
A FLEXIBLE REAL-TIME FRAMEWORK FOR PRE-CALCULATED
GLOBAL ILLUMINATION SOLUTIONS
Markus Lipp, Stefan Maierhofer and Robert F. Tobler
VRVis Research Center
Donau-City-Str. 1/3, A-1220 Wien
Keywords:
real-time rendering, shader programming, global illumination.
Abstract:
A framework for real-time application of view-independent pre-calculated global-illumination solutions, re-
taining the ability to adjust the intensity of light-sources after pre-calculation, is described. High dynamic
range scenes are fully supported. The framework is highly flexible both in terms of light-source numbers and
target hardware: both high-end graphics-cards and older models are supported. Furthermore it is orthogonal
to the global-illumination solution method and the chosen tonemapping operator, and therefore easy to im-
plement into existing applications. Implementation details to both minimize memory footprint and maximize
performance and flexibility are given. The performance of this framework has been evaluated in the context
of an existing CAD application.
1 INTRODUCTION
Global Illumination (GI) Solutions for computer
graphics are inherently expensive to calculate, as the
complex interaction of light with the scene has to be
accounted for. Therefore direct application to Real-
time Graphics is only possible if restrictions on the
scene are made. An often used approach is to define
the scene and light sources, as well as the light inten-
sities, as static, and precalculate a global illumination
solution. If the precalculations are view independent,
it is possible to apply the precalculated GI solution in
Realtime to the scene. The obvious drawback of this
approach is the inflexibility: After the precalculations
there is no way to change parameters of the scene
without doing the expensive precalculations again.
A straightforward extension to view independent
GI precalculations that lifts the restriction of static
light intensities is done the following way: The GI
precalculations are not executed for all lights at once,
instead they are done for subsets of all lights, called
light-groups. This creates one solution of the GI prob-
lem for every light-group. Those separated solutions
can then be combined in real-time with scaling factors
applied to each GI solution, enabling flexible light-
intensities adjustments.
The main focus of this paper is to describe a frame-
work to allow this extension to be used in a highly
flexible and efficient fashion: There is no restriction
on the number of light-groups, and there are only
a few restrictions on the target graphics-hardware.
Techniques to reduce the memory footprint are de-
scribed, as well as implementation and optimization
details for various graphics-hardware.
1.1 Previous Work
Three main research-areas act as a base this frame-
work: The first area, view independent GI, describes
how the precalculations are done as input for the
framework. Many methods for view independent GI
preprocessing have been proposed, with Photonmap-
ping (Jensen, 1996) being the method of choice as
base for this work. Every GI method that allows the
output of the precalculated data to textures can be
used as base for this framework. Therefore the choice
of the GI solution orthogonal to the described frame-
work, as long as the mentioned restriction holds.
The second area are methods of real-time render-
ing. To be more specific, high dynamic range (HDR)
texture storage and rendering, as well as program-
mable hardware shading are used in the framework.
HDR texture storage is required to store the results of
the GI pre-process. Only recent graphics-hardware
allow to use the straightforward way: store the re-
sults with floating point precision. Older hardware
335
Lipp M., Maierhofer S. and F. Tobler R. (2006).
A FLEXIBLE REAL-TIME FRAMEWORK FOR PRE-CALCULATED GLOBAL ILLUMINATION SOLUTIONS.
In Proceedings of the First International Conference on Computer Graphics Theory and Applications, pages 335-341
DOI: 10.5220/0001358303350341
Copyright
c
SciTePress

may use other methods: store in rgbe (Ward, 1991),
or store textures with multi-exposure levels (Cohen
et al., 2001). Note that these two methods are not im-
plemented in the framework, only floating point an
byte textures are supported at the moment. Program-
mable shading describes a new paradigm of real-time
computer-graphics: Instead of a configurable fixed
function pipeline, parts of the pipeline are replaced by
programmable shaders (Mark et al., 2003). Shaders
are extensively used in the framework, as the only
way to enable flexible precalculated GI combinations.
The third area is the process of tonemapping: Phys-
ically plausible GI methods produce images with
an high dynamic range of the output luminance.
