
NEWRITER: A Text Editor for Boosting Scientific Paper Writing
Jo
˜
ao Ribeiro Bezerra
1
, Lu
´
ıs Fabr
´
ıcio Wanderley G
´
oes
2 a
and Wladmir Cardoso Brand
˜
ao
1 b
1
Department of Computer Science, Pontifical Catholic University of Minas Gerais (PUC Minas), Belo Hozizonte, Brazil
2
Department of Informatics, University of Leicester, Leicester, England, U.K.
Keywords:
Writing Assistance, Language Model, Transformer, BERT, Natural Language Processing.
Abstract:
Nowadays, in the scientific field, text production is required from scientists as means of sharing their research
and contribution to science. Scientific text writing is a task that demands time and formal writing skills and can
be specifically slow and challenging for inexperienced researchers. In addition, scientific texts must be written
in English, follow a specific style and terminology, which can be a difficult task specially for researchers that
aren’t native English speakers or that don’t know the specific writing procedures required by some publisher.
In this article, we propose NEWRITER, a neural network based approach to address scientific text writing
assistance. In particular, it enables users to feed related scientific text as an input to train a scientific-text
base language model into a user-customized, specialized one. Then, the user is presented with real-time text
suggestions as they write their own text. Experimental results show that our user-customized language model
can be effectively used for scientific text writing assistance when compared to state-of-the-art pre-trained
models.
1 INTRODUCTION
Text production is required from scientists as means
of sharing their research and contribution to science.
Scientific text writing is a task that demands time and
formal writing skills. The writing process can be
specifically slow and challenging for inexperienced
researchers, delaying the release of their research re-
sults (Ito et al., 2019). Additionally, most scientific
texts must be written in English, following a spe-
cific style, and using specific terminology to be ac-
cepted for publishing in respectable journals and con-
ferences. This can be a difficult task specially for non
native speakers or those that don’t know the specific
writing procedures required by some publishers, de-
manding extra effort and time.
Considering the importance of text production, the
Natural Language Processing (NLP) area is widely
studied by the scientific community in many appli-
cations to solve some of natural language problems.
Recent advances in NLP come as result of the pro-
posal of Sequence-to-Sequence (seq2seq) language
models and the Transformer architecture (Vaswani
et al., 2017). These model and neural network ar-
chitecture address the text processing as a sequence
a
https://orcid.org/0000-0003-1801-9917
b
https://orcid.org/0000-0002-1523-1616
of words, keeping the context of other words in the
text when processing each singular word. The se-
quences of words are transformed into embeddings
that are processed by the language model (LM) by
using Deep Learning (DL) algorithms. Therefore,
many approaches have been proposed for problems
such as machine translation (Li et al., 2019), text
summarization (Kieuvongngam et al., 2020), speech
recognition (Liu et al., 2020), ancient text restoration
(Assael et al., 2019), and question-answering (Esteva
et al., 2020). These approaches have been successful
in these tasks, even being used in a production envi-
ronment by huge companies, such as Google (Chen
et al., 2019).
A lot of effort is being done into developing tools
for writing assistance. Previous studies show pos-
itive results for this application, such as text auto-
completion based on the user’s writing patterns and
style (Chen et al., 2019) and scientific text writing as-
sistance for non-native English researchers (Ito et al.,
2019). Furthermore, with the proposal of LMs com-
pliant to parallel computing, NLP solutions are be-
coming faster and more reliable. Along with the faster
processing times comes the possibility of develop-
ment of real-time solutions for natural language prob-
lems, such as text writing assistance (Donahue et al.,
2020).
Although a lot of works have been done in the con-
Bezerra, J., Góes, L. and Brandão, W.
NEWRITER: A Text Editor for Boosting Scientific Paper Writing.
DOI: 10.5220/0010350905590566
In Proceedings of the 23rd International Conference on Enterprise Information Systems (ICEIS 2021) - Volume 1, pages 559-566
ISBN: 978-989-758-509-8
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
559
text of writing assistance (Chen et al., 2019; Donahue
et al., 2020), not many of them are focused on scien-
tific writing assistance, such as (Ito et al., 2019). Ad-
ditionally, other studies in this area don’t specifically
focus on real-time text suggestions. Moreover, these
studies don’t account for user customization when it
comes to sub-area specific terms and writing style. In
the subject of scientific writing assistance, the user
should be assisted for faster, higher quality text writ-
ing, while also having compliance with the sub-area’s
specific terms and writing style.
