
A Self-adaptive Module for Cross-understanding in Heterogeneous
MultiAgent Systems
Guilhem Marcillaud
1
, Val
´
erie Camps
1
, St
´
ephanie Combettes
1
, Marie-Pierre Gleizes
1
and Elsy Kaddoum
2
1
Institut de Recherche en Informatique de Toulouse, Universit
´
e Toulouse III Paul Sabatier, Toulouse, France
2
Institut de Recherche en Informatique de Toulouse, Universit
´
e Toulouse II Jean Jaures, Toulouse, France
Keywords:
Cross-understanding, Data Imputation, Multi-referential Information, MultiAgent System, Heterogeneous
Agents.
Abstract:
We propose a self-adaptive module, called LUDA (Learning Usefulness of DAta) to tackle the problem of
cross-understanding in heterogeneous multiagent systems. In this work heterogeneity concerns the agents us-
age of information available under different reference frames. Our goal is to enable an agent to understand
other agents information. To do this, we have built the LUDA module analysing redundant information to
improve their accuracy. The closest domains addressing this problem are feature selection and data imputa-
tion. Our module is based on the relevant characteristics of these two domains, such as selecting a subset of
relevant information and estimating the missing data value. Experiments are conducted using a large variety
of synthetic datasets and a smart city real dataset to show the feasibility in a real scenario. The results show an
accurate transformation of other information, an improvement of the information use and relevant computation
time for agents decision making.
1 INTRODUCTION
This paper tackles the problem of cross-
understanding in a heterogeneous MultiAgent
System (MAS) (Wooldridge, 2009). In such a system
each agent has a local view of its environment and
its own understanding of this view i.e. its reference
frame (Hoc and Carlier, 2002). To enable an agent
to use its perception, the agent decision-making
process is adapted to its reference frame. In this
work, we define two agents as heterogeneous when
their reference frame is different. As information
communicated by an agent is shared according to its
reference frame, different agents will have trouble to
understand each other. In systems where cooperation
is needed, understanding problems may lead to
non-cooperative situations (Georg
´
e et al., 2011).
The cross-understanding problem can be encoun-
tered in several problems. For example, let consider
the Internal Decision Layer of an Autonomous Vehi-
cle (Loke, 2019). It is designed to take a decision with
information from a set of sensors perceiving informa-
tion in a reference frame (speed 30 km/h). To enrich
its world understanding the vehicle may have access
to other vehicles information through communication
(speed 18.64 mph). However, a reference frame dif-
ference is an obstacle to the correct use of this infor-
mation.
The studied problem possesses characteristics
from the Feature Selection (Gibbons et al., 1979) and
Data Imputation (Efron, 1994) fields. The Feature Se-
lection one consists in learning the feature from the
set of communicated information that is related to the
missing feature (Li et al., 2017). The Data Imputation
field focuses on estimating missing data from past ob-
servations (Van Buuren, 2018).
This paper addresses the problem of enriching the
understanding of an agent in a MAS using informa-
tion from neighbour agents having their own refer-
ence frame. This can be decomposed into two sub-
problems: 1) enable an agent to understand commu-
nication from heterogeneous agents and 2) improve
the information value using multiple sources (Zhao
and Liu, 2008).
For the first sub-problem, the module we have
developed, called LUDA (Learning Usefulness of
DAta), supposes the existence of a linear relationship
(Montgomery et al., 2012) between two data repre-
senting the same information in different reference
frames. As LUDA aims at being added to an already
Marcillaud, G., Camps, V., Combettes, S., Gleizes, M. and Kaddoum, E.
A Self-adaptive Module for Cross-understanding in Heterogeneous MultiAgent Systems.
DOI: 10.5220/0010298503530360
In Proceedings of the 13th International Conference on Agents and Artificial Intelligence (ICAART 2021) - Volume 1, pages 353-360
ISBN: 978-989-758-484-8
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
353

functioning agent decision-making process the com-
putation impact must be limited. Thus, we strongly
emphasise the requirement for a limited number of
histories necessary to learn reference frame transfor-
mation.
Once the agent is able to transform different ref-
erence frames, it has access to multiple sources of
the same information and focuses on the second sub-
problem. This information redundancy can be used
to improve the accuracy in a noisy environment (Hall
and Llinas, 1997). To enable that, we extended LUDA
with a novel agent behaviour that combines multiple
information instances of the same information.
This paper is organised as follows: in section
2 that starts with an overview of Feature Selection
and Data Imputation, we propose a description of the
cross-understanding problem presented in this paper.
From this description, section 3 describes the LUDA
system. Section 4 discusses several experiments as-
sessing the effectiveness of LUDA. Finally, section 5
concludes the paper and presents some perspectives.
