
ONTOLOGY-BASED ADAPTIVE QUERY REFINEMENT
Lefteris Kozanidis, Paraskevi Tzekou, Nikos Zotos, Sofia Stamou and Dimitris Christodoulakis
Computer Engineering and Informatics Department, Patras University, 26500, Greece
Keywords: Web Search, Query Refinement, Ontology, User Modeling, Retrieval Relevance.
Abstract: Query refinement is the process of providing Web information seekers with alternative wordings for ex-
pressing their information needs. Although alternative query formulations may contribute to the improve-
ment of retrieval results, nevertheless their realization by Web users is intrinsically limited in that alterna-
tive query wordings convey explicit information about neither their degree nor their type of correlation to
the user-issued queries. Moreover, alternative query formulations are determined based on the semantics of
the issued query alone and they do not consider anything about the search intentions of the user issuing that
query. In this paper, we introduce a novel query refinement technique which uses a lexical ontology for
identifying alternative query formulations that are both informative of the user’s interests and related to the
user selected queries. The most innovative feature of our technique is the visualization of the alternative
query wordings in a graphical representation form, which conveys explicit information about the refined
queries correlation to the user issued requests and which allows the user select which terms to participate in
the refinement process. Experimental results demonstrate that our method has a significant potential in im-
proving the user search experience.
1 INTRODUCTION
Most of the Web information seekers typically go to
their preferred search engine; submit a query that
expresses their information needs and receive a list
of results that somehow correlate to the information
sought. Although searching the Web is a
straightforward process, users sometimes encounter
difficulties in finding the desired information, basi-
cally because their self-selected queries fail to com-
municate the user information needs in a precise and
comprehensible by the engine manner.
To overcome the above difficulty, a significant
number of researchers have studied ways for assist-
ing Web users in the query selection process. Most
of the work conducted in this respect attempts to
refine the user-issued queries by expanding them
with semantically similar terms. Query expansion
has been an active field of research for quite a long
time and operates upon the availability of basic lin-
guistic infrastructure. In particular, most query ex-
pansion approaches rely on the use of thesauri or
other types of semantic resources from which they
leverage alternative wordings for refining the user
typed queries. Alternative query formulations are
typically in the form of a list of keywords that are
returned to the user together with the search results.
Upon display of alternative query formulations, the
user might, either employ any of the suggested terms
and append them to his initial query (therefore
enabling expansion), or he might ignore the sugges-
tions altogether and either start a new search session
or terminate his search.
Alternative query formulations, although they
might be useful in assisting the users find what they
are looking for, nevertheless they are intrinsically
problematic in that they do not convey any explicit
information about their correlation to the user-issued
query. As such, they do not help the user realize on
the one hand the inadequacy of his self-selected
query terms and, on the other, the suitability of the
system selected terms in capturing the user’s search
intention. Another limitation in most of the existing
query expansion techniques is that they attempt
query refinement based on the query terms alone and
without considering anything about the interests of
the user issuing that query. In other words, query
expansion has been insofar perceived as a query
improvement technique that offers the same alterna-
tive formulations for a given query regardless of the
varying search intentions that are hidden behind that
query.
43
Kozanidis L., Tzekou P., Zotos N., Stamou S. and Christodoulakis D. (2007).
ONTOLOGY-BASED ADAPTIVE QUERY REFINEMENT.
In Proceedings of the Third International Conference on Web Information Systems and Technologies - Web Interfaces and Applications, pages 43-50
DOI: 10.5220/0001267300430050
Copyright
c
SciTePress
In this paper, we address the above challenges
and we propose a novel query refinement technique
that provides alternative query formulations in a way
that is both informative of and tailored to the user
specific information needs. In particular, our tech-
nique relies on the semantics of the pages that match
the user typed query for identifying a set of key-
words to improve that query. Afterwards, it employs
a lexical ontology for measuring the semantic corre-
lation between the pages’ selected keywords and the
terms in the user-issued query. Pages’ keywords that
are semantically related to the initial query terms
constitute the candidate wordings for improving the
query. Identified alternative queries are further ex-
plored in the ontology in order to determine the se-
mantic correlation that they exhibit to each other.