The objective of this article is to propose a neural
network based approach that, given a number of in-
put scientific texts related to a certain area of interest,
generates recommendations to assist the user in the
process of writing scientific text. The expected result
is that the proposed approach makes the writing pro-
cess faster, more intuitive and improves the quality of
the written text. The text suggestions must be compli-
ant with specific terms used in the sub-area the user
is writing for, enabled by user customization. There-
fore, in this article we propose an approach based on
the Transformer language model for real-time scien-
tific text writing assistance. In order to reach this ob-
jective and evaluate the proposed approach, the fol-
lowing specific objectives are posed:
• Train a specialized language model for scientific
texts;
• Propose a learning approach that the user can fine-
tune the language model training by using other
scientific texts as input for customized writing as-
sistance;
• Propose a real-time writing assistant, where the
approach shows text suggestions as the user writes
their text.
In NLP, writing assistance is a topic focused by
many studies. The state-of-the-art techniques such
as seq2seq models and the Transformer architecture
are widely used since their proposal can help solve
many challenges in the area. The Transformer ar-
chitecture fits with the problem addressed in this re-
search because it allows the understanding of lan-
guage patterns. And the addressed problem’s domain
lies on scientific texts, which follow a structured pat-
tern, built with normalized writing patterns and for-
mal terms as a standard. Therefore, the use of NLP,
specially with Transformer language models, shows
great potential in addressing the challenges this arti-
cle proposes to investigate. In addition, the proposed
approach differs from previous works by the fact that
it allows for user customization through input scien-
tific texts, which results in more accurate assistance
in terms of the user’s area of study or in the specific
writing style used in a publication medium.
The remaining of this article is organized as fol-
