
On Functional Requirements for Keyword-based Query over
Heterogeneous Databases on the Web
Plinio S. Leit
˜
ao-Junior, F
´
abio Nogueira de Lucena, Mariana Soller Ramada,
Leonardo Andrade Ribeiro and Jo
˜
ao Carlos da Silva
Instituto de Inform
´
atica, Universidade Federal de Goi
´
as, Goi
ˆ
ania Goi
´
as Brazil
Keywords:
Keyword Query Processing, Heterogeneous Databases, Functional Requirements
Abstract:
Context. A large amount of data is made available daily on the Web, but many databases cannot be accessed
by conventional search engines, as they require proper access methods and specialised knowledge through
their access languages.
Focus. In the scenario of non-expert users to access databases, multiple database categories, and plural idioms,
this work analyzes the functional requirements that need to be considered for keyword queries processing over
data sources on the Web. The problem is still open and involves challenges such as query interpretation and
access to databases.
Method. The investigation is centered on the problem itself, which is portrayed by a set of functional issues,
which together represent the challenges linked to the research field.
Approach. This work introduces and systematically analyzes the functional requirements to the problem
scope. Issues reported in the literature are refined and evolved to support the modeling of the problem views:
functional responsibilities and their interactions by messaging between problem objects.
Conclusions and Results. This paper contributes to characterize the problem, makes clearer its understanding
and promotes the development of keyword-based query processing systems. A software engineering artifact is
used to model the problem and make it more formal and precise. Further studies will refine such requirements
and build (specialise) artifacts tailored to the solution space.
1 INTRODUCTION
Over the years, databases (data sources) have be-
come present in many applications and today they
play a prominent role in the service of society, such as
promoting the development of intelligent approaches
through learning on the available data. The value of
data and the popularity of databases has brought new
demands and users, the latter also interested in using
simple and intuitive interfaces to manipulate data.
Query languages usually comply with strict syn-
tactic rules, which makes the validity of query state-
ments dependent on the ability to express an informa-
tion need according to such rules. Furthermore, there
is also a strong dependency on the database schema,
since database entities are explicitly mentioned in the
queries. As a consequence, the user needs to know
about the meaning of each term in the schema (i.e.
entity role).
Regarding interfaces to relational databases,
which are widely used in academia and industry, users
face four challenges for writing queries, namely: (i)
the syntax of relational database languages; (ii) the
exact schema of the databases; (iii) the roles of var-
ious entities in the query; and (iv) the precise join
paths to be followed. In the latter, each join path be-
tween database relations denotes a specific meaning,
so a query addresses those that align with the user’s
intent.
Keyword search is arguably the most popular data
access method for ordinary users because they do not
need to know either a query language or the schema
of the data. In fact, the simplicity of this method was
crucial for the popularization of Web search engines.
A keyword query is a simple sequence of words to
represent the user’s demand for information over one
or more data sources. Thus, as database languages
such as SQL and SPARQL are usually devoted to
technically-skilled users, an obvious benefit of key-
word queries is to allow non-expert users to access
data in databases.
For data access, structured or unstructured data
224
S. Leitão-Junior, P., Nogueira de Lucena, F., Ramada, M., Ribeiro, L. and Carlos da Silva, J.
On Functional Requirements for Keyword-based Query over Heterogeneous Databases on the Web.
DOI: 10.5220/0010453802240231
In Proceedings of the 23rd International Conference on Enterprise Information Systems (ICEIS 2021) - Volume 1, pages 224-231
ISBN: 978-989-758-509-8
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

sources have their own access methods, which con-
form to the database category and depend on their log-
ical data structures. For example, a document-based
store considers that a record (document) has a docu-
ment ID and a list of attribute-value pairs (possibly
recursive), so data access requires appropriate meth-
ods to deal with this data organization. In this context,
query processing involves mapping the user’s key-
word query to access methods specific to each data
source.
