
CUPR: Contrastive Unsupervised Learning for Person Re-identification
Khadija Khaldi
a
and Shishir K. Shah
b
Quantitative Imaging Laboratory, Department of Computer Science, University of Houston, U.S.A.
Keywords:
Person Re-identification, Unsupervised Learning, Contrastive Learning, Deep Learning.
Abstract:
Most of the current person re-identification (Re-ID) algorithms require a large labeled training dataset to
obtain better results. For example, domain adaptation-based approaches rely heavily on limited real-world
data to alleviate the problem of domain shift. However, such assumptions are impractical and rarely hold,
since the data is not freely accessible and require expensive annotation. To address this problem, we propose
a novel pure unsupervised learning approach using contrastive learning (CUPR). Our framework is a simple
iterative approach that learns strong high-level features from raw pixels using contrastive learning and then
performs clustering to generate pseudo-labels. We demonstrate that CUPR outperforms the unsupervised and
semi-supervised state-of-the-art methods on Market-1501 and DukeMTMC-reID datasets.
1 INTRODUCTION
Person re-identification (re-ID) is an important task
in computer vision that aims to match a person
across camera views. Significant research from both
academia and industry has been done to address this
problem. Over the past decade, most of the ex-
isting methods mainly focus on hand-crafted algo-
rithms (Gray and Tao, 2008; Farenzena et al., 2010),
salience analysis (Zhao et al., 2013; Wang et al.,
2014), and dictionary learning (Liu et al., 2014). With
recent advances in deep learning and the rising de-
mand for intelligent video surveillance, this problem
has also been addressed using convolutional neural
network (CNN) models. These methods are catego-
rized into supervised, domain adaptation, and unsu-
pervised learning. While, extensive work has been
done in supervised representation learning (Fu et al.,
2019; Geng et al., 2016; Sun et al., 2018; Li et al.,
2018b) to improve the performance of person re-
ID, they fundamentally require massive labeled data
which is unfeasible and expensive to acquire. There-
fore, domain adaptation and unsupervised learning
approaches were proposed upon the success of deep
learning (Wei et al., 2018; Deng et al., 2018; Wang
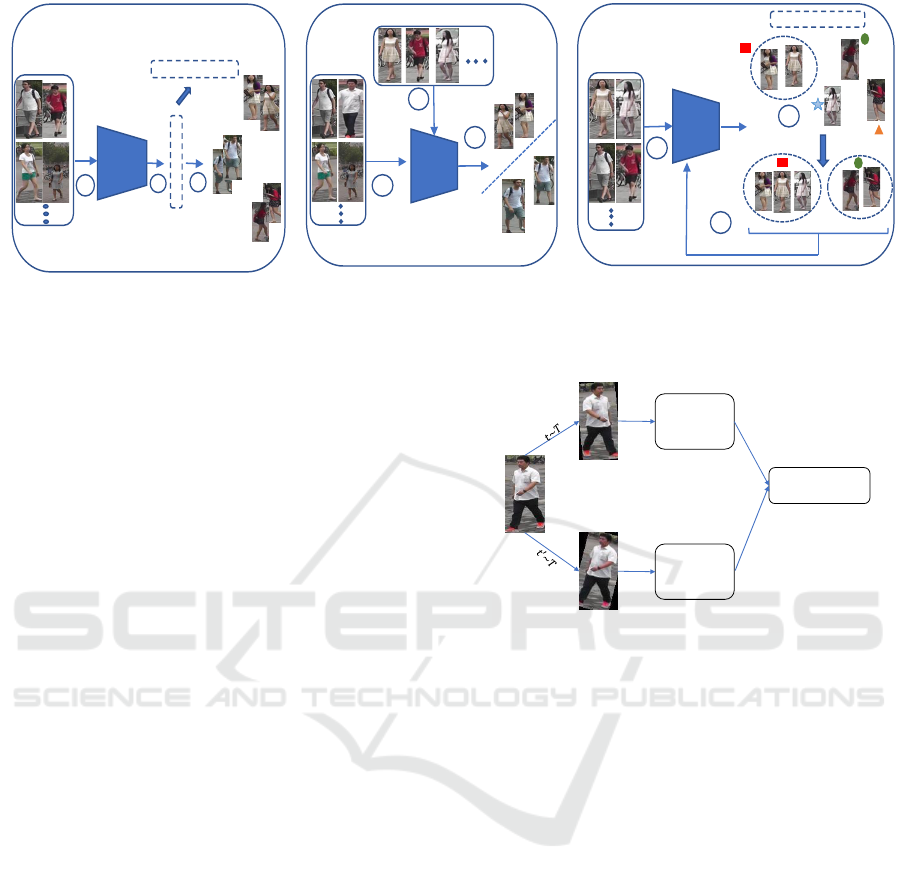
et al., 2018; Lin et al., 2019). An overview of the pre-
vious architectures is shown in Figure 1. While do-
main adaptation methods aim typically to learn a dis-
criminative representation by pre-training the model
a
https://orcid.org/0000-0001-8845-1444
b
https://orcid.org/0000-0003-4093-6906
on labeled source data and then adapt it to the un-
labeled target data. With limited knowledge of the
overlap of the source and the target distribution and
the significant gap between them, these methods re-
main impractical. To address the previous problems,
end-to-end unsupervised methods propose to take ad-
vantage of unlabeled data, e.g. bottom-up cluster-
ing approach (Lin et al., 2019). Specifically, the
latter model starts by considering each sample as
a single cluster, then merges the clusters by apply-
ing a bottom-up clustering approach on the extracted
features. While it does not require annotated data,
this method highly depends on the clustering quality,
which can result in degrading the performance due
to incorrect pseudo labels. To tackle this challenge,
we propose CUPR – Contrastive Unsupervised Learn-
ing for Person re-identification, a novel pure unsuper-
vised learning method. CUPR uses a form of con-
trastive learning that maximizes agreement between
positive pair of the same observation, generated by a
composition of data augmentation, as shown in Fig-
ure 2. We show that CUPR significantly outperforms
prior unsupervised Re-ID state-of-the-art methods by
performing contrastive learning simultaneously with
clustering in an iterative fashion. This allows us
to learn strong feature embedding before generating
pseudo labels in a very simple way requiring no spe-
cialized architectures.