lows. Section 2 presents theoretical foundation. Sec-
tion 3 presents the related work. Section 4 presents
NEWRITER, our proposed approach. Section 5
presents the methodology, with used methods, met-
rics and tools. Section 6 presents the experimental
setup and results. Section 7 presents the conclusion
and directions for future work.
2 BACKGROUND
The development of novel NLP techniques is crucial
for advances in its applications, such as language un-
derstanding, language modelling and machine trans-
lation. It provides researchers with tools capable of
better language representations that can effectively
learn language, process input faster, and reach more
accurate results. Particularly, this Section is organized
as follows: Section 2.1 describes Word embedding,
Section 2.2 presents the seq2seq model, Section 2.3
presents the Transformer architecture, and Section 2.4
describes the BERT language model.
2.1 Word Embedding
NLP is related to other fields such as machine learn-
ing (ML), and broadly artificial intelligence (AI). Re-
cently, state-of-the-art NLP techniques rely on neu-
ral networks, requiring numerical vector input. Thus,
language models use word embeddings, representa-
tions of words in a vector space. These representa-
tions project the relations between words in form of
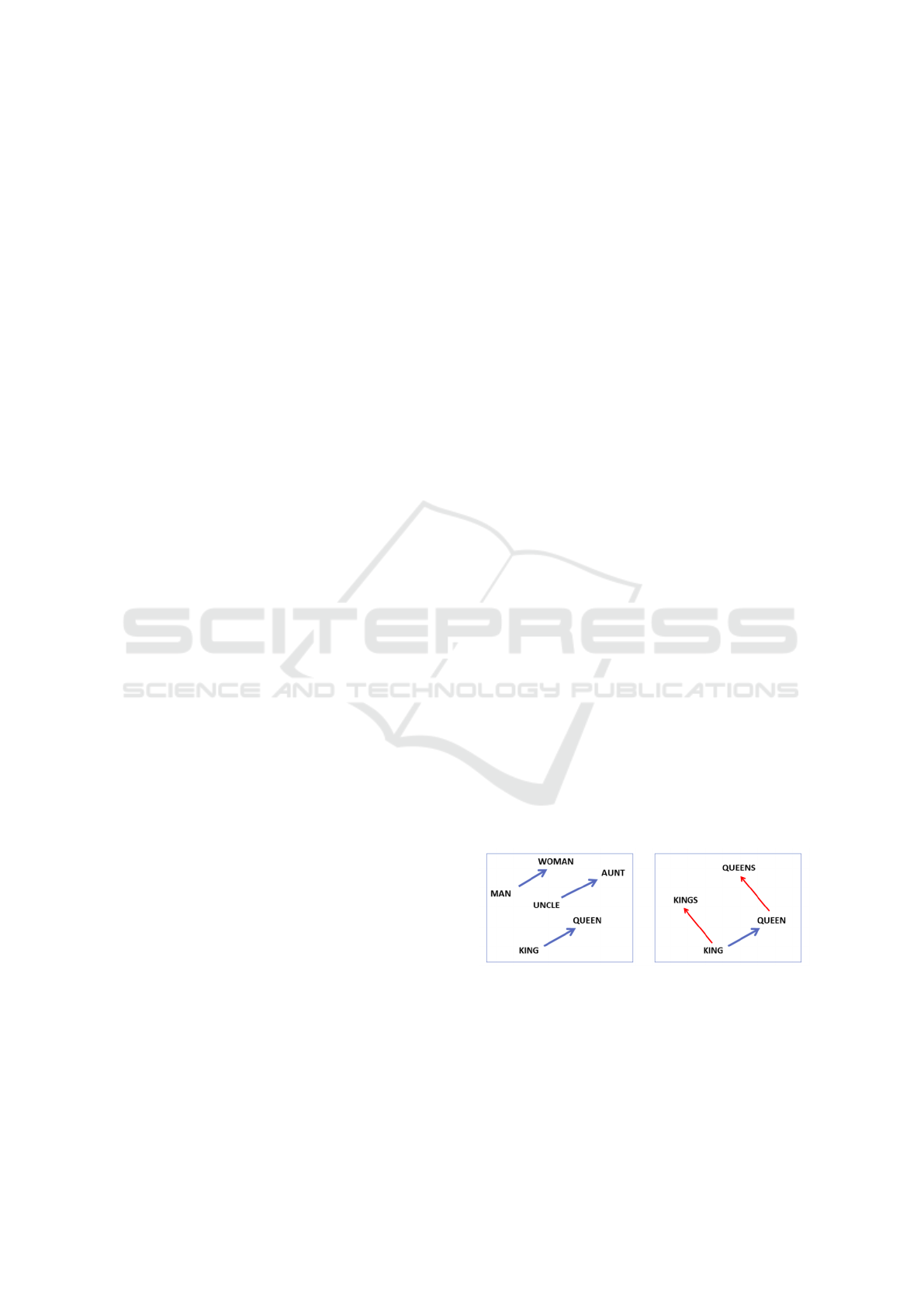
their vector offsets. Figure 1 shows gender relation
between words on the left panel, and singular/plural
relation between words on the right panel (Mikolov
et al., 2013).
Figure 1: Vector offsets in word embeddings. Source:
(Mikolov et al., 2013).
2.2 Sequence-to-Sequence Model
Sequence-to-sequence (seq2seq) are language models
that use recurrent neural network (RNN) to convert
an input sequence into an output sequence, and are
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
560
widely used in NLP since text can be represented as
a sequence of words. A common example of this use
is machine translation, where a sequence of words in
a language is transformed into a sequence of words in
another language.
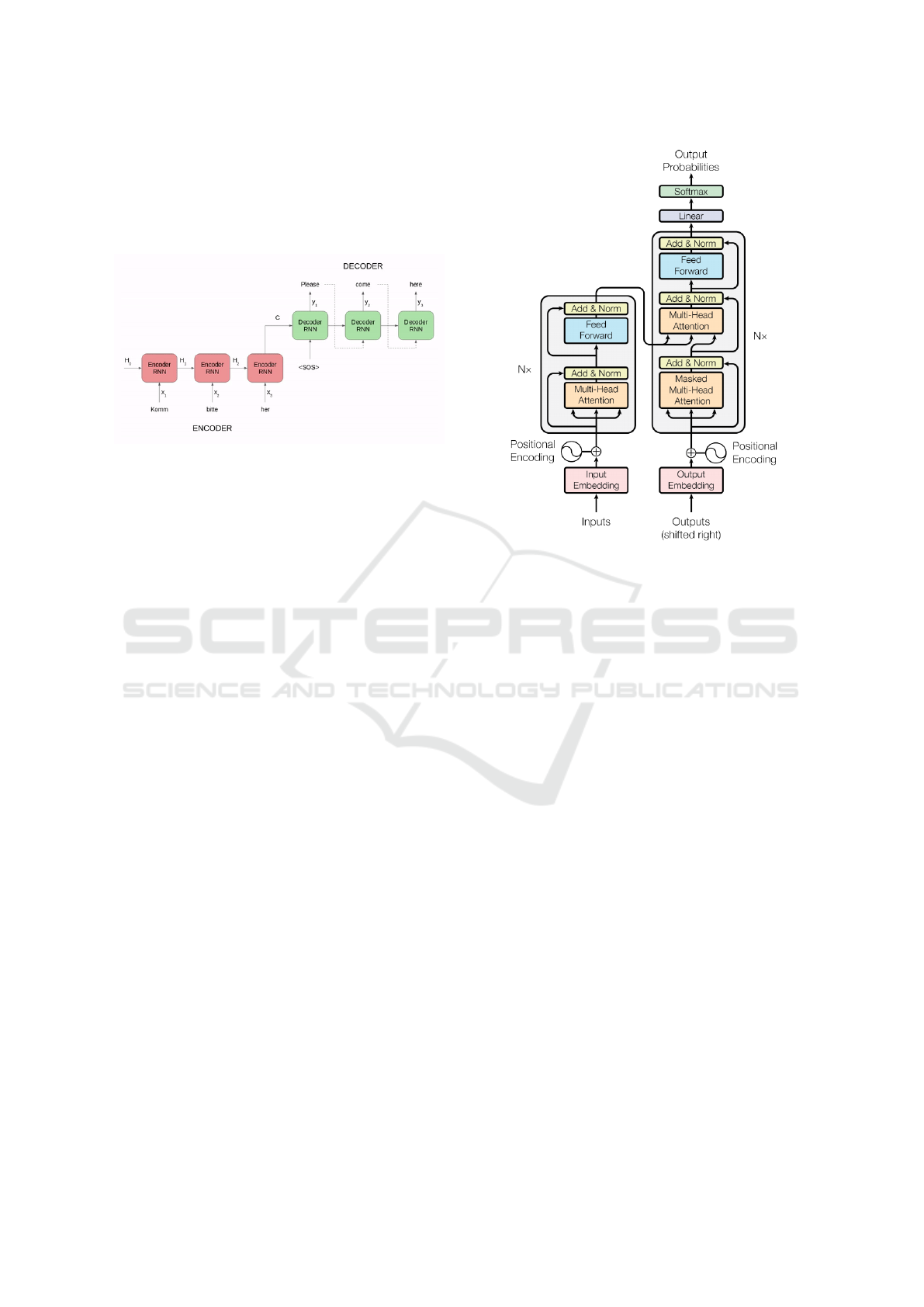
Figure 2: Seq2seq architecture. Source: (Vaswani et al.,
2017).