2 STATE OF THE ART AND
PROBLEM FORMALISATION
Cross-Understanding in MAS is a problem that has
not been studied much even if the problem character-
istics are not new. From existing works, we have iden-
tified two domains, feature selection and data im-
putation, that possess similar characteristics with the
cross-understanding problem. Indeed, in the studied
problem, an agent has access to its own perceptions
and to those of its neighbours agents through com-
munications. Thus, the agent with missing percep-
tions can complete them from perceptions of neigh-
bour agents. This can be seen as a feature selection
problem. However, in our case, the heterogeneity
of agents reference frame makes the feature selec-
tion unsatisfactory because selected perceptions are
not always usable and an estimation of their relation-
ship with the known perception is needed. This is-
sue can be seen as a data imputation problem. Thus,
the cross-understanding problem in a heterogeneous
MAS consists for an agent to be able to select, from
its neighbouring agents perceptions, missing infor-
mation while translating them into its own reference
frame.
2.1 Feature Selection
The issue of variable and feature selection has been
extensively studied in recent years. This problem con-
sists in finding the most relevant variables to use (Gib-
bons et al., 1979) in different contexts, such as data
mining, to reduce the computation time (Duda et al.,
2006), biology to avoid a genetic study, medicine to
understand the cause of a disease (Niel and Sinoquet,
2018), simulation to select the best experiments con-
ditions (Ryzhov et al., 2012) or statistical studies re-
lated to economics.
In an intelligent and complex environment such
as a connected house or an intelligent vehicle, the ob-
servation of the environment comes from a multitude
of sensors. The noise and the redundancy of the per-
ceived data have to be taken into account. To avoid re-
dundancy as much as possible, the multi-source meth-
ods proposed by (Zhao and Liu, 2008) and Multi-view
methods (Wang et al., 2013) are used.
Difference with LUDA. More and more complex
feature selection problems are solved thanks to recent
advancements. One still remaining limitation con-
cerns the storage space needed to achieve accurate
results. Methods usually use a large amount of data
either received or continuously perceived (Li et al.,
2017). This can be problematic for some real case
problems when available computation time is limited.
As feature selection considers a problem with
multiple features for one result. Its objective is to re-
duce the features number to only keep the most rele-
vant ones without changing their value. As the deci-
sion process is a black box, the decision about which
data to choose follows the same issue as ours. Our
stated problem differs as it consists in replacing an
already known feature by another expressed in a dif-
ferent reference frame.
2.2 Data Imputation
Data imputation is the field that focuses on estimat-
ing the value of missing data using multiple histories.
This field addresses the issue of incorrect or missing
data (due to non-functioning or non-available sensors)
and improving data quality in noisy environments
(Marwala, 2009). Usually, data imputation methods
complete the existing dataset (containing enough ob-
servation) or estimate information in real-time from
the previous observation (Marwala, 2009).
Several methods are available for estimating miss-
ing data, which are classified into two categories:
mathematical (Van Buuren, 2018) and artificial intel-
ligence ones (Kumar et al., 2013). The most used
mathematical technique, the regression analysis (Liu
et al., 2018) enables to describe the relationships be-
tween information.
In the field of artificial intelligence, neural net-
works are highly used (Heaton, 2008). Radial Basis
Function Network, a particular family of neural net-
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
354
works, is effective for regressions and functions ap-
proximation (Zhang and Suganthan, 2016) but has a
cost of computation and storage.
In data imputation field, systems learn to esti-
mate new data values from previously observed data.
In contrast, in the cross-understanding problem, the
missing data is available but in a different reference
frame. Moreover, the correct data is lost among the
massive amount of available data. Using data imputa-
tion method for every available data is time consum-
ing and the cost of observation history would not be
adapted to real-time constraint applications.
2.3 Cross-understanding Formalisation
In the cross-understanding problem, an agent among
the agents set perceives from its environment several
information that we have classified into two subsets.
The first subset called principal data (P
D
= {p
d
i
})
refers to information directly linked to the agent sen-
sors (i being one of the agent sensors) and which this
agent can understand. The second subset called ex-
tero data (E
D
= {e
d
j
}) refers to information com-
municated by its neighbouring agents ( j being one of
the agent neighbours), each having its own reference
frame. The cross-understanding problem in hetero-
geneous MAS consists for an agent in being able to
select from E
D
missing information of P
D
while trans-
lating them into its own reference frame.
