
IDENTIFICATION AND PREDICTION OF MULTIPLE SHORT
RECORDS BY DYNAMIC BAYESIAN MIXTURES
Pavel Ettler
COMPUREG Plze
ˇ
n, s.r.o.
P.O.Box 334, 306 34 Plze
ˇ
n, Czech Republic
Miroslav K
´
arn
´
y
Institute of Information Theory and Automation
P.O.Box 18, 182 08 Praha 8, Czech Republic
Keywords:
System identification, prediction, probabilistic mixtures, decision support.
Abstract:
A short data record is not suitable for proper identification of system model which is necessary for reliable
data prediction. The idea consists in utilization of multiple similar short data records for identification of a
dynamic Bayesian mixture. The mixture is used for prediction according to one of three methods described.
Simulated and real data examples illustrate the methods.
1 INTRODUCTION
Applicable model-based control or decision sup-
port rely on system model identified from available
data. Problem arises when data records are too short
for standard identification procedure, especially for
higher order models. Examples of such situation can
be met in many areas including such diverse disci-
plines like analyzing treatment data in medicine or
pass scheduling for metal rolling. Typically, there ex-
ists a set of data records each consisting of several
samples mostly for several data channels. Such sim-
ilar multiple records can be grouped according to a
specific rule and processed in a way described in the
following.
Section 2 sketches basics about Bayesian mixtures
used for identification and prediction. The idea is
demonstrated on a simple deterministic case in Sec-
tion 3. Examples for noisy and multi-dimensional
data are displayed in Section 4 while Section 5 con-
cerns real data. Conclusions 6 summarize results and
outline the future work.
2 EMPLOYING MIXTURES
External behavior of dynamic stochastic systems is
the most generally described by a probability density
function (pdf, denoted by f ) relating the current sys-
tem output y
t
to the current system input u
t
and past
observed history of data d(t − 1) = (d
1
, . . . , d
t−1
),
d
t
= (y
t
, u
t
). Such a model is rarely available di-
rectly. Instead, its version f (y
t
|u
t
, d(t − 1), Θ) pa-
rameterized by unknown parameter Θ is assumed.
Among various parameterized models, the prominent
role is assigned to finite, normal probabilistic mix-
tures
f(y
t
|u
t
, d(t − 1), Θ) =
n
c
X
c=1
α
c
N
y
t
(θ
c
ψ
c;t
, r
c
), (1)
where N
y
(ˆy, r) is normal pdf given by the mean ˆy and
covariance matrix r; θ
c
are regression coefficients of
c-th normal pdf, called component; ψ
c;t
is regression
vector formed in a known way from u
t
; d(t − 1) and
α
c
≥ 0 is component weight such that
P
n
c
c=1
α
c
=
1. The unknown parameter Θ is represented by the
collection r
c
, θ
c
, α
c
. The prominence of mixtures
comes from their (asymptotic) universal approxima-
tion property: loosely speaking they are able to model
any stochastic dynamic system (Haykin, 1994; K
´
arn
´
y
et al., 2005).
Identification of mixtures is hard but relatively well
elaborated task (Titterington et al., 1985; K
´
arn
´
y et al.,
2005) and for asymptotically valid version with con-
stant component weights can be taken as practically
solved task. For instance, the extensive Matlab tool-
box Mixtools (Nedoma et al., 2002) contains the rele-
vant implementations of such an identification, which
estimates also number of components and structures
of respective regression vectors. The projection-based
methodology, proposed in (Andr
´
ysek, 2004) seems to
be the best procedure available.
66
Ettler P. and Kárný M. (2005).
IDENTIFICATION AND PREDICTION OF MULTIPLE SHORT RECORDS BY DYNAMIC BAYESIAN MIXTURES.
In Proceedings of the Second International Conference on Informatics in Control, Automation and Robotics - Signal Processing, Systems Modeling and
Control, pages 66-70
DOI: 10.5220/0001175400660070
Copyright
c
SciTePress
The system model f(y
t
|u
t
, d(t − 1)) obtained after
“excluding” unknown parameters via identification is
essentially predictor of the output y
t
. Its performance
depends weakly on overestimation of the structure of
respective regressors but it is significantly influenced
by the assumption that the component weights are
time invariant. The assumption allows independent
jumps between active (the best describing) compo-
nents irrespectively of u
t
, d(t − 1). This condition is
met in some applications but in the considered tech-
nical ones is unrealistic: usually, the system is de-
scribed just by a subset (often with a single term) of
components for some period of time. Under this situa-
tion, the output prediction based on the whole mixture
is poor. This problem can be overcome by detecting
and utilizing the active components for time periods
in question.