This high dynamic range has to be compressed to
fit the dynamic range of monitors. This process
is called tonemapping, refer to (Artusi, 2004) for
a good overview. Note that the described frame-
work is orthogonal to the problem of tonemapping,
as this framework creates source images to be used
with tonemapping. Therefore tonemapping is not in
the scope of this paper, however in Section 2.4.2 a
speed-up technique applicable to all luminance-based
tonemapping operators is described.
1.2 Organization of this Paper
This paper is structured in the following way: In Sec-
tion 2 the basics and the parts that make up the frame-
work are described. Section 3 shows performance
evaluations and screenshots obtained using the frame-
work. Section 4 serves as a conclusion.
2 METHODS
In this section we will at first describe the extension
to view independent GI precalculation in more de-
tail. Then an overview of the framework is provided
in Section 2.2, followed by a discussion of hardware
specific issues in Section 2.3. Finally, Section 2.4 will
provide details on implementation of specific parts of
the framework.
2.1 Method Details
The basic idea of the extension is simple: At first, the
GI precalculation are not created for the scene with
all light sources, instead they are calculated for each
light source (or group of light sources). After this step
multiple preprocessed GI data is now present for the
scene, one data set for each light source group. This
data can then be combined in Realtime, with arbitrary
scaling applied to either GI solution set. This way the
intensities of every group of lights can be changed in
real time without expensive precalculations.
There are some points to note. For this method to
be not only perceptually correct but physically plau-
sible, the light source interactions in the scene have
to be linear and thus separable for later combination.
Furthermore the combination of the multiple GI data
has to be performed in a linear space. This implies
following restriction on the format of the GI data: The
data must be stored either directly in a linear space, or
it must be stored in a way that can be decompressed
to a linear space for realtime combination. As actual
scenes may have a dynamic range of up to 1:400000
(Drago et al., 2003), the only way to directly store the
data in a linear space is by using floating point num-
bers.
2.2 Framework Overview
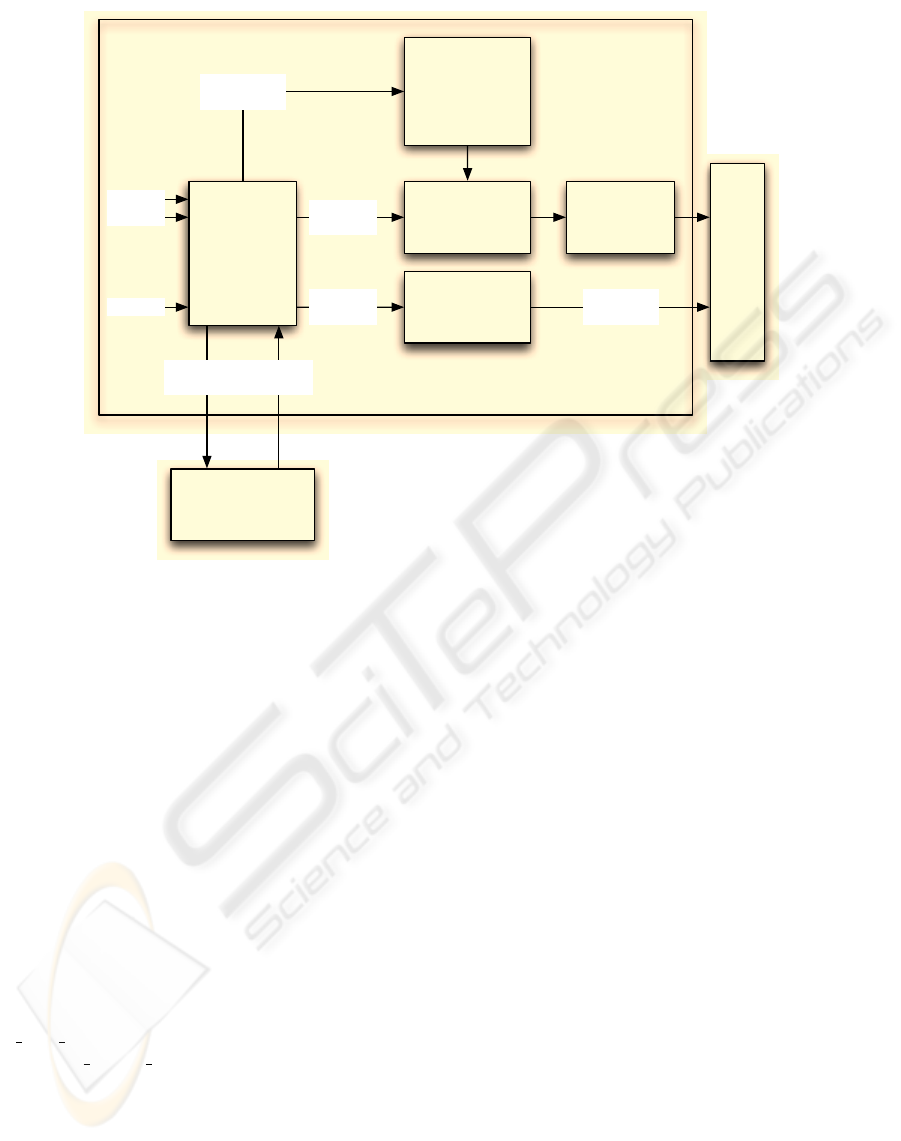
Figure 1 displays the components of the framework.