The main objective of cross-understanding is to
enable an agent to use e
d
j
communicated by a neigh-
bour agent j to replace missing p
d
i
one for its deci-
sion process. The decision process uses a function
f and computes a result r to solve a situation. f is
considered as a black box taking a fixed number of
principal data p
d
i
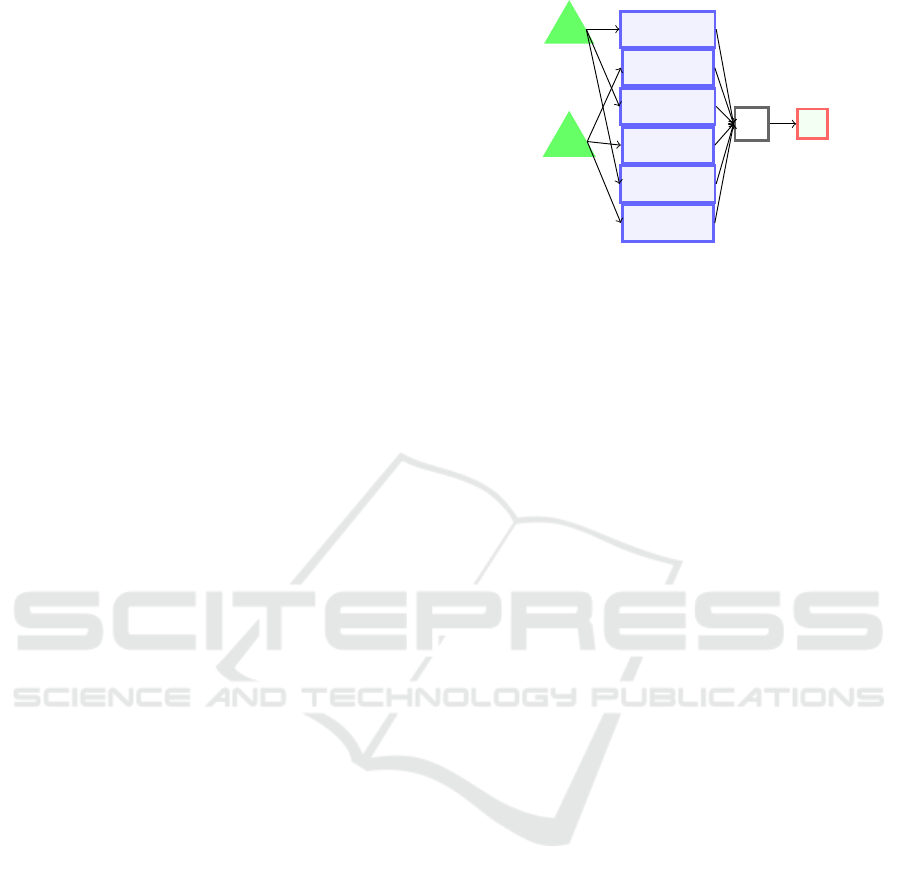
as inputs. The figure 1 illustrates an
example with 6 inputs, 3 p
d
i
(p
d
1
, p
d
3
, p
d
5
) and 3 e
d
j
(e
d
2
,e
d
4
,e
d
6
).
When all principal data are available the computed
result is considered as the ideal one noted r
ideal
. When
the principal data are missing, the objective is to find
the right extero data e
d
j
to replace them while min-
imising the difference between r
ideal
and r obtained
by f using e
d
j
.
For an agent, the problem can be formalised as
follow.
Given P
D
= {p
d
i
} and E
D
= {e
d
j
}
For Each p
d
i
∈ {P
D
}:
1. select e
d
j
∈ {E
D
} that can be linked to p
d
i
2. determine the two coefficients x and y such as
p
d
i
= x × e
d
j
+ y
i
1
(= p
d
1
)
P
D
E
D
i
2
(= e
d
2
)
i
3
(= p
d
3
)
i
4
(= e
d
4
)
i
5
(= p
d
5
)
i
6
(= e
d
6
)
f
r
Figure 1: The function f computes the result r using prin-
cipal data for i
1
,i
3
,i
5
and extero data for i
2
,i
4
,i
6
.
While Minimising:
r =
nbInput
∑
k=0
|p
d
i
− e
d
k
| (1)
As different and several e
d
j
can be available for one
p
d
i
the LUDA’s second objective is to take advantage
of this multi-source to improve the accuracy of the
proposed values for p
d
i
, especially in a noisy environ-
ment.
3 THE ADAPTIVE MULTIAGENT
SYSTEM LUDA
This section presents LUDA a MultiAgent System
(MAS) enabling an agent to translate any data com-
municated into its reference frame.
3.1 MAS Overview
A MAS is composed of multiple interacting and au-
tonomous entities known as agents. An agent is
able to perceive a local part of its environment and
acts with this partial knowledge to autonomously
solve its own goals (Wooldridge, 2009). The MAS
paradigm is highly efficient to solve complex prob-
lems thanks to the local and distributed computation
between agents (Serugendo et al., 2003).
An agent in LUDA respects the following proper-
ties: (i) it is autonomous, it decides alone its actions,
(ii) it interacts with neighbour agents to achieve its
goal, (iii) it has a partial view of the environment, (iv)
it has negotiating skills, and (v) it acts in a dynamic
and continuously evolving environment. In addition,
each agent possesses a characteristic named critical-
ity. Criticality is a numerical value that represents the
degree of non-satisfaction of the agent goals, which
impacts the agent behaviour.
