
the two others is mainly due to the fact that we use
as many peers as users for computations. However,
these results illustrate the considerable gain in com-
parison with centralized techniques. AURA allows
to do real-time predictions. There is no need to do
offline computations since we can take into account
10,000 profiles and 150 items in less than an half-
second. Moreover, the system does not have to wait
until all similarity measures end. As the algorithm is
incremental, we can stop considering other peers at
any moment.
5 CONCLUSION
SofoS is a document sharing platform including a
recommender system. To cope with numerous prob-
lems specific to information retrieval, we proposed a
Peer-to-Peer collaborative filtering model which is to-
tally distributed. It allows real-time personalization
and manages the degree of personalization that users
want. We implement it on a JXTA platform which
has been used by researchers all over the world. We
show in this paper that we can deal with important
problems such as scalability, privacy and quality. We
highlight the benefits of our system by doing offline
performance analysis. We plan on validating these
points by testing our model with real users in real con-
ditions.
Our algorithm is anytime and incremental. Con-
trary to PocketLens, our model is user-based because
we consider that the set of items can change. Even
if an item is deleted, we can continue to exploit its
12
Only 1% of missing data is not realistic but can poten-
tially increase the computation time what is interesting in
this case.
ADAPTIVE PREDICTIONS IN A USER-CENTERED RECOMMENDER SYSTEM
57
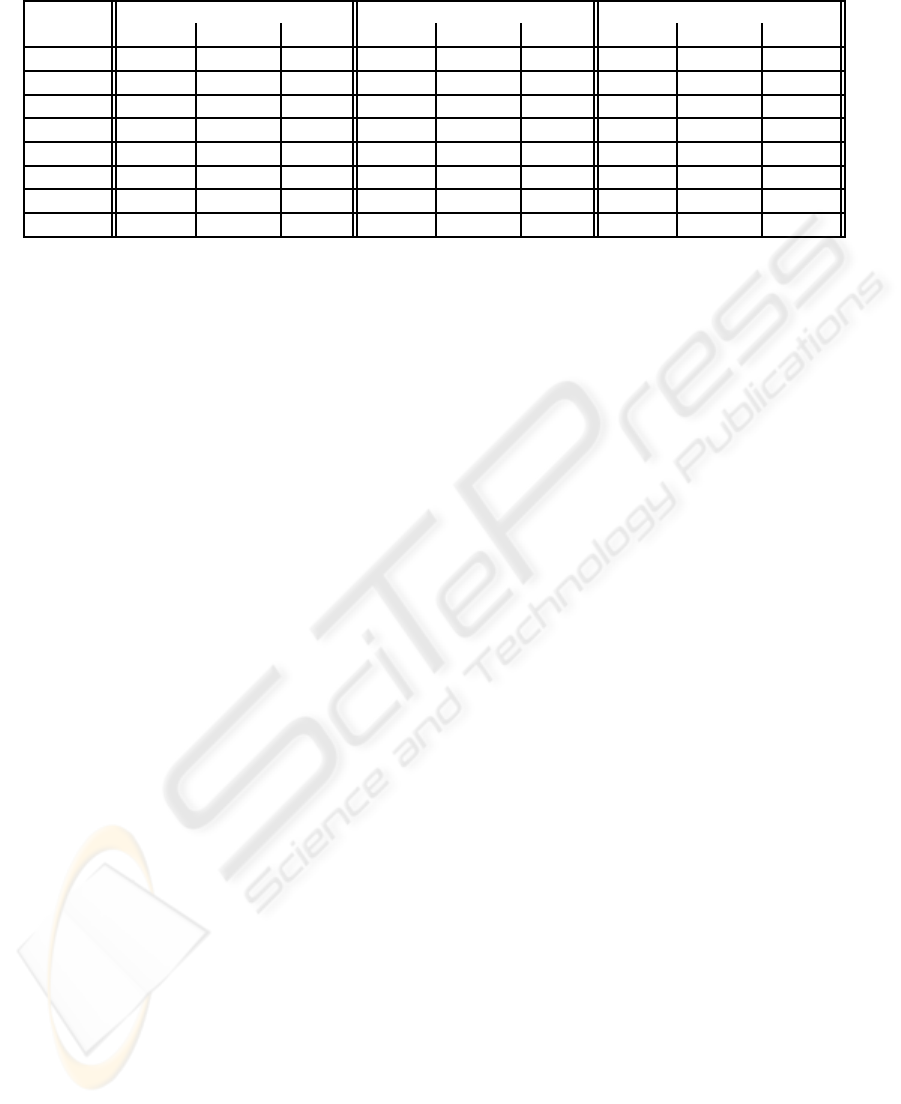
Table 3: Computation times of three collaborative filtering algorithms.