Terms being strongly correlated in the ontology are
selected as alternative wordings for refining the
query. A refined query comprises a set of semanti-
cally similar terms which are interconnected and
displayed to the user in the form of a query graph, as
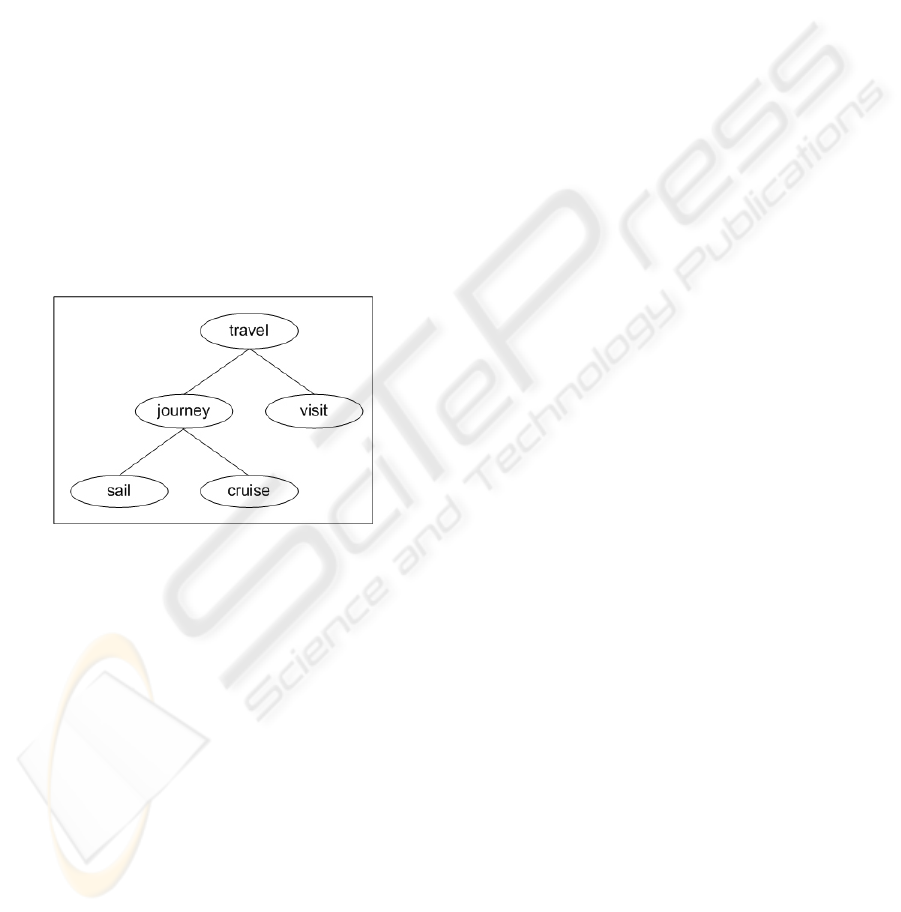
illustrated in Figure 1.
Figure 1: A query graph example.
By selecting alternative query wordings from the
matching pages’ keywords we ensure that the user’s
initial search intention is not neglected in the query
refinement process. Moreover, by exploring the lex-
ical ontology for picking the terms to refine a query,
we guarantee on the one hand the semantic correla-
tion between the user and the system selected terms
and on the other that all alternative query terms re-
late to a common broad concept in the ontology,
resolving thus sense ambiguities. Finally, by dis-
playing alternative query formulation in a graphical
hierarchical structure we ensure the informativeness
of the refined queries.
To evaluate the effectiveness of our ontology-
based query refinement technique in a practical set-
ting we carried out a user survey where we studied
how accurate our technique is in identifying alterna-
tive query formulations that are both comprehensible
and useful to the search engine users. Obtained re-
sults demonstrate that our method has a significant
potential in improving the user search experience.
The remainder of this paper is organized as fol-
lows: in Section 2 we outline the core infrastructure
of our query refinement technique and we describe
in detail the query selection process. In Section 3,
we present our experimental study and we discuss
experimental results. In Section 4, we review related
work and we conclude the paper in Section 5.
2 ONTOLOGY-BASED QUERY
REFINEMENT
Most of the queries issued to Web search engines are
natural language queries. Although natural language
queries are suitable for representing the user infor-
mation needs, nevertheless they oftentimes fail to
retrieve the desired information. This is essentially
due to the variety in the vocabulary between the user
typed queries and the indexed documents. One way
to overcome vocabulary mismatches is to expand the
issued queries with semantically similar terms. In
this paper, we propose the use of a lexical ontology
for selecting alternative query wordings as well as
for structuring these alternative terms in a way that
is perceptible by humans. The main intuition in our
query refinement technique is that humans realize
the suitability of alternative query wordings in terms
of their explicit correlation to both their interests and
self-selected queries.
At a high level, our query refinement method
proceeds as follows. A user goes to a search engine
and starts a query session representing his informa-
tion needs. For every query participating in a user’s
search trace, we collect the retrieved pages and we
process them in order to extract a set of keywords
that represent the pages’ semantic content. We then
employ the pages’ important keywords and we map
them to the lexical elements in the WordNet ontol-
ogy (Fellbaum, 1998). Query matching keywords
that are strongly correlated to each other are deemed
as candidate terms for reformulating the query. We
then select among the candidate query formulations
those terms that are specialized concepts to any of
the queries in the user’s search trace and we present
them to the user in a graphical form.
For editing the refined query graph, we set at the
root node the query that has the broader sense
among all the user issued queries that participate in a
search session. Children nodes represent the set of
query terms and selected keywords that are subordi-
nates of the root concept in the ontology. Relations
between words are represented as links which are
WEBIST 2007 - International Conference on Web Information Systems and Technologies
44
labelled to denote the type of semantic relation that
holds among terms. The user can interactively im-
prove his initial query by clicking on any of the
graph’s nodes. Clicking on a node that has a link to
any of the user issued queries implies that the gener-
ated refined query is a Boolean “and” query that
contains the user defined terms, expanded with the
system selected keywords. Alternatively, clicking on
a node that has no direct link to any of the user is-
sued queries implies that the generated refined query
is a Boolean “or” query that contains any of the sys-
tem selected terms.
In the following paragraph, we present in detail
the process that our model follows for selecting the
candidate terms for reformulating a query. In Sec-
tion 2.2, we describe the way in which our method
explores selected terms for building the refined
query graph. Finally, in Section 2.2.1, we present
how refined query graphs visualize the alternative
query formulations so as to assist the user clarify the
correlation between his self-defined and system-
selected queries. By doing so, we enable the user
interests contribute in the query refinement process.