An important challenge faced by keyword search
approaches is that many candidate answers could be
retrieved in response to a user query. Each candi-
date answer represents a different interpretation of
the query. However, users generally expect an ex-
act answer that perfectly meets their needs, instead of
wasting time choosing one of many possible answers.
Then, approaches that support keyword-based queries
need to deal with ambiguity, being able to reduce the
number of candidate answers by removing the ones
that have a very low chance of meeting the user’s in-
tention and ranking the rest of them. Despite differ-
ent ways to deal with ambiguity have been proposed
(Hristidis and Papakonstantinou, 2002; Bergamaschi
et al., 2011; Kargar et al., 2015; Hormozi, 2019), the
problem of query disambiguation is still a big chal-
lenge (Hormozi, 2019).
Besides that, after finding a reduced set of can-
didate answers, another challenge is to decide which
extra information that exists in the data source and is
semantically related to the query could help show the
user more interesting data.
While previous work has proposed solutions to
many aspects of the problem, a systematic study on
the fundamental issues around building a keyword-
based system to access heterogeneous databases is
surprisingly missing. Keyword query processing ad-
dresses the mapping of the user’s demand to valid
and appropriate access methods to the category of the
relevant databases, which are those chosen as data
sources for the query. In this context, the main ques-
tion for investigation is posed as follows:
Question. Which functional requirements need to be
considered for keyword queries over data sources on
the Web with heterogeneous idioms and database cat-
egories?
Description. The question addresses the functional
responsibilities necessary to meet the user’s demand,
which together portray the problem related to the key-
word query processing to be solved. In order to be
appropriately robust, such responsibilities should in-
volve the main issues raised in literature that refer
to the functional anatomy that outlines the keyword
query processing problem.
Rationale. The focus embraces non-expert users to
access databases as that is a common facility over
most keyword-based approaches. But the question
also covers aspects that are jointly not present in liter-
ature approaches such as selection of databases per-
tinent to the user’s demand, multiple database cat-
egories, and plural idioms. The first involves data
source access availability regards its domain and con-
tent. Multiple database categories and plural id-
ioms potentially increase the number of data sources
and foment more possibilities for better answering
the user query. Overall the scope makes the prob-
lem more complex related to most of the ones re-
ported in literature but closer to real perspectives upon
databases on the Web.
After this introduction, the paper is organized as
follows. Section 2 introduces the paper focus as well
as analyzes and describes the major functional is-
sues of the keyword query problem. Section 3 deals
with functional objects and their interactions. Related
work and threats to validity are presented in Sections
4 and 5, respectively. Section 6 concludes the work
and shows further developments.
2 KEYWORD QUERY PROBLEM:
FUNCTIONAL ISSUES
Problem analysis is the first and primary stage in soft-
ware development. It impacts on the solution engi-
neering, because if the problem is not properly de-
fined, possibly inappropriate software will be build
for the problem. That is potentially the reason for the
high rate of failures in software projects.
Thus before considering implementing a
keyword-based solution, the problem itself needs to
be clearly characterized and defined, which is the aim
of the present work.
2.1 Focus on Problem Domain
As the investigation focus copes with the problem
space rather than the solution, the definition below
formalizes the paper scope:
Definition 1 (Problem Analysis of Keyword Query
Processing). Problem analysis refers to the process of
understanding and defining the problem to be solved
– Keyword Query Processing problem – i.e. it is the
software engineering stage where much of the learn-
ing on the problem needs to occur.
The present work focuses on understanding the prob-
lem by building models and introducing definitions
On Functional Requirements for Keyword-based Query over Heterogeneous Databases on the Web
225

from the problem statement, specifically those related
to functional aspects.
In the next subsection, functional issues specific
to the problem domain are introduced.
2.2 Functional Issues
Bergamaschi et al. (2016) propose an architecture for
keyword search in relational databases to favor the de-
velopment of scalable and effective components; the
authors advocate that the proposal is general enough
to be used also with other sources. The architecture
is organized into layers focusing primarily on func-
tional requirements. In the context of that paper, the
notion of functional requirements conforms to (IEEE-
Computer-Society et al., 2014): describe the func-
tions that the software has to execute. This is the most
recent proposal for a functional framework and repre-
sents a relevant reference for the development of new
researches and the implementation of keyword query
processing systems.
