
Multi-feature and Modular Pedestrian Intention Prediction using a
Monocular Camera
Mostafa Waleed and Amr EL Mougy
German University in Cairo, Cairo, Egypt
Keywords:
Intention Prediction, Autonomous Vehicles, Advanced Driver Assistance System.
Abstract:
Accurate prediction of the intention of pedestrians to cross the path of vehicles is highly important to ensure
their safety. The accuracy of these intention prediction systems is dependent on the recognition of several
pedestrian-related features such as body pose, head pose, pedestrian speed, and passing direction, as well as
accurate analysis of the developing traffic situation. Previous research efforts often focus only on a subset
of these features, therefore producing inaccurate or incomplete results. Accordingly, this paper presents a
comprehensive model for pedestrian intention prediction that incorporates the recognition of all the above
features. We also adopt the Constant Velocity Model to estimate the future positions of pedestrians as early
as possible. Our model includes a reasoning engine that produces a decision based on the output of the
recognition systems of all the aforementioned features. We also consider occlusion scenarios that happen when
multiple pedestrians are crossing simultaneously from the same or different directions. Our model is tested on
well-known datasets as well as a real autonomous vehicle, and the results show high accuracy in predicting
the intention of pedestrians in different scenarios, including ones with occlusion among pedestrians.
1 INTRODUCTION
According to the World Health Organization (who, 7
30), nearly 1.35 million people die each year and 20-
50 million people are injured as a result of road traffic
accidents. More than half of all road traffic deaths are
among vulnerable road users: pedestrians, cyclists,
and motorcyclists.
Autonomous vehicles will have to consider the
random actions of pedestrians to ensure their safety.
Accordingly, the research community has been ac-
tively investigating methods of predicting as early and
accurately as possible the intention of the pedestrian
to cross the path of the vehicle. To achieve this objec-
tive, researchers have developed recognition systems
for several pedestrian features to predict whether or
not a pedestrian intends to cross. For example, body
pose is used to detect the readiness of pedestrians to
cross, head pose is used to detect if a pedestrian is
aware of the incoming traffic, pedestrian direction and
speed are used to detect if the path of a pedestrian will
cross that of the vehicle.
Even though the existing recognition systems may
be able to detect the above features accurately, inten-
tion prediction systems that are built on top of these
recognition systems often fail to produce accurate re-
sults. This is mainly because considering only a sub-
set of these features may not fully capture the inten-
tion of the pedestrian to cross.
Therefore, this paper presents a comprehensive
pedestrian intention prediction model that simulta-
neously considers all the aforementioned features.
We utilize computer vision and machine learning ap-
proaches for the recognition of each feature indepen-
dently, and propose a weighted reasoning engine that
combines the output of all the recognition modules
to produce a prediction of the pedestrian’s intention.
In this reasoning engine, we specify proper weights
that should be give to the output of each recognition
module, according to its contribution to the intention
prediction process. In addition, we address a critical
challenge in the intention prediction which is the oc-
clusion of pedestrians when there is more than one
of them crossing. We propose a technique of frame
analysis to detect occlusion and re-identify the pedes-
trians as the occlusion fades. In order to evaluate
our approach, we test it in three different environ-
ments. First we evaluate our approach on our pro-
posed dataset then we used KITTI dataset (Geiger
et al., 2013) for more test cases. Finally we used
our modified autonomous golf cart to evaluate our ap-
proach. Our proposed model shows promising results
1160
Waleed, M. and El Mougy, A.
Multi-feature and Modular Pedestrian Intention Prediction using a Monocular Camera.
DOI: 10.5220/0010337711601167
In Proceedings of the 13th International Conference on Agents and Artificial Intelligence (ICAART 2021) - Volume 2, pages 1160-1167
ISBN: 978-989-758-484-8
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

in all cases. The remaining sections of this paper are
organized as follows. Section 2 reviews pertaining
research efforts. Section 3 offers the full details of
our proposed model. Section 4 shows the results of
the performance evaluation, while Section 5 provides
concluding remarks.
2 RELATED WORK
In this section we discuss the main recent contri-
butions in pedestrian intention prediction. The au-
thors of (Joon-Young Kwak, 2017) propose a dy-
namic fuzzy automata (DFA) method for pedestrian
intention and use low-level features with a boosted-
type random forest classifier for pedestrian detection
and tracking. To consider the pedestrian character-
istics they use the pedestrian’s distance from curb ,
pedestrian’s speed and the direction of his/her head.
