
CONTENT-BASED TEXTURE IMAGE RETRIEVAL USING THE
LEMPEL-ZIV-WELCH ALGORITHM
Leonardo Vidal Batista, Moab Mariz Meira
Departamento de Inform
´
atica - DI / UFPB
Cidade Universit
´
aria - 58.051-900
Jo
˜
ao Pessoa - PB - Brasil
Nicomedes L. Cavalcanti J
´
unior
Centro de Inform
´
atica - CIn / UFPE
Av. Prof. Luiz Freire, s/n, Cidade Universit
´
aria - 50.740-540
Recife - PE - Brasil
Keywords:
Content-based Image Retrieval, Texture classification, Lempel-Ziv-Welch.
Abstract:
This paper presents a method for content-based texture image retrieval using the Lempel-Ziv-Welch (LZW)
compression algorithm. Each texture image in the database is processed by a global histogram equalization
filter, and then an LZW dictionary is constructed for the filtered texture and stored in the database. The
LZW dictionaries thus constructed comprise a statistical model to the texture. In the query stage, each texture
sample to be searched is processed by the histogram equalization filter and successively encoded by the LZW
algorithm in static mode, using the stored dictionaries. The system retrieves a ranked list of images, sorted
according to the coding rate achieved with each stored dictionary. Empirical results with textures from the
Brodatz album show that the method achieves retrieval accuracy close to 100%.
1 INTRODUCTION
Keyword annotation is the most traditional image re-
trieval paradigm. In this approach, the images are first
annotated manually by keywords. They can then be
retrieved by their corresponding annotations. How-
ever, there are three main difficulties with this ap-
proach, i.e., the large amount of manual effort re-
quired in developing the annotations, the differences
in interpretation of image contents, and the incon-
sistency of the keyword assignments among differ-
ent indexers (Faloutsos et al., 1993; Flickner et al.,
1995). As the size of image repositories increases,
the keyword annotation approach becomes infeasible.
To overcome the difficulties of the keyword-based ap-
proach, an alternative mechanism, content-based im-
age retrieval (CBIR) was proposed in the early 1990’s.
CBIR consists in using visual features, which are im-
age primitives, such as color, texture, and shape fea-
tures, as the image index. This approach has the ad-
vantage of automatic feature extraction.
The explosive growth of digital image technolo-
gies in the last years brings the necessity to investi-
gate and develop new search tools to efficiently lo-
cate pictorial information. Conventional search tools
generally allow exclusively textual queries. Most In-
ternet search tools specifically designed for images
looks for textual relevant information about image
content by analyzing the filename of the graphic files,
’META’ tags and ALT attributes of the ’IMG’ tags
in the HTML code of the pages, terms near the im-
ages in the pages, nature and orientation of sites and
providers, etc. Conventional image databases gener-
ally stores textual information along with the images,
thus allowing textual queries. However, it is known
that textual queries, notably in the scope of multime-
dia databases, tend to present a great number of irrele-
vant results while failing to present many relevant re-
sults. Many efforts have been made to develop CBIR
tools, by extracting and analyzing pictorial features
such as shapes, colors and textures (Zibreira, 2000).
CBIR has attracted great research attention, rang-
ing from government (Jain, 1993; Jain et al., 1995)
and industry (Bach et al., 1996; Dowe, 1993; Flickner
et al., 1995), to universities (Huang et al., 1996; Ma
and Manjunath, 1999; Mandal et al., 1997; Pentland
et al., 1996; Smith and Chang, 1997). Even ISO/IEC
has defined MPEG-7 (ISO/IEC et al., 1997a; ISO/IEC
et al., 1997b; ISO/IEC et al., 1997c) to encompass
a standard multimedia content description interface.
Many CBIR systems, both commercial (Bach et al.,
1996; Dowe, 1993; Faloutsos et al., 1993; Flickner
et al., 1995) and academic have been developed re-
cently.
62
Vidal Batista L., Mariz Meira M. and L. Cavalcanti Júnior N. (2006).
CONTENT-BASED TEXTURE IMAGE RETRIEVAL USING THE LEMPEL-ZIV-WELCH ALGORITHM.