The research in (Bergamaschi et al., 2016) points
out some issues that hinder the design and devel-
opment of systems for keyword search over struc-
tured data. These issues seek to bring out the main
functional points and the challenges posed to achieve
them. We refine such issues by adding new ones (e.g.
queries on non-structured data sources) and aggregat-
ing new perspectives on understanding the keyword
query problem (e.g. how to deal with the user’s in-
tention and how to express the results from heteroge-
neous sources), as follows.
Interpreting the User’s Intention. A simple se-
quence of words is often inaccurate to represent the
user’s demand, that is guided by the chosen words and
the sequence thereof. Furthermore, the same keyword
query can mean differently for distinct users, or even
to the same user but at distinct times. Given these
difficulties, several interpretations are eligible at cap-
turing the user’s intention. The interpretation space
of the user’s intention refers to the potential render-
ings (query interpretations) that query processing can
abstract when trying to decipher the actual user’s de-
mand:
• The interpretation space is defined by analysing
the potential meanings of the keyword query
(query semantics). The query idiom impacts at
defining the interpretation space with respect to
its content and cardinality. A desirable scenario
is to have a reduced space — few points in that
space that means few query interpretations — and
the user demand fits one or even more among all
the ones in such a space. Realistic scenarios usu-
ally differ from desirable ones, as such scenarios
potentially deal with conflicting objectives.
Selecting Relevant Databases. When submitting a
query on the Web, the user expects results from avail-
able databases (data sources) whose content has affin-
ity with the query semantics. To do this, query pro-
cessing needs to find databases on the Web and then
select those (hopefully, the relevant ones) that are po-
tentially data sources for the query. We refer to pri-
vate databases that are not directly accessed by tradi-
tional search engines, so-called hidden data sources.
This issue involves two pertinent aspects: (i) finding
databases on the Web; and (ii) having access to proper
descriptions upon these databases in order to assess
whether they are relevant to user’s demand. As an
example for both aspects, consider that the database
owner makes their legacy databases visible and acces-
sible on the Web and publishes metadata that describe
customized views of these databases, respectively.
Providing Support for Multiple Idioms. Regarding
idioms for processing queries, several idioms are ide-
ally supported, both for queries and data sources. This
also includes multiplicity: when a query gets results
from databases whose idiom are different from the
query idiom. In this context, the most plural scenario
involves three distinct idioms: query idiom, database
metadata idiom and data idiom.
Dealing with Heterogeneous Databases. SQL and
NoSQL databases can be used as data sources for
query processing by keywords — this heterogeneity
increases the potential to resolve the query. In that
sense, by covering all points in the interpretation
space of the user’s intention, it may happen that some
of query interpretations may not be viable for all rel-
evant data sources, then database-dependent queries
are mapped from interpretations to those viable data
sources. As query interpretations should be further
expressed in database queries, there are two chal-
lenges ahead: (i) analyzing which data sources rel-
evant to the query are feasible with respect to each
query interpretation; and (ii) mapping the query inter-
pretations to the proper access methods of the feasible
data sources.
Executing Database Queries. Query processing
should execute all database-dependent queries over
the relevant data sources on the Web. This involves
aspects such as multiple database connections, data
sensitivity as well as stream scale of resulting data.
Expressing Query Results. A query result is the
response obtained from a data source for an inter-
pretation. A user query can have multiple interpre-
tations, and an interpretation can have multiple re-
sponses, each coming from a particular data source.
The results must be expressed in such a way that the
user can understand and decide how useful a result is
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
226

to her/his informational demand.
Ranking the Query Results. Before being returned
to the user, query results are ideally evaluated against
the real user’s intention, aiming to order them accord-
ing to their relevance. So, this issue refers to the es-
timation of how much each query result may fit the
actual information needs of the user. In this sense, a
ranking model is applied to estimate how valuable a
result is to the user. This model can evolve by learning
about a particular user over the time. In the best sce-
nario, the model promotes that the user has the most
relevant results highlighted in the presentation inter-
face. Nevertheless, such a model is an open challenge
in today’s systems.
