
Detecting Cyber Security Attacks against a Microservices Application
using Distributed Tracing
Stephen Jacob
a
, Yuansong Qiao
b
and Brian Lee
c
Department of Computer and Software Engineering, Athlone Institute of Technology, Dublin Rd., Athlone, Ireland
Keywords:
Microservices, Cyber Security, Distributed Tracing, Anomaly Detection.
Abstract:
Microservices are emerging as the dominant software design architecture for many different applications,
and cyber attacks are targeting more software organisations every day. Newer techniques for detecting cyber
intrusions against such applications are in high demand. Application functionality that is executed within
a microservices application can be monitored and logged using distributed tracing. Distributed tracing is
normally used for performance management of microservices applications. In this paper, we used distributed
tracing for detecting cyber-security attacks. Each microservice call, or sequence of calls, executed in response
to a request by an end user of the application is logged as a trace. Anomaly detection is a means of detecting
irregular or unusual events or patterns in a data set that occur to a greater or a lesser degree than the majority
of the data. In this paper, we present initial work that identifies anomalous distributions of traces. A frequency
distribution of traces is obtained from normal data and traffic is identified as an anomaly candidate if it differs
sufficiently from the base distribution. This approach is evaluated using a password guessing attack. In
addition, we briefly discuss a NoSQL injection attack which we argue is difficult to detect using trace data.
1 INTRODUCTION
Many software applications such as those developed
recently by Amazon, Twitter and Netflix are built us-
ing a microservices based architecture. Hackers will
continue to target these state-of-the-art applications
using newer and more sophisticated forms of cyber
attacks. Consequently, software security personnel
require similarly updated means of detecting cyber
threats to their software applications.
One way to do this in a microservices-based appli-
cation is to monitor the system’s overall behaviour us-
ing distributed tracing and perform anomaly detection
to discover anomalies or outliers in the system’s over-
all functionality. A cyber attack deliberately targeting
the app can create an irregular process activity within
the application. By detecting irregular behaviour, cy-
ber security personnel can be forewarned of ongoing
cyber attacks.
In this paper, we use a distributed tracing system
to monitor behaviour in microservices-based applica-
tions with a view to identify cyber security attacks.
a
https://orcid.org/0000-0003-2297-4343
b
https://orcid.org/0000-0002-1543-1589
c
https://orcid.org/0000-0002-8475-4074
For our experiment, we generate normal microservice
traffic and then execute cyber security attacks against
the application. We aim to detect the attack by detect-
ing an anomaly in the trace data. To the best of our
knowledge, our work is the first attempt at using dis-
tributed tracing to detect cyber security attacks in an
application with a microservices architecture.
A machine learning approach is applied to ana-
lyze the resulting traces. A user request generates a
sequence of system calls which are logged by the dis-
tributed tracing system. Normal behaviour of the sys-
tem over some interval of time will generate a number
of these system call sequences. One approach to de-
tect cyber security attacks is to identify a set of system
call sequences that is in someway different from nor-
mal behaviour. Our approach, which is early work, is
to compare the frequency distribution of unique sys-
tem calls in the normal and attack data.
The structure of this paper is as follows: Section
II will explore similar related works involving mi-
croservices applications, the use of distributed trac-
ing to monitor an application’s behaviour and the
use of anomaly detection to detect irregular system
calls in the overall application functionality. Section
III will outline the relevant background information
on the microservices architecture, distributed tracing
588
Jacob, S., Qiao, Y. and Lee, B.
Detecting Cyber Security Attacks against a Microservices Application using Distributed Tracing.
DOI: 10.5220/0010308905880595
In Proceedings of the 7th International Conference on Information Systems Security and Privacy (ICISSP 2021), pages 588-595
ISBN: 978-989-758-491-6
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved

and anomaly detection. Section IV outlines an open-
source microservices benchmark suite and describes
the software tools said application is configured to
use for our experiment. In Section V, we present two
available end-to-end microservice applications from
the benchmark suite, outline their general system be-
haviour and architectural design and two different
possible forms of cyber attack we carried out for the
experiment. Section VI presents the to-date report and
current results obtained from the experiment. In Sec-
tion VII, we outline the conclusions drawn from our
experiment and possible further work to explore in the
future.