In Proceedings of the First International Conference on Computer Vision Theory and Applications, pages 62-68
DOI: 10.5220/0001376600620068
Copyright
c
SciTePress

In Flickner’s and Addi’s works (Flickner et al.,
1995; Addis et al., 2002), tools which approach some
of the relevant aspects of CBIR are presented. These
tools were applied to construct a museum and gallery
web applications respectively which allow search for
artworks by selecting predominant colours from a
palette or by sketching shapes on a canvas.
Texture is a fundamental attribute used by the
human visual system and computer vision systems
for segmentation, classification and interpretation of
scenes (Porat and Zeevi, 1989). There has been a
great interest in the development of texture-based pat-
tern recognition methods in different areas, such as
remote sensing (Dell’Acqua and Gamba, 2003; Au-
gusteijn et al., 1995), image-based medical diagnosis
(Southard and Southard, 1996), industrial automation
(Kumar and Pang, 2002) and biometric recognition
(Jain et al., 2004; He et al., 2004).
Although intuitively recognized by the human vi-
sual system, texture is not easy to characterize for-
mally. The problem resides in the intrinsic difficulty
to define what is most relevant to characterize texture,
as the answer depends on subjective perceptual con-
siderations and on particular applications. Therefore,
texture feature extraction and modeling tends to be a
difficult and application-driven task. A popular yet
rather vague definition states that textures are spatial
patterns formed by more or less accurate repetitions
of some basic subpatterns (Baheerathan et al., 1999).
Modern lossless data compression algorithms have
been applied to pattern recognition problems, due
to their ability to construct accurate statistical mod-
els, in some cases with low computational require-
ments (Bell et al., 1990). A solid theoretical foun-
dation for using LZ78 (Ziv and Lempel, 1978) and
other dictionary-based compression algorithms (Bell
et al., 1990) for pattern classification is well estab-
lished (Ziv, 1988; Ziv and Merhav, 1993).
A potential problem associated with lossless
dictionary-based compression algorithms for image
retrieval is the fact that these methods search exact
matches in the dictionary for strings in the message
to be compressed. A precise dictionary constructed
for a given texture class may present a poor per-
formance when compressing a new sample from the
same class, if this new sample presents gray-level de-
viations caused by digitization noise or illumination
changes.
Degraded performance, even when gray-level devi-
ations are subtle, indicates that the constructed model
may not be able to adequately describe the new tex-
ture sample, and consequently classification accuracy
may also degrade.
Two possible solutions to this problem are:
1. Adoption of a lossy dictionary-based compressor
(Finamore and Leister, 1996), less sensitive to
small, spurious gray-level deviations;
2. Reduction of these deviations by means of image
processing techniques, prior to the use of a lossless
dictionary-based compression algorithm.
Histogram equalization is a well-known non-linear
operation that generates an approximately uniform
distribution of gray-levels over the available range
(Bovik, 2000). Histogram equalization tends to map
to the same value multiple gray levels that have sim-
ilar values, thus reducing the small gray level devia-
tions that tends to cause mismatches in the searching
stage of lossless dictionary-based compressors. The
operation also decreases the probability that an im-
age retrieval system discriminates texture classes by
average gray level or variance, instead of by its tex-
tural properties (Randen and Husy, 1999). This al-
lows a more precise evaluation of the capabilities of
the method to discriminate texture attributes.
Image retrieval based on universal data compres-
sion models have several potential advantages over
classical methods: since there is no feature selection,
no information is discarded - the models describe the
classes as a whole (Frank et al., 2000); no assump-
tions about the probability distributions of the classes
are required; the adaptive model construction capabil-
ity of compression algorithms offers a uniform way
to work with different types of sources (Ojala et al.,
2002); the similarity rule is very simple (Teahan and
Harper, 2001).
This paper proposes a new content-based image
retrieval method for texture images using histogram
equalization and the Lempel-Ziv-Welch (LZW) loss-
less compression algorithm (Welch, 1984). The
rest of this paper is organized as follows. Sec-
tion 2 presents some fundamental concepts; section 3
presents the LZW algorithm; section 4 describes the
proposed method; section 5 presents the empirical
evaluation of the proposed search tool; and section 6
presents a discussion of the results and the concluding
remarks.