Figure 2 shows that in seq2seq models’ architecture,
multiple RNNs are created for each word in the input
text (both for encoders and decoders). In Figure 2, x
i
we observe the elements of the word vector and H
i
are
the hidden states that work as a context vector. Words
are processed in order, and the sum of H
i
is passed
from each RNN to the next, in a process known as the
attention mechanism. So the context from previous
words is used in the processing of the current word in
the vector.
Although very robust, the sequential processing
nature of this architecture prevents parallel process-
ing, which limits its use for longer sequences of text.
Another challenge for the use of seq2seq models is the
difficulty for the RNNs to learn from the dependen-
cies originated by long-ranged sequences of words on
the input vector (Vaswani et al., 2017).
2.3 The Transformer Architecture
The Transformer architecture was proposed to solve
the challenges faced by seq2seq architectures, such
as dealing with long-range dependencies. This archi-
tecture can handle dependencies between input and
output using only recurrence and the attention mecha-
nism. Figure 3 presents the Transformer architecture,
with the encoder on its left half and the decoder on its
right half.
From Figure 3 we observe that both the encoder
and the decoder are composed of N = 6 respectively
identical layers. Each of the encoder’s layers has two
sub-layers: a multi-head self-attention mechanism,
and a position-wise fully-connected feed-forward net-
work. Each of the decoder’s layers has, in addition to
the two layers in each encoder layer, a multi-head at-
Figure 3: The Transformer architecture. Source: (Vaswani
et al., 2017).
tention module over the output of the encoder stack.
The multi-head attention modules are formed by a
stack of self-attention modules, an attention mecha-
nism that relates different positions of a sentence in
order to compute a representation of the sequence.
Multi-head attention modules consist of multiple in-
stances of self-attention modules. The self-attention
modules enable the architecture to consider other
words of the input sequence to better understand each
individual word in the sequence. The self-attention
module estimates the importance of each word in the
sequence to the current word. These values are esti-
mated multiple times in the Transformer architecture
in parallel and independently, hence the name multi-
head attention. Figure 4 shows the data flow between
encoders and decoders in the Transformer architec-
ture.
From Figure 4 we observe that first, the word em-
beddings from the input sequence are passed into the
first encoder block. The embeddings are transformed
and passed on to the next encoder, and this process
repeats until the last encoder is reached. The last
encoder outputs the result to all the decoders in the
stack. However, attention modules can only work
with fixed-length strings, meaning the input text must
be subdivided before used as input. This causes con-
text fragmentation, which limits the Transformer ar-
chitecture effectiveness. To overcome this challenge,
the Transformer-XL architecture was proposed (Dai
NEWRITER: A Text Editor for Boosting Scientific Paper Writing
561

Figure 4: Transformer’s encoder and decoder stacks.
Source: (Vaswani et al., 2017).
et al., 2019). In the Transformer-XL architecture, the
hidden states obtained from the previous input frag-
ment from the original text are used in the processing
of the next fragment, thereby causing no context frag-
mentation.
2.4 BERT
The bidirectional encoder representations from Trans-
formers (BERT) is a state-of-the-art language model
proposed by Google AI team that uses pre-training
and fine-tuning for several NLP tasks. It uses a multi-
layer, bidirectional transfer encoder, in which the self-
attention layer works on the input sequence in both
directions.
The BERT model is pre-trained using two differ-
ent strategies: masked language modeling and next
sentence prediction. In masked language modeling,
15% of an original text words are replaced by either
a token ”[MASK]” or a random word and are feeded
for the language model as input. The objective is that
these masked tokens should be predicted by the lan-
guage model. For next sentence prediction, pairs of
sentences are feeded for the language model as input,
where in 50% of pairs the second sentence is the sub-
sequent sequence in the original text, whereas in the
other 50% the second sentence is another random sen-
tence in the text. The objective is to learn and predict
if the second sentence fits as subsequent to the first
sentence in the original text.
