
CNN-LSTM-CRF for Aspect-Based Sentiment Analysis:
A Joint Method Applied to French Reviews
Bamba Kane, Ali Jrad, Abderrahman Essebbar, Oph
´
elie Guinaudeau, Valeria Chiesa, Ilhem Qu
´
enel
and St
´
ephane Chau
Research and Innovation Direction, ALTRAN Sophia-Antipolis, France
bamba.kane, ali.jrad, abderrahman.essebbar, ophelie.guinaudeau, valeria.chiesa, ilhem.quenel,
Keywords:
Natural Language Processing (NLP), Aspect-Based Sentiment Analysis (ABSA), Convolutional Neural
Network (CNN), Long Short-Term Memory (LSTM), Conditional Random Field (CRF), SemEval.
Abstract:
Aspect Based Sentiment Analysis (ABSA) aims to detect the different aspects addressed in a text and the
sentiment associated to each of them. There exists a lot of work on this topic for the English language, but
only few models are adapted for French ABSA. In this paper, we propose a new model for ABSA, named CLC,
which combines CNN (Convolutional Neural Network), Bidirectional LSTM (Long Short-Term Memory) and
CRF (Conditional Random Field). We demonstrate herein its great performance on the SemEval2016 French
dataset. We prove that our CLC model outperforms the state-of-the-art models for French ABSA. We also
prove that CLC is well adapted for other languages such as English. One main strength of CLC is its ability
to detect the aspects and the associated sentiments in a joint manner, unlike the state-of-the-art models which
detect them separately.
1 INTRODUCTION
Over the last few years a lot of work has been done
in the field of sentiment analysis (Lin and Luo, 2020).
Most of the work focuses on identifying the sentiment
that is expressed in a text, in a global way by giv-
ing a positive, a negative or a neutral appreciation to
the whole text. However, such a task is sometimes
too coarse. For example, given the following review
on a restaurant, ”the meat was delicious but the price
was exaggerated”, it is quite difficult to highlight an
overall sentiment. Aspect Based Sentiment Analysis
(ABSA) is a sub-domain of Natural Langage Process-
ing (NLP) (Thet et al., 2010) which takes up this chal-
lenge and provides a much finer analysis by identify-
ing the sentiment associated to each aspect evoked in
the text.
In the previous example, ABSA objective is to
detect both the two categories of aspects addressed
in the text (food
quality and food price), and the
sentiment associated to each aspect (positive for
food quality and negative for food price). A word
(or a group of words) denoting an aspect is called
target. In this review, ”the meat was delicious but
the price was exaggerated”, the target for the aspect
food quality is meat, and the one for food price is
price.
ABSA can be split into three tasks (Pontiki et al.,
2016):
• Opinion Target Extraction (OTE): aims to detect
the words that constitute the targets.
• Aspect Category Detection (ACD): focuses on the
detection of the different types of aspects that are
evoked in a text.
• Aspect Sentiment Polarity (ASP): assigns a sen-
timent polarity (positive, negative or neutral) for
each identified aspect.
In this paper, we focus on ACD.
There is an increased interest in ABSA especially
with the dedicated challenges of SemEval (Pontiki
et al., 2016) that offers a framework to define and
evaluate models on different domains. It was initiated
for English language and it is now open to several
other languages such as French or Spanish (Pontiki
et al., 2016).
In order to detect the aspects and the related sen-
timents, many methods have been proposed. In (Kir-
itchenko et al., 2014) the authors use Support Vec-
tor Machine (SVM) for this purpose, while (Hamdan
et al., 2015) use Conditional Random Field (CRF).
Convolutional Neural Networks (CNN) have also
498
Kane, B., Jrad, A., Essebbar, A., Guinaudeau, O., Chiesa, V., Quénel, I. and Chau, S.
CNN-LSTM-CRF for Aspect-Based Sentiment Analysis: A Joint Method Applied to French Reviews.
DOI: 10.5220/0010382604980505
In Proceedings of the 13th International Conference on Agents and Artificial Intelligence (ICAART 2021) - Volume 1, pages 498-505
ISBN: 978-989-758-484-8
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

been widely employed for ABSA (Ruder et al., 2016;
Wu et al., 2016).
However, most of these works focus on English
language and there is only a few work in the litera-
ture for the French language. The lack of linguistic
tools or resources is probably the explanation. Since
the French language has it own characteristics such as
gender for nouns, liaisons, or prepositions which are
very different from English, the existing resources are
not suitable.
In this article, we propose a new model named
CLC which combines a CNN to encode word-level
information into its word-level representation and a
bidirectional Long Short Term Memory (BiLSTM) to
model context information of each word. Finally, we
use a sequential CRF to get the best sequence of as-
pects and the related sentiments. Our proposed ap-
proach leads to three main contributions:
• a new architecture for ABSA, named CLC, allow-
ing to detect the aspects and associated sentiment
in a joint manner;
• better performance than state-of-the-art methods
for ABSA on the French language;
• great performance on English SemEval2016
dataset.