The framework takes n light-source descriptions as
input, and further splits them up into m ≤ n user
defined light-groups. An external GI solver is now
called for each light-group, this solver then creates
a GI-solution set for each light-group. After all GI-
solutions are calculated, there are two ways to apply
these solutions to the scene in real-time.
The first method is the fully hardware accelerated
path: Here a shader is generated based on parameters
determined during light-source splitup, as described
in Section 2.4.2. This shader is then applied during
scene-rendering and combines all GI-solutions. Af-
terwards tonemapping is performed on the combined
result.
The second method uses a software-fallback to
combine the solutions, the combined solution can
then be used during scene rendering. This approach
is described in Section 2.4.3.
2.3 Hardware Considerations
The linearity requirement described in Section 2.1
combined with the high dynamic range of actual
scenes, is the reason why this approach only works
straightforward on current graphics hardware, and can
not directly implemented into older hardware. To ex-
plain why this requirement poses a problem for older
graphics hardware, let us be more specific on how
view independent GI methods can be implemented
using current graphics hardware.
GI Implementation Let us assume a GI solution
that creates textures containing the lighting informa-
tion for the scene. These textures, called lightmaps,
contain the precalculated GI solution. Following the
previously described approach, multiple textures must
be created, one set for every light group. Those tex-
tures are used as source textures for a realtime frag-
GRAPP 2006 - COMPUTER GRAPHICS THEORY AND APPLICATIONS
336
Light-
group
Splitup
Dynamic
Shader
generation
Combination
Shader
Software
Fallback
Tone-
mapping
Framebuer
Parameters
for Shader
single
Lightmap
Solution
1 ... m
Solution
1 ... m
GI
Solver
Lightgroup
1 ... m
Solution
1 ... m
Light 1
Light 2
Light n
.
.
.
FRAMEWORK
Figure 1: The components of the presented framework.
ment shader. The used fragment shader combines the
textures in realtime and applies tonemapping at the
end.
As textures are used for storage, the textures must
be able to contain the high dynamic range for a correct
linear combination later on. This restrains these tex-
tures to be in floating point format. Therefore limita-
tions of graphics hardware considering floating point
texture formats have to be analyzed. Table 1 shows
the capabilities regarding floating point texturing on
some generations of graphics hardware, and the cor-
responding OpenGL Extensions that are supported.
Floating Point Support As can be seen in this ta-
ble, only NVidia GeforceFX and Ati R300 series and
later series are able to handle floating point textures.
Further it can be seen that GeforceFX series cards
need the floating point textures to be provided via the
NV
float buffer, unlike the other cards that can han-
dle the ATI
texture float extension. This extension
mismatch can only be resolved by providing different
render paths for these cards, as described in section
2.4.2.
Compatibility However, we want most graphics
cards, and not only the latest series to be able to run
the framework. Therefore two mechanisms are inte-
grated into the framework: The first mechanism is a
software fallback for combination of the lightmap tex-
tures, as described in section 2.4.3. This fallback runs
on every hardware capable of texturing. Note that the
software combination has to performed only when the
light intensities are changed, not on every frame.
