
Obsolescence Prediction based on Joint Feature Selection and Machine
Learning Techniques
Imen Trabelsi
1,2
, Besma Zeddini
3
, Marc Zolghadri
1,4
, Maher Barkallah
2
and Mohamed Haddar
2
1
Quartz Laboratory, SUPMECA, 3 rue Fernand Hainaut, 93407 Saint-Ouen, France
2
LA2MP Laboratory, ENIS, Route Soukra Km 3.5, 3038 Sfax, Tunisia
3
SATIE Laboratory CNRS, UMR 8029, CYTeh ENS Paris-Saclay, Cergy, France
4
LAAS - CNRS, 7 Avenue du Colonel Roche, 31400 Toulouse, France
Keywords:
Obsolescence Prediction, Artificial Intelligence, Machine Learning, Feature Selection.
Abstract:
Obsolescence is a serious phenomenon that affects all systems. To reduce its impacts, a well-structured man-
agement method is essential. In the field of obsolescence management, there is a great need for a method
to predict the occurrence of obsolescence. This article reviews obsolescence forecasting methodologies and
presents an obsolescence prediction methodology based on machine learning. The model developed is based
on joint a machine learning (ML) technique and feature selection. A feature selection method is applied to
reduce the number of inputs used to train the ML technique. A comparative study of the different methods of
feature selection is established in order to find the best in terms of precision. The proposed method is tested
by simulation on models of mobile phones. Consequently, the use of features selection method in conjunction
with ML algorithm surpasses the use of ML algorithm alone.
1 INTRODUCTION
Obsolescence is a problem that affects all sectors. It
is not a new phenomenon; since the early 1990s, the
rate of component obsolescence has increased rapidly.
This is particularly well illustrated by electronic com-
ponents, especially for smartphones. Smartphones
are the devices most subject to rapid renewal due
to their obsolescence, whether technical, software or
aesthetic. For example, when manufacturers still of-
fer new versions or updates that are incompatible with
previous models, we talk about software and aesthetic
obsolescence. But when battery usage is reduced due
to a small number of cycles or when repair becomes
increasingly complicated (with models that are almost
impossible to disassemble and spare parts unavail-
able), we speak of technical obsolescence.
Indeed, obsolescence is inevitable but anticipation
and careful planning can minimize its impact and po-
tentially high cost. The aim of obsolescence man-
agement is to ensure that obsolescence is managed
as an integral part of design, development, production
and maintenance in order to minimize costs and nega-
tive impact throughout the product life cycle (Group,
2016). Thus, the purpose of obsolescence manage-
ment is to determine: the optimal dates and quan-
tity of last time to buy (LTB), the optimal date for
redesign, the components that should be considered
for redesign or that should be replaced (Meng et al.,
2014).
Sandborn has defined three terms for obsolescence
management as follows (Sandborn, 2013):
• Reactive management consists in taking actions
when the obsolescence has already occurred.
• Proactive management is implemented for critical
components that have a risk of going obsolete.
• Strategic management is done in addition to
proactive and reactive management and involves
the determination of the optimum mix of mitiga-
tion approaches and design refreshes.
The most common type of management used is reac-
tive management because it is easier to implement.
It is advisable to use it only if the cost associated
with the obsolescence of a component is low (Pingle,
2015). However, if the probability of obsolescence
and associated costs are high, it is recommended to
apply proactive management strategies to minimize
the risk of obsolescence and associated costs (Rojo
et al., 2010). In fact, forecasting the occurrence of
obsolescence is the key factor in proactive manage-
ment (Sandborn et al., 2011). For this reason, many
Trabelsi, I., Zeddini, B., Zolghadri, M., Barkallah, M. and Haddar, M.
Obsolescence Prediction based on Joint Feature Selection and Machine Learning Techniques.
DOI: 10.5220/0010241407870794
In Proceedings of the 13th International Conference on Agents and Artificial Intelligence (ICAART 2021) - Volume 2, pages 787-794
ISBN: 978-989-758-484-8
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
787

researchers have focused on the development of meth-
ods based on the prediction of obsolescence (Solomon
et al., 2000; Ma and Kim, 2017; Sandborn, 2017; Tra-
belsi et al., 2020).
Recently, with the emergence of machine learning
techniques, some works have been published present-
ing methods based on machine learning for the pre-
diction of obsolescence (Jennings et al., 2016; Grichi
et al., 2017). In these researches, the authors mainly
used the random forest algorithm to predict the state
(obsolete or available) of the product. In the same
line, this work highlights the value of the ML tech-
niques to improve the quality of the obsolescence pre-
diction. In fact, the obsolescence depends on the fea-
tures of the product, but not all the features have the
same effect. For this, a feature selection method must
be used before processing the prediction approach in
aim to select the most important and significant fea-
tures. In this case, the following challenges must be
overcome:
- What are the main algorithms that are best
adapted to select the most important features?
- How does the feature selection method improve
the obsolescence prediction model?
The remain of this paper is organized as follow: Sec-
tion 2 presents the related works on forecasting tech-
niques. In section 3, we present the proposed machine
learning-based methodology and the feature selection
procedure used to obsolescence prediction. Therefore
an explanation of the case study and results are pre-
sented in section 4. Finally, some conclusions and
future work are given in section 5.
2 RELATED WORKS
This section presents an overview of the obsolescence
concept in the first part. Then, we present the prob-
lem of feature selection and different methods used
for supervised learning. Supervised learning is where
the computer is equipped with sample inputs that are
labeled with the desired outputs (Brownlee, 2016).