The paper is organized as follows: in section 2, we de-
scribe the state-of-the-art methods for ABSA. In sec-
tion 3, the new model CLC is detailed. In section 4,
the experimentation details are given. We show and
analyze the performance on the SemEval2016 French
dataset about restaurants and we provide a compari-
son with the state-of-the-art methods.
2 STATE OF THE ART
2.1 Aspect Based Sentiment Analysis
(ABSA)
In this section, we present the state-of-the-art meth-
ods for ABSA and then we detail the methods that are
relevant for French language.
2.1.1 Traditional Methods for ABSA
• NRC-Canada: (Kiritchenko et al., 2014) de-
ployed a traditional Support Vector Machine
(SVM)-based model and added some extensive
feature engineering like Part of Speech (POS)
tags, various types of n-grams, and lexicon fea-
tures.
• Rec-NN (Recursive Neural Networks): (Dong
et al., 2014) used, in a first step, rules in order
to get the word related to the aspect at the top of a
dependency tree. Then, the representation of the
sentence towards the aspect was learned by a se-
mantic composition using Recursive Neural Net-
work.
• DDG (Domain Dependency Graph): (Kumar
et al., 2016) used information extracted from de-
pendency graphs learned on different domains and
languages of SemEval2016 and showed very effi-
cient results on different languages (among which
the French language).
The two followings methods participate to the Se-
mEval2016 challenge for French restaurant reviews:
• XRCE: it was the challenge winner for French
language (Brun et al., 2016; Brun and Nikoulina,
2018). Their method was composed by two steps
: 1) Classification process is performed using
the output of a Conditional Random Field (CRF)
which has been specialized at word level on the
available training data (labeled aspects and senti-
ments) in order to classify terms into one or more
aspect categories. 2) At sentence level, the classi-
fication models associate aspect categories of sen-
tences with probabilities. The aspect categories
are then assigned using a threshold over the as-
signed probabilities
• BUTknot (Machacek, 2016): this method got
the second rank for the SemEval2016 challenge
in French. The aspect detection is based on su-
pervised machine learning using bi-grams bag-of-
words model for multi-languages. The perfor-
mance is enhanced by a term substitution tech-
nique. The system has reached a very good per-
formance in comparison with other submitted sys-
tems for the challenge.
2.1.2 Deep Learning Methods for ABSA
Many deep learning architectures are used for ABSA
(Young et al., 2018):
• CNN (Ruder et al., 2016): proposed a method us-
ing multiple filters and obtained competitive re-
sults on both polarity and aspect detection tasks.
(Poria et al., 2016) designed a seven-layer CNN
architecture and made use of both POS tagging
and word embeddings as features.
• MEM-Net (Memory Network): uses the inter-
aspect relations modeling (Tang et al., 2016b).
This method was used on French SemEval2016
datasets.
CNN-LSTM-CRF for Aspect-Based Sentiment Analysis: A Joint Method Applied to French Reviews
499

LSTM for ABSA. The LSTM model has achieved
many great successes in various NLP tasks and par-
ticularly for ABSA. Following, we present different
models for ABSA using LSTM (Tang et al., 2016a):
• TD-LSTM (Target-Dependent LSTM): it defines
the use of LSTM by considering the target. The
BiLSTM network is used to model both the left
and the right context of a target. Then the left and
right target-dependent representations are con-
catenated for predicting the sentiment polarity of
the target.
• TC-LSTM (Target-Connection LSTM): it uses a
BiLSTM for which semantic relatedness of target
with its context words are incorporated. A target
vector is calculated by averaging the vectors of the
words that compose the target. This method has
optimal performance by using a simple average of
the word embeddings of a target.
• BiLSTM-CRF (Chen et al., 2017): it is a combi-
nation of BiLSTM and CRF layers to extract the
targets related to the aspects. (Kooli and Pigneul,
2018) also uses BiLSTM and CRF for aspect ex-
traction but only on French datasets.
Attention Mecanism. Opposite polarities may be
detected when multiple aspects are considered. Thus,
the use of only target information is not sufficient.
The application of an attention mechanism can extract
the association of important words denoting an aspect
(Wang et al., 2016). It allows to capture the key part
of a sentence in relation with a given aspect and to
identify the associated sentiment.
Let us consider the following example: ”The
menu is great but service is a disaster”. For the tar-
get menu, the word great will have a high weight and
for the target service, the word disaster will have a
high weight. Through attention mechanism, the net-
work can learn the association of a positive sentiment
for the menu and and a negative one for the service.
• Attention-based LSTM with Aspect Embed-
ding (ATAE-LSTM): it strengthens the effect of
target embeddings by appending it with each word
embeddings and uses BiLSTM with attention to
get the final representation for the detection of the
aspects and the related sentiments. (Wang et al.,
2016).