2 ENTROPY AND MARKOV
MODELS
Let S be a stationary discrete information source
that generates messages over a finite alphabet A =
{a
1
,a
2
,...,a
M
}. The source chooses successive
symbols from A according to some probability dis-
tribution that, in general, depends on preceding sym-
bols. A generic message is modeled as a station-
ary stochastic process x =
...
x
−2
x
−1
x
0
x
1
x
2...
, with
x
i
∈ A. Let x
n
= x
1
x
2
...x
n
represent a mes-
sage of length n. Since |A|= M, the source can gen-
erate M
n
different messages of length n. Let x
n
i
,
i =1, 2,...,M
n
denote the i
th
of these messages,
according to some sorting order, and assume that the
CONTENT-BASED TEXTURE IMAGE RETRIEVAL USING THE LEMPEL-ZIV-WELCH ALGORITHM
63

source follows a probability distribution P , so that
message x
n
i
is produced with probability P (x
n
i
).
Let
G
n
(P )=−
1
n
M
n
i=1
P (x
n
i
) log
2
P (x
n
i
) (1)
G
n
(P ) decreases monotonically with n (Shannon,
1948) and the entropy of the source is:
H(P ) = lim
n→∞
G
n
(P ) bits/symbol. (2)
An alternative formulation for H(P ) uses condi-
tional probabilities. Let P (x
n−1
i
,a
j
) be the prob-
ability of sequence x
n
i
= x
n−1
i
a
j
(x
n−1
i
concate-
nated with x
n
= a
j
) and let P (a
j
|x
n−1
i
)=
P (x
n−1
i
,a
j
)P (x
n−1
i
) be the probability of x
n
= a
j
conditioned on x
n−1
i
. The entropy of the n
th
order
approximation to H(P ) (Shannon, 1948) is:
F
n
(P )=−
M
n
i=1
M
j=1
P (x
n−1
i
,a
j
) log
2
P (a
j
|x
n−1
i
)
bits/symbol.
(3)
F
n
(P ) decreases monotonically with n (Shannon,
1948) and the entropy of the source is:
H(P ) = lim
n→∞
F
n
(P ) bits/symbol. (4)
Eq. 4 involves the estimation of probabilities con-
ditioned on an infinite sequence of previous symbols.
When finite memory is assumed the sources can be
modeled by a Markov process of order n − 1, so that
P (a
j
| ...x
n−2
x
n−1
)=P (a
j
|x
1
...x
n−1
). In this
case, H(P )=F
n
(P ).
Define the coding rate of a coding scheme as the
average number of bits per symbol the scheme uses
to encode the source output. A lossless compressor
is a uniquely decodable coding scheme whose goal
is to achieve a coding rate as small as possible. The
coding rate of any uniquely decodable coding scheme
is always greater than or equal to the source entropy
(Shannon, 1948). Optimum coding schemes have
a coding rate equal to the theoretical lower bound
H(P ), thus achieving maximum compression.
For Markov processes of order n − 1, optimum en-
coding is reached if and only if symbol x
n
= a
j
oc-
curring after x
n−1
i
is coded with − log
2
P (a
j
|x
n−1
i
)
bits (Bell et al., 1990; Shannon, 1948). However, it
may be impossible to accurately estimate the condi-
tional distribution P (.|x
n−1
i
) for large values of n,
due to the exponential growth of the number of dif-
ferent contexts, which brings well-known problems,
such as context dilution (Bell et al., 1990).
3 THE LZW ALGORITHM
Even though the source model P is generally un-
known, it is possible to construct a coding scheme
based upon some (possibly implicit) probabilistic
model Q that approximates P . The better Q approx-
imates P , the smaller the coding rate achieved by the
coding scheme.
In order to achieve low coding rates, modern loss-
less compressors rely on the construction of sophis-
ticated models that closely follows the true source
model. Statistical compressors encode messages
according to an estimated statistical model for the
source. Dictionary-based compressors replace strings
of symbols from the message to be encoded with in-
dexes into a dictionary of strings, which is generally
adaptively constructed during the encoding process.
