
Food Recommendation in a Worksite Canteen
Vincenza Carchiolo
1 a
, Marco Grassia
2 b
, Alessandro Longheu
2 c
,
Michele Malgeri
2 d
and Giuseppe Mangioni
2 e
1
Dip. Matematica e Informatica, Universit
´
a di Catania, Italy
2
Dip. Ingegneria Elettrica Elettronica Informatica, University of Catania, Italy
Keywords:
Data Analysis, Recommendation System, Machine Learning.
Abstract:
Recommendation systems tackle with information overload to assist people in finding their best choice accord-
ing to their preferences and past behaviour. This occurred in many contexts, including the food sector where
culinary inspiration, sales increase or healthy advice motivate the adoption of such a system. In this paper we
propose a canteen food recommendation system for workers operating at an innovation hub including more
than 20 companies. The system leverages a 30 months data set of past choices, and adopts a content based
and a collaborative filtering approach for canteen users, suggesting them with dishes chosen by other similar
users. First results for frequent as well as occasional canteen visitors are encouraging to validate the proposed
approach.
1 INTRODUCTION
Information overload in decision-making processes
exploits recommendation systems (Bobadilla et al.,
2013) (Mohamed et al., 2019) both as a tool to help
users find products based on their preferences and
past choices, and to assist companies in making tar-
geted sales based on customers’ interests; one of the
areas where such systems are widely used is the rec-
ommendation of meals (Min et al., 2019).
The food sector is important for various reasons
(Nations, 2015)(Torreggiani et al., 2018), as improv-
ing culinary inspiration, increasing sales, and promot-
ing health improvement. Food recommendation has
been studied by many researchers (Jiang et al., 2019),
(Merler et al., 2016), (Iwendi et al., 2020); to create an
effective system it is crucial to understand how peo-
ple make food-related choices considering factors as
cultural, social, economic and even organic.
In this article we present an application that assists
a worker in booking his/her meal at a canteen operat-
ing in an innovation hub located in Italy (Carchiolo
et al., 2020), (Carchiolo et al., 2021). The canteen
menu manager is a native Italian speaker that inserts
a
https://orcid.org/0000-0002-1671-840X
b
https://orcid.org/0000-0001-5841-6058
c
https://orcid.org/0000-0002-9898-8808
d
https://orcid.org/0000-0002-9279-3129
e
https://orcid.org/0000-0001-6910-0112
in the menu local names for dishes, which are usually
non self-explanatory; this results in a certain discom-
fort for some workers when they have to choose. For
this reason, a key feature of the app is the engine of a
recommendation system that will suggest each worker
with the pot he/she will most likely to prefer. We col-
lected data concerning dishes consumed at a worksite
during about 2.5 years by more than 200 workers of
22 different companies. Starting from this dataset, we
set up a recommendation system aiming to suggest
users with dishes chosen by other similar users. We
adopted a content based approach and a collaborative
filtering approach to manage both frequent and occa-
sional canteen visitors; first results are encouraging to
validate our proposal.
In section 2 related works on food recommenda-
tion systems are considered, whereas in section 3 the
case study is introduced and results from dataset are
discussed, and finally in section 4 some conclusions
and proposals for future activities are presented.
2 FOOD RECOMMENDATION
Food Recommendation (FR) system are diversified
according to their data model, the number of sources
data extracted from and users interaction support;
they involve disparate factors (e.g. cultural prefer-
ences or medical prescriptions), in predicting what
Carchiolo, V., Grassia, M., Longheu, A., Malgeri, M. and Mangioni, G.
Food Recommendation in a Worksite Canteen.
DOI: 10.5220/0010502401170124
In Proceedings of the 6th International Conference on Complexity, Future Information Systems and Risk (COMPLEXIS 2021), pages 117-124
ISBN: 978-989-758-505-0
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
117

people prefer to eat (Elsweiler et al., 2017).
FR system can be used in several scenarios:
• Seasonality of ingredients, products and recipes
determined by analyzing historical trends, to help
in menu planning or to optimize purchase / inven-
tory decisions for restaurants;
• food Diets, using nutrition data to guide customer
preferences according to levels of (or sensitivity
to) salt, sugar, fat, etc.;
• increase in efficiency and cost savings in product
or recipe formulations by selecting cheaper equiv-
alents of current ingredients;
• customer Trends analysis, gathering which
recipes and products users ultimately act or buy,
and the time/season/event those recipes or prod-
ucts are associated to;
• recipe generator for food waste reduction. Start-
ing from available food in the fridge or pantry at
a given moment and using a recipes dataset, a re-
curring neural network can generate a complete
recipe that includes the instructions, the category
and the title (Zhang et al., 2021);
• meal recommendations based on user preferences
provided in the form of meal ratings, exploiting
the tastes of the individual user or the collabora-
tive approach, which is based on the relationships
between users or elements (meals).