• Interactive Attention Network (IAN): (Ma
et al., 2017) uses this model to learn the represen-
tations of the target and its context with BiLSTMs
and attentions interactively, that generates the rep-
resentations for targets and contexts with respect
to each other.
• Attentional Encoder Network (AEN): (Song
et al., 2019) do not use recurrence and employ at-
tention based encoders for modeling context and
aspect.
3 CLC: A NEW ARCHITECTURE
FOR ABSA
In this section, we present our new model: CLC. It
combines CNN, BiLSTM and CRF layers. Here, we
describe each layer of the proposed neural network.
We also motivate our approach and explain why each
layer of the model is used. The global architecture of
the proposed model is illustrated in Figure 4.
3.1 Embedding Layer
Embedding is used to represent each word in a vector
with defined dimensions. The resulting vectors repre-
sent the projections in a continuous vector space. The
position of a word is calculated as a function of the
words in its context. The embedding for a word cor-
responds to the position of this word in the learned
vector space. Nowadays, there are a lot of pre-trained
word embeddings on corpus of millions of words like
Word2Vec, GloVe or Wikipedia2Vec
3.2 CNN
We use CNN layer in order to get a word-level rep-
resentation for each word of a phrase. (Kim, 2014)
proved that a simple CNN gives very good perfor-
mance for text classification with one layer of con-
volution on top of word vectors from an unsupervised
neural language model. (Chiu and Nichols, 2016) also
demonstrated that CNN is efficient for taking into ac-
count some morphological information like suffix or
prefix of a word and encodes it into a neural represen-
tation. Figure 1 shows the different steps we used for
the CNN layer in the CLC model.
3.3 LSTM
LSTM has been proposed to solve the vanish-
ing/exploding gradient problem related to Recurrent
Neural Network (RNN). A LSTM unit is composed of
three gates: input, output and forget which can check
the proportion of information to forget or to keep for
the next step. Figure 2 shows in details a LSTM unit
with its different components.
The formulas for updating a LSTM unit at time t
are:
NLPinAI 2021 - Special Session on Natural Language Processing in Artificial Intelligence
500
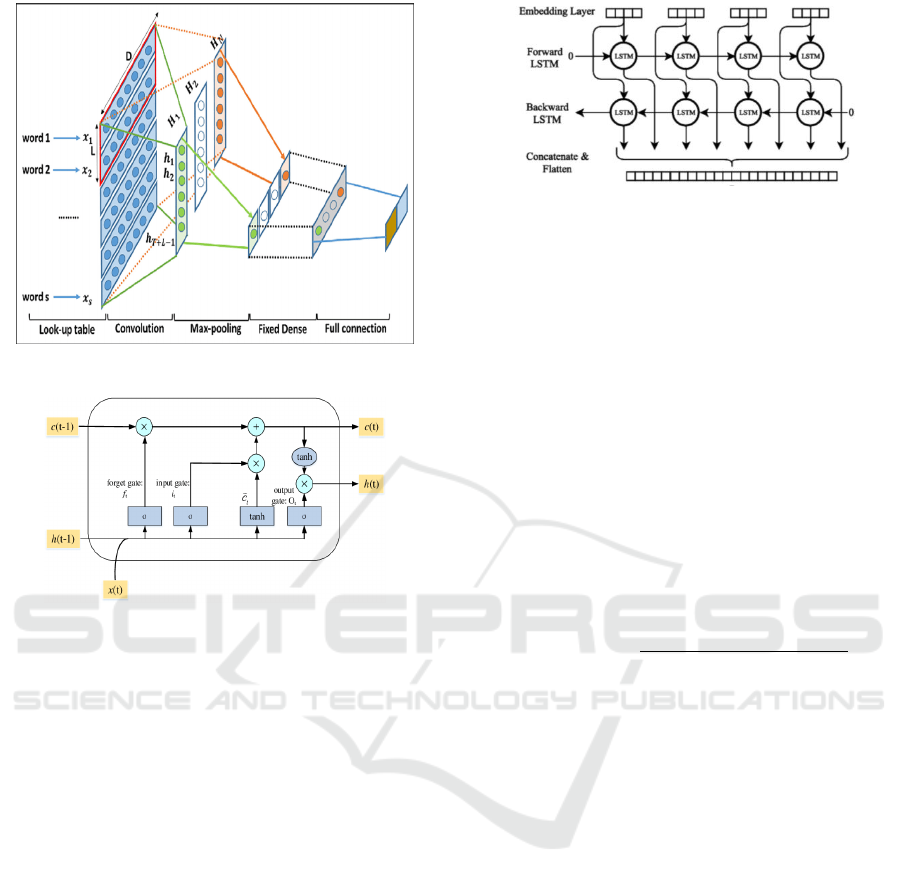
Figure 1: CNN on text (Nguyen et al. 2019).