2.1 Obsolescence Concept
According to IEC 62402, obsolescence is ”the transi-
tion of an item from available to unavailable from the
manufacturer in accordance with the original speci-
fication”. Several factors are responsible for product
obsolescence, including technological evolution or in-
novation, government-imposed laws and regulations,
market demand, etc.(Bartels et al., 2012). Obsoles-
cence is considered as a change that may affect the
product. It can be considered as voluntary or involun-
tary. When the change is made by the manufacturer
itself to promote new products, increase market share
and sales (D
´
em
´
en
´
e and Marchand, 2015), or when the
customers decide to stop using the product for rea-
sons, such as economics (for example, when the cost
of maintenance is higher than the purchase of a new
one), or aesthetics, obsolescence is considered volun-
tary. While, when the change made to the product
is independent of the customer or manufacturer, such
as government imposed regulations, the obsolescence
is considered involuntary, (Bartels et al., 2012). In
the scientific literature (Bartels et al., 2012; Sandborn,
2007; Mellal, 2020), several obsolescence typologies
have been identified, including the following:
• Technological Obsolescence: occurs when there
is a new technology that can replace the old one.
• Functional Obsolescence: is related to a techni-
cal defect that makes the product unusable.
• Aesthetic Obsolescence: is related to fashion ef-
fects and consumer psychology.
• Logistical Obsolescence: means that the product
is no longer procurable due to diminishing manu-
facturing sources and material shortages.
• Economic Obsolescence: is related to the high
cost of using, repairing and/or maintaining the
product.
The obsolescence process ideally goes through dif-
ferent phases. The manufacturer announces the end
of life of the product (Product Discontinued Notifi-
cation) and sets a date by which the officially obso-
lete product will no longer be sold (Last Time Buy).
During the intermediate phase (Phase Out), customers
can still stock up and build up a stock of the obsolete
product. The increasing rate of obsolescence leads to
several risks. In (Mellal, 2020), the author discussed
the various risks causing by the obsolescence in dif-
ferent sectors.
To reduce the affects of obsolescence, many re-
searchers have already worked on forecasting obso-
lescence. The existing methods can be classified into
two categories: mathematical-based approaches and
machine learning-based approaches. In this paper, we
will focus on the ML-based approach developed by
(Jennings et al., 2016). The authors are presented
a ML-based method to predict the status (Available/
Discontinued) of the product. A comparative study of
ML techniques was also developed in this work. The
dataset used to illustrate this approach contains infor-
mation about the launch date, some technical features
(chosen by the authors), and the status of the smart-
phone. As discussed above, product obsolescence de-
pends on the most relevant features. Therefore, one of
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
788

the important points is to determine the most relevant
features for the classification of these products.
2.2 Feature Selection
The problem of feature selection has become increas-
ingly important in the field of data analysis and ma-
chine learning (Samb et al., 2012). The feature se-
lection is a technique that selects among original
features a subset of the most important and signif-
icant attributes. In the context of supervised learn-
ing, this subset should allow meeting the target pur-
pose, namely the accuracy of learning, the speed of
learning, or the applicability of the proposed model
(Khalid et al., 2014). According to (Babiker et al.,
2019), the feature selection methods can be divided
in three main categories: Filter, Wrapper, and Em-
bedded method:
1. Wrapper Method: evaluates a subset of features
by its classification performance using a learning
algorithm (Kohavi et al., 1997). The learning al-
gorithm works on the totality of instances with
different subsets of features. It provides for each
of them the estimated precision of the classifica-
tion of the new instances. The subset inducing the
most accurate classifier is selected. The complex-
ity of the learning algorithm makes the wrapper
method very expensive in terms of time where it
becomes impractical when the number of initial
features is large.
2. Filter Method: is a pre-processing method that
is done before the learning process and indepen-
dently of any machine learning algorithms. In-
stead, the relevance of the feature to the outcome
variable is determined based on the feature’s score
in various statistical tests. Compared to wrapper
methods, filter methods are much faster because
they do not involve training the models.
3. Embedded Method: is performed by a specific
learning algorithm that performs feature selection
during the training process. It differs from other
methods in the way feature selection and learning
interact.
Figure 1 illustrates these three categories of feature
selection.
In this paper, a comparative study will be done to
choose the best algorithm for feature selection of Fil-
ter, Wrapper, and Embedded types. To make the com-
parison feasible, we propose to identify the subset of
features selected by automatic methods and then us-
ing it as the training data for the predictive model. In
section 3, we define precisely the steps of the used
method.
Figure 1: Comparison between (a) filter method, (b) wrap-
per method, and (c) embedded method for feature selection
(Lee, 2009).
3 PROPOSED APPROACH
More and more companies have large amounts of data
that are valuable resources for obsolescence manage-
ment. However, as these resources cannot be suf-
ficiently analyzed and evaluated, they are worthless
for the company. To overcome this problem, ma-
chine learning techniques are being developed. Some
researchers have focused on the application of ML
techniques for the prediction and detection of obso-
lescence (Jennings et al., 2016; Grichi et al., 2017).
To update the approach proposed by (Jennings et al.,
2016), in this work we propose an obsolescence pre-
diction based on joint feature selection and ML Tech-
nique.
