
Using Academic Genealogy for Recommending Supervisors
Gabriel Madeira
1 a
, Eduardo N. Borges
1 b
, Giancarlo Lucca
1 c
,
Washington Carvalho-Segundo
2 d
, Jonata C. Wieczynski
1 e
, Helida Santos
1 f
and Grac¸aliz Dimuro
1,3 g
1
Centro de Ci
ˆ
encias Computacionais, Universidade Federal do Rio Grande, Rio Grande, RS, Brazil
2
Instituto Brasileiro de Informac¸
˜
ao em Ci
ˆ
encia e Tecnologia, Bras
´
ılia, DF, Brazil
3
Departamento de Estad
´
ıstica, Inform
´
atica y Matem
´
aticas, Universidad Publica de Navarra, Pamplona, Spain
Keywords:
Recommender Systems, Academic Genealogy, Academic Supervising, Nearest Centroid Classification.
Abstract:
Selecting an academic supervisor is a complicated task. Masters and Ph.D. candidates usually select the most
prestigious universities in a given region, investigate the graduate programs in a research area of interest,
and analyze the professors’ profiles. This choice is a manual task that requires extensive human effort, and
usually, the result is not good enough. In this paper we propose a Recommender System that enables one to
choose an academic supervisor based on his/her academic genealogy. We used metadata of different theses
and dissertations and applied the nearest centroid model to perform the recommendation. The obtained results
showed the high precision of the recommendations, which supports the hypothesis that the proposed system is
a useful tool for graduate students.
1 INTRODUCTION
One of the first steps during the process of acquir-
ing an academic degree, either Masters or Ph.D., is
the choice of the theme to be investigated and then an
academic supervisor, which will be in charge of aid-
ing the student to achieve his/her goals. In the task
of choosing an academic supervisor, the amount of
experience regarding the theme’s field of study is sig-
nificant. However, this choice might not be so trivial.
This job should include a thorough analysis of each
professor’s curriculum, including the list of scientific
publications and all theses and dissertations advised,
which can be available in multiple and distributed re-
search repositories.
Ray and Marakas (Ray and Marakas, 2007) assert
that students’ usual criteria are professors’ reputation,
knowledge, and matching of interests, among others.
However, this choice is often made in an unplanned
a
https://orcid.org/0000-0001-8348-3498
b
https://orcid.org/0000-0003-1595-7676
c
https://orcid.org/0000-0002-3776-0260
d
https://orcid.org/0000-0003-3635-9384
e
https://orcid.org/0000-0002-8293-0126
f
https://orcid.org/0000-0003-2994-2862
g
https://orcid.org/0000-0001-6986-9888
manner, which can become one of the reasons for re-
gret, lack of motivation, and poor quality of research
output. The authors proposed an analytical hierarchy
process for selecting a thesis supervisor, which shows
that the number of theses supervised is the least im-
portant criterion for both junior and senior graduate
students. Besides matching interests, the professors’
social network and relationship with other professors
in the same institute and outside were pointed out as
essential criteria.
In this paper, we developed a Recommender Sys-
tems (RS) that extracts knowledge from a set of de-
scriptive metadata of theses and dissertations super-
vised throughout the advisors’ career, considering so-
cial aspects extracted from their academic genealogy
trees. Our methods can represent adequately the pro-
file and research area of a young professor who men-
tored few or no students. When inputting the title and
abstract of a thesis/dissertation proposal, the system
returns a ranking of the most compatible advisors for
the chosen theme. So, the major contributions of this
paper are the following: a novel content-based recom-
mendation approach for selecting academic supervi-
sors; the use of academic genealogy trees (Sugimoto,
2014) (see an example in 4) to model the supervisors’
profiles; and the experimental evaluation of the pro-
posed RS using real data from a networked digital li-
Madeira, G., Borges, E., Lucca, G., Carvalho-Segundo, W., Wieczynski, J., Santos, H. and Dimuro, G.
Using Academic Genealogy for Recommending Supervisors.
DOI: 10.5220/0010442608850892
In Proceedings of the 23rd International Conference on Enterprise Information Systems (ICEIS 2021) - Volume 1, pages 885-892
ISBN: 978-989-758-509-8
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
885

brary of theses and dissertations.
The experiments were conducted using a dataset
containing more than 79,000 advisors from more than
600,000 theses and dissertations. Our system was
able to recommend the correct advisors, on average,
in the third position of the suggested ranking.
The rest of this paper is organized as follows. Sec-
tion 2 presents the preliminary concepts necessary to
understand our methods. In section 3 we discuss re-
lated work. Section 4 presents our approach to recom-
mend academic supervisors. In Section 5, we discuss
the obtained results. Finally, in Section 6, we draw
our conclusions.
2 PRELIMINARY CONCEPTS
2.1 Recommender Systems
RSs provide suggestions for information related to
several decision-making processes. The recommen-
dations are offered as ranked lists of information
items, which are personalized for each user. Besides
filtering the most suitable information, RSs organize
it with a high probability of relevance based on user
preferences and constraints. (Ricci et al., 2011).