Figure 2: LSTM unit (Yuan et al. 2019).
i
t
= σ(W
i
h
t−1
+U
i
x
t
+ b
i
)
f
t
= σ(W
f
h
t−1
+U
f
x
t
+ b
f
)
e
c
t
= tan(W
c
ht − 1 +U
c
x
t
+ b
c
)
c
t
= f
t
K
c
t−1
+ i
t
K
e
c
t
o
t
= σ(W
0
h
t−1
+U
0
x
t
+ b
0
)
h
t
= o
t
K
tan(c
t
)
where σ is the element-wise sigmo
¨
ıd function and
J
is the element-wise product. x
t
corresponds to the in-
put vector (like word embedding) at time t, and h
t
is
the hidden state (or output) vector storing all the use-
ful information at (and before) time t. U
i
, U
f
, U
c
, U
o
denote the weight matrices of different gates for in-
put x
t
, and W
i
, W
f
, W
c
, W
o
are the weight matrices for
hidden state h
t
. b
i
, b
f
, b
c
b
o
denote the bias vectors.
BiLSTM consists of two LSTM: one with the in-
put in a forward direction, and the other in a back-
wards direction. BiLSTM allows to fully take into
account the context of each word. Thus, we can learn
the information from context which facilitates the as-
pect detection and the analysis of related sentiments.
Figure 3 shows the BiLSTM architecture.
Figure 3: BiLSTM architecture (from S.Cornegruta and al,
2016.
3.4 CRF
CRF is used in statistical modelling for sequence la-
beling, which can be applied for aspect detection and
ABSA.
The CRF layer with its constraints ensure that the
predicted labels are valid. During the training, these
constraints are learned automatically. Formally, let
z = {z
1
, ..., z
n
} be a phrase with z
i
, the vector for the
i
th
word and y = {y
1
, ..., y
n
} be the generic sequence
of aspects for z. γ(z) constitutes the set of possible
aspects for z. CRF corresponds to a family of condi-
tional probability P(y|z;W ; b) over all possible aspect
sequences y given z and can be formulated as follows:
P(y|z;W ;b) =
∏
n
i=1
ψ
i
(y
i−1
, y
i
, z)
∑
y
0
∈γ(z)
∏
n
i=1
ψ
i
(y
0
i−1
, y
0
i
, z)
where ψ
i
(y
0
, y, z) = exp(W
T
y
0
,y
z
i
+ b
y
0
,y
) are potential
functions, and W
T
y
0
,y
and b
y
0
,y
are the weight vector and
bias corresponding respectively to label pair (y
0
, y).
3.4.1 IOB Tagging
IOB (Inside, Outside, Begin) is a widely used tagging
scheme. The B- tag corresponds to the beginning of
an annotated chunk (target). The I- tag indicates that
the tag is inside a chunk. Only a B- tag (or another I-
tag for n-grams chunks) could precede an I- tag. The
O- tag corresponds to the tokens that do not belong to
any annotated chunks.
We can define the constraints of the CRF layer by
using the IOB scheme. Hence, we can define some
constraints such as:
