
Management Support Systems Model for Incident Resolution in FinTech
based on Business Intelligence
Mar
´
ıa Del Carmen Z
´
u
˜
niga
1 a
, Walter Fuertes
1 b
, Hugo Vera Flores
2 c
and Theofilos Toulkeridis
1,3 d
1
Department of Computer Sciences, Universidad de las Fuerzas Armadas ESPE,
Av. General Rumi
˜
nahui S/N, P.O. Box 171 5 231 - B, Sangolqu
´
ı, Ecuador
2
BI-Solutions, Av. de los Shyris N36-120, Allure Park Building, 170505, Quito, Ecuador
3
Universidad de Especialidades Tur
´
ısticas UDET, Quito, Ecuador
Keywords:
Business Intelligence, Data Mining, Financial Services, Financial Incident Management, FinTech,
Management Support System.
Abstract:
Financial technology corporations (FinTech) specialize in the electronic processing of business transactions
and compensation of charges and payments. Such operations have a technological platform that connects
multiple financial institutions with companies of the public and private sector. In its constant concern for
the provision of efficient services, the company created a unit to guarantee the quality and availability of
24x7x365 of its services by granting their clients confidence regarding online-financial environments through
high-security timely security standards management of incidents. However, poor management of incident
resolution was detected as there are is a lack of tools to monitor transactional behavior or identify anomalies.
Consequently, resolution time has been delayed and, therefore, continuity and regular operation of services. In
this sense, economic losses are frequent, yet the real loss results in its confidence and reputation. In response to
this problematic issue, the current study proposes developing a support model of information management for
the appropriate and timely resolution of incidents by analyzing historical information, which allows to detect
of anomalies in transactional behavior and improve resolution time of events affecting financial services.
The used methodology is ad-hoc and consists of various phases, such as identifying the present situation.
Afterward, it builds the solution based on Ralph Kimball and Scrum methodologies and validates its result.
With the implementation of the work, the business intelligence model improves incident management by
providing indicators for the timely detection of anomalies in financial transactions.
1 INTRODUCTION
With the Internet’s initiation, many traditionally de-
veloped activities have changed and progressed over
time, moving from a manual environment to an elec-
tronic environment. A clear example of this devel-
opment is the financial transactions conducted daily
by millions of persons (Gai et al., 2018). Elec-
tronic transactions realize the extensive use of tech-
nology. However, it requires another element of great
importance for its usability, which is trust, being a
more challenging issue to build in online environ-
ments since transactions are impersonal. The funda-
a
https://orcid.org/0000-0002-2916-2375
b
https://orcid.org/0000-0001-9427-5766
c
https://orcid.org/0000-0002-5701-1013
d
https://orcid.org/0000-0003-1903-7914
mental factor is to promote trust by strengthening the
companies’ computer systems that provide electronic
processing services to feel safe using their digital me-
dia or channels. Financial Technology (FinTech), in
its constant concern for the effective and efficient pro-
vision of its different services, developed a project to
mitigate the business’s operation risks. Whatever the
operational reason, they have a direct effect on the
quality and consistency of financial transactions. In
this type of financial incident, on several occasions,
customers have detected anomalies in the services.
Moreover, since they lack tools to monitor the
quality of transactions, the company’s personnel use
on-demand queries to the database to understand and
resolve incidents. This causes poor handling in the
resolution of incidents due to the low visibility of
indicators that allow monitoring and understanding
transactional behavior on time. Even though FinTech
240
Zúñiga, M., Fuertes, W., Flores, H. and Toulkeridis, T.
Management Support Systems Model for Incident Resolution in FinTech based on Business Intelligence.
DOI: 10.5220/0010456402400247
In Proceedings of the 23rd International Conference on Enterprise Information Systems (ICEIS 2021) - Volume 1, pages 240-247
ISBN: 978-989-758-509-8
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

has qualified personnel for incident management, they
lack the appropriate tools to monitor service quality.
Our research hypothesis establishes that the informa-
tion management model’s implementation will pre-
dominantly optimize the resolution times of financial
incidents registered in the company.