Four pedestrian intention states are defined, two of
them represent that the pedestrian is not passing, and
the other two represent that the pedestrian is pass-
ing. This approach has 9 FPS processing time which
is not sufficient for real time applications. In an-
other paper, Sebastian Kohler et al.(S. K
¨
ohler and Di-
etmayer, 2012) show that the sub-region of the im-
age that covers the pedestrian within its bounding
box is available for a time series, e.g. by the fusion
of LIDAR and video-data and a HOG-based detec-
tion. The methodology of their approach is to gen-
erate the motion descriptors within this box and to
classify the motion. This approach was tested on lab
conditions so it wasn’t proven yet it’s efficiency in
real time applications. Gurkan Solmaz et al.(Solmaz
et al., 2019) propose the use of Internet Of Things
(IOT) technology where the pedestrian next location
is predicted based on his/ her historical data and cur-
rent position. Both the pedestrian GPS position and
velocity are obtained using a mobile device to pre-
dict the pedestrian’s next position using a trajectory
model. This approach assumes that all the pedestri-
ans are using a 4G mobile device and that pedestri-
ans are always walking in the same direction, which
is not the case. Christoph Scholler et al.(C. Sch
¨
oller
and Knoll, 2020) used a simple constant velocity
model(CVM) to predict the pedestrian intention that
does not require any information besides the pedes-
trian’s last relative motion. They denote the position
(x
t
i
,y
t
i
) of pedestrian i at time-step t as P
t
i
. The goal
of pedestrian motion prediction is to predict the fu-
ture trajectory Ti = (P
t
i+1
,. . . ..,P
i
t+n
) for pedestrian
i, taking into account his or her own motion history
H
i
= (p
0
i
,. . . ., p
t
i
).The constant velocity model ap-
proach mispredict the pedestrian intention if he/she
suddenly change his/her walking direction. In (Re-
hder et al., 2018), the authors propose a different ap-
proach that relies on predicting pedestrian intention
using goal directed planning. They use a mixture
density function for possible destinations. They use
these set of destinations as the goal states of a plan-
ning stage that predict the motion of the pedestrian
based on the common motion patterns that are already
known. Those patterns are learned by a fully convolu-
tional network operating on the maps on the environ-
ment. R. Quintero et al .(Quintero et al., 2014) con-
sidered the three-dimensional pedestrian body lan-
guage in order to perform path prediction in a prob-
abilistic framework. For this purpose, the different
body parts and joints are detected using stereo Vision.
The body pose algorithm they use predict the input as
a point cloud on one pedestrian that has been previ-
ously extracted from the general point cloud provided
by the stereo images pair. Let P = {p
1
,..., p
N
} repre-
sent the pedestrian point cloud with N points.The re-
cursive nature of the algorithm limits the accuracy of
a body part on the accuracy of the previous part. If a
part is incorrectly detected all following parts will be
affected. In our proposed approach we overcame all
the mentioned limitations by using multi features in
order to ensure the prediction results and we consid-
ered the processing time to be able to fit our approach
in real time applications.
3 INTENTION PREDICTION
MODEL
Our system architecture consists of several stages.
First, a frame captured by the monocular camera acts
as input to our system. Then, the human detection
model and the head pose model use the captured
frame as an input. The output for the human detec-
tion model is a bounding box for each pedestrian in
the frame which is used as the current location for the
pedestrian while the head pose model output the head
orientation for all the pedestrians. The frame with
bounding boxes after pre-processing act as input for
the body pose estimation model and constant velocity
model while the bounding box points are used to de-
tect the pedestrian direction and the side from which
the pedestrian will pass. Also the pedestrian position
is used to detect their moving speed. The output of the
system is the person’s future position predicted using
the constant velocity model and the person’s intention
as ”passing” or ”Not passing”.
Multi-feature and Modular Pedestrian Intention Prediction using a Monocular Camera
1161

3.1 Pedestrian Detection
For pedestrian detection, we use real-time object
detection model YOLO proposed in (Redmon and
Farhadi, 2018). The input for YOLO v3 is a (720
x 1280 x 3) frame and the output is a (720 x 1280
x 3) frame where a bounding box marks each per-
son in the frame in 2D space which is in form of
(x,y,width,height) for each pedestrian. The position
of pedestrian n is defined as {CenterX
n
,CenterY
n
}
where CenterX
n
= x
n
+ (w
n
/2) and CenterY
n
= y
n
+
(h
n
/2)
3.2 Pedestrian Tracking
After detecting the pedestrians, we need to track them
through the frames as we need the pedestrian his-
tory to be able to predict his/her next move. So, to
track the pedestrian n between two frames at time t-
1 and t we calculate the Euclidean distance between
the center of the pedestrian Center
t−1
n
at t-1 and all
the appearing centers of pedestrians at time t. So,
we have the centers of the pedestrians at time t as
{Center
t
1
,.....,Center
t
n
}. Thus, to match pedestrian n
between two frames we use the following equation:
min
q
(|CenterX
t
n
−CenterX
t−1
S
|)
2
+ (|CenterY
t
n
−CenterY
t−1
S
|)
2
1 6 S 6 N
(1)
A problem was encountered that when occlusion oc-
curs between pedestrians our tracking technique mis-
matches those pedestrians. Accordingly , when a
pedestrian is not detected for one or more frames we
match the lost pedestrian based on the body features
(e.g. body height , body width ) and passing direction,
not only the euclidean distance.