The second mechanism is to allow the use of 8 Bit
per channel textures for lightmaps. It is not possible
to use these textures in a naive way for most scenes,
as they only offer a dynamic range of 1 : 255. There-
fore values have to be packed into those textures in a
nonlinear manner during lightmap creation, and later
during combination in a fragment shader those values
must be unpacked again into a linear space. Arbitrary
functions are applicable during packing, as long as
they are reversible in an easy way for unpacking in
the fragment shader.
The exponential function
x
1
= f(x)=1− e
−x
with its inverse
x = f
1
(x
1
)=−ln(1 − x
1
),x
1
∈ [0, 1[
is used in this implementation. With this function
a dynamic range of 1 : 1413 is achievable, as is
shown: The highest value x =1representable by
8Bit is x = 254/255 = 0.9961, this results in
f
1
(254/255) = 5.541 after unpacking. Therefore a
dynamic range of max/min =5.541/(1/255) =
1412.955 is achieved.
A FLEXIBLE REAL-TIME FRAMEWORK FOR PRE-CALCULATED GLOBAL ILLUMINATION SOLUTIONS
337
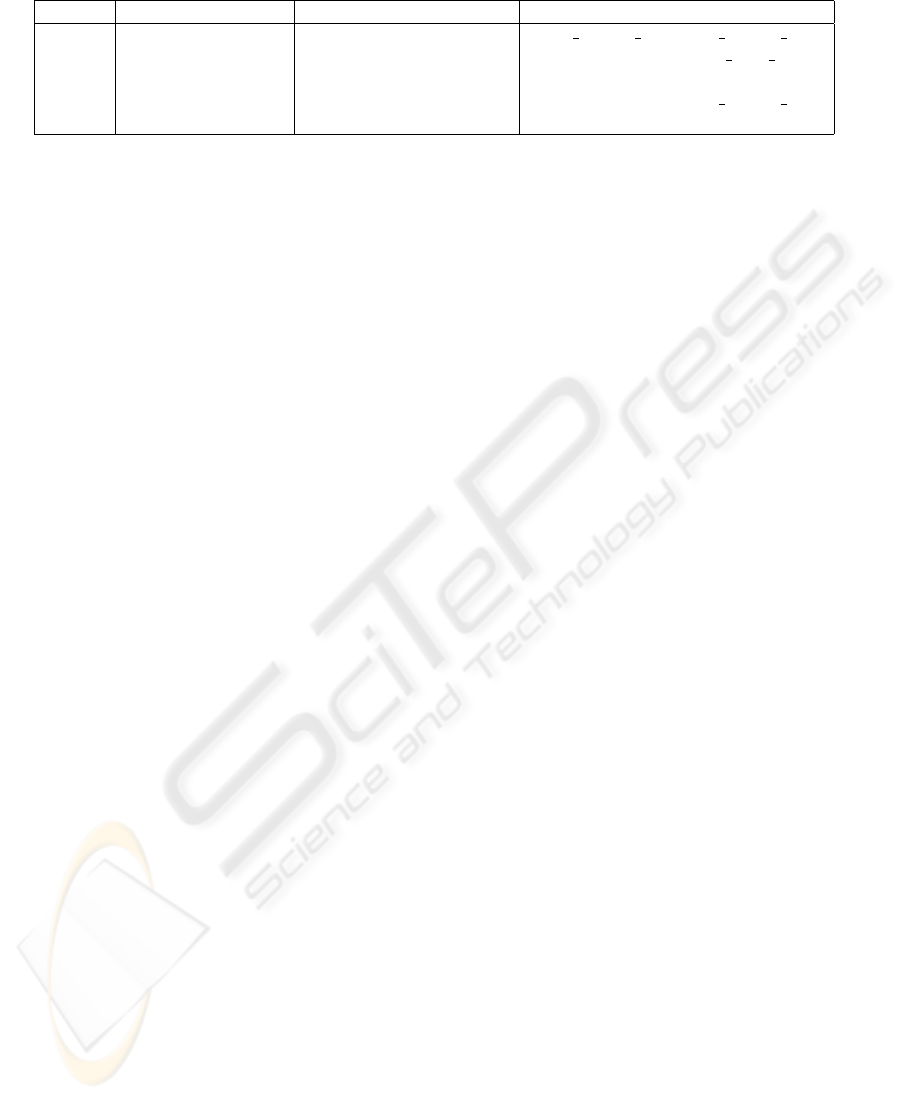
Table 1: Floating point capabilities of graphics-hardware. Sources: (nvi, 2005), (ati, 2005).