Visualising Query Results. This issue is referred to
the presentation of the query results to the user. It is
related to how the results are displayed so that the user
can better understand them and judge their value with
respect to the expected demand.
Overall the functional issues explained above out-
line the major challenges that define the problem
scope and promote proper understanding for further
design of keyword query systems.
3 FUNCTIONAL OBJECTS AND
THEIR INTERACTIONS
Functional responsibilities are fulfilled by objects
identified from the problem, which interact by ex-
changing messages to carry out their functional du-
ties: the characterization of the keyword query prob-
lem is materialized by objects whose interactions aid
to make clearer the functional requirements of the
problem.
Table 1 presents the objects that abstract the main
functional responsibilities: Column 1 identifies the
problem objects; and Column 2 describes the func-
tional responsibility of each object.
Figure 1 presents a Sequence Diagram of the
UML (Unified Modeling Language) — Sequence Di-
agram, for short, which represents the interaction
through messages passed between objects, in the per-
spective of the problem itself. Two aspects that base
the instrument in the figure are:
• The Objects that represent functional responsi-
bilities (rectangles at the figure top) and interact
through the exchange of messages are actually ob-
jects of the problem, rather than objects of a solu-
tion such as a particular keyword query system.
• Interactions between objects promote understand-
ing to the problem, not necessarily establishing a
strict order of message exchanges. That means,
they depict consistent and robust interactions to
represent the problem, but other alternatives to
message sequences are also permissible.
The following are focused on how the functional is-
sues addressed in Section 2 are carried out in the se-
quence diagram.
3.1 Interpreting the User’s Intention
Interpreting the user’s intention includes defining the
interpretation space — a set of interpretations for the
meaning of the keyword query. Definition 2 formally
determines what an interpretation is.
Definition 2 (Query Interpretation). A query interpre-
tation of the user’s demand is a set of term sequences,
such that they have the same meaning to each other.
The simple directed graph G
R
represents the Inter-
pretation R — G
R
is a directed graph with no loops
and no multiple arrows with same source and target
nodes — and it is defined as G
R
= (N, E, s, f ): N is the
set of nodes and each node n
i
∈ N represents a term
or a fork; E is the set of edges and each edge e
i
∈ E
has a source and a target nodes; s and f are the input
and the output nodes of G
R
, respectively; and each
path from s to f denotes a sequence of terms.
For instance, given the keyword query ‘which
2020 award-winning films’, the interpretation shown
in Figure 2 is a set of four sequences: ”2020 awarded
films”, ”2020 awarded movies”, ”2020 award-
winning films” and ”2020 award-winning movies”.
Definition 3 (Query Interpretation Space). The query
interpretation space (or interpretation space, for
short) is the set of interpretations related to the key-
word query. The cardinality of such a set impacts the
number of query results.
The Query Interpreter object typically applies In-
formation Retrieval (IR) and Natural Language Pro-
cessing (NLP) techniques during keyword query anal-
ysis to abstract the interpretation space of the user’s
demand. Each interpretation in this space has its
term sequences enriched from the support of Domain
and Idiom Services: dealWithRestrictions and get-
DomainExtension messages to IdiomService and Do-
mainService objects, respectively.
3.2 Selecting Relevant Databases
Relevant databases are selected by the Data Source
Selector object, which uses the interpretation space
defined for the user’s query (selectDataSource mes-
sage sent by the Controller object). There is inter-
action with the Data Source Catalog Provider ob-
ject (getDataSourceCatalog message sent by the Data
On Functional Requirements for Keyword-based Query over Heterogeneous Databases on the Web
227

Table 1: Functional responsibilities of the keyword query problem.
Problem Object Functional responsibility
Query Interpreter
Defines the interpretation space of the user’s query. Each point in that space
refers to a possible interpretation in relation to the user’s intention that is
represented by the keyword query.