3.3 Features Extraction
3.3.1 Pedestrian Passing Direction (PPD)
The PPD provides a meaningful cue for prediction of
pedestrian intention. If the pedestrian is on the right
side he/she needs to move in the negative direction of
X axis as shown in Fig.1 to cross through the car path.
PPD helps to know if the pedestrian is moving in the
direction of the car or in the other direction. Thus,
the other extracted features can depend on the PPD to
know if the pedestrian is passing or not.
In order detect the PPD and avoid the fluctua-
tion in the pedestrian’s bounding box we use a six
state Mealy finite state machine (FSM) shown in
Fig.2. Each pedestrian in the frame has his own PPD-
FSM where, if the pedestrian is passing from the left
side to the right side, the FSM will be in one of
the three states(left-side0, left-side1, left-side2). The
Figure 1: PPD axis definition.
left-side0 state is the state with highest confidence
that the pedestrian’s direction is from left to right.
Alternatively, if the pedestrian is passing from the
right side to the left side the FSM will be in one of
the other three states (right-side3, right-side4, right-
side5), where right-side5 state is the state with high-
est confidence that the pedestrian’s direction is from
right to left.
Figure 2: The Finite State Machine of the PPD module.
In the first Frame for pedestrian n the PPD-FSM
start state is determined based on the pedestrian po-
sition relative to the car. As the camera position is
the center of the frame, we can conclude that the
car is at the camera position. So, if the position
of pedestrian n in the X-axis is less than that of
the the camera position, the FSM start state will be
left-side0. If pedestrian n position in the X-axis in
more than that of the camera position, the FSM start
state will be left-side5. The PPD-FSM for pedes-
trian n is updated every 5 consecutive frames. So,
to know the direction of pedestrian n we use his/her
position at time t {CenterX
t
n
,CenterY
t
n
} and time t-5
{CenterX
t−5
n
,CenterY
t−5
n
}.
3.3.2 Pedestrian Moving Speed and Direction
(PMSD)
The PMSD of a pedestrian offers an important clue
for estimating his/her action. The objective here is to
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
1162
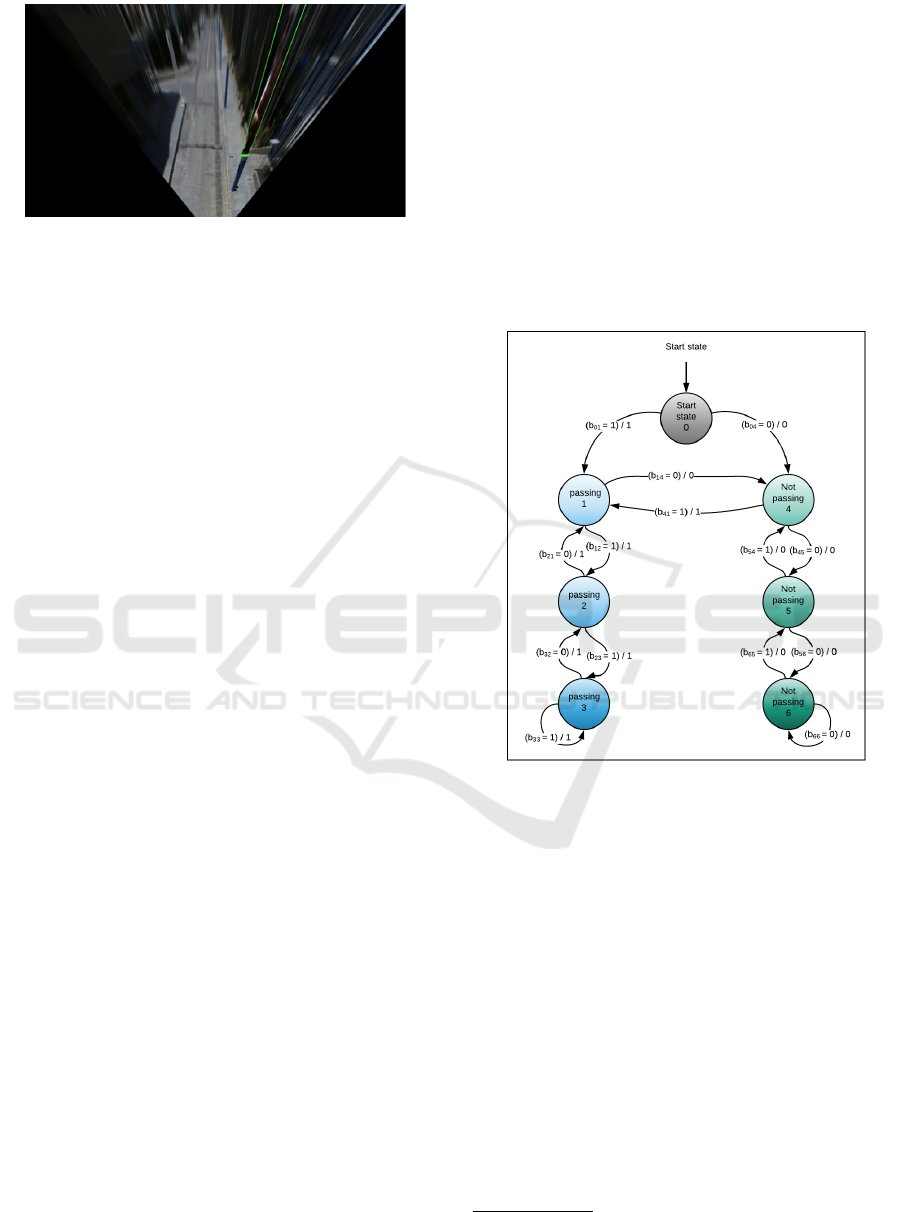
Figure 3: Orthogonal image.
detect whether the pedestrian is moving in the X di-
rection or in the Z direction. The problem with images
that all the lines are collected at one vanishing point,
so even if the pedestrian is moving parallel to the car
path(in the Z direction) in the real world he/she will
appear moving in the car path (in the X direction) in
the image not only the Z direction due to the conver-
gence from 3D space to 2D space. Thus, to be able
