
Occluded Iris Recognition using SURF Features
Anca Ignat
1
and Ioan Păvăloi
2
1
Faculty of Computer Science, University “Alexandru Ioan Cuza” of Iași, Romania
2
Institute of Computer Science, Romanian Academy Iaşi Branch, Iaşi, Romania
Keywords: Iris Recognition, SURF, Occluded Iris Images, Manhattan Distance.
Abstract: In this paper we study the problem of the recognition process for iris images with missing information. Our
approach uses keypoints related features for solving this problem. We present our recognition results obtained
using SURF (Speeded-Up Robust Features) features extracted from occluded iris images. We tested the
influence on the recognition rate of two threshold parameters, one linked with the SURF extraction process
and the other with the keypoint matching scheme. The proposed method was tested on UPOL iris database
using eleven levels of occlusion. The experiments show that the method we describe in this paper produces
better results than Daugman procedure on all considered datasets and the results we previously obtained using
SIFT features. Comparisons were also performed with iris recognition results that use colour for iris
characterization, computed on the same databases of irises with different levels of missing information.
1 INTRODUCTION
There are many applications that use iris biometric
features for automatic security and access control.
This type of authentication that uses iris information
is a non-invasive technology which provides a highly
reliable solution. Generally, irises have a unique
structure for each human being as those provided by
fingerprints or the network of retinal blood vessels.
For each person, the iris has a unique texture pattern
that allows the process of person recognition. It’s true
that one major limitation is related to the image
acquisition conditions, when images of the iris with
occluded parts, or bad illumination can interfere with
the recognition process. These types of problems
require special approaches in order to have acceptable
iris recognition results. One way to treat this problem
is by using keypoint detectors that help extract the
essential iris information.
Since the development of the famous Iris Code
(Daugman, 1993, 2015), a lot of research was
conducted on the problem of iris recognition. An
excellent review of the methods and research
directions in this field can be found in (Bowyer &
Burge, 2016). De Marsico, Petrosino & Ricciardi,.
(2016) and Harakannanavar & Puranikmath (2017)
provide also excellent reviews on the iris recognition
problem. In the pandemic context, when faces are
covered by mask, the iris recognition problem
becomes of increased interest. Nguyen et al. (2017)
present the research on long range iris recognition.
Rattani & Derakhshani (2017) present a survey of
methods that are analysing not only the iris but the
entire region of the eye. A very interesting approach
using deep learning tools are considered in Nguyen
et
al. (2017).
Considering the iris recognition problem with
SURF descriptors, in (Ali et al., 2016) the effect of
different enhancement methods as CLAHE, HE
(Histogram Equalization), AHE (Adaptive Histogram
Equalization) and classical matching procedure are
tested. The method is tested on CASIA dataset and
the results are compared with those obtained using
SIFT, HOG, MSER and DAISY descriptors. The best
results are in range 99.5% to 100% and are obtained
with CLAHE. Mehrotra, Sa & Majhi (2013) propose
a new iris segmentation procedure. The SURF
features are extracted after segmentation. Image
matching is performed using the Euclidean distance
and the nearest neighbour ratio procedure.
Experiments are conducted on different iris datasets:
BATH, with the best results of 98.24%, UBIRIS, with
96.58%, and CASIA with 97.32%. The authors state
that their method is robust to scale changes and
rotations, occlusion and illumination changes. In the
experiments performed on CASIA dataset by Bakshi
et al. (2012), both SIFT and SURF features are
extracted, the matching between two images being
performed in three stages. After, the matching scores
are combined.
508
Ignat, A. and P
˘
av
˘
aloi, I.
Occluded Iris Recognition using SURF Features.
DOI: 10.5220/0010255405080515
In Proceedings of the 16th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2021) - Volume 5: VISAPP, pages
508-515
ISBN: 978-989-758-488-6
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
Mehrotra, Majhi & Gupta (2009) apply SURF
keypoint detection on the annular iris image. The
usual normalization step is skipped to preserve as
much iris information as possible. The matching
procedure uses the Euclidean distance between the
local features, two keypoints are paired if the distance
between them is less than a fixed threshold. Three
datasets are used in experiments, CASIA, BATH and
IITD. In other experiments, Ismail, Ali & Farag
(2015) before computing the SURF descriptors,
CLAHE (Contrast Limited Adaptive Histogram
Localization) enhancement technique is applied. The
experiments are made on CASIA dataset. The
matching procedure uses a fusion process of the
scores obtained at different levels, the results range
from 99.5% to 100%.