Domain Service
Adds value to the interpretation process by providing knowledge about
potential domains linked to user demand, for example, by using ontologies.
Idiom Service
Handles support for idiom-related extensions, such as providing synonyms
and terms with related meaning, as well as translation between idioms.
Data Source Catalog
Provider
Serves the description of the data sources visible and accessible on the Web,
that is, provides the information on databases necessary to select the relevant
ones to the user’s query.
Data Source Selector
Selects the databases that can serve as a source of data for user’s demand from
those available on the Web.
Database Query
Generator
Generates, for each point in the interpretation space, the access methods
(database-dependent queries) for each data source selected as relevant to the
user’s demand.
Data Source Proxy
Represents the service to access data sources, i.e. database accesses in the
solution scope. For instance, to obtain information upon data sources and to
perform queries over the relevant databases.
Database Query
Runner
Handles the execution of each database query, which refers to an interpretation
applied to a relevant data source.
Ranking Model
Refers to the ordering of the results to the user’s query, aiming to rank them
when presenting them to the user.
Search Controller
Deals with the interaction with the user and the control of the sequence of
messages to the other responsibilities.
Source Selector object), aiming to get metadata from
data sources: refers to hidden databases on the Web
(in relation to the documents accessible by traditional
browsers), such as legacy databases but with views
available for access according to their published meta-
data. Regarding relevant data sources, two definitions
are introduced as follows:
Definition 4 (Relevant Data Source). A data source
relevant to a query interpretation is characterized if
the content of that source covers data from which a
potential response to that interpretation can be ob-
tained.
Definition 5 (Set of Relevant Data Sources). The set
of relevant data sources are those that are relevant to
at least one interpretation within interpretation space
for the user’s demand.
3.3 Supporting Multiple Idioms
The idiom of the user’s query is the one used in the
abstraction process of its interpretations. So the in-
terpretation space idiom is the same as the keyword
query. However, in order to reach data sources in the
context of plural idioms, it is pertinent to know and
understand the idiom of each data source in order to
decide on those that are relevant.
Thus, the interaction with the Idiom Service object