Our paper makes the following key contributions:
We present CUPR, a simple pure unsupervised frame-
work that integrates contrastive learning with clus-
tering. We empirically show that contrastive learn-
92
Khaldi, K. and Shah, S.
CUPR: Contrastive Unsupervised Learning for Person Re-identification.
DOI: 10.5220/0010239900920100
In Proceedings of the 16th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2021) - Volume 5: VISAPP, pages
92-100
ISBN: 978-989-758-488-6
Copyright
c
2021 by SCITEPRESS – Science and Technology Publications, Lda. All rights reserved
0
Labeled source dataset
Unlabeled
target dataset
Model
Model
pre-training
Model
Unlabeled dataset
Pseudo-labels
Cluster merge
(b)
(c)
1
2
3
1
2
3
Labeled dataset
Model
(a)
1
Classification
2
3
Cross-entropy
Clustering- loss
Figure 1: Demonstration of previous person Re-ID methods. (a) Supervised methods, (b) Unsupervised cross-domain adap-
tation and (c) Bottom-up image clustering.
ing can improve the performance of person re-ID,
without using any complicated pipelines as the pre-
vious methods suggest. The experimental results
demonstrate that our approach outperforms the state-
of-art methods on two large-scale datasets including
Market-1501 (Zheng et al., 2015) and DukeMTMC-
reID (Gou et al., 2017).
2 RELATED WORK
Most existing person re-id methods are based on su-
pervised learning, they mainly focus on metric learn-
ing (Geng et al., 2016; Hermans et al., 2017; Lisanti
et al., 2014; Zhong et al., 2017) and view-invariant
feature learning (Deng et al., 2018; Li et al., 2018b;
Bian et al., 2019). However, their scalability is very
limited in the real world, where collecting a tremen-
dous amount of labeled data is expensive and in-
feasible. To alleviate the above limitation, unsuper-
vised person Re-ID methods are proposed to learn
from unlabeled data without expensive manual anno-
tation. Most of them can be considered as a deeply
unsupervised approach, an end-to-end unsupervised
approach, or an unsupervised domain adaptation ap-
proach.
2.1 Deeply Unsupervised Person Re-ID
For deeply unsupervised methods, cross-camera label
estimation is one of the approaches. Ye et al. propose
a dynamic graph matching method (Ye et al., 2017)
where the estimated labels and learned metric are up-
dated in an iterative manner. Liu et al. perform K-
reciprocal nearest neighbor search and negative min-
ing (Liu et al., 2017) to estimate the identities of train-
ing tracklets. Similarly, Ye et al. iteratively assign la-
bels to the unlabeled sequences via robust anchor em-
Encoder
Encoder
x
Contrastive Loss
x
x
q
z
q
z
k
q
x
q
Figure 2: Demonstration of contrastive learning for person
re-identification. Two random data augmentation (t∼T and
t’∼ T ) are applied to an anchor to generate positive pair.
The input sample is treated as an anchor while x
k
and x
q
is
the positive pair. CUPR trains an encoder network f
θ
(.) to
ensure that data-augmented embeddings of the same iden-
tity are close to each other.
bedding and top-k counts label prediction, to collect
more anchor video sequences (Ye et al., 2018).
2.2 End-to-End Unsupervised Person
Re-ID
Li et al. propose a Tracklet Association Unsuper-
vised Deep Learning (TAUDL) framework (Li et al.,
2018a), which jointly conducts the within-camera
tracklet discrimination and models the cross-camera
tracklet association. Similarly, Wu et al. introduce
an unsupervised camera-aware similarity consistency
mining approach (Wu et al., 2019) by exploring the
relation of pairwise similarity between intra-camera
matching and cross-camera matching. Yang et al.
propose a PatchNet model (Yang et al., 2019) to learn
discriminative patch features. They train their model
by pulling the features of similar patches together and
pushing dissimilar ones away.
CUPR: Contrastive Unsupervised Learning for Person Re-identification
93

On the other hand, some methods explore itera-
tive clustering to reduce the labeling efforts. Lin et
al. iteratively train their model using pseudo-labels
generated by bottom-up clustering (Lin et al., 2019).
Our method aligns with the last approach, as we
are using an iterative clustering approach. How-
ever, we propose to learn a strong adaptative feature
embedding using contrastive loss, before generating
pseudo-labels.
2.3 Unsupervised Domain Adaptation
Recently, cross-domain transfer learning is used in the
unsupervised re-ID task where knowledge from an ex-
ternal labeled source dataset is transferred to an unla-
beled target dataset.
Among these existing works, GAN has been used
to transfer the source domain images to target-domain
style. To handle the domain shift problem, Wei et al.