2 RELATED WORK
(Gan and Delimitrou, 2018) presented and character-
ized an end-to-end microservices application that im-
plemented an extensible movie renting and streaming
service. An advantage discovered using the movie
service was being able used to measure the duration
time between client API calls to the application and
the computation of the service. The appeal and con-
venience of the microservices architecture was high-
lighted, particularly how the individual services can
communicate with each other using remote procedure
calls and how the framework can be used to analyse
performance bottlenecks. No analysis was carried out
to detect anomalies caused by security attacks.
(Nedelkoski et al., 2019) developed a deep learn-
ing approach to model distributed tracing and log net-
work data with a focus on time-series based anomaly
detection. The model was trained to learn the general
behaviour of complex distributions of distinct data
traces over a long period of time. An anomaly de-
tection technique was developed using a probability-
based error threshold setting. The anomaly detection
models were used to classify data points as anoma-
lies or not and provide descriptive analysis and re-
sults. Furthermore, a post-processing strategy was
combined with the threshold setting to mitigate the
occurrence of data points erroneously classified as
anomalies, or false positives. Again, the techniques
were applied exclusively to performance bottleneck
and did not examine security attacks.
(Chandola et al., 2009) wrote a survey with the in-
tention of providing a thorough overview of research
on anomaly detection. One of the highlights provided
by their survey is the observation that data points clas-
sified as outliers are only anomalous in regards to a
context. Another highlight is that anomalies can be
divided into different categories, each with key as-
sumptions that differentiate outliers from normal, reg-
ular data. An expansive literature on various tech-
niques that can be used for anomaly detection is also
provided, as well as their advantages and disadvan-
tages. Finally, this survey observes that anomaly de-
tection is being utilized in more and more complex
systems every day.
(Gan et al., 2019a) highlights the recent shift
of monolithic architectures to the loosely coupled
microservices-based framework for many software
applications. The paper also presents an open-source
benchmark suite known as DeathStarBench, com-
prised of multiple microservices-based applications.
In the paper, DeathStarBench is used primarily to
study the immensely complex architectural charac-
teristics of a microservices application, observe these
applications in real deployment by hundreds of users
and carry out the identification of performance bottle-
necks.
(Gan et al., 2019c) used a performance debugging
system known as Seer which monitors temporal and
spatial patterns of behaviour in general cloud appli-
cations, including microservices. The Seer system
combines distributed tracing with low-level hardware
monitoring to detect and diagnose Quality of Service
(QoS) violations to avoid unwanted behaviour cas-
cading through the application system. The advan-
tages of microservices-based architectures simplify-
ing correctness debugging, and Seer identifying ap-
plication level bugs and indicating how to improve the
microservices framework were highlighted to achieve
optimal performance.
A survey (Toth and Chawla, 2018) was written to
provide an overview and a more comprehensive un-
derstanding of the concept of group anomaly detec-
tion in contrast to pointwise anomaly detection. The
study highlights the advantages of group deviation de-
tection techniques including discovery of abnormal
behaviour, mitigating risks and prevention of mali-
cious activity in the fields of particles, physics and
health care collusion. The survey also outlines the
state-of-the-art techniques for carrying out group de-
viation detection as well as the frameworks and data
structures.
3 BACKGROUND INFORMATION
In this section, we will describe the microservices
software architecture and give an outline of the dif-
ferent technologies and anomaly detection techniques
used in this paper.
Detecting Cyber Security Attacks against a Microservices Application using Distributed Tracing
589

3.1 Microservices
Microservices, or simply the microservices architec-
ture (MSA), is a service-oriented software architec-
tural design which divides the overall application into
a collection of smaller inter-connected component
services. A single microservice handles one busi-
ness service of the application’s total functionality,
e.g. database queries or message posting.
Microservices-based applications share a com-
mon cross-service API allowing different microser-
vices to communicate with each other. A single mi-
croservice has a well-defined interface that can be
called in response to a user’s request and subsequently
communicates with other microservices using either a
RESTful API or remote procedure calls (RPC) (Sun
et al., 2015) (Nagothu et al., 2018). In a distributed
application, a single microservice will operate along-
side other microservices but can be developed, de-
ployed and scaled independently. Another advantage
of the MSA is that the design supports programming
language and framework heterogeneity (Gan and De-
limitrou, 2018). Therefore, microservices are quickly
becoming a newer platform trend for cloud-native ap-
plications such as Twitter, Amazon and Netflix (Gan
et al., 2019b).