Among the features pointed by (Bobadilla et al.,
2013) that define a RS, we highlight: type of data,
e.g. ratings, content for items, social relationships
and location-aware information; filtering algorithm,
e.g content-based, collaborative, context-aware or hy-
brid; techniques, e.g. probabilistic algorithms and
fuzzy models; sparsity level of the database and the
desired scalability; objective – predictions or top-n
recommendations; quality evaluation, e.g. novelty,
coverage and precision (Ge et al., 2010).
Content-based filtering (Salter and Antonopoulos,
2006) makes recommendations based on user past
choices using the similarity between the content of
these items and those to be recommended. Demo-
graphic filtering (Krulwich, 1997) performs the sim-
ilarity among users, based on the principle that in-
dividuals with common personal attributes will also
have common preferences. Examples of these at-
tributes are gender, age, location and language. Col-
laborative filtering (Bobadilla et al., 2012) allows
users to give ratings (explicit or implicitly) on infor-
mation items, which can be used to recommend con-
tent for other users with similar profiles. Hybrid fil-
tering (Chen et al., 2018) combines multiple filtering
algorithms.
In this paper, we adapted a well-known content-
based filtering neighborhood-based recommendation
technique (Desrosiers and Karypis, 2011) for sug-
gesting academic supervisors, by making used of the
content of theses and dissertations descriptive meta-
data and the advising relationships. We focus on sys-
tem precision disregarding scalability to perform top-
n recommendations.
2.2 Vector Space Model
Proposed by Salton in 1968 (Salton, 1968), Vector
Space Model (VSM) is a classic information retrieval
model implemented in many search engines. It uses
bag of words representation and allows to retrieve
documents ordered according to the query similar-
ity. Let D be a collection of documents represented
by vectors of weights associated with the terms con-
tained in the collection vocabulary. The similarity be-
tween a query q and a document d ∈ D is given by
Eq.(1), which performs the cosine of the angle be-
tween the vectors.
sim(~q,
~
d) = cos(~q,
~
d) =
~q ·
~
d
|~q||
~
d|
(1)
The most common weighting scheme is called TF-
IDF, represented by t f × id f (Manning et al., 2008)
and defined by Eq.(2), where t is a term of the vo-
cabulary V, d is a document, n
t,d
is the frequency of
the term t in the document d, N is the size of the col-
lection, i.e. the amount of documents, and d f
t
is the
frequency of documents containing t.
t f
t,d
× id f
t,d
=
n
t,d
∑
t
0
∈V
n
t
0
,d
× log
N
d f
t
(2)
A VSM can be efficiently implemented using an in-
verted index, which maps each term of the vocabulary
into a list of postings, which contain the identifier of
the document containing the term and additional in-
formation such as frequency.
2.3 Nearest Centroid Classification
Nearest Centroid (Tibshirani et al., 2002; Manning
et al., 2008) is a model that classifies test samples
according to their distance to the centroid of data
classes. For text classification, let n be the amount of
documents in a set D, and let s
i
|1 ≤ i ≤ n be a sample
defined by (~x
i
,y
i
), where~x
i
is a document represented
in the VSM using t f × id f weighting scheme, and let
Y be the set of class labels, and y
i
∈ Y is the class label
of this sample.
In the training phase, the algorithm sets the cen-
troids~µ(l) for each distinct class label l ∈ Y, comput-
ing the vector average or center of mass of its mem-
bers. Equation (3) defines~µ(l), where D
l
is the docu-
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
886

ment whose class label is l.
~µ(l) =
1
|D
l
|
∑
s
i
∈D
l
~x
i
(3)
The prediction function reported in Eq.(4) returns the
class label ˆy which minimizes the Euclidean distance
between the associated centroid ~µ
l
and the test in-
stance ~x. Alternatively, Eq.(5) defines how the label
can be predicted using the cosine similarity, previ-
ously presented in Eq.(1).
ˆy = argmin
l∈Y
|~µ
l
−~x| (4)
ˆy = argmax
l∈Y
sim(~µ
l
,~x) (5)
2.4 Mean Average Precision
The Mean Average Precision (MAP) (Manning et al.,
2008) is a well-know metric for evaluating Informa-
tion Retrieval systems. It performs the mean of the av-
erage precision scores calculated for several queries.
Figure 1 shows an example in which the MAP
is performed. Relevant documents are represented
in bold. For the first query, there are three relevant
documents that are returned in the second, third and
fifth positions of the ranking. The average precision
for query 1 is avg
P
1
= (1/2 + 2/3 + 3/5)/3 = 0.59.
Query 2 retrieves two relevant documents in the first
and third positions. The average precision for query 2
is avg
P
2
= (1/1 + 2/3)/2 = 0.83. Therefore, MAP =
(avg
P
1
+ avg
P
2
)/2 = 0.71.
