
AUGMENTING SEARCH WITH CORPUS-DERIVED SEMANTIC
RELEVANCE
Zachary Mason
Brandeis University
Waltham, MA
Keywords:
Corpus linguistics, semantic search, query refinement, semantic modeling.
Abstract:
This paper describes a system for doing contextually-steered web search. The system is based on a method for
estimating the semantic relevance of a web page to a query.
Consider doing a web search for conferences about web search. The query “search conferences” is not effec-
tive, as it produces results relevant for the most part to searching over conferences, rather than conferences
on the topic of search. The system described in this paper enables queries of the form “search conference
context:pagerank”. The context field in this example specifies a preference for results semantically relevant
to the term “pagerank”, although there is no requirement that said results contain the word “pagerank” itself.
This a more semantic, less lexical way of refining the query than adding literal conjuncts.
Contextual search, as implemented in this paper, is based on the Google (Google) search engine. For each
query, the top one hundred search results are fetched from Google and sorted according to their relevance to
the context query. Relevance is computed as a distance function between the vocabulary vectors associated
with a web-page and a query. For queries, the vocabulary vector is formed by aggregating the web-pages in
the search results for that query. For web-pages, the vocabulary vector is aggregated from that web-page and
other web-pages nearby in link-space.
1 SEMANTIC MODELS OF TEXT
The Internet has a tremendous amount of information
much of which is encoded in natural language. Hu-
man natural language is innately highly polysemous
at both the word and phrasal level, so texts are rife
with ambiguity. This is a problem for purely lexical
search engines. One can refine an ambiguous query
by successively adding qualifiers, but this can be time
consuming and the variety of ways a given idea can be
expressed can make the addition of query conjuncts
dangerously restrictive.
For contextual search we need a way to computa-
tionally model the semantics of short texts - queries
are usually no more than a few words and the amount
of text on a web page can be as low as zero. What is
needed is an approach that supports quick computa-
tions and requires no background knowledge. In the
approach described in this paper, the semantic repre-
sentation need only support a similarity operator (it
is not necessary that, for instance, propositional in-
formation should be extractable from it.) Further re-
quirements are that representations should be com-
pact, should be noise tolerant, and should permit the
comparison of arbitrary texts. Our solution is to use
vectors of associated vocabulary to model the seman-
tics of queries and web pages.
For a query, we obtain a vocabulary vector by do-
ing a web-search on that query (on (Google), for in-
stance), taking all the snippets associated with each
of the top 100 search results and breaking them into a
bag-of-words representation.