(Wei et al., 2018) propose a Person Transfer Gen-
erative Adversarial Network (PTGAN), transferring
the knowledge from one labeled source dataset to an-
other unlabeled target dataset. Similarly, a “learn-
ing via translation” framework (Deng et al., 2018)
is proposed with similarity preserving image gener-
ation (SPGAN). Also, Wang et al. develop TJ-AIDL
framework (Wang et al., 2018), which learns jointly
an attribute semantic and identity discriminative fea-
ture representation space from a labeled source do-
main, then transfer it to any an unlabeled domain.
Similar to supervised learning, these domain
adaptation approaches suffer from the need for col-
lecting annotations for the source dataset. Thus, our
work focuses on the pure unsupervised setting, where
there is no need for data annotation.
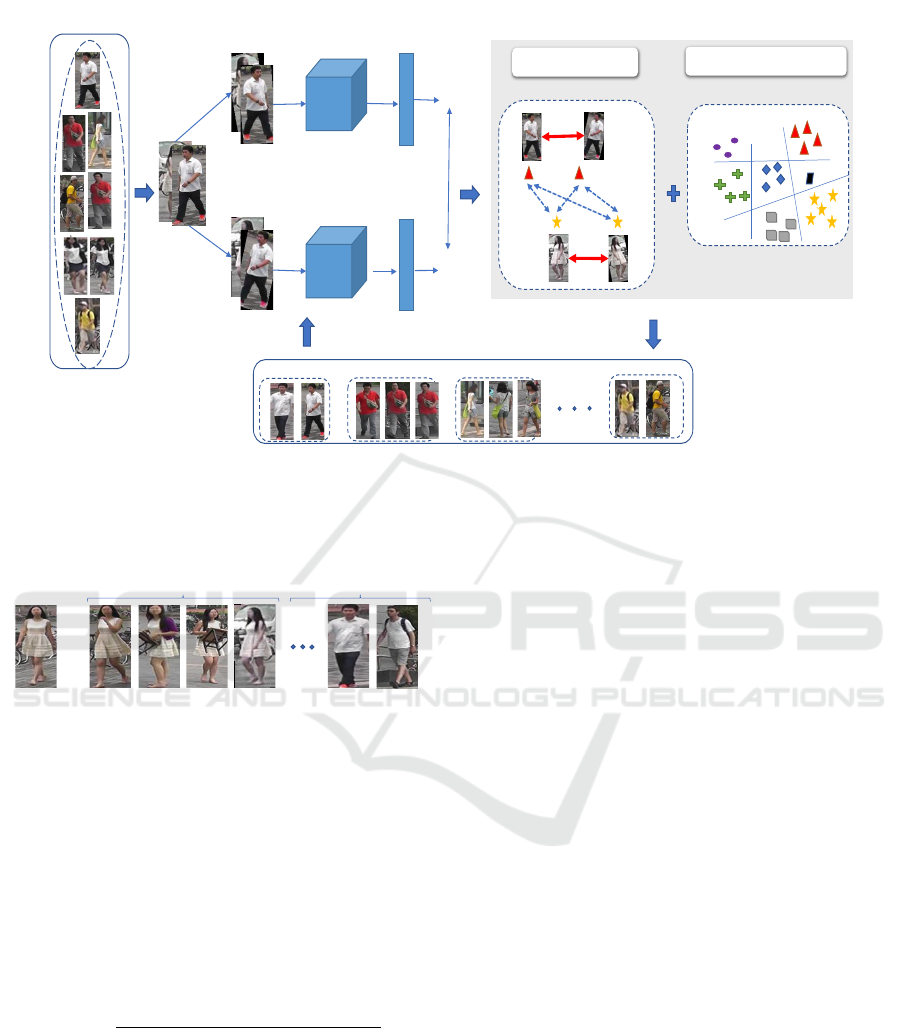
3 PROPOSED METHOD
In this section, we introduce our learning framework
CUPR for unsupervised person re-identification. We
first present the contrastive learning approach, a key
component of our model, which is able to learn
strong representations with no labels. Then, we per-
form a hierarchical-based clustering algorithm on the
learned features to generate pseudo-labels. In prin-
ciple, one could use any clustering algorithm in the
CUPR pipeline. The overview of our proposed frame-
work is described in Figure 3.
Given a training set:
D = {x
1
,x
2
,. . . ,x
N
} (1)
of N unlabeled images, our goal is to learn an encoder
f
θ
(.) that maps high dimensional pixels to strong fea-
ture vector V
i
.
V
i
= f
θ
(x
i
) (2)
CUPR is mainly composed of a CNN backbone
and a pseudo-label generation network. To optimize
the model without human supervision, we propose
two types of self-supervision: (1) contrastive learning
(L
c
) and (2) clustering-based learning (L
cl
). Com-
bining these two losses, the model is able to jointly
consider generating rich representation and forming
well-separated and dense clusters.
At evaluation time, the trained encoder f
θ
(.) gen-
erate feature vectors for the query set {x
q
1
,x
q
2
,. . . ,x
q
N
q
}
and the galley set {x
g
1
,x
g
2
,. . . ,x
g
N
g
}. Then, a pairwise
distance defined as following, is used to perform re-id
matching.
D(x
q
i
,x
g
i
) = k f
θ
(x
q
i
) − f
θ
(x
g
i
)k (3)
3.1 Contrastive Stage
In recent years, discriminative approaches have
shown a lot of promise in learning visual represen-
tation without human supervision, particularly accel-
erated by a well-known paradigm called contrastive
learning (Hadsell et al., 2006; Dosovitskiy et al.,
2014; Oord et al., 2018; Bachman et al., 2019).