In classification problems, the queries are the test
instances submitted to the classification model.
average precision query 2 = (1 + 2/3) / 2 = 0.83
= relevant documents for query 1
Ranking #1
Precision 0/1 1/2 2/3 2/4 3/5
= relevant documents for query 2
Ranking #2
Precision 1/1 1/2 2/3 2/4 2/5
average precision query 1 = (1/2 + 2/3 + 3/5) / 3 = 0.59
mean average precision = (0.59 + 0.83) / 2 = 0.71
Figure 1: An example of MAP considering two queries.
3 RELATED WORK
(Husain et al., 2019) review the literature about ex-
pert finding systems between 2010 and 2019. These
systems have been proposed in different domains and
environments, such as medicine, enterprise, ques-
tion answering communities, and social networks.
Academia was the largest domain, comprising 44
studies (65% of the sample). The majority of these
systems were developed for specific academic tasks
like paper reviewing, research collaborations, finding
similar experts, and industry or university collabora-
tions. Only one study addressed finding a suitable su-
pervisor (Alarfaj et al., 2012). The authors proposed
a simple database-driven approach that selects a su-
pervisor from the university’s academic staff, and a
data-driven approach where candidates are extracted
from pages returned by a web search engine.
(Hasan and Schwartz, 2018) developed RecAdvi-
sor, a criteria-based Ph.D. supervisor recommender
for Florida State University (FSU). The prototype col-
lects information from four different sources: Mi-
crosoft Academic Graph, Computing Research and
Education Association (CORE), professors’ CVs and
FSU’s digital repository. The profiles are indexed us-
ing Elasticsearch (Gormley and Tong, 2015).
Selecting an academic supervisor is not a popu-
lar research theme. Most related work we could find
were proposed for very specific scenarios, such as
finding scientific articles and papers, recommending
academic courses, and suggesting researchers for col-
laboration.
Docear’s RS (Beel et al., 2013) is part of a liter-
ature management software. The system allows a re-
searcher to search, read, make annotations and orga-
nize scientific articles, besides drafting manuscripts.
Docear suggests citations from a digital library con-
taining around 1.8 million research articles from var-
ious disciplines.
Champiri et al. (Champiri et al., 2015) published
a survey analysing if incorporating contextual infor-
mation in recommender systems is an effective ap-
proach to create more accurate and relevant recom-
mendations in digital libraries. They highlight RSs
with the purpose of exploring a research area and find-
ing relevant research sources.
In order to recommend the most relevant courses
to its users, the RARE system (Bendakir and A
¨
ımeur,
2006) combines the benefits of both former students’
experience learned in the data mining process and
current students’ ratings. It is a hybrid filtering ap-
proach based on association rules. Authors used the
association algorithm Apriori implemented by Weka
tool for training the model. With a similar purpose,
O’Mahony and Smyth (O’Mahony and Smyth, 2007)
developed a RS for an on-line enrolment application
of Dublin’s University College. Users can search
by inserting keywords or specific core module IDs.
The output is a list of elective modules which match
Using Academic Genealogy for Recommending Supervisors
887
the search criteria and their profile. Authors used a
item-based collaborative filtering algorithm (Karypis,
2001). Another strategy has recently been proposed to
domain-aware grade prediction and top-n course rec-
ommendation (Elbadrawy and Karypis, 2016).
Rodrigues et al. (Rodrigues et al., 2018) use
different strategies to suggest scientific collabora-
tion for researchers based on their interest. The au-
thors model the similarity between researchers us-
ing data from ResearchGate social network. They
exploit co-authorship attributes and paper reading
records with a hybrid approach, having both content-
based and collaborative filtering. Experimental re-
sults showed that the content-based strategy out-
performs neighborhood-based collaborative filtering
strategies up to 21.16% regarding F-measure for the
top-20 recommendation lists.
Mendonc¸a et al. (Mendonc¸a et al., 2020) present
a systematic mapping of RSs based on scientific pub-
lications. They analysed that Machine Learning al-
gorithms and Vector Space Model representation are
the most used in content-based RSs for the academic
field. On the other hand, for collaborative filtering
approaches, common methods are based in neighbor-
hood, such as k Nearest Neighbors. Databases fre-
quently used were: CiteULike, DBLP, Microsoft Aca-
demic Search (MAS), CiteSeerx, PubMed and Web of
Science.
The RS proposed in this paper differs from most
related works in the following aspects. Instead of rec-
ommending collaborations based in coauthoring, we
used the advising relationships to suggest academic
supervisors. The supervisor profiles are learned us-
ing their academic genealogy trees build from Elec-
tronic Theses and Dissertations (ETDs) repositories.
We quantitatively evaluate our system using data from
more than 79,000 professors and 600,000 students.