3.2 Distributed Tracing
In the field of software engineering, distributed trac-
ing is the process of monitoring, profiling and logging
the execution path through a cloud-native application
at runtime in response to a user’s request. A user’s
request typically results in behaviour that can span
across multiple services in the application, resulting
in a distributed trace, a detailed record of the execu-
tion path through the application.
A distributed trace itself is represented as the se-
quential set of spans, each sharing a traceID. A span
is represented as a single application event, or service
call executed in response to a user’s request. Other
fields, or characteristics in a span include the name of
the executed call, the timestamp and the duration of
the call. The span can also contain meta information
including an executed HTTP URL and the response
code to that HTTP call.
Service tracing and system logging are vital to un-
derstanding the behaviour of user’s requests that ac-
cess and propagate through an application. Due to
the complexity of a cloud system domain, distributed
tracing is well suited and commonly used for per-
formance monitoring of microservices-based applica-
tions.
3.3 Anomaly Detection
Anomaly detection is the process of detecting irreg-
ular instances or occurrences within a data series.
These anomalous instances do not conform to the
general behaviour of the data. Anomalous data can
indicate an error is present. Anomalous instances, or
outliers, can occur in a variety of system data applica-
tions including fraud detection for health insurance,
finances, cyber attack intrusion and military surveil-
lance for enemy activity.
Anomaly detection can be carried out in two dif-
ferent ways: supervised and unsupervised anomaly
detection (Chandola et al., 2009). In supervised
anomaly detection, both the general data and irreg-
ular data series are categorized and labeled. The la-
beled data is then trained by a machine learning al-
gorithm to learn the general behavior of the data and
subsequently detect anomalous data. The data will
be trained whether it contains anomalies or not. By
contrast, unsupervised anomaly detection does not
require labeled training data. It is implied that the
normal instances are far more frequent than anoma-
lous instances and the trained model is robust to such
anomalies. Anomaly detection is generally used in
unsupervised databases, which do not use labels and
lack structure.
There is another classification of anomaly detec-
tion techniques into pointwise anomaly detection and
group anomaly detection (GAD) (Toth and Chawla,
2018). The more recognizable form is pointwise
anomaly detection which detects individual instances
in a data set that are anomalous. Pointwise anomaly
detection is not useful for the detection of anoma-
lous behaviour of groups of instances. Group-based
anomaly detection is an emerging form of detection
which detects an outlier group of instances in the data.
4 EXPERIMENT
In this section, we examine the use of distributed
traces for cyber security anomaly detection using the
open-source microservices benchmark suite Death-
StarBench (Gan et al., 2019a).
First we give an overview of DeathStarBench and
the associated distributed tracing technologies. Then
we analyze two well-known cyber security attacks, a
password guess attack and NoSQL Injection. In par-
ticular, we examine if it is possible to detect these at-
tacks using microservices distributed tracing data.
We see that, while in the case of the password at-
tack, we can detect a group anomaly by looking at
the distribution of unique call sequences over a short
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
590
period of time while it is quite difficult to detect a
NoSQL Injection attack in the case where no changes
have been made to the microservice implementations.
4.1 DeathStarBench
The microservice-based application executed for this
report was DeathStarBench, an open-source bench-
mark suite comprised of several end-to-end appli-
cations including a social networking application
where registered users compose posts and follow
other users, a media application where users can post
movie reviews and a hotel reservation service (Gan
et al., 2019a). The social network application was
chosen for examination in this work.
4.1.1 Docker
Docker is a Platform as a Service (PaaS) tool de-
signed to create, deploy and run applications in a vir-
tual environment. Individual application functionality
and their respective source code, dependencies and li-
braries are isolated and compressed into files called
Docker images. These image files are then used as
templates to build lightweight executable packages
called containers.
In the DeathStarBench suite, every individual mi-
croservice is run as a Docker container. A tool called
docker-compose is used to create, configure and start
the microservices that are part of the application.