to calculate the pedestrian speed and determine the
direction accurately, we need to remove the perspec-
tive incurred by the fact that the camera is mounted
on the car. We convert the perspective image to an
orthogonal image that allows the perspective effect to
be removed from an image as shown in Fig.3.
After converting the original image to an orthog-
onal image we can extract the new position of the
pedestrian after removing perspective effect. Accord-
ingly, we crop the bounding box of each pedestrian
from the the original image shown in Fig.3 . Then,
we convert the image for each pedestrian to an or-
thogonal image. The new position in the X axis now
can be calculated using the color of the bounding
box. So, the new position of pedestrian n at time t
is {NCenterX
t
n
,CenterY
t
n
}. To be able to detect the
PDMS we need to calculate the deltas between the
pedestrian new position at time t and time t-1 which
is defined as :
delta
x
= NCenterX
t
n
− NCenterX
t−1
n
(2)
delta
y
= CenterY
t
n
−CenterY
t−1
n
(3)
delta
x
is the difference between the X positions in two
consecutive frames so it can be considered as the ve-
locity in X direction (vel
x
), and delta
y
can also be
considered the velocity in Y direction (vel
y
). To de-
termine the pedestrian movement direction we faced
a problem that the pedestrian bounding box position
sometimes fluctuates. To solve this problem, we use
seven state Mealy finite state machine to detect pedes-
trian state (PS-FSM), as shown in Fig.4. This way, we
can maintain the correct direction even if the bound-
ing box fluctuates in one of the frames. The PS-FSM
state zero (Start state 0) is a one time visit start state.
In the first frame, the pedestrian position is deter-
mined if he/she is on the left side of the car or right
side on the car using the PPD-FSM. If the pedes-
trian is on the left side or the right and walking to-
ward the car direction, PS-FSM will be in one of the
three states(passing1, passing2, passing3). But if the
pedestrian is walking in X direction away from the
car or the pedestrian is walking in the Z direction, the
PS-FSM will be in one of the three states (Notpass-
ing4, Notpassing5, Notpassing6). The state transition
(event) is represented by arcs between the nodes, as
shown in Fig.4, and the state transition from a state i
to a state j is described as b
i
j
.
Figure 4: Pedestrian state finite state machine(PS-FSM).
3.3.3 Head Orientation (HO)
When pedestrians are moving, their HO tends to coin-
cide with the direction of their movement. Therefore,
we can predict the moving direction of the pedestrian
if we can estimate his/her HO. HO estimation con-
sists of face detection and head orientation estimation.