A more thorough approach is fetching N result
links from the web search, follow them, and amalga-
mating their text. The disadvantage to this approach is
the time required - web-pages may be served slowly,
in practice averaging on the order of seconds to load,
and in any event this approach is bandwidth inten-
sive. Empirically, we find that the expanded repre-
sentation obtained from using whole web pages rather
than snippets does not improve performance (proba-
bly because with snippets performance is already very
367
Mason Z. (2007).
AUGMENTING SEARCH WITH CORPUS-DERIVED SEMANTIC RELEVANCE.
In Proceedings of the Third International Conference on Web Information Systems and Technologies - Web Interfaces and Applications, pages 367-371
DOI: 10.5220/0001259403670371
Copyright
c
SciTePress
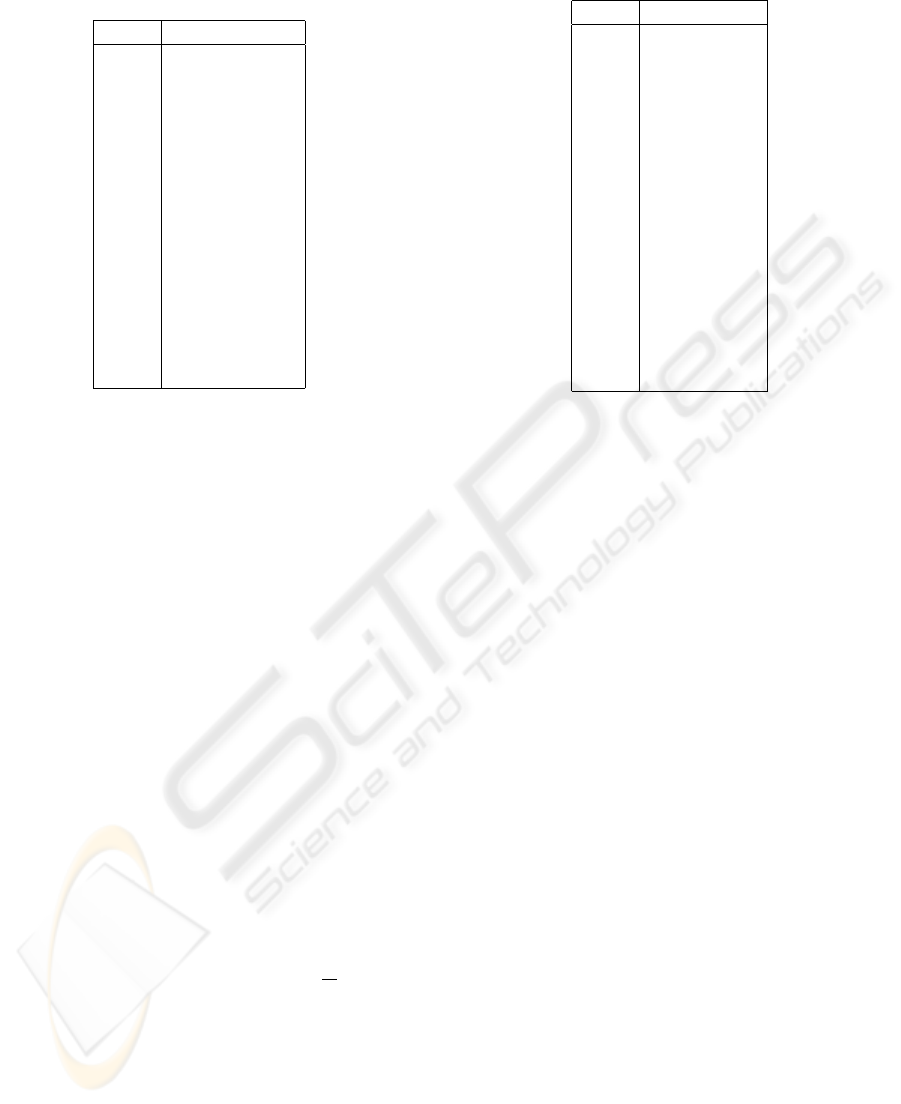
Table 1: Most frequent symbols from vocab. vector of
query “pagerank”.
count symbol
15 software
14 tutorials
12 technology
11 programming
11 development
9 applets
7 articles
6 project
6 enterprise
6 edition
6 developers
6 comprehensive
6 books
5 virtual
5 training
high.)
After filtering out stop-words, the average number
of distinct symbols in the snippet-based representa-
tion of a keyword for 100 snippets is, in a sample of
ten thousand representations, 710. Table 1 has the top
fifteen symbols in the representation for “java”, which
has 512 distinct symbols and a total of 811 symbols.
To get the vocabulary vector for a web-page we
start by taking the text in the web-page and break-
ing it up into a bag-of-words. Unfortunately, many
web pages have relatively little text. They might be
succinct, or they might be stubs, or they might be
nexuses linking to content but offering little direct
content themselves. Low vocabulary counts are, with
this classification method, likely to lead to poor accu-
racy.
We solve this problem and expand the vocabulary
associated with a web page by recursively download-
ing the pages to which the base result page links, up to
a given maximum depth (in this case, 3), and provided
that the links are on the same host as the original link.
The vocabulary vector for each page so spidered
is normalized so that its magnitude is constant. Also,
each page is assigned a weight equal to
1
2
n
where n
is its distance in links from the root page. Finally,
since obtaining the html for web pages is relatively
costly (taking up to a few seconds per page) we limit
the number of pages required by setting a maximum
depth and, for web pages having more than ten links,
choosing ten links at random.
In practice, this produces a characteristic vocabu-
lary vector with on the order of four thousand distinct
terms (after stop words and extraneous matter like
java-script code have been discarded), which provides
Table 2: Most significant unigrams for “William Gibson”.
count symbol
56.0 collector
48.7 gibson
8.7 william
8.4 neuromancer
8.2 book
6.2 buy
4.8 novel
4.5 active
4.0 wait
4.0 request
4.0 eve
3.9 science
3.7 fiction
3.7 award
3.6 recognition
3.5 pattern
sufficient contextual discernment for our purposes.