4 A NOVEL ACADEMIC
SUPERVISOR RS
In this section we present our novel approach for rec-
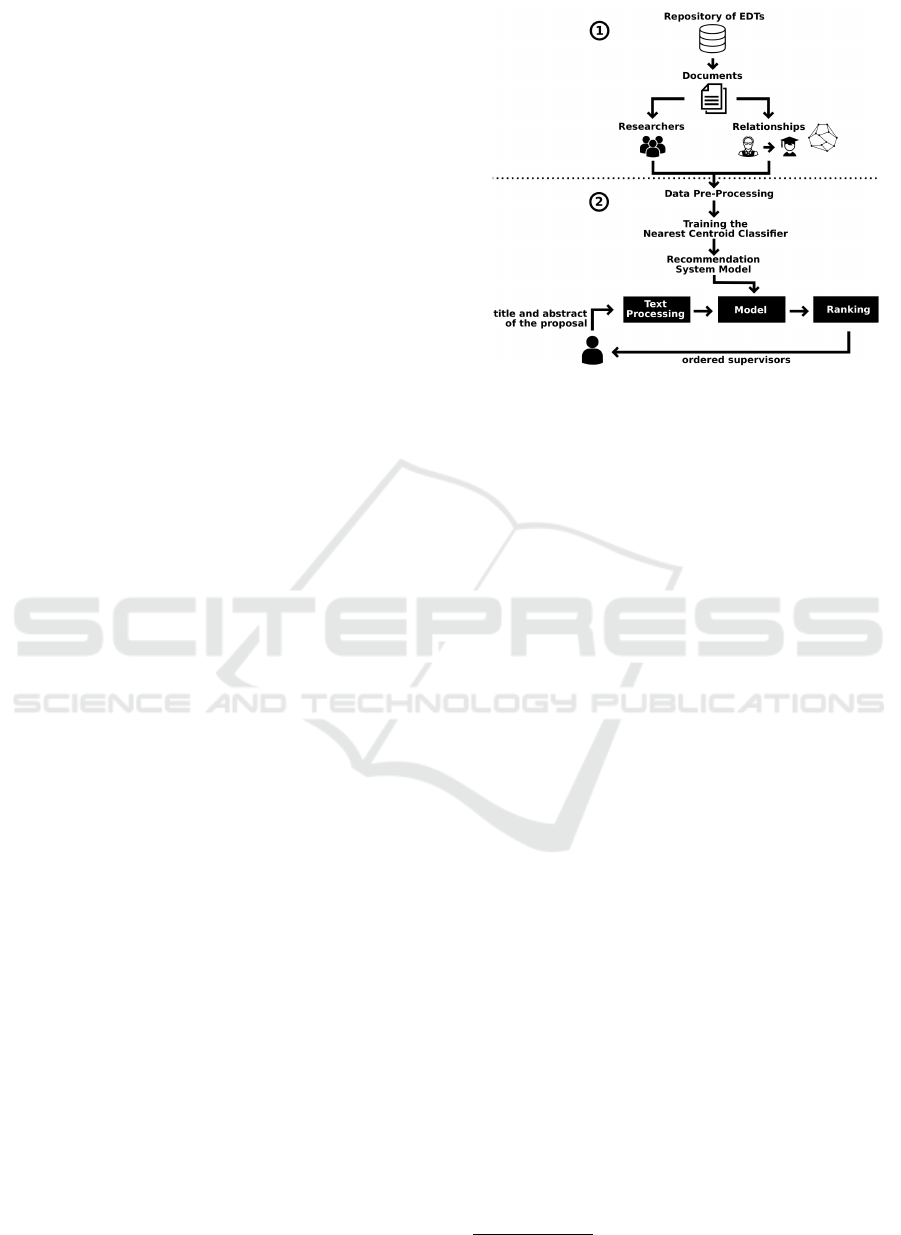
ommending academic supervisors. Figure 2 shows
the architecture of the proposed RS.
The first process collects data and builds the aca-
demic genealogy. From a repository of ETDs, the
RS selects a set of documents of interest. After
that, the researchers, i.e. supervisors and authors,
are extracted from the selected theses and disserta-
tions. A deduplication method is applied to identify
each unique research. From the relationships between
unique researchers, the genealogy graph is built using
the method proposed in (Madeira et al., 2020).
Repository of EDTs
Documents
1
Figure 2: Architecture of the proposed academic supervisor
RS.
Using machine learning, in the second process, we
fit a model that will be used to perform recommen-
dations. Textual data from the academic genealogy
are pre-processed with standard operations. We trans-
form data features into VSM using t f × id f term-
weighting strategy, presented in Section 2.2. Next,
using the transformed data, we train a classifier based
on the Nearest Centroid algorithm (Section 2.3) using
the cosine similarity and build the recommendation
model.
Finally, users can query by inserting the title and
abstract of the research proposal. This information
is transformed using the same pre-processing scheme
as before and then it is used as input of the classi-
fier, which returns a final ranking of recommendations
composed by the most suitable supervisors ordered by
relevance. In the following subsections, each step is
detailed.
4.1 Data Source
The proposed RS can handle different data sources.
Repositories of ETDs must support some interoper-
ability features, such as the OAI-PMH protocol (De-
varakonda et al., 2011), or have an API available for
harvesting metadata.