When greedy parsing is used, at each step the en-
coder searches the current dictionary for the longest
string that matches the next sequence of symbols in
the message, and replaces this sequence with the in-
dex of the longest matching string in the dictionary.
Dictionary-based compressors with greedy parsing,
such as LZW, are highly popular because they com-
bine computational efficiency with low coding rates.
It has been proved that each dictionary-based com-
pressor with greedy parsing has an equivalent statisti-
cal coder that achieves the same compression (Bell
et al., 1990). In dictionary-based coding, the dic-
tionary embeds an implicit statistical model for the
source.
The initial LZW dictionary contains all possible
strings of length one. The LZW algorithm finds the
longest string, starting from the first symbol of the
message, which is already present in the dictionary.
This string is coded with the index for the matching
string in the dictionary, and the string is extended with
the next symbol in the message, x
i
. The extended
string is added to the dictionary and the process re-
peats, starting from x
i
(Bell et al., 1990).
LZW achieves optimum asymptotic performance
for Markov sources, in the sense that its coding rate
tends to the entropy of the source as the length of the
message to be coded tends to infinity (Savari, 1997).
It means that LZW algorithm learns a progressively
better model for the source during encoding, and a
perfect model for the source is learned when an in-
finite message has been coded. In practice, since
the messages to be compressed are finite, LZW only
learns an approximate model for the source.
4 THE PROPOSED METHOD
The accurate models built by modern lossless com-
pressors can be used to characterize texture. Any effi-
VISAPP 2006 - IMAGE UNDERSTANDING
64

cient model-based lossless compressor could be used,
but LZW algorithm was chosen due to its good com-
promise between coding efficiency and computational
requirements (Bell et al., 1990).
4.1 Model Learning and Storage
Consider a database containing N texture samples
t
i
, i =1, 2,...,N. The samples are n x n im-
ages extracted from histogram-equalized images. In
the model learning stage, the LZW algorithm com-
presses sample t
i
following the horizontal scanning
order shown in Figure 1.a, and the resulting dictio-
nary H
i
is stored in the database as a model for the
horizontal structure of t
i
, i =1, 2,...,N. The LZW
algorithm then compresses t
i
following the vertical
scanning order shown in Figure 1.b, and the resulting
dictionary V
i
is stored in the database as a model for
the vertical structure of T
i
, i =1, 2,...,N.
Figure 1: Scanning orders. (a) Horizontal; and (b) Vertical.
4.2 The Retrieval Stage
In the retrieval stage, LZW operates in static mode.
In this mode, one of the dictionaries generated in the
model learning stage is used to encode a query sam-
ple, and no new strings are added to the dictionary
during the encoding process.
A n x n query sample x is coded by the LZW algo-
rithm with static dictionary H
i
, following the horizon-
tal scanning order shown in Figure 1.a., and the corre-
sponding coding rate h
i
is registered, i =1, 2,...,N.
Then the LZW algorithm with static dictionary V
i
en-
codes x, following the vertical scanning order shown
in Figure 1.b, and the corresponding coding rate v
i
is
registered, i =1, 2,...,N. As in the previous stage,
all samples are extracted from histogram-equalized
images.
Let
r
i
=
h
i
+ v
i
2
(5)
Query sample x is considered more similar to tex-
ture t
i
than to texture t
j
in the database if r
i
< r
j
,
i, j =1, 2,...,N. The rationale is that if x is more
similar to t
i
than to any other texture in the database
(according to the texture models), the dictionaries H
i
and V
i
embeds the model that best describes its hori-
zontal and vertical structure, thus yielding the small-
est coding rates.
5 EXPERIMENTAL RESULTS
The complete Brodatz album (Brodatz, 1966), ob-
tained from a public archive, was used to evaluate the
performance of the proposed method. All 112 tex-
tures have 640 x 640 pixels, with 8 bits/pixel. In the
experiments, each Brodatz texture is taken as a sin-
gle class. This corpus is the same used by (Xu et al.,
2000), thus allowing direct comparison with another
CBIR system from the literature. Some examples of
the Brodatz textures are shown in Figure 2. Notice
that some of Brodatz images are so irregular that they
cannot be considered as texture images, according to
most accepted definitions for texture. These highly ir-
regular images have a negative effect on recognition
rate (Xu et al., 2000).