2.1 Query Terms Selection Process
In selecting alternative query formulations for im-
proving the user issued queries, our refinement tech-
nique operates on the content of the users’ past click
data in order to identify the terms that are relevant to
both the user interests and the issued query seman-
tics. More specifically, in our method we rely on the
queries previously issued by a user and we explore
the content of the pages visited for those queries in
order to determine a set of candidate terms for de-
scribing both the user interests and the user queries
semantics. Those candidate terms are used for refin-
ing that user’s subsequent queries.
In particular, given a set of queries issued by a
user during a search session and given also the set of
pages visited for those queries, we employ the vector
space model and we pre-process pages in order to
extract from the pages’ main body (i.e. text) a set of
candidate terms to participate in the query refine-
ment process. As candidate terms we consider only
nouns and proper nouns because these convey most
of the semantic information in texts (Gliozzo et al.,
2004). We then apply the TF*IDF weighting scheme
(Salton and Buckley, 1988) for measuring the candi-
date terms’ importance in the user’s past click-
through data. Finally, we select those terms whose
importance values are within the top 10% of all the
term values considered, and we further explore them
in the WordNet lexical ontology as described in the
following section.
Before delving into the details of the query for-
mulation process, we point out that by selecting the
alternative query wordings from the content of the
pages that have been previously visited by a user; we
ensure that only user relevant terms participate in the
refinement process. Moreover, by leveraging a lexi-
cal ontology for identifying the semantic correlation
between alternative query formulations and the user
interests, we guarantee that refined queries are both
informative of the user’s interests and related to his
search intentions as we will show next.
2.2 Refined Query Formulation
So far we have described the process that our model
follows for selecting a set of candidate terms to re-
fine a query, based on the content terms in the pages
previously visited by a user. We now turn our dis-
cussion on how our model explores the lexical on-
tology for identifying the semantic correlation be-
tween these candidate terms and the user issued que-
ries. Selected terms that exhibit a strong correlation
to the user queries are the ones that our model sug-
gests as alternative query formulations to the user.
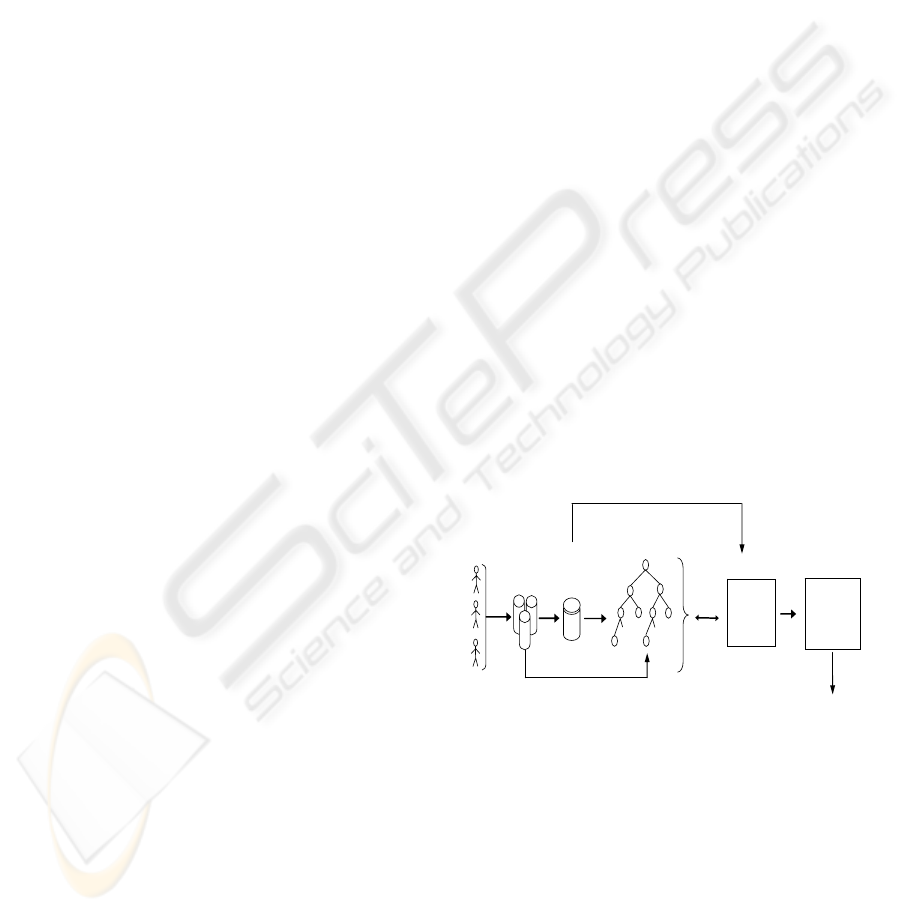
Figure 2, illustrates the query refinement process
that our model follows. In practice, a refined query
contains the set of terms from a user’s past click
history that are both informative of the user’s search
interests and correlated to the user’s search requests.
Indexing
Keywords
Issued
Queries
...
...
Semantic
Similarity
Module
Query
Refinement
Module
Alternative Query
Formulation
Query
Sessions
Figure 2: The query refinement process.