• the first word of a sentence starts with a B- or an
O- tag, and never with an I- tag;
• an O- tag followed by an I- tag is an invalid se-
quence;
• the first tag for a target is a B- tag and never an I-
tag.
CNN-LSTM-CRF for Aspect-Based Sentiment Analysis: A Joint Method Applied to French Reviews
501
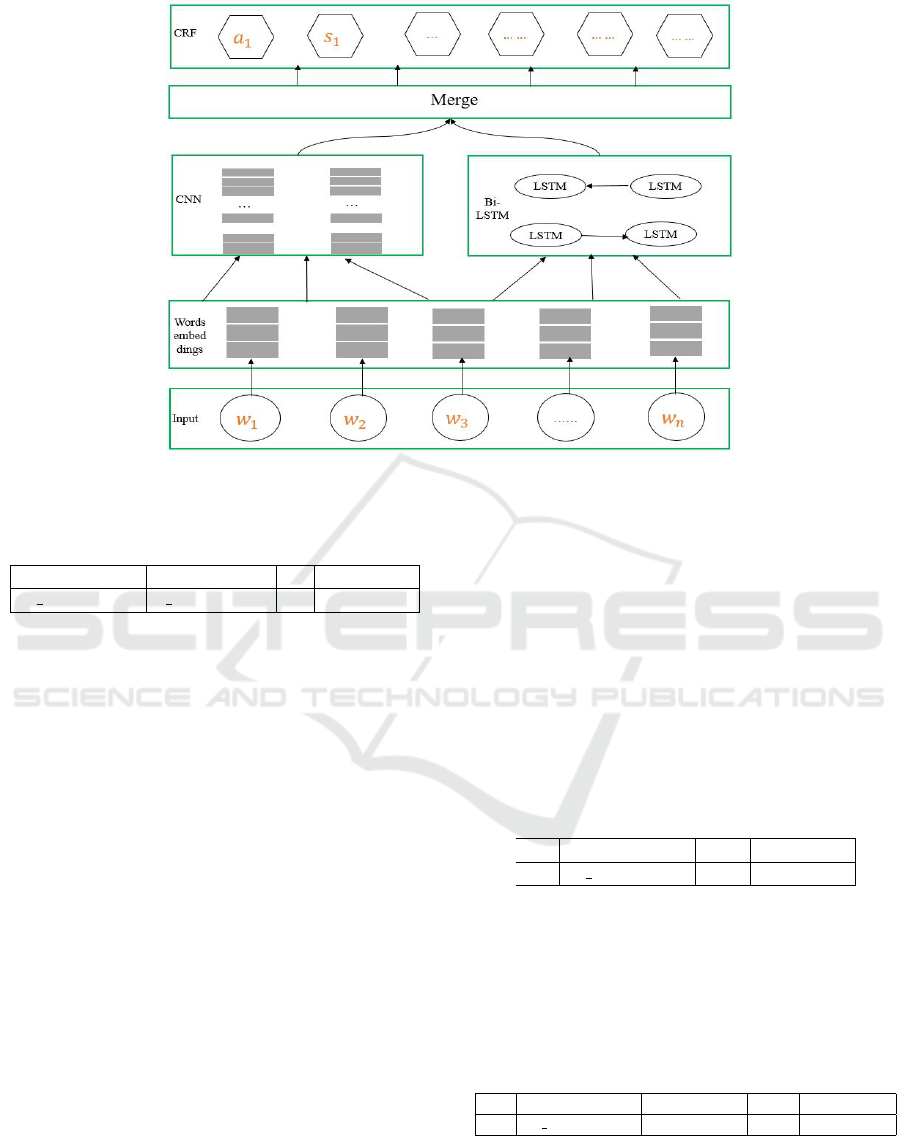
Figure 4: Architecture of CLC. We observe that only the word w
1
denotes an aspect. At the CRF layer, we predict a
1
as the
aspect and s
1
as the associated sentiment.
Table 1: IOB Tagging.
meat price is affordable
B Meal#Price I Meal#Price O O
For example, if the sentence ”meat price is afford-
able” is encoded with the IOB tagging scheme, we
can have this labeling:
We notice in Table 1 that the target meat price is
annotated with a B- and an I- tag for the aspect
Meal#Price. It means that we consider here an unique
target composed of two words and not two distinct tar-
gets (for the aspect Meal#Price).
3.5 Joint Aspect and Sentiment
Detection
Many ABSA models used separate methods for the
two following tasks:
• detection : detecting all the aspects;
• classification : classifying the polarity for each
detected aspect.
In this paper, we propose a joint model able to detect
the aspects and the associated sentiments at the same
time.
Our CLC model is described in Figure 4. As men-
tioned earlier, the CNN layer is an effective approach
to extract morphological information like the prefix or
suffix of a word and encode it into neural representa-
tion. This allows a better word-level representation.
The input used for the CNN layer is the word em-
beddings. Then, the CNN layer acts as a character
embedding. We feed also a BiLSTM layer with the
word embeddings. The output vectors from BiLSTM
and CNN are merged and finally, the merged vectors
are given as input to the CRF layer in order to predict
the aspects and the related sentiments.
Let W and T be the two inputs that we used for
fitting the model: W corresponds to the words and T
to the corresponding tags. In Table 2 we can see an
example of W and T given a customer review.
Table 2: Inputs for an example of a customer review.
W Price was affordable
T B Meal#Price O O
In order to jointly detect aspects and sentiments, we
insert an index for polarity just after the correspond-
ing aspect in W and T and we give these new inputs
to the model for the training (see Table 3). This al-
lows CLC to detect aspects and sentiments at the same
time.
Table 3: Inputs for joint aspect and sentiment detection.