3 BASIC IDEA
Particular short data record, which is to be processed
contains too few samples for valuable identification.
The basic idea consists in rearrangement of data and
their identification by a dynamic Bayesian mixture.
The mixture or its selected components are then used
for prediction.
3.1 Rearrangement of data
To illustrate the method, let us simulate a simple ex-
ample of n
r
= 10 one-dimensional data records each
consisting of n
d
= 5 samples generated by the model
y
k
= a
1
y
k−1
, (2)
where a
1
= 0.6, y
1
= 75 and k = 2, . . . , 5 is the
discrete time index.
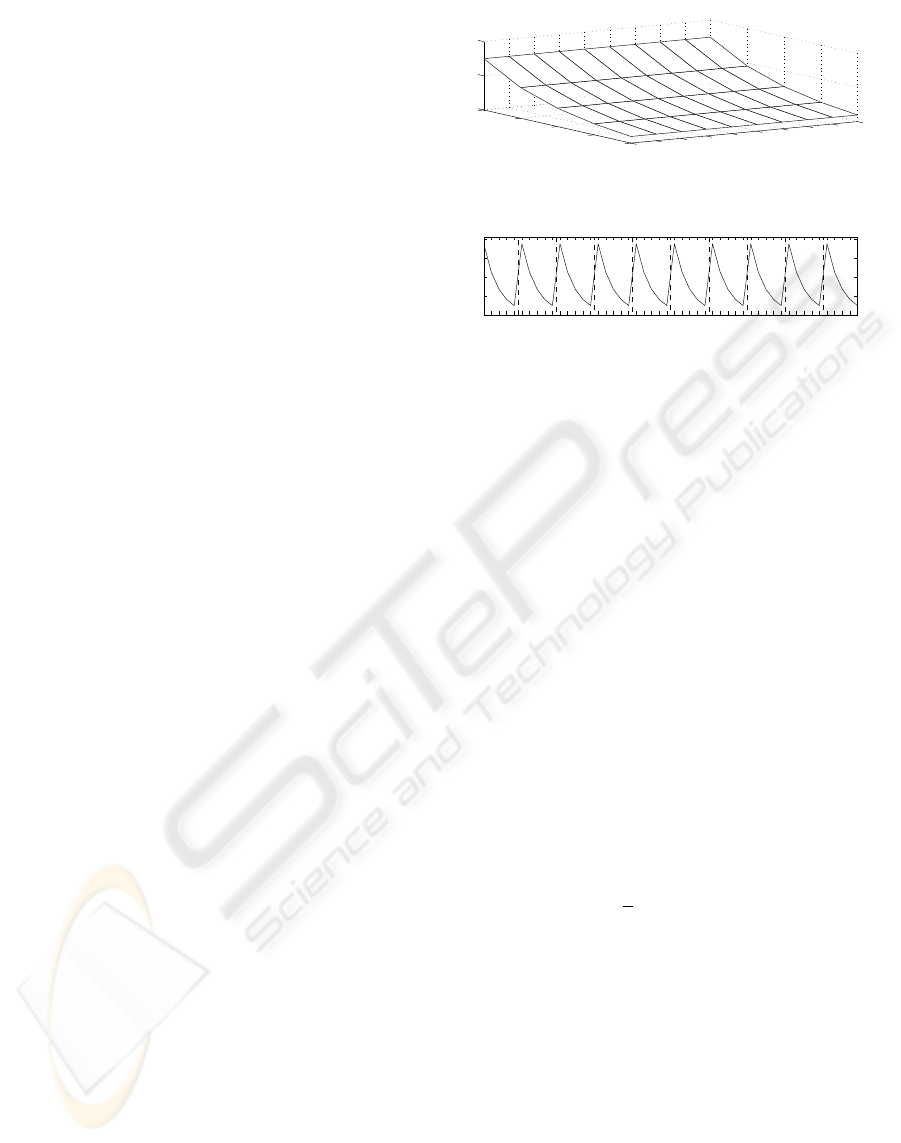
Data can be depicted by a mesh plot shown on the
upper graph of Fig. 1. For the sake of identification
particular records can be merged into a single vector
with l = n
r
· n
d
items as shown on the lower graph
of the same figure. Then, the overall sample index is
t = 1, . . . , l.