First, for face detection we use a pre-trained model
1
on a data set generated by using the cleaned widerface
labels. The head detection model take as an input a
frame that contains the pedestrian and the output is a
bounding box points for each pedestrian face in the
frame as shown in Fig.5.
After detecting the face position, the head ori-
entation can be predicted using Hopenet pre-trained
model proposed in (Ruiz et al., 2018) that takes as in-
1
https://github.com/Linzaer/Ultra-Light-Fast-Generic-
Face-Detector-1MB
Multi-feature and Modular Pedestrian Intention Prediction using a Monocular Camera
1163

put a cropped image of the pedestrian face using the
bounding box of the face and outputs the predicted
pedestrian yaw, roll and pitch as shown in Fig.5.
After extracting all the HO of all pedestrians in a
frame, we start matching those head poses with the
detected pedestrians. The matching is done by us-
ing the face bounding box and the person bounding
box. We are mainly interested in the pedestrian’s head
yaw value as it indicates the rotation angle of the head
around the Y axis.
Figure 5: Head orientation estimation.
3.3.4 Body Pose (BP)
Pedestrian BP is a very important clue that can predict
if this person is going to pass or not even if the pedes-
trian position is still constant. Before the pedestrian
starts using his/her legs to walk, he/she first bends
his/her upper body to give himself/herself the first
push to start the motion. Thus, we use the BP to be
able to predict the pedestrian’s next move. To recog-
nize the BP we use a pre-trained model proposed in
(Cao et al., 2017). The system takes as input a color
image of size w × h and produces the 2D locations of
anatomical keypoints for each person in the image as
shown in Fig.6.
To be able to predict the pedestrian’s next move
we were interested in some keypoints such as right
shoulder, left shoulder, nose, right knee, left knee,
left ear, and right ear. The left and right shoulder
were the main indicators that the upper body is bend-
ing while the left and right knees were the indicators
that the pedestrian started moving. To be able to de-
tect changes in keypoints, we calculated the deltas be-
tween each keypoint at time t-1 and its corresponding
keypoint at time t. For example, if the right knee posi-
tion at time t-1 is {Rknee
t−1
x
,Rk nee
t−1
y
} and the right
knee position at time t is {Rknee
t
x
,Rk nee
t
y
}, the deltas
of the right knee delta
Rknee
is defined as:
Figure 6: Image with pedestrian BP.
delta
Rknee
= {|Rknee
t
x
− Rknee
t−1
x
|,|Rknee
t
y
− Rknee
t−1
y
|}
(4)
Each body part (keypoint) detected has its own con-
fidence based on how effective this part can affect
the pedestrian movement. Left and right knees and
left and right shoulders have the highest confidence
as they are the main contributors to predict if this
pedestrian is going to pass or not. So, for each of
the keypoints, a delta
bodypart
is calculated between
two frames and if this delta is greater than a cer-
tain threshold, the passing confidence of this part is
added to the total confidence, if the delta is in the
direction of the car that is defined using the PPD-
FSM mentioned in 3.3.1. Also, backup deltas are
computed for each keypoint but only every 3 frames.
For example, if the right knee position at time t-3 is
{Rknee
t−3
x
,Rk nee
t−3
y
} and the right knee position at
time t is {Rknee
t
x
,Rk nee
t
y
}, the back up delta of the
right knee backupdelta
Rknee
is calculated as:
backupdelta
Rknee
= {|Rknee
t
x
− Rknee
t−3
x
|,|Rknee
t
y
−Rknee
t−3
y
|}
(5)
These back up deltas help to detect small range body
movements to be able to predict the pedestrian in-
tention as early as possible. Each keypoint delta
or backup delta has its own threshold that is picked
based on the pedestrian position in the Y axis since
the pedestrian change in X position differ based on
the position in Y position. Thus, we divided the im-
age into 10 regions to define the thresholds for dif-
ferent body parts. Each of these regions has its own
average and minimum deltas for each body part.