Păvăloi & Ignat (2018) introduce a new method
for handling occluded iris images, using colour
features. In Ignat & Vasiliu (2019) the problem of
missing information is approached with an inpainting
procedure. In Păvăloi & Ignat (2019b) SIFT
descriptors are employed for solving the problem of
iris recognition for irises with missing information.
We compute SURF descriptors in the present
work and use them for iris recognition. For testing our
method we used the original and the standardized
segmented UPOL iris databases. For simulating the
missing information situations, starting from UPOL
dataset, we generated eleven datasets with different
levels of occlusion. SURF feature extraction
algorithm and the matching procedure depend on
some threshold parameters. We tested the impact of
these thresholds on the recognition results. We
compare the results of our experiments with those
obtained using Daugman procedure, implemented by
Masek and with Păvăloi & Ignat (2109a, 2019b)
results. We obtain better recognition rates on nine out
of eleven datasets.
In Section 2 the datasets used in the experiments
are presented. Section 3 outlines the SURF features
extraction process and the recognition method. In
section 4 are presented the results and the conclusions
as well as future directions of research are stated in
Section 5.
2 DATABASES
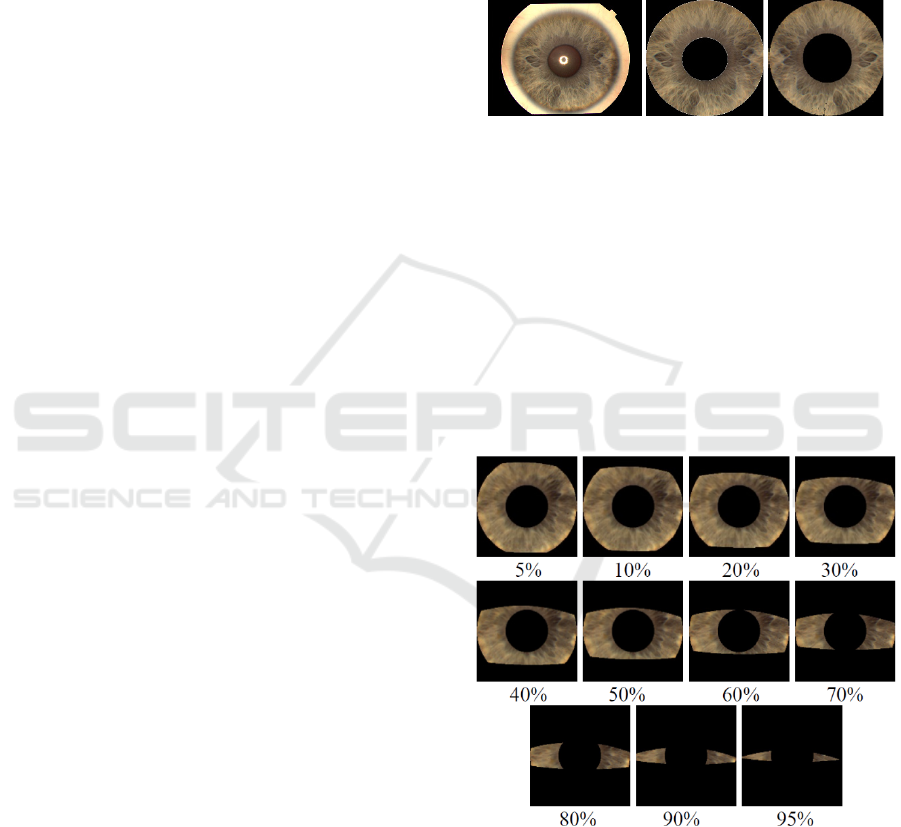
For our computations we used the well-known UPOL
iris dataset (Dobeš et. Al, 2006, 2004) .This dataset
consists of iris images in .PNG format, all the images
having the same dimensions 576 × 768 × 3 pixels (see
the first image from Fig. 1). The collection contains
iris images for 64 persons, six images for each
individual, three for the right eye and three for the left
eye. The background of all these images is black. We
first performed some experiments on the datasets that
contain irises with full information. We have three
versions for UPOL dataset, the original unsegmented,
a manually segmented version (Păvăloi, Ciobanu &
Luca, 2013) and a standardized segmented collection
(Ignat, Luca & Ciobanu, 2016). In Fig. 1, a sample
from each of these datasets are shown.