W Price [sentiment] was affordable
T B Meal#Price positive O O
For these new inputs dedicated to joint detection, we
also need to encode the sentiments. Table 4 shows
the encoding we use for positive, negative or neutral
sentiment. If there is n aspects in the dataset, we can
NLPinAI 2021 - Special Session on Natural Language Processing in Artificial Intelligence
502
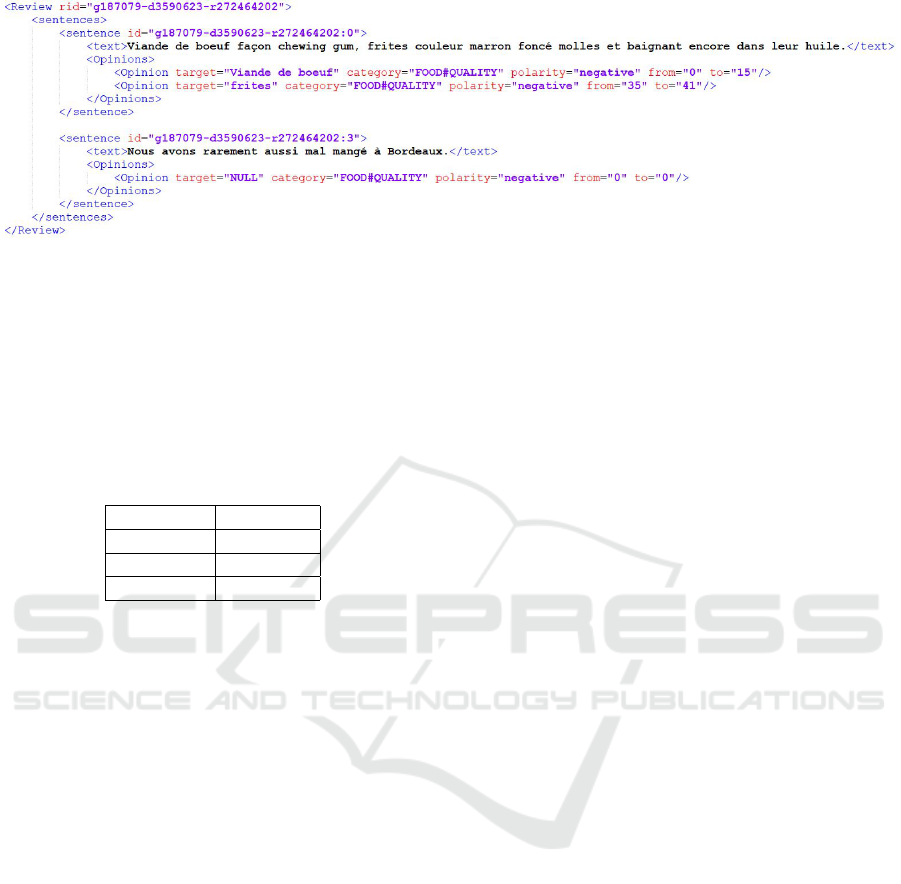
Figure 5: Example of review from French SemEval2016 dataset on restaurants. We note that the aspect is tagged by category.
For implicit aspect the target is NULL, because no words in the sentence is directly referring to the aspect.
observe in table 4 that the positive sentiment is en-
coded by n+1, the negative sentiment is encoded by
n+2 and the neutral one by n+3. It is an arbitrary
choice in order to avoid confusion with the encoding
of the vocabulary words.
Table 4: Encoding of the sentiments for joint detection with
n being the number of aspects.
Sentiment Encoding
positive n + 1
negative n + 2
neutral n + 3
4 EXPERIMENT
In this section, we show how our CLC model is well
adapted for aspect and sentiment detection on French
language. We give details about the dataset we used
and we demonstrate that CLC outperforms the exist-
ing methods for French ABSA.
4.1 SemEval2016 Dataset
French Dataset. In our experiment, we use the
French SemEval2016 annotated dataset about restau-
rants (Apidianaki et al., 2016). It contains 337 re-
views for the training set and 120 reviews for the test
set. The dataset is annotated with targets, aspects and
sentiments (Figure 5). Since each review can be com-
posed of several sentences, the dataset actually con-
tains 1669 annotated sentences for training set and
696 for the test set. It incorporates 12 categories of
aspects and 3 types of sentiments (positive, negative
and neutral). In Figure 5, we give an extract of the
dataset.
English Dataset. In order to confirm that CLC is
adapted for other languages, we also test our model
with a SemEval2016 annotated dataset in English. In
the training set of this dataset, there are 2000 sen-
tences coming from 350 reviews. The test set contains
676 sentences from 90 reviews.
4.2 Training Details
Before training our model we perform some pre-
processing steps such as removing the stop words and
doing lemmatization in order to improve the CLC per-
formance. We use publicly available Wikipedia2Vec
with 300-dimensional embeddings trained on words
from Wikipedia.
For CNN Layer, we used 50 filters with window
length equal to 4. The BiLSTM layer network size is
300.
4.3 Results
Table 5 shows a comparison of our CLC method with
the state-of-the-art models. Since we are interested
in French language, we only consider methods that
give the highest performances on the French SemEval
datasets. We present the F-score for aspect detection
using the French SemEval2016 dataset on restaurants.
Generally, the reference methods only focus on aspect
detection or give separate results for the aspects and
the sentiments.
We can observe in Table 5, that our CLC model
outperforms the state-of-the-art models when we fo-
cus on ACD. Therefore, CLC shows great interest
when it comes to the French language. Thus, CLC
can be used to fill the gap that exists about efficient
methods for aspect detection in French language.
During our study, we observed that using a CRF
layer instead of a softmax activation improves the F-
score from 74.2% to 77.2%. The reason is that the
CRF layer allows to predict the label using neighbour-
ing tagging predictions that eliminates some false pre-
dictions.