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
1164

3.4 Constant Velocity Model (CVM)
After extracting all the features mentioned in the pre-
vious section (PPD, PMSD, HO, BP) we can predict
pedestrian’s intention. However, this is not the only
thing we need to know about the pedestrian. Self
driving cars also need to know the next position of
each pedestrian in order to handle safe maneuvers and
stops. To predict the pedestrian’s future position we
use CVM approach. CVM uses the motion history of
the pedestrian to be able to predict his/her next posi-
tion. We donate the position {NCenterX
t
n
,CenterY
t
n
}
of pedestrian n at time t as p
t
n
, which is extracted
from the orthogonal image as mentioned in section
3.3.2. The goal of pedestrian motion prediction is to
predict the future trajectory F
n
= (p
t+1
n
,...., p
t+m
n
) for
pedestrian n, taking into account his/her motion his-
tory H
n
= (p
0
n
,...., p
t
n
). We use average displacements
between the last 3 frames to be able to predict the fu-
ture displacement, average displacement, defined as:
D
avg
=
(p
t−2
n
− p
t−3
n
) + (p
t−1
n
− p
t−2
n
) + (p
t
n
− p
t−1
n
)
3
(6)
So in order to predict the future position, we use D
avg
as a constant velocity for the pedestrian n in the next m
frames. So p
t+1
n
is calculated by adding the constant
velocity of the pedestrian n D
avg
with p
t
n
so the future
position F
n
, defined as :
F
n
= (p
t
n
+ D
avg
,...., p
t+m−1
n
+ D
avg
) (7)
3.5 Final Prediction
The final prediction is obtained based on the output of
the prediction modules (BP, PMSD, CVM, and HO).
Each of these modules can predict that pedestrian n
is passing with a certain percentage. Then, we apply
a weighted sum to obtain the final prediction. This
weighted sum is defined as :
Final prediction =
4
∑
i=1
module
i
∗ con fidence
i
(8)
Where module
i
is the output percentage of one of
the prediction modules and the con f idence
i
is how
much we trust the output of this module. In this pa-
per, con fidence
i
is obtained based on the error rate of
each module which is calculated in Section 4.
4 PERFORMANCE EVALUATION
In order to compare our proposed approach to the
other approaches, we use six videos from KITTI
datasets (Geiger et al., 2013) to evaluate our own
model. The six videos contains in total 227 frames
and 13 pedestrians. We also propose a novel dataset
to evaluate pedestrian intention prediction. The pro-
posed dataset is captured in the German University in
Cairo(GUC) and consists of eight 2048 × 1536 sized
videos captured by a camera mounted on the front-top
of a moving car.Where the 8 videos of the proposed
dataset contains in total 1123 frames and 20 pedestri-
ans. We use the videos in the two datasets as input for
our system. For each video, we evaluate our approach
based on the output for each frame. Thus, we evaluate
Body Pose and Head Pose detection and orientation
estimation, the Pedestrian Moving Speed and Direc-
tion, the pedestrian Passing Direction, and the pre-
diction of the constant velocity model accuracy. We
also test the proposed approach on our self-driving car
to make sure that our approach is compatible for real
time applications.
4.1 Feature Descriptors for Pedestrian
Intention Prediction
In order to evaluate the proposed approach, we la-
beled the GUC dataset for each pedestrian appearing
in each video. Thus, we classify each pedestrian state
in each frame as ”Passing” or ”Not passing” to be able
to evaluate our proposed approach on the proposed
dataset. Then, we calculate the error rate of the fol-
lowing individual features:(1)PMSD, (2)BP, (3)HO,
(4)CVM, and (5)PPD, using the following equation :
Error rate =
Faulty Predictions
Total Number o f Predictions
(9)
As shown in Fig.7, HO exhibits the lowest perfor-
mance with respect to error rate as 87 %. The major
reason for the lowest performance of HO is the false
decision of the face detection and orientation estima-
tion when the pedestrian is located a long distance
away from the camera. In contrast, PDMS shows
lower error rate of 18% . According to the error
rate graph, we found that some features cannot be
used alone to predict the pedestrian intention (such
as HO and the BP) to avoid false predictions. Also
PPD, which has the lowest error rate of 2%, cannot
be used to predict the pedestrian intention as it only
tells us which curb the pedestrian is passing from.
Thus, in our proposed approach we combine all these
individual features(PDMS+BP+HO+PPD+CVM) to
predict the pedestrian intention and future posi-
tion. The pedestrian intention is detected using
BP+HO+PDMS+PPD and future position is predicted
using CVM that has error rate of 25.8%.