4.1.2 Thrift
Thrift is binary communication protocol and interface
definition language developed by Apache software
Foundation. The Thrift language provides support
for client-server RPCs. In the DeathStarBench suite,
the inter process communication between the differ-
ent microservices is handled by Thrift and the inter-
faces for the microservices are written in the Thrift
language.
4.1.3 Jaeger
Jaeger is an open-source distributed tracing system
that traces a client’s request execution path through
the application. Jaeger is comprised of three differ-
ent components with its own function: jaeger-agent, a
network daemon that listens for executed span or ser-
vice calls sent over a User Datagram Protocol (UDP),
jaeger-collector where the span data is stored and the
jaeger-query which queries the jaeger-collector, re-
trieves the resulting traces and serves as a JavaScript
UI for those traces.
4.1.4 ElasticSearch
In our experiment with DeathStarBench, we recon-
figured the Jaeger-collector component to work with
ElasticSearch, a storage backend for JSON docu-
ments. The ElasticSearch API was primarily used to
download the data in bulk.
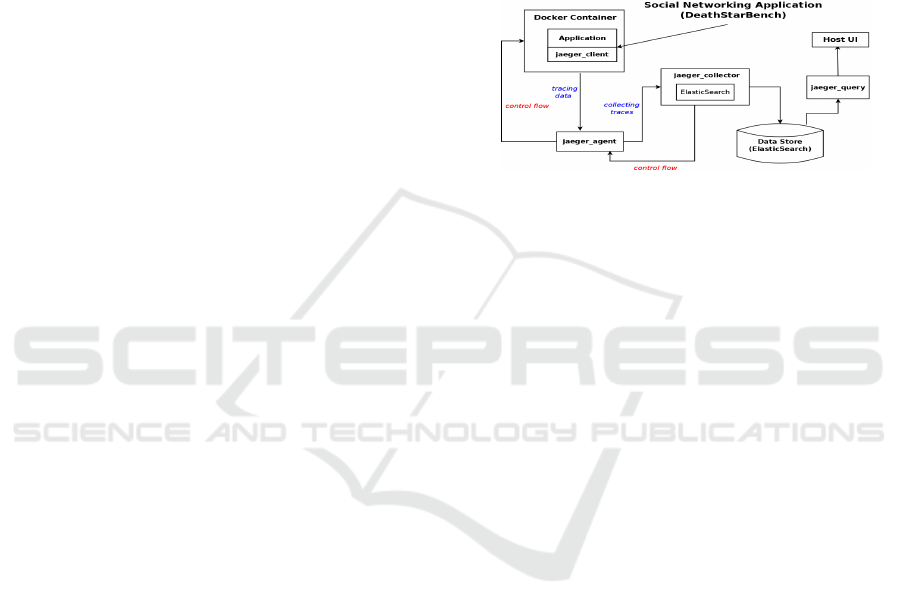
The architecture of the microservices application
including the Docker Host or container, and the Jaeger
components configured with the ElasticSearch stor-
age backend are displayed in Figure 1.
Figure 1: Application Structure for Social Network.
4.2 Password Guessing Attack
A password guess attack is a type of remote to lo-
cal (R2L) cyber attack. An intruder attempts to ac-
cess unauthorized information from a local machine
through a remote machine (Dhanabal and Shanthara-
jah, 2015). The hacker tries multiple times to log into
an application by continuously attempting any combi-
nation of usernames and passwords until they find one
that works. Therefore, a password attack would be
comprised of multiple incorrect logins within a short
span of time.
The social networking application from the Death-
StarBench microservices suite supports a user login
operation, so we selected it for our experiment. We
used a password guessing attack, resulting in multi-
ple incorrect logins within a short period of time, as
an example of anomalous user activity. This irreg-
ular activity would correspond to a group anomaly
whereas one or two incorrect logins in regular trace
data would be normal user activity. The method to
detect this group anomaly is to detect when the fre-
quency distribution of traces is different from the fre-
quency distribution of normal data.
4.2.1 Frequency Analysis
A user request to the application generates a trace
which is a sequence of spans. Each event span is
identified by a combination of the service name and
operation name.