3.2 Identification – deterministic
case
Mixtools package (Nedoma et al., 2002) was used for
mixture identification. For the given deterministic ex-
ample, the result came up to expectation exactly. The
mixture is composed of two components, one corre-
sponding to the model dynamics (2) and another mod-
elling transitions among records.
1
2
3
4
5
1
2
3
4
5
6
7
8
9
10
0
50
100
record number
Data transformation
k (sample index)
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
0
20
40
60
80
k (sample index)
5 10 15 20 25 30 35 40 45 50
t (overall samples index)
Figure 1: Data rearrangement. Short data records generated
by a simple model shown on the upper mesh plot are merged
into the single vector shown on the lower graph.
3.3 Prediction and evaluation
criterion
The mixture was identified in order to get valuable
prediction. One-step-ahead prediction is considered
for the sake of simplicity. For an m-order model the
prediction is accomplished for (n
d
− m) time instants
for a single data record ( y
c;k
means prediction by c-th
component):
y
p;k
=
n
c
X
c=1
α
c
y
c;k
, k = m + 1, . . . , n
d
(3)
Predictions are treated as merged original data
forming a vector y
p
(t), t = 1, . . . , l. To evaluate pre-
diction quality the following modified quadratic cri-
terion E
s
is used (subscript s stands for selected in-
stants of t for which predictions are evaluated):
E
s
=
1
l
l
X
t=1
(y
t
− y
p;t
)
2
. (4)
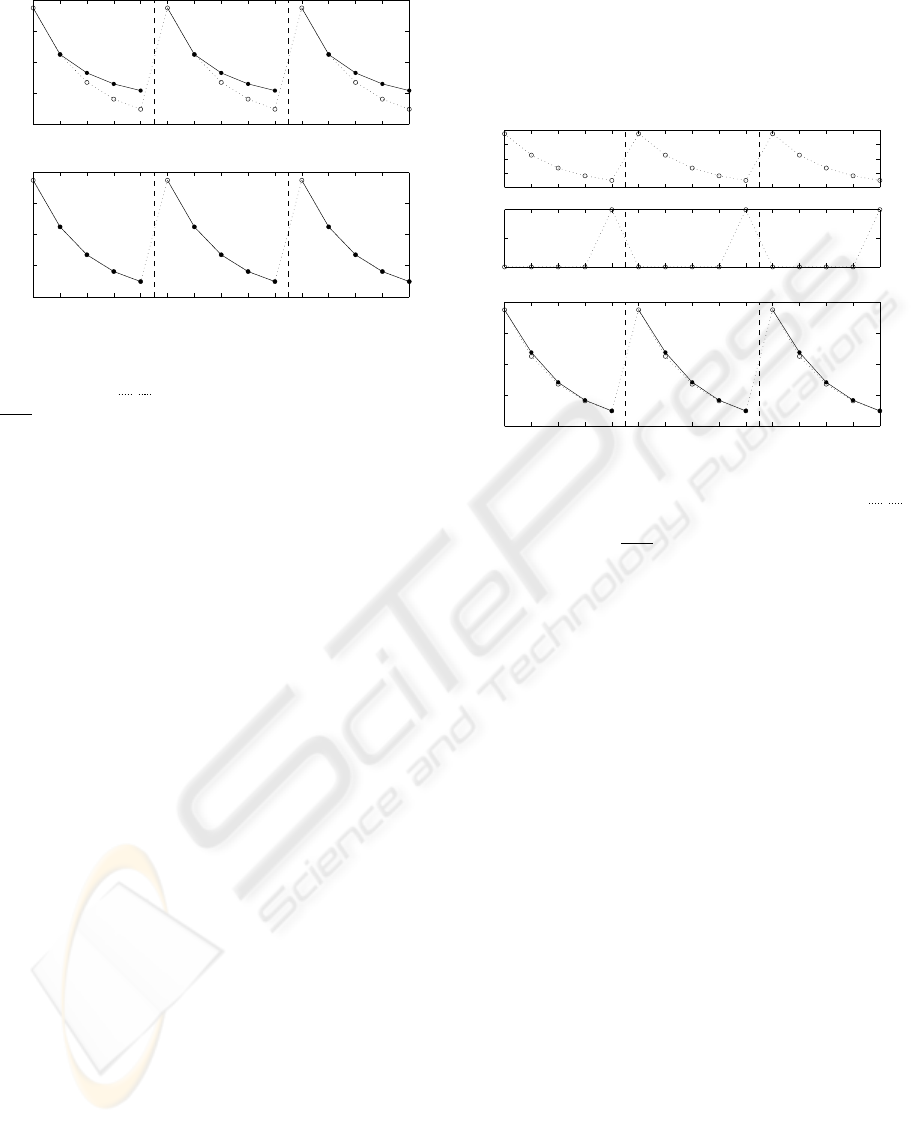
Fig. 2 shows the original data and predictions for
3 randomly chosen succeeding records. The whole
mixture, ie. both components for this case were used
for prediction on the upper graph. It is obvious that
the prediction is poor (E
s
= 52.9). The lower graph
shows predictions calculated from the selected com-
ponent. For this deterministic case the component
matches the model (2) exactly and thus the prediction
is perfect (E
s
= 0).