2.1 Classification of FR Systems
Based on the existing literature, we classify FR sys-
tems into three categories, i.e content-based, collabo-
rative filtering and hybrid approaches.
Content-based approaches aim to tailor recom-
mendations to the user’s individual tastes. This is
achieved building a profile for each user starting from
the attributes used to describe the characteristics of
the meals. (Freyne et al., 2011) introduce recommen-
dations by extracting from the recipes of the various
meals the individual ingredients and the positive eval-
uations of the users about those ingredients. This
means that if an ingredient is present in recipes that
a user flagged as liked, other recipes containing the
same ingredient will also be suggested. Subsequent
work has pursued this approach taking into account
both positive and negative ingredient evaluations, rat-
ing recipes ingredients (Harvey and Elsweiler, 2017).
Other content-based approaches are specifically
suitable to FR systems. For example, since food
decisions are often visually guided, images associ-
ated with recipes are exploited (Zhang et al., 2020).
In (Yang et al., 2017) authors show that basic ap-
proaches can be outperformed exploiting (Elsweiler
et al., 2017) also show that low-level image functions
automatically extracted, such as brightness, color, and
sharpness can be useful for predicting a user’s food
preference.
Collaborative, filter-based methods for meal rec-
ommendation systems have been proposed, in partic-
ular in item-based collaborative filtering recommen-
dations are based on how meals resemble each other,
whereas in user-based collaborative filtering recom-
mendations are based on the preferences provided by
the user and their emerging similarity. In (Freyne and
Berkovsky, 2010) authors present an approach using
Pearson’s correlation on the classification matrix, but
with a worse ranking than the content-based approach
described above. Harvey et al. (Harvey and Elsweiler,
2015) demonstrated that Singular Value Decomposi-
tion (SVD) outperformed both the content-based and
collaborative filtering approaches. A Matrix Factor-
ization (MF) approach for food recommendation sys-
tems that merges classification information and user-
supplied labels to achieve significantly better predic-
tion accuracy than baselines based on decomposition
by content and standard matrices is presented (Ge
et al., 2015).
Among Hybrid filtrations (Freyne and
Berkovsky, 2010) combined a collaborative user-
based filtering method with a content-based method.
In their follow-up work involving user groups, the
same authors used an hybrid approach to combine
three different FR strategies into a single model based
on the ratio between the number of rated articles
respect to the total number. In (Harvey and Elsweiler,
2017) significant results combining an SVD approach
with user and meal bias are achieved.
2.2 FR System Applications
Several commercial solutions for food recommenda-
tions are available with different strategies, as (1) sim-
ple user ratings or (2) user preferences extracted from
their past choices, or (3) similarity between meals
based on their ingredients/allergens, (4) similarity be-
tween users calculated by defining a profile for each
user based on past preferences, or finally (5) exploit-
ing nutritional needs in terms of calories. In the fol-
lowing, some applications are briefly discussed.
Yum-me (Yang et al., 2017) is a FR system based
on personalized nutrition; it learns food preferences
without relying on the user’s dietary history. The
recommender learns users’ food preferences through
a simple visual quiz-based interface and then at-
tempts to generate meal recommendations that meet
the user’s health goals, food restrictions, and personal
appetite for food. It can be used by people who have
COMPLEXIS 2021 - 6th International Conference on Complexity, Future Information Systems and Risk
118

food restrictions, such as vegetarian, vegan, etc. and
it is based on two steps:
1. Users answer a simple survey to specify their
dietary restrictions and nutritional expectations.
This is used to filter foods and create an initial set
of candidates for recommendations.
2. Users then use an adaptive visual interface to ex-
press their food preferences through simple food
comparisons. The preferences learned are used to
further refine the proposed recommendations.
Another example of food recommendation system
is Caviar (HBS-Digital-Initiative, 2020), a commer-
cial system that can be customized via an user se-
lected optimization function, for example:
• Recommended for You algorithm uses a hybrid
machine learning algorithm with content-based
filtering and similarity among users to suggest
restaurants
• 30 minute delivery algorithm selects restaurants
that can fulfill the delivery timeline
• Appetizers under e 10 algorithm selects popular
restaurants that have numerous appetizers below
the set price limit.