As shown in Figure 2, the first step is to collect the
data to identify the product’s obsolescence. The col-
lected data must contain information about technical
specifications, launch date, production end date, and
all other data may affect the product obsolescence. To
obtain more accurate forecast results, the strengths of
the feature selection method and the prediction model
will be unified. Therefore, a crucial step concerning
the feature selection will have to be done before start-
ing the prediction model. At this stage, a subset of the
most relevant features is selected. The third step is
to choose a predictive model among supervised learn-
ing techniques. The predictive model aims to predict
the status (available or obsolete) of the product in the
test dataset. The performance of predictive models is
evaluated using the confusion matrix (Zemouri et al.,
2018). This matrix contains a summary of the number
of correct and incorrect predictions allowing to quan-
tify errors made. In our case, the confusion matrix is
shown in Table 1.
Based on this information, three metrics are cal-
culated:
1. Accuracy: it generally indicates how ”right” pre-
dictions are. It is calculated as follow:
Accuracy =
T P + T N
T P + FP + T N + FN
(1)
Obsolescence Prediction based on Joint Feature Selection and Machine Learning Techniques
789
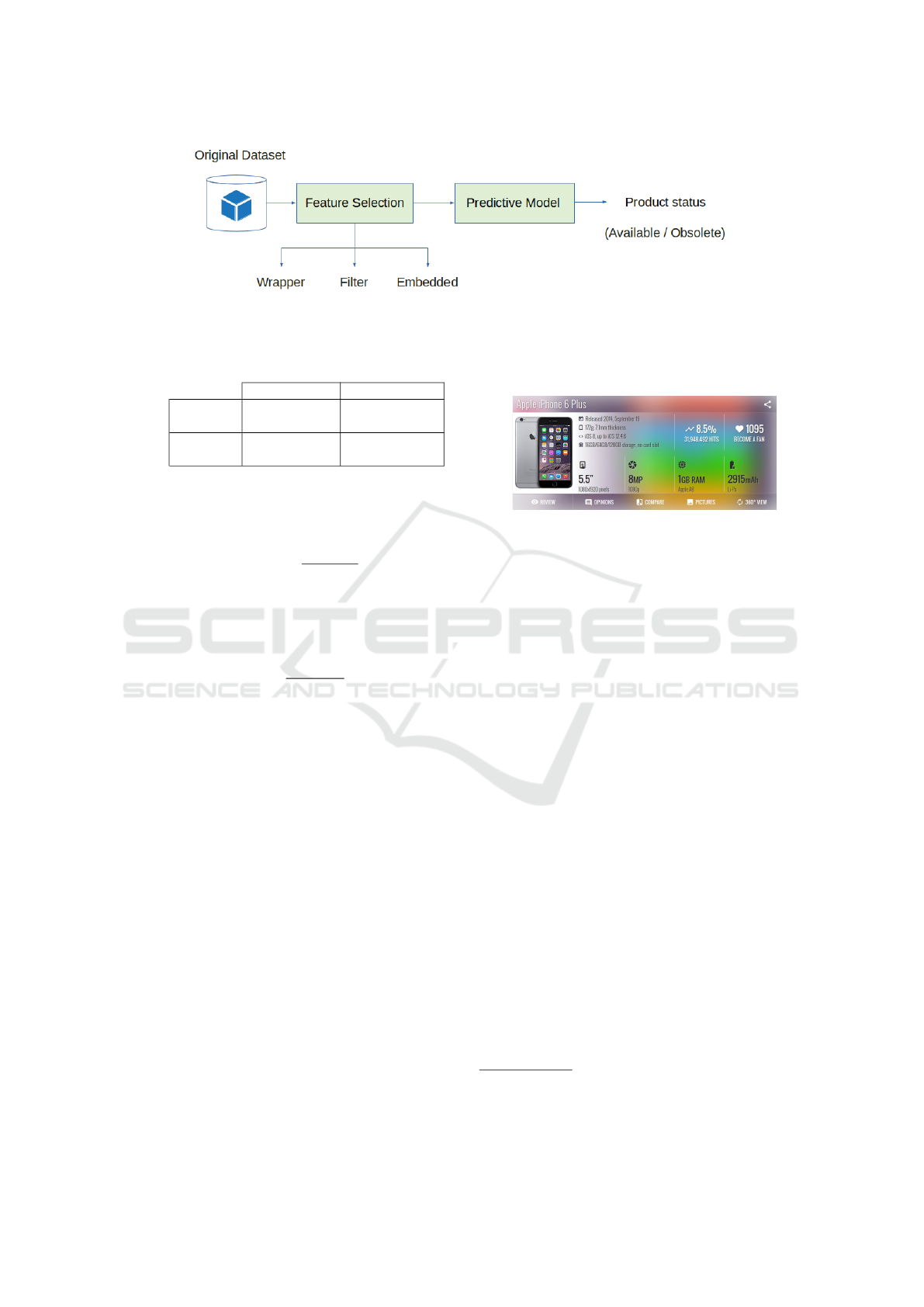
Figure 2: The proposed approach.
Table 1: The confusion matrix.
Predicted class
Obsolete Available
Actual
class
Obsolete
True Positive
(TP)
False Negative
(FN)
Available
False Positive
(FP)
True Negative
(TN)
1. Precision: it measures the class agreement of the
data labels with the positive labels given by the
classifier.
Precision =
T P
T P + FP
(2)
2. Sensitivity or true positive rate (TPR): it mea-
sures how often the model chooses the positive
class when the observation is in fact in the posi-
tive class.
T PR =
T P
T P + FN
(3)
These metrics are calculated for different ML-
techniques to compare them and choose the best one.
4 CASE STUDY
The case study will demonstrate the utility of the fea-
ture selection method in the predictive model. The
smartphone market is evolving very fast, driven by
the regular introduction of new technologies and se-
rious competitors, and by fashion effects. Therefore,
smartphones are used as the illustrative case of the
proposed approach.