In order to assess the effect of histogram equaliza-
tion, tests were made with and without applying this
operation before model learning and retrieval. In this
section and in the next one, the proposed method with
and without histogram equalization will be identi-
fied as CBIR-LZW-HE and CBIR-LZW, respectively.
Each Brodatz texture was partitioned in 128 x 128
non-overlapping subimages, which were taken as tex-
ture samples. Nine of these samples were stored in the
database along with the corresponding LZW dictio-
naries constructed as describe in section 4.1, and the
other ones were used as query samples for testing the
accuracy of the method. Therefore, the database con-
tains 112 texture classes, hereafter identified as C
i
,
i =0, 1,...,111, and each class C
i
has nine samples,
identified as s
ij
, i =0, 1,...,111,j =0, 1,...,8,
for a total of 9 x 112 = 1008 texture samples. Given
a query sample x from class C
i
, retrieval of any one of
the nine samples s
ij
,j =0, 1,...,8, from the same
class is considered successful.
A number of accuracy measures are used in the lit-
erature. In order to directly compare the results of the
proposed method with those of (Xu et al., 2000), the
adopted accuracy measure was the average recogni-
tion rate. Consider that for each query the system re-
turns the c most similar texture samples from the data-
base, according to the LZW models. For a query sam-
ple from class C
i
, let h(c) be the number of samples
from C
i
in the c retrieved samples. Recognition rate,
R(c), is then defined as the ratio between h(c) and the
total number of samples from classes C
i
stored in the
database:
R(c)=
h(c)
9
(6)
The average recognition rate, AR(c), is the average
value of R(c) for all test queries. From the definition,
it follows that AR(c) does not decrease as c increases
and, since there are 1008 texture samples in the test
database, AR(c)=1for c = 1008. More efficient re-
trieval mechanisms tends to achieve AR(c)=1for
CONTENT-BASED TEXTURE IMAGE RETRIEVAL USING THE LEMPEL-ZIV-WELCH ALGORITHM
65
smaller values of c than less efficient mechanisms.
In the ideal case for a database with 9 samples/class,
AR(9) = 1.
Results are shown in Table 1. Figure 2 presents as
an example a query which resulted in a low AR(9),
and Figure 3 presents the whole Brodatz texture from
which this query samples was taken. Figure 4 com-
pares the performance of the proposed method with
M2, which achieved the best performance among the