3.4 Component selection
Criterion for selection of components to be used for
prediction is crucial for the mentioned principle.
IDENTIFICATION AND PREDICTION OF MULTIPLE SHORT RECORDS BY DYNAMIC BAYESIAN MIXTURES
67
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
0
20
40
60
80
y: data °, prediction •
Deterministic case − all mixture components used for prediction
E
s
= 52.90
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
0
20
40
60
80
t
y: data °, prediction •
Deterministic case − selected mixture component used for prediction
E
s
= 0.00
Figure 2: Deterministic case: whole mixture vs. selected
component. Three data records put together and plotted by
the dotted line (
b
). Prediction plotted by the solid line (
r
) was omitted for starting points of records for the 1st
order model. For the upper graph whole mixture was used
for prediction while the selected component was used for
prediction shown on the lower graph.
Method A The simplest possibility is to engage just
the component the weight α
c
of which was identified
as the maximal one. It means practically to set the
weight to one for that component and to zero for the
others and than to use the mixture for prediction.
Method B Another possibility consists in evalua-
tion of prediction error criterion for all possible com-
binations of components to be involved. For most
realistic cases the method results in utilizing sev-
eral components instead of one. This can simply re-
flect uncertainty of measurement or indicate that data
records should be split into two or more groups to al-
low approximation by a simpler mixture.
3.5 Extending data record
Method C A rather different approach consists in
extending the merged data by an additional chan-
nel x
t
, which indicates transitions among particular
records:
x
t
=
1 for the last sample in the record
0 otherwise
The situation is illustrated by two upper plots on
Fig. 3.
In this case components preserve their identified
weights α
c
, ie. the whole mixture is used for predic-
tion. Zero elements of x(t), which is now included in
the regression vectors ψ
c;t
(1) eliminate influence of
“transient” components on computation of y
p
(t). On
the other side, the ones in x(t) enable to predict tran-
sitions accordingly. The lower plot on Fig. 3 shows
the result for the deterministic case. The prediction is
not exact (E
s
= 1.52) but the problem of component
selection was avoided.
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
0
20
40
60
80
t
y: data °, prediction •
Extended deterministic case − all mixture components used for prediction
E
s
= 1.52
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
0
20
40
60
80
y
Extended deterministic case − transition indication added
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
0
0.5
1
x
Figure 3: Extended deterministic case: additional data
channel indicates transition among records. Two data (
b
) channels plotted on upper graphs. Whole mixture was
used for prediction (
r
) shown on the lower graph.
4 SIMULATED EXAMPLES
4.1 Adding noise
Increased model order and introduction of noise make
the simulation more realistic:
y
k
= a
1
y
k−1
+ a
2
y
k−2
+ c
N
e
Nk
, (5)
where a
1
= 0.6, a
2
= 0.1, c
N
= 4 are parameters of
the model,
k = 2, . . . , 5 and e
N
is the output of a random number
generator with normal distribution N (0, 1). Starting
points of records are given by
y
1
= y
0
+ c
U
e
U
, (6)
where y
0
= 50, c
U
= 50 and e
U
is the output of a
random number generator with uniform distribution
in the interval < 0, 1 >.