(a) (b) (c)
Figure 1: Examples of images in UPOL database: (a) -
original, (b)- manually segmented, (c) – automatically
segmented and standardized.
We performed some computations in order to
decide which of the three versions of these datasets to
further use in our experiments. The original,
unsegmented dataset produced results that were
inferior to those obtained on the other two datasets.
The difference between the recognition rates obtained
on the manually segmented dataset and the
standardized one are almost the same (less than 1%).
Figure 2: Samples from occluded UPOL datasets with
missing information from 5%, 10% to 90%.
We decided to employ in our experiments the
standardized UPOL dataset. The images in this
dataset have 404 × 404 × 3 pixels, the region with iris
information having the same size (the pupil zone has
the same size). The eyelid-eyelash occlusion was
simulated by cutting some regions from the lower and
Occluded Iris Recognition using SURF Features
509

upper part of the iris (see Fig 2). We eliminated more
information from the upper part of the iris image than
from the lower part. We eliminated iris information in
such a way as to obtain images that have about 5%,
10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%
and 95% occlusion of the annular region of the iris.
3 SURF FEATURE EXTRACTION
AND RECOGNITION METHOD
SURF, i.e. Speeded-Up Robust Features introduced
in (Bay, Tuytelaars & Van Gool, 2006) is one of the
most employed keypoints detector. As its name
suggests, it is a faster and better version of SIFT
descriptor. Around these keypoints, local features are
extracted, having the same size, either 64 or 128
components. We chose for our experiments the
variant with 128 elements. The number of keypoints
that the SURF method computes, depends on the
content of each image, two different images have
different number of keypoints associated. For each
one of these keypoints a feature vector with 128
components is calculated.
For the same image, one can compute different
number of keypoints, depending on the choice of
parameters involved in the SURF process, such as the
threshold for the Hessian matrix or the number of the
Gaussian pyramid octave or the number of octave
layers within each octave.
We describe in the following the matching
procedure between the keypoints of two images. The
algorithm is an adaptation of the technique developed
in (Păvăloi & Ignat, 2019). Assume we want to match
two images, I and J. We first apply the SURF
procedure to both of them. The SURF algorithm
computes around the detected keypoints, m feature
vectors,
12
,, ,
m
tt t for image I and n feature vectors
12
,,,
n
dd d for image J.
Each image has a different number of feature
vector associated (n≠m). We match keypoints from
image I with keypoints from image J in the following
way. We first compute all the distances from each
feature vector associated with image I to all the
feature vectors associated to image J.
The keypoint represented by feature vector t
i
matches the keypoint represented by feature vector d
k
if the following relation is fulfilled:
dist(t
i
, d
k
) ≤ T dist(t
i
, d
j
), j≠k (1)
where T>0 is a threshold parameter that allows to
control the matching process. This type of matching
is called nearest neighbor ratio matching procedure.
In equation (1) we tested three distances: Euclidean,
Manhattan and Canberra.
After applying the SURF algorithm and performing
the matching procedure, we define the distance
between two images as the average of the distances
between the coordinates of the matching keypoints.
d(I,J)=average{|| p
r
– q
l
||} (2)
where p
r
denote the coordinates of a keypoint from
image I which is paired with a keypoint from image J
with coordinates q
l
. We used the Manhattan formula
for computing the distances between the coordinates
of the keypoints.
Denote by I the test image, and by S={J
p
, p=1,s} the
training set. Assigning a label to image I, using the
above described matching procedure is done by
computing the following steps:
Step 1: Apply the SURF algorithm to I and all the
images in S.
Step 2: Compute the number of matching points
between the test image I and all the images from S
using formula (1).