FooDroid is a recommendation system devel-
oped at University of Zurich (Runo and Wattenhofer,
2011), created to provide a unified platform to man-
age booking of meals by students, having several
canteens with different menus available. Users can
browse the daily menus offered by the various can-
teens, select the meals according to their tastes and
evaluate them on behalf of the colleagues who will
later choose those based on the reviews made. This
recommendation system focuses mainly on:
• Detailed evaluation of the menus offered. In-
deed, since recommendation accuracy is mainly
affected by the (few) users providing the most rat-
ings, some menu choices could not reflect the real
taste of an individual. Therefore, a more personal-
ized recommendation system that operates on the
preferences of individuals (or small groups) is de-
sirable.
• Distance of the canteen from the customer’s loca-
tion, as it is assumed that you can only spend a
limited time for lunch. Thderefore, authors try to
obtain a trade off between the quality of the menus
and the relative proximity to the customer.
FooDroid aims at obtaining a good combination
between the quality of the menu offered by a can-
teen and users preferences, providing students with a
means of evaluating the meals consumed and recom-
mending menus based on these scores in the future.
Snap-n-eat (Zhang et al., 2015) is a mobile food
recognition system based on a deep learning ap-
proach. The system can recognize the food and es-
timate the calories and nutritional content of the food
automatically without any user intervention. To iden-
tify foods, the system allows the user to simply take
a picture of the plate of food. The system detects
the salient region, crops the image and subtracts the
background accordingly. Basically, the app identifies
which segments of the image contain food and then
tries to figure out what type of food is present in each
segment. In addition, the system determines the por-
tion size which is then used to estimate the calories
and nutritional content of the food on the plate. The
system is capable of achieving automatic food detec-
tion and recognition in real life contexts containing
bulky backgrounds. When multiple items of food ap-
pear in an image, the system is able to identify them
and estimate their portions simultaneously.
3 THE CASE STUDY OF
WORKSITE CANTEEN
The FR system we propose here advises employees on
the choice of meal on a daily basis according to the
available menu; a mobile application (not discussed
here) allows to perform these and other actions, as
news management, meeting rooms booking, work-
place lighting control etc.
To set up the FR system, several information from
user’s profile are considered together with those re-
lated to dishes, as its description, the list of ingredi-
ents and/or the contents of the nutritional levels; de-
pending on data available, various machine learning
techniques and models for similarity assessment be-
tween different data can be taken into account.
In particular, for what concern meals, we must
consider that the combinations of dishes on the days
are extremely varied and although the dishes are re-
peated several times during the analysis period, there
is not a high degree of repetition in the menus.
In addition, we classify canteen users into Fre-
quent Visitors (FV) or Occasional visitors (OV),
where a newcomer is first classified as OV and pro-
moted to a FV after a given number of canteen access;
our FR system must address both categories.
3.1 Dataset
The dataset includes data collected during about 2.5
years, from August 2017 to March 2020, concerning
dishes consumed at the worksite, an innovation hub
Food Recommendation in a Worksite Canteen
119

Table 1: Employees distribution over companies.
CompanyID Meals Employees Average
meals
CompanyID Meals Employees Average
meals
0 21030 129 163.0 1 4679 48 97.5
2 7624 29 262.9 3 1593 264 6.0
4 1846 11 167,8 5 76 1 76.0
6 3671 10 367.1 7 6991 85 82.2
8 1206 11 109.6 9 303 3 101.0
10 175 4 43.8 11 2 2 1.0
12 27 1 27.0 13 3 2 1.5
14 72 4 18.0 15 4 1 4.0
16 2 1 2.0 18 2 1 2.0
19 239 33 7.2 20 32 4 8.0
21 13 1 13.0 22 3 1 3.0
Table 2: Dishes distribution.
Dish
category
Description Choices
1 Bread&pizza 8
2 Cold Cuts 17
3 First Course 158
4 Main Course 123
5 Salads 18
where workers of 22 different companies actually op-
erate.
The study of the employees food intake we focus
here is part of a more extensive project for life qual-
ity improvement of the employees at the worksite, in-
creasing their productivity through a better sense of
belonging (Carchiolo et al., 2019).
The number of meals consumed was about 50 000
(49 539), chosen by 264 employees. For a detailed
view on the number of employees of the companies
and the number of meals consumed, we refer the
reader to Table 1. The common canteen is acces-
sible by all the employees through a cross-platform
proprietary App, which provides the canteen manage-
ment with statistical information while retaining the
order and access history of each employee. Employ-
ees are identified with a ”employer code” that permits
us to know the company where they work, their ac-
cess to the canteen and the dishes consumed. Records
with missing values are pruned away from the data
set; this occurred for about 20% of meals. The dishes
proposed are organized in 5 categories that mimic the
italian mean of food. The total number of different
dishes offered by the canteen is 314.