(getIdiomSupport message sent by the Data Source
Selector object) is justified because the catalog of rel-
evant data sources and space for interpretations may
have different idioms. That is necessary to allow
idiom-normalised analysis for searching relevant data
sources.
3.4 Dealing with Heterogeneous
Databases
To handle heterogeneous data sources such as SQL
and NoSQL databases, queries dependent on the
database category are applied to the relevant data
sources, as defined below:
Definition 6 (Database-dependent Query). A
database-dependent query (or database query, for
short) is the representation of a query interpretation
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
228
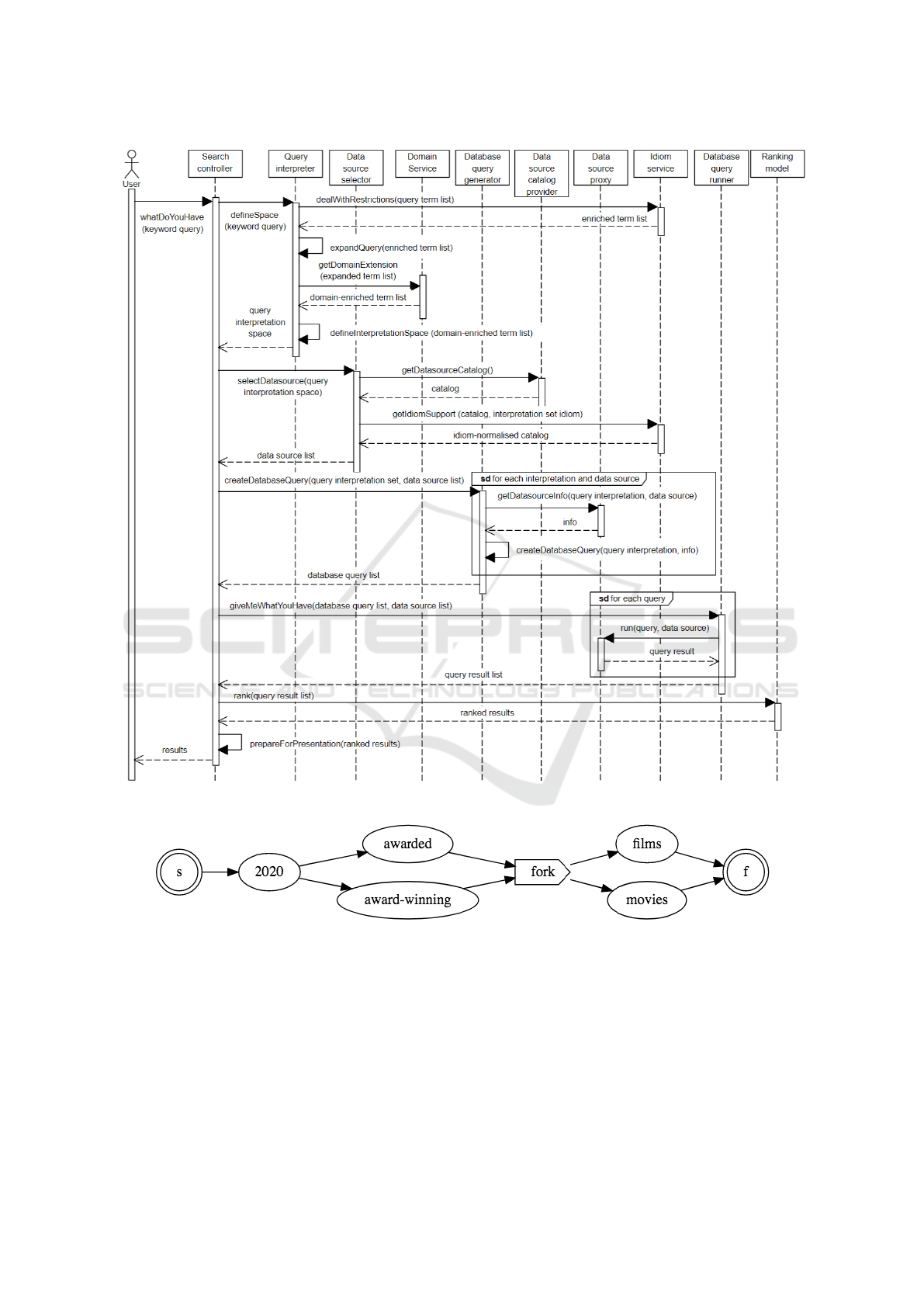
Figure 1: UML sequence diagram for the keyword query problem.
Figure 2: An example of interpretation.
when applied to a particular data source. It con-
siders the data source category (e.g. column family,
relational tables, key-value stores, among others)
and its access methods as well as the entities that
describe the data source.
The Database Query Generator object receives
the createDatabaseQuery message (sent by the Con-
troller object) with two parameters: query interpre-
tation space and relevant data sources. For each in-
terpretation and data source, there is interaction with
the Data Source Proxy object through the getData-
SourceDescription message to obtain information on
the data source entities. Then the Database Query
Generator object analyzes the feasibility of that query
interpretation being applied to the data source. If
so, it translates the query interpretation into a proper
database query to that data source.
On Functional Requirements for Keyword-based Query over Heterogeneous Databases on the Web
229

3.5 Executing Database Queries
The Database Query Runner object receives from the
Controller object the message giveMeWhatYouHave,
whose parameters are ’database query list’ and ’data
source list’. For each query database and data source,
the Database Query Runner object interacts with the
Data Source Proxy object to obtain results from that
interpretation of user demand.
3.6 Expressing Query Results
The query results need to be expressed in such a way
the user can decide how useful they are.
Definition 7 (Query Result). A query result is the
triple hα, β, γi such that: α is a query interpretation;
β is a data source; and γ is data obtained from β re-
lated to α. The former supports user upon data read-
ing and assessing how the interpretation is close to
her/his informational demand; the second addresses
data origin (e.g. url, database description); the later
refers to data themselves.