Vendor Graphics Processor Floating point capability supported via OpenGL Extension
NVidia Geforce 6 Series Full Support ARB texture float, ATI texture float
NVidia Geforce FX Series No Bilinear Filter NV float buffer
NVidia Earlier Series No floating point support -
ATI R300 Series No Bilinear Filter ATI texture float
ATI Earlier Series No floating point support -
To sum it up, if a scene does not exceed the dy-
namic range of 1 : 1413 a exponentially packed 8Bit
representation is sufficient. Otherwise the software-
fallback must be used for correct results, or floating
point textures have to be used.
Note that other possibilities to get high dynamic
range without floating point textures have been pro-
posed (Ward, 1991) (Cohen et al., 2001). Those meth-
ods could also be integrated into the framework, how-
ever they are no implemented at this moment.
2.4 Implementation Details
To actually create an efficient implementation of the
described framework, three points must be consid-
ered. At first, the memory requirements have to be
optimized, as described in Section 2.4.1. Secondly,
the fragment shader used for recombination has to
be flexible and efficient. This is discussed in Sec-
tion 2.4.2. And lastly, a Software-Fallback must be
provided in order to run this framework on older
graphics-hardware. Section 2.4.3 describes this step.
2.4.1 Memory Footprint
To actually make the described method feasible, con-
siderations to reduce the memory footprint have to be
taken. The memory requirement is a possible prob-
lem, as multiple solutions of the GI have to be stored.
If every light has its own lightmap the memory foot-
print may be too large.
Light-Groups In order to reduce the amount of re-
quired GI solutions, Lights can be sorted into groups,
and every group gets its own lightmap set. Of course,
the ability to adjust light-intensity is thereby reduced
to the whole light-group, the separate lights in this
group can not be controlled anymore. It is up to the
user to decide whether lights should be combined to
group. It may be best practice do combine semanti-
cally equivalent lights (e.g. all ceiling lights) to one
group.
Luminance Packing Another method to reduce
memory footprint is to calculate one channel lumi-
nance maps of three channel RGB-Lightmaps. Four
of those luminance maps can then be packed to a
single RGBA Lightmap. The unpacking is then per-
formed in realtime by a fragment program. There-
fore the fragment program takes each component of
a packed RGBA-Lightmap and multiplies it with the
accumulated light source-colour of the corresponding
light group. The light source-colour is provided to the
fragment program via constant registers. It is impor-
tant to note that effects like colour bleeding can not
be reproduced this way, as colour information is re-
stricted to the light source colours only. Again, it is
up to the user do decide whether colour-bleeding is
important for the specific light group.
Lightmap Precision Reducing the precision of the
lightmap textures from 32 Bit floating point to 16 Bit
floating point (half) is another way to decrease the
memory requirements. The half format is probably
sufficient for most scenes. If the dynamic range does
not exceed 1 : 1413, further reduction to 8Bit preci-
sion is possible, as described in Section 2.3.
2.4.2 Fragment Shader
Multiple steps are performed in the combination frag-
ment shader: At first, the value of each lightmap at
the current texture coordinates is fetched. For packed
lightmaps each component of this value is then multi-
plied with the corresponding light source colour. Byte
textures are unpacked to a linear space. Every value
is then multiplied with a scaling factor provided via
constant registers. All scaled values are then summed
up.
This sum is then used for the tonemapping operator.
At the moment the tonemapping operator is directly
implemented in the fragment shader. We have chosen
Adaptive Logarithmic Mapping (Drago et al., 2003)
as the tonemapping operator. As the tonemapping
problem is orthogonal to the lightmap mixing prob-
lem, any tonemapping operator could be used here.