Multi-feature and Modular Pedestrian Intention Prediction using a Monocular Camera
1165
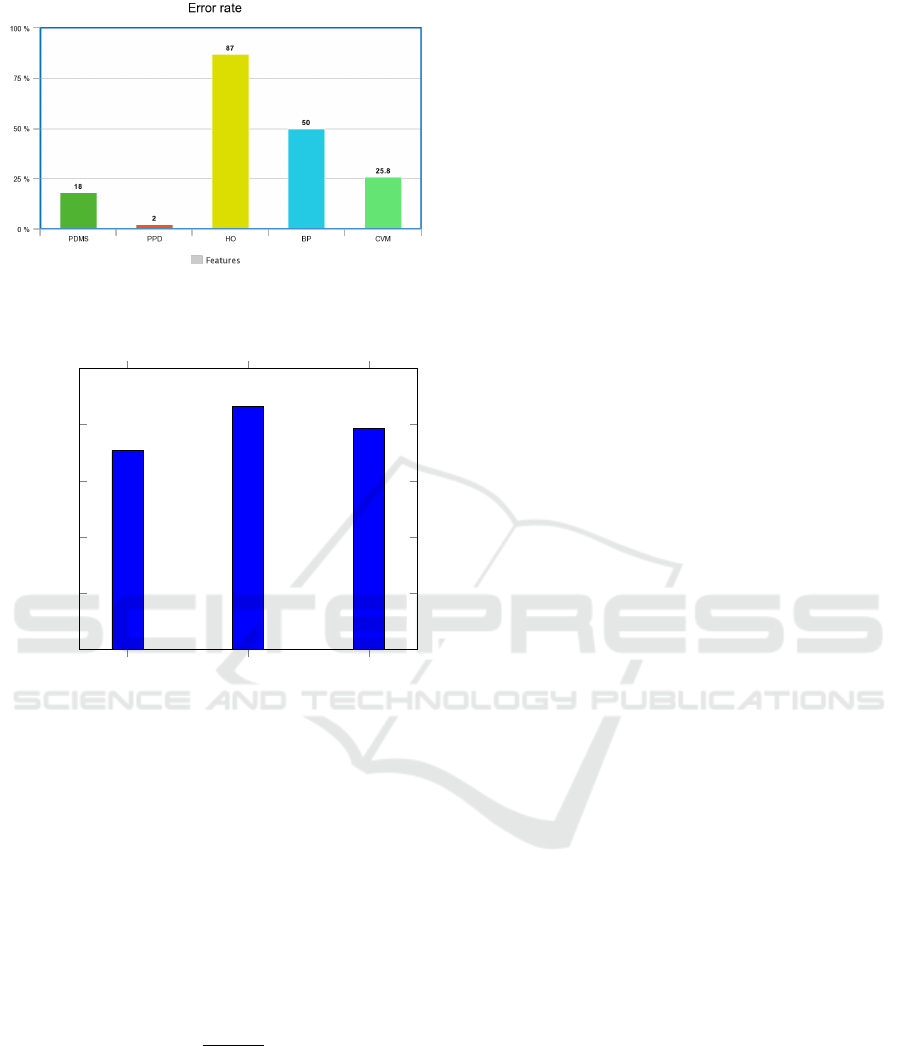
Figure 7: Performance comparison between five individual
features.
Passing Not passing
Avg
0
20
40
60
80
100
70.7
86.34
78.52
%
Precision
Figure 8: Precision.
4.2 Performance of Pedestrian
Intention Prediction
For performance evaluation of pedestrian intention
prediction, we evaluate the precision for our proposed
approach. We calculate the precision of the two out-
put classes for our proposed system which are: Pass-
ing and Not passing as shown in Fig.8. Precision (P)
is defined as the number of true positives (T
P
) over
the number of true positives plus the number of false
positives (F
P
) as shown in Equation.10.
P =
T
P
T
P
+ F
P
(10)
As shown in Fig.8 our proposed approach reaches a
very good precision percentage of 86.34% to predict
if this pedestrian is Not passing and reaches about
70.7% to predict that this pedestrian is passing. The
reason why the precision of Passing is less than that of
Not passing is that our approach needs about two or
three frames to be able to predict that this pedestrian
is changing his/her state from Not passing to Passing.
So, in average the precision was found to be 78.52%.
4.3 Processing Time of the Pedestrian
Intention Prediction
In addition to the prediction performance, we were
concerned with the computational speed of the pro-
posed approach as it should work in real-time. It was
found that the processing time of the proposed ap-
proach is 11 FPS on average which is sufficient for
real-time applications as KITTI dataset (Geiger et al.,
2013) which is used for testing is captured at 10 FPS.
4.4 Pedestrian Intention Prediction
Results
In this section we will show the results of our pro-
posed approach on two videos of the proposed dataset
(GUC dataset), KITTI dataset and a live test on our
self-driving car. In these results we will present dif-
ferent scenarios for pedestrians standing, walking par-
allel to the car direction, and passing in front of the
car.
4.4.1 GUC Dataset
Fig.9 shows the result of the pedestrian intention pre-
diction of the proposed algorithm for five of the test
videos of the GUC dataset. As shown in Fig.9 (a)
the pedestrian actions is classified into two categories:
”Passing” and ”Not passing”. The examples shown in
Fig.9 shows good performance of the proposed algo-
rithm for pedestrian intention. In Fig.9 (a)(2) our ap-
proach mispredicted the intention of the pedestrian as
the pedestrian was not appearing due to the trash bin
and then a recovery happens in Fig.9 (a)(3) and the
prediction was adjusted.