In order to gather huge language understanding,
BERT is trained on huge datasets, a process that
demands a lot of time and processing. However,
once a language model is pre-trained, it can be used
for further training in the fine-tuning process. Fine-
tuning enables training a language model for specific
tasks, while also being able to skip the initial training
with the use of knowledge transference (Devlin et al.,
2019).
3 RELATED WORK
Several work were reported in literature for writing
assistance using NLP. Most of them are related to
scientific text writing. The approach proposed by
(Ito et al., 2019) is the most similar to NEWRITER
proposal and domain, focusing on scientific writing
assistance. However, SmartCompose (Chen et al.,
2019), that aims to assist writing of emails, proposes
a learnig mechanism very similar to NEWRITER.
In (Ito et al., 2019) the authors propose sentence-
level revision (SentRev), a writing assistant focused
on surface-level issues such as typographical, spelling
and grammatical errors. Their system focused on
helping inexperienced authors by producing fluent,
complete sentences given their incomplete, rough text
drafts. The authors also released a evaluation dataset
containing incomplete sentences authored by non-
native writers along with their final versions in pub-
lished academic papers that can be used for further
research in this area.
In (Chen et al., 2019) the authors go over de-
tails on the implementation of Gmail’s SmartCom-
pose functionality, that generates interactive, real-
time suggestions to assist users in writing mails. For
the language model selection, they compared state-
of-the art models such as the Transformer architec-
ture and LSTM-based seq2seq models for efficiency
and latency. Upon testing, they chose a LSTM-based
seq2seq model, since even though the Transformer ar-
chitecture had more accurate results, its extra com-
puting time wasn’t ideal for their application as the
model had more latency as it became more complex.
SmartCompose showed high-quality suggestion pre-
diction, enough to be adopted to Google’s platform in
production.
In a similar vein, (Donahue et al., 2020) present
an approach for text infilling for prediction of miss-
ing spans of text at any position in a document. Al-
though the authors cite the potential of masked lan-
guage infilling for writing assistance tools, their re-
search focuses on language modeling, in the form of
infilling text at the end of a document. In this work,
the authors fine-tune language models capable of in-
filling entire sequences on short stories, scientific ab-
stracts and lyrics. A survey showed that humans had
difficulty identifying which sentences were machine-
generated or original sentences in the short stories do-
main.
In (Aye and Kaiser, 2020), the authors propose
a novel design for predicting tokens in real time for
source code auto-completion, combining static analy-
sis for in-scope identifiers with the use of a language
model, in a system that produces valid code with type-
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
562

checking. The developed solution achieves state-of-
art accuracy while also fitting the constraints of real-
world completion implementations in modern IDEs.
In (Shih et al., 2019) the authors propose XL-
Editor, a training framework for state-of-the-art gen-
eralized auto-regressive pre-training methods to re-
vise a given sentence using variable-length insertion
probability in order to reflect the nature of how a hu-
man revisits a sentence to obtain a refined result. The
XL-Editor is able to estimate the probability of insert-
ing a sequence into a specific position of a sentence,
execute post-editing operations and complement ex-
isting sequence-to-sequence models to refine gener-
ated sequences. The authors demonstrated improved
post-editing capabilities from XLNet to XL-Editor.
Additionally, XL-Editor is extended to address post-
editing style transfer tasks and achieves significant
improvement in accuracy, while also maintaining co-
herent semantic.
In (Grangier and Auli, 2018), the authors propose
a framework for computer-assisted text editing, ap-
plied to translation post-editing and to paraphrasing.
In the proposed framework, a human editor modifies a
sentence, marking tokens they would like the system
to change. Their model then generates a new sentence
that reformulates the original sentence by avoiding
the marked words. The model was developed using
sequence-to-sequence modeling along with a neural
network which takes a sentence with change markers
as input. Their model is shown to be advantageous for
translation post-editing through simulated post-edits
and also for paraphrasing through a user study.
In this section one observe that a lot of progress is
being made in the field of NLP with the use of state-
of-the-art language models. These works show that
modern language models are fit for dealing with tasks
related to text writing, writing style learning and re-
production, and text correction. Related work show
that language models are able to work with scientific
text (Ito et al., 2019) and can be used for real-time
writing assistance applications (Chen et al., 2019).
Therefore, the related work also show that the cur-
rent existing approaches can be used in order to ad-
dress the problem on scientific paper writing. How-
ever, none of the related works implement scientific
text language modeling to a real-time writing assis-
tant application, such as NEWRITER.
4 NEWRITER
Upon research reported in the literature, the assistance
in scientific text writing is a widely studied problem.