4.1 The Dataset
The database contains specific information on several
smartphone models and whether their status is avail-
able or discontinued. There are more than 59 features
such as digital mobile phone technology, battery ca-
pacity, smartphone dimensions, display characteris-
tics, operation system, etc. The data was collected on
one of the most popular mobile phone forums (GSM
Arena)
1
. Figure 3 shows an example of iPhone 6 Plus
specifications.
Figure 3: Example of technical specification from GSM-
Arena.
According to estimates by Canalys
2
, the global
smartphone market was mainly divided between the
Apple, Samsung, Huawei, Xiaomi and Oppo brands.
Therefore, the number of instances is reduced to 1257
models of the 5 brands divided into 576 available
smartphones and 681 as discontinued (or obsolete).
As is well known in the machine learning commu-
nity, reducing input variables is a useful operation. It
has a great impact on the computer’s time and accu-
racy. Therefore, there is a great need to apply an al-
gorithm to select among these most relevant features.
The data present in the site can miss values and
even have erroneous information. These gaps reflect
the limitations imposed by some industries to have a
complete database. To remedy this problem, the data
must first be prepared.
The dataset has been formatted in a machine learn-
ing compatible format. To handle missing data, the
mean imputation method is used. Once the data is
formatted, feature selection methods is applied. The
first part of this case study is to compare the differ-
ent methods of feature selection. To this end, we have
used several feature selection algorithms for the three
methods.
1
https://www.gsmarena.com
2
https://www.canalys.com/newsroom/
canalys-global-smartphone-market-q4-2019
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
790
4.2 Used Tools
In this section, the used techniques for feature selec-
tion and for machine learning are presented. For su-
pervised learning the most used techniques are:
• Random Forest (RF): is a meta-estimator that
applies many decision tree models to different
subsamples of the data set and the end result is ob-
tained as an average of these models, see (Grichi
et al., 2017). The averaging process avoids over-
fitting and therefore improves the accuracy of the
classification.
• Artificial Neural Network (ANN): is a super-
vised machine learning tool that can learn a non-
linear function. It can be used for classification
or regression which make it one of the most used
fault detection technique (Zemouri et al., 2019).
• Support Vector Machine (SVM): aims to find a
separating hyperplane that separates the different
classes. To do this, the Optimal Separating Hyper-
plane (OSH) is defined as the hyperplane situated
between the classes that maximize the margin be-
tween them (Wang et al., 2012).
• K-Nearest Neighbors (KNN): The nearest
neighbors approach is based on finding a fixed
number k of samples from a training dataset,
which are the closest ones, in terms of distance, to
the new instance to predict its label, (Omri et al.,
2020).
• Naive Bayes (NB): The Naive Bayes (NB)
method is a simple, probabilistic, and supervised
classifier, see (Rish et al., 2001). This technique
is based on coupling the Bayes theorem with the
Naive hypothesis of conditional independence be-
tween every pair of features given the value of the
class variable.
The used feature selection algorithms in this case
study are presented as follow. For filter method, we
used:
• Correlation-based Feature Subset Selection is an
algorithm that evaluates the importance of a sub-
set of attributes by considering the individual pre-
dictive ability of each feature along with the de-
gree of redundancy between them (Li et al., 2011).
• Variance Threshold is a simple baseline algorithm
to feature selection. According to (Zhao et al.,
2013), it aims to remove the features whose vari-
ance does not meet some threshold. It automati-
cally removes all features with zero variance, i.e.
features that have the same value in all samples.
For wrapper method we used:
• Wrapper attribute subset evaluator designed to
evaluate features subsets by using a learning tech-
nique. It uses cross validation for estimating the
precision of the learning technique used (Gutlein
et al., 2009).
• Backward Feature Elimination is a feature selec-
tion technique while building a machine learning
model that used to remove features without signif-
icant effect on the prediction of output (Kostrzewa
and Brzeski, 2017).
For embedded method we used:
• Ridge regularization is a process that consider all
the features into the model and try to regularize
the coefficient estimates of a feature such that a
large number of coefficient estimates shrink to-
wards zero (Cawley, 2008).
• Lasso allows to select a restricted subset of fea-
tures by shrinking some of the coefficients to zero,
that means that a certain features will be multi-
plied by zero to estimate the target (Muthukrish-
nan and Rohini, 2016).
The different simulations of feature selection and
classification with machine learning were done using
Python libraries.
4.3 Results and Discussion
Here in all the instances, we have the target which
takes 0 or 1 respectively when the smartphone is ob-
solete the output is 0, if it is available the output is
1. Table 2, represents the precision and the sensitiv-
ity of the classification algorithms for different feature
selection techniques. A cross validation has been per-
formed with k=5. This allows to evaluate the impact
of the selected features on the model performance.