Optimization Note that the chosen tonemapping
operator is luminance based: Given an input lumi-
nance value l
in
, an output luminance value l
out
is
calculated. Therefore we need to calculate the lu-
minance value l
in
of our RGB colour-values c
rgb
at
first. Using the ITU-R BT.601-4 definition of
GRAPP 2006 - COMPUTER GRAPHICS THEORY AND APPLICATIONS
338

luminance, this is done using a simple dot-product
l
in
= c
rgb
◦ (0.299, 0.587, 0.114). We then calculate
l
out
using the tonemapping operator. There is no need
in colour space conversions to get the tonemapped
color t
rgb
, the scalar product t
rgb
= c
rgb
· l
out
/l
in
is sufficient, as shown below:
We want to show that the luminance of t
rgb
= c
rgb
·
l
out
/l
in
equals the luminance l
out
. The luminance of
t
rgb
is defined as l
t
= t
rgb
◦ (0.299, 0.587, 0.114) =
t
r
· 0.299 + t
g
· 0.587 + t
b
· 0.114. Substituting t
rgb
=
c
rgb
· l
out
/l
in
into this formula results in l
t
= c
r
·
l
out
/l
in
·0.299+c
g
·l
out
/l
in
·0.587+c
b
·l
out
/l
in
·0.114.
This simplifies to l
t
= l
out
/l
in
·(c
r
·0.299+ c
g
·0.587+
c
b
· 0.114) =
l
out
l
in
· l
in
= l
out
.
Dynamic Shader Generation The source
lightmaps used in the fragment shader are flexi-
ble in two ways: The number of lightmaps, and the
type of each lightmap. Each lightmap may either be
packed or unpacked, and may be in floating point or
8Bit format. Additionally the OpenGL extension to
be used for floating point-support varies depending
on the graphics hardware, as described in section 2.3.
Therefore the fragment shader used to combine the
textures must adapt to these parameters. In our imple-
mentation this is achieved trough a configurable lua
(Ierusalimschy, 2003) script: The script is configured
with the number of lightmaps for each possible type.
The type of OpenGL extension used toggles where
the textures should be fetched from: On the one hand,
NV_float_buffer requires textures to be bound
to NV_texture_rectangle, they must be sam-
pled via texRECT in cg, and additionally the tex-
ture coordinates must be scaled to absolute pixel po-
sitions. On the other hand, ATI_texture_float
textures must be bound to TEXTURE_2D and fetched
via tex2D.
Using this configurations, the script then gener-
ates a fragment shader using appropriate predefined
textblock-connections. This fragment shader is then
bound during runtime.
Note that recent developments allow the generation
of dynamic shaders to be done via interfaces in Cg
(Mark et al., 2003). However, at the moment of im-
plementation the graphics-card driver support for this
feature was still in an early version. Therefore we re-
strained from using these interfaces, however in near
future it may be feasible to use those interfaces used
instead of lua-scripting.
2.4.3 Software fall-back for Combination
To make this framework compatible to older graph-
ics hardware, a fallback method for all hardware ca-
pable of texturing is required. This method takes all
lightmaps of the GI solutions and combines them on
the CPU. All the steps that are done in the shader
(including tonemapping), as described previously, are
now done on the CPU. A new set of lightmap tex-
tures is now created for storage of the combined re-
sult. This set is now used for simple textured render-
ing.
The combination step just has to be performed
every time the intensity values of the light-groups
change, not for every frame. As pointed out in the
results section, an combination step takes less than a
minute, and is thus much faster than a complete recal-
culation of the GI solution, which can require a few
hours.
3 RESULTS
The described framework was implemented for a
commercial CAD package. To conduct performance
tests, a bath-room scene is used. This scene features
4 lights. The test system has the following specifi-
cations: Pentium 4 1.7GHz, 1Gb RAM, GeforceFX
5950 Ultra.
Following test-cases where used:
Test-Case 1 Every light is in the same light-group,
therefore no separate intensity-adjustment is possi-
ble. This effectively bypasses the described frame-
work. Just tonemapping is performed every frame.
Note that the tonemapping-operator is explicitly
specified in a fragment shader, using a lookup-
texture instead would improve performance.
Test-Case 2 Every light has its own light-group.
4 times as much texture memory is therefore
needed compared to test-case 1. Combination and
tonemapping are performed every frame, therefore
separate intensity adjustment is possible in real-
time.
Test-Case 3 Every light has its own light-group,
however these light-groups are now packed into a
single RGBA-Texture using the method described
in 2.4.1. The texture memory requirement is now
the same as for the first test-case. Combination and
tonemapping are performed every frame, therefore
separate intensity adjustment is possible in real-
time. Figure 2 shows a screen-shot for this test-
case. The blocky appearence in this screenshot
is caused by the lack of linear-filter support for
floating-point textures on the GeforceFX.