We defined a distance metric between two sets of
traces, T
1
and T
2
. Let s
1
, s
2
...s
n
be the set of all unique
Detecting Cyber Security Attacks against a Microservices Application using Distributed Tracing
591

sequences in T
1
and T
2
. The frequency distributions
f(T
1
) and f(T
2
) are defined as:
f (T
1
) = (s
1
, f
1
1
) + (s
2
, f
1
2
) + ... + (s
n
, f
1
n
) (1)
f (T
2
) = (s
1
, f
2
1
) + (s
2
, f
2
2
) + ... + (s
n
f
2
n
) (2)
In the equations above, f
j
i
is the frequency of s
i
in T
j
. The difference in the frequency distributions
d(T
1
, T
2
) is defined using the Euclidean distance met-
ric:
d(T
1
, T
2
) =
q
( f
1
1
− f
2
1
)
2
+ ... + ( f
1
n
− f
2
n
)
2
(3)
4.2.2 User Requests and System Calls
We carry out a simple experiment with two different
types of requests: composePost, where a user uploads
a posts consisting of media content such as text, tags
and links, and userLogin where a user logs in.
When a post is uploaded to the application, the
posts are stored in a MongoDB database and cached
in a Memcached service. The following are some of
the microservice calls that are executed during a com-
posePost request: UploadMedia, UploadText, Up-
loadUniqueID, UploadURLs, UploadUserMentions,
StorePost, WriteUserTimelines, MongoInsertPost and
MmcSetPost. For composePost requests, there are
in total 27 different microservice calls executed and
1308 different microservice call sequences.
For the userLogin requests, there are 4 microser-
vice calls and 3 different sequences. The four calls
used are Login, MmcGetLogin, MongoFindUser, Mm-
cSetLogin. A userLogin request can be satisfied from
the cache if the appropriate user object is in Mem-
cached. If not, a call needs to be made to the Mon-
goDB database to get the user information. The mi-
croservice call MmcGetLogin checks if the user’s
credentials have been cached in Memcached. Mon-
goFindUser looks for the registered user in MongoDb.
MmcSetLogin caches user credentials in Memcached.
The following are valid sequences of microservice
calls executed during a userLogin request.
• (Login -> MmcGetLogin)
• (Login -> MmcGetLogin -> MongoFindUser)
• (Login -> MmcGetLogin -> MongoFindUser ->
MmcSetLogin)
The first sequence of calls can be executed for
both a correct and an incorrect login, depending on
whether a correct or incorrect password is supplied.
The second sequence corresponds to an incorrect lo-
gin as the provided password is not correct and the
user data is not cached to Memcached. The third
sequence corresponds to a correct login as matching
user credentials have been found in MongoDb and are
stored in Memcached.
4.2.3 Definition of Training (Normal) Data
Normal application requests are composed primarily
of composePost requests and correct userLogin re-
quests, along with a small number of incorrect user-
Login requests. In normal application traffic, only a
small number of userLogin requests would be incor-
rect, caused by users entering the wrong credentials
by mistake. An experiment carried out by (Brostoff
and Sasse, 2003) showed that only 10% of all logins
were incorrect.
The requests for composePost were sent to the
social networking application using a HTTP work-
load traffic generator. This returned a total of 1856
distributed traces. A number of userLogin requests
were also sent and returned 592 correct and 102 in-
correct login traces. These HTTP requests generated
2550 traces in total with a vocabulary of 32 span event
types. 2000 of these were set aside as a training (nor-
mal) data and the distribution of the three different re-
quests for this normal data set is displayed in Table 1
below.
Table 1: Normal Data Set.
User Requests Number
composePosts 1526
correct userLogin 420
incorrect userLogin 54
Total 2000
4.2.4 Validation Data
Validation data, also normal data, consists of 300
composePosts, 165 correct and 35 incorrect user-
Login requests giving a total of 500 requests. (Note
that this is a higher proportion of incorrect logins than
documented in (Brostoff and Sasse, 2003)), but this
makes the anomaly detection harder, not easier.) The
corresponding validating traces were divided into 10
subsets each of size 50. These subsets were created
in order to estimate the mean and standard deviation
of the distances (to the normal training data) of other
normal data samples.
4.2.5 Attack Data
A third data set was created to simulate a password
guessing attack against the application. This anoma-
lous data set has many more incorrect userLogin
traces than correct ones. The distribution of the dif-
ferent traces in this anomalous data set is displayed in
Table 2 below.