The identification was accomplished firstly on orig-
inal merged data d(t) where d
t
= y
t
and on the ex-
tended data where d
t
= (y
t
, x
t
) afterwards to allow
comparison of predictions shown on Fig. 4. For the
upper plot, the original data were used for identifi-
cation and the single most important component was
used for prediction (method A). The middle plot uses
the same data and multiple components (2 of 8) se-
lected according to the method B. For the lower plot,
ICINCO 2005 - SIGNAL PROCESSING, SYSTEMS MODELING AND CONTROL
68
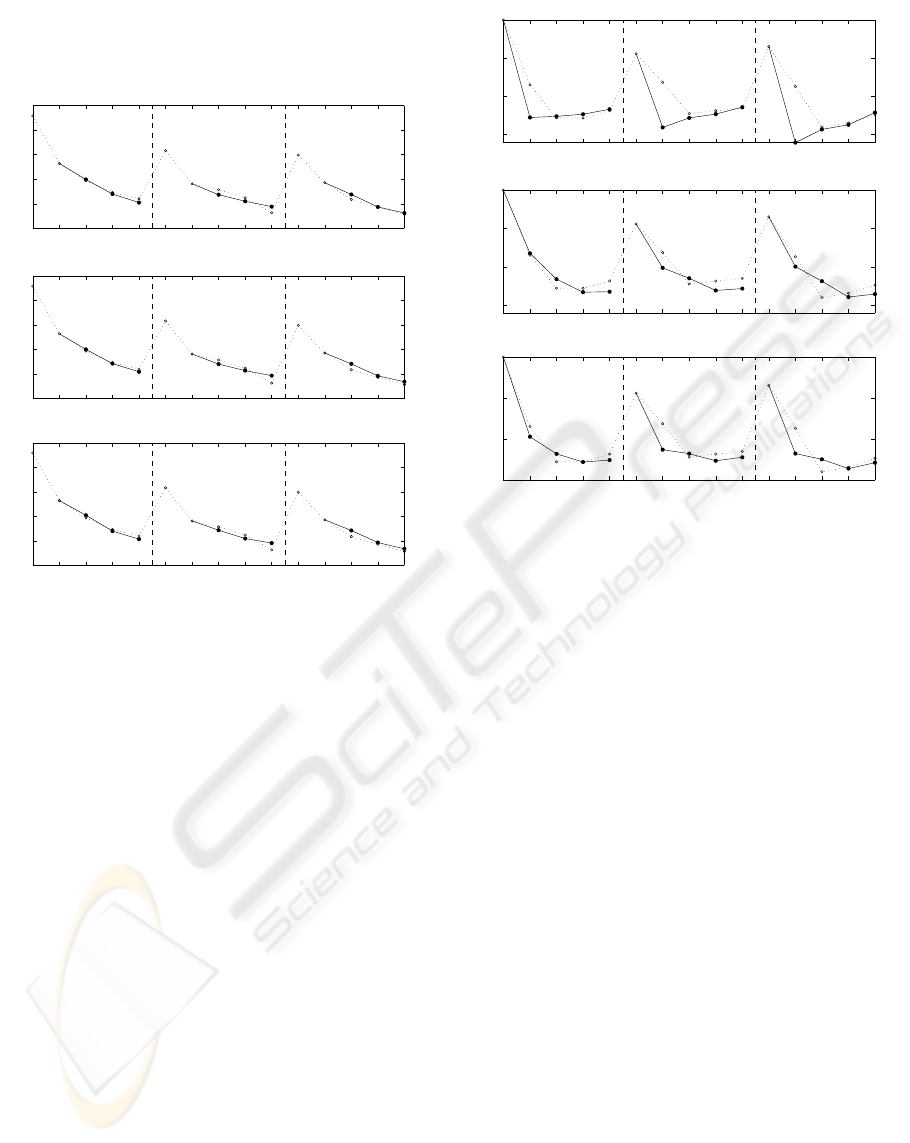
the extended data were utilized and the whole mixture
used for prediction (method C). Values of E
s
are very
similar for all three methods for this case.
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
0
20
40
60
80
100
t
y: data °, prediction •
Method A
E
s
= 7.69
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
0
20
40
60
80
100
t
y: data °, prediction •
Method B
E
s
= 7.38
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
0
20
40
60
80
100
t
y: data °, prediction •
Method C
E
s
= 7.40
Figure 4: Comparison of prediction methods for noisy data.
4.2 Multiple dimensions
Multiple dimensions and increased uncertainty make
the identification more difficult. Let us consider the
model
Y
k
= AY
k−1
+ c
N
e
N;k
, (7)
where
Y
k
=
y
1;k
y
2;k
, A =
0.6 0.1
0.2 −0.8
and c
N
= 4.