It is easy to imagine this approach to modelling
the semantics of web-pages failing. Web-pages of-
ten link to pages that are only peripherally relevant,
or contain text that is digressive or irrelevant. Nev-
ertheless, empirically (see below) this method works
well.
One of the queries discussed below is
“gisbon context:neuromancer” - one of the
most relevant result pages for this query is
http://www.williamgibsonbooks.com/, a part of
whose characterization is in table 2
We compare semantic models using a Naive
Bayes classifier. We approximated lexical prior prob-
abilities by reference tothe British National Corpus
(Leech et al 2001), which lists every word (and its
frequency) in a large, heterogenous cross section of
English documents, along with its frequency.
The score given in the tables below is the natural
log probability of the normalized vocabulary vector
of the web page being generated by the normalized
vocabulary vector of the contextual query, divided by
the number of symbols in the latter vector.
2 EXPERIMENTS
“Gibson” can refer to many things, including sci-
ence fiction author William Gibson (whose first novel
was “Neuromancer”), the Gibson Guitar Corporation
(who also make basses), and actor Mel Gibson (who
was in the move “Lethal Weapon”.) “Gibson”’s pol-
ysemy means that, for each of the intended interpre-
tations of the term, there will be a large number of
WEBIST 2007 - International Conference on Web Information Systems and Technologies
368
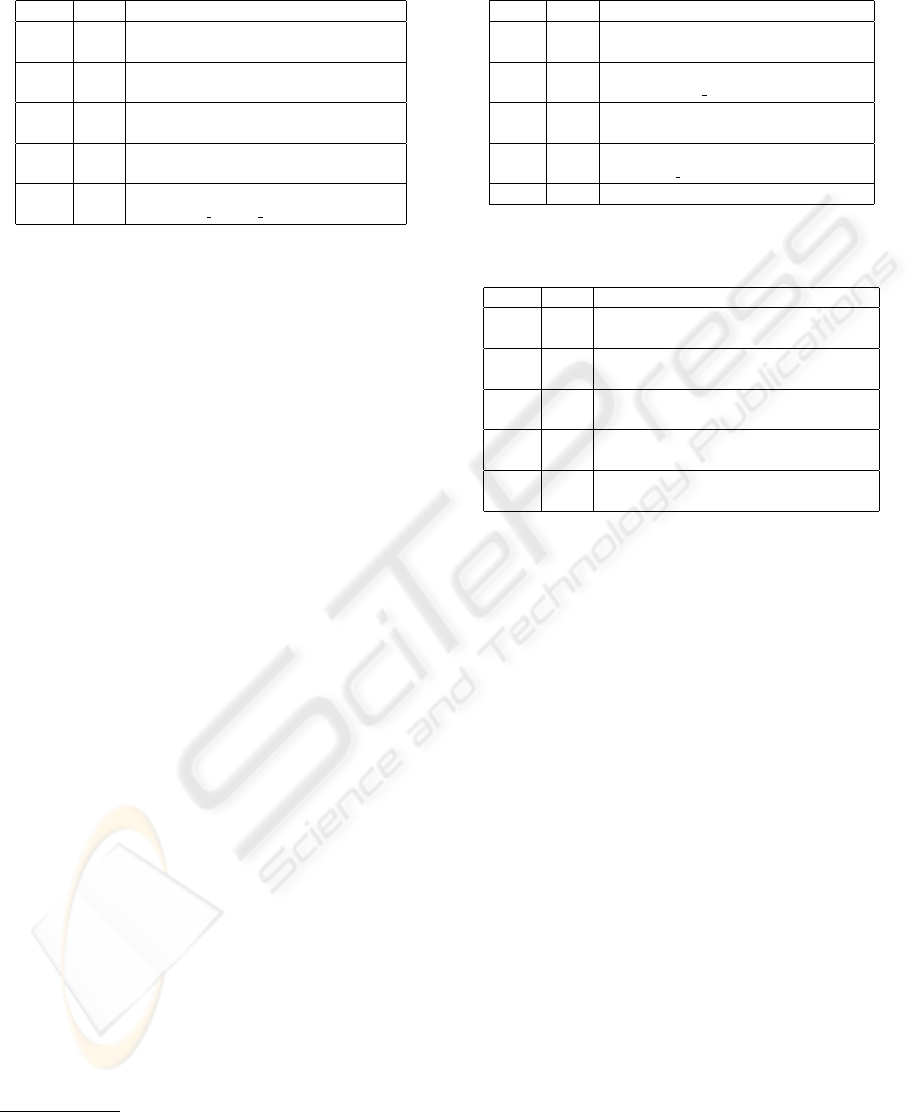
Table 3: Top links for “gibson ctxt(neuromancer)”. Total
good links = 7.