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
592
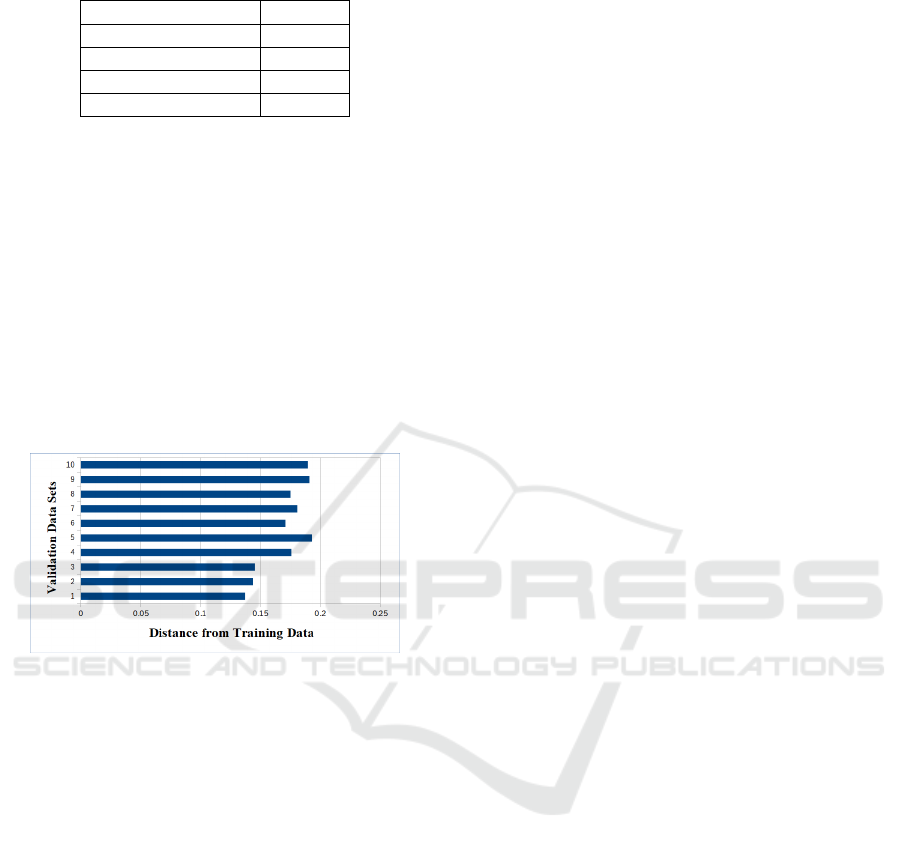
Table 2: Anomalous Data Set.
User Requests Number
composePosts 30
correct userLogin 7
incorrect userLogin 13
Total 50
4.2.6 Experiment
Our experiment with the data sets is outlined as fol-
lows. Using the Eq. 1 defined above, we calculated
the frequency distribution f (T
0
) for all existing traces
in the normal training data set. We then applied Equa-
tion 2 to the 10 validation data sets to calculate the
frequency distribution for each: f (T
1
), f (T
2
), . . .
f (T
10
). Using the distance metric defined in Eq. 3,
we calculated the difference in distributions between
f (T
0
) and each of the validation data distributions
f (T
1
), f (T
2
), ... f (T
10
) and these difference values
are displayed in Figure 2 below.
Figure 2: Distance of Validation Data from Training Data.
In the final stage of our experiment, we applied
Equation 2 to return the frequency distribution of
traces for the anomalous data set denoted as f (T
11
).
4.2.7 Results
We calculated the mean and the standard deviation for
the distance values between the frequency distribu-
tions of the normal data and each of the ten validat-
ing data sets. The mean was 0.1701 and the standard
deviation was 0.0208. We set a threshold of two stan-
dard deviations above the mean, that is 0.2117, for
detecting attack data. We find that the distance of the
attack data from the normal data was 0.2171 which is
above this threshold. Assuming a normal distribution,
we would expect 97.5% of normal validation data to
be below this threshold. All ten validating data sets
are below this threshold as we would expect. In a real
world scenario, a hundred percent prediction like this
would of course be unlikely.