Our primary research question was: Which infor-
mation management models have been used to solve
financial incident deficiencies? In response, a few
proposals are framed in the given research topic. Bed-
ford et al., (Bedford et al., 2005), conceptualize an
incident as: ”the unplanned interruption of an IT ser-
vice and the reduction in its quality. Also, the failure
of a configuration element that has not yet impacted
the service is an incident”. Bobyl et al., (Bobyl et al.,
2018), promotes the continuous development of con-
trols in order to monitor and evaluate the implemented
services. Latrace et al., (Latrache et al., 2015) dis-
cusses several crucial business processes based on in-
formation technology (IT) services because adverse
IT incidents can disrupt the business’s daily activities
and cause adverse effects, such as loss of customer
confidence, productivity, and finances. Serna et al.,
(Serna et al., 2016), argues that information systems
have become a fundamental tool to improve complex
decision-making processes’ efficiency and effective-
ness, particularly those in which quantitative vari-
ables and large volumes of data intervene. Farahmand
(Farahmand et al., 2003), states that an entity needs to
have an effective system capable of identifying, evalu-
ating, and monitoring. These studies demonstrate the
industry’s concern and the scientific community to re-
duce or even avoid entirely financial incidents.
Therefore, this study proposes a tool with the nec-
essary elements to achieve the transactional behav-
ior of financial services, intending to improve inci-
dent management through BI instruments. The de-
velopment of a BI solution was proposed within this
working framework, consisting of analyzing customer
needs, developing and configuring visual reports, cre-
ating data warehouses, information cubes, indicators,
metrics, dimensions, and control boards. These BI
solutions are subject to constant changes which the
company experiences, so it remains below develop-
ment. Agile methodologies offer adequate support for
BI project management. However, they need to be
supported by their BI methodologies for their design
and development.
Furthermore, while a traditional methodology al-
lows modeling the processes that cover BI sys-
tems’ needs, agile methodologies include managing
projects quickly and flexibly. In this way, it is possible
to apply these two methodologies in the same project.
The most popular agile methodology best adapted
to BI project management is Scrum (Schwaber and
Sutherland, 2013). Scrum, in conjunction with Ralph
Kimball’s dimensional modeling method (Kimball
and Ross, 2011), was used for the development of the
solution. Therefore, this research’s main contribution
is to favor the country’s financial sector by develop-
ing a tailored system that allows visualizing the status
of transactions over time. Hereby, the user can iden-
tify variations, which demonstrate the service qual-
ity’s degradation and allows FinTech to act on time to
detect anomalies and resolution of interruptions.
The remainder of the article is organized as fol-
lows: Section 2 describes the theoretical framework
necessary to obtain a suitable foundation for imple-
menting the solution. Section 3 explains the solution
design. Section 4 presents the evaluation of the re-
sults. Finally, section 5 contains the conclusions and
lines of future work.
2 BACKGROUND
2.1 Business Intelligence (BI)
According to (Ayoubi and Aljawarneh, 2018), BI
is an interactive process that explores and analyzes
structured information about an area and discovers
trends or patterns to derive ideas and draw conclu-
sions. M
´
endez del R
´
ıo defines BI as a set of tools and
applications to aid decision-making, enabling interac-
tive access, analysis, and multiplication of mission-
critical corporate information. These applications
provide valuable knowledge about operational infor-
mation by identifying business problems and opportu-
nities. Users can access large amounts of information
in order to establish and analyze relationships and un-
derstand trends that will ultimately support business
decisions (D’Arconte, 2018). Based on the definitions
mentioned earlier, BI is a set of processes that facil-
itate data integration from various systems, whether
internal or external, to facilitate the analysis and inter-
pretation of information through visualization tools to
support decision-making and knowledge generation.
Within this context, information sources are
those where an organization’s operational data are
recorded. Depending on their origin, they can be in-
ternal or external sources, such as Operational or
transactional systems, including custom-developed
applications such as ERP, CRM, and SCM; Depart-
mental information systems, which includes fore-
casts, budgets, spreadsheets, among others; External
information sources, in some cases purchased from
third parties. They are essential to enrich the informa-
tion about customers.