score rank url
0.79 5 X http://www.williamgibsonbooks.c
om/
0.73 31 X http://www.antonraubenweiss.com
/gibson/
0.42 25 X http://www.georgetown.edu/irvin
emj/technoculture/pomosf.ht
0.31 94 X http://www.ibiblio.org/cmc/mag/
1995/sep/doherty.html
0.23 9 X http://en.wikipedia.org/wiki/Wi
lliam Gibson (novelist)
irrelevant search results.
FIX ME
We put the system to the test on set of ambiguous
queries - “gibson”, “fencing” and “web spider”. We
use the contextual queries (“neuromancer”, “lethal
weapon”, “acoustic bass”), (“immigration”
1
, “less
than zero”
2
), and (“jumping spider”, “pageranl”), re-
spectively. We construct a contextual semantic query
for each of these and evaluate the relevance of the re-
sults generated. Recall that one of the essential advan-
tages of this method is that the relevant pages need not
actually contain the contextual query.
Why not discard all the apparatus associated with
the query “gibson ctxt(neuromancer)” and just use the
query “gibson neuromancer”? The answer is that the
latter query will give us pages about the book Neuro-
mancer but not about William Gibson and his work
in general. When one wants contextual but not ex-
tremely narrow focus, the context operator is useful.
Our test queries were as follows:
1. gibson ctxt(neuromancer)
2. gibson ctxt(acoustic bass)
3. gibson ctxt(lethal weapon)
4. fencing ctxt(foil)
5. fencing ctxt(agriculture)
6. web spider ctxt(jumping spider)
7. web spider ctxt(pagerank)
We evaluate the system’s precision and accuracy
(in the top 10 slots in the filtered search.) Table 10
and table 11 summarize the system’s results. Table 10
shows accuracy and precision over the top five high-
est scoring web-pages of the first hundred served by
google for the root query, and table 11 does the same
for the top 20 pages.
1
In the early twentieth century many immigrants to the
US passed through Ellis Island.
2
Brett Easton Ellis is a well-known author, one of whose
novels is called Less Than Zero.
Table 4: Top links for “gibson ctx(lethal weapon)”. Total
good links = 5.
score rank url
0.48 81 X http://www.the-movie-times.com/
thrsdir/actors/melgibson.ht
0.18 65 X http://www.starpulse.com/Actors
/Gibson, Mel/
0.16 13 X http://www.imdb.com/name/nm
0000154/
0.14 92 X http://www.rottentomatoes.com/p
/mel gibson/
0.12 74 http://deb.org/
Table 5: Top links for “gibson ctx(guiatar)”. Total good
links = 11.
score rank url
0.85 11 X http://www.zzounds.com/cat–Gib
son–3549
0.84 99 X http://www.12fret.com/retail/gg
ibsel.htm
0.78 12 X http://www.zzounds.com/cat–Gib
son-Electric-Guitars–3102
0.69 33 X http://www.samedaymusic.com/bro
wse–Gibson–3549
0.54 34 X http://www.samedaymusic.com/bro
wse–Gibson-Electric-Guitar
As the tables show, the algorithm does well. The
worst performing query is fencing ctxt(agriculture).
In the top 100 Google results for the query fencing,
there are only seven relevant to agricultural fencing.
When sorted by relevance to ctxt(agriculture), the top
three ranked sites are relevant, but after this the results
deteriorate. This is because there is only a weak con-
nection between the notion of agriculture and fencing
as it is used in an agricultural context.
Tables 3, 4, 5, 6 and 8 present the top 20 score-
sorted web-pages, of the top 100 returned by Google,
for their respective queries. A URL has an X to its left
if that URL is relevant to the contextual query. The
correlation between relevance score and actual rele-
vance (as judged by a human, is very high. The top
four results are invariably relevant to the contextual
query. The drop off in quality of result appears to
take place near, if not precisely at, the inflection point
on the sorted relevance scores. The primary apparent
fault is that there are sometimes relevant web-pages
separated from the cluster of relevant pages at the top
of the rankings by a set of irrelevant pages.