four variations of the method proposed by (Xu et al.,
2000).
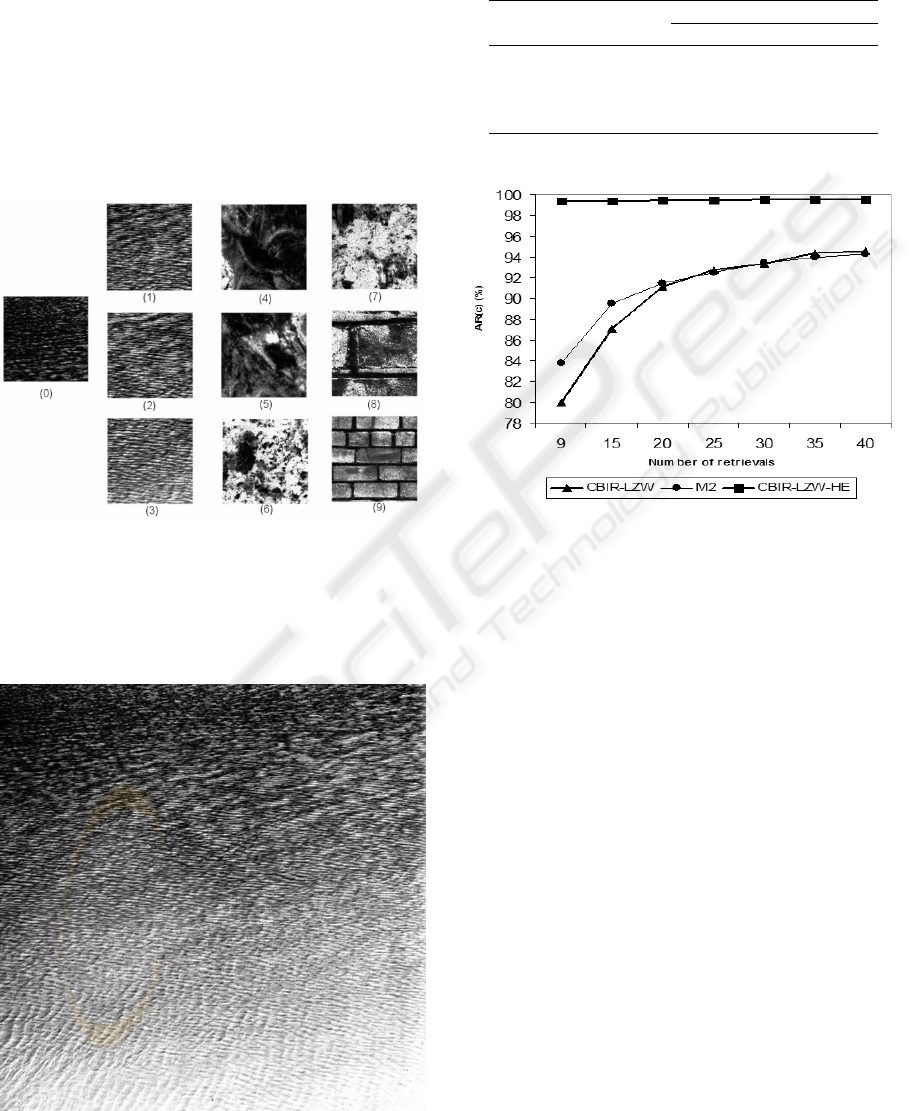
Figure 2: A query resulting in AR(9) = 0.3333 with
CBIR-LZW-HE. Sample 0 is the query sample, sample 1 is
the first retrieved sample, sample 2 is the second retrieved
sample, and so on.
Figure 3: Texture D38, from which the query sample in
Figure 2 was taken.
Table 1: AR(c) achieved by the proposed method, with and
without histogram equalization, for various c (number of
retrievals).
Sample size (n x n) CCR(%)
CLZW CLZW-GHE
4 x 4 80.6 99.9
8 x 8 97.9 100
16 x 16 99.7 100
32 x 32 100.0 100
Figure 4: AR(c) achieved by the proposed method, with
and without histogram equalization, and by the M2 method
reported in literature.
6 DISCUSSION AND
CONCLUSIONS
This paper proposed a new, simple and accurate
content-based image retrieval method for texture im-
ages using histogram equalization and the LZW algo-
rithm.
Table 1 shows that histogram equalization has a
strong positive impact on performance. CBIR-LZW-
HE achieved AR(9) = 0.9939(99.39%), while CBIR-
LZW achieved AR(40) = 0.9459(94.59%).
Figure 4 compares the performance of the proposed
method with M2 (Xu et al., 2000), over the same data-
base. The comparison shows the superiority of CBIR-
LZW-HE over M2. This superiority is still more re-
markable in the most restrictive case (c =9), with
CBIR-LZW-HE achieving AR(9) approximately 15
percent points above the value achieved by M2.
As stated before, many Brodatz images are so irreg-
ular that they cannot be considered as texture images,
according to accepted definitions for texture. Xu’s
work(Xu et al., 2000) assessed the effects of this pe-
culiarity of Brodatz album by dividing the textures in
VISAPP 2006 - IMAGE UNDERSTANDING
66

two separate databases, one containing only visually
homogeneous textures and the other one containing
only visually inhomogeneous textures. By analyzing
recognition rate over these two databases, they con-
cluded that irregular images have a negative effect on
recognition rate. On the other hand, CBIR-LZW-HE
results, with AR(c) near 100%, even for small values
of c, indicate that the method was to some extent ro-
bust to these irregularities.
Figure 2 presents an example query with a particu-
larly low AR(9)(33, 33%). As can be seen in Figure 3,
Brodatz texture D38, from which the query sample
was taken, presents a strong non-uniform illumination
variation, to the point of saturation in the lower right
corner, making recognition a difficult task.