In this study, we used a Brazilian repository,
known as (Biblioteca Digital Brasileira de Teses e
Dissertac¸
˜
oes – BDTD)
1
. This networked digital li-
brary contains metadata from more than 600 thousand
documents. BDTD integrates and disseminates, in an
unique website, the complete content of different the-
ses and dissertations that are produced in Brazilian
1
Available in http://bdtd.ibict.br.
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
888

universities. Additionally, its access is open and free
of any kind of charge.
This digital library also contributes to increase the
content of Brazilian theses and dissertations on the
internet, growing the visibility of the national techno-
logical and scientific production. Moreover, BDTD
also provides major visibility and management of the
investments done in graduate programs.
From the BDTD available metadata fields, we
picked:
• network acronym str – acronym for the univer-
sity;
• network name str – name of the origin repository;
• title – document’s title;
• description – document’s abstract;
• author – document’s author;
• advisor – document’s supervisor;
• author lattes – URL of the author’s curriculum in
Lattes Platform
2
;
• topic – related topics of the document;
• citation – how to cite the document;
• language – language of the document (mostly in
Portuguese)
• publishDate – year the document was published;
• format – indicates if a document is a Ph.D. thesis
or a Master dissertation;
• url – URL of the document in its original reposi-
tory.
We collected 612,714 theses or dissertations from
BDTD. For each document, we extracted the re-
searchers (author and supervisor) and their relation-
ship to build the academic genealogy. The giant com-
ponent of the graph had more than 300 thousand ver-
tices connected by more than 350 thousand edges.
4.2 Data Pre-processing
The amount of documents collected and the data vol-
ume stored can be large. Data can have different no-
tations and language particularities. Thus, in order to
standardize the information, a pre-processing is nec-
essary. We applied the following operations in the
textual data. First, the title, description, author and
advisor metadata fields are tokenized. Tokens are nor-
malized by turning characters to lowercase, removing
2
An information system maintained by the Brazilian Na-
tional Council for Scientific and Technological Develop-
ment (CNPq) that integrates databases of curricula, research
groups and institutions. Available in http://lattes.cnpq.br.
word2
tf-idf weight
advisor1
advisor2
centroid
Ranking
1:
advisor2
2: advisor1
new_document
word1
tf-idf weight
Figure 3: An example of how Nearest Centroid algorithm
works with VSM.
accents and non-alphanumeric symbols. We also re-
moved stopwords in Brazilian Portuguese using the
NLTK toolkit (Loper and Bird, 2002). This opera-
tion reduces data volume and speeds up the system
without affecting significantly the quality of the re-
sults. After that, the space of features of the title
and description are transformed into the VSM, using
t f × id f term-weighing strategy.
Besides, we applied a cleaning process, removing
duplicates and documents with missing information.
We also corrected misreported information, resulting
in 579,486 pre-processed theses and dissertations.
Finally, an additional pre-processing operation
sets the class label using the advisor metadata field,
composing the training samples with the structure
s
i
= (~x
i
,y
i
), where ~x
i
is the title and description t f ×
id f weights, and y
i
is the class label of the sample i.
The conducted experiments used only one level of the
tree but the system can be parameterized to reach any
depth, adding the vector components of the supervi-
sors’ theses in the training samples.
4.3 Training the Classifier for
Recommendation
Due to the good results presented in (Han and
Karypis, 2000), we chose the Nearest Centroid clas-
sification algorithm to learn the supervising profiles.
Figure 3 shows an example of how the algorithm
works regarding two candidate advisors and a new test
instance (Ph.D. or Masters proposal). Each circle or
triangle refers to a thesis or dissertation in the mul-
tidimensional term space. Dots are the centroids of
the clusters formed by all works supervised by each
advisor, i.e. the supervisors’ profiles. The user re-
ceives as recommendation a profile list, composed by
the class labels (distinct advisors) of the n = 2 nearest
centroids.
Using Academic Genealogy for Recommending Supervisors
889

5 EXPERIMENTAL EVALUATION
In this section, we explain how we evaluate the qual-
ity of the proposed academic supervisor RS, we re-
port implementation details, and we also present the
obtained results.
5.1 Validation
To evaluate the proposed RS, we used k-fold cross-
validation technique, which consists in splitting the
available dataset in k folds and calculating the evalu-
ation metrics k times, where in each interaction, one
of the parts is used for testing and the others are used
for training the model.
We used the evaluation metric Mean Average Pre-
cision (MAP), presented in Section 2.4 applied in the
output of the predict function, which is a ranking with
more than 79 thousand positions. Besides, a student
may have two different advisors, one for the Masters
dissertation and another for the Ph.D thesis. In this
case, both were considered correct recommendations,
because they could appear in distinct positions of the
ranking.
5.2 Implementation
The implementation was coded in Python using the
scikit-learn library (Pedregosa et al., 2011). The
Nearest Centroid algorithm was adapted from the
scikit-learn implementation to return an ordered list
of centroids. This list is the ranking of the most suit-
able academic supervisors from BDTD for a Ph.D. or
Masters proposal in the query.