AUGMENTING SEARCH WITH CORPUS-DERIVED SEMANTIC RELEVANCE
369

Table 6: Top links for “fencing ctxt(foil)”. Total good links
= 39.
score rank url
0.89 68 X http://www.maryland-fencing.org
/links.htm
0.78 98 X http://en.wikipedia.org/wiki/Gi
orgio Santelli
0.71 53 X http://www.mtsu.edu/ fencing/eq
uipment.html
0.67 41 X http://www.brown.edu/Athletics/
Fencing/links.html
0.66 28 X http://www.va-usfa.org/etc/supp
liers.html
Table 7: Top links for “fencing ctxt(agriculture)”. Total
good links = 7.
score rank url
0.66 89 X http://www.sheepandgoat.com/fen
cing.html
0.14 84 X http://www.agry.purdue.edu/ext/
forages/rotational/fencing/
-0.01 17 X http://www.foothill.net/ ringra
m/fenceopt.htm
-0.10 20 http://www.ahfi.org/
-0.10 38 http://www.latourdulac.com/fenc
ing/
Table 8: Top links for “web spider ctxt(jumping spider)”.
Total good links = 39.
score rank url
1.52 71 X http://www.cirrusimage.com/spid
er.htm
1.06 45 X http://www.uky.edu/Ag/CritterFi
les/casefile/spiders/fishin
0.99 32 X http://www.fi.edu/qa99/spotligh
t5/index.html
0.94 70 X http://www.cirrusimage.com/spid
er nursery web.htm
0.93 7 X http://www.xs4all.nl/ ednieuw/S
piders/Info/Construction of
Table 9: Top links for “web spider ctxt(pagerank)”. Total
good links = 59.
score rank url
0.50 92 X http://www.newfreedownloads.com
/Web-Authoring/Site-Managem
0.43 67 X http://software.ivertech.com/Si
teScan-WebSpiderLinkChecker
0.36 59 X http://www.tomdownload.com/web
authoring/site management/s
0.35 15 X http://www.searchtools.com/tool
s/ows.html
0.28 14 X http://www.searchtools.com/robo
ts/robot-code.html
Table 10: Results summary for contextual search for top 5
most relevant web-pages.
query acc. prec. total
gibson ctxt(lethal weapon) 0.80 0.80 6
gibson ctxt(neuromancer) 1.00 1.00 8
gibson ctxt(acoustic bass) 1.00 1.00 12
fencing ctxt(foil) 1.00 1.00 40
fencing ctxt(agriculture) 0.60 0.60 8
web spider ctxt(pagerank) 0.80 0.80 59
web spider ctxt(jumping spider) 1.00 1.00 40
Table 11: Results summary for contextual search for top 20
most relevant web-pages.
query acc. prec. total
gibson ctxt(lethal weapon) 0.83 0.25 6
gibson ctxt(neuromancer) 0.88 0.35 8
gibson ctxt(acoustic bass) 0.92 0.55 12
fencing ctxt(foil) 1.00 1.00 40
fencing ctxt(agriculture) 0.62 0.25 8
web spider ctxt(jumping spider) 1.00 1.00 40
web spider ctxt(pagerank) 0.85 0.85 59
3 RELATED WORK
The literature has many approaches to search query
disambiguation. (Allan and Raghavan 02) describes
an approach in which search queries are clarified
by means of automatically generated, corpus-derived
questions intended to identify the relevant aspect of
the initial query. (Burton-Jones et al 03) and (Storey
et al 06) describes a system that uses structured se-
mantic information, in the form of WordNet or other
manually constructed ontologies, to automatically re-
fine search queries. (Sanderson and Lawrie 00) de-
scribes a method for disambiguating queries by pro-
viding a topic hierarchy for users to negotiate. The
HiB system (Bruza and Dennis 97) offers query re-
finement by means presenting the user with corpus-
derived suggestions for expansion and contraction of
the scope of the query. (Shen et al) describes an ap-
proach to classifying queries in an ontology. Given
a query, the system passes that query on to various
search engines - its primary source of data are the
ODP
3
classifications of that query, but in the event
that these are unavailable it uses a feature-set derived
from the web-pages returned for that query by the
search engines.
Query disambigutation is a form of sense dis-
ambiguation, the literature of which contains some
corpus-derived techniques. (Niu et al 04) describes
an approach to word sense disambiguation that is
in some respects analogous to the work described
here. Their work uses a similarity metric based on
3
Open Directory Project.