A Self-adaptive Module for Cross-understanding in Heterogeneous MultiAgent Systems
355

3.2 LUDA Agents
We propose a MAS-based module to enable an agent
to understand communications from heterogeneous
agents. Based on the problem formalisation in section
2.3, we identified three types of agents: data agents,
morph agents and group agents as well as one en-
tity, the Decision Process (DP). The decision process
is a black box only able to compute a result with val-
ues given by agents (it corresponds to the f function
in fig. 1).
Data Agents. For each information (belonging ei-
ther to E
D
or P
D
) a data agent is created and associ-
ated with it. The objective of each data agent is to
find the other data agents representing the same in-
formation in a different reference frame. Let remind
that in this work, we assume that two different data
representing the same information are linked by a lin-
ear transformation: d
1
= x × d
2
+ y. To achieve this
objective, a data agent creates as many morph agents
as other data agents in the environment.
Morph Agents. Once created a morph agent is
associated with two data agents: its creator d
c
and
the objective one (d
o
) which is one of the data agents
of the environment. The morph agent goal is to find
values of linear coefficients that help its d
c
to approx-
imate the best linear transformation towards the value
of its d
o
. To modify the coefficient values, the morph
agent uses an adaptation strategy exploiting the crit-
icality. The criticality of a morph agent is computed
from the error of the worst situation encountered dur-
ing its operation (i.e. a situation where the agent has
decided to accelerate instead of brake). From a sit-
uation, the morph agent stores as an observation the
d
c
value and the d
o
value. The observation is eval-
uated by comparing the d
c
value transformed by the
morph agent with the d
o
value acquired during this
observation (cf. equation 2). An observation is eval-
uated each time the coefficients are modified. As the
scale of each reference frame is different, the differ-
ence value needs to be normalised using the principal
data range enabling the morph agents to interact with
each other.
crit(ma) = argmax(
|(x × d
c
+ y) − d
o
|
range(d
o
)
) (2)
Instead of using a linear regression, morph agents use
an adaptation process to compute coefficients. This
process aims at reducing the memory required for
all morph agents. Indeed, the more available ob-
servations, the more accurate the linear transforma-
tion. However, the amount of memory increases as
the number of observations increases. As the required
memory has to stay at a ”reasonable” level, we pro-
pose to store in memory only the observations with
the highest error to adapt the coefficients x and y.
Observations selection relies on the observation rele-
vance. Relevance is the difference between the princi-
pal data value and the value transformed by the morph
agent. From the three worst observations that it keeps
in memory, the agent computes the best coefficients
to satisfy them. Then, it computes its new coefficients
using a weighted sum of the old coefficients and the
best ones. The weight used is ω ∈ [0.1, 0.9]. The
higher ω, the higher the impact on new coefficients.
Using its new coefficients a morph agent modifies the
relevance of observations it has in memory.
This behaviour enables to observe two trends: ei-
ther the criticality decreases until it converges around
a low value with the augmentation of observed situ-
ations, either no convergence is observed. The first
trend occurs when a linear relation exists between
both the data objective and the data agent. In other
words, a low criticality means that the morph agent
is able to transform the reference frame of its d
c
into
its d
o
. A morph agent unable to reduce its criticality
is considered useless and consequently, it destroys it-
self. However, to avoid inappropriate destruction be-
cause of a slow adaptation, a morph agent considers
itself useless only if its criticality is high and if an-
other morph agent from the same data agent has a
low criticality.
Group Agents. As different e
d
j
represent the
same d
p
i
, we introduced a third agent type called
group agent. A group agent is always linked to at
least one data agent. A group agent aims at having
the most reliable value to give to the Decision Process
DP and to reach this goal, it tries to regroup several
data agents together.
The environment of a group agent is composed of
all the other group agents of the environment, the data
agents linked to it and the DP. A group agent can ex-
ecute four types of action: 1) propose one of its data
agent to another group agent, 2) propose a merging
with another group agent, 3) exclude a data agent
and 4) send a value to a DP. A group agent eval-
uates its criticality using formula 3 according to the
adequacy of all its data agents. The adequacy of the
data agent da
i
with the data agent da
j
is the criti-
cality computed by the morph agent of da
j
. A group
agent tries to have as much data agents as possible.
The parameter δ ∈ [0.0,2.0] models the group agent
will to link a new data agent. The highest δ is, more
easy is to link a new data agent.
crit
ga
=
∑
(i=0, j=1,i6= j)
(crit(ma
da
i
,da
j
) − δ)
nbDataAgentInGA
(3)
From this formula, the criticality of a group agent
strongly depends on which data agent is inside the
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
356

group. To lower its criticality, a group agent wants to
exclude high critical data agents, and enables those
data agents to be available to join another group.
Each group agent evaluates the impact of the integra-
tion of the proposed data agent from a criticality point
of view. If the integration reduces the group agent
criticality, the data agent is accepted. When no group
is willing to host the data agent, it is expelled and
associated with a new group agent. This new group
agent contains this unique data agent. However, as
adding a new low critical, data agent decreases the
overall criticality of the group agent, this latter is will-
ing to be linked to the most data agents possible in
order to reduce the impact of noisy information.