We highlight that due to dataset volume, we
needed to modify the source code of the python
library. Precisely, the scikit-learn uses a float64
matrix to store the documents represented in the
VSM. This approach slows down the system perfor-
mance. So, to avoid this problem, we have changed
it to scipy.sparse.lil matrix, which implements row-
based list of lists sparse matrix.
Experiments run on a dual-socket quad-core
Intel
R
Xeon
R
L5420 2.5 GHz CPU with 32 GB of
memory.
5.3 Results
In this section, we start by presenting a query example
and the returned recommendations. After, we focus
on the evaluation considering MAP and the frequency
in which the correct advisor is well recommended.
Figure 4 shows the academic genealogy tree of the
researcher named Mar
´
ılia Abrah
˜
ao Amaral. Note that
she had two different advisors, one for Masters (M)
and another for Ph.d (D). Relationships labels also
include the thesis or dissertation’s publication year.
Moreover, we can also observe that this person has
already advised a Masters student in 2017.
Marília Abrahão Amaral Tree
D-2008
D-1997
M-2002
M-2017
Anne Caroline Lesinhovski
Marília Abrahão Amaral
Neri Dos Santos
Vania Ribas Ulbricht
Jose Palazzo Moreira De Oliveira
Figure 4: An example of an academic genealogy tree, where
each arrow represents a Ph.D. (D) or Master (M) advising
relationship.
In the proposed RS, using as input the title and ab-
stract of her thesis, we obtain a ranking of supervi-
sor recommendations. The first five positions are pre-
sented in Table 1.
Note that a correct answer (Marilia’s Masters ad-
visor, J. Palazzo) was returned in the fifth position.
Considering that we have more than 79 thousand pos-
sible candidates, the obtained result is fairly good.
Moreover, if we take into account the remain-
der recommendations, all suggestions are indeed re-
lated to Marilia’s research field and can also be con-
sidered exceptional recommendations. The first two
researchers (J. Valdeni and R. Vicari), for instance,
work in the same university of J. Oliveira. Those three
professors had already been part of the same research
group within the same graduate program. Therefore,
any of them could have been Marilia’s advisor as their
profiles are strongly related to her topic of interest.
Table 1: Returned recommendations using the title and ab-
stract of Mar
´
ılia Abrah
˜
ao Amaral’s Ph.D. thesis.
Position Name
1 Jose Valdeni de Lima
2 Rosa Maria Vicari
3 Alex Sandro Gomes
4 Jos
´
e Dutra de Oliveira Neto
5 Jose Palazzo Moreira de Oliveira
. . .
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
890
Notwithstanding the above, the analysis of only
one returned ranking can not be enough to evaluate
the system quality for this query. Thus, considering
all ten models fitted in cross-validation, the obtained
mean position of this advisor was 5.2, reinforcing the
quality of the recommendation.
To evaluate the general quality of the pro-
posed system, we performed a study considering all
573,671 instances. Table 2 presents the results of the
cross-validation process, achieving a MAP equals to
32.41%, meaning that our system was able to suggest
the correct advisors, on average, in the third position
of the recommended ranking, since 1/3 ≈ 0.3241.
Table 2: Cross-Validation evaluation considering the MAP
metric.
Fold MAP Fold MAP
1 0.3259 6 0.3245
2 0.3266 7 0.3256
3 0.3216 8 0.3223
4 0.3236 9 0.3242
5 0.3239 10 0.3228
Avg. 0.3241
In order to clarify the effectiveness of the method, we
present a graphical analysis of the general obtained
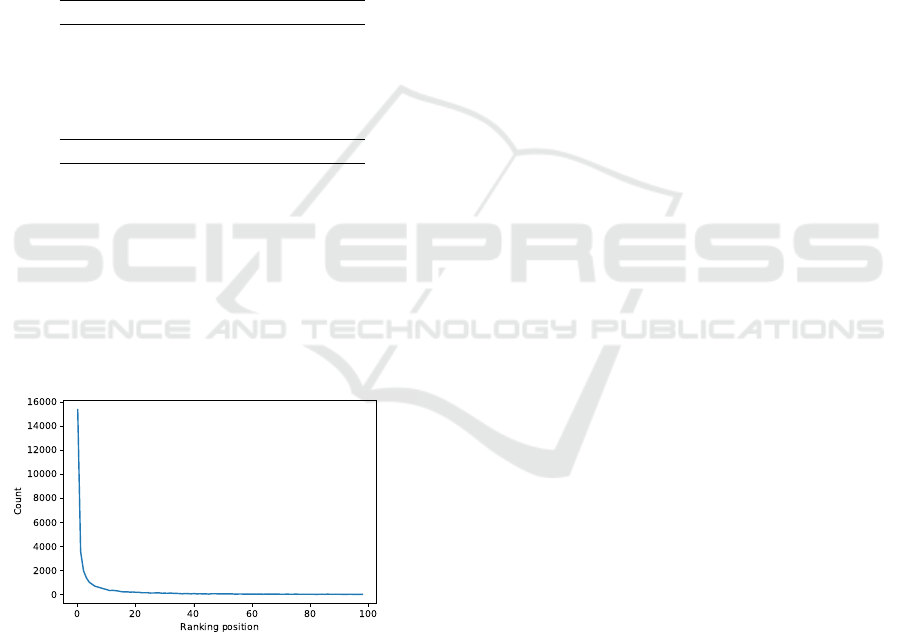
results. Precisely, in Figure 5, we show a histogram
containing the frequency of each position of a correct
advisor returned in the ranking. In this figure, the x
axis represents the first 100 positions of the ranking.