Future directions of research include assessing the
robustness of the method to gray-scale, rotation and
spatial-scale changes and investigating the use of
lossy dictionary-based compressors. In fact, prelim-
inary tests in this direction are already being con-
ducted. First results indicate that histogram equaliza-
tion makes the method robust to uniform gray-scale
variations. Some developments are also being inves-
tigated in order to make the method invariant to ro-
tation and non-uniform illumination variations, with
promising results. It should be noticed that although
invariance is an important feature in CBIR tools, in
many practical applications (e.g. in industrial quality
control by computer vision) images are acquired un-
der strictly controlled conditions, and practically do
not present scale, rotation or illumination changes.
The robustness of CBIR-LZW-HE to irregulari-
ties in the test database suggests that investigating
the applicability of the method to content based non-
textured images is also a very promising direction of
research.
REFERENCES
Addis, M., Lewis, P., and Martinez, K. (2002). Artiste im-
age retrieval system puts european galleries in the pic-
ture. Cultivate Interactive, (7).
Augusteijn, M. F., Clemens, L. E., and Shaw, K. A.
(1995). Performance evaluation of texture measures
for ground cover identification in satellite images by
means of a neural network classifier. IEEE Transac-
tions on Geoscience and Remote Sensing, 33(3):616–
626.
Bach, J. R., Fuller, C., Gupta, A., Hampapur, A.,
B. Horowitz, R. H., Jain, R., and Shu, C. F. (1996).
The virage image search engine: An open framework
for image management. In Proc. SPIE Storage and
Retrieval for Image and Video Databases IV, San Jose,
CA, USA.
Baheerathan, S., Albregtsen, F., and Danielsen, H. E.
(1999). New texture features based on the complexity
curve. Pattern Recognition, 32(4):605–618.
Bell, T. C., Cleary, J. G., and Witten, J. H. (1990). Text
Compression. Englewood Cliffs: Prentice-Hall.
Bovik, A. e. (2000). Handbook of Image and Video Process-
ing. San Diego: Academic Press.
Brodatz, P. (1966). Textures: A Photographic Album for
Artists and Designers. New York: Dover.
Dell’Acqua, F. and Gamba, P. (2003). Texture-based char-
acterization of urban environments on satellite sar im-
ages. IEEE Transactions on Geoscience and Remote
Sensing, 41(1):153–159.
Dowe, J. (1993). Content-based retrieval in multimedia
imaging. In Proc. SPIE Storage and Retrieval for Im-
age and Video Databases.
Faloutsos, C., Flickner, M., Niblack, W., Petkovic, D., Eq-
uitz, W., and Barber, R. (1993). Efficient and effective
querying by image content. Tech. Rep., IBM Res. Rep.
Finamore, W. and Leister, M. A. (1996). Lossy lempel-ziv
algorithm for large alphabet sources and applications
to image compression. volume 1, pages 235–238.
Flickner, M., Sawhney, H., Niblack, W., Ashley, J., Huang,
Q., Dom, B., Gorkani, M., Hafine, J., Lee, D.,
Petkovic, D., Steele, D., and Yanker, P. (1995). Query
by image and video content: The qbic system. IEEE
Computer.
Frank, E., Chui, C., and Witten, I. H. (2000). Text cat-
egorization using compression models. In Storer,
J. A. and Cohn, M., editors, Proceedings of DCC-
00, IEEE Data Compression Conference, pages 200–
209, Snowbird, US. IEEE Computer Society Press,
Los Alamitos, US.
He, X., Hu, Y., Zhang, H., Li, M., Cheng, Q., and Yan, S.
(2004). Bayesian shape localization for face recogni-
tion using global and local textures. IEEE Transac-
tions on Circuits and Systems for Video Technology,
14(1):102–113.
Huang, T., Mehrotra, S., and Ramchandran, K. (1996).
Multimedia analysis and retrieval system (mars)
project. In Proc. 33rd Annu. Clinic Library Appl. of
Data Processing Digital Image Access and Retrieval.
ISO/IEC, JTC1/SC29/WG11, and N1920 (1997a). Mpeg-7:
Context and objectives (v.5).