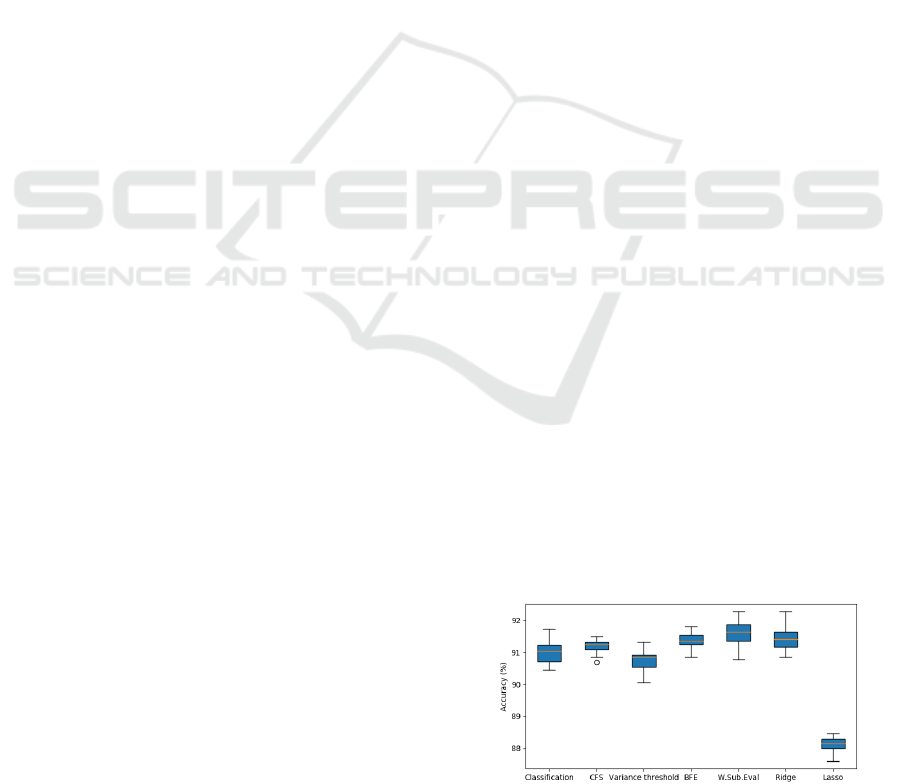
These results show that the Random Forest (RF)
technique has better accuracy than other algorithms
without the feature selection step. This accuracy is
improved by applying feature selection techniques
such as wrapper methods, as shown in Figure4.
Figure 4: The comparison of the Random Forest accuracy
with different feature selection techniques.
Obsolescence Prediction based on Joint Feature Selection and Machine Learning Techniques
791
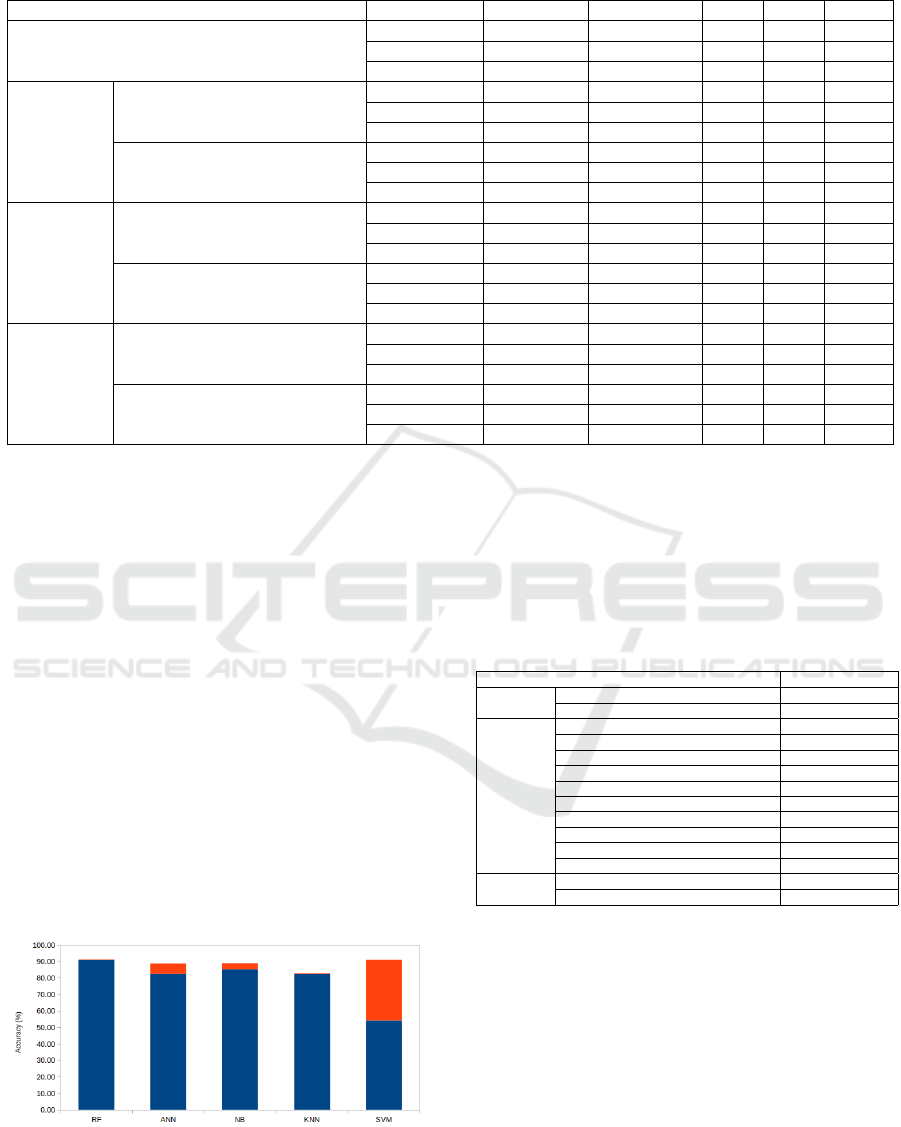
Table 2: Simulation results.