We note that the multiplicity of proposals in the
different categories is not homogeneous and two of
them are way larger than others (see Table 2).
Each dish is described by:
• the ingredients
• the type of cooking
Figure 1: # of ingredient for dishes.
• the features of dietary restrictions
• the heat intake and nutrients present
The ingredients are obtained on the most common
Italian recipes. In the proposed dish 143 ingredients
are used and the number of main ingredients in each
dish ranges from 1 to 11, as depicted in Fig 1. In
fig. 2 the distribution of ingredients in dishes is re-
ported. As shown, some ingredients are very com-
mon while others appear only occasionally in differ-
ent dishes. The most widely used ingredient is extra
virgin olive oil used for the preparation of 83% (in
fig. 2 the red circle on the top) of the dishes; other
4 ingredients are very common in the dishes (they are
highlighted with the second red circle) and are present
in about 30% of the dishes. These ingredients reflect
the tradition of Italian cuisine.
We have also identified 5 different types of cook-
ing: fried, boiled, stew, grilled and baked. Each dish
can have a combination of these types of cooking
(even none of them). In fig. 3 the distribution of types
of cooking in the dish is shown. In particular, the im-
pact of the single cooking method and the multiplicity
of that in a dish are illustrated.
As a restriction to the diet, those belonging to the
”gluten free” and ”vegetarian” categories are identi-
fied as the characterization of the dishes. In fig. 4
it is shown the distribution of veggie and gluten free
dishes.
COMPLEXIS 2021 - 6th International Conference on Complexity, Future Information Systems and Risk
120
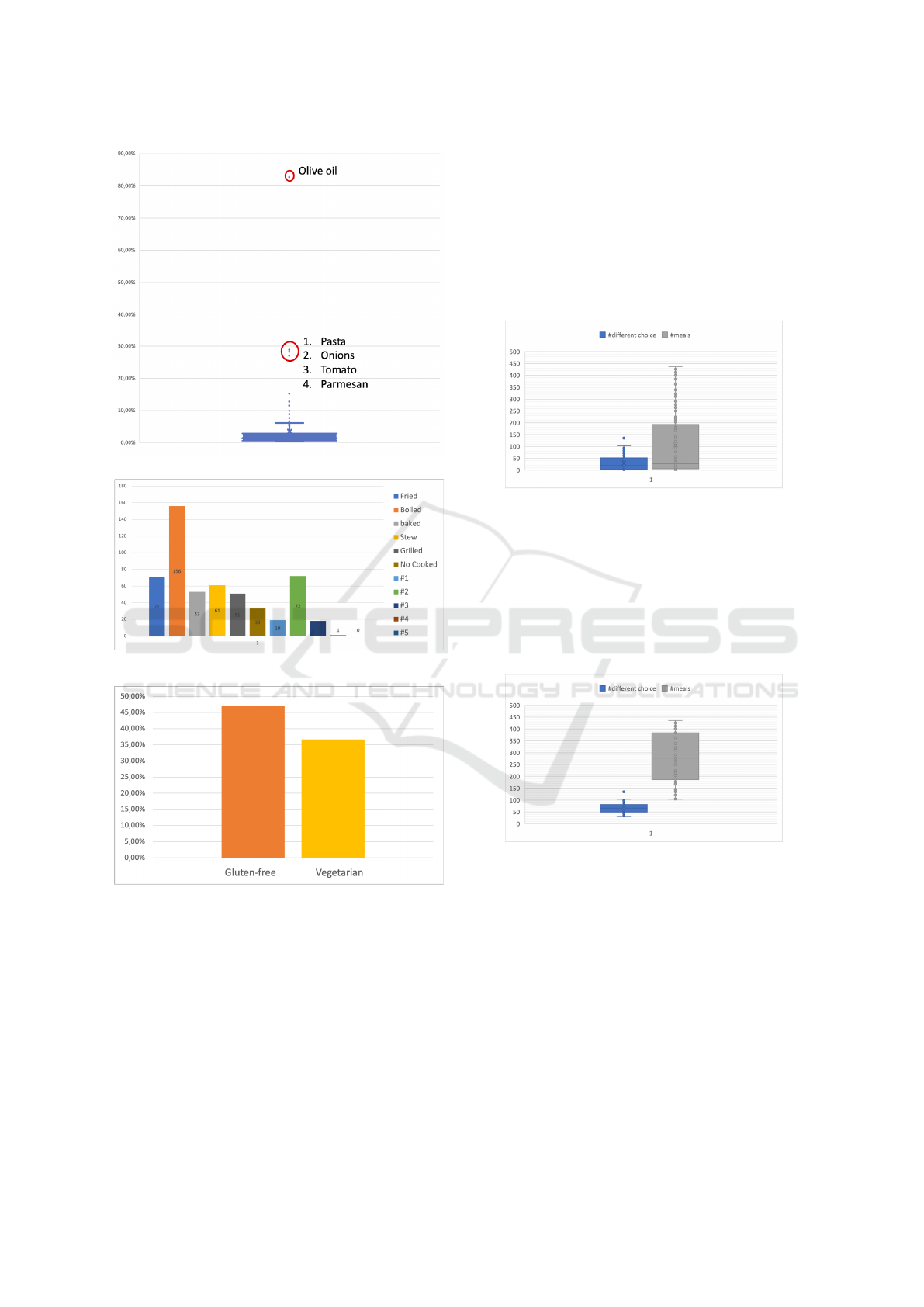
Figure 2: Ingredients for dishes.