ISO/IEC, JTC1/SC29/WG11, and N1921 (1997b). Third
draft of mpeg-7 requirements.
ISO/IEC, JTC1/SC29/WG11, and N1922 (1997c). Mpeg-7
applications document.
Jain, A. K., Ross, A., and Prabhakar, S. (2004). An in-
troduction to biometric recognition. IEEE Transac-
tions on Circuits and Systems for Video Technology,
14(1):4–20.
Jain, R. (1993). Nsf workshop on visual information man-
agement systems. SIGMOD Rec., 22(3):57–75.
Jain, R., Pentland, A., and Petkovic, D. (1995). NSF-ARPA
workshop visual inform. management syst.
CONTENT-BASED TEXTURE IMAGE RETRIEVAL USING THE LEMPEL-ZIV-WELCH ALGORITHM
67

Kumar, A. and Pang, G. K. H. (2002). Defect detection
in textured materials using optimized filters systems.
IEEE Transactions on Man and Cybernetics, Part B:
Cybernetics, 32(5):553–570.
Ma, W.-Y. and Manjunath, B. S. (1999). Netra: A tool-
box for navigating large image databases. Multimedia
Systems, 7(3):184–198.
Mandal, M. K., Panchanathan, S., and Aboulnasr, T. (1997).
Image indexing using translation and scale-invariant
moments and wavelets. In Storage and Retrieval for
Image and Video Databases (SPIE), pages 380–389.
Ojala, T., Pietikainen, M., and Maenpaa, T. (2002). Mul-
tiresolution gray-scale and rotation invariant texture
classification with local binary patterns. IEEE Trans-
actions on Pattern Analysis and Machine Intelligence,
24(7):971–987.
Pentland, A., Picard, R. W., and Sclaroff, S. (1996). Pho-
tobook: content-based manipulation of image data-
bases. Int. J. Comput. Vision, 18(3):233–254.
Porat, M. and Zeevi, Y. Y. (1989). Localized texture
processing in vision: Analysis and synthesis in the ga-
borian space. IEEE Transactions on Biomedical En-
gineering, 36(1):115–129.
Randen, T. and Husy, J. H. (1999). Filtering for texture
classification: a comparative study. IEEE Transac-
tions on Pattern Analysis and Machine Intelligence,
21(4):291–310.
Savari, S. A. (1997). Redundancy of the lempel-ziv-welch
code. In Proc. DCC, Salt Lake City, pages 191–200.
Shannon, C. E. (1948). A mathematical theory of commu-
nication. Bell Syst. Tech. J., 27:379–423.
Smith, J. R. and Chang, S.-F. (1997). Visually searching the
web for content. IEEE MultiMedia, 4(3):12–20.
Southard, T. E. and Southard, K. A. (1996). Detection of
simulated osteoporosis in maxillae using radiographic
texture analysis. IEEE Transactions on Biomedical
Engineering, 43(2):123–132.
Teahan, W. J. and Harper, D. J. (2001). Using compression-
based language models for text categorization. In
Workshop on Language Modeling and Information
Retrieval, pages 83–88.
Welch, T. A. (1984). A technique for high performance data
compression. IEEE Computer, 17(6):8–19.
Xu, K., Georgescu, B., Meer, P., and Comaniciu, D. (2000).
Performance analysis in content-based retrieval with
textures. In Proc. Int. Conf. Patt. Recog., volume 4,
pages 275–278.
Zibreira, C. (2000). Descric¸
˜
ao e Procura de V
´
ıdeo
Baseadas na Forma. Master thesis, Instituto Superior
T
´
ecnico de Lisboa, Portugal.
Ziv, J. (1988). On classification with empirically observed
statistics and universal data compression. IEEE Trans-
actions on Information Theory, 34(2):278–286.
Ziv, J. and Lempel, A. (1978). Compression of individ-
ual sequences via variable-rate coding. IEEE Trans-
actions on Information Theory, 24(5):530–536.
Ziv, J. and Merhav, N. (1993). A measure of relative en-
tropy between individual sequences with application
to universal classification. IEEE Transactions on In-
formation Theory, 39(4):1270–1279.
VISAPP 2006 - IMAGE UNDERSTANDING
68