In refining a query issued by a user, our model
relies on the terms selected from that user’s click-
through data and proceeds as follows. Selected terms
together with all the queries participating in the
user’s search trace, from which these terms origi-
nate, are mapped to the ontology’s nodes. Thereaf-
ter, our system measures the relevance score of
every selected term against each of the queries in the
ONTOLOGY-BASED ADAPTIVE QUERY REFINEMENT
45

search trace. Relevance score is determined by the
semantic similarity measure, introduced in (Resnik,
2005) which is established on the hypothesis that the
more information two concepts share in common,
the more similar they are. The information shared by
two concepts is indicated by the information content
of their most specific common subsumer. Formally
the semantic similarity between two words, w
1
and
w
2
, connected in the ontology via a relation r is
given by:
(
)
r12 12
s i m ( w , w ) = - log P m s cs ( w , w )
(1)
The measure of the most specific common sub-
sumer (mscs) depends on: (i) the length of the short-
est path from the root to the most specific common
subsumer of w
1
and w
2
and (ii) the density of con-
cepts on this path. Based on the semantic similarity
values between the query terms and the words in a
user’s click history we determine the set of terms
that our system suggests for refining a given query
of the user.
In picking the terms to refine a user typed query
among the set of candidate words, our model oper-
ates on a twofold criterion. On the one hand, se-
lected terms should constitute specialized concepts
of any of the query concepts in a user’s search trace,
i.e. the type of relation r in the above equation
should be set to hyponymy. On the other hand, se-
lected terms should be strongly correlated to any of
the queries in the user’s search trace, i.e. the value of
their correlation should be among the top 10% of all
their correlation values to the queries in the user’s
search trace.
By enabling only hyponyms of the user submit-
ted queries participate in the refinement process, we
ensure that the system suggested terms are both
relevant to the user queries and useful in helping the
user clarify his vague information needs. Moreover,
by allowing from all the candidate query hyponyms
only the closest hyponyms (i.e. those with a high
correlation value) participate in the refinement proc-
ess, we ensure that the system suggested terms are
not overly specific and as such that they will retrieve
information that is both useful and relevant to the
user’s needs.
Having identified the selection process of the
terms that our system suggests to the user for refor-
mulating his query, we now describe the visualiza-
tion of the refined query. Refined query visualiza-
tion pertains to the structuring of the alternative
query formulations in a query graph. A refined query
graph sets a word at each of its nodes and links
nodes in a hierarchical structure so as to enable the
user’s navigation in the system selected terms.
2.2.1 Visualizing Refined Queries
For editing the refined query graph, we set at the
root node the query that has the broader sense
among all the user issued queries that participate in a
search session. In selecting the term to be set at the
root of the query graph, we rely on WordNet and we
measure the semantic distance that every query in a
search trace has from a top level concept. We then
pick the query term of the minimum distance from a
top node to denote the root concept of the generated
query graph. For instance, consider that the follow-
ing queries participate in a user’s search session:
subway, railway, transportation, and car. Mapping
the above queries to WordNet hierarchies and esti-
mating their semantic distance from WordNet’s top
nodes, results into the identification of the query
term transportation as the query with the broader
sense among all queries in the considered session. In
the above example, our model would set the term
transportation at the root node of the refined query
graph.
Having selected the root term of the query graph,
we proceed with the structuring of the graphs’ chil-
dren nodes. Children nodes represent the remaining
terms in the user’s session as well as the terms that
our system has selected from the visited pages. For
structuring the children concepts under the graph’s
root, we again explore the semantic relations en-
coded among the above terms in WordNet and we
pick those terms that are interconnected through a
specialization link for editing the children concepts
of the refined query graph.
At the end of this process our system builds a
graph of the terms that are suggested to the user as
alternative formulations of his queries. The resulting
graph is a hierarchy of concepts that sets at its root
the most general term that a user has selected for
describing his vague information need. The lower
concepts in the hierarchy are a combination of the
user and the system selected terms that convey in-
formation about more specific concepts which clar-
ify the user’s information need.