Test-Case 4 Every light has its own light-group,
however the software-fallback is enabled for com-
bination. One combination step for this scene takes
approximately 30 seconds. This step has to be per-
formed everytime a light-group intensity changes.
Tonemapping is performed during the combination
step, therefore 8Bit textures are sufficient for the
A FLEXIBLE REAL-TIME FRAMEWORK FOR PRE-CALCULATED GLOBAL ILLUMINATION SOLUTIONS
339

resulting combined texture. This reduces the re-
quired texture memory to 0.5. Figure 3 shows a
screen-shot for this test-case.
Table 2 summarizes the performance results for
those test-cases. As can be seen, the performance dif-
ference between un-adjustable lights and adjustable
lights is 6Fps at most. We think this slight drop in
framerate is worth the gained flexibility. Software
fall-back is even faster than un-adjustable lights, as
no tonemapping is performed per frame, and faster
8Bit textures can be used. To sum it up, software
fall-back is a good compromise between performance
and flexibility, while the hardware-accelerated-mode
allows instant adjustment of light-intensities on cur-
rent graphics-hardware without loosing too much per-
formance. Therefore the described framework scales
well on different graphics-hardware, and can thus be
considered usable for actual application on a wide
range of graphics-hardware.
4 CONCLUSION
We have described a framework that allows flexi-
ble adjustment of light-source intensities without ex-
pensive recalculation of the GI solution. Limita-
tions of graphics-cards regarding this framework have
been observed, and implementation details for differ-
ent generations of graphics-hardware were discussed.
The results show that this framework is feasible on a
broad range of graphics-cards, as the increased flexi-
bility only inflicts a small hit in performance.
REFERENCES
(2005). NVIDIA GPU Programming Guide. NVIDIA Cor-
poration.
(2005). Radeon 9500/9600/9700/9800 OpenGL Program-
ming and Optimization Guide. ATI Corporation.
Artusi, A. (2004). Real Time Tone Mapping. PhD thesis,
TU Vienna University of Technology.
Cohen, J., Tchou, C., Hawkins, T., and Debevec, P. E.
(2001). Real-time high dynamic range texture map-
ping. In Proceedings of the 12th Eurographics Work-
shop on Rendering Techniques, pages 313–320, Lon-
don, UK. Springer-Verlag.
Drago, F., Myszkowski, K., Annen, T., and Chiba, N.
(2003). Adaptive logarithmic mapping for display-
ing high contrast scenes. In Brunet, P. and Fellner,
D. W., editors, Proc. of EUROGRAPHICS 2003, vol-
ume 22 of Computer Graphics Forum, pages 419–
426, Granada, Spain. Blackwell.
Ierusalimschy, R. (2003). Programming in Lua. Published
by Lua.org.
Jensen, H. W. (1996). Global illumination using photon
maps. In Proceedings of the eurographics workshop
on Rendering techniques ’96, pages 21–30, London,
UK. Springer-Verlag.
Mark, W. R., Glanville, R. S., Akeley, K., and Kilgard,
M. J. (2003). Cg: a system for programming graphics
hardware in a c-like language. ACM Trans. Graph.,
22(3):896–907.
Ward, G. (1991). Real pixels. In Arvo, J., editor, Graphics
Gems II, pages 80–83. Academic Press.
GRAPP 2006 - COMPUTER GRAPHICS THEORY AND APPLICATIONS
340

Table 2: Performance evaluations.
Number of Lightgroups Type of Lightgroup-Textures rel. Texture Memory usage Fps
1, framework bypassed 1x 16 Bit RGBA Float 1.0 28
4 4x 16 Bit RGBA Float 4.0 25
4 1x Packed 16 Bit RGBA Float 1.0 22
4, software fallback 1x 8 Bit RGBA 0.5 36
Figure 2: Hardware accelerated combination (No bilinear filter as GeforceFX does not support this for float-textures), combi-
nation every frame - 25fps.
Figure 3: Software fallback for combination, one combination at beginning - 36fps.
A FLEXIBLE REAL-TIME FRAMEWORK FOR PRE-CALCULATED GLOBAL ILLUMINATION SOLUTIONS
341