4.3 NoSQL Injection Attack
A NoSQL Injection attack is an attack where the
hacker gets a software system to behave in a way it
never intended to by injecting code that accesses the
database into a data field. (Belmar, 2019). For exam-
ple, an application could allow access to information
on a single user with a provided user’s ID. A hacker
could instead get the app to return all users’ data from
the database.
In the case of an application using MongoDB,
this requires the execution of database query with a
WHERE clause. The attacker enters JavaScript code
that ends up being executed in the WHERE clause.
For example, if the user enters ’|| ’a’ == ’a’ for a user-
name, this can result in the query returning data on all
users. In order to make an application vulnerable to
such an attack, it is necessary to remove all checks on
user input format and ensure that the query is imple-
mented using a WHERE clause. This would not be a
recommended way to access a NoSQL database.
To detect this using distributed tracing data, ei-
ther the call sequence would need to change for
the NoSQL Injection request or the duration of the
system service calls would need to increase. The
call sequence could only be changed if the hacker
could change a number of the service implementa-
tions. Also notice that the duration of the MongoDb
database call is unlikely to change even if a request for
a single user object or for all user objects is executed.
In the second case, the call would return a resulting
database object called a ResultSet of fixed batch size
and execution time will not be appreciably longer that
a request for a single user.
In addition, even if it was possible to obtain a Re-
sultSet of User objects from the database, it would
not be possible to move them between services due
to the well-defined interfaces between the microser-
vices. A ReadUserInfo method is constrained to re-
turn only a single JSON User object.
The conclusion is that even if it were possible to
read a number of users from the database it would
not be possible to detect the attack using distributed
tracing logs.
5 CONCLUSIONS
This report explored our use of the distributed trac-
ing, in particular the Jaeger implementation, to mon-
itor and log user requests to a microservices-based
application. We applied anomaly detection to de-
tect cyber security attacks in the generated log traces.
We see that it is possible to use distributed tracing
Detecting Cyber Security Attacks against a Microservices Application using Distributed Tracing
593

to detect a password guessing cyber security attack.
Distributed tracing is typically used to detect perfor-
mance issues in microservices applications but to the
best of our knowledge, distributed tracing has not pre-
viously been used to detect cyber security attacks.
In particular, we detected a simulated password
guess attack against our application using the gener-
ated distributed traces. Due to the fact that a password
guessing attack can only be detected by examining a
number of requests the technique can be categorized
as group-based anomaly detection. We calculated the
distribution of normal application request traffic, and
compared this distribution to that of the anomalous
data. The frequency distribution for the password at-
tack is further from the normal data than the normal
validation data sets and using the mean and standard
deviation of frequency distance of the validating data
sets, the distance from normal data is greater than two
standard deviations above the mean. This value is a
candidate for an anomaly detection threshold.
We also determined that it is not feasible to de-
tect certain types of cyber-security attacks against a
microservices-based application using this approach.
We argued that it is not possible to detect a type of
NoSQL Injection attack which results in multiple ob-
jects being returned from a NoSQL database instead
of a single object. This would not result in any sub-
stantial changes to the distributed logging data and
hence would not be detectable.
6 FURTHER WORK
At the moment, our work is preliminary and only rep-
resents the behaviour of a microservice application
using sequences of microservice calls. We plan to
use call graphs instead of sequences of calls to rep-
resent behaviour. Call graphs would be comprised of
nodes which correspond to microservices, and edges
corresponding to the calls between the microservices.
Graph-related approaches have previously been used
to model microservices (Aubet et al., 2018) and de-
tect anomalous performance issues in such applica-
tions (Le et al., 2011).
The Euclidean distance metric in Eq. 3 takes no
account of the order in which sequences occur. To ad-
dress this limitation, we intend to train a neural net-
work to learn the normal behaviour of the sequences
of call graphs. A Long Short Term Memory (LSTM)
deep learning network model is suited to modeling se-
quential data and identifying long-term dependencies
in the sequences. Our LSTM model would be used
to assign a probability value to each sequence of call
graphs. An anomaly would be triggered if a sequence
of call graphs was found to have a lower probability
than most sequences. Recent work has demonstrated
that LSTM neural networks can learn the behaviour of
time-series data and subsequently detect anomalous
data (Malhotra et al., 2015) (Nedelkoski et al., 2019).