Step 3: Denote by m
p
the number of matching points
between the test image I and image J
p
. Let q be the
maximum number of matching points, i.e.
q=max{m
p
; p=1,…,s} (3)
Select from the training set a subset of images that
have at least "q-1" matching keypoints with the test
image I.
Step 4: We compute the distances between test image
I and the images selected after Step 3. Choose the
image from the subset at minimum coordinates
distance. The selected image will provide the label for
the test iris image.
We tested the above mentioned three distances and
the best results were obtained with Manhattan
distance, so this is the distance that was used in our
computations.
4 RESULTS
The number of extracted keypoints and feature
vectors computed with SURF depends on the Hessian
matrix threshold and the numbers of the pyramid
octave. For this work we have tested how these
parameters influence the recognition results. We
experimentally found that the most important
parameter, the parameter which made the difference,
is the threshold for the Hessian blob detector in SURF
features extraction method. We denote this threshold
parameter by H. Our computations show that this
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
510

parameter is of most significance for the method we
propose in this paper. Different values for this
parameter produce sets of keypoints of different sizes.
Smaller values for this threshold provide more
detailed information about the analysed image, thus
improving the iris recognition results. On the other
hand, it is of interest to have as few SURF descriptors
as possible, because this reduces the computation
time in the matching process. In our computations we
adopted a Leave-One-Out type of recognition
method.
For each dataset, we have employed personalized
values for the parameter H. We first computed some
statistical values for each set of feature vectors, and
different values of the threshold H parameter. These
values are the total number of keypoints for the entire
dataset, the minimum and maximum number of
keypoints for the analysed images and the average
number of keypoints. For this purpose, we used the
segmented standardized UPOL dataset. The results
are in Table 1.
Table 1: SURF statistics for the standardized segmented
dataset.
Statistics/
H ↓
Total
no
Min Max Average
100 195575 138 839 509.31
150 140669 81 705 366.33
200 106907 49 580 278.4
250 84644 26 484 220.43
300 68704 10 423 178.92
400 48492 4 321 126.28
500 36368 2 253 94.71
Obviously, small values for the H parameter
produces large numbers of features and as its value
increases the number of feature vectors decreases. We
performed computations on both the original
unsegmented UPOL dataset and for the standardized
segmented dataset. For the first dataset the number of
feature vectors was bigger than for the second one.
For example, for H = 500, the original dataset has an
average of 94840 features (and a recognition rate of
86.46%), and the standardized segmented dataset
only 36368 features (recognition rate 94.71%). The
reason why we use in our further computations the
standardized segmented version of UPOL dataset is
that we obtained better results on this dataset than on
the other datasets.
It is obvious that the number of well recognized
images increases when the number of extracted
keypoints increases. One has to carefully choose the
H parameter in order to balance the recognition
results and the computing time.
Considering the following values for the threshold
parameter involved in the matching process, T∈{0.6,
0.7, 0.8}, and for the Hessian related threshold
H∈{100, 200, 250, 300, 400, 500} we obtain the
recognition results depicted in Table 2.
Table 2: Number of well recognized images on
standardized UPOL dataset.
T
/
H 100 200 250 300 400 500 Avg
0.6 382 378 372 369 358 342 366.83
0.7 384 378 373 371 364 350 370.00
0.8 381 375 369 363 347 335 361.67
Although the recognition results are very good,
the processing time for H =100 is very big, because
the number of detected keypoints is large, and each
feature vector associated with these keypoints has to
be compared with all the others. Anyway, for T= 0.7
and H=100 the maximum number of recognized
image (384) is achieved.
We also computed the number of well recognized
images on the original UPOL dataset. The two
threshold parameters that we analyse in this work
were T∈{0.5, 0.6, 0.7}, and H∈{200, 300, 400, 600,
1000}, and the results are in Table 3. Note that the
recognition results are lower than those computed for
the segmented, standardized dataset. This emphasizes
the fact that a good segmentation procedure yields
good recognition results.
Table 3: Number of correctly recognized images on original
UPOL.
T/H 200 300 400 600 1000 Avg
0.5
376 365 351 321 260
334.6
0.6 376 364 346 318 253 331.4
0.7 371 345 330 296 222 312.8
Considering the parameter H=200, and computing
the above mentioned statistics for the eleven datasets
with different levels of missing iris information we
get the results from Table 4.