A group agent also has the possibility to merge
with another group agent if they both possess data
agents representing the same information. The merg-
ing decreases the adequacy of its data agents. How-
ever, it must not lead to the expulsion of one data
agent of the group. In the same way as the propo-
sition of hosting a data agent, two group agents can
evaluate if the resulting merging is less critical than
remaining separated.
Finally, a group agent aims to propose a value
to the DP. A group agent sends a proposition for an
input i of the DP. To increase the accuracy, the group
agent adapts the proposed value of each available data
agent for the input. A group agent associates a weight
w
j
with each data agent to which it is linked. Those
weights enable it to compute the value sent to the DP
according to equation 4.
value
ga
=
∑
i=0
w
i
∗ da
i
∑
i=0
w
i
(4)
Once the value proposed to the DP, the group agent
receives the DP feedback which is the ideal value.
Then, the group agent adapts the weights to improve
its accuracy for the next time. Each data agent has
a noisy value. Some sensors overestimate, others un-
derestimate the same information and some sensors
are more accurate than others. A group agent adapts
the weight of each data agent according to the value
they have given. The most accurate data agents are
rewarded with an increase in their weight, while other
weights are reduced. In addition, a group agent in-
creases the weight of data agents whose value would
impact positively the group agent value if its weight
was higher. Equation 5 is used by a group agent to
modify the weight of its data agents. With α, β and γ
the parameters used to modify the evolution speed of
the weight and V the value of the entity (i for the data
agent, DP for the decision process and ga the group
agent). After several experiments exploring those pa-
rameters, the values α = 0.1, β = 0.05 and γ = 1/30
have been chosen.
w
i
=
w
i
+ α if |V
i
−V
DP
| < V
ga
−V
DP
|
w
i
− γ if |V
i
−V
DP
| > |V
ga
−V
DP
|
w
i
+ β if V
DP
∈]V
ga
,V
i
[ or V
DP
∈]V
i
,V
ga
[
(5)
3.3 Resolving Objectives through
Agents Interactions
In MAS, interaction between agents can lead to a
global phenomenon called emergence. This section
describes the emergence of the objectives from the in-
teractions of agents.
First Objective: Replacing Missing Data. This
first objective is achieved thanks to interactions of
data and morph agents. The e
d
i, j
replacing a missing
p
d
is selected according to its adequacy with p
d
. After
several resolution cycles, we observe a reduction of
the morph agents number linked to a data agent. The
remaining morph agents achieve an accurate transfor-
mation of the reference frame. As a consequence, a
data agent is able to replace a missing p
d
still linked
to the morph agent.
Second Objective: Improving the Reliability of
Information. This second objective enables to over-
come the noisy data problem. As the data agent
can now translate its value into a different reference
frame, it is interesting to group together related e
d
and p
d
to extract the most accurate value from the
group so formed, thus taking advantage of the multi-
source information to reduce the noise. At the be-
ginning, group agents are, at the most, as many as
data agents. After several resolution cycles (cf sec-
tion 4.1), related data agents have a strong adequacy
and the group agents linked together merge. By con-
sequence, the number of group agents decreases and
the remaining group agents have more related data
agents. The value sent by a group agent to the DP is
the combination of all the linked data agents values.
4 EXPERIMENTATION
This section aims at evaluating the LUDA system
with a large number of experiments. Most used
datasets are synthetically generated to verify the lin-
ear transformation hypothesis and have a significant
amount of different data. A real smart city dataset has
been modified using real translations to experiment on
real data.
A Self-adaptive Module for Cross-understanding in Heterogeneous MultiAgent Systems
357
4.1 Metrics
The efficiency of the LUDA method is evaluated us-
ing several metrics:
1. the accuracy of morph agents adaptation (the
transformed value is compared to the correct one);
2. the resulting group: complete or incomplete
group, misplaced or excluded data agent;
3. the impact of the values sent to the DP on the re-
sult of equation 1;
4. the time required to complete an adaptation cycle;
5. the number of remaining agents.
The different experiments consider several environ-
ments with various number of i) principal data and of
ii) extero data per principal data.
All the experiments last 200 cycles of resolution.
A resolution cycle consists in : 1) each group agent
computes a value to give to the DP; 2) each morph
agent receives the DP feedback and adapts its coeffi-
cients; 3) each group agent receives the feedback and
adapts the data agents weight and 4) group agents re-
organise themselves.
4.2 Experimentation with Noisy Data
Noise is added to each dataset using one of the three
Gaussian-based strategies : 1) every data is altered us-
ing a Gaussian noise with identical distribution; 2) the
Gaussian distribution is different for each data and 3)
the data value is always over or below the true value.