One of the key challenges for contrastive learning
is defining positives and negative samples relative to
an anchor. Inspired by recent contrastive learning al-
gorithms (Chen et al., 2020; He et al., 2019), for each
data sample we create two positive pair (x
i
and x
j
), by
applying a composition of multiple data augmenta-
tion operations. This will generate images with a rich
appearance and a view variation. In this work, we
sequentially apply three simple augmentations: ran-
dom cropping, horizontal flipping, and color jittering.
Other data augmentation combination were used, but
they resulted in lower performance. Then, our base
encoder f
θ
(.) extracts feature vectors form the aug-
mented data examples as following.
f
θ
(x
i
) = z
i
, z
i
∈ R (4)
To this end, we randomly sample a mini-batch of
M examples and generate a pair of positive pair for
each sample, resulting in 2M data points. Differently
from SimCLR (Chen et al., 2020), we explicitly de-
fine our negative samples. Otherwise, while trying
to maximize the agreement between the augmented
views, we will minimize the agreement between them
and other samples of the same person identity. There-
fore, to avoid this problem we use a neighborhood ap-
proach to mine the negative samples in a mini-batch
which is illustrated in Figure 4. Given the feature vec-
tors z
i
, we compute the pairwise distance between z
i
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
94
CNN
CNN
Embedding
Embedding
Encoder
(. )
Push
away
Pull
closer
Pull
closer
Contrastive Loss ℒ
Clustering-based Loss ℒ
Person 1
Person 3
Person 2
Person N
Generate Pseudo-labels
Maximize agreement
Unlabeled data
(1)
(2)
(3)
(4)
Figure 3: An illustration of the Contrastive Unsupervised Learning for Person Re-Identification. CUPR is an iterative frame-
work mainly composed of a CNN backbone and aims to learn rich representations. First, our framework extracts image
features with a CNN model, then the HDBSCAN clustering method is performed using the feature similarities to generate
pseudo-labels. In an iterative end-to-end fashion, our model CUPR is trained using two optimization functions: (1) contrastive
loss and (2) clustering-based loss.
Sample
Top -r list
Ranking list
Negative samples
Figure 4: An illustration of mining negative samples in a
mini-batch. We compute the ranking list N
i
for the target
image x
i
, then we select negative samples not belonging to
top-r list R
i
.
and all other augmented examples z
k
within a mini-
batch, and thus we can get the ranking list N
i
for the
sample x
i
. Then, we argue that the augmented sam-
ples not in the top-r nearest neighbor list R
i
are likely
to be the negative samples.
Finally, we define our contrastive loss function for a
positive pair (i, j) in a mini-batch as follows:
L
c
= −log
exp(sim(z
i
,z
j
)/τ)
∑
2M
k=1,k /∈R
i
1
[k6=i]
exp(sim(z
i
,z
k
)/τ)
(5)
where 1
[k6=i]
is an indicator function evaluating
to 1 iff k 6= i and τ is a temperature parameter that
controls the softness of probability distribution over
classes. The final loss is computed across all positive
pairs, both (i, j) and (j, i), in a mini-batch.
3.2 Clustering Stage
Combining clustering and representation learning is
one of the most effective strategies for unsupervised
learning. This has been adopted by the recent Deep-
Cluster method (Caron et al., 2018). However, it is
not trivial to apply clustering for person re-id due to
the presence of different viewpoints and low-image
resolution. Therefore, we design a clustering-based
learning strategy that not only generates reliable clus-
ters but also boosts the model performance.
Given the training data T = {x
1
,x
2
,. . . ,x
N
}, at
the beginning we generate feature vectors F =
{ f
θ
(x
1
), f
θ
(x
2
),. . . , f
θ
(x
N
)}, then we compute the co-
sine similarity between the feature vectors of sample
x
i
and all the other samples to generate the following
distance matrix D as:
D = [D(x
1
) D(x
2
) ... D(x
N
)]
T
, (6)
D(x
i
) = V
T
.v
i
, v
i
= f
θ
(x
i
)
∀i ∈ {1, 2, ..., N}
Then, we apply a hierarchical density-based clus-
tering algorithm (HDBSCAN) (Campello et al., 2013)
(other clustering methods can be employed) to obtain
reliable clusters for self-supervision. Each cluster is
considered as a specific class, in which samples of the
same cluster can be assigned to the same pseudo label.
CUPR: Contrastive Unsupervised Learning for Person Re-identification
95

Algorithm 1: Contrastive Unsupervised Learning for re-ID.
Input : Unlabeled training data
T = {x
i
}
N
; I
max
; epoch
max
;
batch
max
Output : Model M.
Initialization: Initialize Model parameters θ
1 for step = 1 → I
max
do
2 for e = 1 → epoch
max
do
3 for b = 1 → batch
max
do
4 Generate positive pair z
i
and z
j
5 Extract feature vectors V = f
θ
(.)
6 Compute distance matrix Eq.(6)
7 Compute contrastive-loss L
c
Eq.5
8 Compute cluster-loss L
cl
Eq.(7)
9 Backward to update θ Eq.(9)
10 Update the memory bank V
C
11 end for
12 end for
13 Generate new pseudo-labels
14 Initialize memory V with new dimensions
15 Evaluate the performance of f
θ
(.)
16 if Per f > Per f
∗
then
17 θ
∗
= θ
18 end if
19 end for
Note that HDBSCAN discard images not belong-
ing to any cluster by considering them as noise. To
address this limitation, we consider discarded images
as individual clusters of single data points.