As mentioned in section 3.5, our CLC model can
CNN-LSTM-CRF for Aspect-Based Sentiment Analysis: A Joint Method Applied to French Reviews
503

Table 5: Aspect detection Comparison for French SemEval-2016 dataset about restaurants.
F1-Score
(Kumar et al., 2016) 57.8
(Ruder et al., 2016) 61.2
(Brun et al., 2016) 61.2
(Poria et al., 2016) 67.06
(Chen et al., 2017) 73.50
(Kooli and Pigneul, 2018) 70.97
CLC 77.2
also be deployed for joint aspect and sentiment de-
tection. We observe that when we use CLC as a joint
model, the F1-score for the couple (aspect, sentiment)
reaches 88.7%. The reason is that CLC learns well
the correlation between the aspect and the sentiment.
Thus, more aspects are well detected.
CLC Applied on Other Datasets. In order to prove
the generalization capability of CLC, we apply it on
an unseen dataset which is the french SemEval2016
dataset about Museum. The Museum dataset contains
162 french annotated reviews with 668 sentences for
testing. CLC achieves great performances in this con-
text with a a F1-score equal to 69.97%
To prove that CLC is also adapted for English lan-
guage, we tested it on a SemEval2016 English dataset
on restaurants. We achieve in this case great perfor-
mance with a F1-score equal to 80.14% and shows
that our model can be used for ABSA in multiple lan-
guages.
5 CONCLUSION
In this paper we propose a new model named CLC for
ABSA and more precisely for aspect and sentiment
detection.
Several efficient methods have been proposed for
English language in literature. However, only a few
work has been done in French due to the lack of re-
sources. Thus, the main contribution of our work
is that we propose a new model that gives high per-
formance on the French language. CLC is also well
adapted for other language as we proved it for En-
glish.
The strength of the proposed model is its ability to
jointly detect the aspects and the associated sentiment
at the same time and thus fully exploit the correlation
between them.
For the future works, it could be interesting to add
an attention mechanism in CLC which may improve
its performance. There is also a great need to develop
unsupervised models for ABSA to get rid off the de-
pendency on annotations. This would open new per-
spectives to explore since there is a huge amount of
unannotated data available on the web (e.g. customer
reviews on TripAdvisor).
REFERENCES
Apidianaki, M., Tannier, X., and Richart, C. (2016).
Datasets for aspect-based sentiment analysis in
French. In Proceedings of the Tenth International
Conference on Language Resources and Evaluation
(LREC’16).
Brun, C. and Nikoulina, V. (2018). Aspect based sen-
timent analysis into the wild. In Proceedings of
the 9th Workshop on Computational Approaches to
Subjectivity, Sentiment and Social Media Analysis,
WASSA@EMNLP 2018, Brussels, Belgium, October
31, 2018.
Brun, C., Perez, J., and Roux, C. (2016). XRCE at
semeval-2016 task 5: Feedbacked ensemble mod-
eling on syntactico-semantic knowledge for aspect
based sentiment analysis. In Proceedings of the
10th International Workshop on Semantic Evaluation,
SemEval@NAACL-HLT 2016, San Diego, CA, USA,
June 16-17, 2016.
Chen, T., Xu, R., He, Y., and Wang, X. (2017). Improving
sentiment analysis via sentence type classification us-
ing bilstm-crf and CNN. Expert Syst. Appl., 72:221–
230.
Chiu, J. P. C. and Nichols, E. (2016). Named entity recogni-
tion with bidirectional lstm-cnns. Trans. Assoc. Com-
put. Linguistics, 4:357–370.
Dong, L., Wei, F., Tan, C., Tang, D., Zhou, M., and Xu, K.
(2014). Adaptive recursive neural network for target-
dependent twitter sentiment classification. In Pro-
ceedings of the 52nd Annual Meeting of the Associ-
ation for Computational Linguistics, ACL 2014, June
22-27, 2014, Baltimore, MD, USA, Volume 2: Short
Papers.
Hamdan, H., Bellot, P., and B
´
echet, F. (2015). Lsislif:
CRF and logistic regression for opinion target extrac-
tion and sentiment polarity analysis. In Proceedings
of the 9th International Workshop on Semantic Eval-
uation, SemEval@NAACL-HLT 2015, Denver, Col-
orado, USA, June 4-5, 2015.
NLPinAI 2021 - Special Session on Natural Language Processing in Artificial Intelligence
504

Kim, Y. (2014). Convolutional neural networks for sentence
classification. CoRR, abs/1408.5882.
Kiritchenko, S., Zhu, X., Cherry, C., and Mohammad, S.
(2014). Nrc-canada-2014: Detecting aspects and sen-
timent in customer reviews. In Proceedings of the 8th
International Workshop on Semantic Evaluation, Se-
mEval@COLING 2014, Dublin, Ireland, August 23-
24, 2014.