Feature selection Performance RF ANN NB KNN SVM
Without feature selection
Accuracy 91.02±0.34 82.39±2.5 85.20 82.26 54.18
Precision 93.41±0.35 80.05±5.48 81.69 86.35 54.18
Sensitivity 89.62±0.35 86.55±2.46 93.69 79.88 100.00
Filter
Cfs Subset Eval
Accuracy 91.19±0.2 88.26±3.88 89.98 89.98 89.82
Precision 93.83±0.16 90.03±3.69 93.29 92.50 94.38
Sensitivity 89.62±0.35 88.34±7.13 87.81 88.69 86.34
Variance Threshold
Accuracy 90.77±0.3 80.78±2.96 80.35 82.18 55.93
Precision 93.24±0.24 84.67±3.07 75.23 84.05 55.37
Sensitivity 89.44±0.51 79.02±6.25 95.01 82.82 96.18
Wrapper
Backward Feature Elimination
Accuracy 91.36±0.23 88.88±0.77 89.02 82.74 91.09
Precision 93.38±0.33 90.35±1.07 88.95 85.91 94.52
Sensitivity 90.47±0.34 89±1.12 91.04 81.50 88.69
Wrapper subset eval
Accuracy 91.62±0.37 84.17±3.07 62.21 84.17 54.26
Precision 93.65±0.23 85.8±2.43 58.97 87.77 54.24
Sensitivity 90.69±0.6 84.94±6.5 99.41 82.23 99.56
Embedded
Ridge
Accuracy 91.43±0.35 81.63±5.76 80.90 91.65 91.49
Precision 93.91±0.14 85.94±7.59 76.53 94.44 94.29
Sensitivity 90.02±0.62 80.23±10.82 93.39 89.87 89.72
Lasso
Accuracy 88.1±0.22 82.42±2.68 86.48 82.26 54.18
Precision 88.86±0.29 87.31±2.43 81.43 86.35 54.18
Sensitivity 89.22±0.23 79.15±5.5 97.21 79.88 100.00
Moreover, for the predictive model SVM, the applica-
tion of the ridge technique improved its accuracy up to
91.49%. Whereas without feature selection technique
it has sensitivity 100% that means that the SVM only
can not identify the available smartphone, it consid-
ers that all the smartphones were obsolete. Therefore,
it is more important to use feature selection meth-
ods and ML algorithms than to use only ML algo-
rithms. As shown in Table 2, obsolescence predic-
tion based on backward feature elimination and ANN
Technique is more accurate than using ANN only. As
mentioned above, feature selection technique allows
to select only those features which are necessary.
Comparing all algorithms of feature selection, we
note that backward feature elimination seems to be
the best technique to increase the performance of the
predictive model. Figure 5 shows the improvement of
the accuracy of the different ML-techniques using the
backward feature elimination.
Figure 5: The improvement of the accuracy en applying
Backward Feature Elimination.
As shown in the Table 3, we can see that through
the application of the feature selection technique, the
number of features used to train the predictive model
has been reduced from 59 to 21 maximum. Therefore,
the feature selection technique allows to optimize the
training time and reduce data collection effort.
Table 3: The number of features selected by the different
feature selection techniques.
Feature selection techniques Features number
Filter
CfsSubsetEval 7
VarianceThreshold 16
Wrapper
Backward Feature Elimination + RF 10
Wrapper subset eval + RF 14
Backward Feature Elimination + ANN 10
Wrapper subset eval + ANN 20
Backward Feature Elimination + KNN 10
Wrapper subset eval +KNN 10
Backward Feature Elimination + NB 10
Wrapper subset eval + NB 7
Backward Feature Elimination + SVM 10
Wrapper subset eval + SVM 21
Embedded
Ridge 13
Lasso 16
The figure 6 illustrates the features selected by the dif-
ferent techniques. The most relevant feature, which is
selected by 11 techniques, corresponds to the launch
date of the smartphone.
From this study, it is proven that there is a small
set of features that impact the smartphone obsoles-
cence. Thus, an efficient obsolescence prediction ap-
proach can be established by controlling these fea-
tures. However, the phenomenon of obsolescence is
a dynamic concept which evolves over time which
means that these features can be modified depend-