However, the state-of-the-art NLP approaches can be
used to address this problem. In addition, the avail-
ability of free usage of computing power to accelerate
machine learning applications leads to fast and acces-
sible language model training for user-customized so-
lutions. In this article, we propose NEWRITER, a neu-
ral network based approach to address scientific text
writing assistance. Figure 5 presents the NEWRITER
architecture.
Figure 5: NEWRITER’s architecture.
As shown in Figure 5, initially, the user gathers a
number of scientific articles from their area of study.
These articles are then used in the process of fine-
tuning a base language model in order to customize
it to the user’s needs. The language model used as a
base was SciBERT, as it is a BERT model fine-tuned
using scientific text and accomplishes better results in
this domain than the base BERT model. Using SciB-
ERT as a base language model saves the time needed
to fine-tune a specialized model for scientific text,
which would require gathering a number of scientific
articles and many time for the fine-tuning process.
For the fine-tuning process, the Huggingface’s Trans-
formers library is used, as it implements the needed
methods in an intuitive and easy to use API, and is
widely supported by the community.
In order to make the fine-tuning process faster and
accessible for the end-user, this process is made using
Google Colab. A notebook was created for the user
to be able to input scientific texts in their area of in-
terest. By running the available scripts, the language
model is fine-tuned using the provided texts and the
user can download the resultant customized language
model for use in the writing process. For the writ-
ing assistance, an additional module was developed.
In order to develop a quick, multi-platform interface,
the module was developed using Python 3 and the
prompt toolkit python library. The prompt toolkit
library is used for interfacing with the user via ter-
minal, displaying an input text area, while processing
the text recommendations in a separate thread to not
interrupt the user in the writing process.
As the user writes their text, the module gathers
all text currently in the text area and adds the spe-
cial token ”[MASK]” after the last word. The result-
NEWRITER: A Text Editor for Boosting Scientific Paper Writing
563

ing string is processed using the user-customized lan-
guage model in a fill-mask task, where the language
model returns the top most-appropriate tokens to be
placed over the ”[MASK]” token. For each one of
the five recommendations, a thread is created. Each
thread repeats the same procedure for the language
model input, but only gets the best rated token re-
peatedly until the generated string reaches a specific
length or is a punctuation mark. Finally, it picks the
five best rated next tokens as a 5-way recommenda-
tion route and extends each route to generate a bet-
ter context for the user to pick from. This process is
done in order to provide the user with multiple possi-
ble routes to continue writing the current sentence.
5 METHODOLOGY
In this section, one present experimental setup and
tools used to develop and evaluate a proper scien-
tific text writing assistant. Therefore, Section 5.1
presents the tools that were used for the development
of the scientific text writing assistant and Section 5.2
presents the methods and metrics used in this article.
5.1 Tools
This study’s objective is to generate recommendations
to assist a user in the process of writing scientific
text. For this objective’s accomplishment, a base pre-
trained language model was selected, a module was
developed for the model to be further fine-tuned, and
another module was developed for the user to be able
to write with the assistance provided by the language
model. In the following sections, one present the tools
used in this article. Section 5.1.1 presents the SciB-
ERT language model, Section 5.1.2 presents Hug-
gingFace’s Transformers library, and Section 5.1.3
presents Google Colaboratory.
5.1.1 SciBERT Language Model
In order do address the lack of high-quality, large-
scale labeled scientific language models, SciBERT
was proposed by (Beltagy et al., 2019). SciBERT is
a BERT-based model trained on scientific text on a
large multi-domain corpus of scientific publications,
aimed to improve the usage of NLP in the scientific
text domain. SciBERT is trained on 1.14M papers
from Semantic Scholar
1
and contains its own vocabu-
lary (scivocab) with 3.1B tokens. Compared to BERT,
SciBERT shows better results on scientific domain
NLP tasks.
1
http://www.semanticscholar.org
5.1.2 HuggingFace’s Transformers Library
HuggingFace’s Transformers (Wolf et al., 2019) is a
library created to gather several state-of-the-art lan-
guage models and architectures into an unified API
along with examples, tutorials and scripts, for use by
the community.
The library contains implementations of state-
of-the-art architectures such as BERT, GPT-2,
RoBERTa, XLM, DistilBert, among others. There
are thousands of pre-trained models available in more
than 100 languages with community-contributed
models available online. It also has interoperability
between PyTorch and TensorFlow 2.0, tools widely
used for NLP tasks. The library is highly adopted
among both the researcher and practitioner commu-
nities.
5.1.3 Google Colaboratory
Google Colaboratory,also referred simply as Colab, is
a cloud service provided by Google based on Jupyter
Notebooks, used for education and research on ma-
chine learning. It provides free access to a GPU suit-
able for deep learning. The research from (Pessoa
et al., 2018) shows the service can be used to suc-
cessfully accelerate not only deep learning applica-
tions but also other classes of GPU-centric applica-
tions. Experimental results show faster training of a
convolutional neural network on Colaboratory’s run-
time than using 20 physical cores on a Linux server.