Items 100 150 1000
Users AURA CorrCF It-It AURA CorrCF It-It AURA CorrCF It-It
200 0”01 2”60 2”14 0”01 3”17 2”71 0”07 11”09 52”74
400 0”02 6”09 3”87 0”02 7”62 5”29 0”12 32”24 1’22”
600 0”02 11”78 5”59 0”03 15”21 7”34 0”18 1’04” 2’05”
800 0”03 19”98 7”23 0”04 25”67 10”53 0”27 1’52” 2’33”
1,000 0”03 30”22 8”56 0”05 40”68 12”84 0”30 3’06” 3’25”
1,400 0”04 1’00” 11”50 0”06 1’17” 18”10 0”42 6’04” 4’29”
10,000 0”31 7:30’ 1’22” 0”48 - 2’05” 1”90 - 49’28”
100,000 3”04 - - - - - - - -
ratings in the prediction computations. Moreover, the
stochastic context of our model allows the system to
update the modified profiles instead of resetting all
the knowledge about neighbors. At last, our model is
very few memory-consumingbecause it does not need
to store any neighbors’ ratings, similarity matrix, dot
product matrix and so on. It only requires the sum of
pearson coefficients and four lists of user IDs.
Currently, we are developing our protocols further
to cope with other limitations, such as trust and secu-
rity aspects by using specific communication proto-
cols as in (Polat and Du, 2004).
REFERENCES
Berkovsky, S., Eytani, Y., Kuflik, T., and Ricci, F.
(2006). Hierarchical neighborhood topology for pri-
vacy enhanced collaborative filtering. In in CHI
2006 Workshop on Privacy-Enhanced Personalization
(PEP2006), Montreal, Canada.
Breese, J. S., Heckerman, D., and Kadie, C. (1998). Em-
pirical analysis of predictive algorithms for collabo-
rative filtering. In Proceedings of the fourteenth An-
nual Conference on Uncertainty in Artificial Intelli-
gence (UAI-98), San Francisco, CA.
Canny, J. (2002). Collaborative filtering with privacy. In
IEEE Symposium on Security and Privacy, pages 45–
57, Oakland, CA.
Castagnos, S. and Boyer, A. (2006). A client/server user-
based collaborative filtering algorithm: Model and im-
plementation. In Proceedings of the 17th European
Conference on Artificial Intelligence (ECAI2006),
Riva del Garda, Italy.
Cranor, L. F. (2005). Hey, that’s personal! In the Interna-
tional User Modeling Conference (UM05).
Han, P., Xie, B., Yang, F., Wang, J., and Shen, R. (2004).
A novel distributed collaborative filtering algorithm
and its implementation on p2p overlay network. In
Proc. of the Eighth Pacific-Asia Conference on Knowl-
edge Discovery and Data Mining (PAKDD04), Syd-
ney, Australia.
Miller, B. N., Konstan, J. A., and Riedl, J. (2004). Pock-
etlens: Toward a personal recommender system.
In ACM Transactions on Information Systems, vol-
ume 22.
Pennock, D. M., Horvitz, E., Lawrence, S., and Giles, C. L.
(2000). Collaborative filtering by personality diag-
nosis: a hybrid memory- and model-based approach.
In Proceedings of the sixteenth Conference on Uncer-
tainty in Artificial Intelligence (UAI-2000), San Fran-
cisco, USA. Morgan Kaufmann Publishers.
Polat, H. and Du, W. (2004). Svd-based collaborative fil-
tering with privacy. In Proc. of ACM Symposium on
Applied Computing, Cyprus.
Resnick, P., Iacovou, N., Suchak, M., Bergstorm, P., and
Riedl, J. (1994). Grouplens: An open architecture for
collaborative filtering of netnews. In Proceedings of
ACM 1994 Conference on Computer Supported Co-
operative Work, pages 175–186, Chapel Hill, North
Carolina. ACM.
Sarwar, B. M., Karypis, G., Konstan, J. A., and Reidl, J.
(2001). Item-based collaborative filtering recommen-
dation algorithms. In World Wide Web, pages 285–
295.
Shardanand, U. and Maes, P. (1995). Social information fil-
tering: Algorithms for automating “word of mouth”.
In Proceedings of ACM CHI’95 Conference on Hu-
man Factors in Computing Systems, volume 1, pages
210–217.
WEBIST 2007 - International Conference on Web Information Systems and Technologies
58