Figure 3: Cooking method for dishes.
Figure 4: Diet restriction.
3.2 Food Recommendation System
As already introduced, machine learning algorithms
used in recommendation systems are typically classi-
fied into two main categories: content based and col-
laborative filtering methods, although modern recom-
mendation systems combine both approaches. In our
solution we use a popularity based approach for the
Occasional Visitors, while we use an item–based col-
laborative filter for Frequent Visitors. For this reason
the data will be prepared differently in the two cases.
As previously discussed, the average number of
meals consumed in the canteen is 187, but only for
about 80% of them the dataset contains details of the
choice. An analysis of the dataset shows that the
distribution of accesses is not uniform at all. Fig. 5
shows that many employees access the canteen infre-
quently (gray bar), while others access a much higher
number of times. Fig. 5 shows in blue the variety in
the choice of dishes by each person.
Figure 5: # of meals and # of different choice of Complete
Data Set.
On the base of this analysis, we consider the value
of 100 meals already consumed at the canteen as the
threshold for identifying the FV. In the case of ”Fre-
quent Visitors” (FV), fig. 6 shows the variety in the
choice of dishes by each person (blue bar), while gray
bar shows the number of times each person accesses
the canteen.
Figure 6: # of meals and # of different choice for FV.
In fig 7 the number of times a dish has been chosen
by the FV is reported. As shown, there are dishes that
are much more common than others, meaning that
when using a polarity-based recommendation system
these will be the dishes offered.
3.2.1 Case 1: Frequent Visitors
To solve our problem either user–based or item–based
collaborative filtering can be used. In the latter case,
the selection of the item (namely, the dish) is made
adopting a similarity based filtering among dishes.
The goodness of the results of a recommendation sys-
tem is affected by the model used for coding the de-
Food Recommendation in a Worksite Canteen
121
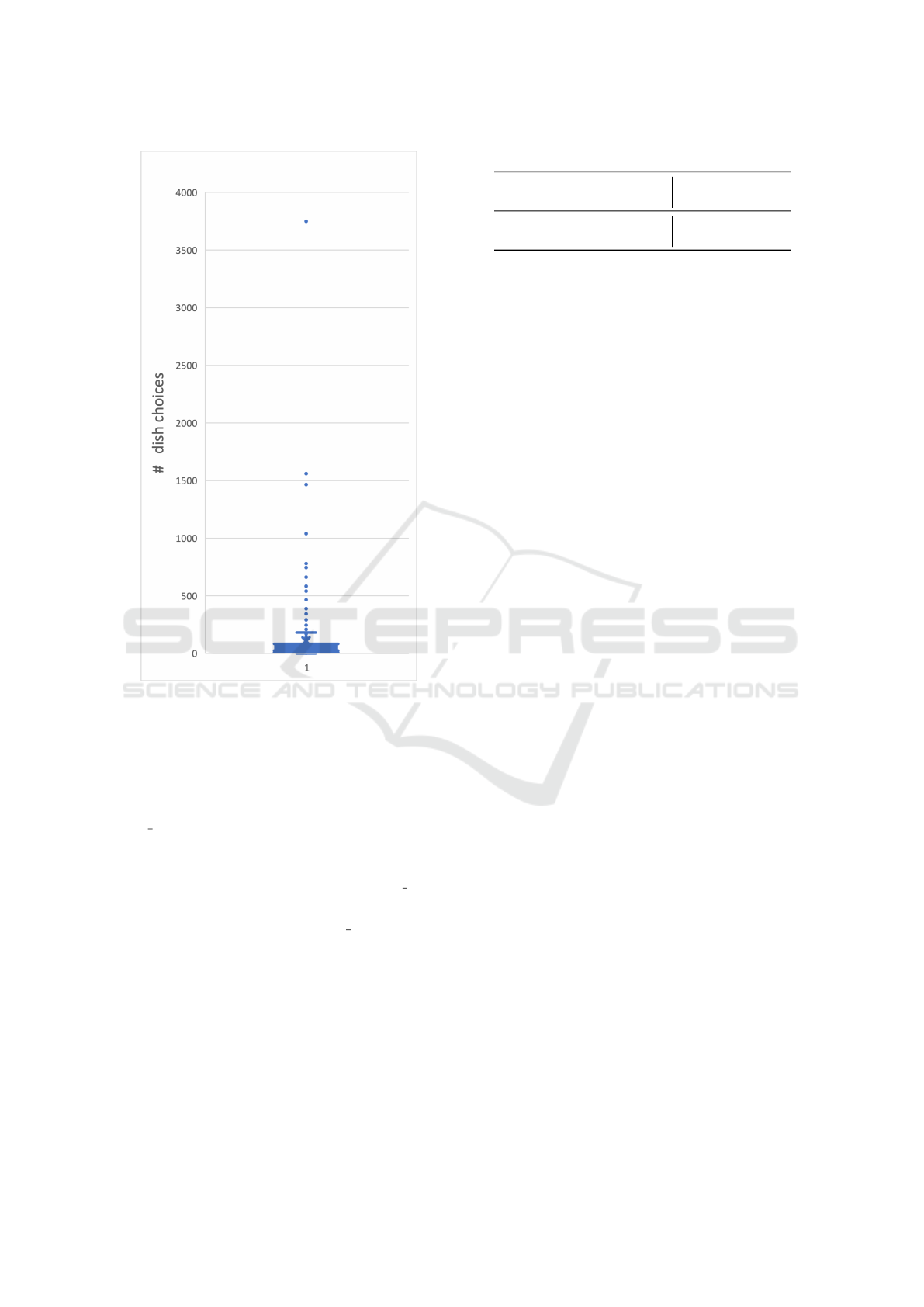
Figure 7: Distribution of meal choice.
scription of the dishes and therefore to the algorithm
used to evaluate the similarity; several approaches can
be used:
• encoding the string of dish description D, by ap-