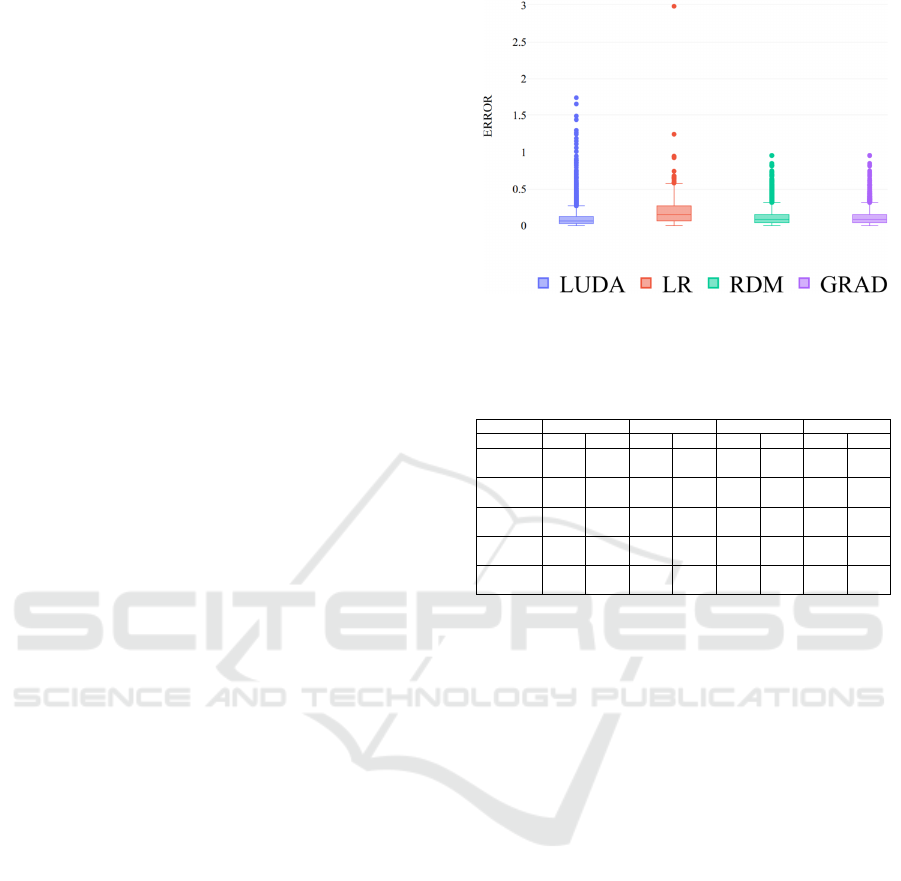
Similarities of Translation Functions. This sec-
tion assesses the effectiveness of the morph agent
learning. We compare our results to state-of-the-art
methods that are linear regression (LR), Random for-
est regression (RDM) and Gradient Boosting Regres-
sion (GRAD). Figure 2 shows the value difference
between the true data and data estimated with impu-
tation methods. For visualisation purposes, only 100
cycles are displayed. We observe that even if the error
is lower using LUDA, some peaks have arisen, which
has a negative impact on the overall result. A peak
represents a situation where a morph agent was not
efficient to transform the value of its data agent.
Formed Groups. Table 1 shows the resulting
groups at different resolution cycles. Data is well-
placed when it shares the same group as their related
p
d
. A group is completed when all the data agents
representing the same information in various refer-
ence frames are grouped together. In an environment
with no noise or with same noise, group accuracy is
high. In case of different noise values, the noisiest
observations are stored in memory to be used for the
Figure 2: Difference between the true data and data esti-
mated with LUDA, LR, RDM and GRAD.
Table 1: Formed Groups result according to the percentage
of Completed Groups (CG) and Well-Placed Data (WPD).
Cycle 30 90 150 180
Metric CG WPD CG WPD CG WPD CG WPD
68 data
No noise
100 100 100 100 100 100 100 100
68 data
5% noise
88.24 92.65 88.26 95.59 94.11 95.59 94.11 98.53
68 data
Diff noise
70,59 85,29 88,24 97,06 64,71 88,24 64,71 85,29
192 data
Diff noise
75,51 90,10 73,47 94,27 73,47 91,15 71,43 90,63
392 data
Diff noise
73,74 89,54 75,76 92,86 76,77 92,09 78,79 93,62
adaptation. Noise degrades the efficiency of the ade-
quacy computation, leading to less efficient agent in-
teractions and fusion.
Decision Process Result Difference. This section
explores the advantages of using several data using
the LUDA system in a noisy environment. Figure 3
shows the value difference between the principal data
and the one adapted by a group agent following equa-
tion 1. The effectiveness of LUDA compared to using
only known data depends on the noise nature (simi-
lar or different Gaussian, overestimation and under-
estimation). LUDA is more effective when different
sources underestimate or overestimate. The peaks ob-
served in figure 2 have a direct negative impact on the
DP result. A LUDA improvement would be to detect
when the value of a data agent is really far from those
proposed by the other data agents in the same group.
4.3 Exploration of the Computation
Time
To explore the computation time, experiments con-
sider the number of remaining agents compared to the
objective (metric 5 in 4.1), and the time to achieve a
resolution cycle.