Management Support Systems Model for Incident Resolution in FinTech based on Business Intelligence
241

Additionally, the Extract, Transform and Load
(ETL) process is responsible for the recovery of data
from information sources to strengthen the data ware-
house. The ETL process is divided into five sub-
processes (Hahn, 2019): Extraction, which phys-
ically retrieves the data from different information
sources. The raw data are available at this time.
Cleanup, which recovers the raw data and checks
its quality, removes duplicates, and, where possi-
ble, fixes erroneous values and fills in empty values.
In other words, the data are transformed whenever
possible in order to reduce loading errors. Hereby,
clean and quality data are available. Transformation,
which retrieves clean, high-quality data and struc-
tures, summarizes it in the different analysis mod-
els. The result of this process is obtaining clean,
consistent, summarized, and useful data. Integra-
tion, which validates that the data loaded into the data
warehouse is consistent with the definitions and for-
mats. It also integrates them into the several models of
the different business areas which have been defined
through them—finally, Actualization, which allows
adding the new data to the data warehouse.
2.2 Financial Technology (FinTech)
FinTech has become a common term in the financial
industry that describes novel technologies adopted by
financial service companies (Gai et al., 2018). We se-
lected FinTech as it specializes in the electronic trans-
fer of funds and information through its products and
services for the financial sector. One of its products
is the collection and payment service. Due to the va-
riety and complexity of configurations, it is the ser-
vice that inspired the current study, with the certainty
that it will form the basis for future developments in
other FinTech services. The interbank collection and
payment network allows a financial institution to con-
nect to collection companies through the technolog-
ical platform, supporting its clients to proceed with
their financial contributions. The collection may be
realized online and back office.
We consider that the service indicators allow
knowing the transactionality of financial institutions
and their percentage of participation in the interbank
network. Below are the service indicators for the col-
lection and payment network: a) Status, which al-
lows knowing the status of transactions (i.e., success-
ful or rejected). b) Response, which allows know-
ing the reasons why a transaction presents a specific
status (e.g., successful, invalid password, funds not
available, the client does not exist, destination not
available, external decline, etcetera.); and, c) Chan-
nel, which refers to the client’s channel to conduct
their contribution: virtual channel, window.
2.3 Methodologies for the Design and
Development of the Solution
Companies need to innovate their way of responding
to changes’ demands based on constant technological
developments. Within this context, agile methodolo-
gies appear as a set of working ways oriented towards
a dynamic execution that seeks to promote adaptation
to change and obtain positive results (Schwaber and
Sutherland, 2013). Agile methodologies are based on
people and their interactions. They allow adapting the
way of working to the project’s conditions to manage
them flexibly, safely, and efficiently, reduce costs, and
increase productivity (Alliance, 2016).
Within this working framework, the development
of a BI solution was proposed to analyze the clients’
needs, developing and configuring visual reports by
creating data warehouses, information cubes, screens,
indicators, metrics, and dimensions. Agile method-
ologies offer support for BI project management.
However, they need to be supported by their BI
methodologies for their design and development.
Furthermore, while a traditional methodology al-
lows modeling the processes that cover BI sys-
tems’ needs, agile methodologies encompass meth-
ods for managing projects quickly and flexibly, so
it is possible to apply these two methodologies in
the same draft. The most popular agile methodol-
ogy best adapted to BI project management is Scrum
(Schwaber and Sutherland, 2013). Scrum allows
partial and regular deliveries of the final product,
prioritized by the benefit they bring to the project
client. Scrum is designed for projects in complex
environments, where it is required to obtain results
quickly, while the requirements are changing, innova-
tion, competitiveness, flexibility, and productivity are
fundamental (Malik et al., 2019).
In conjunction with Scrum, Ralph Kimball’s di-
mensional modeling method (Kimball and Ross,
2011)(Macas et al., 2017) was used to develop the
solution. This method, also calls the Dimensional
Life Cycle of the Business, includes the definition of
the technical architecture, the physical design of the
database and ETL, and the definition and develop-
ment of the application. The final phase of deploy-
ment allows the application to be available to users
for evaluation and production. This cycle is based on
four basic principles (Nugra et al., 2016), are focus on
the business, building an adequate information infras-
tructure. At this point, all the necessary elements are
provided in order to deliver value to business users.