5.2 Methods and Metrics
The perplexity metric is commonly used to evaluate
the quality of a trained language model. It measures
the effectiveness of a probability model, such as a lan-
guage model, in predicting a given sample. It allows
the comparison of language models, with a low per-
plexity value indicating that a language model is bet-
ter suited at predicting the given sample. Equation 1
shows how perplexity p is estimated given a proba-
bility model q, for N test samples and b is a constant,
usually set to 2 (Brown et al., 1992).
p = b
−
1
N
∑
N
i=1
log
b
q(x
i
)
(1)
A comparison between SciBERT and a customized
language model was made to evaluate the quality of
the user-customized language model’s recommenda-
tions. A synthetic use-case was used for compari-
son of the language models, using a 10-fold cross-
validation based on their perplexity metric to an input
sample. In a k-fold cross-validation, the input sample
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
564

is equally partitioned into k sub-samples. For k itera-
tions, k
i
is used as a test sample while the other k − 1
parts are used as training samples. Then, the results
of the k tests are averaged for a single estimation re-
sult. The most used value for k is 10, also referred
as a 10-fold cross-validation. The selected area of in-
terest for the test was NLP, particularly scientific text
writing assistance.
6 EXPERIMENTAL RESULTS
Table 1 presents the 10-fold cross-validation test.
Even with the small provided input, the user-
customized language model shows to be more than
3% better suited for the task, as shown in the improve-
ment column. The training process took, in average,
25 seconds, which is compliant for a one-time pre-
processing for using the writing software.
Table 1: Perplexity comparison between the user-
customized language model and SciBERT for specific do-
main scientific text.
Fold User LM SciBERT Improvement
Fold 1 5.10 5.19 0.02
Fold 2 5.73 5.80 0.01
Fold 3 4.33 4.42 0.02
Fold 4 5.81 5.89 0.01
Fold 5 4.54 4.60 0.01
Fold 6 9.11 9.55 0.05
Fold 7 13.37 13.80 0.03
Fold 8 8.85 9.11 0.03
Fold 9 12.68 13.32 0.05
Fold 10 12.82 13.26 0.03
Average 8.23 8.49 0.03
Figure 6 shows an example of the writing approac’s
usage in three sequential moments. As the user
writes their text, NEWRITER displays possible writ-
ing routes, highly related to the current context. Addi-
tionally, the recommended string is highly related to
the domain addressed in the scientific texts used for
the language model fine-tuning.
Figure 7 presents two cases where the language
model was capable of memorizing and displaying
acronyms for terms used in the natural language area,
along with correct parenthesis and punctuation usage.
The displayed recommendations show multiple
options for the next word in real-time, and progres-
sively extend upon the recommended writing routes
in the following few seconds, without interrupting the
user interaction for the text area. In cases where the
recommendations might not be accurate, which can
happen specially for recommendation paths starting
Figure 6: NEWRITER’s writing software example 1.
Source: Author.
Figure 7: NEWRITER’s writing software example 2.
Source: Author.
from a lower score, it does not affect the final user ex-
perience, as the final text is curated by the user. Even
if the recommendation itself makes sense only to a
certain point, it still helps users with idiomatic expres-
sions or connectives to link words together in the text
and make the writing process flow better.
7 CONCLUSION
The scientific text domain can be more welcoming
for beginner researchers and for non-native English
speakers, and the accomplishments in this article
show that the existing NLP approaches can be used to
reach this objective. Experimental results show that
user-customized language models can be used to im-
prove the effectiveness of scientific text writing assis-
tance compared to state-of-the-art pre-trained models.
NEWRITER presents a proof of concept for real-time
writing assistance using customized, user-trained lan-
guage models. However, there are still more parame-
ters to explore for the language model fine-tuning and
other ways the user could be assisted in the writing
process.
For future work, the language model fine-tuning
process can be further tested and asserted, and the
tool’s interface can be improved. The recommenda-
tions could be made to select better words and expres-
sions in the middle of the text, as it would explore the
bidirecionality of the BERT model. Additionally, as
the perplexity tends to reach lower values, texts writ-
ten using NEWRITER will tend to become repetitive
and the tool could also promote what could be consid-
NEWRITER: A Text Editor for Boosting Scientific Paper Writing
565

ered plagiarism. Therefore, NEWRITER’s architec-
ture could be extended to implement a Computational
Creativity module. Finally, the tool should be tested
with real users - scientists, writing scientific text - to
answer a survey to assert the utility of the developed
tool.
ACKNOWLEDGEMENTS
The present work was carried out with the support
of the Coordenac¸
˜
ao de Aperfeic¸oamento de Pessoal
de N
´
ıvel Superior - Brazil (CAPES) - Financing
Code 001. The authors thank the partial support of
the CNPq (Brazilian National Council for Scientific
and Technological Development), FAPEMIG (Foun-
dation for Research and Scientific and Technological
Development of Minas Gerais), and PUC Minas.