Figure 3 illustrates the refined query graph gen-
eration process. In our example we assume four que-
ries in a search session, i.e. q
1
, …q
4
and 7 keywords
identified by our system as candidate query reformu-
lations, i.e. k
1
, …, k
7
. From all the queries in the ses-
sion, we denote q
3
to be the query of the broader
sense. Moreover, we use WordNet ontology for
identifying the semantic relations that hold between
both query terms and selected keywords. Thereafter,
WEBIST 2007 - International Conference on Web Information Systems and Technologies
46
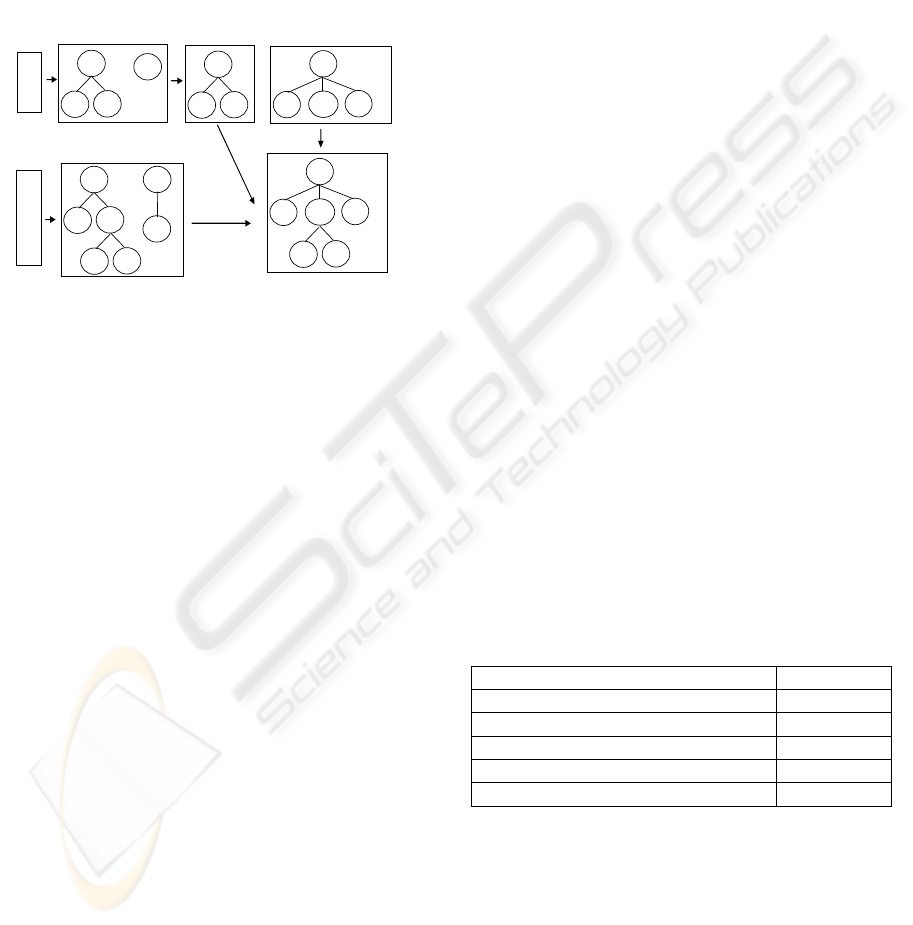
following the approach described above, our system
initializes a query graph by setting the query of the
broader sense at the root node and proceeds with the
children nodes as these are determined on the basis
of their specialization (is-a) links in WordNet hierar-
chies. Query terms and pages’ selected keywords
that are specializations of the root term are added to
the query graph and presented to the user, as shown
in the Figure below.
Query
Session
q
1
q
2
q
3
q
4
q
2
q
4
q
3
q
2
q
4
q
3
q
1
q
2
K
4
q
3
q
4
WordNet Data
k
1
k
2
k
3
k
4
k
5
k
6
k
7
k
6
k
7
k
3
k
4
k
1
k
5
k
2
q
2
K
4
q
3
q
4
k
5
k
2
Refined
Q
uer
y
Gra
p
h
Query Relations
Interests User
Graph
Selected
keywords
System Query Graph
Figure 3: The refined query graph generation process.
The user can interactively improve his initial
query by clicking on any of the graph’s nodes.
Clicking on a node that has a link to any of the user
issued queries implies that the generated refined
query is a Boolean “and” query that contains the
user defined terms, expanded with the system se-
lected keywords. Alternatively, clicking on a node
that has no direct link to any of the user issued que-
ries implies that the generated refined query is a
Boolean “or” query that contains any of the system
selected terms.
Although the proposed query graph has weights
on its nodes and links, indicating the degree of se-
mantic similarity between the respective concepts,
these values are currently not visible, nor are they
editable. We defer the description of both their visu-
alization and editing for a future study.
3 EXPERIMENTAL SETUP
To evaluate the effectiveness of our query refine-
ment technique in providing users with alternative
query formulations that are both informative and
representative of the user’s particular search needs,
we experimentally studied the effect that our refined
queries have on both retrieval performance and the
users’ perception of the refined queries correlation to
their search intentions.
For our study, we launched a prototype search
engine of 500K pages and we implemented a proto-
type query refinement system using a Pentium R4
server, which is an RDBMS SQL database. Word-
Net hierarchies were stored in the database and ac-
cessed on a demand basis. Moreover, the TF*IDF
values of the indexed pages’ terms were pre-
computed at the index level and stored separately.
Similarity scores between the user queries and the
pages’ selected keywords were computed dynami-
cally and stored in a secondary similarity index. The
execution time of our query refinement module is
proportional to the number of pages considered for
alternative query wordings selection. To minimize
our system’s complexity, we computed the candidate
terms TF*IDF values offline.
Having launched our system, we relied on the
query sessions and the clickthrough data of six ex-
perienced Web users that we contacted for evaluat-
ing the effectiveness of our technique. In particular,
we used all the queries participating in the consid-
ered query sessions as well as the pages visited for
each of those queries as our experimental dataset.
Following the process described above, we proc-
essed the pages visited for each of our experimental
queries and we selected a number of keywords for
refining each of the above queries. System selected
keywords together with their corresponding user
issued queries were mapped to the WordNet ontol-
ogy’s nodes and following the steps presented in
Section 2.2, our system generated a refined query
graph for each of the queries examined. Table 1
summarizes some statistics on our experimental
data.
Table 1: Statistics on the experimental dataset.