Finally, we minimize the clustering-based loss
function L
cl
, which is formulated as follows:
L
cl
= −log
exp(V
T
c,i
v
i
/τ)
∑
C
j=1
exp(V
T
c, j
v
i
/τ)
(7)
where V
c
is an external memory bank that stores the
feature vectors for each cluster, and C is the number
of clusters at the current step.
At the first training stage, C = N. τ denotes a temper-
ature parameter. The memory bank is updated as:
V
y
i
(t) ←
1
2
(V
y
i
+V
y
i
(t − 1)) (8)
where V
y
i
denotes the up-to-date y
i
-th column of the
memory bank V.
To summarize, the total loss function for each im-
age in a mini-batch of our model is then formulated
as:
L = L
cl
+ λL
c
(9)
4 EXPERIMENT
4.1 Datasets
To evaluate our proposed method, we carried
out experiments on two large-scale person Re-ID
datasets, namely Market-1501 (Zheng et al., 2015),
DukeMTMC-reID (Gou et al., 2017). Market-
1501 (Zheng et al., 2015) is a large-scale dataset for
person re-ID captured by 6 cameras on a university
campus, where pedestrians are detected and cropped
by the Deformable Part Model (DPM) (Felzenszwalb
et al., 2009). The dataset contains 12,936 images of
751 identities for training and 19,732 images of 750
identities for testing. DukeMTMC-reID (Gou et al.,
2017) is a large-scale re-ID dataset derived from the
DukeMTMC dataset (Ristani et al., 2016) and has 8
cameras. It contains 36,411 labeled images of 1,404
identities. Similar to Market1501, 702 identities are
used for training and remaining identities as testing.
4.2 Protocols
For performance measurement, we use the cumulative
matching characteristic (CMC) and the mean Average
Precision (mAP). We report the rank-k scores which
represent the retrieval precision and the mAP value
which reflects the overall recall rate.
4.3 Implementation Details
We adopt ResNet-50 (He et al., 2016) without the
last classification layer as the base neural network en-
coder with pre-trained weights on ImageNet (Deng
et al., 2009). We first generate positive pairs using
augmentation operations such as: cropping, horizon-
tal flipping and color jittering. During training, we
set the number of iterations to be 13 and the training
epochs in the first stage to be 20 and 5 for the re-
maining steps. We use stochastic gradient descent as
the optimization with a momentum of 0.9 to optimize
the model. The learning rate is initialized to 0.1 and
changed to 0.01 after 15 epochs. For the clustering
stage, the minimum sample parameter for the HDB-
SCAN (Campello et al., 2013) algorithm is set to 3.
4.4 Comparison with the State of the
Art
We compare our proposed CUPR framework with
4 types of state-of-the art unsupervised re-id meth-
ods: (1) unsupervised cross-domain re-id models
(TJAIDL (Wang et al., 2018), SPGAN (Deng et al.,
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
96
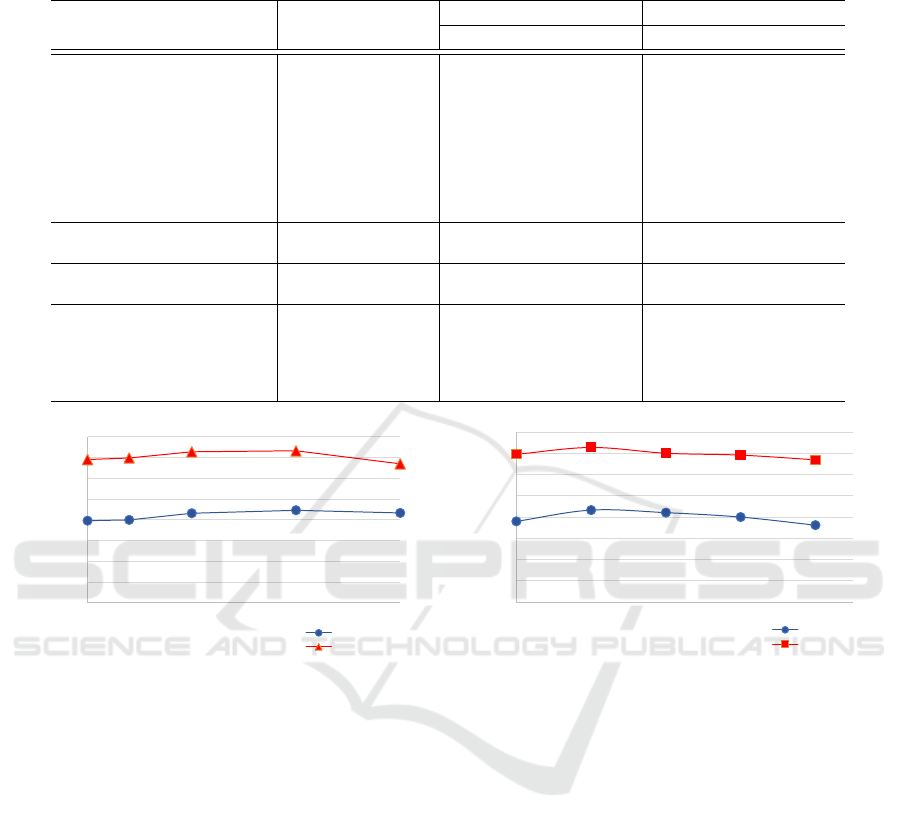
Table 1: Comparisons with the state-of-the-art person re-id methods on Market-1501 and DukeMTMC-reID. The 1st and 2nd
highest scores are marked by red and blue respectively.