plying the one-hot encoder, to generate the array
A D describing the plate
• using a string SI obtained by concatenating the list
of ingredients included in the dish and applying
the one-hot encoder to generate the array A SI de-
scribing the plate
• using the product between array A SI with the ma-
trix containing the amount of each ingredient in
the plate
• adding the description of the dish with the amount
of nutrients.
Two dishes will be considered similar according
to the first semantic model, which is the simplest to
implement. The differences arising from the choice
of the model are not analyzed in this paper.
In the case of a user–based collaborative filtering,
a common solution is the use of some ranking. Our
Table 3: Test results.
FV FV + OV
RMSE CV RMSE CV
KNN 0.973 0.955 0.948 0.965
SVD 0.972 0.954 0.949 0.966
dataset does not include a ranking among elements,
but it is built using the history about the past choices
of dishes. In particular, a table is extracted from
the dataset in which each row contains the informa-
tion about the menu offered on a given day, the user
who made the reservation and his choices. To solve
our problem we made a test with both the classical
approaches of collaborative filtering: memory–based
and a model–based. For each model, we perform two
experiments, one on data about FV’s and another on
the complete data set (FV+OV).
In the former case, we used a KNN (K-Nearest
Neighbours) with means model. This algorithm uses
the similarities between users and/or items as weights
to predict a rating for them. This similarity is com-
puted by using the Pearson correlation or cosine sim-
ilarity function.
The second approach used is based on the SVS
Model Based Collaborative Filtering. The Singular-
Value Decomposition, or SVD for short, is a matrix
decomposition method for reducing a matrix to its
constituent parts in order to make certain subsequent
matrix calculations simpler. It provides another way
to factorize a matrix, into singular vectors and singu-
lar values.
To find the rating R that a user U would give to an
item I, the approach includes (1) finding users similar
to U who have rated the item I, and (2) calculating
the rating R based on the ratings of users found in
the previous step; when using KNN with means to
remove the bias we take into account the mean ratings
of each user.