Finally, we will also examine the possibility of strate-
gic attacks designed to circumvent the anomaly detec-
tion mechanism and examine ways to prevent these
types of attacks.
ACKNOWLEDGEMENTS
This publication has emanated from research con-
ducted with the financial support of Athlone Insti-
tute of Technology under its President’s Seed Fund
(2020) and Science Foundation Ireland (SFI) under
Grant Number SFI 16/RC/3918, co-funded by the Eu-
ropean Regional Development Fund.
REFERENCES
Aubet, F.-X., Pahl, M.-O., Liebald, S., and Norouzian,
M. R. (2018). Graph-based anomaly detection for iot
microservices. Measurements, 120(140):160.
Belmar, C. (2019). A nosql injection primer (with mongo).
Brostoff, S. and Sasse, M. A. (2003). “ten strikes and you’re
out”: Increasing the number of login attempts can im-
prove password usability. Human-Computer Intera-
tion, Security.
Chandola, V., Banerjee, A., and Kumar, V. (2009).
Anomaly detection: A survey. ACM computing sur-
veys (CSUR), 41(3):1–58.
Dhanabal, L. and Shantharajah, S. (2015). A study on
nsl-kdd dataset for intrusion detection system based
on classification algorithms. International Journal of
Advanced Research in Computer and Communication
Engineering, 4(6):446–452.
Gan, Y. and Delimitrou, C. (2018). The architectural impli-
cations of cloud microservices. IEEE Computer Ar-
chitecture Letters, 17(2):155–158.
Gan, Y., Zhang, Y., Cheng, D., Shetty, A., Rathi, P., Katarki,
N., Bruno, A., Hu, J., Ritchken, B., Jackson, B., et al.
(2019a). An open-source benchmark suite for mi-
croservices and their hardware-software implications
for cloud & edge systems. In Proceedings of the
Twenty-Fourth International Conference on Architec-
tural Support for Programming Languages and Oper-
ating Systems, pages 3–18.
Gan, Y., Zhang, Y., Hu, K., Cheng, D., He, Y., Pancholi, M.,
and Delimitrou, C. (2019b). Leveraging deep learn-
ing to improve performance predictability in cloud mi-
croservices with seer. ACM SIGOPS Operating Sys-
tems Review, 53(1):34–39.
Gan, Y., Zhang, Y., Hu, K., Cheng, D., He, Y., Pancholi,
M., and Delimitrou, C. (2019c). Seer: Leveraging big
ICISSP 2021 - 7th International Conference on Information Systems Security and Privacy
594

data to navigate the complexity of performance debug-
ging in cloud microservices. In Proceedings of the
Twenty-Fourth International Conference on Architec-
tural Support for Programming Languages and Oper-
ating Systems, pages 19–33.
Le, D. Q., Jeong, T., Roman, H. E., and Hong, J. W.-K.
(2011). Traffic dispersion graph based anomaly detec-
tion. In Proceedings of the Second Symposium on In-
formation and Communication Technology, pages 36–
41.
Malhotra, P., Vig, L., Shroff, G., and Agarwal, P. (2015).
Long short term memory networks for anomaly detec-
tion in time series. In Proceedings, volume 89, pages
89–94. Presses universitaires de Louvain.
Nagothu, D., Xu, R., Nikouei, S. Y., and Chen, Y. (2018).
A microservice-enabled architecture for smart surveil-
lance using blockchain technology. In 2018 IEEE In-
ternational Smart Cities Conference (ISC2), pages 1–
4. IEEE.
Nedelkoski, S., Cardoso, J. S., and Kao, O. (2019).
Anomaly detection and classification using distributed
tracing and deep learning. In CCGRID, pages 241–
250.
Sun, Y., Nanda, S., and Jaeger, T. (2015). Security-
as-a-service for microservices-based cloud applica-
tions. In 2015 IEEE 7th International Conference
on Cloud Computing Technology and Science (Cloud-
Com), pages 50–57. IEEE.
Toth, E. and Chawla, S. (2018). Group deviation detec-
tion methods: A survey. ACM Computing Surveys
(CSUR), 51(4):1–38.
Detecting Cyber Security Attacks against a Microservices Application using Distributed Tracing
595