Figures 4 and 5 show impact of the data number
on computation time. In the worst-case scenario, all
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
358
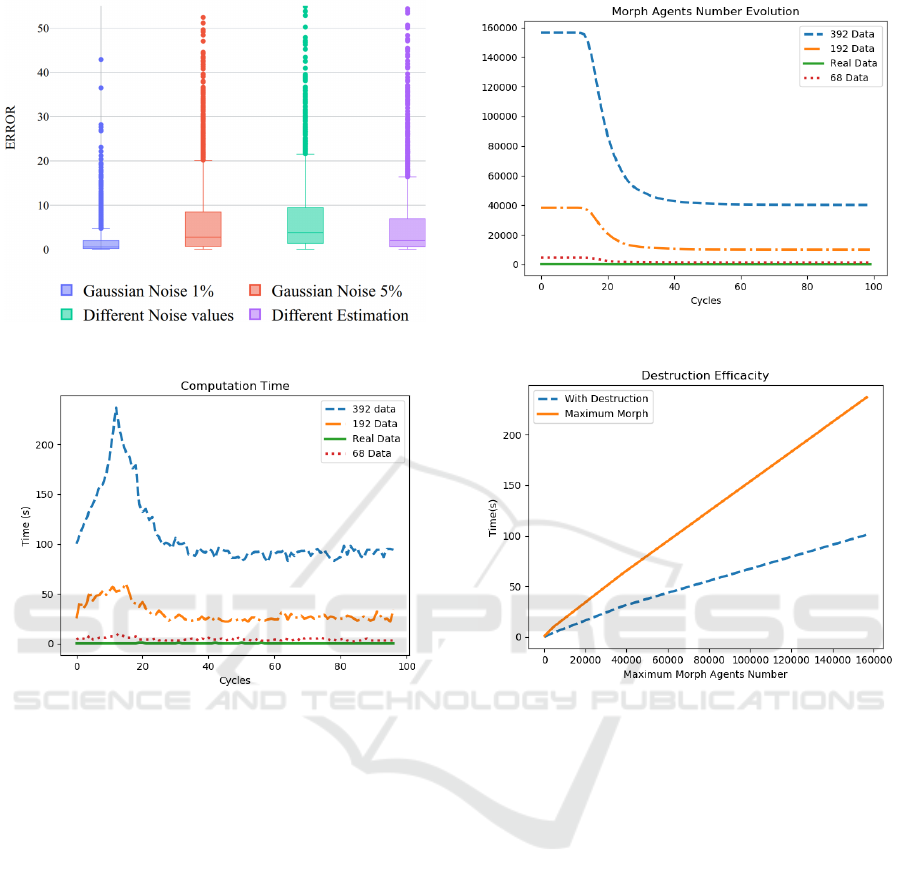
Figure 3: Effectiveness of LUDA on different noise values.
Figure 4: Evolution of the morph agents coefficients adap-
tation.
data are available and each data agent has created a
morph agent to link it with a data agent. During the
coefficients adaptation of morph agents, the destruc-
tion of useless morph agents decreases the computa-
tion time as seen in figure 4. A peak has arisen at
cycle 17 and then the number of remaining morph
agents reduces until the 35
th
cycle from which it is
stabilised.
In a real case with computation time constraints,
the number of data to process in one cycle should be
limited. A solution would be to give priority to crit-
ical morph agents while non-critical ones would not
adapt. Figure 6 assesses the effectiveness of destroy-
ing useless morph agents, on the computation time.
5 CONCLUSION AND
PERSPECTIVES
In this paper, we presented the MAS-based LUDA
module to address the cross-understanding in MAS.
Figure 5: Evolution of the morph agents number.
Figure 6: Difference between keeping morph agents and
enabling them to destroy themselves.
Heterogeneity of agents reference frame can be an
obstacle to the cooperation resolution of a MAS in
multi-sources context. Thanks to the interactions of
three types of agents, the LUDA module achieves
two objectives: 1) translate information from a ref-
erence frame to another one and 2) reduce the noise
by grouping similar information from different refer-
ence frames. The low number of observations enables
to add the LUDA module to an agent in operation.
We are currently working on using LUDA in the
real context of Connected and Autonomous Vehicles
(CAVs). Using LUDA in the Internal Decision Layer
of a CAV should enable it to understand any commu-
nication. The different reference frames used by each
vehicle constructor may impact communications be-
tween CAVs. In this context, LUDA could translate
a value communicated by a CAV and enable coopera-
tive strategies.
We plan to improve the morph agent learning al-
gorithm to enable it to learn non-linear function with
a small loss of effectiveness. The approximation of a
A Self-adaptive Module for Cross-understanding in Heterogeneous MultiAgent Systems
359

non-linear function in addition to several linear func-
tions is currently under study. A further study will
be conducted with three objectives: 1) improving
the adaptation of morph agents to include non-linear
transformations; 2) reducing the computation time of
the data agent displacement between groups by re-
ducing the necessity for a group to know every other
group; 3) reducing initial computation time by giving
a cooperative strategy to morph agents to select only
the one that needs adaptation the most. Furthermore,
group values adaptation can be improved by estimat-
ing the noise of each data agent.