From the statistics in this table we deduce that the
number of feature vectors decreases as the level of iris
occlusion increases. Starting with 60% missing
information the average number of keypoints is less
than 200 and for 90% and for 95% missing
information the average is less than 100. Sure, one
can force SURF to compute more features by
choosing smaller values for the H threshold
parameter, but this comes with the inconvenience of
a very long computing time.
Occluded Iris Recognition using SURF Features
511
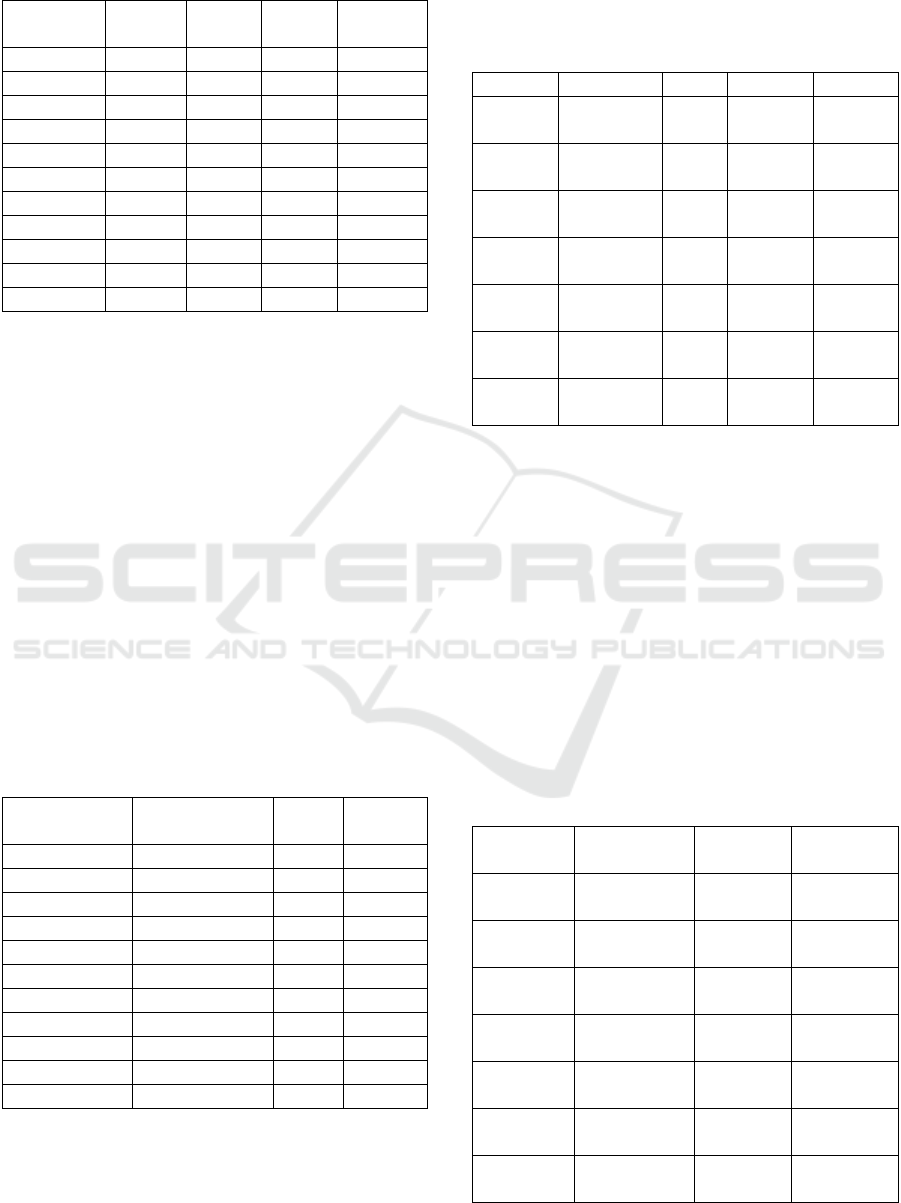
Table 4: SURF statistics for occluded datasets H= 200, T=
0.7.