# of sessions 6
# of queries 57
avg. # of queries/user 9.5
avg. # of visited pages /query 5.3
avg. # of selected keywords / refined query 3.8
avg. # of nodes/ refined query graph 5.2
We then presented the generated refined query
graphs to the respective participants in our survey
and asked them to execute the improved queries by
clicking on any of the system selected terms in the
query graph and examine the first 10 pages returned
for each of their queries. In this respect, we asked
our subjects to evaluate how useful and therefore
intuitive the refined queries are, by indicating on a
5-point scale (i) how accurate the refined queries are
ONTOLOGY-BASED ADAPTIVE QUERY REFINEMENT
47
in capturing their search intentions and (ii) how ef-
fective the refined queries are in retrieving the de-
sired information. With respect to this last criterion
we asked our participants to compare the retrieval
performance for each of their queries before and
after refinement.
In judging the user ratings, we perceive accuracy
of a refined query to be indicative of our technique’s
ability in considering the user interests in the re-
finement process. On the other hand, we perceive
effectiveness of a refined query to be indicative of
our technique’s potential in improving the relevance
of retrieved results. Obtained results are presented
and discussed in the following section.
3.1 Experimental Results
We begin our evaluation, by discussing the effec-
tiveness that our query refinement technique has on
retrieval performance. In this respect, we explore the
ratings that our users gave to the relevance of the top
10 results retrieved for each of their queries, with
and without refinement. We then computed, for each
of our subjects an average rating, which indicates
that user’s overall perception of our technique’s effi-
ciency in improving relevance of retrieved results.
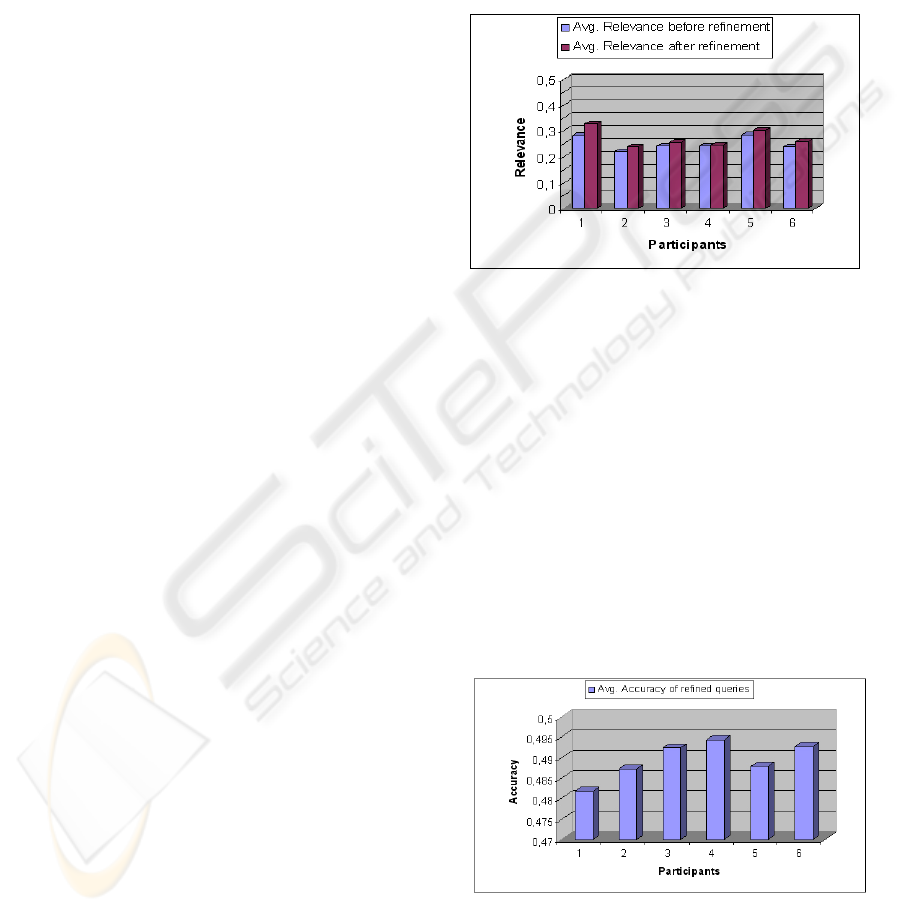
In Figure 4 we aggregate the average ratings by
participants to show the overall effectiveness of our
query refinement technique in improving the user
search experience. The x-axis represents our partici-
pants and the y-axis indicates the average ratings
that each of our subjects gave to the relevance of the
retrieved results. Average ratings are given on a 5-
point scale, with values ranging between 0 and 0.5,
with 0.5 indicating that all the pages considered (i.e.
the first ten pages returned for each query) are
highly relevant to the issued query. In the Figure, for
each participant the first column represents the aver-
age ratings for retrieval performance based on the
user issued queries alone, whereas the second col-
umn represents the average ratings for retrieval per-
formance based on the refined queries, suggested by
our system.
Note that, in our experiments, refined queries are
Boolean “or” queries since we asked our participants
to pick any of the system suggested terms for im-
proving their self-selected queries. By doing so, we
ensure that our evaluation reflects the true efficiency
of our system in identifying alternative query formu-
lations that are valuable to Web users. Nevertheless,
we plan to evaluate the efficiency of Boolean “and”
refined queries in a forthcoming study.