Merged data to be identified consist of a 2×l matrix
for methods A and B and 3 × l matrix for method C.
Fig. 5 compares the three methods of prediction. It
can be seen that method B is becoming favourable for
increasing uncertainty being involved.
5 REAL DATA EXAMPLE
A subset of records from a hot reversing rolling
mill was selected for a real data example. The mill
processes metal bars or slabs in several passes to pro-
duce thick strips. Thickness is not measured automat-
ically on the given mill, which makes pass scheduling
a non-trivial task.
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
−50
0
50
100
t
y2: data °, prediction •
Method A
E
s
= 704.06
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
−50
0
50
100
t
y2: data °, prediction •
Method B
E
s
= 135.31
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
−50
0
50
100
t
y2: data °, prediction •
Method C
E
s
= 175.46
Figure 5: Comparison of prediction methods for multidi-
mensional noisy data for channel y
2
.
Three data channels – working roll position, rolling
force and electric current of the roll drive were se-
lected for the example. Characteristic values (means
of selected parts of passes) were evaluated for 5 suc-
ceeding passes to produce 3 × 5 data matrix for a sin-
gle record. Available records for a specific material
were merged (Fig. 6) and used for identification.
Fig. 7 shows predictions for three real data chan-
nels. The mixture was identified for the second-order
model. Method B turned out to be far most success-
ful for this case (3 of 7 components were utilized).
This confirmed the trend indicated by previous exam-
ples. Direct comparison of values of the criterion (4)
would be misleading for this case because of dissimi-
lar ranges and units used for particular data channels.
Therefore Fig. 8 shows histograms of prediction er-
rors recalculated to the percentage of range of the cor-
responding data channel.
6 CONCLUSIONS
Utilization of Bayesian dynamic mixtures for identi-
fication and subsequent prediction of multiple short
data records was described. The principle was shown
on a simple deterministic case. Two methods of pre-
diction differing in number of mixture components to
be utilized and the third method relying on extension
of data were introduced and demonstrated on noisy
IDENTIFICATION AND PREDICTION OF MULTIPLE SHORT RECORDS BY DYNAMIC BAYESIAN MIXTURES
69
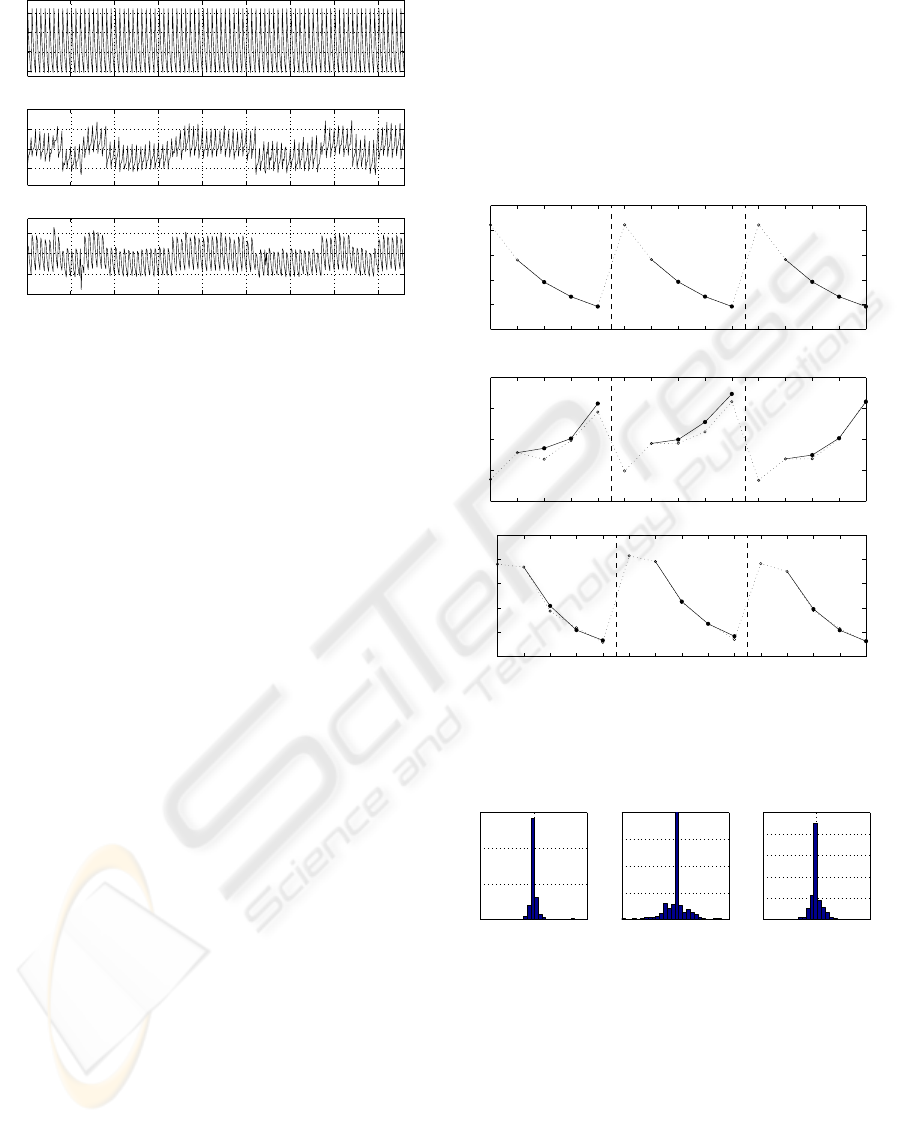
50 100 150 200 250 300 350 400
10
20
30
40
Z [mm]
Real data
t
50 100 150 200 250 300 350 400
3
4
5
F [MN]