In the y axis, there is the amount of correct recom-
mendations for each position in the x axis.
Figure 5: Number of queries that returned the correct advi-
sor for each position of the ranking.
It can be noted that more than 15,000 queries have
returned a correct advisor in the first position. More-
over, the majority of the queries have returned the ad-
visor at least in the 10th position. After that, we ob-
serve that the system presents a stability. After the
100th position, the recommendations tend to be zero.
6 CONCLUSION
In this work we developed a recommender system that
extracts knowledge from a set of descriptive meta-
data of theses and dissertations. We proposed a novel
content-based recommendation approach for suggest-
ing academic supervisors using academic genealogy
to model their profiles.
Unlike most of the related work, which helps for
finding scientific literature, academic courses, or re-
searchers for collaboration, our system recommends
supervisors for thesis and dissertation proposals. Tak-
ing into account that choosing an adequate advisor
can be a hard task, such system seems to be an im-
portant assisting tool.
Experiments were conducted using realdata from
a repository containing more than 600 thousand the-
ses and dissertations. The evaluation shows that our
system was able to recommend a correct advisor, on
average, in the third position of the suggested ranking.
In future works, we intend to integrate an aca-
demic genealogy tree viewer with the recommender
system in a Web platform. Lastly, additional filters
will be included, such as the location and the univer-
sity acronym.
ACKNOWLEDGMENTS
This study was supported by CAPES Financial
Code 001, PNPD/CAPES (464880/2019-00), CNPq
(301618/2019-4), and FAPERGS (19/2551-0001279-
9, 19/2551-0001660).
REFERENCES
Alarfaj, F., Kruschwitz, U., Hunter, D., and Fox, C. (2012).
Finding the right supervisor: Expert-finding in a uni-
versity domain. In Proceedings of the Conference of
the North American Chapter of the Association for
Computational Linguistics: Human Language Tech-
nologies: Student Research Workshop, NAACL HLT
’12, page 1–6, USA. Association for Computational
Linguistics.
Beel, J., Langer, S., Genzmehr, M., and N
¨
urnberger, A.
(2013). Introducing docear’s research paper rec-
ommender system. In Proceedings of the 13th
ACM/IEEE-CS Joint Conference on Digital Libraries,
JCDL ’13, page 459–460, New York, NY, USA. As-
sociation for Computing Machinery.
Bendakir, N. and A
¨
ımeur, E. (2006). Using association rules
for course recommendation. In Beck, J. E., Aimeur,
E., and Barnes, T., editors, Proceedings of the AAAI
Workshop on Educational Data Mining, pages 1–10,
Palo Alto, California, USA. Association for the Ad-
vancement of Artificial Intelligence.
Using Academic Genealogy for Recommending Supervisors
891

Bobadilla, J., Hernando, A., Ortega, F., and Guti
´
errez, A.
(2012). Collaborative filtering based on significances.
Information Sciences, 185(1):1–17.
Bobadilla, J., Ortega, F., Hernando, A., and Guti
´
errez,
´
A.
(2013). Recommender systems survey. Knowledge-
Based Systems, 46:109–132.
Champiri, Z. D., Shahamiri, S. R., and Salim, S. S. B.
(2015). A systematic review of scholar context-aware
recommender systems. Expert Systems with Applica-
tions, 42(3):1743 – 1758.
Chen, R., Hua, Q., Chang, Y.-S., Wang, B., Zhang, L., and
Kong, X. (2018). A survey of collaborative filtering-
based recommender systems: From traditional meth-
ods to hybrid methods based on social networks. IEEE
Access, 6:64301–64320.
Desrosiers, C. and Karypis, G. (2011). A comprehensive
survey of neighborhood-based recommendation meth-
ods. In Recommender systems handbook, pages 107–
144. Springer, Boston, MA.
Devarakonda, R., Palanisamy, G., Green, J. M., and Wilson,
B. E. (2011). Data sharing and retrieval using oai-
pmh. Earth Science Informatics, 4(1):1–5.
Elbadrawy, A. and Karypis, G. (2016). Domain-aware
grade prediction and top-n course recommendation.