Obtained results demonstrate the potential that
our query refinement technique has in improving
retrieval performance. Specifically, we observe that
all our subjects deemed the first ten retrieved results
to be more relevant to their queries after these are
refined, compared to the relevance of the results
returned for the same non-refined queries. There-
fore, we claim that our system is efficient in select-
ing alternative query formulations that are relevant
to the user typed queries and being such they con-
tribute to the retrieval of results that are highly rele-
vant to the user information needs.
Figure 4: Average relevance of the top ten retrieved pages.
To further support our claim, we measured the
user’s perception of the refined queries’ accuracy in
capturing their search intentions. Figure 5, illustrates
the user ratings for the refined queries accuracy. The
x-axis represents our participants and the y-axis in-
dicates the average ratings that each of our subjects
gave to the accuracy of the system selected terms in
representing their search intentions. Average ratings
are again given on a 5-point scale; with values rank-
ing from 0 to 0.5; with 0 indicating that the system
selected keywords are inaccurate in representing the
user intentions and 0.5 indicating that the system
selected keywords perfectly represent the user inten-
tions.
Figure 5: Accuracy of the refined queries in capturing user
search intentions.
WEBIST 2007 - International Conference on Web Information Systems and Technologies
48

Obtained results confirm the validity of our as-
sumption that relying on the semantics of the query
matching pages for selecting the terms to reformu-
late a query, results to a refined query that is both
relevant to the user typed request and the user search
intention. A detailed analysis of the obtained results
indicates that all the subjects in our study deemed
the alternative query formulations suggested by our
system, as highly relevant to their search intentions.
Therefore, we claim that our approach has a promis-
ing potential in assisting Web users select queries
that are expressive of their underlying search inten-
tions.
Although experimental results demonstrate the
potential that our query refinement technique has in
improving retrieval performance and ultimately the
user search experience, nevertheless our study is so
far preliminary and involves a small number of both
users (i.e. 6) and queries (i.e. 57). We are currently
investigating the effectiveness that our refinement
technique has on a larger pool of both users and que-
ries. Moreover, we are examining ways of improv-
ing our system’s effectiveness by incorporating a
spell-checker at the query processing module, which
relies on both the user’s previous queries and the
ontology’s terms to correct any spelling mistakes
that might appear in the user typed queries.
4 RELATED WORK
There has been much work on query refinement,
aiming at dealing with vocabulary mismatches in the
course of Information Retrieval (IR). Previous stud-
ies, address the automatic expansion of queries by
using co-occurrence data (Jones and Barber, 1971),
syntactic context (Grefenstette, 1992) or relevance
information (Smeaton and van Rijsbergen, 1993).
For identifying semantically related terms, many
types of thesauri have been employed, ranging from
hand-crafted (Vossen, 1998), to co-occurrence-based
(Chen et al., 1995), (Crouch, 1990), (Qui and Frei,
1993) and head-modifier based thesauri (Grefen-
stette, 1992) (Jing and Croft, 1994). Aside from
automatic query expansion, semi-automatic tech-
niques have been proposed, such as the relevance
feedback analysis (Harman, 1992), where the related
terms come from user-identified relevant documents,
or the local feedback analysis (Xu and Croft, 1996),
where the top N retrieved documents are used for
finding query-related terms.
Although early IR studies address the problem of
query expansion within the limited scope of small
text collections, the Web’s evolution introduced sig-
nificant challenges in improving IR efficiency. For
the effective expansion of queries in the context of
Web searching, many approaches have been ad-
dressed. Some of these rely on past queries to im-
prove automatic query expansion. For instance, the
work of (Fitzpatrick and Dent, 1997) uses the results
of the users’ past queries to formulate affinity pools,
out of which the terms employed for expansion are
selected. This technique has demonstrated an im-
provement of 15% on TREC-5 collection. More re-
cently, the work reported in (Billerbeck et al., 2003),
evaluates a query association technique to expand
the TREC-10 Web track (Hawking and Craswell,
2001) queries. This approach concerns associating
queries to a document if they share a high statistical
similarity with the document. Experimental results
showed that query expansion based on associations
yields 18%-20% retrieval improvement compared to
an optimal conventional expansion approach. Fi-
nally, other efforts i.e. (Khan et al., 2004) (Celik and
Elci, 2006), concentrate on utilizing conceptual on-
tologies to find conceptually related terms and thus
improve IR effectiveness.
The approaches summarized here, touch upon
aspects related to our work and as such we perceive
our approach to be complementary to other query
refinement techniques. However, what makes our
method different from existing techniques is that we
assist the user realize the underlying correlation be-
tween his self-selected queries and the refined query
wordings that are suggested by the system. To
achieve that, we visualize refined queries in the form
of a lexical graph and we enable the user interact
with this suggested query graph by clicking on the
terms he wishes to employ in his refined search.
This way, our query refinement technique is not only
effective in identifying alternative query formula-
tions but it is also adaptive in the sense that it allows
a user select different reformulations for the same
query, depending on the specific search needs that
he has every time he issues a query.
5 CONCLUDING REMARKS
In this paper we have discussed the query refinement
problem and we have introduced a novel query re-
finement technique which uses a lexical ontology for
selecting a set of semantically related terms for re-
formulating a query.