Kimball proposes a method that facilitates simplify-
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
242

ing the complexity of the development of Data Ware-
house solutions (Kimball and Ross, 2011).
3 RESEARCH DESIGN
3.1 Definition of Roles, Analysis of Data
Sources and Definition of Indicators
and Metrics
For the development of the solution, three resources
were included: Operations Coordinator, Scrum Spe-
cialist, and BI Developer. The Product Owner col-
lected user stories and acceptance criteria for each one
of them, which became the input to define and write
the Product Backlog elements.
Product Backlog collects the requirements to form
the product. Instead, the Product Owner is responsi-
ble for compiling this list. Based on the business’s
needs, in the Sprint Planning, it was established that
the system is developed in three Sprints, being the
user stories with high priority to those which are con-
templated in the first instance.
In the Sprint Backlog, the requirements to be de-
veloped for the system were specified. In the first
Sprint, the initial information gathering tasks were
planned, considered essential for proper development.
This required the active participation of the Product
Owner and the commitment to manage the access and
delivery of relevant data to develop the UP Collec-
tions and Payments data mart. Table 1 demonstrates
the pending list for each Sprint.
Table 1: List of pending of each Sprint.
Sprint Activities
1 Data source identification and analysis
1 Definition of management indicators
1 Physical design of DSA data model
1 Physical design of DWH data model
1 DSA and DWH database creation
1 Report model generation (prototype)
2 Design and development of ETLs
2 Create attributes, metrics and cubes
2 Dashboards development for monitoring
3 Channel dashboard development
3 Dev. of transaction response dashboards
3 Creation and setup of the autoload job
3 Incremental bucket loads
3 User testing and tuning
3 Go into production
In this phase of development, we identified the data
source analysis, which will constitute the data ware-
house construction input. The Financial Services
Company has a transactional system developed under
Oracle database, Oracle Developer, and Oracle Appli-
cation.
The Key Performance Indicators (KPIs) are met-
rics that help identify a specific action or strategy’s
performance regarding the definition of indicators and
metrics. It is possible to identify performance based
on the objectives set previously (Midor et al., 2020).
For FinTech, the objectives set for monitoring the
quality of services are established by the total num-
ber of transactions and the transaction status. There-
fore, the indicators that they request to analyze for
the Collections and Payments Service are Total trans-
actions by Merchant, transactions by Financial insti-
tution, transactions by Status, transactions by collec-
tion channels, transactions per Transaction response,
transactions by type of transaction.
3.2 Physical Model of the Data Staging
Area and Data Warehouse
The first step was to design the intermediate layer
between the source system and the Data Warehouse
(DWH), called Data Staging Area.
Data Staging Area (DSA): The DSA is the central
layer that served as storage between the source sys-
tem and the DWH. It allows managing the data with
the origin’s structure to facilitate the DWH’s denor-
malized model’s integration and transformation. The
created structures contain identical fields from the cat-
alogs and transactional table of the data source.
Data Warehouse (DWH): Its function is more
complicated than a data warehouse. It is composed of
Dimensions: Dimensional modeling allowing to con-
textualize the facts by adding different analysis per-
spectives. A dimension contains a series of attributes
or characteristics through which we can group and fil-
ter the data. Tables of Facts: Facts are composed of
the details of the process; this means that they con-
tain numerical data and measurements (metrics) of the
business being analyzed. The technique used to per-
form the dimensional modeling of the current study
is the star model. It is composed of a central fact ta-
ble called DW HEC TRANSACCIONES COBROS,
which is connected through relationships to the di-
mension tables.
3.2.1 Sprint 1: Prototype Design and
Implementation
We developed a prototype that allows users to vali-
date the solution’s usability. The technique used was
Management Support Systems Model for Incident Resolution in FinTech based on Business Intelligence
243

”visual design,” which consists of the design of the
GUI. For this purpose, we created an information
cube whose data source was an Excel file with fic-
titious data. We used the visualization tool available
at FinTech.