To evaluate the results we calculate the RMSE
(Root Mean Squared Error), the most common met-
rics used to measure accuracy for continuous vari-
ables, and the Cross Validation (CV) of RSME with
KNN and SVD model; for each one we made a test
on the two above mentioned datasets: FV and (FV
+ OV). Table 3 summarizes the RSME and CV ob-
tained.
3.2.2 Case 2: Occasional Visitors
In defining the recommendation systems, one of the
problems described is relating to cold starts, in partic-
ular when a new user is introduced into the data set.
Models defined above do not make a correct predic-
tion on a user whose past choices are unknown, there-
COMPLEXIS 2021 - 6th International Conference on Complexity, Future Information Systems and Risk
122

Figure 8: Ranking for the most frequent visitor.
fore we adopt an alternative solution using a popu-
larity based recommender system that ranks products
based on their popularity (i.e. the rating count) at a
given moment. If a product is highly rated then it is
most likely to be ranked higher and hence will be rec-
ommended. As it is based on the products popularity,
the same set of products will be recommended for all
the users (no personalizing).
Data used to train the model contains User ID and
a Meal ID column. Each row represents an observed
interaction between the user and the element. Pairs
(user, meal) are stored with the model so that they
can later be excluded from recommendations if de-
sired. In addition, a Target column is added which
represents the Ranking of the choice. This ranking
is calculated as a function of the number of times the
person consumed a meal with respect to the total num-
ber of days that the meal was available and therefore
normalized in a range space.
Based on these assumptions, the initial data nec-
essary to create the model are different as the booking
history with the daily menu proposed and the choice
made is no longer required, rather it is only necessary
to obtain the sequence of choices made by each em-
ployee over time.
Results of such a model are at a very early stage
and the further development step envisaged is the re-
placement of the simple model based on popularity
with one that takes into account the group of people
with whom the new employee has already had con-
tacts because these with high probabilities will influ-
ence the choices.
Since this is a popularity based recommender
model, we are getting similar result for all users. i.e.
the model is recommending same products for all the
users. Then we will choose meals recommended by
most popular persons (fig 8 shows the results).
4 CONCLUSIONS AND FUTURE
WORK
In this paper we described a food recommendation
system for users of a workplace canteen. Exploiting a
dataset of past choices and using a content based and
a collaborative filtering approach for canteen users,
the proposed system suggests users dishes chosen by
other similar users. First results for frequent as well
as occasional canteen visitors are encouraging though
further steps are need to validate the proposed ap-
proach, in particular:
• to leverage dishes complete features, as ingredi-
ents and macro nutrients
• to combine time series and machine learning for
prediction purposes, to help both canteen manager
for a better menu planning as well as users for a
better choice
• to test the proposed recommendation system in or-
der to validate it through users feedback
As future extensions, it is planned to use an iot based
approach (Loria et al., 2017) to collect other data,
such as movements and contacts between different
employees, useful for improving user profiling.
Food Recommendation in a Worksite Canteen
123

REFERENCES
Bobadilla, J., Ortega, F., Hernando, A., and Gutierrez, A.
(2013). Recommender systems survey. Knowledge-
Based Systems, 46:109 – 132.
Carchiolo, V., Grassia, M., Longheu, A., Malgeri, M., and
Mangioni, G. (2020). A network-based analysis to un-
derstand food-habits of a canteen clients. In Proceed-
ings of the 22nd International Conference on Informa-
tion Integration and Web-based Applications Services
iiWAS ’20.
Carchiolo, V., Grassia, M., Longheu, A., Malgeri, M., and
Mangioni, G. (2021). A network-based analysis of
a worksite canteen dataset. Big Data and Cognitive
Computing, 5(1).
Carchiolo, V., Longheu, A., Barbera, S., and Tommaso, P.
(2019). Personalized wellness in smart offices. In Pro-
ceedings of IADIS International Conference on Ap-
plied Computing 2019, pages 97–104.
Elsweiler, D., Trattner, C., and Harvey, M. (2017). Ex-
ploiting food choice biases for healthier recipe rec-
ommendation. In Proceedings of the 40th Interna-
tional ACM SIGIR Conference on Research and De-
velopment in Information Retrieval, SIGIR ’17, page
575–584, New York, NY, USA. Association for Com-
puting Machinery.
Freyne, J. and Berkovsky, S. (2010). Intelligent food plan-
ning: Personalized recipe recommendation. In Pro-
ceedings of the 15th International Conference on In-
telligent User Interfaces, IUI ’10, page 321–324, New
York, NY, USA. Association for Computing Machin-
ery.