Methods Labels
Market-1501 DukeMTMC-reID
mAP rank-1 rank-5 mAP rank-1 rank-5
TJAIDL (Wang et al., 2018)
Cross-domain:
labeled source
26.5 58.2 74.8 23.0 44.3 59.6
SPGAN (Deng et al., 2018) 26.9 58.1 76.0 26.4 46.9 62.6
PTGAN (Wei et al., 2018) 15.7 38.6 57.3 13.5 27.4 43.6
HHL (Zhong et al., 2018) 31.4 62.2 78.8 27.2 46.9 61.0
PAUL (Yang et al., 2019) 36.8 66.7 - 35.7 56.1 -
ATNet (Liu et al., 2019) 25.6 55.7 73.2 24.9 45.1 59.5
PUL (Fan et al., 2018) 20.1 44.7 59.1 16.4 30.4 46.04
EUG (Wu et al., 2018)
One labeled image
per identity
26.2 55.8 72.3 28.5 48.8 63.4
TAUDL (Li et al., 2018a)
Pure unsupervised:
Camera label
41.2 63.7 - 43.5 61.7 -
OIM (Xiao et al., 2017)
Pure unsupervised:
No label
14.0 38.0 58.0 11.3 24.5 38.8
BUC (Lin et al., 2019) 29.6 61.9 73.3 22.1 40.4 52.5
TSSL (Wu et al., 2020) 43.3 71.2 - 38.5 62.2 -
Ours 44.6 73.3 84.6 41.4 64.2 76.2
0
10
20
30
40
50
60
70
80
0 0.5 1 1.5
Rank-1 and mAP Scores (%)
(a) Loss weight
mAP Score (%)
Rank-1
0
10
20
30
40
50
60
70
80
1 3 5 7 9
Rank-
1 and mAP Scores (%)
(b) Minimum Sample
mAP Score (%)
Rank-1
Figure 5: Analysis of hyper-parameters. (a): The impact of the loss weight λ. (b): The impact of the minimum sample S
min
for each cluster generated by HDBSCAN.
2018) PTGAN (Wei et al., 2018), HHL (Zhong et al.,
2018), PAUL (Yang et al., 2019), ATNet (Liu et al.,
2019)) and PUL (Fan et al., 2018), (2) one labeled
image per identity models (EUG (Wu et al., 2018)),
and (3) pure unsupervised re-id models (TAUDL (Li
et al., 2018a), OIM (Xiao et al., 2017), BUC (Lin
et al., 2019), TSSL (Wu et al., 2020)).
The comparisons are shown in Table 1. On
Market-1501, we obtain the best performance among
the compared methods with rank-1 = 73.3%, mAP
= 44.6%. Therefore, we improved the state of the
art TSSL (Wu et al., 2020) by 2.1% and 1.3% re-
spectively, by using a simple learning framework.
Compared with OIM (Xiao et al., 2017), we achieve
35.3% more in rank-1 score and 30.6% improvement
in mAP. We also compare our method to the state-of-
the-art cross-domain methods. Although these meth-
ods exploit labelled source data, our approach clearly
outperforms the cross-domain state of the art method
with 6.6% in rank-1 accuracy and 7.8% in mAP.
Similarly, CUPR surpasses all previous methods on
DukeMTMC-reID by the best rank-1 accuracy 64.2%
and the second best mAP 41.4%. While TAUDL (Li
et al., 2018a) performs better in terms of mAP, it as-
sumes extra camera annotation.
Without any human supervising, CUPR outper-
forms the state-of-the-art methods, which indicates
that our method is not only effective in exploiting the
unlabeled data, but it is also simple and require no
complex architecture.
4.5 Algorithm Analysis
We perform an analysis on three parameters: (1) the
loss weight in Eq.(9), (2) the minimum samples pa-
rameter for HDBSCAN and (3) the temperature pa-
rameter in Eq.(5) to evaluate the parameters sensitiv-
ity.
Analysis of the Loss Weight. λ is a hyperparame-
ter used to control the relative importance of the con-
trastive loss L
c
. We sample λ from {0,0.2,0.5,1,1.5}
CUPR: Contrastive Unsupervised Learning for Person Re-identification
97

-40
-20
0
20
40
- 40 - 20 0 20 40
Figure 6: T-SNE visualization of feature distribution of 50
random identities from Market-1501 dataset. Samples with
the same color represent the same identity. Samples with
different colors grouped together are False Positives. The
model groups them by mistake because they look very sim-
ilar.
to evaluate its impact on the result. As shown in
Figure 5.(a), the performance of CUPR increases to
73.3% in rank-1 accuracy and 44.6% in mAP from
λ = 0.5 to λ = 1, then after start gradually decreas-
ing.
Analysis of the Temperature. τ is a parameter that
controls the softness of probability distribution over
our clusters. To test its effect, we sample τ from the
set {0.1, 0.2, 0.5, 1}. We observed that the best result
is obtained when τ is set to 0.5.
Analysis of the Minimum Sample. In this study, we
analyse the effect of the number of minimum samples
S
min
on the Re-ID results. The larger the value of S
min
we provide, the more conservative our clustering will
be. We test the impact of {1,3, 5, 7, 9} minimum sam-
ples on the performance of our CUPR framework. As
shown in Figure 5.(b), we can see that setting S
min
to
3 yields to higher accuracy. Meanwhile, larger S
min
results in declaring lot of points as a noise which neg-
atively impact the accuracy results.