3.2.2 Sprint 2: ETL Design and Development
The ETL process starts with the DSA tables’ trunca-
tion, followed by the transactional system’s data ex-
traction. They are placed in the DSA in order to per-
form the transformation and cleaning process. Then,
they are stored in the data warehouse. In order to per-
form such a step, we used SQL Server Integration Ser-
vices (SISS). A SISS package is a work unit in which
the elements which participate in the ETL process are
created. These elements may be of two types:
• Control Flows: They are the program flow control
structures. They indicate the sequence with which
the ETL elements need to be executed.;
• Data Flow: Also known as the stored procedure
(SP), which allows defining the start of the load.
The first step in the ETL process is to create a project
in Microsoft Visual Studio called pqt ETL. As the
next step, we need to create the data connections to
the source, DSA, and DWH. Then, we proceeded with
creating the SQL task to truncate all the tables in the
DSA to clean them to receive the information from
the source. To comply with such intention, we drag
the ”Execute SQL Task” object and type the trunca-
tion SQL statement.
The elements for the extraction of data from the
source tables to the DSA are created one by one using
the ”Data Flow Task” object. In this object, we need
to configure both the data source and the destination.
Once the data extraction is realized, the next step is
the cleaning, integrity validation, consolidation, and
uploading of the data to the DWH.
3.2.3 Creation of Attributes, Metrics, and Smart
Cubes
This task starts with the attributes creation of the di-
mensions, the relationship between them, and the def-
inition of business indicators, where the relationship
of the logical layer and its equivalents in the physi-
cal layer is established, i.e., tables and fields of the
database.
• Creation of Attributes: Attributes in Microstrat-
egy are associated with an ID and a description
for their Creation;
• Creation of Facts: Facts are values by which the
business will be analyzed. For the present study,
the facts are the number of transactions, trans-
action amount, commission, number of approved
transactions, and rejected transactions. The facts
will be used to create the metrics, which will be
the elements and attributes for creating the Smart
Cube. In the menu
¨
Scheme objects
¨
ın the Facts
folder, the metrics are created. The indicators are
then created in the ”Public objects” menu. In this
step, we need to specify the mathematical opera-
tion that will be applied to the event.
• Creation of Smart Cubes: In Microstrategy, a di-
mensional cube (dataset) allows OLAP Services
functions in reports and documents, reducing ac-
cess to the data warehouse.
3.2.4 Development of Dashboards for SP
Monitoring and Transaction Status
In this phase, we performed the reports and dash-
board development containing the attributes and in-
dicators implemented in the previous section. Also,
detailed reports were generated that will be used in
order to analyze the transactional behavior of UP’s
collection and payment network. The deliverable’s
objective was to provide dashboards for the Service
Quality Sub-Process to identify the trend of rejec-
tion of transactions and unusual increases that may
affect UP services. Hereby, a dashboard was pro-
vided for the Operations Coordinator to view details
such as graphs of total transactions, approved and re-
jected transactions, annual, monthly, daily amounts,
and market share percentages. Next, in Fig. 1 and 2,
the developed dashboards are presented:
Figure 1: Dashboards Sprint 2.
3.3 Sprint 3: Sprint Goal Development
The results obtained with this Sprint’s execution
were: (1) Development of two dashboards that al-
low to identify the channels with the highest collec-
tion of the different types of transaction and visualize
the responses, which generate the transaction’s rejec-
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
244

Figure 2: Dashboards Sprint 2.
tion. This analysis will allow the quality area to no-
tify the Account Executive of the news presented for
resolution. (2) Creation and configuration of the au-
tomatic loading Jobs of both the DWH and Micros-
trategy cube, i.e., put into production. (3) Conduction
of the final tests and completion with the movement
towards production.
3.3.1 Channel Dashboard Development and
Transaction Response
In this deliverable, we developed the dashboard to
identify the channels with the highest collection, clas-
sified by type of transaction (i.e., consultation, pay-
ments, and reversals). Likewise, the transaction re-
sponse dashboard was developed, displaying the inci-
dence of error response codes issued by the collect-
ing institution. It should be noted that before the im-
plementation of this study, there were no reports on
collection by channel and details of response codes.
The tool provides clear and concise information on
the channels with the highest collection, recurrence,
and error codes, elements which allow the Company
to pursue the correct decisions to mitigate errors in
the transaction responses and emphasize the use of
digital channels. Figure 3 illustrates the dashboards
developed:
Figure 3: Dashboards Sprint 3.