The Database Query Runner object builds the re-
sult triples and sends them to the Controller object in
the response of giveMeWhatYouHave message. To-
gether the triple components make query results more
evaluable as well as improve user experience.
3.7 Ranking the Query Results
The Ranking Model object receives the query result
set from the Controller object and applies a ranking
model to that set, as defined:
Definition 8 (Ranking Model). A ranking model is
the function r( f (α), g(β), h(γ)) that returns how ap-
propriate a result is to the user’s demand, such that:
f (α) measures the adequacy of the interpretation α
to the query; function g(β) scales the fitness of data
source β to the query; and function h(γ) scores how
proper data obtained from α in β meet user’s demand.
As a consequence the Controller object receives
scored query results, i.e. a rank of query results.
3.8 Visualising Query Results
The Controller object prepares the ranked query re-
sults in order to present them to the user. For instance,
initially the descriptions of the interpretation and the
data source are presented, ordered according to the
rank of the results. Then the user ’clicks’ on one or
more of the results to view the data obtained.
The definitions introduced above seek to converge
the understanding of the problem terminology and to
more precisely outline functional responsibilities and
their interactions.
4 RELATED WORK
Regarding the focus of this research, Selection and
ranking of relevant data sources with respect to a
keyword query were addressed in (Sayyadian et al.,
2007; Li et al., 2008; Ramada et al., 2020). Pu and
Yu proposed in (Pu and Yu, 2008; Pu and Yu, 2009)
support for keyword query cleaning, which involves
spelling corrections and segmentation of neighbour-
ing keywords so that each segment corresponds to
a high quality data term. Various ranking functions
have been proposed to deal with the inherently ambi-
guity of keyword searches, providing a way to mea-
sure the relevance of each result and order query re-
sults (Hristidis and Papakonstantinou, 2002; He et al.,
2007; Luo et al., 2008; Hormozi, 2019). Despite
the many contributions from the community to ad-
dressing issues related to the keyword search prob-
lem, to the best of our knowledge, the research field
has mainly addressed efforts from the solution per-
spective. A systematic study of the fundamental is-
sues surrounding the construction of a keyword-based
query system, from the problem perspective, has yet
to be developed.
5 THREATS TO VALIDITY
Functional requirements are illustrated by using a
software engineering artifact, a UML Sequence Di-
agram. That is a more formal way to introduce the
functional responsibilities and interactions thereof re-
lated to the keyword query processing problem in-
stead of including figures whose notation is usually
not known.
Regarding the generalization of the findings, they
are grounded on functional issues, in which some of
them were initially introduced by the research field.
Such issues represent what the literature ’thinks’ at
the moment about functional challenges related to the
keyword query processing problem.
The contributions were initially based on evidence
from papers related to the problem and evolved in a
systematic way: the authors were randomly divided
into pairs; each pair analysed every issue described in
Section 2 to produce a partial artifact per issue; the
partials were then evaluated and evolved by at least
another pair of authors; several meetings with all au-
thors integrated the partial artifacts to consolidate the
final artifact of the complete problem.
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
230

6 CONCLUSIONS
The present work analyzed functional issues that are
related to the keyword query processing problem.
Such issues represent important aspects that make
such a problem challenging and complex.
The problem involves submitting keyword-based
queries — using an appropriate interface for non-
expert users — to access the content of heterogeneous
data sources with respect to the database category and
the plurality of idioms. Unlike other sources of data
accessible on the Internet, such as documents of pub-
lic content, the problem reaches sensitive databases,
which are usually hidden on the Web.
The main contribution of the work is to advance
the characterization and formalization of the problem
in functional terms, such that it promotes a greater un-
derstanding of its functional requirements and a better
perception of its complexity. Some specific contribu-
tions of this work include:
• evolution of functional issues present in the litera-
ture, by bringing more details and perspectives for
understanding as well as adding new issues not yet
addressed;
• abstraction of problem objects that are actually
necessary responsibilities for modeling the func-
tional requirements;
• construction of a software engineering artifact -
UML Sequence Diagram - describing the prob-
lem domain objects and the interactions between
them; such a diagram also eases keyword-based
query comprehension;
• introduction of definitions in the problem domain
to add more formalism, extend existing terminol-
ogy and promote new perspectives on the func-
tional issues.