REFERENCES
Assael, Y., Sommerschield, T., and Prag, J. (2019). Restor-
ing ancient text using deep learning: a case study on
greek epigraphy. In Proceedings of the 9th Interna-
tional Joint Conference on Natural Language Pro-
cessing, IJCNLP’19, pages 6368–6375.
Aye, G. A. and Kaiser, G. E. (2020). Sequence model de-
sign for code completion in the modern IDE. CoRR,
abs/2004.05249.
Beltagy, I., Lo, K., and Cohan, A. (2019). SciBERT: Pre-
trained language model for scientific text. In Proceed-
ings of the 9th International Joint Conference on Nat-
ural Language Processing, IJCNLP’19, pages 3615–
3620.
Brown, P., Della Pietra, S., Pietra, V., Lai, J., and Mercer, R.
(1992). An estimate of an upper bound for the entropy
of english. Computational Linguistics, 18:31–40.
Chen, M. X., Lee, B. N., Bansal, G., Cao, Y., Zhang, S.,
Lu, J., Tsay, J., Wang, Y., Dai, A. M., Chen, Z.,
Sohn, T., and Wu, Y. (2019). Gmail smart com-
pose: Real-time assisted writing. In Proceedings of
the 25th ACM SIGKDD International Conference on
Knowledge Discovery & Data Mining, KDD ’19, page
2287–2295.
Dai, Z., Yang, Z., Yang, Y., Carbonell, J. G., Le, Q. V.,
and Salakhutdinov, R. (2019). Transformer-XL: At-
tentive language models beyond a fixed-length con-
text. CoRR, abs/1901.02860.
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K.
(2019). BERT: Pre-training of deep bidirectional
Transformers for language understanding. CoRR,
abs/1810.04805.
Donahue, C., Lee, M., and Liang, P. (2020). En-
abling language models to fill in the blanks. ArXiv,
abs/2005.05339.
Esteva, A., Kale, A., Paulus, R., Hashimoto, K., Yin,
W., Radev, D., and Socher, R. (2020). CO-
Search: COVID-19 information retrieval with seman-
tic search, question answering, and abstractive sum-
marization. CoRR, abs/2006.09595.
Grangier, D. and Auli, M. (2018). QuickEdit: Editing text
& translations by crossing words out. In Proceed-
ings of the 2018 Conference of the North American
Chapter of the Association for Computational Lin-
guistics: Human Language Technologies, NAACL-
HLT’18, pages 272–282.
Ito, T., Kuribayashi, T., Kobayashi, H., Brassard, A., Hagi-
wara, M., Suzuki, J., and Inui, K. (2019). Diamonds
in the rough: Generating fluent sentences from early-
stage drafts for academic writing assistance. In Pro-
ceedings of the 12th International Conference on Nat-
ural Language Generation, INLG’19, pages 40–53.
Kieuvongngam, V., Tan, B., and Niu, Y. (2020). Au-
tomatic text summarization of COVID-19 medical
research articles using BERT and GPT-2. CoRR,
abs/2006.01997.
Li, L., Jiang, X., and Liu, Q. (2019). Pretrained language
models for document-level neural machine transla-
tion. CoRR, abs/1911.03110.
Liu, C., Zhu, S., Zhao, Z., Cao, R., Chen, L., and Yu, K.
(2020). Jointly encoding word confusion network and
dialogue context with BERT for spoken language un-
derstanding. CoRR, abs/2005.11640.
Mikolov, T., Yih, W.-t., and Zweig, G. (2013). Linguis-
tic regularities in continuous space word representa-
tions. In Proceedings of the 2013 Conference of the
North American Chapter of the Association for Com-
putational Linguistics: Human Language Technolo-
gies, NAACL-HLT’13, pages 746–751.
Pessoa, T., Medeiros, R., Nepomuceno, T., Bian, G.-B., Al-
buquerque, V., and Filho, P. P. (2018). Performance
analysis of Google Colaboratory as a tool for acceler-
ating deep learning applications. IEEE Access, PP:1–
1.
Shih, Y.-S., Chang, W.-C., and Yang, Y. (2019). XL-
Editor: Post-editing sentences with xlnet. CoRR,
abs/1910.10479.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones,
L., Gomez, A. N., Kaiser, L. u., and Polosukhin,
I. (2017). Attention is all you need. In Guyon,
I., Luxburg, U. V., Bengio, S., Wallach, H., Fer-
gus, R., Vishwanathan, S., and Garnett, R., editors,
Advances in Neural Information Processing Systems,
volume 30, pages 5998–6008.
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C.,
Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M.,
and Brew, J. (2019). HuggingFace’s Transformers:
State-of-the-art natural language processing. CoRR,
abs/1910.03771.
ICEIS 2021 - 23rd International Conference on Enterprise Information Systems
566