Qualitative Analysis. To further explore the distribu-
tion of the learned features, we used T-SNE to visual-
ize the feature embedding of the clusters, by plotting
50 random identities in a 2-dimensional space. As
shown in Figure 6, samples of the same identity are
grouped together.
5 CONCLUSION
In this paper, we propose a novel contrastive unsuper-
vised learning approach for person re-identification
(CUPR). It jointly learns a discriminative represen-
tation of unlabeled data and optimizes a CNN model
to generate accurate pseudo-labels using clustering.
Specifically, the model is trained by considering each
sample as an individual cluster. Then, hierarchical
clustering algorithm is applied to the feature embed-
ding learned from the model to generate new pseudo-
labels. The key component of CUPR is demonstrated
by its simple architecture and its ability to exploit un-
labeled data. By combining our findings, we improve
considerably over previous methods for self super-
vised, semi-supervised, and cross-domain methods.
REFERENCES
Bachman, P., Hjelm, R. D., and Buchwalter, W. (2019).
Learning representations by maximizing mutual infor-
mation across views. In Advances in Neural Informa-
tion Processing Systems, pages 15509–15519.
Bian, J.-W., Wu, Y.-H., Zhao, J., Liu, Y., Zhang, L., Cheng,
M.-M., and Reid, I. (2019). An evaluation of fea-
ture matchers for fundamental matrix estimation. In
British machine vision conference (BMVC), volume 2.
Campello, R. J., Moulavi, D., and Sander, J. (2013).
Density-based clustering based on hierarchical den-
sity estimates. In Pacific-Asia conference on knowl-
edge discovery and data mining, pages 160–172.
Springer.
Caron, M., Bojanowski, P., Joulin, A., and Douze, M.
(2018). Deep clustering for unsupervised learning of
visual features. In Proceedings of the European Con-
ference on Computer Vision (ECCV), pages 132–149.
Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. (2020).
A simple framework for contrastive learning of visual
representations. arXiv preprint arXiv:2002.05709.
Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., and Fei-
Fei, L. (2009). Imagenet: A large-scale hierarchical
image database. In 2009 IEEE conference on com-
puter vision and pattern recognition, pages 248–255.
Ieee.
Deng, W., Zheng, L., Ye, Q., Kang, G., Yang, Y., and
Jiao, J. (2018). Image-image domain adaptation with
preserved self-similarity and domain-dissimilarity for
person re-identification. In Proceedings of the IEEE
conference on computer vision and pattern recogni-
tion, pages 994–1003.
Dosovitskiy, A., Springenberg, J. T., Riedmiller, M., and
Brox, T. (2014). Discriminative unsupervised fea-
ture learning with convolutional neural networks. In
Advances in neural information processing systems,
pages 766–774.
Fan, H., Zheng, L., Yan, C., and Yang, Y. (2018). Un-
supervised person re-identification: Clustering and
fine-tuning. ACM Transactions on Multimedia Com-
puting, Communications, and Applications (TOMM),
14(4):1–18.
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
98

Farenzena, M., Bazzani, L., Perina, A., Murino, V., and
Cristani, M. (2010). Person re-identification by
symmetry-driven accumulation of local features. In
2010 IEEE Computer Society Conference on Com-
puter Vision and Pattern Recognition, pages 2360–
2367. IEEE.
Felzenszwalb, P. F., Girshick, R. B., McAllester, D., and
Ramanan, D. (2009). Object detection with discrim-
inatively trained part-based models. IEEE transac-
tions on pattern analysis and machine intelligence,
32(9):1627–1645.
Fu, Y., Wei, Y., Zhou, Y., Shi, H., Huang, G., Wang, X.,
Yao, Z., and Huang, T. (2019). Horizontal pyramid
matching for person re-identification. In Proceedings
of the AAAI Conference on Artificial Intelligence, vol-
ume 33, pages 8295–8302.
Geng, M., Wang, Y., Xiang, T., and Tian, Y. (2016). Deep
transfer learning for person re-identification. arXiv
preprint arXiv:1611.05244.
Gou, M., Karanam, S., Liu, W., Camps, O., and Radke,
R. J. (2017). Dukemtmc4reid: A large-scale multi-
camera person re-identification dataset. In Proceed-
ings of the IEEE Conference on Computer Vision and
Pattern Recognition Workshops, pages 10–19.
Gray, D. and Tao, H. (2008). Viewpoint invariant pedestrian
recognition with an ensemble of localized features. In
European conference on computer vision, pages 262–
275. Springer.
Hadsell, R., Chopra, S., and LeCun, Y. (2006). Dimen-
sionality reduction by learning an invariant mapping.
In 2006 IEEE Computer Society Conference on Com-
puter Vision and Pattern Recognition (CVPR’06), vol-
ume 2, pages 1735–1742. IEEE.
He, K., Fan, H., Wu, Y., Xie, S., and Girshick, R. (2019).
Momentum contrast for unsupervised visual represen-
tation learning. arXiv preprint arXiv:1911.05722.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep resid-
ual learning for image recognition. In Proceedings of
the IEEE conference on computer vision and pattern
recognition, pages 770–778.
Hermans, A., Beyer, L., and Leibe, B. (2017). In defense
of the triplet loss for person re-identification. arXiv
preprint arXiv:1703.07737.
Li, M., Zhu, X., and Gong, S. (2018a). Unsupervised per-
son re-identification by deep learning tracklet associ-
ation. In Proceedings of the European conference on
computer vision (ECCV), pages 737–753.