In Proceedings of the 10th ACM Conference on Rec-
ommender Systems, RecSys ’16, page 183–190, New
York, NY, USA. Association for Computing Machin-
ery.
Ge, M., Delgado-Battenfeld, C., and Jannach, D. (2010).
Beyond accuracy: Evaluating recommender systems
by coverage and serendipity. In Proceedings of the
Fourth ACM Conference on Recommender Systems,
RecSys ’10, page 257–260, New York, NY, USA. As-
sociation for Computing Machinery.
Gormley, C. and Tong, Z. (2015). Elasticsearch: the defini-
tive guide: a distributed real-time search and ana-
lytics engine. O’Reilly Media, Inc., Sebastopol, CA,
USA.
Han, E.-H. S. and Karypis, G. (2000). Centroid-based
document classification: Analysis and experimental
results. In European conference on principles of
data mining and knowledge discovery, pages 424–
431, Department of Computer Science / Army HPC
Research CenterUniversity of Minnesota, Minneapo-
lis. Springer.
Hasan, M. A. and Schwartz, D. G. (2018). Recadvisor:
Criteria-based ph.d. supervisor recommendation. In
The 41st International ACM SIGIR Conference on Re-
search & Development in Information Retrieval, SI-
GIR ’18, page 1325–1328, New York, NY, USA. As-
sociation for Computing Machinery.
Husain, O., Salim, N., Alias, R. A., Abdelsalam, S., and
Hassan, A. (2019). Expert finding systems: A sys-
tematic review. Applied Sciences, 9(20):4250.
Karypis, G. (2001). Evaluation of item-based top-n recom-
mendation algorithms. In Proceedings of the Tenth
International Conference on Information and Knowl-
edge Management, CIKM ’01, page 247–254, New
York, NY, USA. ACM.
Krulwich, B. (1997). Lifestyle finder: Intelligent user pro-
filing using large-scale demographic data. AI Maga-
zine, 18(2):37.
Loper, E. and Bird, S. (2002). NLTK: the natural language
toolkit. CoRR, cs.CL/0205028.
Madeira, G., Borges, E. N., Lucca, G., Santos, H., and
Dimuro, G. (2020). A tool for analyzing academic ge-
nealogy. In Filipe, J.,
´
Smiałek, M., Brodsky, A., and
Hammoudi, S., editors, Enterprise Information Sys-
tems, pages 443–456, Cham. Springer International
Publishing.
Manning, C. D., Raghavan, P., and Sch
¨
utze, H. (2008). In-
troduction to information retrieval. Cambridge Uni-
versity Press, Cambridge, England.
Mendonc¸a, F. C., Gasparini., I., Schroeder., R., and Kem-
czinski., A. (2020). Recommender systems based
on scientific publications: A systematic mapping.
In Proceedings of the 22nd International Confer-
ence on Enterprise Information Systems - Volume 1:
ICEIS,, pages 735–742, Set
´
ubal, Portugal. INSTICC,
SciTePress.
O’Mahony, M. P. and Smyth, B. (2007). A recommender
system for on-line course enrolment: An initial study.
In Proceedings of the 2007 ACM Conference on Rec-
ommender Systems, RecSys ’07, page 133–136, New
York, NY, USA. Association for Computing Machin-
ery.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V.,
Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P.,
Weiss, R., Dubourg, V., Vanderplas, J., Passos, A.,
Cournapeau, D., Brucher, M., Perrot, M., and
´
Edouard
Duchesnay (2011). Scikit-learn: Machine learning
in python. Journal of Machine Learning Research,
12(85):2825–2830.
Ray, S. and Marakas, G. (2007). Selecting a doctoral dis-
sertation supervisor: Analytical hierarchy approach to
the multiple criteria problem. International journal of
doctoral studies, 2(1):23–32.
Ricci, F., Rokach, L., and Shapira, B. (2011). Introduc-
tion to recommender systems handbook. In Rec-
ommender systems handbook, pages 1–35. Springer,
Boston, MA.
Rodrigues, M. W., Brand
˜
ao, W. C., and Z
´
arate, L. E.
(2018). Recommending scientific collaboration from
researchgate. In 7th Brazilian Conference on Intelli-
gent Systems (BRACIS), pages 336–341, New York,
NY, USA. IEEE.
Salter, J. and Antonopoulos, N. (2006). Cinemascreen
recommender agent: combining collaborative and
content-based filtering. IEEE Intelligent Systems,
21(1):35–41.
Salton, G. (1968). Automatic Information Organization and
Retrieval. McGraw Hill Text, New York, NY, USA.
Sugimoto, C. R. (2014). Academic genealogy. In Beyond
bibliometrics: Harnessing multidimensional indica-
tors of scholarly impact, pages 365–380. MIT Press,
Cambridge, MA, USA.
Tibshirani, R., Hastie, T., Narasimhan, B., and Chu,
G. (2002). Diagnosis of multiple cancer types by
shrunken centroids of gene expression. Proceedings
of the National Academy of Sciences, 99(10):6567–
6572.
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
892