WEBIST 2007 - International Conference on Web Information Systems and Technologies
370

LSA-derived representations of and shared vocabu-
lary from the contexts surrounding the instances of
an ambiguous keyword in a corpus - the senses of the
word in question are then derived using unsupervised
learning techniques. (schutze 98) presents a corpus-
based approach to word-sense disambiguation. It is
based on the idea that two instances of an ambigu-
ous word have the same sense if they have second-
order similarity - that is, if there is substantial overlap
between the words that they co-occur with co-occur
with.
The related work described in this section is
mostly about providing methods guiding the user,
with more or less automation, to the information he
wants. This work is different in that it provides a
powerful but intuitive language for the user to express
what he wants.
4 CONCLUSIONS AND FUTURE
WORK
The method described in this paper is simple but
effective. This technique for non-lexical, semantic
search works because of the existence of a very-large,
multi-topical collection of corpora, in the form of
the Internet, and a fast, efficient method for search-
ing over it lexically (in this case, Google, though any
search engine would do.) The key observation is that
simple characterizations of the search-result pages for
a query provide a reasonable characterization of that
query’s meaning that can be used to compute inter-
document distances.
This paper used supervised learning techniques
over queries and documents but these distance met-
rics could also be used with unsupervised clustering
algorithms. There have been many papers about the
shape of the Internet, with topologies based on con-
nectivity (i.e., (Faloutsos et al 99)) - it would be in-
teresting to use the technique described herein to de-
rive the semantic topology of the Internet, though the
bandwidth and processing power required to do such
a project justice would be vast.
REFERENCES
James Allan and Hema Raghavan (2002). Using Part-of-
Speech Patterns to Reduce Query Ambiguity. SIGIR
’02, Tampere, Finland.
P.D. Bruza and S.Dennis. (1997) Query-reformulation on
the internet: empirical data and the hyperindex search
engine. In Proceedings of the RIAO Conference: Intel-
ligent Text and Image Handling, pages 488-499, Mon-
treal, Canada.
Andrew Burton-Jones, Veda C. Storey, Vijayan Sugu-
maran and Sandeep Purao. (2003) A Heuristic-Based
Methodology for Semantic Augmentation of User
Queries on the Web. International conference on con-
ceptual modeling, ER’03, pp. 476-489,
Michalis Faloutsos, Petros Faloutsos, Christos Faloutsos
(1999) On power-law relationships of the Internet
topology. Proceedings of the conference on Applica-
tions, technologies, architectures, and protocols for
computer communication.
Google, Inc. www.google.com
Cheng Niu, Wei Li, Rohini K. Srihari, Huifeng Li, Lau-
rie Crist. (2004). Context Clustering for Word Sense
Disambiguation Based on Modeling Pairwise Con-
text Similarities. SENSEVAL-3: Third International
Workshop on the Evaluation of Systems for the Se-
mantic Analysis of Text, Barcelona.
Geoffrey Leech, Paul Rayson, Andrew Wilson (2001).
Word Frequencies in Written and Spoken English:
based on the British National Corpus. Longman, Lon-
don.
Overture, Inc. www.overture.com
M. Sanderson and D. Lawrie. (2000) Building, testing, and
applying concept hierarchies. In W. Bruce Croft, ed-
itor, Advances in Information Retrieval: Recent Re-
search from the CIIR, W. Brude Croft, ed., Kluwer
Academic Publishers, chapter 9, pages 235-266.
Kluwer Academic Press, 2000.
Schutze, Hinrich. (1998) Automatic Word Sense Discrimi-
nation. Computational Linguistics. 24:1, 97-123.
Dou Shen, Rong Pan, Jian-Tao Sun, Jeffrey Junfeng
Pan, Kangheng Wu, Jie Yin, Qiang Yang. (To ap-
pear.) Query Enrichment for Web-query Classifica-
tion. ACM Transactions on Information Systems
Veda C. Storey, Andrew Burton-Jones, Vijayan Sugumaran,
Sandeep Purao. (Preprint, submitted to Information
Systems Review.) Making the Web More Semantic: A
Methodology for Context-Aware Query Processing.
Yahoo, Inc. www.yahoo.com
AUGMENTING SEARCH WITH CORPUS-DERIVED SEMANTIC RELEVANCE
371