4.4.2 KITTI Dataset
Fig.9(b) shows the result of the pedestrian intention
prediction of the proposed algorithm on one of the
test videos of KITTI dataset. As shown in Fig.9 the
pedestrian’s actions are classified into two categories:
”Passing” and ”Not passing”. The examples shown
in Fig.9 (b) shows good performance of the proposed
algorithm for pedestrian intention. In Fig.9 (b) (1) a
pedestrian is passing and is matched correctly. How-
ever, In Fig.9 (b) (2) mismatching happens and the
passing pedestrian appeared to be Not passing. In
Fig.9 (b) (3) our approach recovered and rematched
the pedestrian and predicted that he is passing again
correctly.
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
1166

Figure 9: Results for pedestrians’ intention prediction
(GUC & KITTI dataset).
4.4.3 Live Testing
In this section we are going to show the results of the
proposed approach and how it was working in real
time scenarios on our modified self-driving vehicle.
We tested our system on our self-driving car ”Herbie”
within the campus of the German International Uni-
versity(GIU). The test cases were a pedestrian walk-
ing in front of the car and pedestrian running in front
of the car and a pedestrian is passing and intersects
with the car path. Our system detects the pedestrian
and outputs that there is a pedestrian passing in front
of the car and the system on the car made the appro-
priate action and stopped.
5 CONCLUSIONS
In this paper, we propose pedestrian intention predic-
tion system based on machine learning and computer
vision. To predict if the pedestrian is passing or not
HO, BP, PDMS, PPD features were extracted. We
also use CVM to be able to predict the pedestrian’s
future position so we can avoid the collision between
the car and the pedestrian. Our system is evaluated
using datasets and live testing, where it is proven that
our approach is effective in detecting pedestrian in-
tention and future position. Also, the performance of
our proposed approach was found to be sufficient for
real time applications. In future research, we will fo-
cus on compensating the ego-motion on the camera
to be able to remove the effect of car movement, as
the pedestrian’s motion is influenced by the distance
between the pedestrian and the car. Furthermore, we
will use more accurate and advanced matching and
tracking techniques to avoid mis-predictions due to
false matches.
REFERENCES
(accessed 2020-07-30). Road traffic injuries.
https://www.who.int/news-room/fact-sheets/detail/
road-traffic-injuries.
C. Sch
¨
oller, V. Aravantinos, F. L. and Knoll, A. (2020).
What the Constant Velocity Model Can Teach Us
About Pedestrian Motion Prediction. 5.
Cao, Z., Simon, T., Wei, S.-E., and Sheikh, Y. (2017). Real-
time multi-person 2d pose estimation using part affin-
ity fields. In The IEEE Conference on Computer Vi-
sion and Pattern Recognition (CVPR).
Geiger, A., Lenz, P., Stiller, C., and Urtasun, R. (2013).
Vision meets robotics: The kitti dataset. International
Journal of Robotics Research (IJRR).
Joon-Young Kwak, Byoung Chul Ko, J.-Y. N. (2017).
Pedestrian intention prediction based on dynamic
fuzzy automata for vehicle driving at nighttime.
Quintero, R., Almeida, J., Llorca, D. F., and Sotelo, M. A.
(2014). Pedestrian path prediction using body lan-
guage traits. pages 317–323.
Redmon, J. and Farhadi, A. (2018). Yolov3: An incremental
improvement. arXiv.
Rehder, E., Wirth, F., Lauer, M., and Stiller, C. (2018).
Pedestrian prediction by planning using deep neural
networks.
Ruiz, N., Chong, E., and Rehg, J. M. (2018). Fine-grained
head pose estimation without keypoints. In The IEEE
Conference on Computer Vision and Pattern Recogni-
tion (CVPR) Workshops.
S. K
¨
ohler, M. Goldhammer, S. B. K. D. U. B. and Diet-
mayer, K. (2012). An analysis of the current state of
English majors’ BA thesis writing [J]. Early detection
of the Pedestrian’s intention to cross the street, 3.
Solmaz, G., Berz, E. L., Dolatabadi, M. F., Aytac¸, S., F
¨
urst,
J., Cheng, B., and den Ouden, J. N. (2019). Learn
from iot: Pedestrian detection and intention prediction
for autonomous driving. In SMAS ’19.
Multi-feature and Modular Pedestrian Intention Prediction using a Monocular Camera
1167