ACKNOWLEDGEMENTS
This work is part of the neOCampus opera-
tion of the University Toulouse III Paul Sabatier.
www.neocampus.org
REFERENCES
Duda, R. O., Hart, P. E., et al. (2006). Pattern classification.
John Wiley & Sons.
Efron, B. (1994). Missing data, imputation, and the boot-
strap. Journal of the American Statistical Association,
89(426):463–475.
Georg
´
e, J.-P., Gleizes, M.-P., and Camps, V. (2011). Co-
operation. In Di Marzo Serugendo, G., Gleizes, M.-
P., and Karageorgos, A., editors, Self-organising Soft-
ware: From Natural to Artificial Adaptation, pages
193–226. Springer, Berlin Heidelberg.
Gibbons, J. D., Olkin, I., and Sobel, M. (1979). An intro-
duction to ranking and selection. The American Statis-
tician, 33(4):185–195.
Hall, D. L. and Llinas, J. (1997). An introduction to multi-
sensor data fusion. Proceedings of the IEEE, 85(1):6–
23.
Heaton, J. (2008). Introduction to Neural Networks for
Java, 2nd Edition. Heaton Research, Inc., 2nd edition.
Hoc, J.-M. and Carlier, X. (2002). Role of a common frame
of reference in cognitive cooperation: sharing tasks
between agents in air traffic control. Cognition, Tech-
nology & Work, 4(1):37–47.
Kumar, K., Parida, M., and Katiyar, V. (2013). Short term
traffic flow prediction for a non urban highway using
artificial neural network. Procedia - Social and Be-
havioral Sciences, 104.
Li, J., Cheng, K., Wang, S., Morstatter, F., Trevino, R. P.,
Tang, J., and Liu, H. (2017). Feature selection: A data
perspective. ACM Computing Surveys, 50(6):1–45.
Liu, T., Wei, H., and Zhang, K. (2018). Wind power predic-
tion with missing data using gaussian process regres-
sion and multiple imputation. Applied Soft Comput-
ing, 71:905 – 916.
Loke, S. W. (2019). Cooperative automated vehicles: A
review of opportunities and challenges in socially in-
telligent vehicles beyond networking. IEEE Transac-
tions on Intelligent Vehicles, 4(4):509–518.
Marwala, T. (2009). Computational Intelligence for Miss-
ing Data Imputation, Estimation, and Management:
Knowledge Optimization Techniques. IGI Global, 1st
edition.
Montgomery, D. C., Peck, E. A., and Vining, G. G. (2012).
Introduction to linear regression analysis. John Wiley
& Sons.
Niel, C. and Sinoquet, C. (2018). Optimisation par colonie
de fourmis pour la s
´
election de variables par con-
struction stochastique de couverture de Markov - Ap-
plication pour la m
´
edecine de pr
´
ecision. In 19th
edition of the annual congress of the French Soci-
ety for Operation Research and Decision Assistance,
ROADEF2018, Lorient, France.
Ryzhov, I. O., Defourny, B., and Powell, W. B. (2012).
Ranking and selection meets robust optimization. In
Proceedings of the 2012 Winter Simulation Confer-
ence (WSC), pages 1–11.
Serugendo, G. D. M., Foukia, N., Hassas, S., Karageorgos,
A., Most
´
efaoui, S. K., Rana, O. F., Ulieru, M., Valck-
enaers, P., and Van Aart, C. (2003). Self-organisation:
Paradigms and applications. In International Work-
shop on Engineering Self-Organising Applications,
pages 1–19. Springer.
Van Buuren, S. (2018). Flexible imputation of missing data.
CRC press.
Wang, H., Nie, F., and Huang, H. (2013). Multi-view clus-
tering and feature learning via structured sparsity. In
Dasgupta, S. and McAllester, D., editors, Proceed-
ings of the 30th International Conference on Machine
Learning, volume 28, pages 352–360, Atlanta, Geor-
gia, USA.
Wooldridge, M. (2009). An introduction to multiagent sys-
tems. John Wiley & Sons.
Zhang, L. and Suganthan, P. (2016). A survey of random-
ized algorithms for training neural networks. Informa-
tion Sciences, 364-365:146 – 155.
Zhao, Z. and Liu, H. (2008). Multi-source feature se-
lection via geometry-dependent covariance analysis.
In Saeys, Y., Liu, H., Inza, I., Wehenkel, L., and
de Pee, Y. V., editors, Proceedings of the Workshop on
New Challenges for Feature Selection in Data Min-
ing and Knowledge Discovery at ECML/PKDD 2008,
volume 4, pages 36–47, Antwerp, Belgium. PMLR.
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
360