3.4 Creation of Load of Jobs
In this phase, the package was published in the Sys-
tem Integration of SLQ Server (Server, 2020), and we
created the daily extraction job below the following
criteria: Daily ETL execution: This was necessary to
extract the information based on the accounting date
of the previous day. Also, we performed the config-
uration of notifications of success or failure for the
ETL and smart cube in Microstrategy. Incremental
Bucket Loads: It consists of performing the incremen-
tal loads of the historical data of the transactional ta-
ble of the data source. User Testing: In order to en-
sure that the solution is quality-driven, certification
tests were conducted with the Product Owner to gain
user acceptance. Transfer to Production: This activ-
ity consisted of publishing the developed dashboards
in the production environment and granting permis-
sions to the users created for this purpose. User train-
ing: With the launch of the product, the user training
for the correct practice of the product was finally per-
formed, with relative success.
In summary, Figure 4 represents the complete de-
ployment cycle of model implementation. As previ-
ously explained, it starts with collecting user stories
and prioritization to obtain the product backlog. The
dimensional model’s development follows the inter-
action of one to three of the sprints to finally execute
the model’s implementation.
4 EVALUATION OF RESULTS
4.1 Comprehensive Daily Monitoring
The Comprehensive Monitoring dashboard allows
users to observe the percentage of the number of ap-
proved and rejected transactions, supporting FinTech
collaborators to identify unusual increases per day by
financial institutions and businesses to realize imme-
diate action. Fig. 5 indicates the daily comprehensive
monitoring dashboard.
4.2 Rejected Transactions
Figure 6 illustrates the rejected transactions according
to each month’s collections during the year 2019 until
May 2020. The rejections registered in 2019 tend not
to present more significant variability. Even though a
growing trend is visible as of July, reaching its peak
in December with 402,025 rejected transactions com-
pared to only about 209,631 in January of the same
year. This means that the actions given to the causes
Management Support Systems Model for Incident Resolution in FinTech based on Business Intelligence
245

USER
STORY
USER
STORY
USER
STORY
USER
STORY
Product
Backlog
SPRINT
BACKLOG
SPRINT
1
SPRINT
2
SPRINT
3
Dimensional
model design
Data source
analysis
Definition of
indicators
Design
DSA/DWH
Data source connection
Truncate DSA
tables
Creation attributes
and metrics
Extraction
transformation and
loading
Balance and certification DWH
Design and
development ETL
Visualization
Dashboard
development
Incremental
loads
configuration
Step to
production
Figure 4: A complete deployment cycle of model implementation.
Figure 5: Daily Comprehensive Monitoring Dashboard.
which generated these rejections were not enough to
reduce this behavior.
209631
431718
410564
208573
237932
241739
353916
315463
328198
366324
348886
402025
485193
422187
492332
424456
692885
1544721
1636826
1510394
836153
920172
566228
227528
Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
Data collection
Rejected transactions
Year
Year−2019
Year−2020
Figure 6: Dashboard of rejected transactions.
Contrarily, in the year 2020, significant variability in
the data is visualized since it presents a significant
growth, from May (692,885) to July, which reaches
the highest value of about 1’636,826. This is due to
the pandemic confinement, as the use of online col-
lection services increased drastically. The analysis of
transactional behavior through the application dash-
boards allowed us to deduce the outstanding contribu-
tion to take actions and mitigate the causes that moti-
vated this increase.
4.3 Return of Investment (ROI)
Considering that the present study was developed on
the existing infrastructure in FinTech, the ROI was fo-
cused on the development and implementation costs
of the software solution and the quantification of the
benefits in two years. For this purpose, in princi-
ple, the hourly rate that the collaborators involved in
the BI project invest monthly was established, whose
function was to analyze information to manage inci-
dents related to the Collections and Payments service
quality.
Specifically, the total monthly hours each team
member would use to generate the indicators and
analysis to manage the quality improvement of the
services were considered, such as Operations Leader,
Operations Coordinator, BI Coordinator, Coordina-
tor of Quality, summing up of about 1,143.75 USD.