ing on the date of observation. Therefore, each obso-
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
792
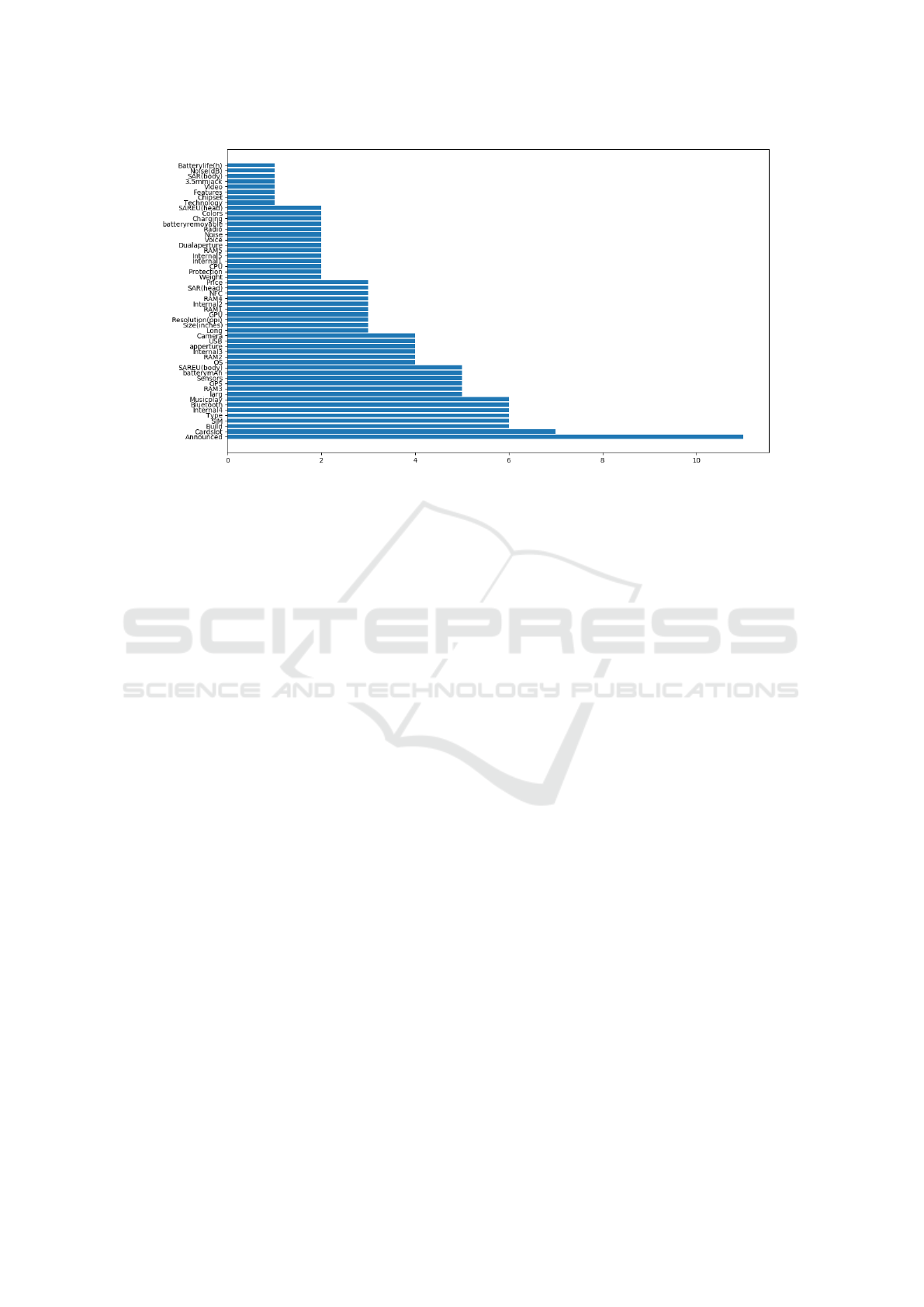
Figure 6: The most important features selected by the different feature selection techniques.
lescence prediction must be presented with a validity
horizon. As a perspective for this work, we propose
to study the evolution of the features that impact ob-
solescence for a given system.
In this paper, obsolescence status is considered as
the case where the manufacturer announce the prod-
uct end-of-life. However, for the user, the problem
arises in other words. Indeed, he can decide for him-
self to abandon the use of a product that has become
useless due, for example, to its replacement by a new
product. In this context, an other limitation to our ap-
proach is the behavior of costumers. Obsolescence
status is then modified according to this issue. Hence,
it is necessary to integrate this customer-related infor-
mation into the study of obsolescence by proposing
an approach based on natural language processing.
5 CONCLUSIONS
In this paper, we have discussed a new joint technique
of feature selection and machine learning used for ob-
solescence prediction. Our approach is applied in a
real data set concerning the obsolescence of smart-
phones. The results show that the obsolescence of the
smartphone is linked to specific features such as the
launch date, the ability of the smartphone to insert a
memory card slot,etc. Thus, an effective obsolescence
prediction strategy lies in the prevention of obsoles-
cence of these features. However, this work is limited
in the obsolescence detection (binary class) without
taking into account its evolution over time and its de-
pendence on the system environment (market and en-
tities).
To go further, the authors believe that it is necessary
to evaluate obsolescence as a dynamic problem that
evolves over time. Thus, the features which have
an impact on the obsolescence of a system during a
given period can be changed during another period.
In this context, a data-driven obsolescence manage-
ment approach is needed. This approach should bring
together the different data that characterize the sys-
tem environment (technologies, laws, aesthetics, etc)
in order to control adapt the prediction model to these
environment change.
REFERENCES
Babiker, M., Karaarslan, E., and HOS¸CAN, Y. (2019). A
hybrid feature-selection approach for finding the digi-
tal evidence of web application attacks. Turkish Jour-
nal of Electrical Engineering & Computer Sciences,
27(6):4102–4117.
Bartels, B., Ermel, U., Sandborn, P., and Pecht, M. G.
(2012). Strategies to the prediction, mitigation and
management of product obsolescence, volume 87.
John Wiley & Sons.
Brownlee, J. (2016). Master Machine Learning Algorithms:
discover how they work and implement them from
scratch. Machine Learning Mastery.
Cawley, G. C. (2008). Causal & non-causal feature selec-
tion for ridge regression. In Causation and Prediction
Challenge, pages 107–128.
D
´
em
´
en
´
e, C. and Marchand, A. (2015). L’obsolescence des
produits
´
electroniques: des responsabilit
´
es partag
´
ees.
In Les ateliers de l’
´
ethique/The Ethics Forum, vol-
ume 10, pages 4–32. Centre de recherche en
´
ethique
de l’Universit
´
e de Montr
´
eal.
Grichi, Y., Beauregard, Y., and Dao, T. (2017). A random
forest method for obsolescence forecasting. In 2017
Obsolescence Prediction based on Joint Feature Selection and Machine Learning Techniques
793

IEEE International Conference on Industrial Engi-
neering and Engineering Management (IEEM), pages
1602–1606. IEEE.
Group, E. (2016). Expert group 21: Obsolescence manage-
ment final report.