Kooli, N. and Pigneul, E. (2018). Analyse de sentiments
`
a
base d’aspects par combinaison de r
´
eseaux profonds
: application
`
a des avis en franc¸ais (A combination
of deep learning methods for aspect-based sentiment
analysis : application to french reviews). In Actes de la
Conf
´
erence TALN. CORIA-TALN-RJC 2018 - Volume
1, Rennes, France, May 14-18, 2018.
Kumar, A., Kohail, S., Kumar, A., Ekbal, A., and Bie-
mann, C. (2016). IIT-TUDA at semeval-2016 task
5: Beyond sentiment lexicon: Combining domain de-
pendency and distributional semantics features for as-
pect based sentiment analysis. In Proceedings of the
10th International Workshop on Semantic Evaluation,
SemEval@NAACL-HLT 2016, San Diego, CA, USA,
June 16-17, 2016.
Lin, P. and Luo, X. (2020). A survey of sentiment analysis
based on machine learning. In Zhu, X., Zhang, M.,
Hong, Y., and He, R., editors, Natural Language Pro-
cessing and Chinese Computing - 9th CCF Interna-
tional Conference, NLPCC 2020, Zhengzhou, China,
October 14-18, 2020, Proceedings, Part I.
Ma, D., Li, S., Zhang, X., and Wang, H. (2017). Interactive
attention networks for aspect-level sentiment classifi-
cation. In Proceedings of the Twenty-Sixth Interna-
tional Joint Conference on Artificial Intelligence, IJ-
CAI 2017, Melbourne, Australia, August 19-25, 2017.
Machacek, J. (2016). Butknot at semeval-2016 task 5: Su-
pervised machine learning with term substitution ap-
proach in aspect category detection. In Proceedings of
the 10th International Workshop on Semantic Evalu-
ation, SemEval@NAACL-HLT 2016, San Diego, CA,
USA, June 16-17, 2016.
Pontiki, M., Galanis, D., Papageorgiou, H., Androutsopou-
los, I., Manandhar, S., Al-Smadi, M., Al-Ayyoub,
M., Zhao, Y., Qin, B., Clercq, O. D., Hoste, V.,
Apidianaki, M., Tannier, X., Loukachevitch, N. V.,
Kotelnikov, E. V., Bel, N., Zafra, S. M. J., and
Eryigit, G. (2016). Semeval-2016 task 5: Aspect
based sentiment analysis. In Proceedings of the
10th International Workshop on Semantic Evaluation,
SemEval@NAACL-HLT 2016, San Diego, CA, USA,
June 16-17, 2016.
Poria, S., Cambria, E., and Gelbukh, A. F. (2016). Aspect
extraction for opinion mining with a deep convolu-
tional neural network. Knowl. Based Syst., 108:42–
49.
Ruder, S., Ghaffari, P., and Breslin, J. G. (2016). INSIGHT-
1 at semeval-2016 task 5: Deep learning for multilin-
gual aspect-based sentiment analysis. In Proceedings
of the 10th International Workshop on Semantic Eval-
uation, SemEval@NAACL-HLT 2016, San Diego, CA,
USA, June 16-17, 2016.
Song, Y., Wang, J., Jiang, T., Liu, Z., and Rao, Y. (2019).
Attentional encoder network for targeted sentiment
classification. CoRR, abs/1902.09314.
Tang, D., Qin, B., Feng, X., and Liu, T. (2016a). Ef-
fective lstms for target-dependent sentiment classifi-
cation. In COLING 2016, 26th International Con-
ference on Computational Linguistics, Proceedings of
the Conference: Technical Papers, December 11-16,
2016, Osaka, Japan.
Tang, D., Qin, B., and Liu, T. (2016b). Aspect level sen-
timent classification with deep memory network. In
Proceedings of the 2016 Conference on Empirical
Methods in Natural Language Processing, EMNLP
2016, Austin, Texas, USA, November 1-4, 2016.
Thet, T. T., Na, J., and Khoo, C. S. G. (2010). Aspect-
based sentiment analysis of movie reviews on discus-
sion boards. J. Inf. Sci., 36(6):823–848.
Wang, Y., Huang, M., Zhu, X., and Zhao, L. (2016).
Attention-based LSTM for aspect-level sentiment
classification. In Proceedings of the 2016 Conference
on Empirical Methods in Natural Language Process-
ing, EMNLP 2016, Austin, Texas, USA, November 1-4,
2016.
Wu, H., Gu, Y., Sun, S., and Gu, X. (2016). Aspect-
based opinion summarization with convolutional neu-
ral networks. In 2016 International Joint Conference
on Neural Networks, IJCNN 2016, Vancouver, BC,
Canada, July 24-29, 2016, pages 3157–3163. IEEE.
Young, T., Hazarika, D., Poria, S., and Cambria, E. (2018).
Recent trends in deep learning based natural language
processing [review article]. IEEE Comput. Intell.
Mag., 13(3):55–75.
CNN-LSTM-CRF for Aspect-Based Sentiment Analysis: A Joint Method Applied to French Reviews
505