Statistics/
Occlusion
Total
no
Min Max Average
05 11095 54 5 288.95
10 11090 57 571 288.81
20 10579 54 541 275.51
30 98312 45 508 256
40 91958 245 458 239.4
50 84561 33 433 220.2
60 73765 29 365 192.1
70 55860 28 284 145.4
80 43606 15 218 113.56
90 3220 15 149 83.87
95 2413 15 117 62.85
In Table 5 we present the number of correctly
classified images for H=200, T=0.7 for irises with
occlusions. We performed computations on the entire
dataset and separately on the left eye and on the right
eye.
Note that the results are very good (98.95% for
70% missing information). For images with 10% or
5% iris information the SURF descriptor is unable to
compute sufficient keypoints to have good
recognition results. Note that, on average, the
recognition results are similar for the complete
dataset, right eye and left eye (95.45% for both eye
dataset, 95.97% for the left eye, and 96.07% for the
right eye). An interesting situation occurs for the left
eye dataset with 70% missing information, in this
case the recognition rate is 100%.
Table 5: Recognition results for dataset with occlusion, H=
200, T= 0.7.
Recogn. /
Occlusion
Left+Right
e
y
e
Left
e
y
e
Right
e
y
e
05 382 192 190
10 381 191 191
20 382 190 192
30 381 192 190
40 380 192 189
50 383 192 191
60 379 190 191
70 380 192 190
80 378 190 188
90 339 168 175
95 267 138 142
In the sequel, we focused our attention on the two
datasets with the smallest amount of iris information.
For H∈{25, 50, 100, 150 our method applied on the
datasets with 90% and 95% of missing information
will produce the results Table 6.
Table 6: SURF statistics for occluded datasets with 90%
and 95% occlusion, T=0.7.
Total no Min Max Av
g
.
90%
H=50
66871 89 230 174.14
90%
H=100
48468 36 194 126.22
90%
H=150
39035 20 170 101.65
95%
H=25
57093 96 183 148.68
95%
H=50
50753 59 176 132.17
95%
H=100
36891 25 155 96.07
95%
H=150
29459 17 136 76.74
The recognition results in terms of correctly
classified images, for the datasets and parameters used
in Table 6 are in Table 7. For the complete dataset with
90% missing information one gets a very good
recognition rate of 95.31%, for T=0.7, and H=50. For
the complete dataset with only 5% of iris information,
the best recognition result (89.58%) is obtained for
T=0.7 and H=25. For the right eye dataset with 95%
missing information and H=25 we get an excellent
95.31% recognition result. We remarked that, in this
situation, the right eye dataset has a better average
recognition rate (90.25%) than the complete dataset
(86.97%) and the left eye (87.27%).
Table 7: Recognition results for occluded datasets with 90%
and 95% missing information, T=0.7.
Left+Right
e
y
e
Left eye Right eye
90%
H=50
366 180 187
90%
H=100
356 176 181
90%
H=150
348 177 178
95%
H=25
344 170 183
95%
H=50
335 169 173
95%
H=100
303 154 157
95%
H=150
286 147 154
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
512
In Table 8 we compare the results obtained with
this method, those obtained in Păvăloi & Ignat
(2019a,2019b) in two papers from 2019, one using
only SIFT features, and the other using colour and
SIFT features. We also compare our results with
Daugman’s Iris Code (Daugman, 1993, 2015),
algorithm that was implemented by Masek (Masek,
2003).
Table 8: Comparison results with other methods for the
segmented standardized UPOL dataset, T=0.7
Methods/
Miss.
Info.
(PI,a) (PI,b) Daugmann-
Masek
Our
method
0 384 374 382 384
05 382 372 381 382
10 380 374 380 381
20 377 376 378 382
30 382 378 377 381
40 380 377 377 380
50 381 374 375 383
60 377 374 370 379
70 375 373 361 380
80 369 375 341 378
90 305 369 316 366
95 174 367 275 344
In the last column of Table 8 the results were obtained
with different values for the blob detection related
threshold, H (the values that provided the best
results). We get better recognition results in nine out
of the twelve analysed experiments. For the cases of
90% and 95% missing information the SURF
procedure extracts very few keypoints and thus the
recognition rate is lower. The method that provides
better results in these situations, although uses a
keypoint detector, but the results are improved in
these case, by the colour features (Păvăloi & Ignat,
2016).