Freyne, J., Berkovsky, S., and Smith, G. (2011). Recipe
recommendation: Accuracy and reasoning. In Pro-
ceedings of the 19th International Conference on User
Modeling, Adaption, and Personalization, UMAP’11,
page 99–110, Berlin, Heidelberg. Springer-Verlag.
Ge, M., Elahi, M., Ferna
´
andez-Tob
´
ıas, I., Ricci, F., and
Massimo, D. (2015). Using tags and latent factors in a
food recommender system. In Proceedings of the 5th
International Conference on Digital Health 2015, DH
’15, page 105–112, New York, NY, USA. Association
for Computing Machinery.
Harvey, M. and Elsweiler, D. (2015). Automated recom-
mendation of healthy, personalised meal plans. In Pro-
ceedings of the 9th ACM Conference on Recommender
Systems, RecSys ’15, page 327–328, New York, NY,
USA. Association for Computing Machinery.
Harvey, M. and Elsweiler, D. (2017). You are what you eat:
Learning user tastes for rating prediction. In Springer,
C., editor, Kurland O., Lewenstein M., Porat E. (eds)
String Processing and Information Retrieval. SPIRE
2013., Lecture Notes in Computer Science.
HBS-Digital-Initiative (2020). Caviar - premium bites at
your doorstep. last-access: 2020.
Iwendi, C., Khan, S., Anajemba, J. H., Bashir, A. K., and
Noor, F. (2020). Realizing an efficient iomt-assisted
patient diet recommendation system through machine
learning model. IEEE Access, 8:28462–28474.
Jiang, H., Wang, W., Liu, M., Nie, L., Duan, L.-Y., and
Xu, C. (2019). Market2dish: A health-aware food
recommendation system. In Proceedings of the 27th
ACM International Conference on Multimedia, MM
’19, page 2188–2190, New York, NY, USA. Associa-
tion for Computing Machinery.
Loria, M. P., Toja, M., Carchiolo, V., and Malgeri, M.
(2017). An efficient real-time architecture for col-
lecting iot data. In 2017 Federated Conference on
Computer Science and Information Systems (FedC-
SIS), pages 1157–1166.
Merler, M., Wu, H., Uceda-Sosa, R., Nguyen, Q.-B., and
Smith, J. R. (2016). Snap, eat, repeat: A food recog-
nition engine for dietary logging. In Proceedings of
the 2nd International Workshop on Multimedia As-
sisted Dietary Management, MADiMa ’16, page 31–
40, New York, NY, USA. Association for Computing
Machinery.
Min, W., Jiang, S., Liu, L., Rui, Y., and Jain, R. (2019).
A survey on food computing. ACM Comput. Surv.,
52(5).
Mohamed, M., Khafagy, M., and Ibrahim, M. (2019). Rec-
ommender systems challenges and solutions survey.
Nations, U. (2015). Transforming our world: the 2030
agenda for sustainable development. Technical report.
https://sustainabledevelopment.un.org/resourcelibrary.
Runo, M. and Wattenhofer, R. (2011). Foodroid: A food
recommendation app for university canteens. Master’s
thesis, ETH Zurich, Zurich, Switzerland.
Torreggiani, S., Mangioni, G., Puma, M. J., and Fagiolo,
G. (2018). Identifying the community structure of the
food-trade international multi-network. Environmen-
tal Research Letters, 13(5):054026.
Yang, L., Hsieh, C.-K., Yang, H., Pollak, J. P., Dell, N.,
Belongie, S., Cole, C., and Estrin, D. (2017). Yum-
me: A personalized nutrient-based meal recommender
system. ACM Trans. Inf. Syst., 36(1).
Zhang, M., Tian, G., Zhang, Y., and Duan, P. (2021). Rein-
forcement learning for logic recipe generation: Bridg-
ing gaps from images to plans. IEEE Transactions on
Multimedia, pages 1–1.
Zhang, W., Yu, Q., Siddiquie, B., Divakaran, A., and Sawh-
ney, H. (2015). Snap-n-eat: Food recognition and nu-
trition estimation on a smartphone. Journal of dia-
betes science and technology, 9(3).
Zhang, X., Luo, X., and Chen, B. (2020). Multi-view visual
bayesian personalized ranking for restaurant recom-
mendation. Applied Intelligence.
COMPLEXIS 2021 - 6th International Conference on Complexity, Future Information Systems and Risk
124