Gutlein, M., Frank, E., Hall, M., and Karwath, A. (2009).
Large-scale attribute selection using wrappers. In
2009 IEEE symposium on computational intelligence
and data mining, pages 332–339. IEEE.
Jennings, C., Wu, D., and Terpenny, J. (2016). Forecasting
obsolescence risk and product life cycle with machine
learning. IEEE Transactions on Components, Packag-
ing and Manufacturing Technology, 6(9):1428–1439.
Khalid, S., Khalil, T., and Nasreen, S. (2014). A survey of
feature selection and feature extraction techniques in
machine learning. In 2014 Science and Information
Conference, pages 372–378. IEEE.
Kohavi, R., John, G. H., et al. (1997). Wrappers for feature
subset selection. Artificial intelligence, 97(1-2):273–
324.
Kostrzewa, D. and Brzeski, R. (2017). The data di-
mensionality reduction in the classification process
through greedy backward feature elimination. In
International Conference on Man–Machine Interac-
tions, pages 397–407. Springer.
Lee, M.-C. (2009). Using support vector machine with a hy-
brid feature selection method to the stock trend predic-
tion. Expert Systems with Applications, 36(8):10896–
10904.
Li, B., Wang, Q., and Hu, J. (2011). Feature subset selec-
tion: a correlation-based svm filter approach. IEEJ
Transactions on Electrical and Electronic Engineer-
ing, 6(2):173–179.
Ma, J. and Kim, N. (2017). Electronic part obsolescence
forecasting based on time series modeling. Interna-
tional Journal of Precision Engineering and Manu-
facturing, 18(5):771–777.
Mellal, M. A. (2020). Obsolescence–a review of the litera-
ture. Technology in Society, page 101347.
Meng, X., Th
¨
ornberg, B., and Olsson, L. (2014). Strate-
gic proactive obsolescence management model. IEEE
Transactions on Components, Packaging and Manu-
facturing Technology, 4(6):1099–1108.
Muthukrishnan, R. and Rohini, R. (2016). Lasso: A fea-
ture selection technique in predictive modeling for
machine learning. In 2016 IEEE international confer-
ence on advances in computer applications (ICACA),
pages 18–20. IEEE.
Omri, N., Al Masry, Z., Mairot, N., Giampiccolo, S., and
Zerhouni, N. (2020). Industrial data management
strategy towards an sme-oriented phm. Journal of
Manufacturing Systems, 56:23–36.
Pingle, P. (2015). Selection of obsolescence resolution strat-
egy based on a multi criteria decision model.
Rish, I. et al. (2001). An empirical study of the naive bayes
classifier. In IJCAI 2001 workshop on empirical meth-
ods in artificial intelligence, volume 3, pages 41–46.
Rojo, F. J. R., Roy, R., and Shehab, E. (2010). Obsoles-
cence management for long-life contracts: state of the
art and future trends. The International Journal of Ad-
vanced Manufacturing Technology, 49(9-12):1235–
1250.
Samb, M. L., Camara, F., Ndiaye, S., Slimani, Y., and
Esseghir, M. A. (2012). Approche de s
´
election
d’attributs pour la classification bas
´
ee sur l’algorithme
rfe-svm. In 11
`
eme Colloque Africain sur la Recherche
en Informatique et Math
´
ematiques.
Sandborn, P. (2007). Software obsolescence-complicating
the part and technology obsolescence management
problem. IEEE Transactions on Components and
Packaging Technologies, 30(4):886–888.
Sandborn, P. (2013). Design for obsolescence risk manage-
ment. Procedia CIRP, 11:15–22.
Sandborn, P. (2017). Forecasting technology and part obso-
lescence. Proceedings of the Institution of Mechanical
Engineers, Part B: Journal of Engineering Manufac-
ture, 231(13):2251–2260.
Sandborn, P., Prabhakar, V., and Ahmad, O. (2011). Fore-
casting electronic part procurement lifetimes to enable
the management of dmsms obsolescence. Microelec-
tronics Reliability, 51(2):392–399.
Solomon, R., Sandborn, P. A., and Pecht, M. G. (2000).
Electronic part life cycle concepts and obsolescence
forecasting. IEEE Transactions on Components and
Packaging Technologies, 23(4):707–717.
Trabelsi, I., Zolghadri, M., Zeddini, B., Barkallah, M., and
Haddar, M. (2020). Fmeca-based risk assessment ap-
proach for proactive obsolescence management. In
IFIP International Conference on Product Lifecycle
Management, pages 215–226. Springer.
Wang, J., Liu, S., Gao, R. X., and Yan, R. (2012). Current
envelope analysis for defect identification and diag-
nosis in induction motors. Journal of Manufacturing
Systems, 31(4):380–387.
Zemouri, R., Omri, N., Devalland, C., Arnould, L., Morello,
B., Zerhouni, N., and Fnaiech, F. (2018). Breast can-
cer diagnosis based on joint variable selection and
constructive deep neural network. In 2018 IEEE 4th
Middle East Conference on Biomedical Engineering
(MECBME), pages 159–164. IEEE.
Zemouri, R., Omri, N., Fnaiech, F., Zerhouni, N., and
Fnaiech, N. (2019). A new growing pruning deep
learning neural network algorithm (gp-dlnn). Neural
Computing and Applications, pages 1–17.
Zhao, Z., Zhang, R., Cox, J., Duling, D., and Sarle, W.
(2013). Massively parallel feature selection: an ap-
proach based on variance preservation. Machine
learning, 92(1):195–220.
ICAART 2021 - 13th International Conference on Agents and Artificial Intelligence
794