The images from the standardized UPOL
collection are very regular, the annular iris region and
the pupil have the same size in all the images. We
tested our method on images with an irregular
structure of the iris, and non-uniform background, by
performing some computations on the images from
the original UPOL collection. We considered three
cases, namely images with 30%, 60% and 90%
missing information (see Fig. 3).
30% 60% 90%
Figure 3: Examples of iris images with missing information
from the original UPOL database: 30%, 60%, 90%.
We used, as before, H= 200 and T=0.7. The
results of our computations are in Table 9. In this
case, due to the fact that the image contains non-iris
information, the recognition rate decreses more
rapidly as the occlusion increases.
Table 9: Recognition results for the original UPOL dataset,
30%, 60%, 90% missing information.
Missing
info.
Left+Right
e
y
e
Left eye Right eye
0 371 186 186
30 354 180 175
60 342 168 176
90 245 126 119
We analyzed the importance of a standard iris
segmentation by applying our method on the
manually segmented UPOL. The iris images in this
dataset have variable iris and pupil areas (see Fig. 4).
The background is black. We used the same values of
the thresold paramaters, H= 200 and T=0.7. The
results are in Table 10. Note that in this case the
results are lower than those obtained for the other two
datasets. One reason for these results is the fact that
SURF extracts orientation and shape information
around the keypoints. Another reason for these
differences is the distance (2) we use in the
classification process. For very regular images, such
as the images from the standardized UPOL collection,
this distance works. For the other datasets one needs
to find a new distance. A third reason is the fact that
the H parameter need to be carefully chosen for each
dataset in order to obtain good recognition results.
0% 40% 80%
Figure 3: Examples of iris images with missing information
from the manually segmented UPOL database: 0%, 40%,
80%.
Occluded Iris Recognition using SURF Features
513
Table 10: Recognition results for the manually segmented
UPOL dataset, 10% to 90% missing information.
Missing
info.
Left+Right
e
y
e
Left eye Right eye
10 346 178 182
20 342 176 179
30 339 178 176
40 329 175 170
50 322 168 168
60 321 164 168
70 290 160 153
80 259 138 135
90 178 93 106
One way to improve the results for datasets with
irregular shape of the iris images is to add texture
information to the feature vectors extracted around
the keypoints.
5 CONCLUSIONS
This paper presents the computation results on
occluded iris image recognition using SURF features
and an adapted method we previously developed for
SIFT keypoint detection. In experiments, the UPOL
iris dataset was employed. We obtain, in some
situations, better results than those computed with
SIFT based features. We observed that the
recognition accuracy depends on the number SURF
features but after a certain level, the recognition rate
reaches a plateau. For each dataset, the value of the
Hessian threshold parameter used for computing
SURF features must be established after some
experiments. Usually, an average bigger than 200
SURF descriptors for an image seems to give very
good recognition results. Sure, for datasets with 90%
or 95% missing information that target cannot be
reached. Experiments have revealed that a good value
for the matching threshold parameter is 0.7.
In our future work we intend to employ also other
datasets, as UBIRIS for example. In our future
experiments we are interested in combining SURF
method with texture features and the colour
information.
REFERENCES
Daugman, J. G. (1993). High confidence visual recognition
of persons by a test of statistical independence. IEEE
transactions on pattern analysis and machine
intelligence, 15(11), 1148-1161.
Daugman, J. (2015). Information theory and the iriscode.
IEEE transactions on information forensics and
security, 11(2), 400-409.
Bowyer, K. W., & Burge, M. J. (Eds.). (2016). Handbook
of iris recognition. Springer London.
De Marsico, M., Petrosino, A., & Ricciardi, S. (2016). Iris
recognition through machine learning techniques: A
survey. Pattern Recognition Letters, 82, 106-115.
Harakannanavar, S. S., & Puranikmath, V. I. (2017,
December). Comparative survey of iris recognition. In
2017 International Conference on Electrical,
Electronics, Communication, Computer, and
Optimization Techniques (ICEECCOT) (pp. 280-283).