In particular, we proposed the investigation of a
user’s previous searches and the query relevant
documents’ semantics for selecting a set of terms
that are both informative of the user’s search inten-
tions and semantically related to the user issued que-
ries. These terms are then employed by our query
refinement module which computes their semantic
ONTOLOGY-BASED ADAPTIVE QUERY REFINEMENT
49

similarities in WordNet ontology and, based on both
their similarity values and their semantic relation
types; it determines which terms to participate in the
refined query. Refined query terms are organized in
a hierarchical structure, the so-called refined query
graph, which sets at its nodes the refined query
terms and links them together, enabling the user
navigate from the most general to the most specific
terms suggested by the system.
The preliminary experimental evaluation of our
technique demonstrates that our query refinement
method has a significant potential in improving the
user search experience. In particular, experimental
results indicate that users perceive the refined que-
ries that our system suggests, to be highly informa-
tive and highly relevant to their search intentions. As
such, we argue that our method has a promising po-
tential in assisting Web users issue queries that de-
scribe their information needs in an accurate and
comprehensive manner.
Although, further experimentation is needed be-
fore we deploy our technique to a practical setting,
nevertheless be believe that our approach can pave
the ground for more elaborate approaches in the
query refinement process, especially when it comes
to the users’ interaction with query refinement ser-
vices. However, one issue that our method leaves
open is how to handle cases where a user’s search
profile gets contaminated from searches that reflect
temporary rather than persisting information inter-
ests. We defer this study for a future work, since it
requires a significant body of research on how users
search the Web.
ACKNOWLEDGEMENTS
The work reported here is partially supported by the
Greek Secretariat of Research and Technology
(GSRT) under a PENED Grant awarded to the first
author. Any opinions, findings, and conclusions or
recommendations expressed in this material are
those of the author(s) and do not necessarily reflect
the views of the GSRT.
REFERENCES
Billerbeck, B., Scholer, F., Williams, H.E., Zobel, J.,
2003. Query Expansion Using Associated Queries. In
Proceedings of the ACM CIKM International Confer-
ence on Information and Knowledge Management,
New Orleans, Louisiana, USA.
Celik, D., Elci, A. 2006. Discovering and Scoring of Se-
mantic Web Services based on Client Requirement(s)
through a Semantic Search Agent. In Proceedings of
the 30
th
Annual International Computer Software and
Applications Conference, Vol. II, IEEE Computer So-
ciety Press, pp. 273-278.
Chen, H., Schatz, B., Yim, T., Fye, D., 1995. Automatic
Thesaurus Generation for an Electronic Community
System. In ASIS Journal, Vol. 46(3) pp. 175-193.
Crouch, C., 1990. An Approach to the Automatic Con-
structions of Global Thesauri. In Information Process-
ing and Management, Vol. 26(5) pp. 139-147.
Fellbaum, Ch., 1998. WordNet: an Electronic Lexical
Database, MIT Press.
Fitzpatrick, L., Dent, M., 1997. Automatic Feedback Us-
ing Past Queries: Social Searching? In Proceedings of
the 20
th
ACM-SIGIR Conference, pp. 306-313.
Gliozzo, A., Strapparava, C., Dagan, I., 2004. Unsuper-
vised and Supervised Exploitation of Semantic Do-
mains in Lexical Disambiguation. In Computer Speech
and Language, 18(3) pp. 275-299.
Grefenstette, G., 1992. Use of Syntactic Context to Pro-
duce Term Association Lists for Text Retrieval. In
Proceedings of the 15
th
ACM SIGIR Conference.
Harman, D., 1992. Relevance Feedback Revisited. In Pro-
ceedings of the 15
th
ACM SIGIR Conference.
Hawking, D., Craswell, N., 2001. Overview of the TREC-
2001 Web Track. In: Voorhees, E., Harman, D.K.
(eds.): The Tenth Retrieval Conference. NIST Special
Publication pp. 500-250, Washington D.C.
Jing, Y., Croft, B., 1994. An Association Thesaurus for
Information Retrieval. In RIAO Conference.
Khan, L., McLeod, D., Hovy, E., 2004. Retrieval Effec-
tiveness of an Ontology-Based Model for Information
Selection. In VLDB Journal, Vol. (13) pp. 71-85.
Qui, Y., Frei, H.P., 1993. Concept Based Query Expan-
sion. In Proceedings of the 16
th
ACM SIGIR Confer-
ence.
Resnik, Ph., 2005. Using Information Content to Evaluate
Semantic Similarity in a Taxonomy. In Proceedings of
the 14
th
Intl. Joint Conference on Artificial Intelli-
gence, pp. 448-453.
Salton, G., Buckley, C., 1998. Term Weighting Ap-
proaches in Automatic Text Retrieval. In Information
Processing and Management, Vol. 24(5) pp. 513-523.
Smeaton, A.F., van Rijsbergen, C.J., 1993. The Retrieval
Effects on Query Expansion on a Feedback Document
Retrieval System. In Computer Journal, Vol. 26(3) pp.
239-246.
Spark Jones, K., Barber, E.B., 1971. What Makes an
Automatic Keyword Classification. In ASIS Journal,
Vol. (18) pp. 166-175.
Vossen, P., 1998. EuroWordNet: a Multilingual Database
with Lexical Semantic Networks. Kluwer Academic
Publishers.
Xu, J., Croft, B., 1996. Query Expansion Using Local and
Global Document Analysis. In Proceedings of the 15
th
ACM SIGIR Conference
.
WEBIST 2007 - International Conference on Web Information Systems and Technologies
50