Threats to validity are addressed by: (i) building a
software engineering artifact, as it is a systematic rep-
resentation; (ii) grounding the results on functional is-
sues introduced mainly by the research area; and (iii)
producing partial artifacts by random pairs of authors,
and integrating them to consolidate the final artifact of
the complete problem by all authors.
Further studies will refine the functional require-
ments and build (specialise) artifacts tailored to the
solution domain.
REFERENCES
Bergamaschi, S., Domnori, E., Guerra, F., Lado, R. T., and
Velegrakis, Y. (2011). Keyword Search over Rela-
tional Databases: A Metadata Approach. In Proceed-
ings of the ACM SIGMOD International Conference
on Management of Data, pages 565–576. ACM.
Bergamaschi, S., Ferro, N., Guerra, F., and Silvello, G.
(2016). Keyword-Based Search Over Databases: A
Roadmap for a Reference Architecture Paired with an
Evaluation Framework, pages 1–20. Springer Berlin
Heidelberg.
He, H., Wang, H., Yang, J., and Yu, P. S. (2007). Blinks:
Ranked keyword searches on graphs. In Proceed-
ings of the ACM SIGMOD International Conference
on Management of Data, pages 305–316. ACM.
Hormozi, N. (2019). Disambiguation and Result Expan-
sion in Keyword Search Over Relational Databases.
In Proceedings of the IEEE International Conference
on Data Engineering, pages 2101–2105. IEEE Com-
puter Society.
Hristidis, V. and Papakonstantinou, Y. (2002). DISCOVER:
Keyword Search in Relational Databases. In Proceed-
ings of the International Conference on Very Large
Data Bases, pages 670–681. Morgan Kaufmann.
IEEE-Computer-Society, Bourque, P., and Fairley, R. E.
(2014). Guide to the Software Engineering Body of
Knowledge SWEBOK Version 3.0. IEEE Computer
Society Press, Los Alamitos, CA, USA.
Kargar, M., An, A., Cercone, N., Godfrey, P., Szlichta,
J., and Yu, X. (2015). Meaningful Keyword Search
in Relational Databases with Large and Complex
Schema. In Proceedings of the IEEE International
Conference on Data Engineering, pages 411–422.
IEEE Computer Society.
Li, G., Ooi, B. C., Feng, J., Wang, J., and Zhou, L. (2008).
Ease: An effective 3-in-1 keyword search method
for unstructured, semi-structured and structured data.
In Proceedings of the ACM SIGMOD International
Conference on Management of Data, page 903–914.
ACM.
Luo, Y., Wang, W., and Lin, X. (2008). SPARK: A keyword
search engine on relational databases. In Proceedings
of the IEEE International Conference on Data Engi-
neering, pages 1552–1555. IEEE Computer Society.
Pu, K. Q. and Yu, X. (2008). Keyword query cleaning.
Proceedings of the International Conference on Very
Large Data Bases, page 909–920.
Pu, K. Q. and Yu, X. (2009). FRISK: keyword query clean-
ing and processing in action. In Proceedings of the
IEEE International Conference on Data Engineering,
pages 1531–1534. IEEE Computer Society.
Ramada, M. S., da Silva, J. C., and de S
´
a Leit
˜
ao-J
´
unior, P.
(2020). From keywords to relational database content:
A semantic mapping method. Information Systems,
88:101460.
Sayyadian, M., LeKhac, H., Doan, A., and Gravano, L.
(2007). Efficient keyword search across heteroge-
neous relational databases. In Proceedings of the
IEEE International Conference on Data Engineering,
pages 346–355. IEEE.
On Functional Requirements for Keyword-based Query over Heterogeneous Databases on the Web
231