IEEE.
Nguyen, K., Fookes, C., Jillela, R., Sridharan, S., & Ross,
A. (2017). Long range iris recognition: A survey.
Pattern Recognition, 72, 123-143.
Rattani, A., & Derakhshani, R. (2017). Ocular biometrics in
the visible spectrum: A survey. Image and Vision
Computing, 59, 1-16.
Nguyen, K., Fookes, C., Ross, A. & Sridharan, S. (2017)
Iris recognition with off-the-shelf CNN features: A
deep learning perspective. IEEE Access, 6, 18848-
18855.
Ali, H. S., Ismail, A. I., Farag, F. A., & Abd El-Samie, F.
E. (2016). Speeded up robust features for efficient iris
recognition. Signal, Image and Video Processing,
10(8), 1385-1391.
Mehrotra, H., Sa, P. K., & Majhi, B. (2013). Fast
segmentation and adaptive SURF descriptor for iris
recognition. Mathematical and Computer Modelling,
58(1-2), 132-146.
Bakshi, S., Das, S., Mehrotra, H., & Sa, P. K. (2012,
March). Score level fusion of SIFT and SURF for iris.
In 2012 International Conference on Devices, Circuits
and Systems (ICDCS) (pp. 527-531). IEEE.
Mehrotra, H., Majhi, B., & Gupta, P. (2009, December).
Annular iris recognition using SURF. In International
Conference on Pattern Recognition and Machine
Intelligence (pp. 464-469). Springer, Berlin,
Heidelberg.
Ismail, A. I., Ali, H. S., & Farag, F. A. (2015, February).
Efficient enhancement and matching for iris
recognition using SURF. In 2015 5th national
symposium on information technology: Towards new
smart world (NSITNSW) (pp. 1-5). IEEE.
Păvăloi, I., & Ignat, A. (2018, September). Experiments on
Iris Recognition Using Partially Occluded Images. In
International Workshop Soft Computing Applications
(pp. 153-173). Springer, Cham.
Ignat, A., & Vasiliu, A. (2018). A study of some fast
inpainting methods with application to iris
reconstruction. Procedia Computer Science, 126, 616-
625.
Păvăloi, I., & Ignat, A. (2019). Iris Image Classification
Using SIFT Features. Procedia Computer Science, 159,
241-250.
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
514

Dobeš, M., Martinek, J., Skoupil, D., Dobešová, Z., &
Pospíšil, J. (2006). Human eye localization using the
modified Hough transform. Optik, 117(10), 468-473.
Dobeš, M., Machala, L., Tichavský, P., & Pospíšil, J.
(2004). Human eye iris recognition using the mutual
information. Optik, 115(9), 399-404.
Păvăloi, I., Ciobanu, A., & Luca, M. (2013, November). Iris
classification using WinICC and LAB color features. In
2013 E-Health and Bioengineering Conference (EHB)
(pp. 1-4). IEEE.
Ignat, A., Luca, M., & Ciobanu, A. (2016). New Method
of Iris Recognition Using Dual Tree Complex Wavelet
Transform. In Soft Computing Applications (pp. 851-
862). Springer, Cham.
Bay, H., Tuytelaars, T., & Van Gool, L. (2006, May). Surf:
Speeded up robust features. In European conference on
computer vision (pp. 404-417). Springer, Berlin,
Heidelberg.
Păvăloi, I., & Ignat, A. (2019, November). Iris Occluded
Image Classification Using Color and SIFT Features. In
2019 E-Health and Bioengineering Conference (EHB)
(pp. 1-4). IEEE.
Masek, L. (2003). Recognition of human iris patterns for
biometric identification (Doctoral dissertation,
Master’s thesis, University of Western Australia).
Masek, L. (2003). Matlab source code for a biometric
identification system based on iris patterns.
http://people. csse. uwa. edu.
au/pk/studentprojects/libor/.
Păvăloi, I., & Ignat, A. (2016, August). Iris recognition
using color and texture features. In International
workshop soft computing applications (pp. 483-497).
Springer, Cham.
Occluded Iris Recognition using SURF Features
515