Li, W., Zhu, X., and Gong, S. (2018b). Harmonious atten-
tion network for person re-identification. In Proceed-
ings of the IEEE conference on computer vision and
pattern recognition, pages 2285–2294.
Lin, Y., Dong, X., Zheng, L., Yan, Y., and Yang, Y. (2019).
A bottom-up clustering approach to unsupervised per-
son re-identification. In Proceedings of the AAAI Con-
ference on Artificial Intelligence, volume 33, pages
8738–8745.
Lisanti, G., Masi, I., Bagdanov, A. D., and Del Bimbo,
A. (2014). Person re-identification by iterative re-
weighted sparse ranking. IEEE transactions on pat-
tern analysis and machine intelligence, 37(8):1629–
1642.
Liu, J., Zha, Z.-J., Chen, D., Hong, R., and Wang, M.
(2019). Adaptive transfer network for cross-domain
person re-identification. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recogni-
tion, pages 7202–7211.
Liu, X., Song, M., Tao, D., Zhou, X., Chen, C., and Bu,
J. (2014). Semi-supervised coupled dictionary learn-
ing for person re-identification. In Proceedings of
the IEEE Conference on Computer Vision and Pattern
Recognition, pages 3550–3557.
Liu, Z., Wang, D., and Lu, H. (2017). Stepwise met-
ric promotion for unsupervised video person re-
identification. In Proceedings of the IEEE interna-
tional conference on computer vision, pages 2429–
2438.
Oord, A. v. d., Li, Y., and Vinyals, O. (2018). Representa-
tion learning with contrastive predictive coding. arXiv
preprint arXiv:1807.03748.
Ristani, E., Solera, F., Zou, R., Cucchiara, R., and Tomasi,
C. (2016). Performance measures and a data set
for multi-target, multi-camera tracking. In Euro-
pean Conference on Computer Vision, pages 17–35.
Springer.
Sun, Y., Zheng, L., Yang, Y., Tian, Q., and Wang, S. (2018).
Beyond part models: Person retrieval with refined part
pooling (and a strong convolutional baseline). In Pro-
ceedings of the European Conference on Computer Vi-
sion (ECCV), pages 480–496.
Wang, H., Gong, S., and Xiang, T. (2014). Unsupervised
learning of generative topic saliency for person re-
identification. In Proceedings of the British Machine
Vision Conference. BMVA Press.
Wang, J., Zhu, X., Gong, S., and Li, W. (2018). Transferable
joint attribute-identity deep learning for unsupervised
person re-identification. In Proceedings of the IEEE
Conference on Computer Vision and Pattern Recogni-
tion, pages 2275–2284.
Wei, L., Zhang, S., Gao, W., and Tian, Q. (2018). Per-
son transfer gan to bridge domain gap for person re-
identification. In Proceedings of the IEEE conference
on computer vision and pattern recognition, pages 79–
88.
Wu, A., Zheng, W.-S., and Lai, J.-H. (2019). Unsuper-
vised person re-identification by camera-aware sim-
ilarity consistency learning. In Proceedings of the
IEEE International Conference on Computer Vision,
pages 6922–6931.
Wu, G., Zhu, X., and Gong, S. (2020). Tracklet
self-supervised learning for unsupervised person re-
identification. In AAAI Conference on Artificial Intel-
ligence, volume 2.
Wu, Y., Lin, Y., Dong, X., Yan, Y., Ouyang, W., and Yang,
Y. (2018). Exploit the unknown gradually: One-
shot video-based person re-identification by stepwise
learning. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, pages
5177–5186.
CUPR: Contrastive Unsupervised Learning for Person Re-identification
99

Xiao, T., Li, S., Wang, B., Lin, L., and Wang, X. (2017).
Joint detection and identification feature learning for
person search. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, pages
3415–3424.
Yang, Q., Yu, H.-X., Wu, A., and Zheng, W.-S. (2019).
Patch-based discriminative feature learning for unsu-
pervised person re-identification. In Proceedings of
the IEEE Conference on Computer Vision and Pattern
Recognition, pages 3633–3642.
Ye, M., Lan, X., and Yuen, P. C. (2018). Robust an-
chor embedding for unsupervised video person re-
identification in the wild. In Proceedings of the Euro-
pean Conference on Computer Vision (ECCV), pages
170–186.
Ye, M., Ma, A. J., Zheng, L., Li, J., and Yuen, P. C. (2017).
Dynamic label graph matching for unsupervised video
re-identification. In Proceedings of the IEEE inter-
national conference on computer vision, pages 5142–
5150.
Zhao, R., Ouyang, W., and Wang, X. (2013). Unsupervised
salience learning for person re-identification. In Pro-
ceedings of the IEEE Conference on Computer Vision
and Pattern Recognition, pages 3586–3593.
Zheng, L., Shen, L., Tian, L., Wang, S., Wang, J., and Tian,
Q. (2015). Scalable person re-identification: A bench-
mark. In Proceedings of the IEEE international con-
ference on computer vision, pages 1116–1124.
Zhong, Z., Zheng, L., Cao, D., and Li, S. (2017). Re-
ranking person re-identification with k-reciprocal en-
coding. In Proceedings of the IEEE Conference
on Computer Vision and Pattern Recognition, pages
1318–1327.
Zhong, Z., Zheng, L., Li, S., and Yang, Y. (2018). Gener-
alizing a person retrieval model hetero-and homoge-
neously. In Proceedings of the European Conference
on Computer Vision (ECCV), pages 172–188.
VISAPP 2021 - 16th International Conference on Computer Vision Theory and Applications
100