t
50 100 150 200 250 300 350 400
500
1000
1500
2000
I [A]
t
Figure 6: Real data from a hot reversing rolling mill.
86 records of characteristic values for final 5 passes were
merged. Three data channels were selected: Z - position of
the working roll, F - rolling force and I - electric current of
the main mill drive.
and multidimensional data respectively. A simplified
set of data records from a hot reversing rolling mill
was used for a real data example.
Experiments showed that the mixture used for pre-
diction should be composed by more than one com-
ponent (method B). The algorithm for components se-
lection will be more elaborated.
Further research will be focussed on utilization of
the idea for real multidimensional short data records.
Results should help to advance applications of the
Bayesian decision support.
ACKNOWLEDGEMENTS
The work was accomplished within the research cen-
tre DAR, supported by the grant 1M6798555601 of
the Czech Ministry of Education.
REFERENCES
Andr
´
ysek, J. (2004). Approximate recursive Bayesian
estimation of dynamic probabilistic mixtures. In
Andr
´
ysek, J., K
´
arn
´
y, M., and Krac
´
ık, J., editors, Mul-
tiple Participant Decision Making, pages 39–54. Ad-
vanced Knowledge International, Magill, Adelaide.
Haykin, S. (1994). Neural networks: A comprehensive
foundation. Macmillan College Publishing Company,
New York.
K
´
arn
´
y, M., B
¨
ohm, J., Guy, T., Jirsa, L., Nagy, I., Nedoma,
P., and Tesa
ˇ
r, L. (2005). Optimized Bayesian Dynamic
Advising: Theory and Algorithms. Springer, London.
to appear.
Nedoma, P., B
¨
ohm, J., Guy, T. V., Jirsa, L., K
´
arn
´
y, M.,
Nagy, I., Tesa
ˇ
r, L., and Andr
´
ysek, J. (2002). Mixtools:
User’s Guide. Technical Report 2060,
´
UTIA AV
ˇ
CR,
Praha.
Titterington, D., Smith, A., and Makov, U. (1985). Statis-
tical Analysis of Finite Mixtures. John Wiley & Sons,
Chichester, New York, Brisbane, Toronto, Singapore.
ISBN 0 471 90763 4.
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
0
10
20
30
40
50
Best prediction • for real data °
t
Z [mm]
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
2.5
3
3.5
4
4.5
t
F [MN]
1 2 3 4 5 1 2 3 4 5 1 2 3 4 5
800
1000
1200
1400
1600
1800
t
I [A]
Figure 7: Prediction of real data made according to the
method B. Data taken from a hot reversing rolling mill.
−0.5 0 0.5
Relative frequency
Z %
−10 0 10
Histograms of prediction error
F %
−10 0 10
I %
Figure 8: Histograms of percentage prediction error for
three real data channels.
ICINCO 2005 - SIGNAL PROCESSING, SYSTEMS MODELING AND CONTROL
70