This work’s implementation costs are included, such
as External Consulting for 8,000 USD and Devel-
opment for 6,000 USD. Besides, implementing a BI
project requires resources, both for the implementa-
tion phase and the solution’s maintenance (operation).
The BI coordinator’s proportional value is considered
the main item for the operation; this meant that the
costs related to maintenance amounted to a total of
about 600 USD.
In order to deliver a benefit value as close as pos-
sible to the national reality, the calculation was per-
formed considering macroeconomic figures such as
inflation and active interest rate. As of January 2020,
the central bank records an active interest rate of
9.14%, while inflation is recorded at 0.23%. There-
fore, a discount rate of 9.4% is estimated. With these
inputs, the discount rate was calculated at 9.4%. Fig-
ure 7 demonstrates the cost/benefit behavior for two
years and reveals the investment’s profitability. Ad-
ditionally, it indicates that during the first year, the
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
246
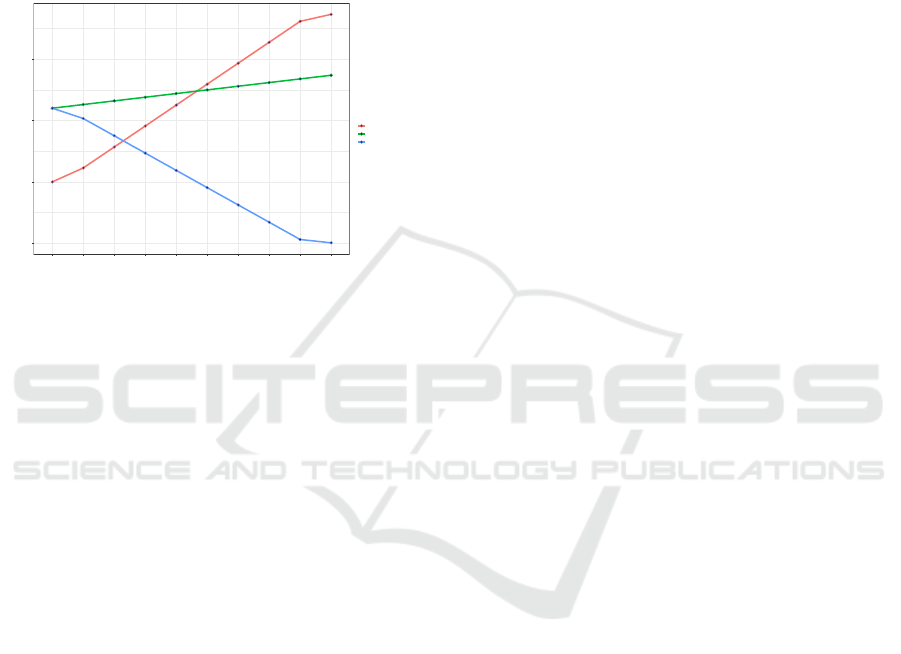
project’s costs are higher than the benefits, which
means that person-hours were lacked to be used ef-
ficiently. However, this behavior changes from the
breakeven point, where the costs are approximate
14,982 (USD), and the benefits are 15,946.4 (USD).
Therefore, the lower the investment costs, the greater
the benefit obtained for the project. We deduced that
person-hours are better used to analyze information
based on the implemented model with these results.
12000
12596.4
13192.8
13789.2
14385.6
14982
15578.4
16174.8
16771.2
17367.6
0
2273.8
5684.4
9095.1
12505.8
15916.4
19327.1
22737.8
26148.4
27285.3
12000
10322.6
7508.4
4694.1
1879.8
−934.4
−3748.7
−6563
−9377.2
−9917.7
Jan−19 Mar−19 Jun−19 Sep−19 Dec−19 Jan−20 Mar−20 Jun−20 Sep−20 Dec−20
Working Period
Cost (USD)
Label
Benefit
Costs
profitability
Figure 7: The behavior of cost/benefit and ROI.
5 CONCLUSIONS
The present study focused on implementing a BI sys-
tem with the necessary elements to achieve the trans-
actional behavior of financial services visible, in-
tending to improve incident management through BI
instruments. Hereby, management indicators were
identified, which allowed us to evaluate, understand,
and value transactional behaviors and trends through
a graphic representation. This resulted in a useful
tool that provides insights for employees who need to
manage anomaly detection and resolution. The sys-
tem’s implementation was able to be delivered in a
shorter time since the agile methodology for project
management Scrum was used combined with Kim-
bal’s dimensional modeling methodology, allowing
collaborators to hold a support tool for managing their
work. As future work, a new version’s deployment
is planned to take competitive advantages that these
platforms provide, such as data streaming and mas-
sive queries.
REFERENCES
Alliance, S. (2016). Learn about scrum. Saatavissa:
https://www. scrumalliance. org/why-scrum [Viitattu
9.7. 2016].
Ayoubi, E. and Aljawarneh, S. (2018). Challenges and op-
portunities of adopting business intelligence in smes:
collaborative model. In Proceedings of the First Inter-
national Conference on Data Science, E-learning and
Information Systems, pages 1–5.
Bedford, P., Millard, S., and Yang, J. (2005). Analysing the
impact of operational incidents in large-value payment
systems: A simulation approach. Liquidity, Risks and
Speed in Payment and Settlement Systems–A Simula-
tion Approach, pages 247–74.
Bobyl, V. V., Dron, M. A., and Taranenko, A. (2018). Op-
erational risks: Assessment and ways of mitigation.
D’Arconte, C. (2018). Business intelligence applied in
small size for profit companies. Procedia computer
science, 131:45–57.
Farahmand, F., Navathe, S. B., Enslow, P. H., and Sharp,
G. P. (2003). Managing vulnerabilities of information
systems to security incidents. In Proceedings of the
5th international conference on Electronic commerce,
pages 348–354.
Gai, K., Qiu, M., and Sun, X. (2018). A survey on fin-
tech. Journal of Network and Computer Applications,
103:262 – 273.
Hahn, S. M. L. (2019). Analysis of existing concepts of
optimization of etl-processes. In Computer Science
On-line Conference, pages 62–76. Springer.
Kimball, R. and Ross, M. (2011). The data warehouse
toolkit: the complete guide to dimensional modeling.
John Wiley & Sons.
Latrache, A., Nfaoui, E. H., and Boumhidi, J. (2015). Multi
agent based incident management system according to
itil. In 2015 Intelligent Systems and Computer Vision
(ISCV), pages 1–7.
Macas, M., Lagla, L., Fuertes, W., Guerrero, G., and Toulk-
eridis, T. (2017). Data mining model in the discovery
of trends and patterns of intruder attacks on the data
network as a public-sector innovation. In 2017 Fourth
International Conference on eDemocracy & eGovern-
ment (ICEDEG), pages 55–62. IEEE.
Malik, Z. H., Farzand, H., Ahmad, M., and Ashraf, A.
(2019). Tour de force: A software process model for
academics. In Intelligent Computing-Proceedings of
the Computing Conference, pages 885–901. Springer.
Midor, K., Sujov
´
a, E., Cierna, H., Zarebinska, D., and Ka-
niak, W. (2020). Key performance indicators (kpis)
as a tool to improve product quality. New Trends in
Production Engineering, 3(1):347–354.
Nugra, H., Abad, A., Fuertes, W., Galarraga, F., Aules,
H., Villacis, C., and Toulkeridis, T. (2016). A low-
cost iot application for the urban traffic of vehicles,
based on wireless sensors using gsm technology. In
2016 IEEE/ACM 20th International Symposium on
Distributed Simulation and Real Time Applications
(DS-RT), pages 161–169.
Schwaber, K. and Sutherland, J. (2013). The scrum guide:
The definitive guide to scrum: The rules of the
game.(2011). Available: scrum. org.
Serna, M. A. A., Arias, J., G
´
omez, J., Lopera, F., and Ar-
bel
´
aez, L. (2016). Information system for the quantifi-
cation of operational risk in financial institutions. In
2016 11th Iberian Conference on Information Systems
and Technologies (CISTI), pages 1–7.
Server, G. S. (2020). Sql server integration services.
Management Support Systems Model for Incident Resolution in FinTech based on Business Intelligence
247
